
- 1C++ 多态
- 2vue中使用 lodash Debounce防抖不生效原因_lodash debounce不生效
- 3抖音短视频seo矩阵源码开源SaaS部署(四)_短视频源码开源
- 4助力开发者,而非取代
- 5如何运用_Python_建立你的第一个_Slack_聊天机器人?
- 6Qt获取控件位置,坐标总结_qt 获取按钮在窗口位置
- 7RAG(大模型+知识库)落地与知识管理的春天-新的知识运营体系_大模型 知识库redmine
- 8手把手教你创建VS离线安装包_visual studio离线安装包怎么安装
- 9【深度学习】如何选择适合你的模型训练方法:Fine Tuning、DreamBooth、LoRA与Textual Inversion详细指南_dreambooth训练
- 10探索Swift编程的数据库管理新星:Swift-Kuery
计算机毕业设计hadoop+spark天气预测 天气可视化 天气大数据 空气质量检测 空气质量分析 气象大数据 气象分析 大数据毕业设计 大数据毕设_基于hadoop天气数据分析系统报告论文
赞
踩
| 课题题目 | 基于Hadoop+Spark的天气数据分析系统的设计与实现 |
| 课题来源 | 自拟 |
| 成果形式 | žA毕业设计 B毕业论文 C实做类毕业设计 |
| 开题报告内容(可另附页) 一,课题研究目的 随着大数据技术的不断发展,天气数据的分析和利用已成为气象服务领域的重要方向。通过对海量天气数据的分析,可以揭示天气变化的规律,预测未来气象情况,为人们的生产生活提供决策依据。Hadoop和Spark是当前大数据处理领域的两大主流技术,它们在数据处理、存储和分析方面具有强大的优势。因此,设计和实现基于Hadoop+Spark的天气数据分析系统,对于提高天气数据的处理效率、降低气象服务成本、提高气象服务水平等方面具有重要的意义。 二,国内外历史研究现状 天气预报系统是现代气象学的重要组成部分,它的发展和应用对于人类社会具有重要意义。随着大数据技术的不断发展,越来越多的行业开始利用大数据来提高业务效率和决策质量,其中,天气预报行业的数据具有海量、高维和时序性等特点,对于这些数据的处理和分析具有重要的实际应用价值。我国每年新增的气象资料达到PB量级,同时气象数据类型相对复杂,这使得传统的数据存储和处理技术不能很好解决目前用户的需求。传统的天气预报数据处理方法存在着处理速度慢、精度低等问题,无法满足现代天气预报系统的需求。 七十年代以来,美、日、苏相继用“ 模斯”方法作各种气象要素预报从而使整个天气预报在客观化定量化和自动化方面向前迈进了一大步。一些知名的科技公司,如Google、IBM、Microsoft等,都在开发和使用基于Hadoop+Spark的大数据天气分析系统。这些系统能够处理海量的天气数据,包括温度、湿度、风速、风向、气压、降雨量等,并通过机器学习和数据挖掘技术对天气变化进行预测和分析。 而我国是世界上自然灾害种类最多、活动最频繁、危害最严重的国家之一。气象灾害每年给我国造成的经济损失占到国民生产总值的1%~3%。近年来,极端天气气候事件频发,而且在未来还将呈增加趋势,气象灾害的监测预警已成为全社会的一项主要任务。经过多年的建设,我国已初步建立了地基、空基、天基观测相结合的综合观测系统;对灾害性天气的预报预测水平和质量都有了较大提高,初步建立了较完整的数值预报体系,同时,气象预报内容不断丰富,预报范围也开始向空间天气等领域发展。 近几年,云计算技术作为互联网领域的新产物,它为海量数据存储和处理提供了新的契机,它在海量数据挖掘技术领域中具有显著的优势,且已经得到了广泛的应用。因此,本课题旨在设计和实现一个基于Hadoop+Spark的天气数据分析系统,实现对海量天气数据的快速处理和准确分析,为天气预报提供更加准确、及时的数据支持。 三、课题研究内容 1、主要研究方法 本课题采用Hadoop, Spark, MySQL数据库工具编写天气数据分析系统,采用ECharts进行可视化。
该系统具有对海量天气数据的快速处理和准确分析;提高天气预报的准确性和时效性,为用户提供更加优质的天气预报服务等功能。
