
- 1windows下搭建Redis群集,实现主从复制 和 故障转移_redis在windows上故障转移
- 21.1 微信Native支付 - 接入指引与支付安全
- 3考研系列-数据结构第七章:查找(下)_b树和b+树
- 4朝阳医院2018年销售数据 数据分析与可视化
- 5微信部署ChatGPT机器人/bot_chatgpt for wechat
- 6粤嵌gec6818开发板-播放视频、音频文件(管道文件控制)_6818开发版视频播放
- 7算法导论笔记:13-04红黑树以及其他平衡树_加权平衡树
- 82023年2月可用的免费图床_图床链接生成器
- 9热门开源项目推荐
- 10FPGA之JESD204B接口——总体概要 尾片_204b映射关系
Python八股文:基础知识Part1
赞
踩
1. 不用中间变量交换 a 和 b

这是python非常方便的一个功能可以这样直接交换两个值
2. 可变数据类型字典在for 循环中进行修改

这道题在这里就是让我们去回答输出的内容,这里看似我们是在for循环中每一次加入了都在list中加入了一个字典,然后字典的键值对的value每次都加了1,实际上最后list中的值只会保留最后一个i的值,因为每一次我们对字典进行赋值的时候用的key都是同一个,每次修改都会将list中已有的字典都修改,内存中只有一个a这个字典的变量
3. 带有不同数据类型的交集并集差集

这里我们一眼看上去可能会觉得这两个集合中的交集只有9.9 和 4 + 3j,但是我们忽略了在进行这种比较的时候,每个数据类型都有自己的Boolean 形态,s1中的True,和s2中的1,在Boolean value中都代表True,所以也算是交集的一部分,同时我们可以发现在求交集的顺序的时候,其实是把后者作为优先,理解成在是 s1&s2就是在s1中找s2里面的元素,所以第一个输出了1,第二个输出了True
4. 逻辑运算符的顺序
在python中,我们进行逻辑运算的时候,参考的优先级应该是not -> and -> or,所以下面这个表达书中
