
- 1大模型行业,根本没有什么“真”开源?
- 2SpringBoot 切片做请求接口日志_spring 代码如何在日志切面层面获取 post json 请求参数 而不影响业务使用
- 3注册GitHub账户_github账号15天后重新注册需要多少钱
- 4RabbitMQ常见的四种工作模式_mq的工作模式
- 5C#和Java究竟哪个更有前途?_c#和java哪个有前途
- 6OpenStack网络_openstack vpc网络
- 7算法之LRU和LFU算法_lfusix
- 8Android ContentProvider 使用_android 如何只读方式打开contentprovider
- 9【专栏目录】_drone-yolo复现
- 10Vs Code码云拉取新项目步骤详解_vs api项目拉取
【LLM】GLM系列模型要点_glm4
赞
踩
note
GLM
Paper:https://arxiv.org/abs/2406.12793
GitHub:https://github.com/THUDM
HF:https://huggingface.co/THUDM
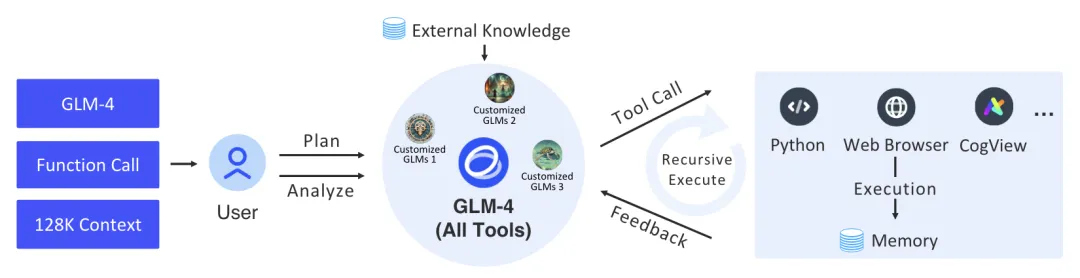
经过进一步优化的GLM-4 All Tools模型能够理解用户的意图,并自主决定何时以及如何使用包括网络浏览器、Python解释器、文本到图像模型以及用户自定义函数在内的工具来高效完成复杂任务。在实际应用中,GLM-4 All Tools在访问在线信息和使用Python解释器解决数学问题等任务中的表现超过了GPT-4 All Tools。
一、数据层面
1. 预训练数据
ChatGLM系列模型的预训练语料库由多种语言的文档构成,主要为英文和中文,涵盖了网页、维基百科、书籍、代码和论文等多种来源。数据处理流程精心设计,分为三个主要阶段:去重、过滤和分词。
- 在去重阶段,我们通过精确匹配和模糊匹配技术剔除重复或相似的文档,确保数据集的多样性。
- 在过滤阶段,我们移除了包含攻击性内容、占位符文本和源代码等噪声文档,以提升数据质量。最后,在分词阶段,文本被转换成token序列,为后续处理打下基础。
- 预训练数据中的token数量对模型训练速度有直接影响。为了提高效率,我们采用了字节级字节对编码(BPE)算法,分别对中文和多语种文本进行学习,并将学到的token与tiktoken中的cl100k_base tokenizer的token合并,形成了一个包含15万词汇的统一token集。在最终训练集中,我们对不同来源的数据进行了重新加权,增加了高质量和教育性来源(如书籍和维基百科)的数据比例,使得预训练语料库包含了约十万亿个tokens。
二、GLM4模型层面
No Bias Except QKV:为了提升训练速度,我们去除了所有偏差项,除了注意力层中的查询(Query)、键(Key)和值(Value)偏差。这一变化略微改善了长度外推法的性能。
RMSNorm 和 SwiGLU:我们用RMSNorm替换了LayerNorm,并用SwiGLU替换了ReLU。这两种策略能够提升模型性能。
旋转位置嵌入(RoPE):我们将RoPE扩展到二维形式,以适应GLM中的二维位置编码。
分组查询注意力(GQA):我们用GQA替换了传统的多头注意力(MHA),以减少推理过程中的KV缓存大小。由于GQA使用的参数比MHA少,我们相应增加了FFN的参数数量,以保持模型大小的一致性。
ChatGLM系列模型的上下文长度经历了多次扩展,从ChatGLM的2K增长到ChatGLM2和ChatGLM3的32K,再进一步增长到GLM-4的128K和1M。这种扩展不仅仅是通过上下文长度的增加(位置编码的扩展和对长文本的持续训练)实现的,而且还通过对长上下文的优化对齐,使得GLM-4能够有效地处理长文本。
