
- 1国内外二十五个优秀软件测试网站_软件测试项目案例网站
- 22020年CSP-J2 CSP-S2 复赛题解_cspj2020复赛解析
- 3IntelliJ IDEA 拉取gitlab项目_idea拉取gitlab项目
- 4有关百度的职级体系,这些是你需要知道的!_百度员工怎么考级
- 5论文翻译:通过云计算对联网多智能体系统进行预测控制
- 6YOLOv8模型调参---数据增强_yolo 数据增强
- 72024免费最好用的苹果电脑mac虚拟机工具Parallels Desktop19中文版下载_mac 虚拟机 免费
- 8数据库(MySQL)—— 初识和创建用户_mysql 创建用户
- 9深度学习之轻量化神经网络MobileNet
- 10hive初始化命令出错bin/schematool -dbType mysql -initSchema_初始化mysql错误schematool:未找到命令
hadoop搭建(伪分布式、完全分布式、高可用)_伪分布式journalnode怎样启动
赞
踩
环境
Linux操作系统(centos),5台,Hadoop,jdk1.7,zookeeper,XShell,xftp
安装linux虚拟机(至少5台)
事先在windous上安装好VWmare、Xshell、XFtp
然后在VWmare上安装centos,自行去官网下载映像文件,先安装一台(node01),然后配置好基本的设置后再克隆另外四台(node02、node03、node04、node05)
安装node01
