
- 1深度学习之目标检测Faster RCNN模型算法流程详解说明(超详细理论篇)_fasterrcnn算法
- 2linux svn强制注释,svn强制提交时添加注释
- 3UE4出现报错,不知道怎么修改_epicaccountid:
- 4U3D shader基础
- 5【前端工程化面试题】webpack的module、bundle、chunk分别指的是什么?
- 6css 合同打印print--水印_print-template 模板添加水印
- 7线性代数 --- 投影与最小二乘(下),多元方程组的最小二乘解与向量在多维子空间上的投影_最小二乘法多维
- 8支付宝APP支付完成后台回调示例-java_java 支付宝小程序回调 验证商户号
- 9element ui 级联选择器个省市区_element ui地区选择器
- 10软件测试笔试题1_alpha测试需要用户参加吗
【显卡】AMD和Nvidia显卡系列&相关对比(A100 vs RTX4090)_a100相当于几张4090
赞
踩
【显卡】AMD和Nvidia显卡系列&相关对比(A100 vs RTX4090)
1. 介绍
在【显卡】一文搞懂显卡 详细解释了显卡。不懂的小伙伴可以去看看。
显卡(Video card、Display card、Graphics card、Video adapter)是个人计算机基础的组成部分之一,将计算机系统需要的显示信息进行转换驱动显示器,并向显示器提供逐行或隔行扫描信号,控制显示器的正确显示,是连接显示器和个人计算机主板的重要组件,是“人机”的重要设备之一,其内置的并行计算能力现阶段也用于深度学习等运算。
- 显卡又称显示卡( Video card),是计算机中一个重要的组成部分,承担输出显示图形的任务,对喜欢玩游戏和从事专业图形设计的人来说,显卡非常重要。
- 主流显卡的显示芯片主要由NVIDIA(英伟达)和AMD(超威半导体)两大厂商制造,通常将采用NVIDIA显示芯片的显卡称为N卡,而将采用AMD显示芯片的显卡称为A卡。
- 配置较高的计算机,都包含显卡计算核心。在科学计算中,显卡被称为显示加速卡。
- 显示芯片( Video chipset)是显卡的主要处理单元,因此又称为图形处理器(Graphic Processing Unit,GPU)。
- GPU是NVIDIA公司在发布GeForce 256图形处理芯片时首先提出的概念。尤其是在处理3D图形时,GPU使显卡减少了对CPU的依赖,并完成部分原本属于CPU的工作。
- GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。
- 显卡所支持的各种3D特效由显示芯片的性能决定,采用什么样的显示芯片大致决定了这块显卡的档次和基本性能,比如NVIDIA的GT系列和AMD的HD系列。
- 衡量一个显卡好坏的方法有很多,除了使用测试软件测试比较外,还有很多指标可供用户比较显卡的性能,影响显卡性能的高低主要有显卡频率、显示存储器等性能指标。
本文我们主要讲讲两个著名显卡芯片公司的产品。
- AMD(超威半导体):农企,红厂
- Nvidia(英伟达):老黄家,绿厂 ;
Nvidia和AMD,实际上并不是显卡的牌子,它们是专门生产显卡中最重要的显示芯片。就好比是两家专门生产汽车中发动机的厂商一样,它们本身并不生产整辆汽车。采用了英伟达或者AMD显示芯片的显卡,一般被人们叫做英伟达显卡或者AMD显卡。
- 像华硕、微星、技嘉、七彩虹、影驰、索泰、蓝宝石这类名字,才是显卡的牌子。
2. Nvidia显卡
