
- 1linux一把梭之升级(centos7.9)_kernel-devel离线安装
- 2【NLP】文本生成评价指标:BLEU_nlp文本生成评估指标
- 3Mac电脑安装nvm(node包版本管理工具)
- 4【git】如何查看某个分支从哪个分支checkout -b出来的_如何看从那个分支 checkout出来的
- 5mysql 5 可执行漏洞_MySQL暴身份认证漏洞 需升级到5.5.24可修正
- 6[算法] 优先算法(六):二分查找算法(下)
- 7RabbitMQ学习笔记:内存(Memory)|磁盘空间(Disk space)阀值_rabbitmq disk space
- 8JAVA语言的优点及特性_java语言的特点和优势
- 9x-cmd-pkg | gojq - 基于 Go 编写的 jq 工具_golang jq 工具
- 10Github Copilot 使用技巧
新手不摸黑!一文看懂LangChain Agent源码(二)_langchain 源码解读
赞
踩
导语
LangChain 是一个优秀的 LLM 应用开发框架,让普通开发者能够快速入门 LLM 应用开发,能够轻松地实现预期功能。agent 模块是使用 LangChain 框架开发 LLM 应用中最重要的模块之一。上一篇文章中,我们完成了 agent 模块中 Agent 和 AgentExecutor 初始化的源码分析,这次我们继续分析 agent 执行的源码,看看 agent 如何使用大模型进行推理,又如何根据推理使用工具。
查看上一篇的内容可以在下方公众号中查看

执行推理的源码分析
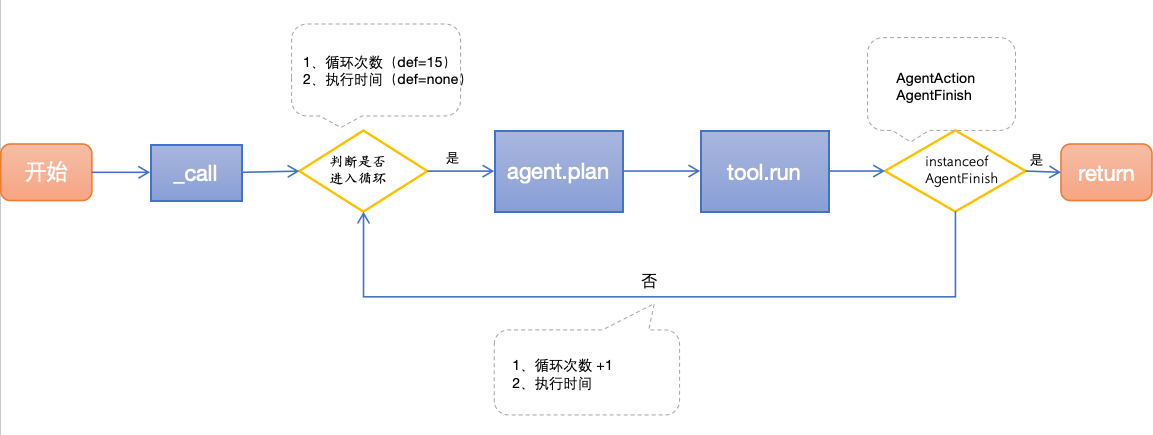
1、执行代码总览
从上图我们看到 AgentExecutor 的执行过程,实际上就是一个循环执行推理的过程,推理过程分两个大的步骤:
- 一是访问 LLM 获得计划,也就是 agent.plan 方法;