安装步骤如下:
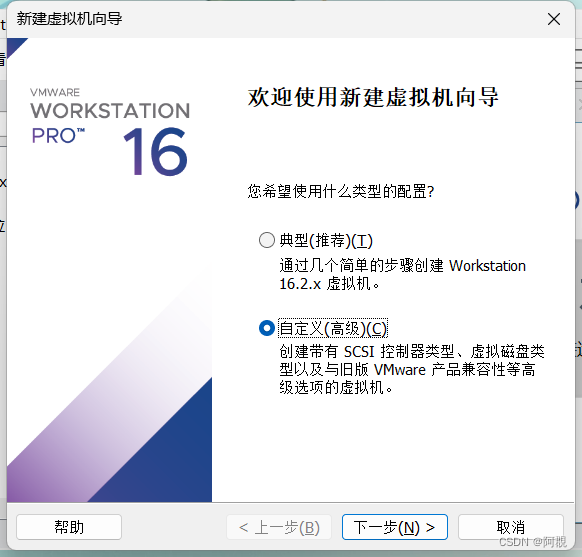
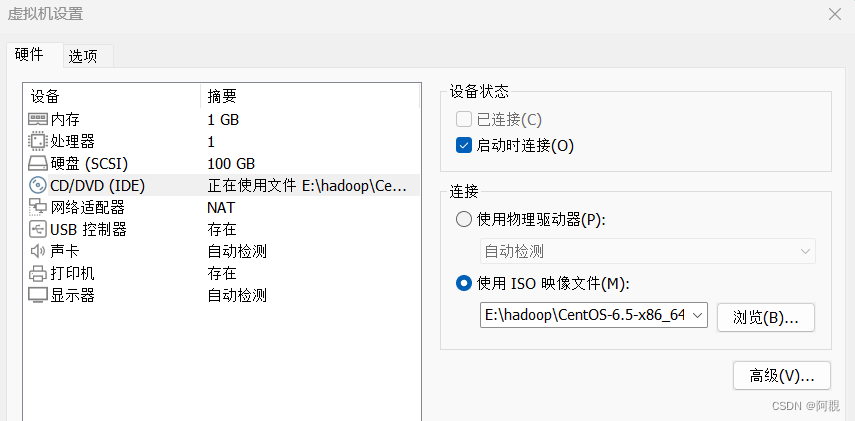
这里先不要选择映像文件
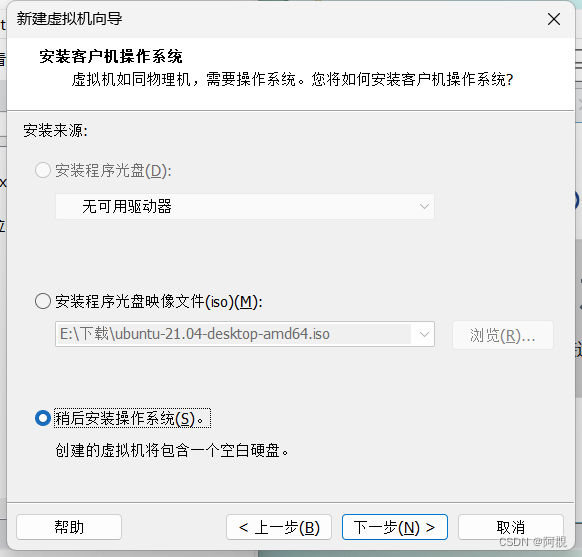
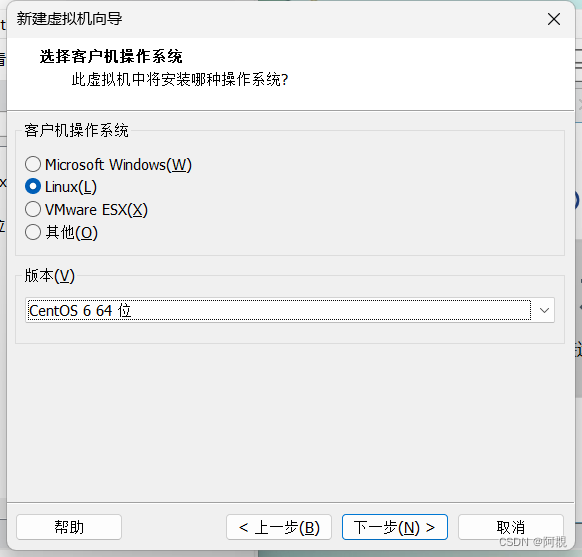
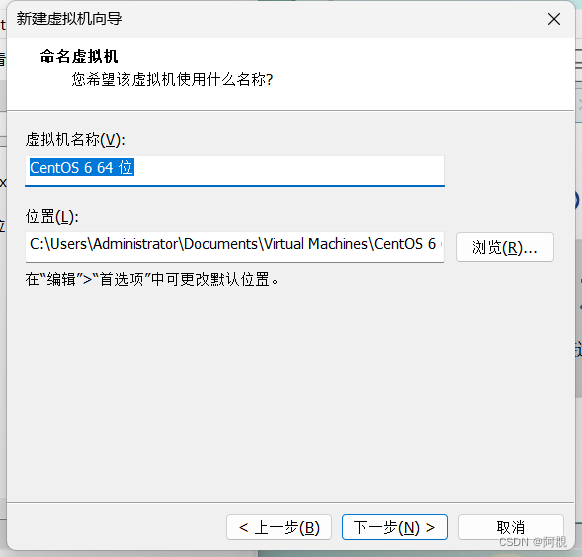
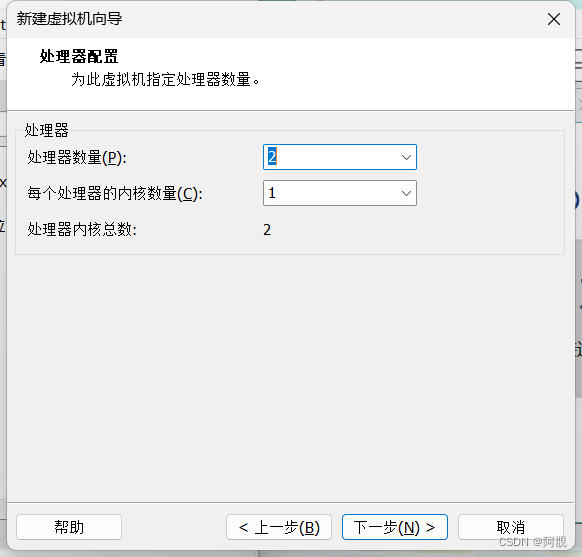
根据需要选择处理器和数量
不要选择立即分配,否则你的磁盘马上就要被用完了,这样选择,后面会睡着linux虚拟机使用的实际空间慢慢扩大容量
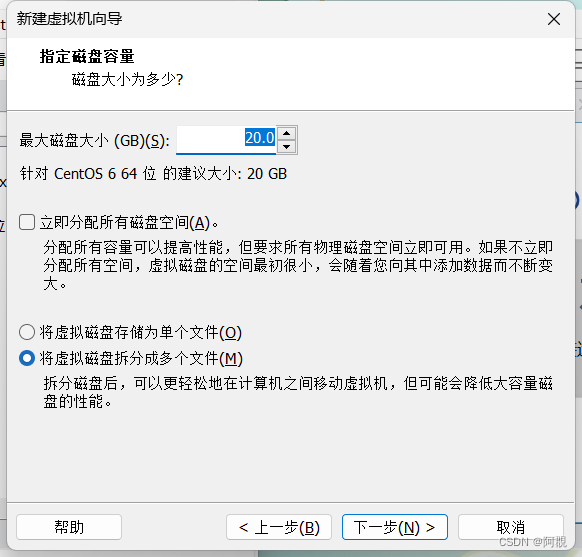
然后再在设置里选择镜像
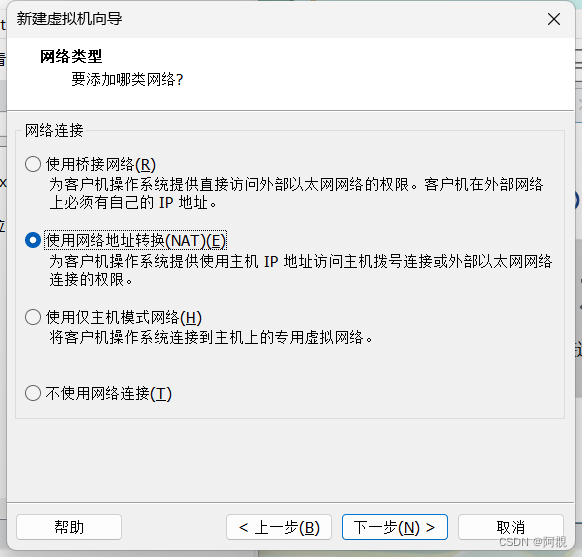
配置网络
(1)打开VWmare虚拟网络编辑器,(编辑-虚拟网络编辑器),配置NAT模式,不要选HDCP方式配置ip地址,查看子网地址和网关(NAT设置查看网关)
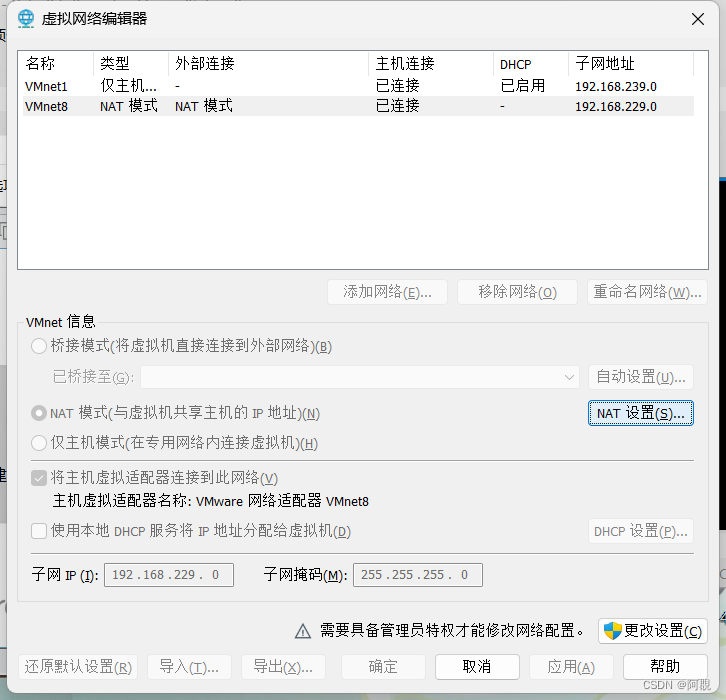
(2)修改网络配置文件
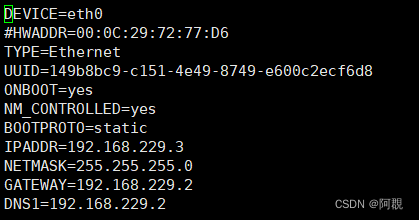
vi /etc/sysconfig/network-scripts/ifcfg-eth0
然后修该成一下内容:
主要是ip地址和网关,自己配置,只要和虚拟网络编辑器里的子网在同一网段内就行
#HWADDR=00:0c:29:F4:2F:93 // 网卡地址,注释便于克隆
ONBOOT=yes
BOOTPROTO=static // 将dhcp改为static,配置固定IP,
IPADDR=192.168.133.254 // 进入vmware虚拟网络编辑器查看,再设置IP
NETMASK=255.255.255.0
GATEWAY=192.168.133.2
DNS1=114.114.114.114
service network restart 重新加载
(3)关闭防火墙
chkconfig iptables off //开机禁用
service iptables stop
(4)关闭selinux
vi /etc/selinux/config
SELINUX=disabled //将enforcing改为disabled
(5)删除/etc/udev/rules.d/70-persistent-net.rules
rm -f /etc/udev/rules.d/70-persistent-net.rules //便于克隆,该文件也有网卡地址映射
(6)拍摄快照,克隆新的虚拟机(右键node01-管理-克隆) ,启动新虚拟机,MAC地址就会改变

(7)重复第2步,配置4台虚拟机IP
配置主机名和映射
配置主机名
vi /etc/sysconfig/network
hostname=node01(node02、node03......)