三、GLM-4 All Tools
GLM-4 All Tools 是专门为支持智能体和相关任务而进一步优化的模型版本。它能够自主理解用户的意图,规划复杂的指令,并能够调用一个或多个工具(例如网络浏览器、Python解释器和文本到图像模型)以完成复杂的任务。
下图展示了 GLM-4 All Tools系统的整体工作流程。当用户提出复杂请求时,模型会对任务进行分析,并逐步规划解决问题的过程。如果模型确定无法独立完成任务,它将依次调用一个或多个外部工具,利用它们的中间反馈和结果来协助解决任务。
四、GLM的其他技术
LLM 的涌现能力:我们深入研究了 LLM 的涌现能力,探讨了预训练损失与模型在下游任务上的性能之间的关系。我们发现,在不同模型大小和训练token数量下,当预训练损失相同时,LLMs在下游任务上展现出相似的性能。此外,我们还观察到,在某些任务(如MMLU和GSM8K)上,只有当预训练损失降至特定阈值以下时,模型性能才会显著超越随机概率。基于这些发现,我们将涌现能力重新定义为模型在较低预训练损失下所展现出的特殊能力。(arXiv:2403.15796)
LongAlign:为了扩展LLMs处理长上下文的能力,我们提出了LongAlign,这是一套全面的长上下文对齐方法。它使得GLM-4能够处理长达128K token的长文本,并且在性能上与Claude 2和GPT-4 Turbo (1106)持平。(arXiv:2401.18058)
ChatGLM-Math:我们还专注于提升LLMs在数学问题解决方面的能力,推出了ChatGLM-Math。这一方法通过自我批评机制来选择数据,而不是依赖于外部模型或手动标注。(arXiv:2404.02893)
ChatGLM-RLHF:为了使LLMs更好地与人类反馈对齐,我们提出了ChatGLM-RLHF,这是将PPO和DPO应用于LLMs的一种方法。(arXiv:2404.00934)
Self-Contrast:为了避免依赖昂贵的人类偏好反馈数据,我们开发了Self-Contrast,一种无需反馈的对齐策略。它利用目标LLM自身来生成大量负样本,以此进行RLHF对齐。(arXiv:2404.00604)
AgentTuning:为了提高 LLM 的智能体能力,我们开发了 AgentTurning 框架,该框架包括 AgentInstruct 指令微调数据集,其中包含智能体与环境之间的高质量交互轨迹。(arXiv:2310.12823)
APAR:为了提高LLMs对具有分层结构响应的推理速度,我们提出了自并行自回归(APAR)生成方法。它通过指令微调来训练LLM规划其并行生成过程,并执行APAR生成。(arXiv:2401.06761)
基准测试:我们还开发了一系列开放的LLM基准测试,包括用于评估LLMs作为智能体能力的AgentBench(arXiv:2308.03688),用于评估长上下文处理性能的LongBench(arXiv:2308.14508),用于测量ChatGLM与中文内容对齐质量的AlignBench(arXiv:2311.18743),用于评估非Python编程语言中HumanEval问题的HumanEval-X(arXiv:2303.17568),以及用于测量模型解决实际编程任务能力的NaturalCodeBench (NCB)(arXiv:2405.04520)。
备注:大模型的训练少不了算力资源,博主和一些平台有合作~
高性价比4090算力租用,注册就送20元代金券,更有内容激励活动,点击。
GPU云服务器租用,P40、4090、V100S多种显卡可选,点击。