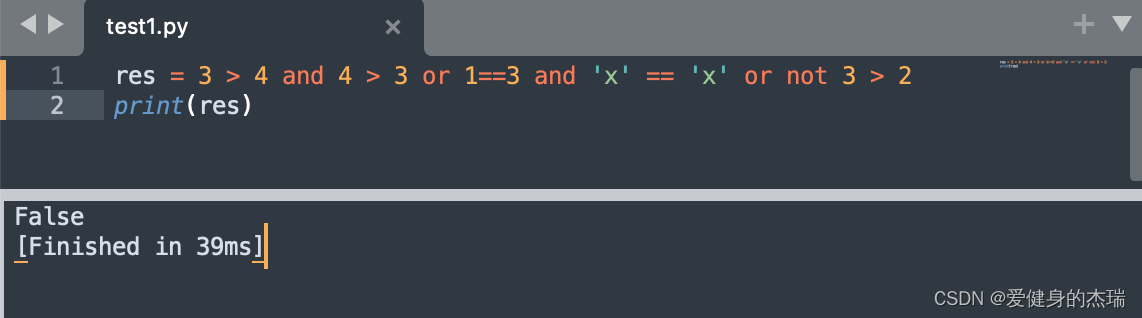
一开始我们就先把not 3 > 2 的结果算出来应该是False,然后我们再记录所有的and左右两边的表达式的结果 (False and True) or (False and True) or (False),最后发现这三个括号中的and的结果都是False,所以最后or连接起来的最终结果还是False
5. 使用max() 对字典
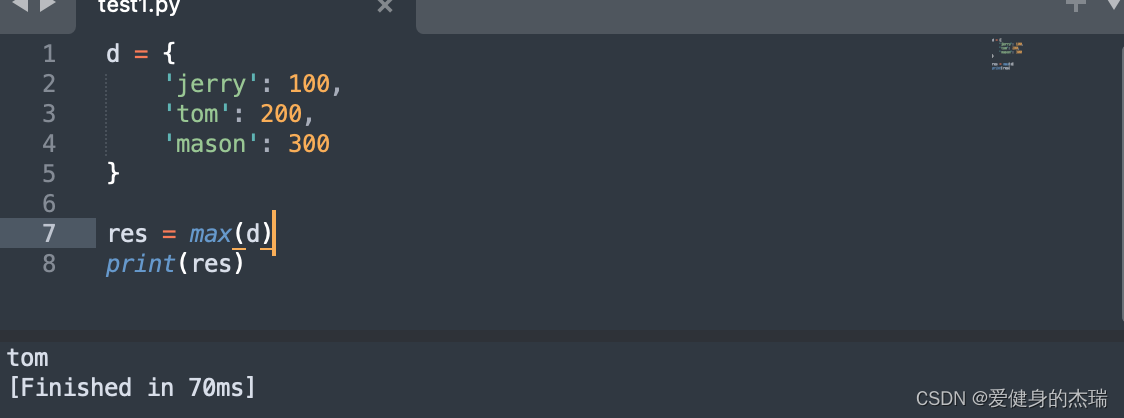
默认比较的是字典中的key,而不是value,但是我们可以通过利用lambda匿名函数来修改key param的值来修改max函数的逻辑
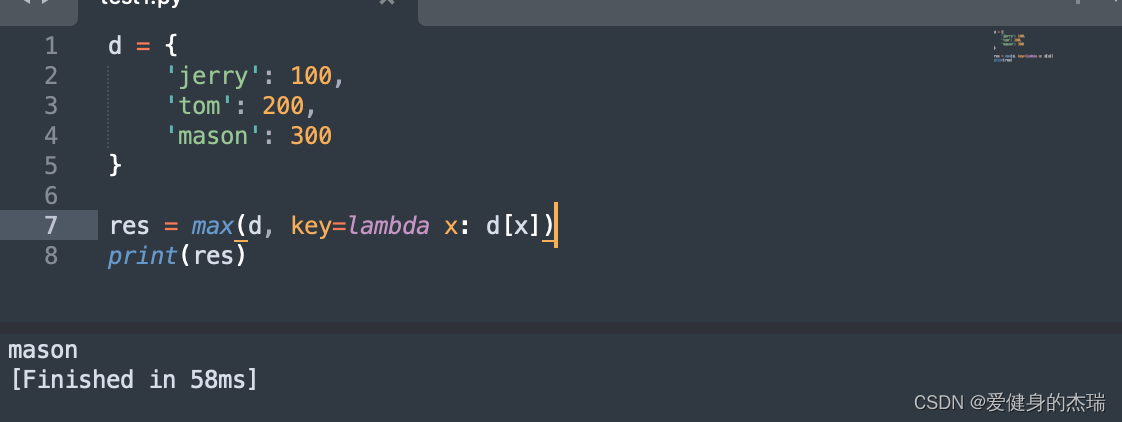
例如这里,key本身默认的是传入字典中key的值,但是这里我们修改为拿到key之后去找字典中key所对应的value的值,这样max()比较的就是每一个key的value大小了,并且返回的依然是key的值
6. 自定义函数装饰器
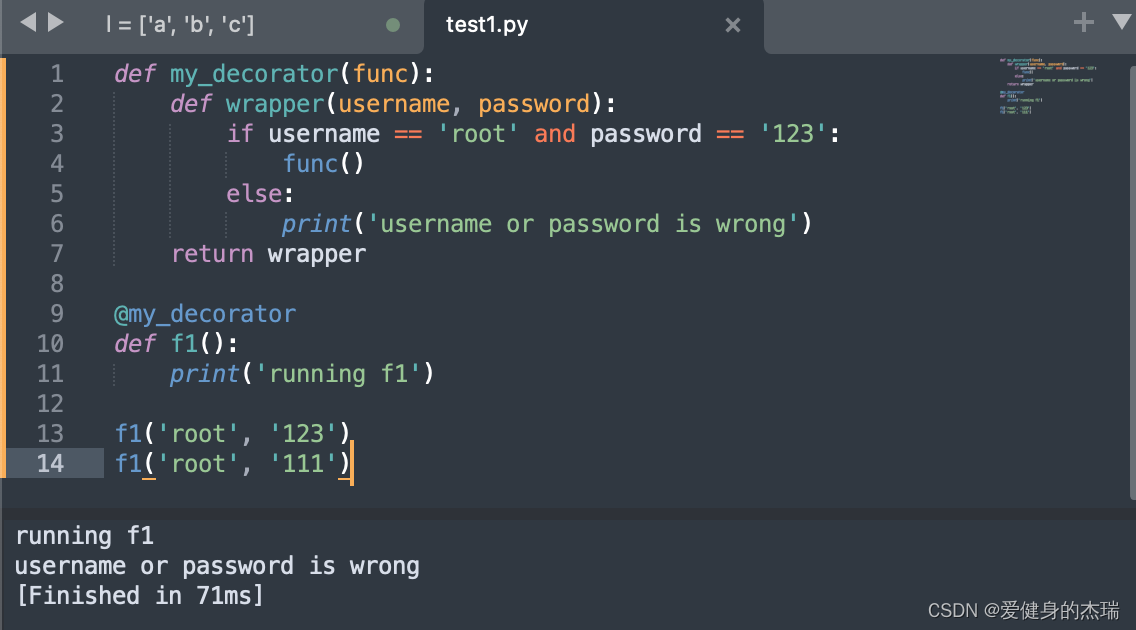
这里可以看到我们是如何定义装饰器的,或者可以给装饰器定义任意参数和关键字参数然后保证被修饰的函数可以传入任何参数
- def my_decorator(func):
- def wrapper(*args, **kwargs):
- print("Something is happening before the function is called.")
- result = func(*args, **kwargs)
- print("Something is happening after the function is called.")
- return result
- return wrapper
-
- # 装饰器用法
- @my_decorator
- def say_hello(name):
