CVPR最佳论文:探索RAHF模型捕捉人类反馈在T2I领域的创新实践_rich human feedback
赞
踩
一、摘要

论文:Rich Human Feedback for Text-to-Image Generation,https://arxiv.org/pdf/2312.10240
代码:https://github.com/google-research/google-research/tree/master/richhf_18k
这篇论文《Rich Human Feedback for Text-to-Image Generation》由多个作者合作完成,主要来自加州大学圣地亚哥分校、谷歌研究院、南加州大学、剑桥大学和布兰迪斯大学。论文的核心内容是关于文本到图像(Text-to-Image, T2I)生成模型的最新进展和面临的挑战,挑战如生成图像的伪影/不合理性、与文本描述不一致以及美学质量低下。为了解决这些问题,作者们受到人类反馈强化学习(Reinforcement Learning with Human Feedback, RLHF)在大型语言模型中成功的启发,提出了一种新的方法来丰富反馈信号:通过标记图像中不合理或与文本不一致的区域,并注释文本提示中在图像中未被正确表示或缺失的词汇。作者们收集了18,000张生成图像的丰富人类反馈(RichHF-18K),并训练了一个多模态变换器来自动预测这些丰富的反馈。研究表明,预测的丰富人类反馈可以用来改进图像生成,例如,通过选择高质量的训练数据进行微调,或通过创建掩膜来修复问题区域。值得注意的是,这些改进可以推广到超出训练集中使用的模型范围,如Muse模型。此外,作者们还计划发布RichHF-18K数据集,以便社区进一步研究和开发。
二、核心创新
本文的核心算法创新主要体现在以下几个方面:
-
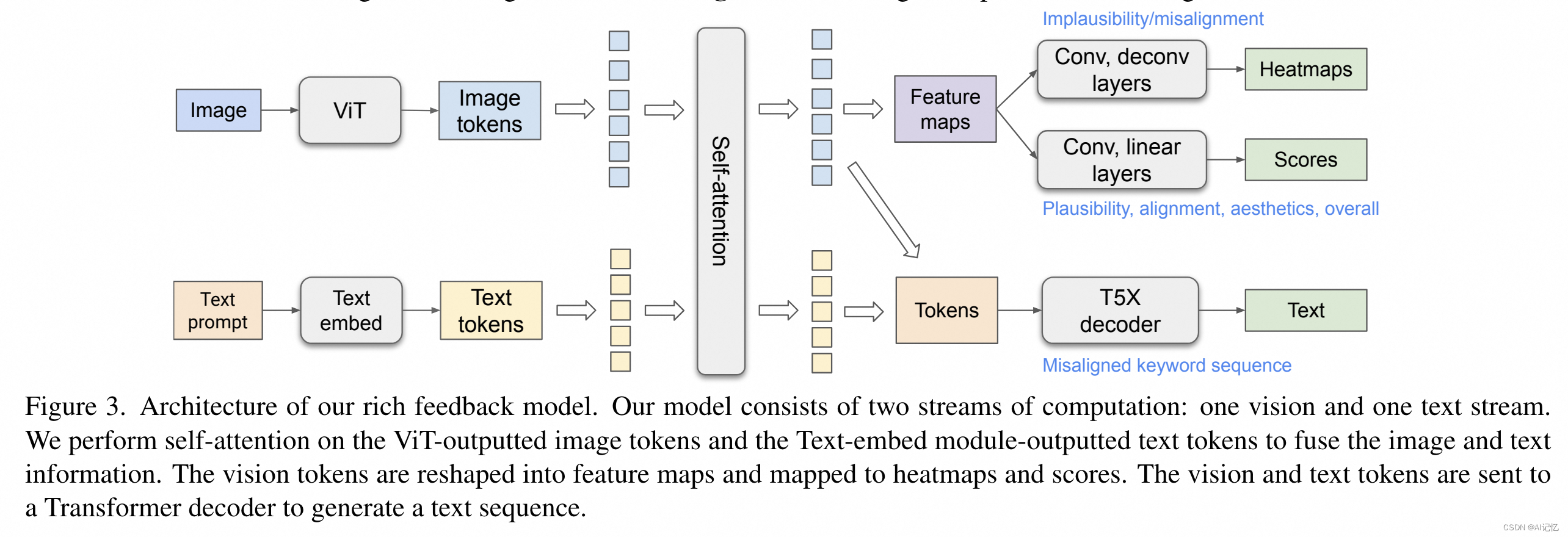
多模态Transformer模型(RAHF):创新性地设计了一个多模态Transformer模型,用于自动预测丰富的人类反馈。该模型融合了图像和文本信息,通过自注意力机制来理解和预测人类对生成图像的评价。模型能够预测图像中不合理或与文本描述不一致的区域(通过热图表示),以及文本提示中未正确表示或缺失的概念(通过标记关键词)。
-
综合评分系统:引入了一套综合评分系统,包括图像合理性、文本-图像对齐、美学和整体评分,为评估生成图像提供了更丰富的维度。
-
面向多类型任务的模型设计(Augmented Prompt):通过在文本提示中增加任务类型信息,模型能够为不同的预测任务生成特定的视觉特征图和文本编码,从而能share更多参数,减少模型的head数,提高特定任务的性能。
-
损失函数设计:为模型设计了一种复合损失函数,结合了像素级均方误差(MSE)损失、分数预测的MSE损失以及序列预测的教师强制交叉熵损失,以优化模型的预测性能。
-
数据集贡献和注释方法的创新:创建了RichHF-18K数据集,该数据集通过详细的人类反馈对生成的图像进行了注释,包括图像区域的标记和文本-图像不一致的关键词标注,这为模型训练提供了高质量的训练数据。