- 二是根据计划选择是否执行 tool,也就是 tool.run;
根据 AgentFinish 和 AgentAction 这两种状态值来判断是继续循环还是返回结果;
控制循环的条件除了 AgentFinish 和 AgentAction 两种输出状态之外,还有之前我们提到的参数控制 max_iterations 最大循环次数和 max_execution_time 最长执行时间。
2、核心执行逻辑_call(agent.py -> _call)
_call 方法的逻辑比较简单,
下图是 _call 方法的代码(三段逻辑已用红色序号标出):
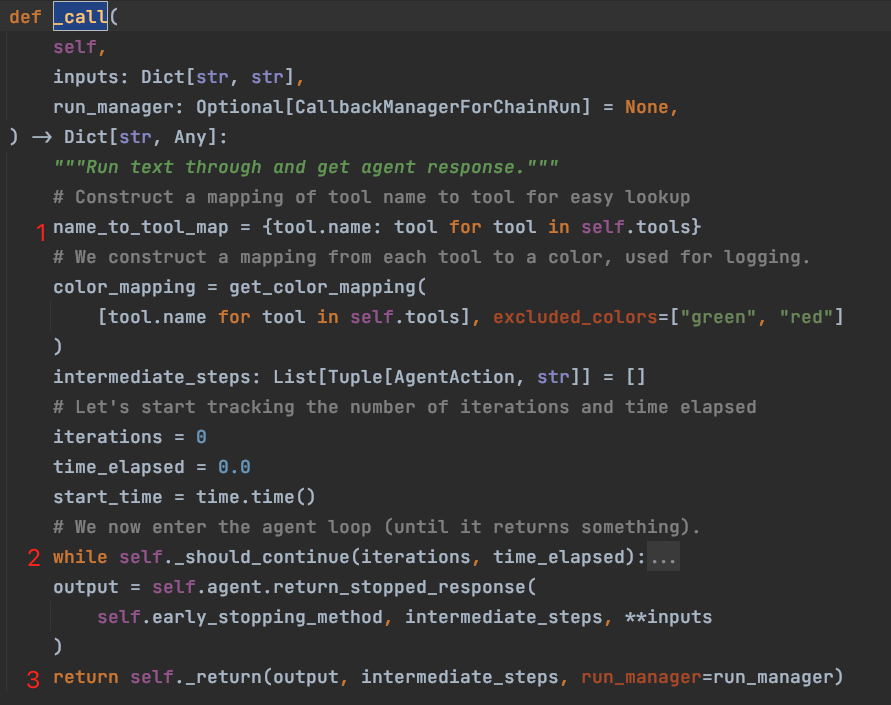
- 第 1 步是加载了需要使用的工具,放在 map 里面备用;
- 第 2 步就是核心的循环逻辑,plan ➕ tool 执行,这里如果有返回给用户的输出,会在循环中直接返回;
- 第 3 步的输出实际上是第二步循环异常退出之后的输出处理;
那么这里关键的步骤在第 2 步:plan ➕ tool 执行
3、循环逻辑
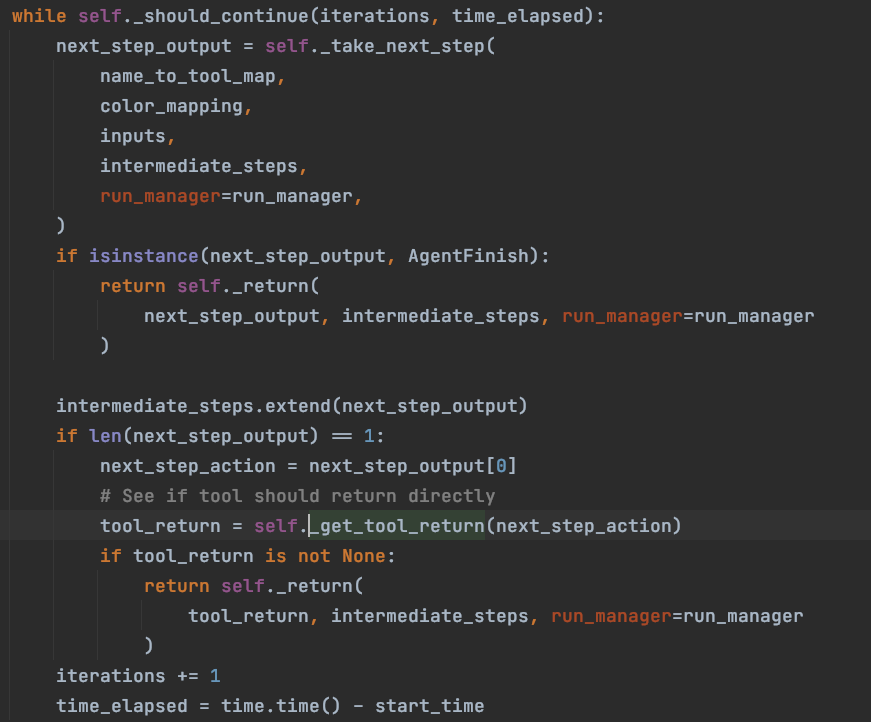
下图是 _call 方法中的循环逻辑,
plan 和 tool 执行,它们在方法 _take_next_step 中,其余的代码是判断本次推理是否可 return 的逻辑,我们不做重点分析,现在我们去看 plan 的执行和 tool 的调用。
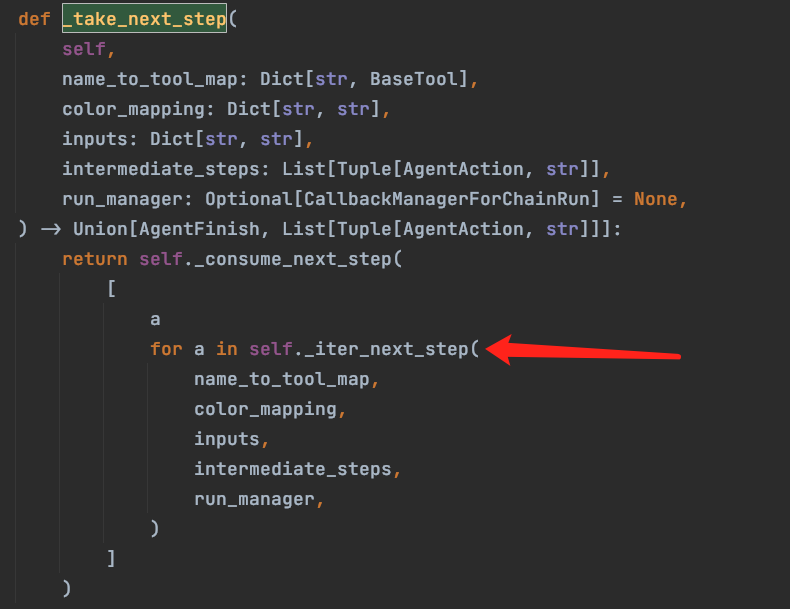
4、方法_take_next_step
当我们进入 _take_next_step 方法会发现,还需要进一步到方法 _iter_next_step 中,所以我们再进入方法 _iter_next_step 中。
5、方法_iter_next_step
最终我们在这里找到了核心方法 plan 和 tool 执行的入口。
