
- 1idea git 过滤target_IDEA + maven 零基础构建 java agent 项目
- 2安装IK分词器_ik分词器不能直接解压
- 3使用docker安装SQL审计工具archery_sql语法检查工具 docker
- 4IBM MQ部分知识点梳理
- 5微信小程序获取手机号报错getPhoneNumber:fail no permission
- 6FLP不可能原理
- 7信息论在机器学习中的实际应用
- 8脱胎于 S 语言的R语言,Ross Ihaka 和 Robert Gentleman 和社区的力量让 R 在学术界与研究机构放光彩
- 9【AI】本地部署可以与文件沟通的GPT:Llama 2 + GPT4All + Chroma_ollama gpt4all
- 10Redis精通系列——LFU算法详述(Least Frequently Used - 最不经常使用)_redis lfu算法
LLaMa3.1 模型训练四十问
赞
踩
\1. Q: LLaMa3.1上下文窗口多大?
A: 128K Token; 标准预训练阶段8K Token; 长上下文调整预训练阶段 128K Token(提升16倍);
2. Q: LLaMa3.1 Token编码方式?
A: BPE + RoPE(500,000)
3. Q: LLaMa3.1 语料库词库大小?
A: 15T 语料库 (LLaMa2 只有1.8T)
4. Q: LLaMa3.1 最大模型参数量?
A: 405B
5. Q: LLaMa3.1 包含哪几种多媒体的模态
A: 图像、语音、视频
6. Q: 语料去重做了哪些工作?
A: URL去重,文档去重, 行/句子去重。
7. Q: 语料去重用了哪些算法?
A: URL去重:最新页面URL链接
文档去重:MinHash算法
行句子去重:ccNet(3000万文档桶中出现6次)
8. Q: 语料清洗做了哪些工作?
A: 去重,个人身份信息(PII)过滤,成人内容过滤, 文本提取, 质量分类, 语言分类
9. Q: 语料清洗用了哪些算法?
A: 过滤: 重复N-Gram覆盖率, 敏感词过滤, KL散度近似语料过滤
文本提取: 图片Alt属性提取, HTML Alt数学公式提取, 代码内容提取
质量分类:fasttext, wiki引用识别,Roberta分类, LLaMa2分类, DistilRoberta分类
语言分类:LLaMa2分类
10. Q: 高质量语料数据增强方式?
A: 知识分类重采样(最终实现各任务知识分类比例偏差较小)
数据混配(最终实现 50%的通识文本 Token, 25%的数学和推理 Token, 17%的编码Token, 8%的多语种Token。 )
公式代码退火(最终实现对标OpenAI的在标准测试集上的效果)
11. Q: *高质量语料数据增强的算法?*
A: 知识分类重采样:基于任务的文本标记, 基于标记重采样文本(例如, 降采样艺术,娱乐分类文本的比例)
数据混配: 应用Scaling Law,采样数据集上做大量实验, 推测大数据集效果, 然后选定配比, 再进行关键基准测试集效果评定。
公式代码退火:
12. Q: LLaMa3.1激活函数选择
A: SwiGLU,
13. Q: *LLaMa3.1模型大小是如何定的?*
A: 根据Scaling law, 1)先定计算预算:6×10^18 FLOPs到10^22 FLOPs。 2)选择40M到16B参数进行预训练, 确定IsoFLOPs曲线,推算Validation Loss目标。3)固定2000步训练之后, 执行Cosine学习率调度调整。4)拟合ISOLoss Contours, 或者固定Loss拟合计算效率。
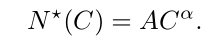
5)根据(α, A) = (0 . 53 , 0 . 29), 16.55T tokens, 3.8×10^25 FLOPs的算力预算下, 最佳参数大小为 402B。