或者直接hostname命令配置
配置映射(/etc/hosts)
192.168.133.31 node01
192.168.133.32 node02
编辑 C:\WINDOWS\System32\drivers\etc\hosts,让windows应用程序也可以访问主机名

可以在node01上ping一下node02试一下看可不可以ping通(ping node02)
伪分布式搭建
在node01上搭建
(1)安装jdk
下载jdk的rpm文件到Windows上,然后通过Xftp传到虚拟机上
解压 rpm -i jdk-7u67-linux-x64.rpm ,解压到/usr/java/jdk1.7.0_67
配置环境变量
vi + /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_67
PATH=$PATH:$JAVA_HOME/bin
通过. /etc/profile 或 source /etc/profile使其生效
(2)设置ssh免密钥登录
cd /root/.ssh/
如果没有.ssh目录,可以登录localhost自动产生
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 产生秘钥和公钥文件
将id_dsa.pub公钥文件追加到验证文件authorized_keys
cat id_dsa.pub >> authorized_keys 
设置.ssh目录权限 chmod 700 -R .ssh
第二种方法:
ssh-keygen
ssh-copy-id -i id_rsa.pub node01
(3)安装Hadoop
传输安装文件到/root/software
建立解压目的目录
mkdir -p /opt/jxxy
解压 tar xf hadoop-2.6.5.tar.gz -C /opt/jxxy/
配置环境变量 vi + /etc/profile
export HADOOP_HOME=/opt/jxxy/hadoop-2.6.5
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(4)修改配置文件
文件所在目录:/opt/jxxy/hadoop-2.6.5/etc/hadoop
1. 修改hadoop-env.sh,mapred-env.sh,yarn-env.sh,加上jdk的环境变量
export JAVA_HOME=/usr/java/jdk1.7.0_67
2. 修改core-site.xml
定义默认名称节点的地址和端口号
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
</configuration>
3. 修改hdfs-site.xml
设置数据冗余量
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. slaves
从节点信息:
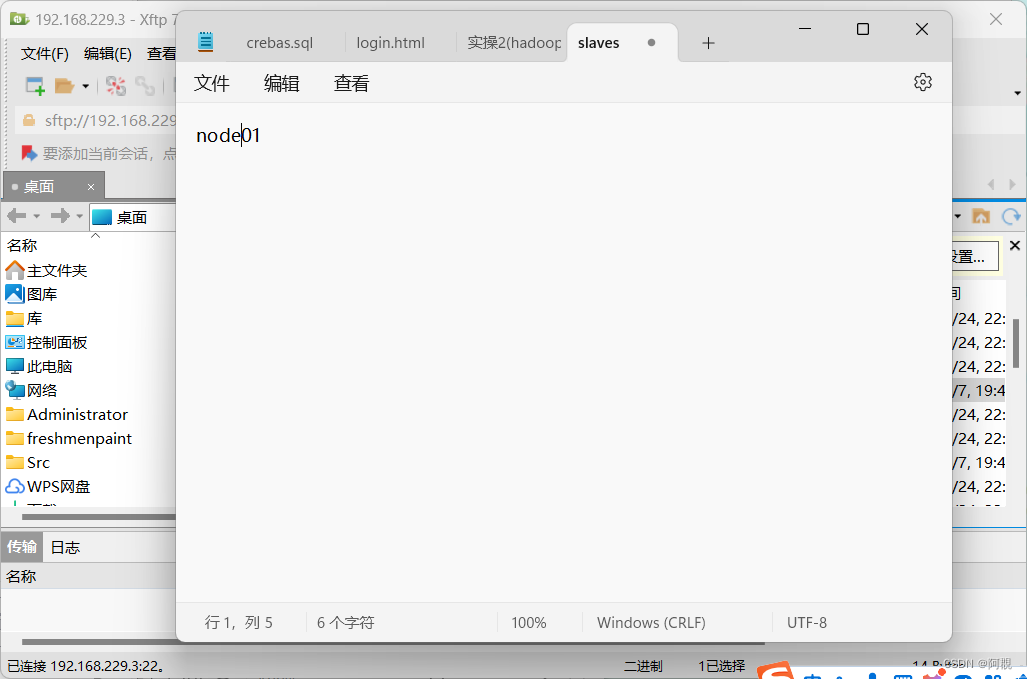
因为是伪分布式,所以Namenode和Datanode都在一个机子上
5. 修改hdfs-site.xml
增加第二名称节点的地址和端口信息
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
</configuration>
6.修改core-site.xml
修改数据块存放路径
<property>
<name>hadoop.tmp.dir</name>
<value>/var/jxxy/hadoop/pseudo</value>
</property>
(5) 格式化
hdfs namenode -format
可以查看 /var/jxxy/pseudo/dfs/name/current/fsimage_.....
