
- 1国内外二十五个优秀软件测试网站_软件测试项目案例网站
- 22020年CSP-J2 CSP-S2 复赛题解_cspj2020复赛解析
- 3IntelliJ IDEA 拉取gitlab项目_idea拉取gitlab项目
- 4有关百度的职级体系,这些是你需要知道的!_百度员工怎么考级
- 5论文翻译:通过云计算对联网多智能体系统进行预测控制
- 6YOLOv8模型调参---数据增强_yolo 数据增强
- 72024免费最好用的苹果电脑mac虚拟机工具Parallels Desktop19中文版下载_mac 虚拟机 免费
- 8数据库(MySQL)—— 初识和创建用户_mysql 创建用户
- 9深度学习之轻量化神经网络MobileNet
- 10hive初始化命令出错bin/schematool -dbType mysql -initSchema_初始化mysql错误schematool:未找到命令
Java多线程编程-(7)-使用线程池实现线程的复用和一些坑的避免_java等待网络返回结果中线程复用
赞
踩
前几篇:
Java多线程编程-(1)-线程安全和锁Synchronized概念
Java多线程编程-(2)-可重入锁以及Synchronized的其他基本特性
Java多线程编程-(3)-线程本地ThreadLocal的介绍与使用
Java多线程编程-(5)-使用Lock对象实现同步以及线程间通信
Java多线程编程-(6)-两种常用的线程计数器CountDownLatch和循环屏障CyclicBarrier
线程复用:线程池
首先举个例子:
假设这里有一个系统,大概每秒需要处理5万条数据,这5万条数据为一个批次,而这没秒发送的5万条数据数据需要经过两个处理过程,第一步是数据存入数据库,第二步是对数据进行其他业务的分析,假设第一步我是用的是普通的JDBC插入数据,为了不影响程序的继续执行,我写了一个线程,让这个子线程不阻塞主线程,继续处理第二步骤的数据,我们知道插入5万条数据大概需要2至3秒的时间,如果每一批次插入数据库的时候,就创建一个线程进行处理,可想而知,由于插入数据库的时间较久,不能很快的处理,这样的话,一段时间之后,系统中就会有很多的这种插入数据的线程(PS:只是假设场景,方案设计的可能不合理)。
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("5万条数据入库!");
}
}).start();- 1
- 2
- 3
- 4
- 5
- 6
如果,我们使用上述的方式去创建线程,使用start()方法启动线程,该线程会在run()方法结束后,自动回收该线程。虽然如此,在上边的场景中线程中业务的处理速度完全达不到我们的要求,系统中的线程会逐渐变大,进而消耗CPU资源,大量的线程抢占宝贵的内存资源,可能还会出现OOM,即便没有出现,大量的线程回收也会个GC带来很大的压力。
可想而知,虽然多线程技术可以充分发挥多核处理器的计算能力,提高生产系统的吞吐量和性能。但是,若不加控制和管理的随意使用线程,对系统的性能反而会产生不利的影响。
还拿上边的例子说,如果我们使用线程池的方式的话,可以实现指定线程的数量,这样的话就算再多的数据需要入库,只需要排队等待线程池的线程即可,就不会出现线程池过多而消耗系统资源的情况,当然这只是意见简单的场景。
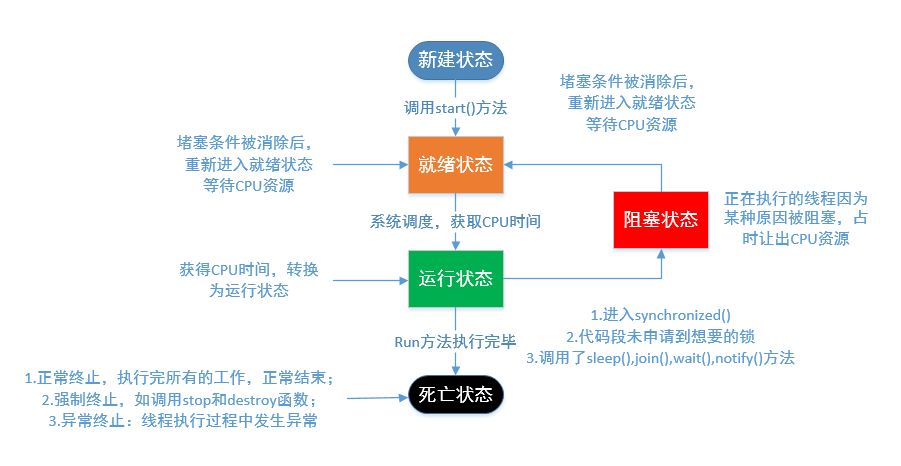
说到这里,有人要说了线程不是携带资源的最小单位,操作系统的书籍中还给我们说了线程之间的切换消耗很小吗?虽然如此,线程是一种轻量级的工具(或者称之为:轻量级进程),但其创建和关闭依然需要花费时间,如果为了一个很简单的任务就去创建一个线程,很有可能出现创建和销毁线程所占用的时间大于该线程真实工作所消耗的时间,反而得不偿失。
那么什么是线程池?