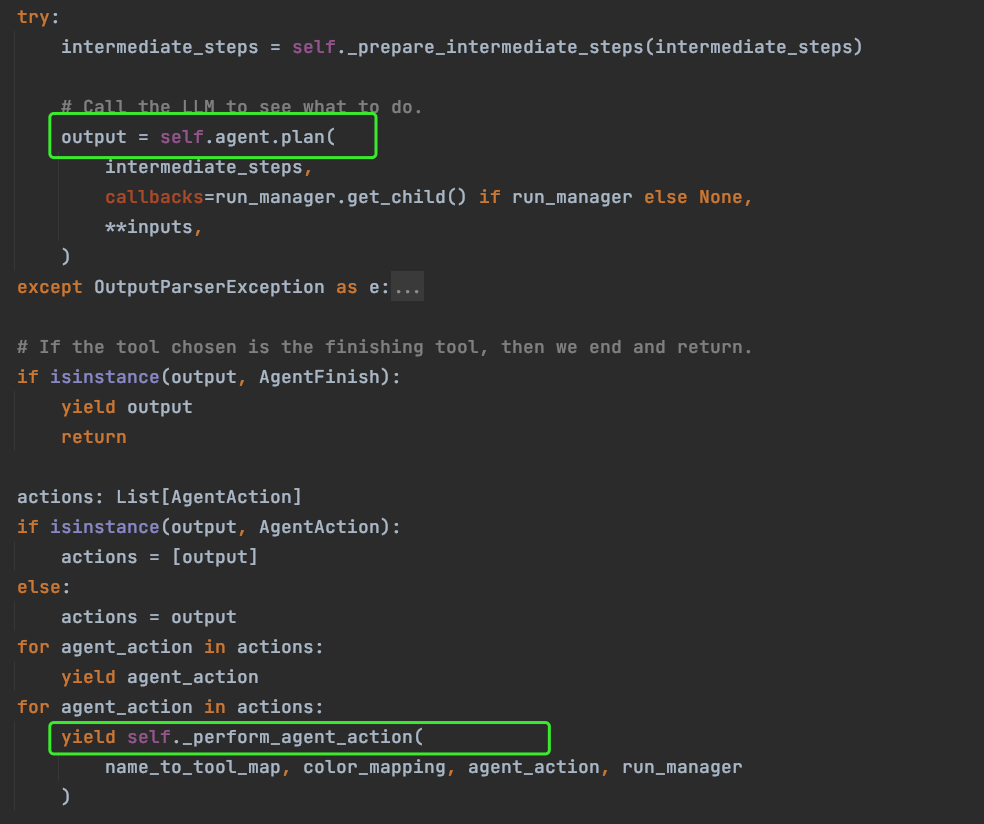
A. 这里稍微留意一下 intermediate_steps 变量,如果程序不断循环,这个变量会将之前的步骤逐渐累加起来,放入提示词中传给 LLM;
B. 然后是 plan 方法,这里面会去调用 LLM 获取推理计划,我们不再进入内部的调用过程,直接看一下它的返回结果,这里我们会看到模型给出的 action 是名为“tool_name”的工具名称,而且 action_input 是一个多数据的字典结构,也就是说大语言模型成功按照工具中的 args_schema 结构解析出了传参数据。
下面的 JSON 是实际的 action_input(实例中具体的值已经被处理掉,只保留了具体结构):
**Action: **```{
"action": "tool_name",
"action_input": {
"args1": "123",
"args2": "60",
"args3": "10"
}
}```**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
C. 上面的内容在经过 parser 方法之后(可以查看 StructuredChatOutputParser ->parse 的代码实现,上面已经在 Agent 组件初始化时介绍过 output_parser 的定义,这里不再重复分析代码),此处因为 LLM 并没有输出“Final Answer”的最终回答,所以它会被转换为下面的 AgentAction 结构(列举了主要字段值),可以清晰地看到 tool 的 name 和传参数据(隐去了敏感数值):
tool='tool_name'
tool_input={
'args1': '123',
'args2': '60',
'args3': '10'
}
log='**Action: **\n\n```\n{
\n"action": "tool_name",
