
- 1加密算法之安全hash算法、RSA非对称加密算法分析_rsa hash
- 2解决在CMD和Powershell中无法使用bash或sh指令运行.sh文件的问题_powershell sh
- 3maven中setting的配置方法_设置maven依赖和setting
- 4学习被动引流的3个关键技巧_关键词被动引流的玩法
- 5神经网络算法:一文搞懂GPT(Generative Pre-trained Transformer)
- 6力扣(LeetCode)175. 组合两个表(2022.06.24)_力扣175
- 7深度学习和神经网络_深度学习之神经网络基础(前馈神经网络)
- 8机器人工具箱基本使用(二)_robot.plot
- 9CyberVadis评估!
- 10AI数字人应该怎么制作?详细教程_ai数字人制作教程
基于NL2SQL的兵棋数据智能统计分析方法研究_vanna nl2sql
赞
踩
源自:系统仿真学报 作者:殷来祥 李志强 付琼莹
“人工智能技术与咨询”发布
摘 要
面对海量的兵棋数据,传统界面查询的方式已经无法满足指挥员快速、全面、精准查询数据的要求。通过深入分析兵棋数据特点与主流NL2SQL(natural language to struct query language)模型的缺陷,提出了一套适合兵棋数据智能统计查询的解决方案。针对领域数据集缺乏,提出了一套基于人机协助、动态迭代的兵棋数据集构建方案;针对兵棋查询问句时间敏感的问题,提出了一套“规则+深度学习”的时间表达式识别与规范方法;针对兵棋数据量大提取查询值困难的问题,修改完善了Bridge模型的值提取与SQL生成架构。综合运用以上方案,使兵棋数据查询的精准匹配准确率达到75%以上。
关键词
兵棋;NL2SQL;数据集;时间处理;统计查询
引 言
目前,基于传统查询界面的兵棋统计查询系统已基本满足了指挥员对兵棋数据统计分析的需求,但在使用过程中面临2个突出问题:①界面固化、查询内容受限,指挥员只能检索特定的查询内容,其他查询需要专业分析人员从数据中捞取;②操作复杂、人机交互不友好,指挥员需要反复切换查询界面获取所需数据,并且数据以整个页面的形式返回,而非仅呈现用户关注的数据。
针对以上问题,本文提出一套基于NL2SQL(natural language to struct query language)的兵棋数据智能统计分析方法。指挥员可以运用自然语言直接查询分析兵棋推演生成的评估分析主题数据库,并精准高效的返回分析结果。既可省去人工构建结构化查询语言的繁琐过程,又可精准返回指挥员关注的内容,进一步提升指挥员信息获取效率、降低指挥员认知负担,提高指挥决策效率与准确度。该系统具有很强的泛化性,可广泛应用于以关系型数据库为存储结构的业务软件,如联合作战指挥信息系统、联合作战指挥训练系统等。
1 NL2SQL简介及应用难点
1.1 NL2SQL简介
NL2SQL是指在给定数据库和自然问句的条件下,将自然问句解析成SQL语句,并执行SQL语句返回查询结果的技术。NL2SQL研究由来已久,20世纪70年代,美国就研究出了基于规则的NL2SQL系统,如Luar、Baseball等[1]。其可以通过格式化的自然语言查询数据库返回检索结果,但功能相对简单。由于自然语言的多变性、复杂性以及当时的技术水平,相关研究并未取得实质性突破。近年来,随着深度学习技术在机器翻译、语音识别等领域取得巨大成就,特别是NL2SQL数据集的发布,将NL2SQL研究推向了一个新的高度,成为自然语言解析领域的热点[2]。