为了避免系统频繁的创建和销毁线程,我们可以将创建的线程进行复用。数据库中的数据库连接池也是此意。
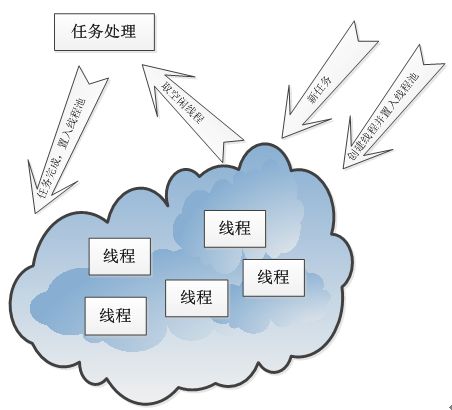
在线程池中总有那么几个活跃的线程,也有一定的最大值限制,一个业务使用完线程之后,不是立即销毁而是将其放入到线程池中,从而实现线程的复用。简而言之:创建线程变成了从线程池获取空闲的线程,关闭线程变成了向池子中归还线程。
再多的概念,不过多解释,因为很基础,也不是本文的重点。
使用线程池的好处
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够带来3个好处:
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
JDK对线程池的支持
JDK提供的Executor框架
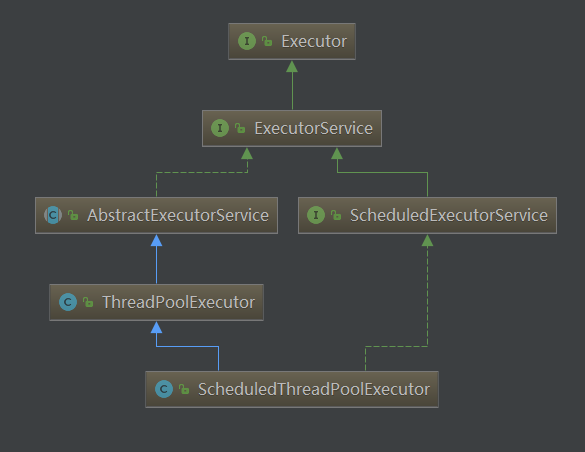
JDK提供了Executor框架,可以让我们有效的管理和控制我们的线程,其实质也就是一个线程池。Executor下的接口和类继承关系如下:
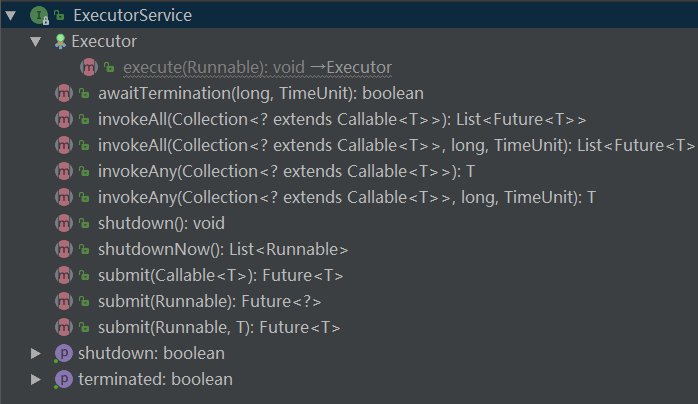
其中,ExecutorService接口定义如下:
如果使用Executor框架的话,Executors类是常用的,其方法如下:
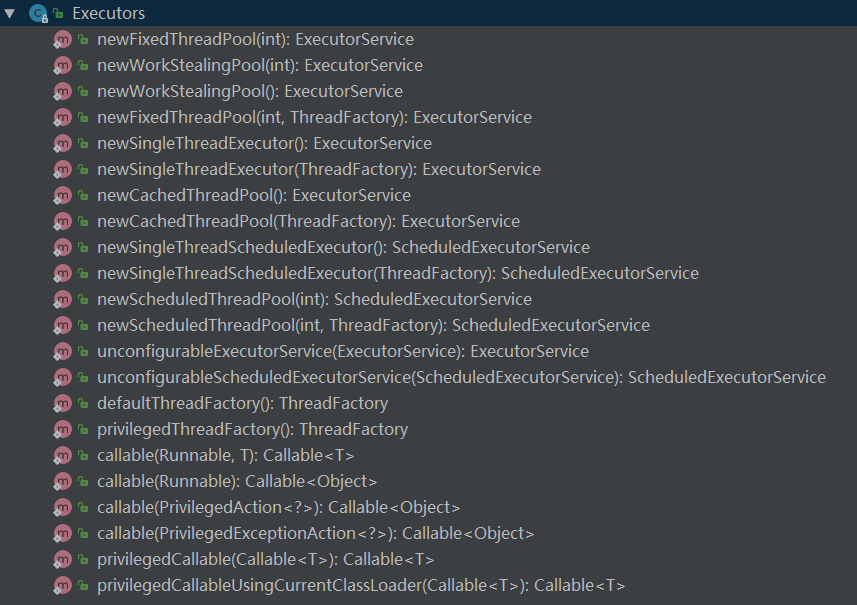
其中常用几类如下:
public static ExecutorService newFixedThreadPool()
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newCachedThreadPool()
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
public static ScheduledExecutorService newScheduledThreadPool()
- 1
- 2
- 3
- 4
- 5
- 6
1、newFixedThreadPool:该方法返回一个固定线程数量的线程池;
2、newSingleThreadExecutor:该方法返回一个只有一个现成的线程池;
3、newCachedThreadPool:返回一个可以根据实际情况调整线程数量的线程池;
4、newSingleThreadScheduledExecutor:该方法和newSingleThreadExecutor的区别是给定了时间执行某任务的功能,可以进行定时执行等;
5、newScheduledThreadPool:在4的基础上可以指定线程数量。
创建线程池实质调用的还是ThreadPoolExecutor
在Executors类中,我们拿出来一个方法简单分析一下:
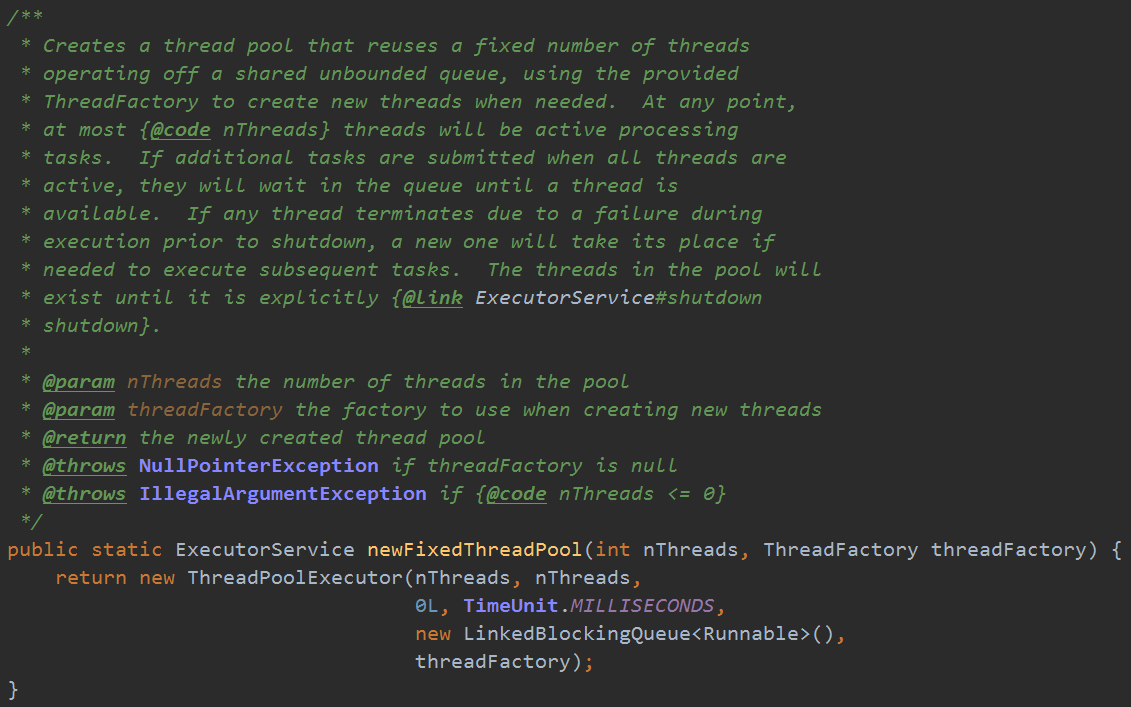