- print("Hello, " + name + "!")
- return "Greeting sent."
-
- # 调用被装饰的函数
- result = say_hello("Alice")
- print(result)

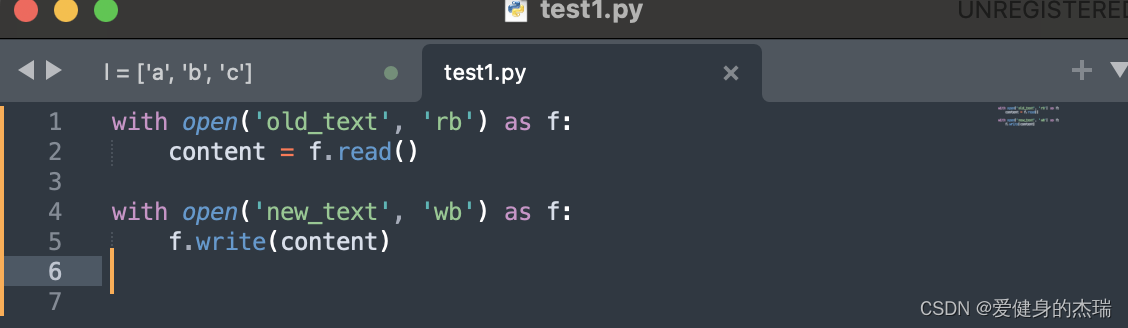
7. 简单的复制文件代码
8. Python的异常处理机制
当面试官询问 Python 的异常处理机制时,你可以从以下几个方面来介绍:
1. **异常的概念**:异常是 Python 中用于处理程序在运行过程中遇到的错误或异常情况的一种机制。当程序出现错误时,Python 解释器会引发一个异常对象,导致程序执行被中断,同时异常对象包含了错误的相关信息。
2. **异常处理语句**:在 Python 中,我们可以使用 `try`、`except`、`else` 和 `finally` 等关键字来处理异常。这些关键字可以使程序在出现异常时执行相应的处理逻辑,以保证程序的稳定性和可靠性。
3. **`try-except` 块**:`try-except` 块用于捕获异常并进行处理。在 `try` 块中编写可能会引发异常的代码,然后在 `except` 块中指定处理异常的逻辑。如果 `try` 块中的代码引发了异常,则会跳转到相应的 `except` 块进行处理,而不会导致程序终止。
4. **异常类型**:Python 中有许多内置的异常类型,比如 `SyntaxError`、`TypeError`、`ValueError` 等。你可以根据具体的情况选择捕获特定类型的异常,以便进行精确的处理。
5. **`else` 块**:`else` 块用于在 `try` 块中没有发生异常时执行的代码。如果 `try` 块中的代码成功执行完成,没有引发异常,则会执行 `else` 块中的代码。
6. **`finally` 块**:`finally` 块用于在无论是否发生异常都需要执行的清理操作,比如关闭文件或释放资源。`finally` 块中的代码会在 `try` 块中的代码执行完成后执行,即使 `try` 块中的代码引发了异常也会执行。