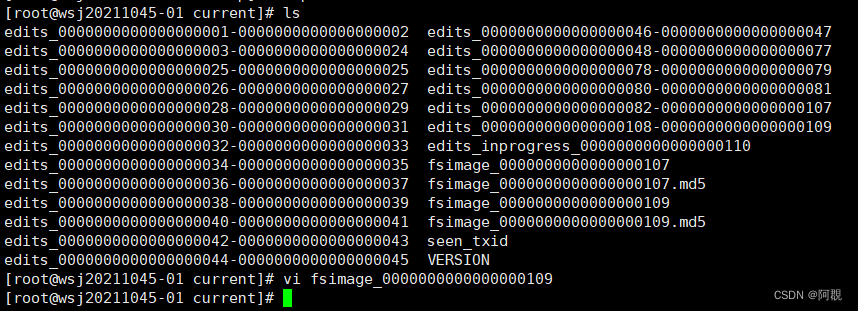
cat VERSION clusterID(集群ID)
每次格式化都会产生一个clusterID,一个集群的Namenode和dataNode的clusterID是一样的
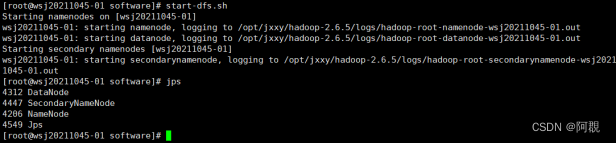
(6)启动集群
start-dfs.sh
可以jps查看启动哪些进程
(7)通过浏览器查看信息
ss -nal 可以查看通讯端口
在火狐等浏览器输入node01:50070,前提是要在windows下的c:/windows/system32/drivers/etc/hosts文件添加IP节点映射
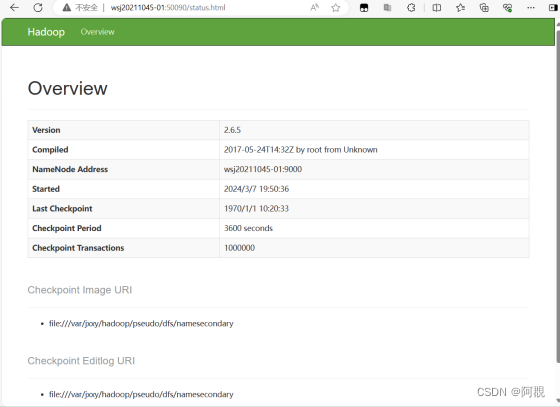
(8)练习上传文件
1. 创建路径
hdfs dfs -mkdir -p /user/root
hdfs dfs -ls /
2. 上传文件
cd ~/software
ls -lh ./ //查看文件大小
hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
在浏览器查看,该文件应该生成两个块,块大小默认128MB
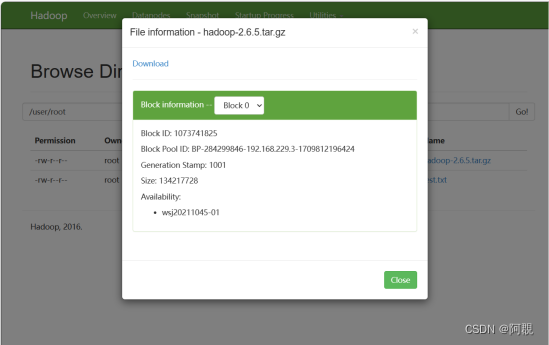
查看/var/jxxy/pseudo/data/....实际存储位置
完全分布式搭建
1、准备工作:(前提:已配置好node02为伪分布式服务器)
(1)安装java
(2)同步所有服务器时间
date -s "2020-02-01 15:11:00" //所有会话
(3)cat /etc/sysconfig/network //查看机器IP映射
(4)cat /etc/hosts //所有所有机器别名
(5)cat /etc/sysconfig/selinux //selinux 关闭
(6)关闭防火墙
(7)ssh 免密钥 //管理节点分发密钥文件给其他节点
node02: scp id_dsa.pub node03:`pwd`/node02.pub
node03: cat node02.pub >>authorized_keys
以此类推
2、修改配置文件
node02:
(1)core-site.xml
添加默认名称节点服务地址和数据存储目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node02:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/jxxy/hadoop/full</value>
</property>
</configuration>
(2)hdfs-site.xml
设置冗余量和第二名称节点通信端口
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node03:50090</value>
</property>
(3)slaves
设置从节点
node03
node04
node05
3、分发hadoop-2.6.5给其他节点
scp -r /opt/jxxy/ node03:`pwd`
4、分发环境变量给其他节点
scp /etc/profile node03:/etc
source /etc/profile是配置生效
5、格式化
hdfs namenode -format
ls /var/jxxy/hadoop/full可以查看clusterid
6、启动:
start-dfs.sh
出现问题,可以查看日志