目前,NL2SQL的主要任务分为单表查询和多表查询两种。单表查询任务的代表数据集有Wikisql[3]、TableQA[4](中文),其对应的SQL语句相对比较简单。2019年,模型在2个数据集上的精度均已经超过普通人类的水平。当前,NL2SQL研究主要集中在多表查询任务上。多表查询任务的代表数据集有Spider[5]、DuSQL[6](中文),现主要研究集中在Spider数据集上进行,关于中文多表查询任务的研究相对较少。截止发文,Spider数据集上最佳模型PICARD[7]的执行精度已经达到75.1%。
1.2 NL2SQL应用难点
尽管近年来NL2SQL技术取得了巨大的进展,但其距实际的兵棋统计查询应用还有较大的差距,突出表现在以下3个方面:
(1) 现有数据集存在与实际应用不符的情况。以最为流行的多表跨领域数据集Spider为例,数据集定义时明确要求:问句必须清晰明确,且必须包含查询结果的全部信息,不能包含需要特定数据库之外的常识信息。现实的兵棋查询问句远比这些复杂,指挥员问句简短精炼,字面信息较少但内含深刻,同时问句中包含大量常识信息。如数据库可能未直接给出战损数据,但根据常识“战损数=初始数―现有数”可以得出答案。直接将公开数据集训练的模型迁移至兵棋领域会产生大量的偏差,需要利用兵棋领域数据集对已训练好的模型进行微调,使其达到较高的精度。
(2) 现有模型对时间信息处理能力不足。兵棋查询问句中包含大量的时间信息,如“当前阶段,红方共消耗多少枚弹药?”。虽未明确出现时间表达式,但其蕴含着重要的时间信息。如果不能准确识别时间信息,将不可能得到准确的答案。首先要根据作战时间推算出当前的阶段,而后再将当前阶段映射成标准的时间格式。此外,兵棋查询问句还包括物理时间、作战时间两类时间,形式非常相似,现有模型很难进行区分,需要提出针对性的时间解决策略。
(3) 现有模型确定Where条件中Value值的方式无法推广至兵棋领域。Guo等[8]通过预训练模型BERT(bidirectional encoder representation from transformers)识别自然语言问句与数据表列中所有值的注意力分数,从而确定Value值,该方法只能适用于数据库数据极少的Spider数据集。现实兵棋数据库中数据动辄上百万条,无法将该方法应用于兵棋查询。
2 基于NL2SQL兵棋数据智能统计分析基本结构
基于NL2SQL兵棋数据智能统计分析基本结构主要包括问句预处理模块、NL2SQL模块和SQL执行模块3部分,其基本结构如图1所示。对于输入的指挥员问句,首先通过问句预处理模块,将其处理为规范化问句;而后通过NL2SQL模块,将规范化问句解析成SQL语句;最后,通过SQL执行器执行SQL问句,返回查询结果。
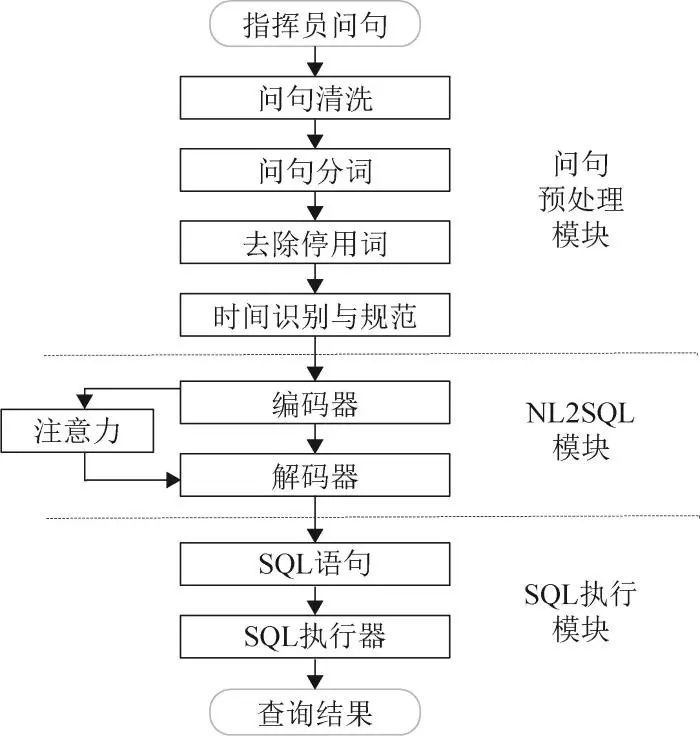
图1 兵棋数据智能统计分析基本结构
问句预处理模块,主要将指挥员输入的含糊不清、指代不明的自然问句转化为更适合模型处理的规范化问句,以降低自然语言解析难度。其主要包括问句清洗、问句分词、去除停用词、时间识别与规范等4项内容。前3项内容作为智能问答的基础性工作,许多中文NLP工具可以实现以上功能,如Jieba、TLP、LAC等,且准确率可达90%以上[9],文中不再赘述。
