
- 1基于一体化有序信息和事件关系的脚本事件预测_事件关系脚本学习
- 2idea git 合并多个commit_idea git合并多个commit
- 3关于def __init__(self)_def --init--
- 4字节跳动的真实工作体验_字节跳动稳定吗
- 5华为HCIP-Datacom认证题库(H12-821)_mqc与pbr一样,只能在设备的三层接口下调用
- 60.1## 梯度下降的优化算法,SGD中的momentum冲量的理解_sgd momentum如何取值
- 7将本地项目上传到GitHub_添加本地git代码到sourcetree
- 8基于Python+Django+Vue+Mysql前后端分离的图书管理系统_djangovue前后端分离图书馆
- 9基于JSP的图书销售管理系统_jsp 图书信息管理 博客
- 10Linux系统Docker部署DbGate并结合内网穿透实现公网管理本地数据库_docker安装基于web的数据库管理工具_dbgate docker
GitHub免费提供机器学习扫描代码漏洞,现已支持JavaScript/TypeScript
赞
踩
晓查 发自 凹非寺
量子位 | 公众号 QbitAI
今天,GitHub更新一项实验版新功能。
用上机器学习后,新版CodeQL代码扫描服务可以帮开发者发现更多安全漏洞。
目前在JavaScript和TypeScript存储库上开发测试,以后会逐步增加各种语言支持。
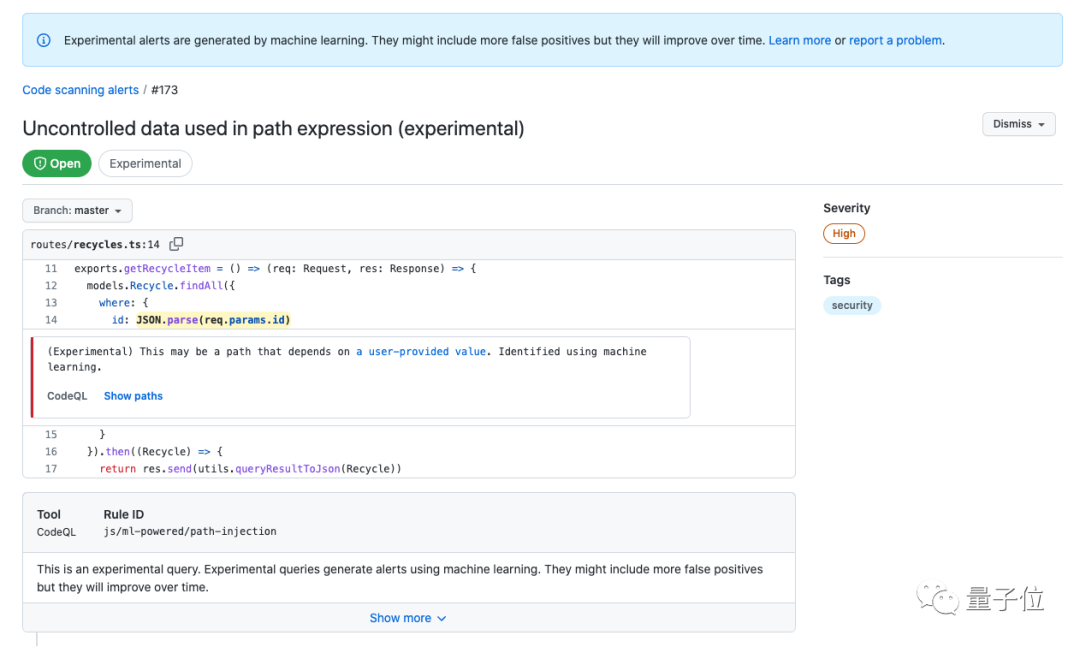
在测试期间,CodeQL已经从12,000个存储库中发现了超过20,000个安全问题,包括远程代码执行(RCE)、SQL 注入和跨站脚本(XSS)漏洞。
如何使用
GitHub的CodeQL代码扫描对于公共存储库是免费的。