- try:
- # 可能会引发异常的代码
- result = 10 / 0
- except ZeroDivisionError:
- # 处理除零异常
- print("Error: Division by zero!")
- else:
- # 如果没有异常发生时执行的代码
- print("No exceptions occurred.")
- finally:
- # 无论是否发生异常都需要执行的清理操作
- print("Cleaning up resources.")
9. 利用生成器计算一组数组的阶乘
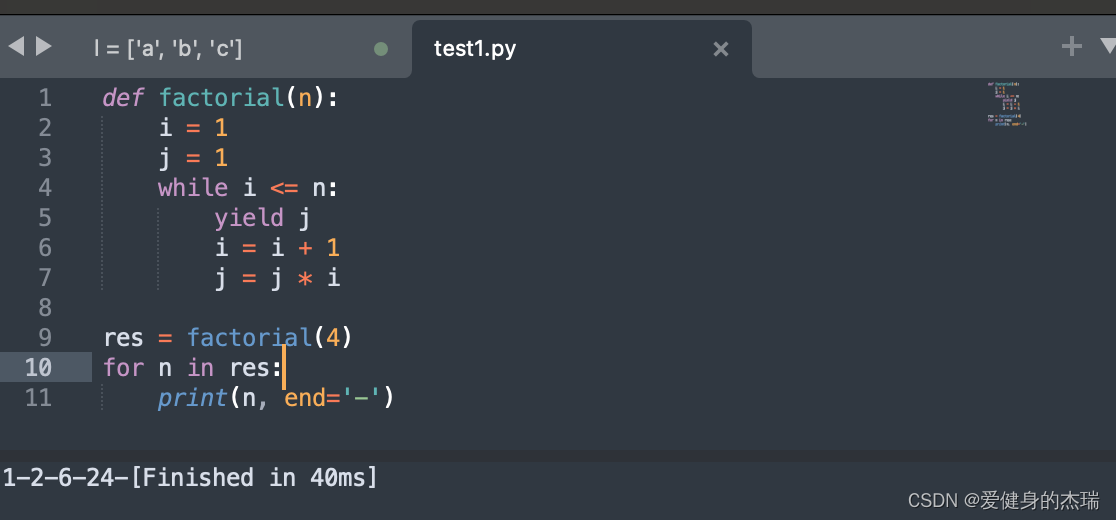
在 Python 中,生成器(Generator)是一种特殊的迭代器,它允许按需生成值,而不是一次性生成并存储所有值。生成器是使用函数和 yield 语句来创建的。当生成器函数被调用时,它会返回一个生成器对象,而不是执行函数体中的代码。每次调用生成器的 next() 方法或使用 for 循环迭代生成器时,生成器函数会从上一次停止的地方继续执行,直到遇到下一个 yield 语句,然后返回其值,并暂停执行。这使得生成器在处理大型数据集或无限序列时非常高效,因为它们在需要时逐个生成值,而不会一次性将所有值加载到内存中。
10. 继承中的函数调用

这里就是在说当我们调用一个子类中没有的函数的时候,就会去父类中找,然后呢在父类中调用f1函数用的是self,这里的self是实例化的对象,也就是说尽管调用的是父类的f1,但是obj是一个bar对象,所以self.f1()还是会call Bar中的f1对象,而不是父类中的
如果只有开头有双下划线 __function 而没有结尾,这通常是用于指示私有属性或方法。虽然 Python 中没有真正的私有属性或方法,但是以双下划线开头的属性或方法会被解释器修改名称,以避免与子类中的同名属性或方法冲突。
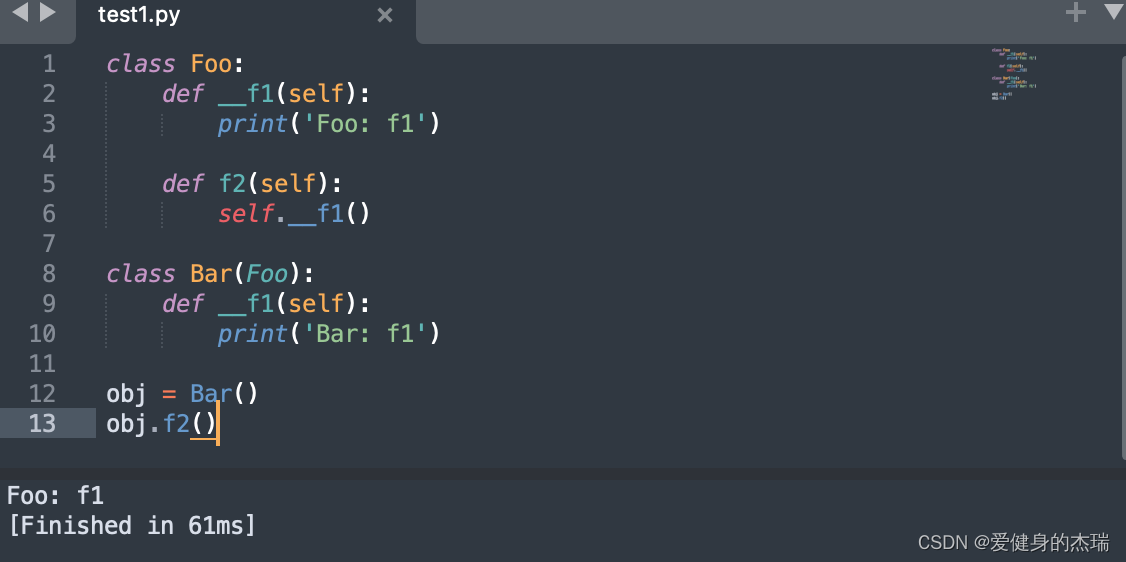