兵棋智能统计查询不同于一般的智能问答,问句解析对时间信息特别敏感。以问句“火力急袭阶段,红方共消耗精确弹药多少发?”为例,若不能有效处理时间表达式“火力急袭阶段”,并将其转化为标准化的时间表达式“20XX年X月X日XX时XX分——20XX年X月X日XX时XX分”,将无法准确完成问句解析任务。针对兵棋问句中时间表达式的识别与规范,本文提出了基于“规则+深度学习”的处理方法。
NL2SQL模块,主要将规范化的指挥员问句转化为标准的SQL语句,是兵棋数据智能统计分析的核心模块。针对兵棋统计分析特点,本文提出了基于改进Bridge模型的兵棋问句解析模型,模型采用经典的编码、解码结构,通过添加注意力机制利用有限的注意力资源从大量信息中快速筛选出高价值的信息。同时,针对模型训练缺乏兵棋领域NL2SQL数据集的问题,本文提出了一种基于人机协助、动态迭代更新的兵棋数据集构建方法。
SQL执行模块,主要负责执行SQL语句返回问句答案。目前,市面上有大量成熟的SQL执行软件、模块,可直接调用,在此不做赘述。
3 兵棋领域数据集构建
兵棋领域问句具有专有词汇多、隐含条件较多、问句简短精炼等特点,在通用跨领域数据集(DuSQL、Spider等)训练出的NL2SQL模型无法很好的应用于兵棋数据查询,普遍存在查询精度不高的问题。为解决此问题,需要构建兵棋专用数据集(BqSQL),微调在通用跨领域数据集中训练出的模型,以提高兵棋数据查询的准确率。
3.1 数据集构建基本思想
数据集的样本数量将直接影响着模型的效果。然而,常规构建NL2SQL领域数据集的方法需要大量了解兵棋数据结构和熟练掌握SQL技能的专家,人力成本巨大。为解决这一难题,借鉴现代软件“快速上线、逐步完善、迭代升级”的敏捷开发思想,提出了一种人机结合的迭代式数据集构建方法。将数据集的构建分为两个阶段:第一阶段,通过专家标注和模板生成的方式,构建初始数据集;第二阶段,通过运行兵棋NL2SQL原型系统,在使用过程中记录用户反馈,通过用户反馈升级完善数据集。
3.2 初始数据集构建
初始数据集的构建主要采取2种方式:①通过领域专家直接标注的方式;②通过人机协助生成的方式。领域专家标注的数据集主要用于模型测试,人机协作生成的数据集主要用于模型微调训练,其比例为1:9。初始数据集构建的基本处理流程如图2所示。
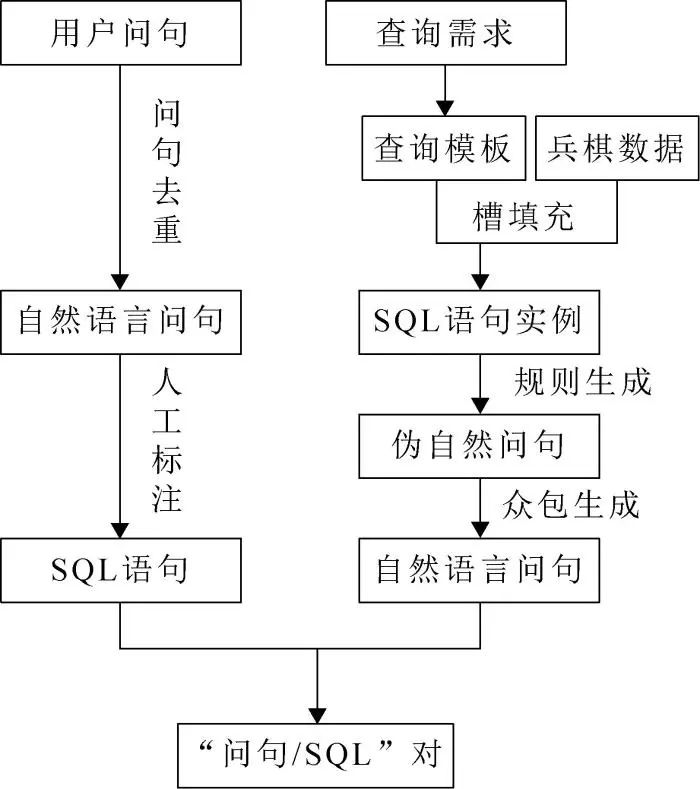
图2 NL2SQL初始数据集构建流程图
专家标注的方式。通过专家访谈、问卷调查、实地调研等形式,搜集汇总指挥员、评估人员等对于兵棋数据查询的基本需求及常用的兵棋查询问句。对收集的兵棋查询问句进行相似性和准确性检测,剔除重复、模糊、无意义的兵棋查询问句,邀请对兵棋数据库熟悉的技术专家将兵棋查询问句解析为对应的SQL语句。该数据集整体质量较高,能够准确反映指挥员、评估人员在使用系统过程中的真实情况。本文将该部分由专家标注的数据集作为测试集,主要用于评估模型的准确率。
人机协助的方式。通过专家标注的方式虽然贴近实际、准确度高,但其非常依赖精通兵棋数据库的技术专家,耗时耗力且生成SQL语句时极易出错,不便于大量标注样本数据。在充分借鉴了百度DuSQL[6]数据集构建方案基础上,提出了一种基于人机协助的兵棋NL2SQL数据集构建方案,其基本流程如图3所示。首先,由领域专家研究分析指挥员对兵棋数据的查询需求,构建不依赖查询数值的模板;而后,将查询模板槽位与数据库链接产生大量的SQL查询实例,生成大量与SQL实例相对应的伪问句;最后,通过众包的方式将伪问句转化为兵棋查询问句。
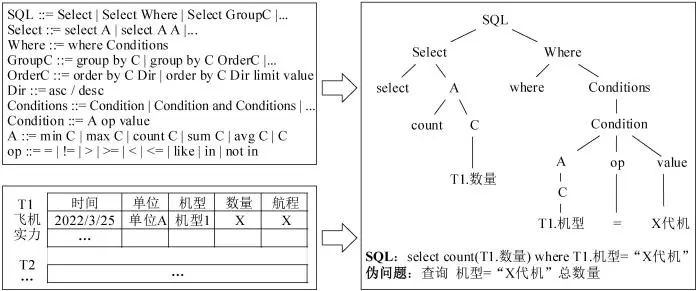