可以看出,类似的其他方法一样,在Executors内部创建线程池的时候,实际创建的都是一个ThreadPoolExecutor对象,只是对ThreadPoolExecutor构造方法,进行了默认值的设定。ThreadPoolExecutor的构造方法如下:
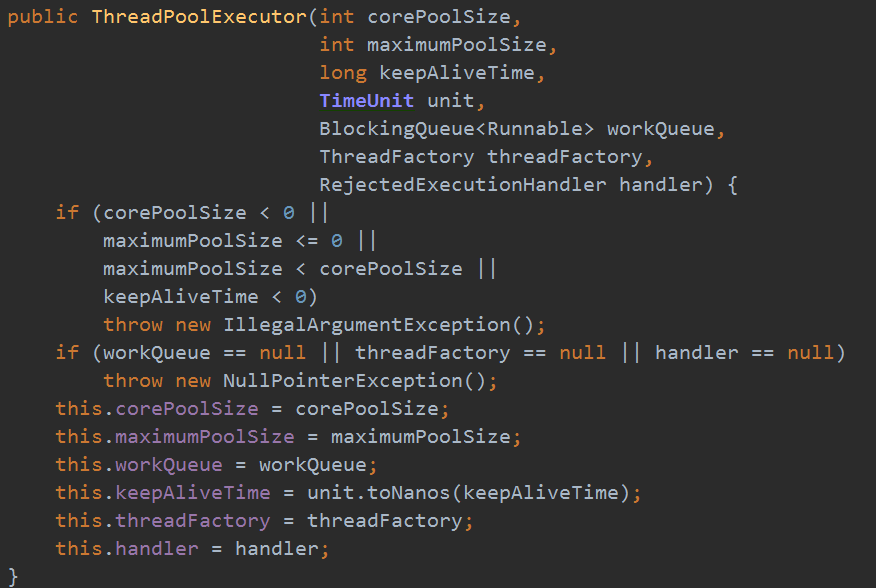
参数含义如下:
1、corePoolSize 核心线程池大小;
2、maximumPoolSize 线程池最大容量大小;
3、keepAliveTime 线程池空闲时,线程存活的时间;
4、TimeUnit 时间单位;
5、ThreadFactory 线程工厂;
6、BlockingQueue任务队列;
7、RejectedExecutionHandler 线程拒绝策略;- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中这里的任务队列有以下几种:
Executor框架实例
1、实例一:
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 10; i++) {
int index = i;
executorService.submit(() -> System.out.println("i:" + index +
" executorService"));
}
executorService.shutdown();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
submit(Runnable task)方法提交一个线程。
但是使用最新的“阿里巴巴编码规范插件”检测一下会发现:

线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,
这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
阿里巴巴编码规范插件地址:https://github.com/alibaba/p3c
2、实例二:
遵循阿里巴巴编码规范的提示,示例如下:
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService = new ThreadPoolExecutor(2, 2, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 10; i++) {
int index = i;
executorService.submit(() -> System.out.println("i:" + index +
" executorService"));
}
executorService.shutdown();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
或者这样:
public class ThreadPoolDemo {