\n"action_input": {
\n"args1": "123",
\n"args2": "60",
\n"args3": "10"\n
}\n
}\n```\n\n**'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6、方法_perform_agent_action
它是实际执行 tool 的地方,当我们在上一步中拿到了 output,我们进入该方法。
这里会从之前初始化好的 name_to_tool_map 中查找要执行的工具,随后执行它,我们要进入 run 方法,查看它在执行时如何处理工具的多参数逻辑。
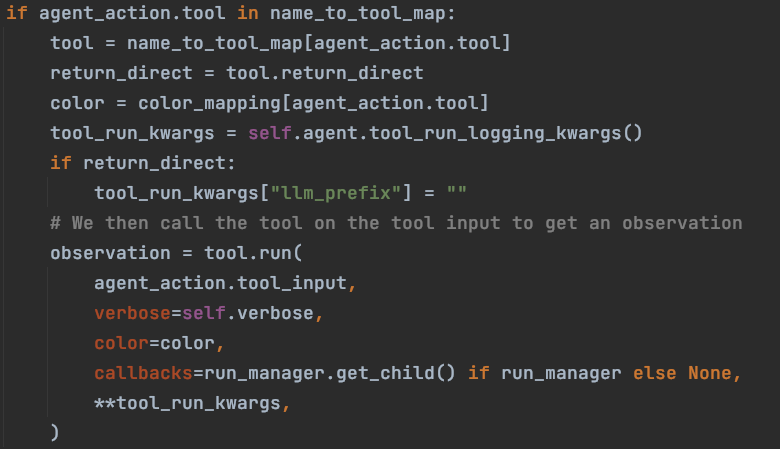
A. tool 执行 run(tools.py -> run)
这里的 _parse_input 方法是处理多参数传参的关键,需要着重看一下它的实现
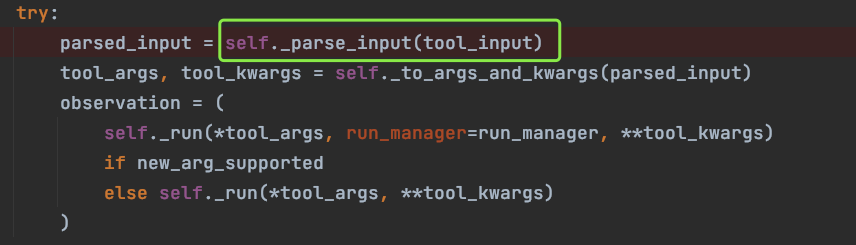
下图就是 _parse_input 方法的实现:
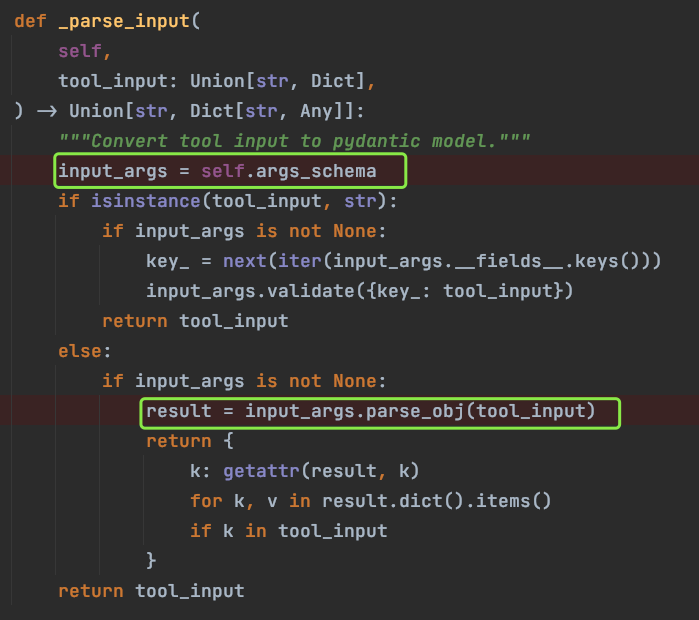
关注绿色框中的代码,首先它需要使用工具中制定的 args_schema 参数,这里可以回头看上面给出的工具定义(指定了 args_schema=tool_input),随后调用 args_schema 的 parse_obj 方法把大语言模型给出的 tool_input 的字符串转换成 args_schema 参数结构(自定义工具中 tool_input 类的定义),最后会输出参数列表词典,作为工具的最后传参;
至此,STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION 类型的 Agent 是如何支持多参传递的逻辑已经解析完成,其中 args_schema 参数至关重要。