就像在这里,我们的私有方法是没办法在类外面进行访问的,所以当foo.f2被执行的时候, __f1( )所指的就是我们Foo中的私有函数__f1
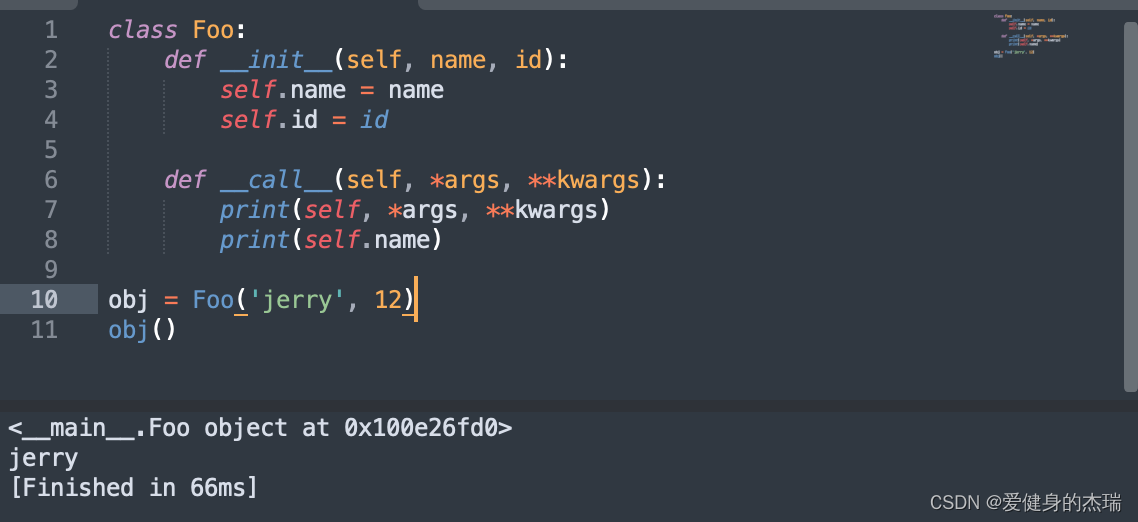
11. 对象实例化的调用
我们可以通过修改__call__这个内置函数来对一个实例化的对象进行调用
12. 单例模式
单例模式是一种设计模式,它确保类只有一个实例,并提供一个全局访问点来访问该实例。单例模式通常用于管理共享资源、数据库连接、配置对象等。
实现单例模式的方法通常包括:
1. **懒汉式**:在需要时才创建单例实例。这种方法可能会导致线程安全问题,因此需要进行适当的同步处理。
- class Singleton:
- __instance = None
-
- @classmethod
- def get_instance(cls):
- if cls.__instance is None:
- cls.__instance = Singleton()
- return cls.__instance
2. **饿汉式**:在类加载时就创建单例实例。这种方法在多线程环境下是线程安全的,但可能会浪费内存。
- class Singleton:
- __instance = Singleton()
-
- @classmethod
- def get_instance(cls):
- return cls.__instance
3. **基于装饰器**:使用装饰器来装饰类,使其只能有一个实例。
- def singleton(cls):
- instances = {}
-
- def get_instance(*args, **kwargs):
- if cls not in instances:
- instances[cls] = cls(*args, **kwargs)
- return instances[cls]
-
- return get_instance
-
- @singleton