public static void main(String[] args) {
ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 2, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 10; i++) {
int index = i;
pool.submit(() -> System.out.println("i:" + index +
" executorService"));
}
pool.shutdown();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3、实例三:
自定义ThreadFactory、自定义线程拒绝策略
public static void main(String[] args) {
ExecutorService executorService = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(10),
new ThreadFactory() { //自定义ThreadFactory
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName(r.getClass().getName());
return thread;
}
},
new ThreadPoolExecutor.AbortPolicy()); //自定义线程拒绝策略
for (int i = 0; i < 10; i++) {
int index = i;
executorService.submit(() -> System.out.println("i:" + index));
}
executorService.shutdown();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
更多实例代码,可参考:https://gitee.com/xuliugen/codes/ta5dbsge0kvhy62qu8li157
使用submit的坑
首先看一下实例:
public class ThreadPoolDemo3 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 5; i++) {
int index = i;
executorService.submit(() -> divTask(100, index));
}
executorService.shutdown();
}
private static void divTask(int a, int b) {
double result = a / b;
System.out.println(result);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果:
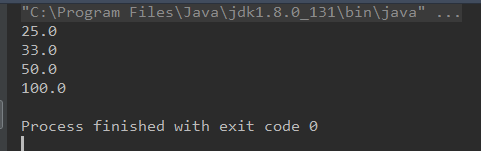
上述代码,可以看出运行结果为4个,因该是有5个的,但是当i=0的时候,100/0是会报错的,但是日志信息中没有任何信息,是为什么那?如果使用了submit(Runnable task) 就会出现这种情况,任何的错误信息都出现不了!
这是因为使用submit(Runnable task) 的时候,错误的堆栈信息跑出来的时候会被内部捕获到,所以打印不出来具体的信息让我们查看,解决的方法有如下两种:
1、使用execute()代替submit();
public class ThreadPoolDemo3 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 5; i++) {
int index = i;
executorService.execute(() -> divTask(100, index));
}
executorService.shutdown();
}
private static void divTask(int a, int b) {
double result = a / b;
System.out.println(result);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行结果:
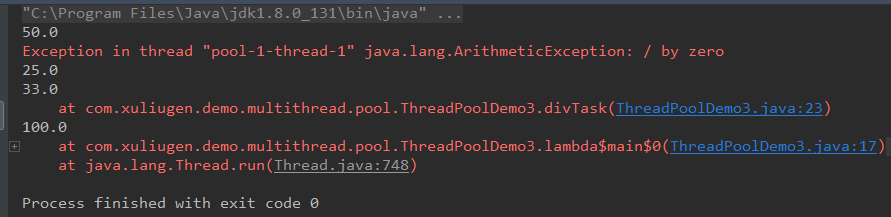
2、使用Future
public class ThreadPoolDemo3 {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 5; i++) {
int index = i;
Future future = executorService.submit(() -> divTask(200, index));
try {
future.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
executorService.shutdown();
}
private static void divTask(int a, int b) {
double result = a / b;
System.out.println(result);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
运行结果:
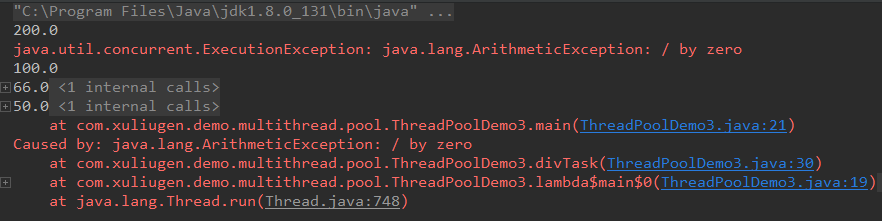
3、execute和submit的区别
(1)execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。通过以下代码可知execute()方法输入的任务是一个Runnable类的实例。
(2)submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。