三、实验结果
a.)定性结果
本文的定性实验结果主要体现在以下几个方面:
-
分数预测(Score Prediction):展示了模型预测的分数与人类标注者给出的分数之间的对比,如图7所示,其中包括合理性、美学、文本-图像对齐和整体评分的例子。

-
不合理/不一致热图预测(Implausibility/Misalignment Heatmap Prediction):提供了模型预测的不合理和不一致热图的例子,如图5和图6所示,展示了模型如何识别图像中的特定区域,这些区域与文本提示不匹配或包含不合理的元素。

-
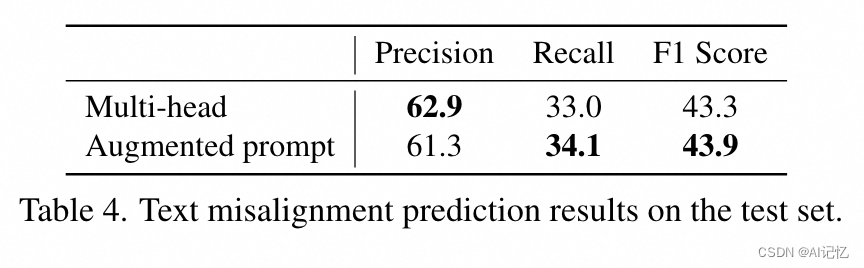
文本不一致关键词预测(Text Misalignment Prediction):展示了模型预测的文本不一致关键词的例子,如图14所示,模型能够识别并预测人类标注者标记的文本中的不一致关键词。

-
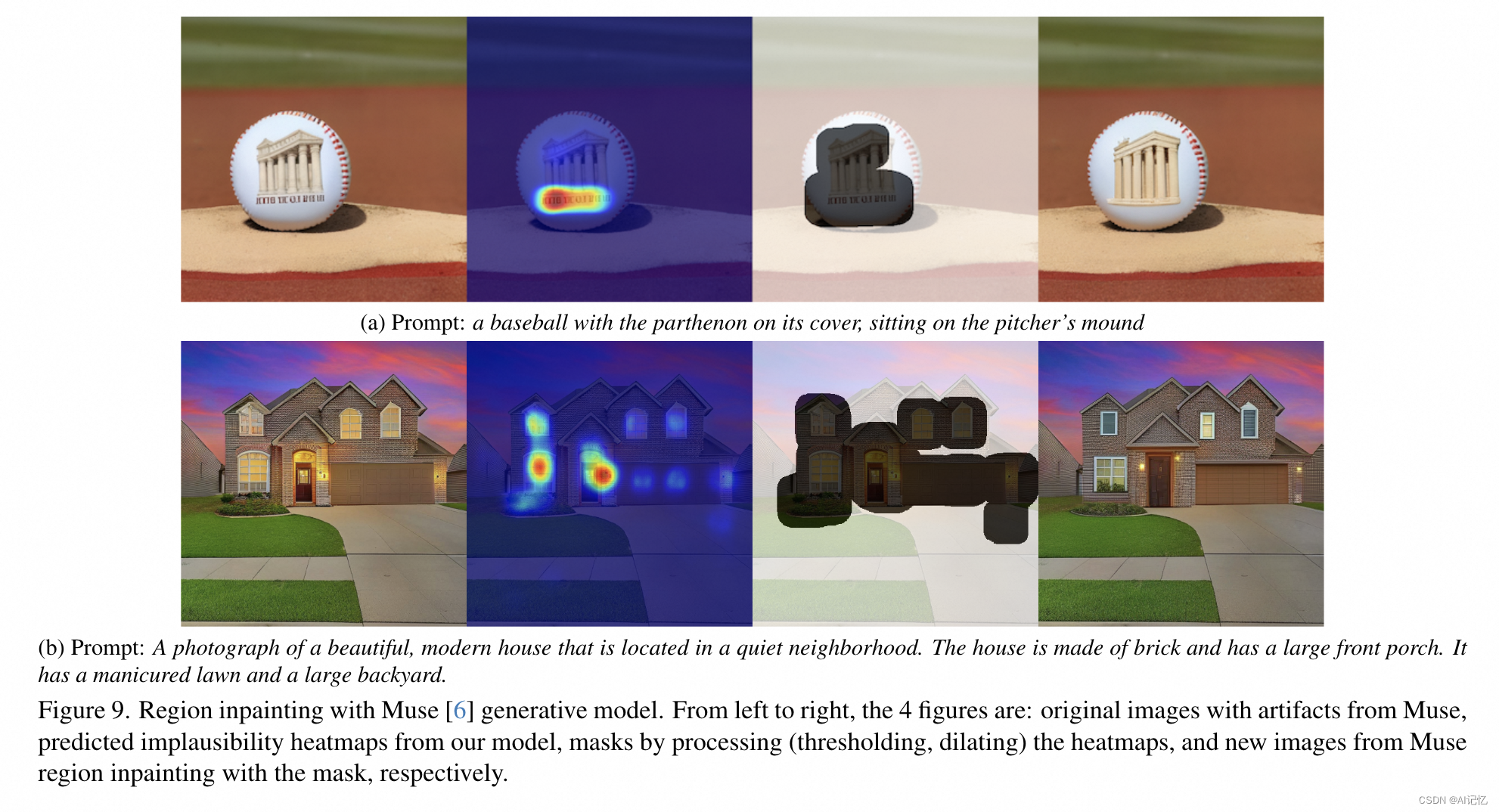
图像生成改进(Image Generation Improvement):展示了使用RAHF模型预测的分数和热图进行图像生成改进的例子,如图8和图9所示。这些例子说明了通过微调和区域修复(inpainting)技术,可以显著提高生成图像的质量。

