
- 1奖金711万!这位“山东宝妈”破解美国运算100万年才可能解开的密码!
- 2Unity Sprite Packer 问题集合_sprites can not be generated from textures with np
- 3程序员该如何确定任务(项目)的排期?_计算机做一个项目具体的排期该怎么样
- 4【初阶数据结构篇】顺序表的实现(赋源码)
- 5exe打包工具,封装exe安装程序--Inno Setup_磁盘跨越必须启用
- 6基于SpringBoot+Vue的游戏分享网站(带1w+文档)
- 730岁还在技术路上前进,软件测试是不是被严重低估了?
- 8C++11 auto关键字详解
- 9支持图片识别语音输入的LobeChat保姆级本地部署流程
- 10【JS逆向补环境】最新mtgsig参数分析与算法还原
基于Hadoop的招聘数据可视化系统实现(爬虫、hadoop+hive、flask+echarts、薪资预测、岗位推荐)_基于flask框架的hive项目
赞
踩
概要
随着大数据技术的兴起,AI人工智能领域迎来了大量的人才,而网络招聘成为了求职者的首选渠道。然而,招聘网站信息往往是重复、分散且不一致,就业人员需要花费大量时间才能找到真正合适的岗位。
- 1
整体架构流程
本文利用Flask框架设计并实现了一个AI岗位招聘数据可视化系统。首先,系统利用Selenium技术实现对网页数据的自动抓取;接着,构建由三台服务器组成的Hadoop集群,并将爬取数据存储在HDFS分布式文件系统中,使用基于Spark的Hive数据仓库进行数据处理和分析,生成得到的分析数据用可视化方式呈现给用户;并且,系统还使用线性回归算法实现薪资预测以及基于用户的协同过滤算法实现岗位推荐功能,最终给用户提供了一个更加直观、易懂的AI岗位招聘数据可视化系统。
项目流程架构图
项目实现
系统主要分为三个部分:数据采集-搭建数据仓库-建设数据可视化系统
1、数据采集
数据采集使用的技术是Selenium,而Selenium是能够在浏览器中运行测试,仿佛是真实用户在进行操作一样的工具,Selenium能模拟浏览器发送请求,并与网页中的元素进行交互,从而在网页中提取出数据,相较于其他的爬虫方法,Selenium能高效爬取到动态的数据,采用合法手段进行反爬虫策略,确保数据的有效爬取。
从Boss直聘网站上爬取AI岗位招聘数据,而爬取得到的数据由csv文件保存