ll /opt/jxxy/hadoop-2.6.5/logs
tail -100 hadoop-root-datanode-node03.log
8、浏览器查看信息
node02:50070(或node03)
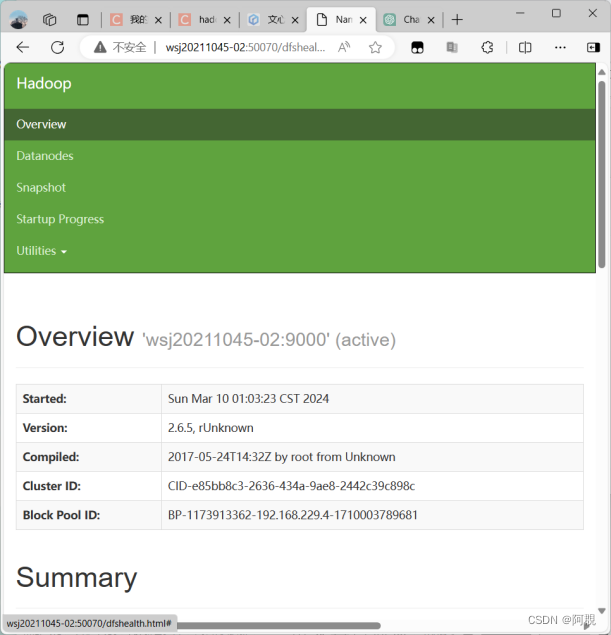
9、练习上传文件
在~/software目录里创建一个新文件
for i in `seq 100000`;do echo "hello jxxy$i" >> test.txt;done
查看新文件大小
ll -h //test.txt文件大小约为1.6M
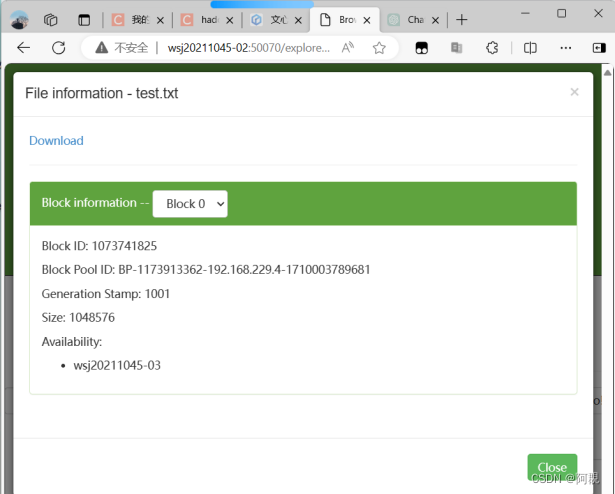
设置块大小上传文件
hdfs dfs -D dfs.blocksize=1048576 -put test.txt
浏览器查看文件块
高可用搭建
两个NamNode(node2、3)要互相免密
1)搭建zookeeper和配置
首先下载zookeeper安装包解压并在zookeeper安装目录中的conf目录下配置
(1)配置文件:
1. dfs.nameservices
设置逻辑名称
hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
2. dfs.ha.namenodes.[nameservice ID]
两个Namenode只能1主1从两个
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
3. dfs.namenode.rpc-address.[nameservice ID].[name node ID]
设置rpc地址
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node03:8020</value>
</property>
4.dfs.namenode.http-address.[nameservice ID].[name node ID]
设置http地址
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node02:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node03:50070</value>
</property>
5.dfs.namenode.shared.edits.dir
设置juniornode的url
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node02:8485;node03:8485;node04:8485/mycluster</value>
</property>
6.dfs.client.failover.proxy.provider.[nameservice ID]
java class that HDFS clients use to contact the Active Namenode
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
7. dfs.ha.fencing.methods
a list of scripts or java classes which will be used to fence the Active Namenodes during a failover
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value> //id_dsa 私钥