- class MyClass:
- pass
无论使用哪种方法,单例模式都可以确保在应用程序的生命周期中,只有一个实例被创建并且可以被全局访问。
13. 深拷贝和浅拷贝
在python中我们列表本身的copy函数, list.copy( )和copy包中的copy.copy( ) 执行的都是浅拷贝,浅拷贝只成功”独立“拷贝了列表的外层,而列表的内层列表,还是共享的,这是因为,我们修改了嵌套的 list,修改外层元素,会修改它的引用,让它们指向别的位置,修改嵌套列表中的元素,列表的地址并未发生变化,指向的都是用一个位置。在浅拷贝中,其实如果我们用id() 来查看两个列表中每个元素单独的地址,你就会发现其实是一样的
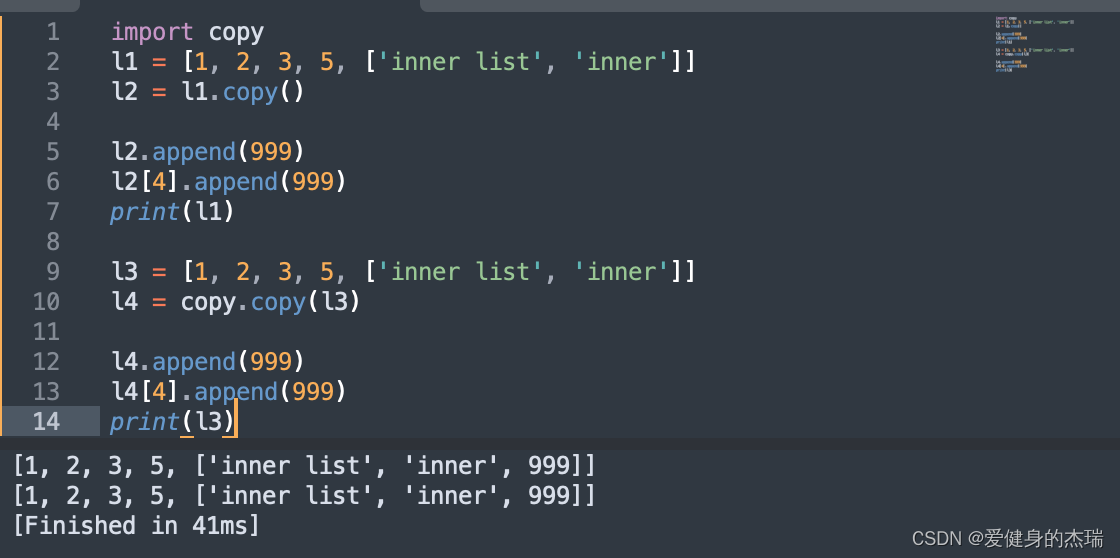
深拷贝使得两个列表完全独立开来,每一个列表的操作,都不会影响到另一个

14. __new__ 和 __init__ 的区别
`__new__` 和 `__init__` 都是 Python 中用于创建对象的特殊方法(也称为魔术方法或构造方法),它们在面向对象编程中起着不同的作用。
__new__` 方法:
- `__new__` 是一个静态方法(类方法),它在对象实际创建之前被调用。
- `__new__` 负责创建实例对象,并返回该实例对象。它是一个类级别的方法,因此它的第一个参数是类本身(通常命名为 `cls`)。
- `__new__` 方法在对象实例化时最先被调用,它负责分配内存空间、创建对象,并返回对象的引用。
- 通常情况下,你不需要直接调用 `__new__` 方法,因为 Python 会在调用 `__init__` 方法之前自动调用 `__new__` 方法来创建对象。
__init__` 方法:
- `__init__` 是一个实例方法,在对象创建后被调用,用于初始化对象的状态。
- `__init__` 方法可以接受额外的参数,用于初始化对象的属性。
- `__init__` 方法中通常包含初始化对象的代码,如给对象的属性赋值等。