图3 基于人机协助的数据集构建方法
如图3所示,SQL语句可以被表示成基于规则结构的语法树{Select = select A,select A A,⋯⋯,Where = where Conditions,⋯⋯}。以上模板是基于语法规则产生的,在实际的使用过程中还需服从指挥员问句分布,确保生成具有明确军事含义的SQL查询问句。例如,查询问句中分类操作GroupC主要通过时间、空间、装备类型、力量等字段进行分类;字段的聚类操作,主要针对射程、数量、编制数等数值型字段进行聚类;选择字段时,如查询部队、装备位置时必须同时选择经、纬度字段等等。通过一系列规则,确保生成涵盖绝大多数查询、军事意义明确的SQL查询语句。
为保证NL2SQL数据集的质量,本文基于以下两种标准自动检测低质量“自然语言问句/SQL”对。①重叠度,为了保证问句的自然性,通过字符串匹配度方式计算伪问题与自然问句的重叠度,如果重叠度高于0.6的问题被认为是低质量的问题;②相似性,为确保自然问句中包含了足够的SQL查询信息,本文训练了一个“自然语言问句/SQL”的相似度模型,如果问句相似度低于0.7的问题则认为是低质量的问题。
3.3 动态升级完善数据集
通过专家标注与模板生成的方式,本文已经构建了3 000条样本数据。通过兵棋初始数据集微调利用通用数据集训练好的NL2SQL模型,模型精度可以达到75%以上,初步具备了上线应用的条件。将该原型系统集成至兵棋战况统计查询系统,作为系统的附加功能,供指挥员使用。使用过程中,原型系统可以自动记录用户的查询问句,并邀请用户对查询准确性进行评估价。对于用户反馈查询结果准确的问句,通过数据校核后添加至初始数据集;对于用户反馈查询结果不准确的问句,通过人工标注的方式将其解析成SQL语句,经数据校核后再添加至初始数据集。通过用户的不断使用、反馈,数据集将不断迭代更新,进一步提高数据集质量、扩大数据集体量,促进模型准确度的提高。
4 时间表达式识别与规范方法
时间表达式是一种特殊的实体,蕴含着大量问句查询的关键信息,准确识别与规范处理时间表达式对于提高NL2SQL的准确率大有裨益,特别是对于时间准确度要求比较高的兵棋数据查询领域。
4.1 时间表达式识别
时间表达式通常可分为简单时间表达式、复杂时间表达式、偏移时间表达式和特殊时间表达式[10]。对于时间表达式的识别,本文采取命名实体识别与规则匹配的方式。命名实体识别是自然语言处理的一项基础性内容,其目的是准确识别语料中的人名、地名、日期、组织机构、专有名词等命名实体。
经过几十年的发展,中文命名实体识别已经非常成熟,准确率也比较好。以百度LAC开源工具为例,其命名识别综合准确率已经达到95.5%。可以较好满足对时间实体的识别。同时,由于兵棋领域的特殊性,普通的命名实体工具可能无法识别特殊时间实体,如“火力急袭击阶段”“抢滩登陆阶段”等,大部分命名实体工具会将其识别为名词。对于具有特殊含义的时间表达式,本文采取枚举法,看问句中是否包含相应的特殊表达式,将其识别为时间实体。
4.2 时间表达式规范
时间表达式规范是指将识别出的时间表达式赋予一个标准格式,以便于计算机进行处理,为后续的应用提供支持。如将“八月十五日”转化为标准格式“2022-08-15”。通常,在确定基准时间的基础上对时间表达式进行规范化处理。
4.2.1 基准时间确定