</property>
<property>
8.fs.defaultFS
当未给定任何路径前缀时,Hadoop FS客户端使用的默认路径前缀
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
9. 高可用的数据存储目录
<property>
<name>hadoop.tmp.dir</name>
<value>/var/jxxy/hadoop/ha</value>
</property>
10. dfs.journalnode.edits.dir
journalnode后台进程存储其本地状态的路径
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/jxxy/hadoop/ha/journalnode</value>
</property>
(2)zookeeper配置(自动故障转移)
hdfs-site.xml
ZooKeeper quorum and ZKFailoverController process
ZooKeeper 功能:Failure detection; Active Namenode election
ZKFC 功能:health monitoring;Zookeeper session management;zookeeper-based election
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>node03:2181,node04:2181,node05:2181</value>
</property>
(3)配置zoo.cfg(zookeeper/conf)
clientPort=2181
dataDir=/root/software/zkdata
server.1=node03:2888:3888
server.2=node04:2888:3888
server.3=node05:2888:3888
1是id号,2888是主从节点通信端口,3888是选举机制端口,zookeeper也是主从架构,也有选举机制。
这里要注意的是每个zookeeper节点(上面的node03、node04、node05)要在dataDir所指示的目录中创建一个myid文件,里面的内容是每个节点的id,比如node03是1。
2)启动zookeeper
在node03、node04、node05上zkServer.sh start
jps查看进程QuorumPeerMain是否启动,或者:
zkServer.sh status // Mode:leader or Mode:foolwer

zkServer.sh stop //关闭zookeeper
注意:至少启动两台服务器
3)启动journalnode(3个节点)
由于有过半原则的限制,必须至少启动两个节点
hadoop-daemon.sh start journalnode

4)格式化node02(或node03)
hdfs namenode -format
5)启动node02
hadoop-daemon.sh start namenode
![]()
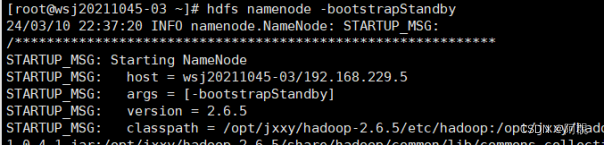
6)复制node02元数据信息给node03
hdfs namenode -bootstrapStandby (在node03)
7)两个namenode在zookeeper上注册
zkCli.sh客户端(node3、4、5)查看