B. 工具执行完,此时我们再次回到 _call 方法中
我们此时拿到的是一个完整的 next_step_output 数据,包括了 AgentAction 以及 observation 的工具输出两部分内容。
这里我们需要进入 _get_tool_return 方法,解析 next_step_output 获取工具输出,看是否要终止循环;
如下图:
- 第一个方框中首先将 next_step_output 分成了 AgentAction 以和 observation 两部分;
- 然后第二个方框中判断当前使用工具的输出是否为直接输出结果,如果是,则输出 AgentFinish 来终止 AgentExecutor 的中的循环。因为上面我们自定义的工具设置了 return_direct=true,所以这里返回的正是 AgentFinish。
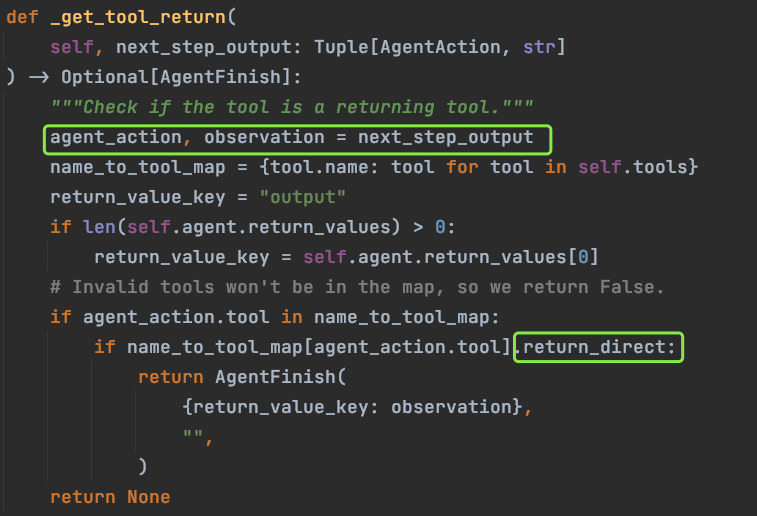
这里说明一下,如果工具中设置了return_direct=true,工具的输出结果会作为本次调用的最后输出结果直接返回给用户,否则工具的输出结果仍然会再次传给 LLM 进行最后一次分析,在一些特殊场景,设置return_direct=true会让输出结果更加可控,同时节省了部分 token。
最后,使用工具返回的tool_return数据,继续执行 _return方法,获取 final_outputs 数据,也就是 AgentFinish 中的 return_values,对应的正是工具输出的observation数据。
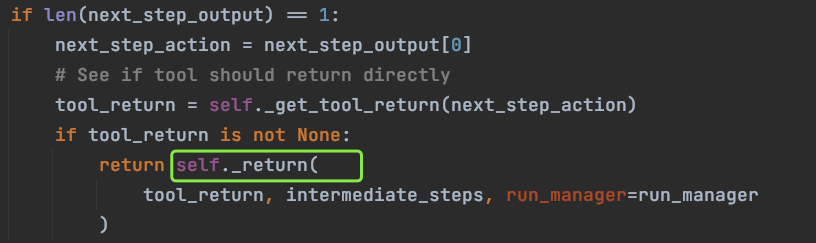
至此,Agent 执行的全部过程已经分析完毕。
结束语
碍于语言的苍白,无法非常清晰地描述所有执行逻辑,大家在开发过程中可以多注意 debug 代码,积累经验,逐渐熟悉。
快乐学习,简单学习!
关注了解更多 AI 编程、Java 编程知识!

本文由mdnice多平台发布

