
- 1AI大模型探索之路-实战篇7:Function Calling技术实战:自动生成函数_callingfunction
- 2【技术博客】Carsim-Simulink联合仿真实现ACC自动巡航跟随及分层控制_carsim acc
- 3如何开发 LightGBM集成树算法模型_集成树lgbm模型
- 4Istio复习总结:xDS协议、Istio Pilot源码、Istio落地问题总结
- 5零代码本地搭建AI大模型,详细教程!普通电脑也能流畅运行,中文回答速度快,回答质量高_ai模型搭建
- 6手机当电脑摄像头的简单方法,图文详解2024实用的虚拟摄像头软件(免费分享)
- 7低代码如何帮助企业数字化转型?_低代码 数字化转型
- 8Flutter完整版开发入门与实战指南(603页.PDF)一文带你通过Flutter
- 9mysql5.7单表500万_mysql 5.7单表300万数据,性能严重下降,如何破?
- 10十大排序算法(C++)_c++排序算法
Kafka之日志存储详解_卡夫卡日志
赞
踩
目录
1. 存储介质的速度常识
1.1 各个存储介质的速度层级图
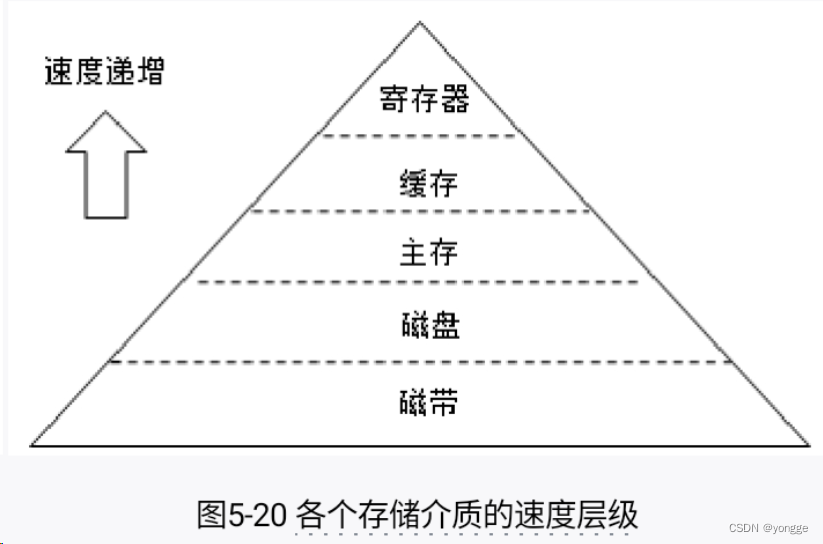
1.2 速度层级描述
一个由6块7200r/min的RAID-5阵列组成的磁盘簇的线性(顺序)写入速度可以达到600MB/s,而随机写入速度只有100kb/s,两者性能相差6000倍。
2. kafka日志文件目录结构
2.1 kafka日志文件目录描述
首先我们需要了解的是Kafka的日志文件目录是日志根目录加上主题和分区来命名的,如以下格式:<topic>-<partition>。
举个例子,假设由一个主题名为”topic-log“,此主题有4个分区,那么在实际物理存储上表现为”topic-log-0“”topic-log-1“”topic-log-2“”topic-log-3“,如下图所示:
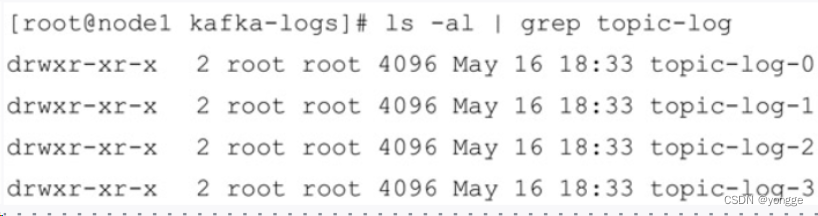
2.2 每个主题分区下的文件目录结构
如下图所示:
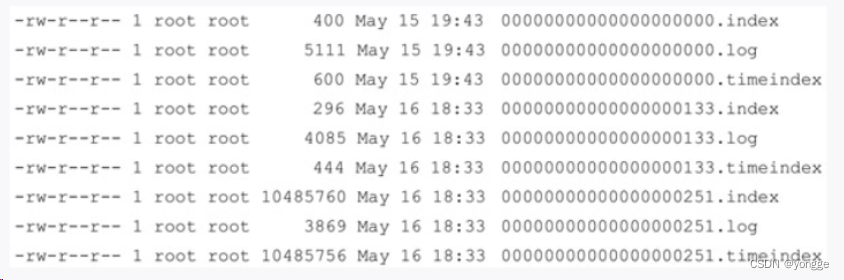
3. 具体日志文件详解
3.1 ".index"文件
索引文件,以稀疏索引(sparse index)的方法构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量(由broker端参数log.index.interval.bytes指定,默认值为4096,即为:4kb)的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小log.index.interval.bytes的值,对应地可以增加或缩小索引项的密度。
稀疏索引通过MappedByteBuffer将索引文件映射到内存中,以加快索引的查询速度。偏移量索引文件中的偏移量是单调递增的,查询指定偏移量时,使用二分查找法来快速定位偏移量的位置,如果指定的偏移量不在索引文件中,则会返回小于指定偏移量的最大偏移量。时间戳索引文件中的时间戳也保持严格的单调递增,查询指定时间戳时,也根据二分查找法来查找不大于该时间戳的最大偏移量,至于要找到对应的物理文件位置还需要根据偏移量索引文件来进行再次定位。稀疏索引的方式是在磁盘空间、内存空间、查找时间等多方面之间的一个折中。
3.2 ”.timeindex“文件
基于时间戳与 offset组成的索引文件,与
3.3 ".log" 文件
真正保存消息数据的日志文件
3.4 其他文件
clear-offset-checkpoint: 记录已清理和未清理的部分
log-start-offset-checkpoint: 对应logStartOffset,用来标识日志的起始偏移量。各个副本在变动LEO和HW的过程中,logStartOffset也可能随之而动
meta.properties: 记录分区的元数据。
recovery-point-offset-checkpoint和replication-offset-checkpoint这两个文件分别对应了LEO和HW。
Kafka会有一个定时任务负责将所有分区的LEO刷写到恢复点文件recovery-point-offset-checkpoint中,定时周期由broker参数log.flush.offset. checkpoint.interval.ms来配置,默认值为60000。还有一个定时任务负责将所有分区的HW刷写到复制点文件replication-offset-checkpoint中,定时周期由broker端参数replica.high.watermark.checkpoint.interval.ms来配置,默认值为5000。
4.回顾与总结
kafka的日志存储保证的消息的可靠性,日志文件的存储方式及读写方式让kafka更加的高性能。
- 导入依赖
org.apache.kafka [详细] 赞
踩

