
- 1XGBoost_xgboost损失函数
- 2JAVA poi-tl 制作word模板 表格数据行循环 带有复选框勾选的表格_poi-tl 复选框
- 3前端echarts框架实现饼状图、柱状图和折线图_饼图前端
- 4Redis与Lua脚本(进阶篇)_redis lua
- 5Linux下安装配置Postfix邮件服务器_550 domain may not exist or dns check failed
- 6【STM32】FPU的启用和基于ARM-DSP库函数的实时信号RMS计算_stm32f4开启fpu
- 7怎么将B站上的视频下载到本地?_urlgot
- 82024年安卓最新我的MVVM 开源小项目已发布~,阿里技术面试题_android mvvm开源项目
- 9AI大模型】跌倒监控与健康:技术实践及如何改变未来
- 10Netty性能测试_netty tcp压力测试
基于情感分析的LSTM预测股票走势_lstm股票评论情感分析代码
赞
踩
目录
一.LSTM
在金融时间序列分析中,长短期记忆网络(LSTM)因其能够捕捉数据中的长期依赖关系而被广泛采用。本文就不在此进行多说,相关文章可以借鉴<如何从RNN起步,一步一步通俗理解LSTM>,LSTM的主要优势在于它的门控机制,包括遗忘门、输入门和输出门,如图2所示


二.股票数据
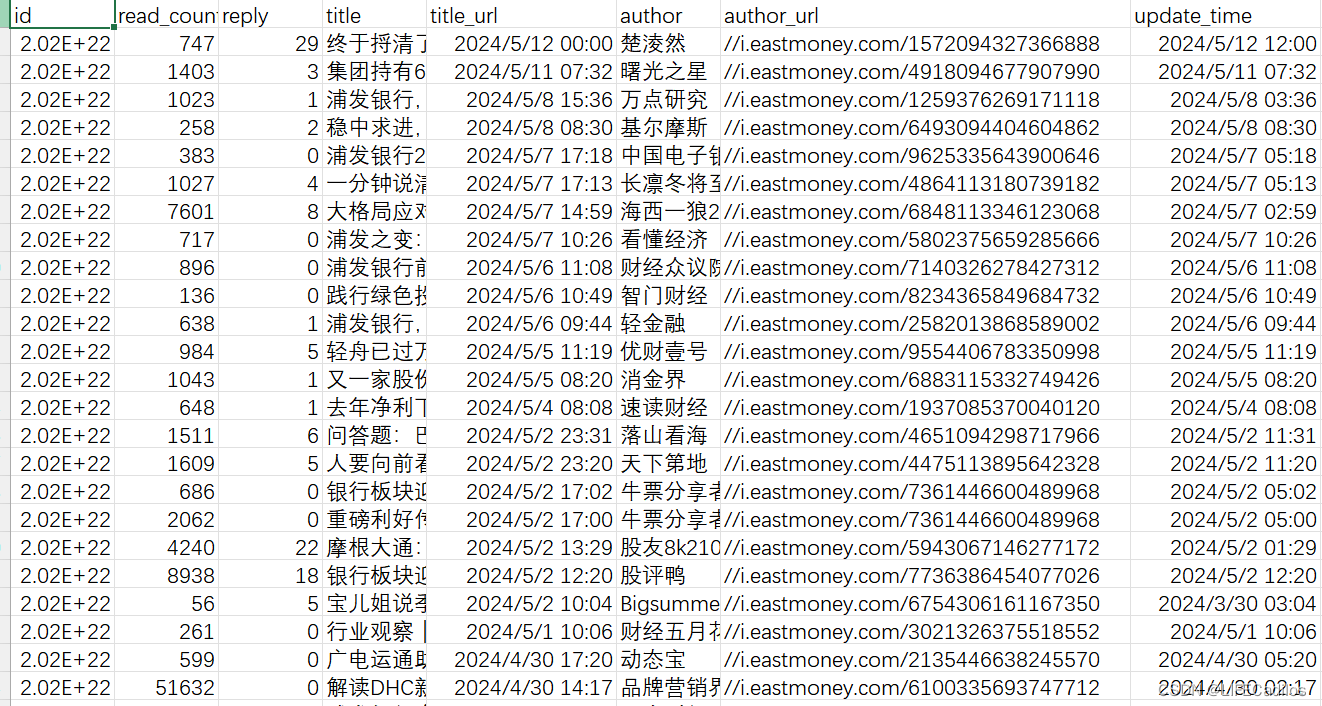
研究采集2000年至2024年的浦发银行股票交易数据,涵盖开盘价、收盘价、最高价、最低价、成交量及成交金额等。爬取东方财经网的浦发银行评论共3479条,从国家统计局与Choice金融终端共收集到2000-2024年的股票价格数据共3393条数据,如图下所示 :
| open | close | high | low | volume | sum | |
| 2010-02-03 | 19.31 | 19.89 | 19.93 | 19.01 | 76493075 | 1.5E+09 |
| 2010-02-04 | 19.61 | 19.66 | 19.89 | 19.6 | 46162099 | 9.09E+08 |
| 2010-02-05 | 19.2 | 19.42 | 19.68 | 19.16 | 43895954 | 8.5E+08 |
| 2010-02-08 | 19.45 | 19.22 | 19.5 | 19.08 | 37230982 | 7.17E+08 |
| 2010-02-09 | 19.2 | 19.42 | 19.49 | 19.17 | 26496190 | 5.14E+08 |
| ………………………………………………………………………………………………………………………………………… | ||||||
| 2024-01-26 | 6.78 | 6.87 | 6.91 | 6.75 | 70997933 | 4.85E+08 |
| 2024-01-29 | 6.86 | 6.9 | 6.97 | 6.85 | 55269921 | 3.82E+08 |
| 2024-01-30 | 6.9 | 6.83 | 6.95 | 6.82 | 40737046 | 2.8E+08 |
| 2024-01-31 | 6.81 | 6.83 | 6.88 | 6.74 | 45661999 | 3.11E+08 |
| 2024-02-01 | 6.83 | 6.8 | 6.88 | 6.78 | 44252421 | 3.02E+08 |
| 2024-02-02 | 6.82 | 6.84 | 6.92 | 6.72 | 59482913 | 4.07E+08 |
三.文本数据
文本数据则包括新闻报道、金融报告以及社交媒体上的投资讨论,这些数据主要来自于东方财富网股吧,数据源丰富了本研究的情感分析和文本挖掘部分。为了确保数据的有效性和可靠性,所有文本数据均从公开可信的渠道收集,并通过程序自动化工具每日更新和存储数据。部分数据如下:
四.文本数据情感分析
案例采用基于机器学习的情感分析方法,主要利用了针对中文文本处理的工具SnowNLP以评估金融文本的情绪倾向。SnowNLP的核心功能是情感分析,该功能基于朴素贝叶斯分类器实现。
在本案例中,代码通过调用SnowNLP(x).sentiments对评论标题进行情感得分计算,鉴于每天的评论数量众多,本研究对这些得分进行平均处理,以获得每日的情绪综合评分。,此方法返回一个介于 0(完全消极)到 1(完全积极)之间的分数。得分反映了文本内容的情绪倾向,通过设置阈值(0.5),将情感得分转化为具体的情绪类别(正面或负面),进而进行进一步的分析和统计。这种方法对于分析时间序列数据中的情绪变化尤其有用,还加深了我们对市场情绪变化的理解,使得预测更具前瞻性和适应性。代码如下所示:
- import pandas as pd
- from snownlp import SnowNLP
-
- # 加载数据
- data = pd.read_excel('浦发银行.xlsx')
-
- # 确保时间列存在且格式正确。由于时间列包括具体时间,因此需要匹配包括时间的格式
- data['update_time'] = pd.to_datetime(data['update_time'], format='%Y/%m/%d %H:%M', errors='coerce')
- # 确保时间和标题都不是空值
- data = data.dropna(subset=['update_time', 'title'])
-
- # 情感分析,计算情感得分
- data['sentiment_score'] = data['title'].apply(lambda x: SnowNLP(x).sentiments)
-
- # 根据情感得分定义情感类型
- threshold = 0.5
- data['sentiment_type'] = data['sentiment_score'].apply(lambda x: 'positive' if x >= threshold else 'negative')
-
- # 对每天的数据分组并计算positive和negative的平均值
- result = data.groupby(data['update_time'].dt.date).agg({
- 'title': 'count', # 计算每天的标题数量
- 'sentiment_score': ['mean', 'count'], # 计算每天的平均情感得分及其数量
- 'sentiment_type': lambda x: (x == 'positive').mean() # 计算正面情感的比例
- }).reset_index()
-
- # 重命名列便于理解
- result.columns = ['Date', 'Title Count', 'Average Sentiment Score', 'Sentiment Count', 'Positive Sentiment Ratio']
-
- # 创建新的列pos和neg
- result['Positive'] = result.apply(lambda x: x['Average Sentiment Score'] if x['Positive Sentiment Ratio'] >= 0.5 else None, axis=1)
- result['Negative'] = result.apply(lambda x: x['Average Sentiment Score'] if x['Positive Sentiment Ratio'] < 0.5 else None, axis=1)
-
- # 使用0.5填充空缺值(根据需要可以调整这个值)
- result['Positive'].fillna(0.5, inplace=True)
- result['Negative'].fillna(0.5, inplace=True)
-
- # 保存到Excel文件
- result.to_excel('分析结果.xlsx', index=False)

| 日期 | 积极情绪指数 | 日期 | 积极情绪指数 |
| 2018-12-15 | 0.8553 | 2018-11-30 | 0.5903 |
| 2018-12-16 | 0.9605 | 2018-12-01 | 0.8363 |
| 2018-12-19 | 0.6188 | 2018-12-02 | 0.9439 |
| 2018-12-21 | 0.5056 | 2018-12-04 | 0.7746 |
| 2018-12-27 | 0.9627 | 2018-12-06 | 0.7256 |
| 2018-12-29 | 0.7180 | 2018-12-08 | 0.7935 |
| 2018-12-30 | 0.6807 | 2018-12-10 | 0.8210 |
五.数据合并,归一化分析
- import pandas as pd
-
- # Load both Excel files
- result_path = '/mnt/data/分析结果.xlsx'
- data_result = pd.read_excel(result_path)
-
- bank_data_path = '/mnt/data/浦发银行.xlsx'
- data_bank = pd.read_excel(bank_data_path)
-
- # Ensure both date columns are in the same datetime format
