
- 1一文梳理ChatTTS的进阶用法,手把手带你实现个性化配音,音色、语速、停顿,口语,全搞定_chattts参数
- 2售票系统设计_在web中,休克更新是什么
- 3消息中间件之 Rabbitmq 的下载安装和使用详细说明_rabbitmq 下载安装
- 4分布式对象池用哪些组件
- 5rabbitMQ对优先级队列的使用_java设置rabbitmq队列优先级
- 6阿里云同步gcr.io的镜像_使用阿里云同步gcr镜像
- 7最新AI提问不再难:“RBGR魔法公式”让你秒变提示词高手(2)
- 8【毕业设计/课程设计】基于SSM的汽车销售管理系统设计与实现(源码+文章) Java | JSP | MVC | Web_毕业论文 销售管理系统
- 9Qt小例子学习61 - 拖动显示显示图像/图标/数据_qt drop 显示图标
- 10PyTorch 框架的 Yolov5 移植_寒武纪yolov5移植
【机器学习】交叉熵做损失函数 BCE loss_bceloss损失函数
赞
踩
参考文章:
为什么用交叉熵做损失函数
详解机器学习中的熵、条件熵、相对熵和交叉熵
这边做摘抄
1.信息熵
信息熵是消除不确定性所需信息量的度量。(多看几遍这句话)
信息熵就是信息的不确定程度,信息熵越小,信息越确定。

(因为事件都有个概率分布,这里我们只考虑离散分布)
举个列子,比如说:
今年中国取消高考了,那我们就要去查证了,
这样就需要很多信息量(去查证);反之如果说今年正常高考,大家回想:这很正常啊,不怎么需要查证,这样需要的信息量就很小。
从这里我们可以学到:根据信息的真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性,即最小信息熵。
简而言之概率越低,需要越多的信息去验证
所以验证真假需要的信息量和概率成反比。我们需要用数学表达式把它描述出来,推导:
设一个离散的随机变量为 x,已知信息的量度依赖于概率分布 p(x),因此我们想要寻找一个函数I(x),它是概率 p(x)的单调函数,表示信息量。
若有两个不相关的事件x和y,则观察两个事件同时发生时获得的信息量应该等于观察到事件各自发生时获得的信息之和:
I(x,y) = I(x)+I(y)
而两个事件是独立不相关的,所以
p(x,y) = p(x)p(y)
易得
I(x)与p(x)之间有对数关系
log(p(x)p(y)) = log(p(x))+log(p(y))
即I(x) = -log(p(x))
其中负号是用来保证信息量是正数或者零
I(x) 也被称为随机变量 x 的自信息 (self-information),描述的是随机变量的某个事件发生所带来的信息量。图像如图:

假设一个发送者想传送一个随机变量的值给接收者。那么在这个过程中,他们传输的平均信息量可以通过求 I(x)=−logp(x) 关于概率分布 p(x) 的期望得到,其中n 为事件的所有可能性即:
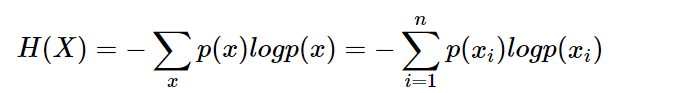
H(X) 就被称为随机变量 x 的熵,它是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望
2.相对熵(KL散度)
相对熵又称KL散度,如果对于同一个随机变量xx有两个单独的概率分布p(x)和 q(x) ,可以使用相对熵来衡量这两个分布的差异。
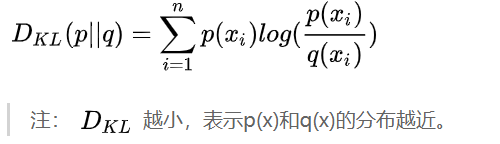
3.交叉熵

在机器学习中,往往用p(x)用来描述真实分布, q(x)用来描述模型预测的分布。
所以 相对熵 = 交叉熵-信息熵
由于信息熵描述的是消除 p (即真实分布) 的不确定性所需信息量的度量,所以其值应该是最小的、固定的。
那么:优化减小相对熵也就是优化交叉熵,所以在机器学习中使用交叉熵就可以了。
使用交叉熵的原因
模型在训练数据上学到的预测数据分布与真实数据分布越相近越好
此处真实数据分布指的就是训练数据的分布(标注)。
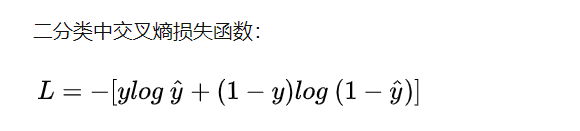
交叉熵损失函数一般用来代替均方差损失函数与sigmoid激活函数组合。



:均方差对参数的偏导的结果都乘了sigmoid的导数
而sigmoid的导数 其变量值很大或很小时趋近于0,所以偏导数很有可能接近于0。

由参数更新公式:参数=参数-学习率×损失函数对参数的偏导
偏导很小时,参数更新速度会变得很慢,而当偏导接近于0时,参数几乎就不更新了。
反观交叉熵对参数的偏导就没有sigmoid导数,所以不存在这个问题。这就是选择交叉熵而不选择均方差的原因。