ls,只有[zookeeper]

hdfs zkfc -formatZK //initializing HA state in zookeeper

再查看发现有[hadoop-ha,zookeeper]

8)在node02上启动(因为有免密钥登录)
start-dfs.sh
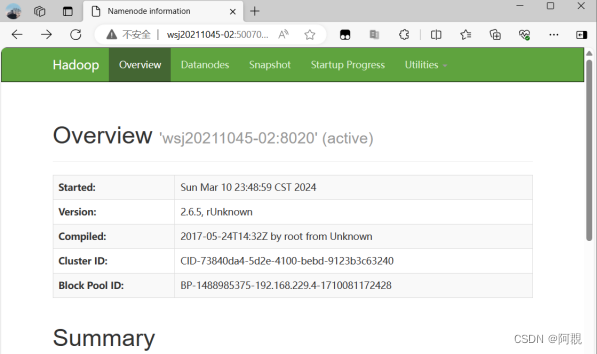
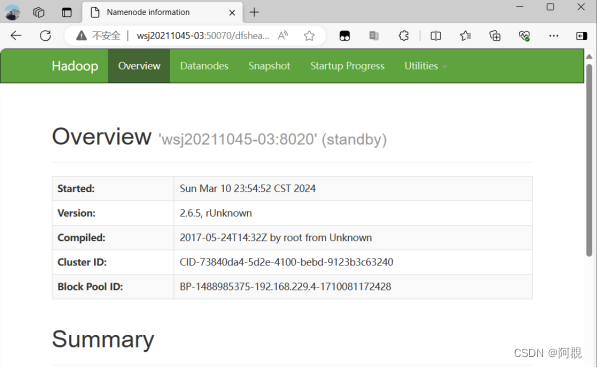
9)浏览器访问
node-02:50070 //active
node-03:50070 //standby
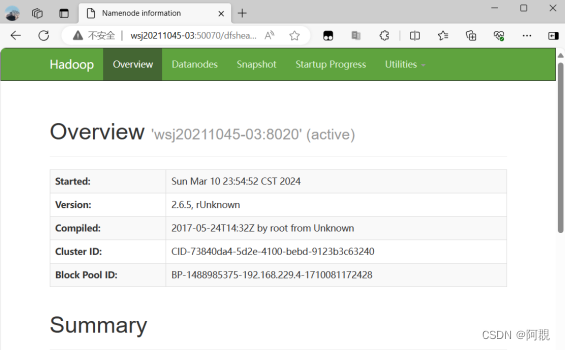
10)实验:关闭node02(active namenode)
hadoop-daemon.sh stop namenode
node03:50070 //显示为active
出现的问题以及解决方案
1、出现安装后不出现界面的情况,如图:
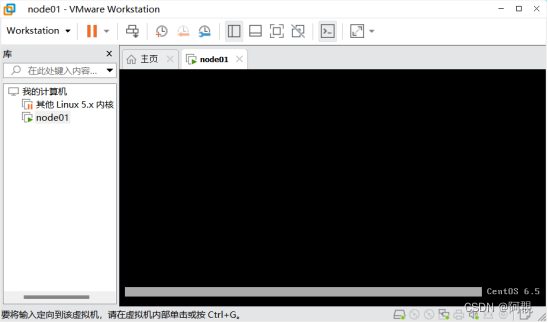
原来VMware默认启动时是以等级5,即图形化界面启动,而我们安装的操作系统是字符界面(等级3)启动,所以我们开始选择镜像的时候先不要选择,而是创建好虚拟机后再选择。
Linux下有7个运行级别:
| 0 | 系统停机模式,系统默认运行级别不能设置为0,否则不能正常启动,机器关闭。 |
| 1 | 单用户模式,root权限,用于系统维护,禁止远程登陆,就像Windows下的安全模式登录。 |
| 2 | 多用户模式,没有NFS网络支持。 |
| 3 | 完整的多用户文本模式,有NFS,登陆后进入控制台命令行模式。 |
| 4 | 系统未使用,保留一般不用,在一些特殊情况下可以用它来做一些事情。例如在笔记本电脑的电池用尽时,可以切换到这个模式来做一些设置。 |
| 5 | 图形化模式,登陆后进入图形GUI模式,XWindow系统。 |
| 6 | 重启模式,默认运行级别不能设为6,否则不能正常启动。运行init机器就会重启。 |
2、实验中如果要手动配置分区和挂载点,必须设置的是“/”和swap分区。
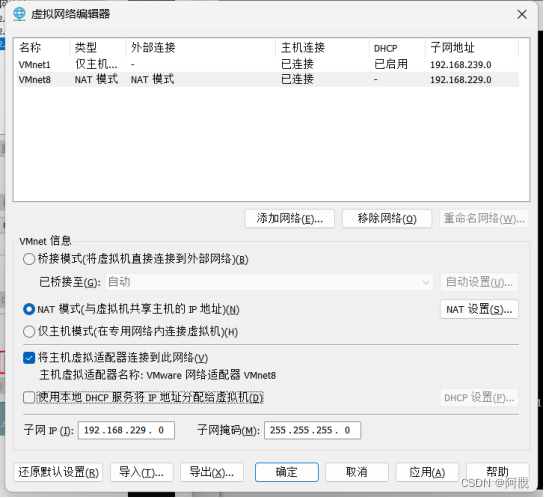
3、设置网络的时候,一定要先查看虚拟网络编辑器中的网络适配器的子网地址和网关,保持设置的ip地址和子网地址保持一致且设置网关地址是NAT模式。
4、配置ip地址时候,需要注意的就是如果DEVICE都配置成eth0重新加载不成功,所以要一定要确保/etc/udev/rules.d/70-persistent-net.rules文件删除。
5、配置ssh免秘登录时,有可能不成功,不成功的原因可能是因为hosts中配置的映射名和主机名不一样,到时公钥中的名称也和映射不一样,所以一定要保证用一样的名字。
6、配置hosts映射后,ping node04和node05时还是不能通过主机名ping通,通过ip地址却能成功。解决办法是尽量不要用Xshell来分发和粘贴复制,因为可能会产生多余字符。这个很重要,在实验中很多问题都是因为hosts配置出错。
7、在搭建高可用的时候,配置配置文件要注意由于secondary namenode已经被第二个namenode替代,所以不用再配置,而且要注意JournalNode和Zookeeper的节点分别对应哪几个机器,那些节点上运行什么程序一定不要搞混了。(node02、node03、node04上是journalNode,node03、node04、node05上是zookeeper客户端节点)