NVIDIA,也就是俗称的N卡,是专业视觉计算领域的领导者,1999年研发的GPU极大推动了PC游戏市场的发展、重新定义了现代计算机图形技术,并彻底改变了并行计算。现在,GPU深度学习为现代 AI 这个全新计算时代提供了新动力。
其一大特色是对AI生态的适应(CUDA)广泛应用于AI领域(beat AMD)。CUDA技术,一种基于NVIDIA图形处理器(GPU)上全新的并行计算体系架构,让科学家、工程师和其他专业技术人员能够解决以前无法解决的问题,作为一个专用高性能GPU计算解决方案,NVIDIA把超级计算能够带给任何工作站或服务器,以及标准、基于CPU的服务器集群 CUDA是用于GPU计算的开发环境,它是一个全新的软硬件架构,可以将GPU视为一个并行数据计算的设备,对所进行的计算进行分配和管理。在CUDA的架构中,这些计算不再像过去所谓的GPGPU架构那样必须将计算映射到图形API(OpenGL和Direct 3D)中,因此对于开发者来说,CUDA的开发门槛大大降低了。CUDA的GPU编程语言基于标准的C语言,因此任何有C语言基础的用户都很容易地开发CUDA的应用程序。 由于GPU的特点是处理密集型数据和并行数据计算,因此CUDA非常适合需要大规模并行计算的领域。CUDA除了可以用C语言开发,也已经提供FORTRAN的应用接口,未来可以预计CUDA会支持C++、Java、Python等各类语言。可广泛的应用在图形动画、科学计算、地质、生物、物理模拟等领域。2008年NVIDIA推出CUDA SDK2.0版本,大幅提升了CUDA的使用范围。使得CUDA技术愈发成熟。
2.1 分类(不同系列)
英伟达(NVIDIA)是美国一家专业的计算机图形芯片制造商,英伟达显卡市场份额占据全球第一的位置,英伟达的显卡产品系列涵盖GeForce、Quadro、Tesla、NVS、GRID等,满足不同领域的应用需求。
-
GeForce显卡:GeForce显卡是英伟达公司推出的主流消费级显卡,其型号包括GTX1050、GTX1050ti、GTX1060、GTX1070、GTX1080、GTX1080ti、RTX2060、RTX2070、RTX2080、RTX2080ti、RTX3080(90)、RTX4080(90)等。
- GeForce显卡的主要功能是用于高性价比的家庭娱乐,比如游戏、影音、图形设计等,支持VR技术也是主流GeForce显卡的一大特色。
- 英伟达20系显卡之后使用了全新的RTX前缀,而其最大的亮点就是采用了光线追踪的技术,那么与此前的GTX相比还有什么区别?
- 1)在NVIDIA显卡中,从2004年的Geforce 6800系列开始就有【GT】的代号,代表着中高端显卡或者是加强版显卡,比如6600GT和6800GT,到了2005年的7800系列之后便引入了【GTX】的代号,直接代表着高端或者顶级显卡。进入GTX400系列以后,当时还有象征中低端的【GTS】命名,后来就连【GTS】也没有了,全部的独立显卡统称为【GTX】,仅用后面的数字大小来区分性能等级,至今GTX1000系列显卡一直延续着这样的命名方式;
- 2)20系列之后的显卡中,由于新增了光线追踪的特性,因此由原来的GTX前缀改为RTX,这里的【RT】就代表着光线追踪(ray tracing的缩写),象征着RTX2080显卡拥有非常强大的光线追踪性能;得益于采用全新的【图灵】架构和RT计算单元,因此RTX20系列的显卡有着更为出色的光线追踪性能,并实现了即时处理游戏光线追踪的条件;