目前,新的JavaScript/TypeScript分析工具,已向security-extended和security-and-quality分析套件的所有用户推出。
如果你已经在使用这些套件,那么将自动使用新的机器学习技术进行分析。
如果你之前没使用过,可按照以下步骤启用CodeQL。
1、在你的存储库主页下,单击Security。

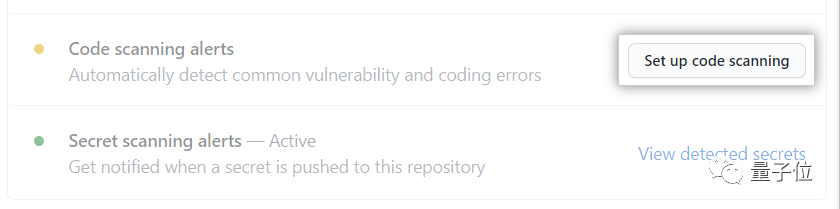
3、在Code scanning alerts右侧,点击Set up code scanning。如果缺少这一项,需要由存储库管理员启用GitHub高级安全性。
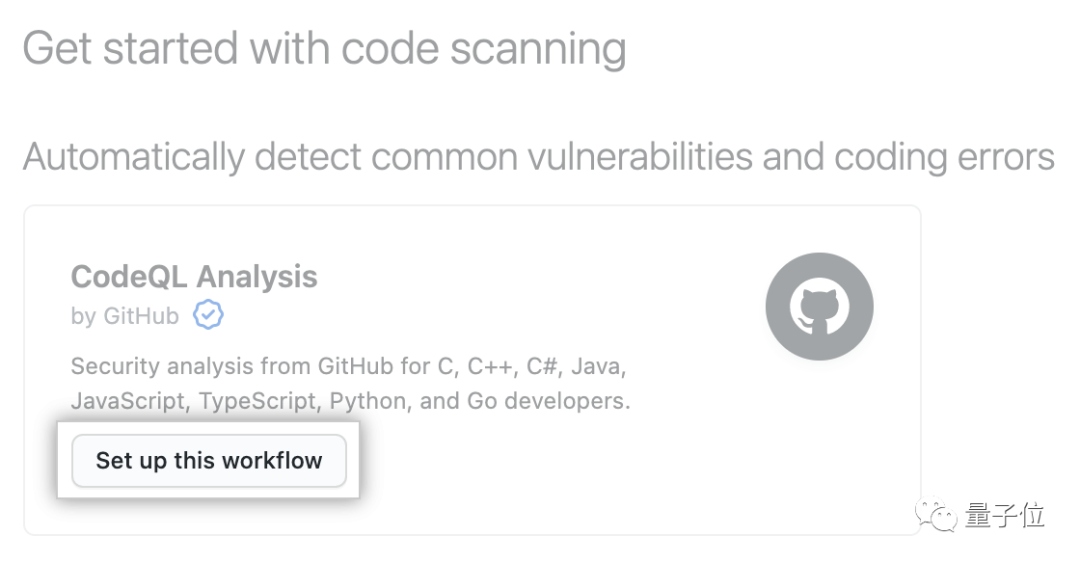
4、在“Get started with code scanning”下,单击在CodeQL Analysis中的Set up this workflow。
5、使用Start commit下拉菜单,输入文件名并提交。
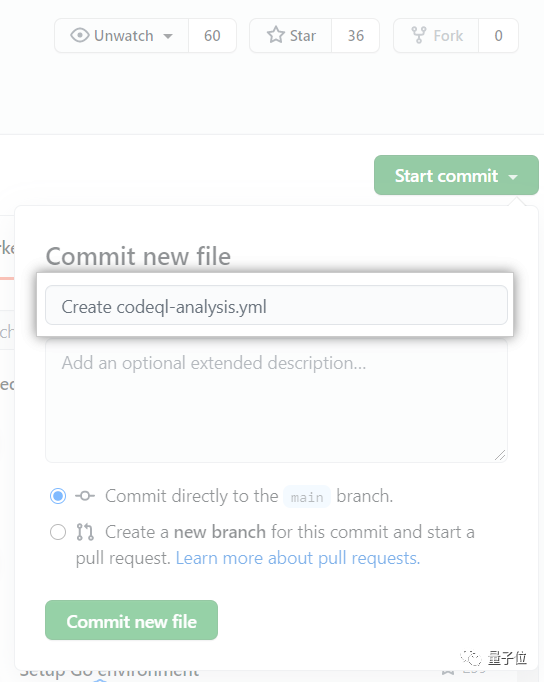
6、选择直接提交到默认分支,还是创建一个新分支并启动拉取请求。
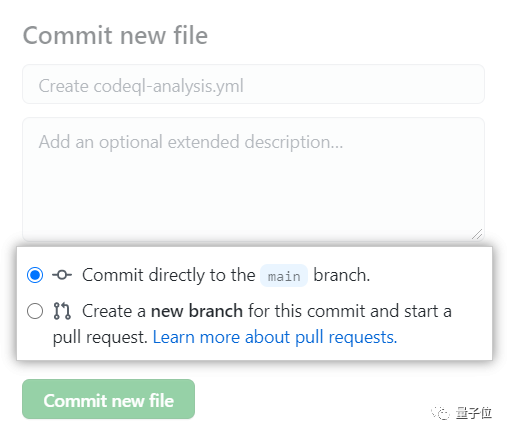
8、单击提交新文件。
代码扫描分析成功后,用户将在“Security”选项卡中看到安全警报信息。
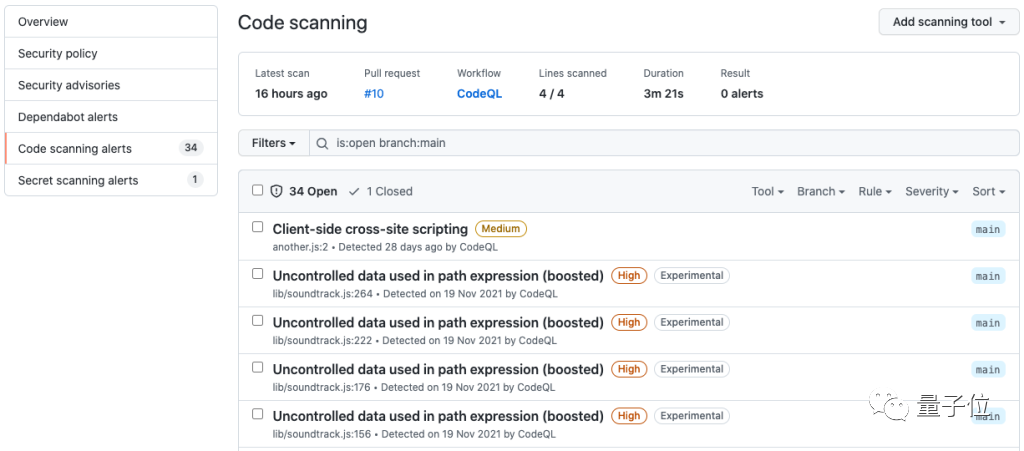
为何用ML能产生更好效果
为了检测存储库中的漏洞,CodeQL引擎首先构建了一个数据库,对代码的特殊关系表示进行编码,然后在数据库上执行一系列CodeQL查询。
但随着开源生态系统的快速发展,长尾效应越来越明显。