指挥员问句中的时间表达方式有时以相对时间来表示,如“昨天”“上一阶段”等。尽管可以通过命名实体识别工具识别出时间实体,但若没有基准时间也无法推算出具体的时间信息。在兵棋智能查询过程中,绝大多数情况下以当前时间作为基准时间。但与普通的智能问答不同,兵棋系统中有两个当前时间,分别为物理时间和作战时间。兵棋系统是对未来特定作战场景的模拟,其各种推演假设也基于未来作战场景展开,其依据的时间更多是作战仿真时间。例如,上一阶段,我军共消耗精确弹药多少枚?“上一阶段”指的是作战过程的上一阶段,当前作战时间可以直接从仿真系统中获得。算法在处理指挥员问句时,会以作战时间作为基准时间。但如果问句中识别出一个明确含义的物理时间信息,则以物理时间为基准时间。
4.2.2 时间规范化过程
时间规范化过程主要包括:特殊时间表达式规范化,简单时间、复杂时间规范化,偏移时间规范化等3步。
特殊时间表达式规范化,主要处理类似于“火力急袭击阶段”“抢滩登陆阶段”等蕴含特殊时间信息的字符串。该类型的字符串在没有明确背景知识的条件下很难获得其蕴含的信息。该实体数量相对较少,可以直接采取枚举的方式进行规范化。当时间命名实体识别到该类时间表达式时,通过字符串模糊匹配的方式匹配预存于系统中的特殊时间表达式字段,将其转换成标准时间。如“火力急袭击阶段”规范化为“20XX年XX月XX日XX时XX分——20XX年XX月XX日XX时XX分”。
简单时间、复杂时间规范化,主要处理相对标准的时间表达式,如“22年4月”“二零二二年四月一日”等。该类信息具有明显的特征,并且带有数量词及时间单位,主要通过正则表达式方式将其转化为标准格式。
偏移时间规范化,主要处理具有偏移信息的时间表达式,通常由一个时间段加方位词构成。当未出现明显时间段信息时,以作战时间作为基准时间,在此基础上加减偏移时间得到规范化时间。
简单时间、复杂时间、偏移时间规范化主要采取正则表达式转化的方式,其正则表达式可参见文献[11]。
5 自然语言问句解析模型
5.1 问题定义
NL2SQL是指对于给定的自然问句Q和数据库S,将自然语言问句Q生成对应的SQL语句P,即<Q,S>→P。自然问句Q={q1,q2,⋯,qM}是由一系列子词组成的序列,qi 为问句的第i个子词,M为子词数量。数据库S由表T={t1,t2,…,tN }和字段C={c1,⋯,c1|t1|,⋯,cN|1|,⋯,cN|tN|}构成。其中,ti 为数据库中第i个表,N为数据库表的数量,|tN|为第N个数据表字段数量。每个表ti 和每个字段ci 都有一个对应的文本名称。字段ci 区分主键和外键,主键用于对每个数据记录进行唯一索引,外键用于引用不同表中的主键。除此之外,数据库中的每个字段还有不同的数值类型τ∈{number,text,}。
5.2 模型构建
关于模型构建,主要借鉴了文献[12]提出的Bridge模型[12]。主要基于以下2点考虑:①其首次提出“桥接”的思想,可以较好解决问句与数据列表匹配问题;②模型准确率高且相对简单,更适合工业化运用。在使用过程中针对兵棋数据查询对模型值匹配与解码层进行了优化。
5.2.1 编码层
大部分前期研究仅考虑数据Schema与自然语言问句的关系,将其作为输入预测SQL问句,并未考虑数据库的内容。近期研究表明,添加数据库内容信息可以明显增强预测的准确性[13]。单纯从数据库Schema中无法判断X代机属于哪个字段,需要结合数据库内容进行判断。同时,实际使用过程中,需要对飞机进行多标签分类,其分类维度表述不清,导致模型很难识别出正确的列。因此,在模型编码时,将数据库Schema、数据库部分字段值、自然问句同时进行编码。其编码过程如图4所示。