- 3)除了在核心上面的更新以外,在显存上,也从原来的GDDR5X升级为最新的GDDR6,在带宽、频率和功耗方面都有着更为出色的表现;
- 4)流处理器区别,显卡中的流处理器越多,则说明性能越强,RTX2080的流处理器为2944个,而GTX1080的流处理器为2560个,流处理器方面提升了15%左右;
- 5)制造工艺区别。GTX1080基于是16纳米制造工艺,而RTX2080是基于最新的12纳米制造工艺,很显然工艺数字约越小,说明越好。采用最新的12nm工艺,会让晶体管数量大幅提升但有一部分划分到了Ray Tracing Core(光线追踪核心)上了,虽然面积也增大了,但晶体管的密度是提高了;
- 6)TDP和供电区别,由于RTX2080由于晶体管数和核心面积都变大了,TDP功耗也随之提升。
-
Quadro显卡:Quadro显卡是英伟达公司推出的专业级显卡,其型号包括Quadro K620、Quadro K1200、Quadro K2200、Quadro K4000、Quadro K4200、Quadro K5000、Quadro K5200、Quadro P400、Quadro P600、Quadro P1000、Quadro P2000、Quadro P4000、Quadro P5000、Quadro P6000等。
- Quadro显卡主要是针对设计、建模、视觉分析等专业领域,其优势在于高计算性能、低功耗、低延迟等,无论是专业的设计师还是专业的游戏玩家都可以通过Quadro显卡体验更好的绘图流畅度。
-
Tesla显卡:Tesla显卡是英伟达公司推出的深度学习用显卡,其型号包括Tesla K40、Tesla K80、Tesla P4、Tesla P40、Tesla P100、Tesla V100、Tesla T4、Tesla M40、Tesla M60、A40、A100、A800等。
- Tesla显卡的主要功能是用于超级计算机的深度学习,比如图像处理、语音识别、机器学习、物体检测等,相比GeForce显卡的性能更加强悍,可以支持更高的计算速度。
-
NVS显卡:NVS显卡是英伟达公司推出的多屏显示用显卡,其型号包括NVS 310、NVS 315、NVS 510、NVS 810、NVS 510M、NVS 810M等。
- NVS显卡的主要功能是用于多显示器的驱动,比如工程设计、金融分析、智能展示等,可以支持多达8个显示器的显示,而且支持4K分辨率,支持三明治拼接等,可以满足多显示器的高端需求。
-
GRID显卡:GRID显卡是英伟达公司推出的虚拟化用显卡,其型号包括GRID K1、GRID K2、GRID M60-1Q、GRID M60-2Q等。
- GRID显卡主要是针对虚拟化技术而设计的,可以支持虚拟桌面、虚拟机器学习等,可以支持多个用户同时访问一台服务器,而且支持虚拟桌面可以支持多屏显示,可以满足大规模的虚拟化部署。
总的来说,英伟达显卡大全及其型号有GeForce、Quadro、Tesla、NVS、GRID等,各类型号的显卡都有其自身的优势,可以满足不同领域的应用需求。英伟达显卡的市场份额占据全球第一的位置,也深受全球用户的喜爱和认可,令英伟达的显卡更加的受欢迎。
2.2 相关对比
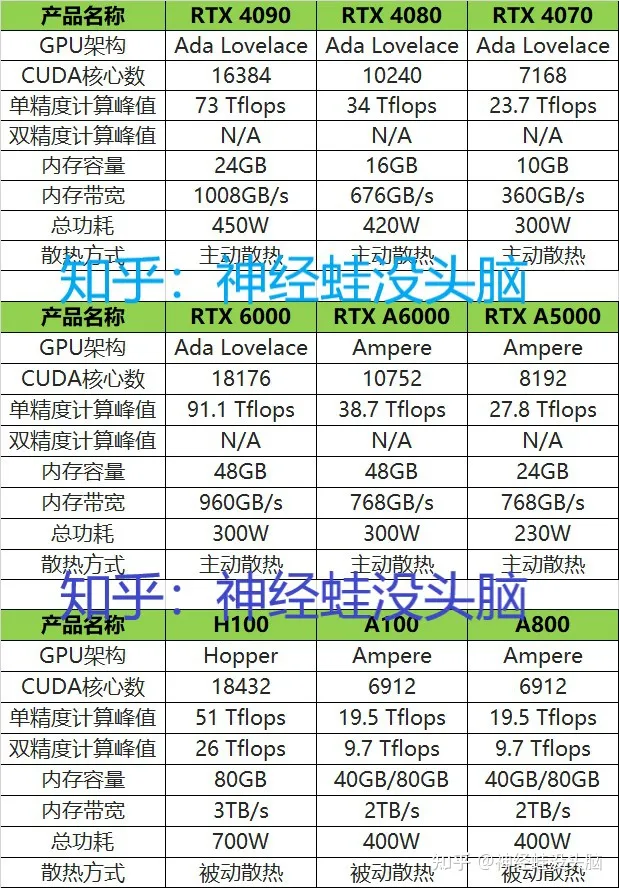
2.2.1 A100 和 RTX3090(4090)
参数上A100只有19.5T fp32浮点,而3090有35T,本以为3090会比A100快(不使用混合精度的情况下),但是看了网上几篇对比文,居然发现都是A100比3090要快?而且还快不少?