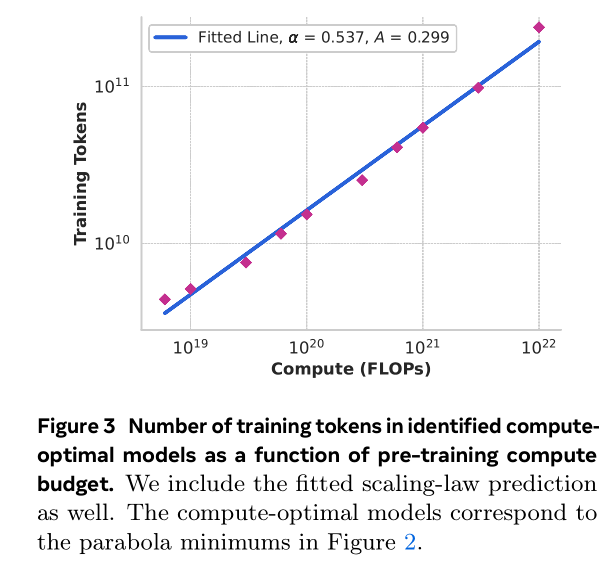
14. Q: *LLaMa3.1学习率调度调整用了什么策略*?
A: 用了Consine学习率调度策略, 余弦衰减设置为峰值的0.1,
15. Q: *LLaMa3.1用了多少GPU?*
A: 16K的H100 GPU上进⾏训练(能耗 700W TDP,内存80GB HBM3)。
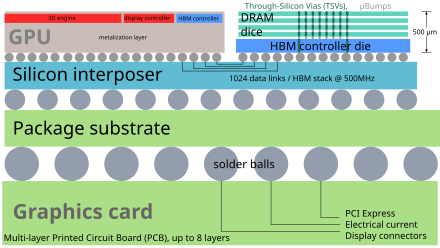
16. Q: *LLaMa3.1训练硬件平台是什么?*
A: 服务器 Grand Teton AI服务器平台(8个GPU,2个CPU)
**
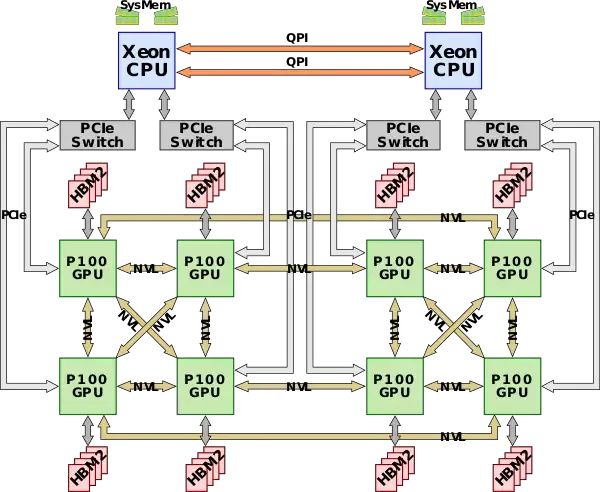
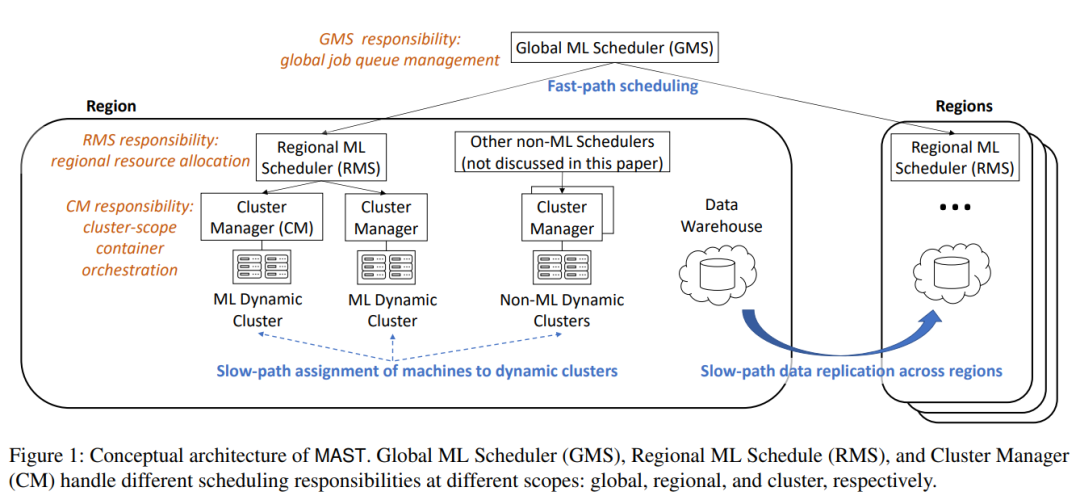
17. Q: *LLaMa3.1训练软件平台式什么?*
A: MAST平台(ML Application Scheduler on Twine), 主要围绕着提升GPU占用率, 以及满足一定按时间分割的特性做了调度优化。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/天景科技苑/article/detail/945384
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