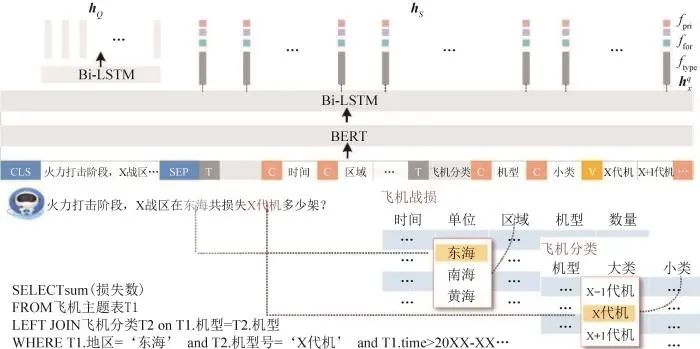
图4 NL2SQL模型编码示意图
对于数据库信息,用表、字段、值分别表示,在每个表之前加上特殊标记[T],在每个字段之前添加特殊标记[C],在字段值前边添加特殊标记[V]。将多个表的信息连接起来,就得到的数据库的序列化表示。最后按照BERT-wmm的输入模式,在问题前加上[CLS],在问题与数据库信息之间加入[SEP]就获得了“问题—数据库”信息的序列化表示X。
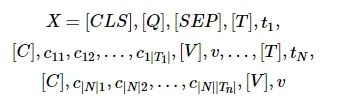
(1)
对于原始序列X,首先通过Huggingface提供的Transformer模块得到BERT-wmm的输入表示。而后,借助BERT-wmm的12层Transformer结构充分学习每个词之间语义关联,最终得到输入文本的上下文表示。而后,再输入Bi-LSTM进一步加强单词之间的上下文表示得到 hX。对于问题部分,本文再将其输入Bi-LSTM得到问题的编码HQ。对于数据库部分本文首先将数据库的Schema信息融入,再将其输入Bi-LSTM得到数据库的编码 hS。
为能够更加稠密的表示数据表信息,设计了一个融合Schema信息的字段表示模型。其包含了数据表字段的主键(fpri)、外键(ffor)、数值类型(ftype)信息。通过前馈神经网络,将数据库Schema信息与字段文本信息融合为一个稠密的数据编码表示。其实现方式为
![]()
(2)
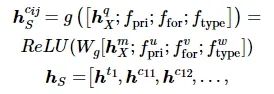
(3)
![]()
(4)
式中:g为前馈神经网络;p为与之相关的表ti 在原始输入X中的索引;q表示与之相关的字段cij在原始输入X中的索引;u、v、w分别为该字段主键、外键、类型的特征指标;|T|为数据库中所具有表的数量;|N|、|M|分别为对应表中所有字段的数量。因表ti 不具有主、外键等属性,为便于处理,对相应的位置用0进行填充。
5.2.2 基于词向量余弦算法的值匹配
原Bridge模型中采取字符串模糊匹配的方式匹配数据库值内容存在2个不足:①无法匹配表达形式不同但内涵一致的词,如“F22”与“猛禽”;②不便于并行高效计算,字符串匹配主要运行在CPU上,无法充分发挥GPU并行计算优势。
本模型改用词向量余弦算法实现值匹配,一是可以实现语义级的匹配,避免出现因表达形式不同而无法匹配的问题;二是可以利用faiss库[14]实现快速匹配,faiss是FaceBook的AI团队针对大规模相似度检索问题开发的一个工具,对10亿量级的索引可以做到毫秒级检索,并支持GPU加速。
对于输入的兵棋查询问句,首先利用中文分词工具LAC进行分词和序列标注,得到分词序列和词性表示。考虑到时间、数字信息定义相对比较清晰,且在字段原数据编码过程中已将其融入。为降低模型复杂度,提高运行速率,忽略查询问句中数字、时间词与数据库中字段属性为{time、number、bool}的匹配。对于查询问句和数据库中文本类的词,首先利用word2vec[15]将其转化为低维稠密向量,而后再利用faiss库快速计算其相似度。对于相似度高于70%匹配值进行排序,选取前2名作为字段值。如果无相似度大于70%的匹配值,则不考虑加入。
5.2.3 解码层
本文采用基于多头注意力的LSTM指针生成网络作为模型的解码器。将编码器的最后一层状态 ht 及基于多头注意力机制的上下文 Ct 作为解码器的输入。在每一个步骤中,模型执行以下操作:从字典表中生成一个token或者从问题编码中复制一个token作为解码输入。