(1).数据采集模块:这个模块负责从天气网爬取天气数据,并将其传输到Hadoop或Spark集群进行处理。 (2).数据存储模块:这个模块负责将处理后的数据以表结构形式存储数据库中,以便后续查询和分析。 (3).数据预处理模块:这个模块负责对采集到的原始数据进行清洗、转换和标准化等操作,以便后续的分析和处理。 (4).数据分析模块:这个模块使用Hadoop和Spark的大数据处理能力,对经过预处理的数据进行分析,以提取天气模式、趋势和预测等有用信息。 (5).数据可视化模块:这个模块将分析结果以图表、图形等形式展示给用户,以便他们能够直观地了解天气状况和趋势。 (6).预测模型模块:这个模块利用线性回归预测,对天气数据进行预测和分析,提供未来天气状况的预测结果。 四、课题的准备情况 (1)通过查阅文献和资料,基本了解天气分析系统应具备的功能,并构思好将要呈现的功能模块。 (2)将电脑安装好pycharm, Hadoop, Tableau, Java这些开发时必需要到的工具。 (3)通过查阅相关文献准备相关专业方面的知识,对天气预测系统将要使用的技术有了大致的了解。认真复习python, matplotlib, Hadoop, springboot, mysql相关的知识点。 (4)从网上学习相关框架搭建,解决方案,测试知识。 五、工作进度计划 第一学期第14周 查阅相关文献资料,撰写开题报告并提交系统 第一学期第15-16周 学习相关技术,进行需求分析 第一学期第17周 熟悉开发环境 第二学期第1-4周 进行总体设计及数据库设计 第二学期第5-6周 进行界面设计、模块设计与功能实现 第二学期第7-9周 进行系统集成,完成中期检查,并将中期报告提交系统 第二学期第10-11周 进行系统测试与运行,完善系统功能 第二学期第12-13周 对系统进行最后调试,撰写毕业设计论文 第二学期第14-15周 根据论文查重结果进行修改,进行答辩 第二学期第16周 提交毕业设计材料
| |
| 指导教师意见(课题难度是否适中、工作量是否饱满、进度安排是否合理、工作条件是否具备等) 课题难度适中、工作量较为饱满、进度安排合理、具备工作条件。 指导教师签名: 2021 年12 月 5 日 | |
| 系(教研室)意见(选题是否适宜、各项内容是否达到专业培养目标要求、整改意见等) 专家组组长签字: 2021 年12 月 10 日 | |
任务书
一 系统功能
本天气数据分析系统,主要有数据采集,数据存储,数据预处理,数据分析,数据可视化,预测模型等类型。
具体实现目标如下:
(1).数据采集模块:这个模块负责从天气网爬取天气数据,并将其传输到Hadoop或Spark集群进行处理。
(2).数据存储模块:这个模块负责将处理后的数据以表结构形式存储数据库中,以便后续查询和分析。
(3).数据预处理模块:这个模块负责对采集到的原始数据进行清洗、转换和标准化等操作,以便后续的分析和处理。
(4).数据分析模块:这个模块使用Hadoop和Spark的大数据处理能力,对经过预处理的数据进行分析,以提取天气模式、趋势和预测等有用信息。
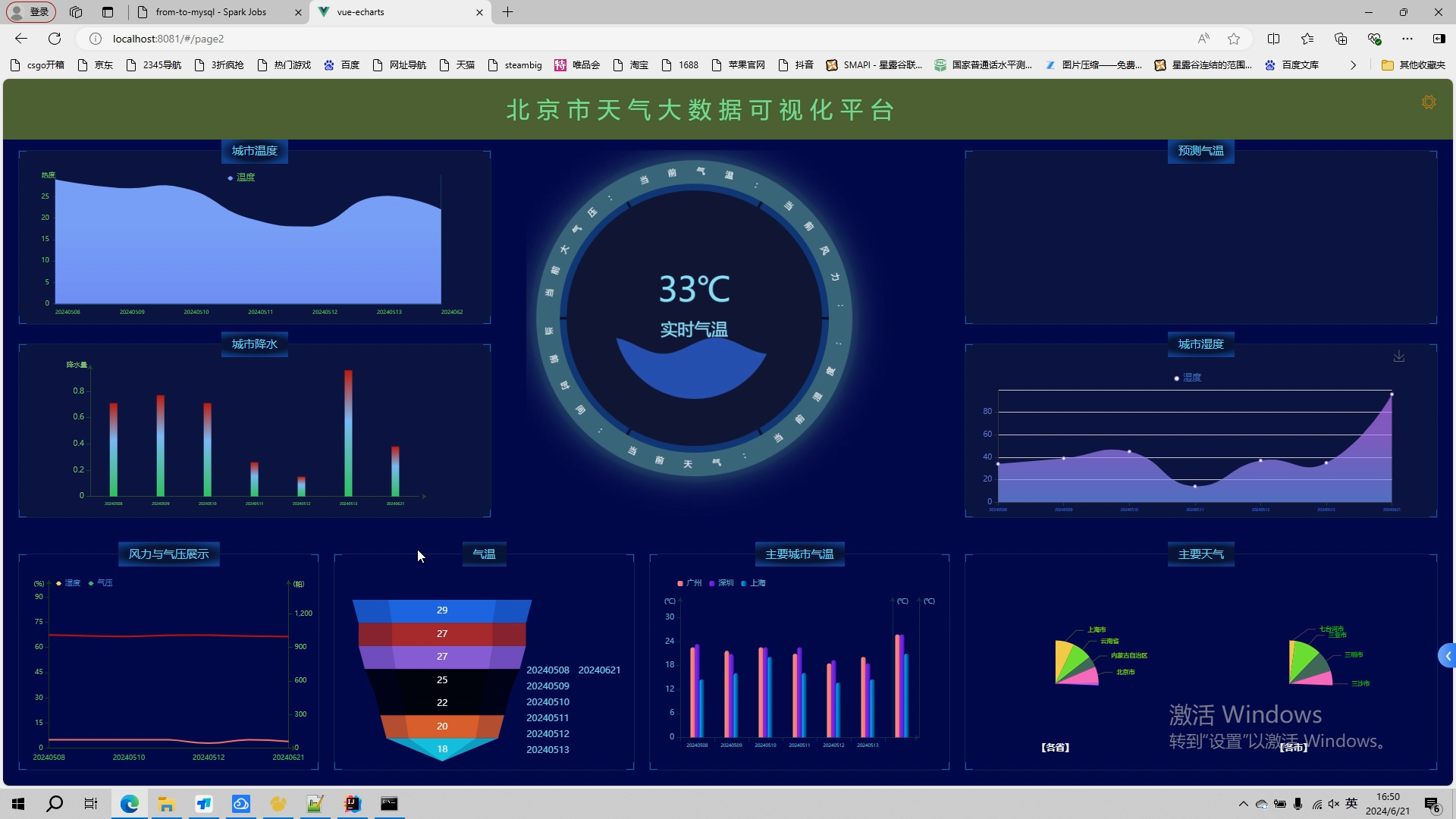
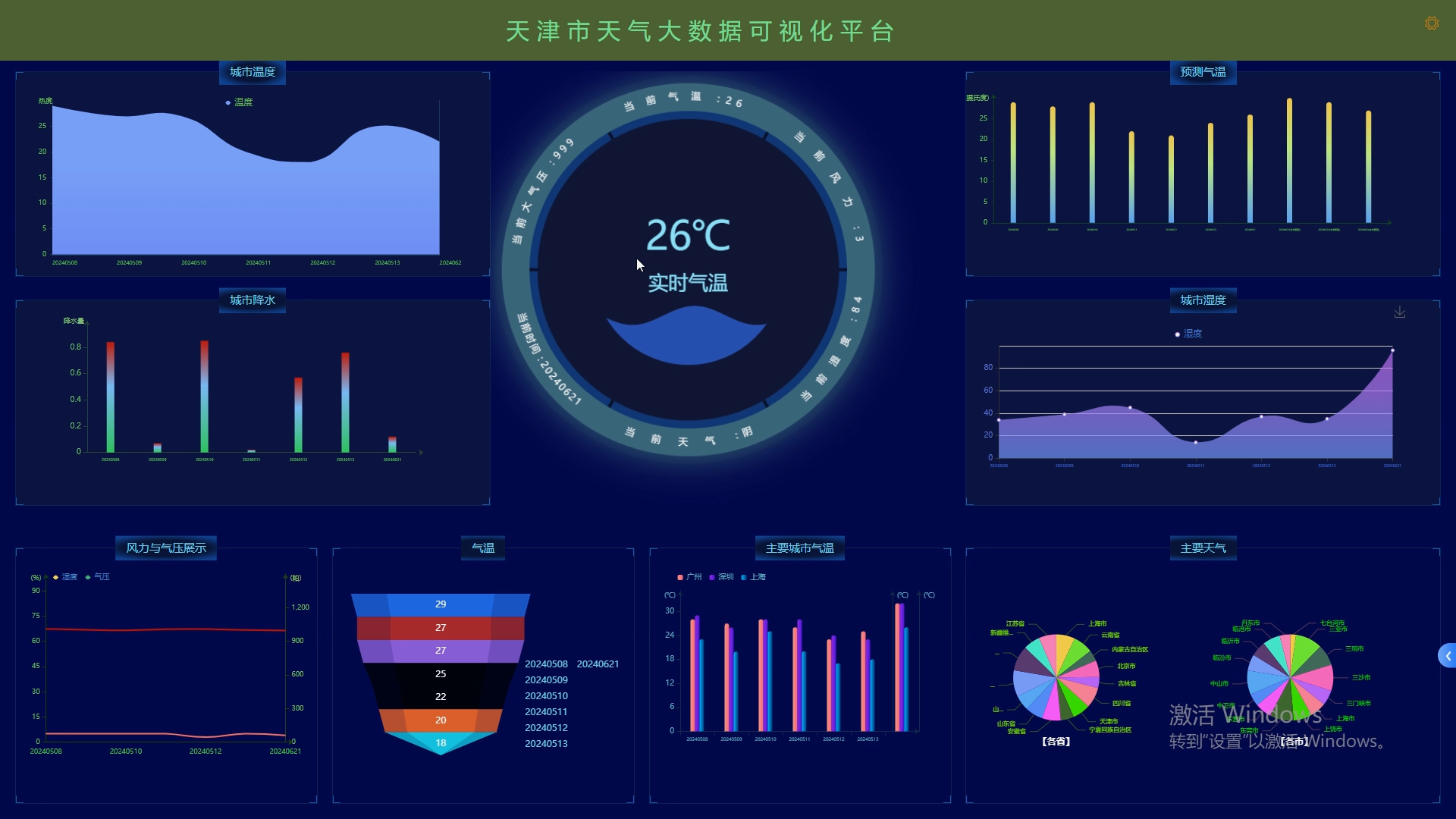
(5).数据可视化模块:这个模块将分析结果以图表、图形等形式展示给用户,以便他们能够直观地了解天气状况和趋势。
(6).预测模型模块:这个模块利用线性回归预测,对天气数据进行预测和分析,提供未来天气状况的预测结果。
二、实现方式
该项目采用Hadoop,Spark,Zookeeper, kafka,Hbase等技术搭建了一个基于Spark的天气分析预测系统,具体的实现模块分为以下几部分:
- 使Python和PyCharm进行数据采集,从天气网爬取天气数据。
- 数据库使用MySQL,来存取项目数据,以表结构的形式存在。
- 数据分析采用Sparksql,分析不同影响因素。
- 可视化采用Matplotlib在Tableau上绘制出柱状图折线图和饼图。
- 预测模型采用线性回归模型进行训练。使用Python中的机器学习库将预处理后的 数据集作为输入,并使用标签数据(例如未来一段时间内的天气状况)作为输出。
核心算法代码分享如下:
- https://dblab.xmu.edu.cn/post/8116/
-
- ## 启动hadoop
- cd /data/hadoop/sbin
- start-all.sh
-
-
-
- ## 启动hive
-
- cd /data/hive
-
- nohup hive --service metastore &