- data_bank['日期'] = pd.to_datetime(data_bank['日期'], errors='coerce')
- data_result['Date'] = pd.to_datetime(data_result['Date'], errors='coerce')
-
- # Attempt to merge again
- merged_data_final = pd.merge(data_result, data_bank, left_on='Date', right_on='日期', how='inner')
-
- # Save the correctly merged data to a new Excel file
- final_merged_file_path = '/mnt/data/final_merged_data.xlsx'
- merged_data_final.to_excel(final_merged_file_path, index=False)
六.对变量进行相关性分析
分析结果如下,由此可见,pos.neg与股票技术的相关性很强


七.基于lstm进行股票价格预测
- #!/usr/bin/python3
- # -*- encoding: utf-8 -*-
- from this import s
-
- import matplotlib.pyplot as plt
- import numpy as np
- import tushare as ts
- import pandas as pd
- import torch
- from torch import nn
- import datetime
- import time
- from sklearn.metrics import r2_score # Import r2_score from sklearn
-
- DAYS_FOR_TRAIN = 10
-
-
- class LSTM_Regression(nn.Module):
- """
- 使用LSTM进行回归
- 参数:
- - input_size: feature size
- - hidden_size: number of hidden units
- - output_size: number of output
- - num_layers: layers of LSTM to stack
- """
-
- def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
- super().__init__()
-
- self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
- self.fc = nn.Linear(hidden_size, output_size)
-
- def forward(self, _x):
- x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)
- s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
- x = x.view(s * b, h)
- x = self.fc(x)
- x = x.view(s, b, -1) # 把形状改回来
- return x
-
-
- def create_dataset(data, days_for_train=5) -> (np.array, np.array):
- """
- 根据给定的序列data,生成数据集
- 数据集分为输入和输出,每一个输入的长度为days_for_train,每一个输出的长度为1。
- 也就是说用days_for_train天的数据,对应下一天的数据。
- 若给定序列的长度为d,将输出长度为(d-days_for_train+1)个输入/输出对
- """
- dataset_x, dataset_y = [], []
- for i in range(len(data) - days_for_train):
- _x = data[i:(i + days_for_train)]
- dataset_x.append(_x)
- dataset_y.append(data[:, 2][i + days_for_train])
- return (np.array(dataset_x), np.array(dataset_y))
-
-
- # 定义一个函数来对DataFrame的指定列进行归一化
- def normalize_columns(df, columns_to_normalize):
- for column in columns_to_normalize:
- df[column] = (df[column] - df[column].min()) / (df[column].max() - df[column].min())
- return df
-
-
- if __name__ == '__main__':
- t0 = time.time()
- data = pd.read_csv('浦发银行单一.csv', index_col='Date') # 读取文件
- print(data.shape)
- data = data.astype('float32').values # 转换数据类型
- data = data
- print(data.shape)
- print(data)
- for i in range(data.shape[1]):
- plt.plot(data[:, i])
- plt.savefig('data.png', format='png', dpi=200)
- plt.close()
- # 将价格标准化到0~1
- max_value = np.max(data[:, i])
- min_value = np.min(data[:, i])
- data[:, i] = (data[:, i] - min_value) / (max_value - min_value)
- print(data[:, i])
-
-
- dataset_x, dataset_y = create_dataset(data, DAYS_FOR_TRAIN)
-
- train_size = int(len(dataset_x) * 0.70)
-
- train_x = dataset_x[:train_size]
- train_y = dataset_y[:train_size]
-
-
- train_x = train_x.reshape(-1, 1, DAYS_FOR_TRAIN * 6)
- train_y = train_y.reshape(-1, 1, 1)
-
-
- train_x = torch.from_numpy(train_x)
- train_y = torch.from_numpy(train_y)
- #
- model = LSTM_Regression(6 * DAYS_FOR_TRAIN, 10, output_size=1, num_layers=4)
-
- model_total = sum([param.nelement() for param in model.parameters()]) # 计算模型参数
- print("Number of model_total parameter: %.8fM" % (model_total / 1e6))
-
- train_loss = []
- loss_function = nn.MSELoss()
- optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
- for i in range(350):
- out = model(train_x)
- loss = loss_function(out, train_y)
- loss.backward()
- optimizer.step()
- optimizer.zero_grad()
- train_loss.append(loss.item())
-
- # 将训练过程的损失值写入文档保存,并在终端打印出来
- with open('log.txt', 'a+') as f:
- f.write('{} - {}\n'.format(i + 1, loss.item()))
- if (i + 1) % 1 == 0:
- print('Epoch: {}, Loss:{:.5f}'.format(i + 1, loss.item()))
-
- # 画loss曲线
- plt.figure()
- plt.plot(train_loss, 'b', label='loss')
- plt.title("Train_Loss_Curve")
- plt.ylabel('train_loss')
- plt.xlabel('epoch_num')
- plt.savefig('loss.png', format='png', dpi=200)
- plt.close()
-
- # torch.save(model.state_dict(), 'model_params.pkl') # 可以保存模型的参数供未来使用
- t1 = time.time()
- T = t1 - t0
- print('The training time took %.2f' % (T / 60) + ' mins.')