- 当你使用类创建对象时,Python 会在调用 `__new__` 方法创建对象后立即调用 `__init__` 方法来初始化对象。
区别:
- `__new__` 是创建实例对象的方法,它负责分配内存空间并返回对象的引用,而 `__init__` 是初始化对象状态的方法,它负责给对象的属性赋初值。
- `__new__` 在对象实例化时调用,而 `__init__` 在对象初始化时调用。
- `__new__` 方法返回一个对象的引用,而 `__init__` 方法不返回任何值。
总而言之,`__new__` 和 `__init__` 在对象的创建和初始化过程中起着不同的作用,`__new__` 负责创建对象,而 `__init__` 负责初始化对象的属性。通常情况下,你只需要在需要特殊处理时重写 `__new__` 方法,而 `__init__` 方法则用于初始化对象的常规属性。
分配空间」是__new__ 方法,初始化是__init__方法
15. map( )函数返回的是一个迭代器iterator对象,需要用list( )来转换成列表
16. isinstance( ) 和 type( ) 的区别
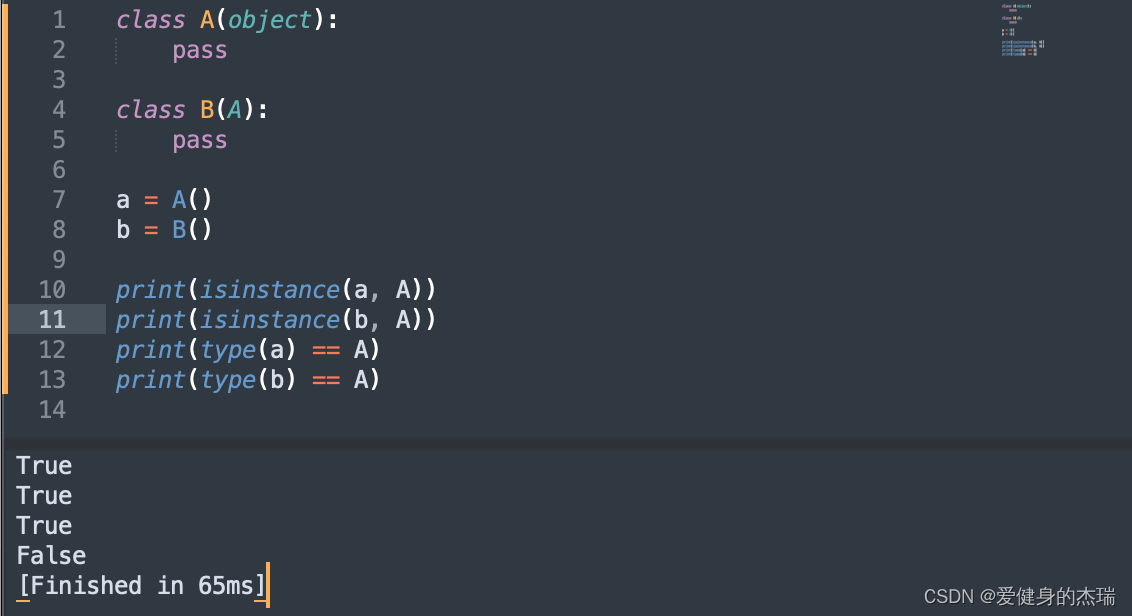
type() 不会认为子类是一种父类类型,不考虑继承关系
isinstance() 会认为子类是一种父类类型,考虑继承关系
17. Python常用的标准库
- os:提供不少于操作系统相关联的函数
- sys:提供了访问Python解释器相关信息的接口,比如命令行参数、标准输入输出等。通常用于命令行参数。
- datetime:日期时间
- re:正则匹配
- math:数学运算
- unitest:进行模块的单元测试
- random:提供生成伪随机数的函数
- threading:多线程编程相关功能
- time:提供了时间相关的函数和类,比如计时器
- json:提供对json数据的序列化反序列化操作
- socket:提供了网络编程相关的功能,比如创建 TCP/UDP 连接等。
- logging:提供了日志记录相关的功能。
18. 装饰器的使用场景
记录日志:装饰器可以用于记录函数的调用信息,包括输入参数和返回值。这对于调试和性能分析非常有用。
- def log(func):
- def wrapper(*args, **kwargs):
- print(f"Calling function {func.__name__}")
- result = func(*args, **kwargs)
- print(f"Function {func.__name__} returned {result}")
- return result
- return wrapper
-
- @log
- def add(a, b):
- return a + b
-
- add(1, 2) # 输出:Calling function add Function add returned 3
计时:装饰器可以用于测量函数的执行时间。这对于性能优化和代码分析很有帮助。
- import time
-
- def timer(func):
- def wrapper(*args, **kwargs):
- start_time = time.time()
- result = func(*args, **kwargs)
- end_time = time.time()
- print(f"Function {func.__name__} took {end_time - start_time} seconds to run")
- return result
- return wrapper
-
- @timer
- def fibonacci(n):
- if n <= 1:
- return n
- return fibonacci(n-1) + fibonacci(n-2)
-
- fibonacci(10) # 输出:Function fibonacci took 0.001234567 seconds to run