关于基于多头注意力机制的上下文 Ct 的计算,本文采用Vaswani等[16]提出的多头注意力机制计算方法。在每一步t,对于给定的解码状态 St 和编码状态[ hQ,hS ],则Ct 的计算公式为
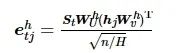
(5)
![]()
(6)
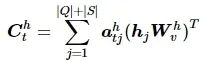
(7)
![]()
(8)
式中:h∈[1,2,…,H] 表示多头注意机制中注意力头的序号,H为注意力头的总数;j∈[1,2,…,|Q|+|S|] 表示编码层输入序列的序号,|Q|+|S| 为总的输入序列的token个数。
将样本集出现的词汇、数据库中的词汇与原词词汇表的并集作为模型的扩展词汇表V,从字典表V中生成词汇的概率为
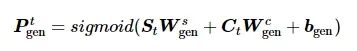
(9)
则在当前词汇表的分布为
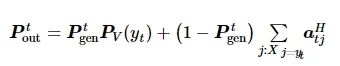
(10)
式中:PV(yt) 为LSTM的softmax的输出分布;X表示输入编码序列中的所有词汇。
通过指针生成网络,一定程度解决了生成where中值信息不准确以及问句中未登录词对自然语言解析的影响[17]。利用指针生成网络的复制功能,可以将问句编码中[V]中的值准确复制到SQL语句中,保证生成值信息的准确性;同时,当自然语言问句与数据库进行字符串匹配无法产生[V]信息时,利用指针生成网络中生成功能,生成对应的where值信息。
6 实验结果分析
6.1 数据集
实验中,主要采取2种数据集来测试模型的精度,分别是DuSQL、BqSQL。DuSQL是2020年百度公司Wang等推出的一个大型中文跨领域多表查询数据集,该数据集包含200个数据库、813个表、23 797个“自然问句/SQL”对。DuSQL是一个融入先验知识的数据集,含有部分涉及行或列计算的SQL查询,一些计算行列是在数据集中不存在的,需要依据常识进行推理得到。BqSQL是针对兵棋数据查询领域创建的单领域多表查询数据集,包含3 000条“自然问句/SQL”对,主要对模型进行微调,以提高模型的准确度。实验中,按照8:1:1的比例划分训练集、验证集、测试集。
6.2 实验环境及评价标准
实验在Ubuntu 22.04上进行,CPU为Intel 10105f,GPU为RTX3090,内存大小32 G,编程语言为Python 3.8,深度学习框架为Pytorch 1.10,模型主要参数如表1所示。
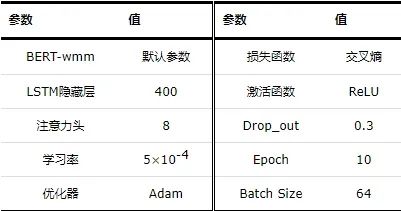
表1 模型主要参数
按照文献[18]的标准,实验采用精准匹配准确率对模型进行评估,即预测SQL与标准SQL语句相等的问题占比。在评测过程中,不考虑列名出现的顺序对于精准匹配准确率的影响。计算公式为
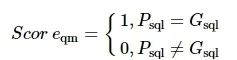
(11)
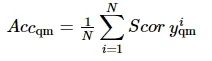
(12)
式中:Accqm为精准匹配准确率;N为自然语言问句数量;Psql、Gsql分别为预测的SQL语句与标准的SQL语句。
6.3 对比实验
为充分利用公开数据,同时检验本文模型的效果。本文首先利用公开数据集训练Bridge模型和本文模型,而后将训练好的模型直接迁移至兵棋数据查询领域,检验训练好的模型在兵棋数据集中的效果。模型在DuSQL、BqSQL测试集上的精准匹配准确率如表2所示。