安全专家不断扩展和改进这些查询,对其他常见库和已知模式进行建模。然而,手动建模很耗时,而且总会有一些无法手动建模的不太常见的库和私有代码。
这时候机器学习就派上了用场。
通过给定大量训练代码片段,每个查询都标记为正面或负面样本,为每个片段提取特征,并训练深度学习模型对新示例进行分类。
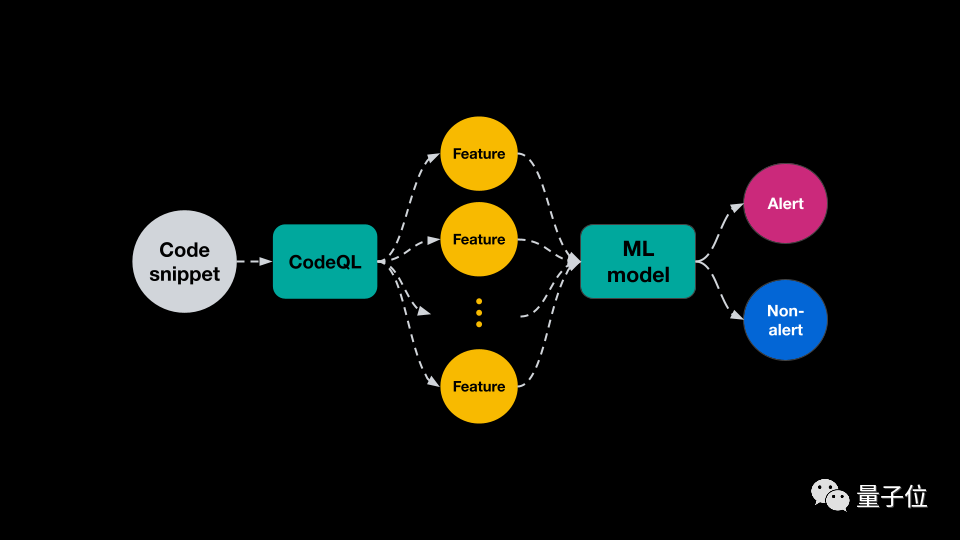
GitHub不是将每个代码片段简单地视为一串单词或字符,直接应用标准NLP技术对这些字符串进行分类,而是利用CodeQL访问有关底层源代码的大量信息,为每个代码片段生成一组丰富的feature,然后像NLP那样对它们进行标记和子标记。
由此从训练数据中生成一个词汇表,并将索引列表输入到深度学习分类器中,输出当前样本是每种漏洞的概率。
虽然现在基于ML的漏洞扫描仅适用于JavaScript/TypeScript,但GitHub承诺未来会支持更多语言,现在CodeQL已经支持了Python、Go、C/C++在内的多种流行语言。
最后,GitHub还强调,虽然全新工具可以发现更多漏洞,但也有可能提高误报率(召回率约为 80%,精度约为 60%)。未来这项功能会随着时间推移而改善。
参考链接:
[1]https://github.blog/2022-02-17-code-scanning-finds-vulnerabilities-using-machine-learning/
[2]https://github.blog/2022-02-17-leveraging-machine-learning-find-security-vulnerabilities/
[3]https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/setting-up-code-scanning-for-a-repository