-
- nohup hive --service hiveserver2 &
-
-
- head -5 user_log.csv
-
-
- sed -i '1d' user_log.csv
-
-
- predeal.sh
-
- chmod +x ./predeal.sh
- ./predeal.sh ./user_log.csv ./small_user_log.csv
-
-
-
- hadoop dfs -mkdir -p /dbtaobao/dataset/user_log
- hadoop dfs -put dfs -put /data/ebiz2024/small_user_log.csv /dbtaobao/dataset/user_log
- hadoop dfs -cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10
-
- drop database if exists dbtaobao;
- create database if not exists dbtaobao;
- use dbtaobao;
-
-
- CREATE EXTERNAL TABLE dbtaobao.user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to xmu dblab,Now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/dbtaobao/dataset/user_log';
-
-
-
-
- select * from user_log limit 10;
-
- use dbtaobao;
- show tables;
-
- show create table user_log;
- desc user_log;
-
- select month,day,cat_id from user_log limit 20;
- select brand_id from user_log limit 10; -- 查看日志前10个交易日志的商品品牌
-
- select ul.at, ul.ci from (select action as at, cat_id as ci from user_log) as ul limit 20;
- select count(*) from user_log;
- select count(distinct user_id) from user_log; -- 在函数内部加上distinct,查出user_id不重复的数据有多少条
-
-
- select count(*) from (select user_id,item_id,cat_id,merchant_id,brand_id,month,day,action from user_log group by user_id,item_id,cat_id,merchant_id,brand_id,month,day,action having count(*)=1)a;
-
-
- select count(distinct user_id) from user_log where action='2';
-
- 。。。。。。。。。。。。。。。。。。。
-
-
-
- hive> create table scan(brand_id INT,scan INT) COMMENT 'This is the search of bigdatataobao' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; -- 创建新的数据表进行存储
- hive> insert overwrite table scan select brand_id,count(action) from user_log where action='2' group by brand_id; --导入数据
- hive> select * from scan; -- 显示结果
-
- select * from scan limit 10;
-
-