-
人类评估(Human Evaluation):提供了人类评估者对原始Muse模型和经过RAHF模型预测分数微调后的Muse模型生成的图像进行偏好选择的结果,如表5所示,显示了微调后的模型在图像合理性方面得到了改善。

b.)定量结果
本文中的定量实验结果主要集中在以下几个方面:
-
分数预测(Score Prediction):使用Pearson线性相关系数(PLCC)和Spearman等级相关系数(SRCC)作为评估指标,RAHF模型在四个细粒度评分任务(图像合理性、文本-图像对齐、美学和整体评分)上的表现均优于基线模型(ResNet-50和PickScore)。

-
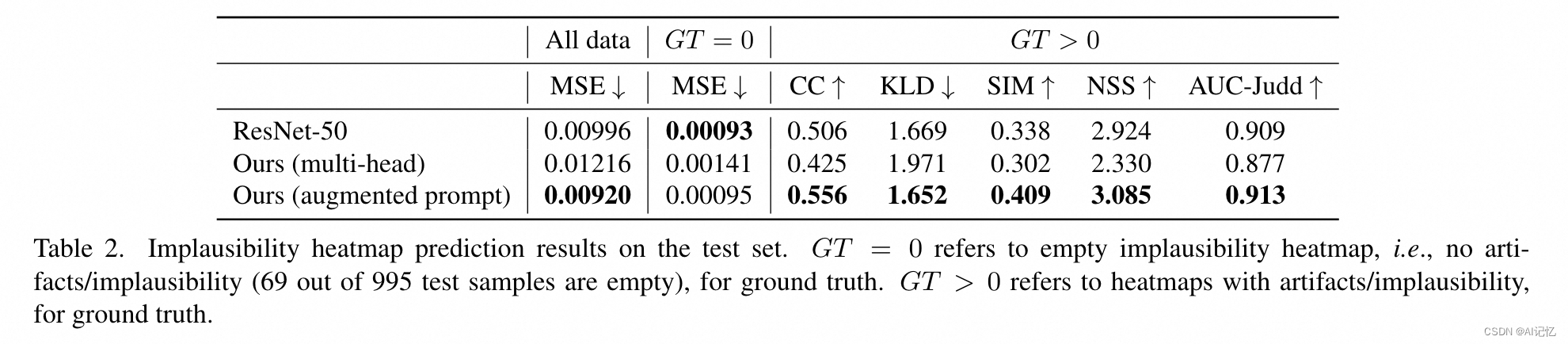
不合理热图预测(Implausibility Heatmap Prediction):在不合理热图预测任务上,RAHF模型使用像素级均方误差(MSE)作为评估指标,并且在所有样本以及只有非空真实标注的样本上都报告了结果。此外,还使用了标准的显著性热图评估指标(如NSS/KLD/AUC-Judd/SIM/CC)来评估非空真实标注的样本。
-
文本不一致热图预测(Text Misalignment Heatmap Prediction):类似于不合理热图预测,文本不一致热图预测也使用了MSE和显著性热图评估指标来衡量模型性能。

-
文本不一致序列预测(Text Misalignment Sequence Prediction):对于文本不一致序列预测任务,采用了基于标记的精确度(Precision)、召回率(Recall)和F1分数来评估模型性能。