编写爬虫程序
根据所需要后续可视化分析展示的数据进行元素定位采集
import datetime from selenium.webdriver.support.ui import WebDriverWait from selenium.common.exceptions import StaleElementReferenceException from selenium import webdriver from selenium.webdriver.common.by import By import time import re import csv with open(f'boss_job_city_info.csv','a',encoding='ANSI',newline='') as filename: csvwriter = csv.DictWriter(filename,fieldnames=[ '岗位','地点','薪资','工作经验','学历','公司名称','技能','工作福利','工作类型','融资情况','公司规模','链接' ]) path = 'chromedriver.exe' dr = webdriver.Chrome(path) dr.get("https://www.zhipin.com/web/geek/job?query=AI&city=101030100&page=9") dr.implicitly_wait(8) time.sleep(5) def job_info(): job_list = dr.find_elements(By.CLASS_NAME, 'job-card-wrapper') for job in job_list: # 职位 job_name = job.find_element(By.CLASS_NAME,'job-name').text # 地点 job_area = job.find_element(By.CLASS_NAME,'job-area').text # 薪资 salary_raw = job.find_element(By.CLASS_NAME, 'salary').text salary_split = salary_raw.split('·') salary = salary_split[0] if re.search(r'天',salary): continue # experience_education = job.find_elements(By.XPATH, '//ul[@class="tag-list"]/li') experience_education = job.find_element(By.CLASS_NAME,'tag-list').find_elements(By.TAG_NAME,'li') # 工作经验 experience = experience_education[-1].text education = experience_education[-2].text # 学历 # 公司名称 company_name = job.find_element(By.CLASS_NAME, 'company-name').text company_tag_list = job.find_element(By.CLASS_NAME, 'company-tag-list').find_elements(By.TAG_NAME,'li') if len(company_tag_list) != 3: print('跳过') continue # 公司类型 company_type = company_tag_list[0].text # 公司融资 company_salary_info = company_tag_list[1].text # 公司规模 company_size_info = company_tag_list[2].text # 工作福利 company_welfare = job.find_element(By.CLASS_NAME, 'info-desc').text # 技能 skill_list = job.find_element(By.CSS_SELECTOR, '.job-card-footer.clearfix').find_element(By.CLASS_NAME,'tag-list').find_elements(By.TAG_NAME,'li') skill = [] for skill_l in skill_list: skill_i_text = skill_l.text if len(skill_i_text) == 0: continue skill.append(skill_i_text) href = job.find_element(By.CSS_SELECTOR,'.job-card-body a').get_attribute('href') print(href) dict = { '岗位': job_name, '地点': job_area, '薪资': salary, '工作经验':experience, '学历':education, '公司名称':company_name, '技能': skill, '工作福利':company_welfare, '工作类型': company_type, '融资情况':company_salary_info, '公司规模': company_size_info, '链接':href } csvwriter.writerow(dict) print(job_name, job_area, salary, experience, education, company_name, company_type, company_salary_info, company_size_info, company_welfare, skill, sep='|') dr.find_element(By.CLASS_NAME,'ui-icon-arrow-right').click() for page in range(1,11): time.sleep(5) job_info()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
2、搭建数据仓库
数据处理采用的是使用Hive数据仓库对数据进行数据分层架构设计,首先该系统数据分析平台基于CentOs7搭建,并安装好Hadoop各生态核心组件,根据项目环境要求,在Vmvare中创建了三台虚拟机,配置好虚拟机环境后,开始构建Hadoop分布式集群,对系统环境、Hadoop的配置文件进行修改,其中配置了主节点Hadoop202负责集群的管理和控制,Hadoop203和Hadoop204则是负责数据的存储以及计算,集群三个节点之间的协作可以快速处理分析大规模的数据。
启动hadoop如图所示:

紧接着是搭建Hive数据仓库,安装配置Hive的环境变量,修改Hive中conf目录下的配置文件,将HDFS分布式文件系统和Yarn集群地址写入配置文件,并且需要安装MySQL,把Hive的元数据配置到MySQL中,为了方便后续在Hive的设计数据分层,通过hiveserver2建立远程连接的端口,使用了DataGrip工具远程连接Hive数据仓库,对数据仓库进行SQL操作。
启动hiveserver2:

安装好hive后,对数据上传到hdfs分布式文件系统上,在hive使用创建表映射出表数据,系统分层采用了ODS-DWD-DWA的结构,ODS层则为源数据,DWD为对ODS层的数据进行清洗加工,DWA层数据是根据后续图表需要展示的数据进行细分。
查询ODS层数据:

DWA层在HDFS文件系统分布:

从数据仓库经过分层后得到了清洗、转换和统计后的数据,为了后续实现数据可视化系统,使用MySQL关系型数据库存储经过一系列处理后的数据,根据不同的业务需求创建不同的表存储对应的分析数据,所以使用数据交互工具Sqoop对HDFS上的数据导出到MySQL数据库:
bin/sqoop export \
--connect jdbc:mysql://hadoop202:3306/boss \
--username root \
--password 123456 \
--table dwa_job_industry_count \
--columns "company_type,numbers" \
--export-dir /user/hive/warehouse/boss.db/dwa_job_industry_count \
--input-fields-terminated-by "\001"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3、数据可视化系统
系统采用了Flask框架+echarts可视化工具进行可视化系统设计,并且加入了线性回归算法对薪资进行预测和基于用户协同过滤算法进行岗位推荐。

部分可视化图表展示:

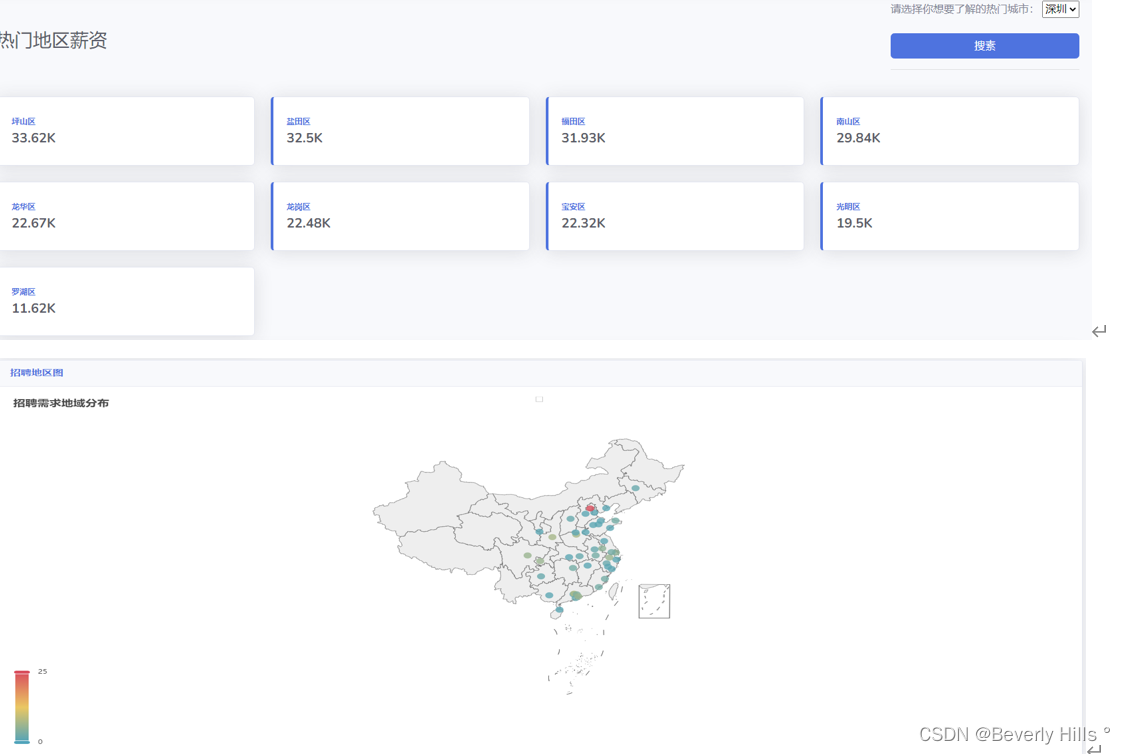

岗位推荐功能:

预测薪资功能:

其中代码实现:
import pandas as pd from sqlalchemy import create_engine import pymysql # 连接到数据库 con = create_engine('mysql+pymysql://root:123456@192.168.10.202:3306/boss?charset=utf8') # 用户 df_user = pd.read_sql('select * from user',con=con) df_taobao = pd.read_sql('select * from extracteddata', con=con) # 地图 df_area = pd.read_sql('select * from dwa_job_area_count',con=con) # 城市地区,薪资 df_city = pd.read_sql('select * from dwa_job_city_area_count',con=con) # 公司招聘排名 df_company = pd.read_sql('select * from dwa_job_company_name_count',con=con) # 学历要求 df_education = pd.read_sql('select * from dwa_job_education_count',con=con) # 学历对应工资 df_eduSal = pd.read_sql('select * from dwa_job_education_salary_count order by salary desc ',con=con) # 工作经验 df_experience = pd.read_sql('select * from dwa_job_experience_count',con=con) # 工作经验对应工资 df_experienceSal = pd.read_sql('select * from dwa_job_experience_salary_count order by salary desc ',con=con) # 融资情况 df_financing = pd.read_sql('select * from dwa_job_financing_count',con=con) # 职业方向分布 df_industry = pd.read_sql('select * from dwa_job_industry_count order by numbers desc',con=con) # 职位数量 df_job = pd.read_sql('select * from dwa_job_name_count order by numbers desc',con=con) # ai职位薪资 df_aiSal = pd.read_sql('select * from dwa_job_name_salary_count order by salary desc',con=con) # 技能要求 df_skill = pd.read_sql('select * from dwa_job_skill_count',con=con) df_job_info = pd.read_sql('select * from dwa_boss_job_info_detail',con=con)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
@app.route('/re_men', methods=['GET', 'POST']) def re_men(): email = session.get('email') if request.method == 'GET': city = query.querys('select * from dwa_job_city_area_count where job_city like %s order by salary desc', ['深圳'], 'select') elif request.method == 'POST': request.form = dict(request.form) city = query.querys('select * from dwa_job_city_area_count where job_city like %s order by salary desc', [request.form['area']], 'select') result = [] for data in city: data_dict = { 'job_area': data[1], 'salary': float(data[2]) } result.append(data_dict) data = df_area.to_dict(orient='records') # 提取不同列的数据 job_areas = df_area['job_area'].tolist() numbers = df_area['numbers'].tolist() return render_template( 're_men.html', email=email, city=result, data=json.dumps(data), job_areas=job_areas, numbers=numbers )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
<div class="row"> {% for item in city %} <div class="col-xl-3 mb-4"> <div class="card border-left-primary shadow h-100 py-2"> <div class="card-body"> <div class="row no-gutters align-items-center"> <div class="col mr-2"> <div class="text-xs font-weight-bold text-primary text-uppercase mb-1"> {{ item['job_area'] }} </div> <div class="h5 mb-0 font-weight-bold text-gray-800">{{ item['salary'] }}K</div> </div> </div> </div> </div> </div> {% endfor %} </div>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
数据挖掘
薪资预测:
薪资预测模型分析的数据是采用爬取下来的数据进行预测,在分析之前,需要对数据进行特征清洗,将数据出现空缺或者杂乱情况,清洗后才能拿来使用,保证数据分析的正确性。
首先,通过读取文件获取文件的信息,进而查看爬取下来的文件数据的前两行信息,观察数据并对数据进行分析处理,为后续进行模型预测奠定基础。文件数据格式如图所示:

通过查看前两行文件可知,地区、薪资、工作经验都的数据格式都不符合进行模型分析,需要对地区进行字符串切割,而薪资、工作经验则是取区间的平均值,由此得到具体的城市、薪资、工作经验数据,有利于后续的分析。处理结果数据如图所示:

通过以上对数据进行清洗与预处理,部分数据本身是字符串形式,若要对他们进行模型预测,则需要将三种维度信息进行重编码,城市通过创建LabelEncoder()对象,使用fit_transform方法对城市数据进行拟合和转换的操作,以致于把城市转换伟数值编码以便分析,而工作经验原本只是数值类型无需作重编码,而学历的重编码使用字典形式对不同的学历进行赋值,赋值情况如表8所示。重编码完成完成后,对数据进行缺失值处理即可作为训练模型数据。
表8 学历重编码表
学历 重编码值
中专/中技 0
高中 1
大专 2
本科 3
硕士 4
博士 5
学历不限 6
训练代码:
def wage_pred(area, exp, edu): jobs = pd.read_csv('D:\\毕设\\毕设\\毕设\\web - 副本\\utils\\boss_job_info_test.csv', engine='python', encoding='gbk') jobs = jobs[['area', 'salary', 'education', 'experience']] jobs['area'] = jobs['area'].apply(get_area) jobs['experience'] = jobs['experience'].apply(get_exp) jobs['salary'] = jobs['salary'].apply(get_salary) # 对城市进行重编码 le_area = LabelEncoder() jobs['area_code'] = le_area.fit_transform(jobs['area']) # 对教育程度进行重编码 education_mapping = {'中专/中技': 0, '高中': 1, '大专': 2, '本科': 3, '硕士': 4, '博士': 5, '学历不限': 6} jobs['education_code'] = jobs['education'].map(education_mapping) # 处理缺失值 imputer = SimpleImputer(strategy='mean') X = jobs[['area_code', 'experience', 'education_code']] X_imputed = imputer.fit_transform(X) # 模型学习 model = LinearRegression() model.fit(X_imputed, jobs['salary']) area_code = le_area.transform([area])[0] edu_code = education_mapping[edu] X_input = [[area_code, exp, edu_code]] wage_pred = model.predict(X_input) print(wage_pred) return wage_pred
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
岗位推荐:
推荐算法使用的是基于用户的协同过滤算法,计算用户之间的相似度,将与其他用户相比相似度最高的用户的收藏列表以及搜索列表,再将收藏列表的岗位进行加权比重,将排名靠前的十个岗位推荐给登录用户。
代码:
import numpy as np import pandas as pd from sqlalchemy import create_engine import pymysql # 连接到数据库 con = create_engine('mysql+pymysql://root:123456@192.168.10.202:3306/boss?charset=utf8') # 用户 df_collection = pd.read_sql('select user_id,job_id from collection union all select user_id,job_id from select_job',con=con) data = df_collection.to_dict(orient='records') # 创建一个空字典 merged_data = {} # 遍历数据列表 for entry in data: user_id = entry['user_id'] job_id = entry['job_id'] # 如果用户ID已经存在于合并后的字典中,则将作业ID添加到对应的值列表中 if user_id in merged_data: merged_data[user_id].append(str(job_id)) else: # 如果用户ID不存在于合并后的字典中,则创建一个新的键值对 merged_data[user_id] = [str(job_id)] # 将合并后的字典转换为所需的格式 result = {str(k): list(v) for k, v in merged_data.items()} # 基于用户的协同过滤算法 print(result) class UserCF(): def __init__(self, user_item_dict): # 将每个用户的物品取集合 self.user_item_dict = {key: set(user_item_dict[key]) for key in user_item_dict.keys()} # 用户列表 self.users_list = list(self.user_item_dict.keys()) # 两两用户之间计算用户相似度 def compute_similer_twouser(self): # 记录与其他用户相似度的字典 user_similer_list = dict() for i in self.users_list: user_similer_list[i] = dict() for j in self.users_list: # 去除自身相似度 if i != j: # 两用户间物品并集,并计算余弦相似度 similer_item = self.user_item_dict[i] & self.user_item_dict[j] user_similer_list[i][j] = round( len(similer_item) / (len(self.user_item_dict[i]) * len(self.user_item_dict[j])) ** 0.5, 3) return user_similer_list # 优化后的倒查表方式计算用户相似度 def computer_similer_backform_normal(self): import numpy as np # 记录物品的所有用户的字典 item_user_dict = dict() # 建立物品到用户的倒查表 for i, items in self.user_item_dict.items(): for j in items: if j not in item_user_dict.keys(): item_user_dict[j] = list() item_user_dict[j].append(i) # 建立用户物品二维矩阵 user_matrix = np.zeros((len(self.users_list), len(self.users_list)), dtype=int) for item, users in item_user_dict.items(): for user1 in users: for user2 in users: if user1 != user2: # 记录不同用户间共同物品的数目 user_matrix[self.users_list.index(user1)][self.users_list.index(user2)] += 1 # 计算用户相似度 user_similer_list = dict() for user1 in self.users_list: user_similer_list[user1] = dict() for user2 in self.users_list: if user1 != user2: # 利用二维矩阵存储的用户相似度进行计算 user_similer_list[user1][user2] = round( user_matrix[self.users_list.index(user1)][self.users_list.index(user2)] / (len(self.user_item_dict[user1]) * len(self.user_item_dict[user2])) ** 0.5, 3) return user_similer_list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
参考文章
https://blog.csdn.net/cxm259/article/details/118961604
https://blog.csdn.net/BGMcat/article/details/123300633
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/weixin_53118431/article/details/140174857