- hive> create table dbtaobao.inner_user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to XMU dblab! Now create inner table inner_user_log ' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
-
- hive> INSERT OVERWRITE TABLE dbtaobao.inner_user_log select * from dbtaobao.user_log;
-
- select * from inner_user_log limit 10;
-
-
-
- CREATE TABLE `dbtaobao`.`user_log` (`user_id` varchar(20),`item_id` varchar(20),`cat_id` varchar(20),`merchant_id` varchar(20),`brand_id` varchar(20), `month` varchar(6),`day` varchar(6),`action` varchar(6),`age_range` varchar(6),`gender` varchar(6),`province` varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
-
-
- sqoop export --connect jdbc:mysql://localhost:3306/dbtaobao --username root --password 123456 --table user_log --export-dir '/user/hive/warehouse/dbtaobao.db/inner_user_log' --fields-terminated-by ',';
-
-
-
-
- hadoop fs -put /data/ebiz2024/train_after.csv /dbtaobao/dataset
- hadoop fs -put /data/ebiz2024/test_after.csv /dbtaobao/dataset
-
-
-
- cd /data/jars/spark
- /data/spark/bin/spark-shell --jars /data/jars/spark/mysql-connector-java-5.1.47.jar --driver-class-path /data/jars/spark/mysql-connector-java-5.1.47.jar
-
-
-
-
- import org.apache.spark.SparkConf
- import org.apache.spark.SparkContext
- import org.apache.spark.mllib.regression.LabeledPoint
- import org.apache.spark.mllib.linalg.{Vectors,Vector}
- import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
- import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
- import java.util.Properties
- import org.apache.spark.sql.types._
- import org.apache.spark.sql.Row
- val train_data = sc.textFile("/data/ebiz2024/train_after.csv")
- val test_data = sc.textFile("/data/ebiz2024/test_after.csv")
- val train= train_data.map{line =>
- val parts = line.split(',')
- LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts
- (2).toDouble,parts(3).toDouble))
- }
- val test = test_data.map{line =>