-
- tt0 = time.asctime(time.localtime(t0))
- tt1 = time.asctime(time.localtime(t1))
- print('The starting time was ', tt0)
- print('The finishing time was ', tt1)
-
- # for test
- model = model.eval() # 转换成测试模式
- # model.load_state_dict(torch.load('model_params.pkl')) # 读取参数
-
- # 注意这里用的是全集 模型的输出长度会比原数据少DAYS_FOR_TRAIN 填充使长度相等再作图
- dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN * 6) # (seq_size, batch_size, feature_size)
- dataset_x = torch.from_numpy(dataset_x)
-
- pred_test = model(dataset_x) # 全量训练集
- # 的模型输出 (seq_size, batch_size, output_size)
- pred_test = pred_test.view(-1).data.numpy()
- pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使长度相同
- assert len(pred_test) == len(data)
-
- # Calculate R^2 score
- r2 = r2_score(data[:, 3], pred_test)
- print(f'R^2 score: {r2:.4f}')
-
- plt.plot(pred_test, 'r', label='prediction')
- plt.plot(data[:, 3], 'b', label='real')
- plt.plot((train_size, train_size), (0, 1), 'g--') # 分割线 左边是训练数据 右边是测试数据的输出
- plt.legend(loc='best')
- plt.title(f'Prediction vs Real (R^2 score: {r2:.4f})')
- plt.savefig('result.png', format='png', dpi=200)
- plt.show()
- plt.close()
-
为了维护稳定,对每列进行单独归一化处理,防止量纲问题,将每列的值转换到0-1的范围。鉴于LSTM需要序列数据作为输入,使用滑动窗口的方法从时间序列中提取特征,在代码中,days_for_train是窗口代码,即使用days_for_train 天的数据来预测下一天的数据。这里的_x是包含连续几天的数据特征。
数据整形(reshape):输入的数据应该是(序列长度seq_len,批大小batch_size,特征数量input_size),这一特点是为了符合pytorch的要求,每个训练样本都被处理为单独的一个小批量,而每个批量都包含了序列的全部时间与全部特征,使得LSTM有效的学习数据序列的时间依赖性。
批处理与模型输入:将数据转化为pytorch的tensor输入模型,对参数进行调整,最大化捕捉特征关系,提高拟合度并且避免过度拟合。随后做对比分析,并用r-square来做拟合程度评估
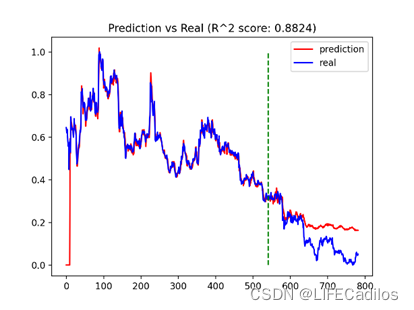
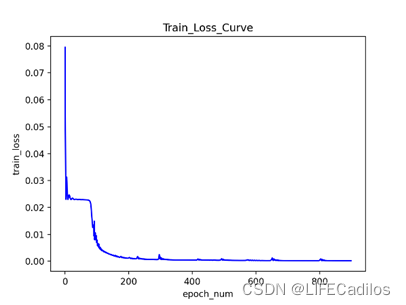

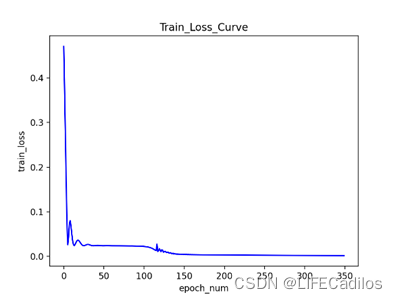
在原有的技术指标之上加入了pos与neg的变量,R^2 表示有预测值与真实值的拟合程度,越接近1表示拟合度越高,再加入pos与neg变量之后,拟合度由0.8186提高到了0.8824,可知pos与neg对预测结果的影响很大。本文LSTM代码借鉴LSTM-代码讲解(股票预测)