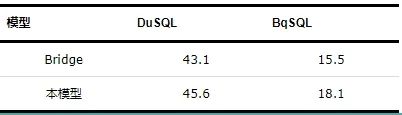
表2 模型在DuSQL、BqSQL数据集上的准确率 (%)
不难发现,尽管DuSQL数据集是跨领领域数据集,训练集与测试集属于不同的数据库,具有一定的泛化性,但直接将训练好的模型应用于兵棋领域,会导致模型精度的大幅下降。
本文采用2种方式训练本模型:①直接利用BqSQL数据集训练本模型;②首先利用公开数据集DuSQL训练本模型,而后再利用BqSQL数据集进行微调。2种训练方式在BqSQL数据集上的精准匹配准确率如表3所示。
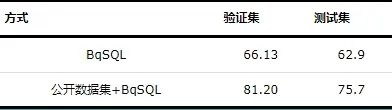
表3 模型在BqSQL数据集上的准确率 (%)
实验发现,直接利用兵棋数据训练本模型,由于样本量过少,导致模型训练不充分,模型泛化能力弱且准确度低。通过利用大量公开数据集训练本模型,再用兵棋数据进一步微调模型,可有效缓解兵棋领域数据集样本量少和公开数据集领域泛化能力不强的问题,可有效提高模型的准确率。
6.4 消融实验
本文通过对模型进行消融实验,进一步查看各模块对于模型精度的影响。首先,将不采用时间规范模块和值匹配模块的模型作为基础模型进行训练,评估基础模型的准确率;而后在基础模型上添加时间处理模块进行训练,评估模型的准确率;最后在基础模型上添加值匹配模块进行训练,评估模型的准确率。消融实验的结果如表4所示。
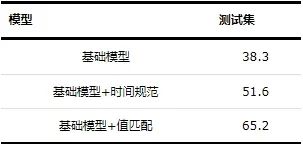
表4 消融实验实验结果 (%)
通过消融实验可以看出,基础模型在BqSQL数据集上的精度非常低,仅有38.3%,添加时间处理模块与值匹配模块均能够明显提高模型精度。通过添加时间处理模块使模型精准匹配准确率提高了13.3%,主要原因是查询问句中存在许多特殊时间实体,如“火力急袭击阶段”“抢滩登陆阶段”等,一般模型无法处理需该时间表达式,导致时间信息提取错误。通过添加值匹配模块使模型精准匹配准确率提高了26.9%,主要原因是兵棋数据库字段含义比较抽象,特别是多维度切分时,不依靠字段值内容很难准确匹配数据库字段。消融结果表明针对数据解释性差且问句包含大量时间信息的兵棋查询任务,通过问句时间信息规范化处理与问句与数据库进行值匹配能显著提升兵棋NL2SQL的准确率。
7 结论
本文主要研究了兵棋数据查询领域的NL2SQL工业应用,针对当前主流模型迁移至兵棋领域存在的诸多问题提出了一整套解决方案。首先,提出了基于人机协助、快速迭代更新的兵棋领域NL2SQL数据集构建方案,有效解决了数据集构建困难、领域数据集缺乏的问题,通过兵棋领域数据集微调模型的方式,提高了模型的准确度;其次,针对时间实体对查询精度影响较大的问题,提出了基于“深度学习+模板”的时间实体识别与规范化策略,提升了模型处理时间表达式的能力;最后,针对Value值识别困难与不准确的问题,对Bridge模型的值链接模块和解码过程的值生成进行了优化,提高了值识别与问句生成的准确率。在实际运用过程中,指挥员查询问句中有时包含明确上下文信息,依靠单条问句无法准确理解问句的含义。在未来的工作中,考虑采用多轮问答的方式实现基于自然语言的兵棋数据统计查询工作,提高兵棋查询问句解析的准确率。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询”发布