- val parts = line.split(',')
- LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts(2).toDouble,parts(3).toDouble))
- }
- val numIterations = 1000
- val model = SVMWithSGD.train(train, numIterations)
- model.clearThreshold()
- val scoreAndLabels = test.map{point =>
- val score = model.predict(point.features)
- score+" "+point.label
- }
- scoreAndLabels.foreach(println)
- model.setThreshold(0.0)
- scoreAndLabels.foreach(println)
- model.clearThreshold()
- val scoreAndLabels = test.map{point =>
- val score = model.predict(point.features)
- score+" "+point.label
- }
-
-
- //设置回头客数据
- val rebuyRDD = scoreAndLabels.map(_.split(" "))
- /下面要设置模式信息
- val schema = StructType(List(StructField("score", StringType, true),StructField("label", StringType, true)))
- //下面创建Row对象,每个Row对象都是rowRDD中的一行
- val rowRDD = rebuyRDD.map(p => Row(p(0).trim, p(1).trim))
- //建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
- val rebuyDF = spark.createDataFrame(rowRDD, schema)
- //下面创建一个prop变量用来保存JDBC连接参数
- val prop = new Properties()
- prop.put("user", "root") //表示用户名是root
- prop.put("password", "123456") //表示密码是hadoop
- prop.put("driver","com.mysql.jdbc.Driver") //表示驱动程序是com.mysql.jdbc.Driver
- //下面就可以连接数据库,采用append模式,表示追加记录到数据库dbtaobao的rebuy表中
- rebuyDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/dbtaobao", "dbtaobao.rebuy", prop)
-
-
-
-
- val rebuyRDD = scoreAndLabels.map(_.split(" "))
-
- val schema = StructType(List(StructField("score", StringType, true),StructField("label", StringType, true)))
-
- val rowRDD = rebuyRDD.map(p => Row(p(0).trim, p(1).trim))
-
- val rebuyDF = spark.createDataFrame(rowRDD, schema)
-
- val prop = new Properties()
- prop.put("user", "root")
- prop.put("password", "123456")
- prop.put("driver","com.mysql.jdbc.Driver")
-
- rebuyDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/dbtaobao", "dbtaobao.rebuy", prop)
-