这其实是一个非常有意思的问题,但很多回答都没有抓住重点。
- 首先说结论,A100 在深度学习应用上面远比 3090 快,这一点是有人亲自测试过的。
- 其次,如果我们打开 3090 和 A100 在 NVIDIA 官网的参数,会发现 A100 只有 20 TFLOPS FP32 浮点,但 3090 却有 32 TFLOPS,似乎 3090 会快很多。
- 但是,如果我们仔细了解 Ampere 架构之后就会发现,这个参数仅仅是 CUDA core 的性能。Ampere 配置了第三代支持 BF16 和 TF32 的 tensor core ;
- 如果算上这部分算力,A100 有 312 TFLOPS BF16 和 156 TFLOPS TF32 (with FP32 accumulation),而 3090 的 tensor core 被老黄硬生生砍了一刀,只有 71 TFLOPS BF16 和 35 TFLOPS TF32 (with FP32 accumulation);
- 也就是说 tensor core 这方面 3090 只不到 A100 四分之一的性能。
因此,在深度学习里,不管你是用 CNN 还是 Transformer,绝大多数的浮点计算量都集中在矩阵乘法上面,而这部分的负载恰好能用 tensor core 运行。即便不主动使用混合精度, 一些框架也会默认使用 TF32 进行矩阵计算,因此在实际的神经网络训练中,A100 因为 tensor core 的优势会比 3090 快很多。
再来说一下二者的区别:
- 两者定位不同,Tesla系列的A100和GeForce 系列的RTX3090,现在是4090,后者定位消费级,前者定位数据中心;
- 主要还有2方面不同:
- 1、显存 :A100有40G 和80G 显存两个版本,对于很多需要大显存场景有绝对优势,大显存在量级处理速度上也会有巨大差距;
- 2、双精度计算能力:Tesla系列的A100具备较强的双精度计算能力,GeForce 系列的RTX3090、4090几乎没有双精度计算能。
对于需要科学计算精度的科研来说,只能选择A100这样的双精度计算能力强的GPU,要不然花了时间做出来的结果也不正确。
2.2.2 对比网站
- V100 vs A100
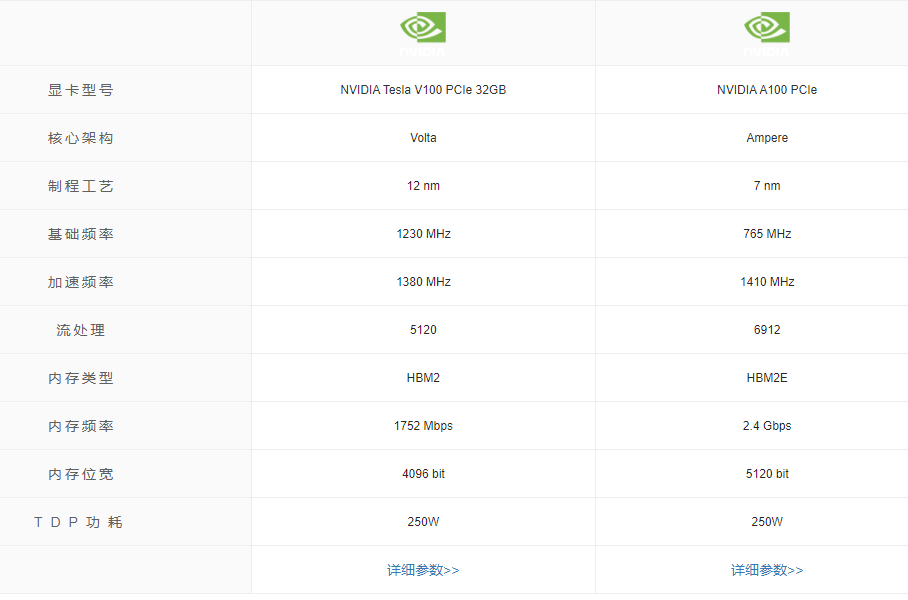
想要对比更多的GPU型号,可以去这个网站:芯参数评测
3. AMD显卡
AMD的显卡我们俗称的A卡,其实最早A卡并不是AMD的而是ATI的,ATI在2006年被AMD以54亿美元的巨资收购了,成为了AMD的一部分,此后AMD宣布放弃ATI品牌,将旗下所以显卡都统一更名为AMD。
说起AMD,作为搞计算机AI领域的,虽然也有与cuda对应的rocm,但是确实不如Nvidia对于AI生态的适应。AMD在深度学习确实非常费劲,rocm只有linux系统下支持,你还得双系统。另外官方兼容列表只有6800系列,6700/6600以下和更早的a卡还得折腾,不能保证能运行。总而言之纯粹是玩票产物,离生产力差的太远。
再说起AMD显卡,什么560,560d,560xt,500x系列,584,588,590,5882048sp,vega,raedon是不是一下就懵逼了呢?
- 其实就是AMD新老显卡交织同时卖,N卡的老黄那边产品线有条不紊;
- AMD只能一代一代套马甲提频换名勉强跟着,光命名混乱是不一定导致型号混乱,真正的混乱还是产品之间定位有严重重叠或者某个价格段段有空缺。
- 以R9 280、R9 280x、R9 285、R9 285x、R9 380、R9 380x为例,这些卡还有许多不同的显存版本,价格差距也在500元以内,这是真的混乱。
此外AMD卡清库存的速度比隔壁(Nvidia)慢,甚至有时候两代马甲卡能一起卖半年,进一步加剧了这种混乱(拿不出新架构,新核心,疯狂马甲炒冷饭导致的AMD产品线混乱),总的来说,AMD是走一步看一步,而Nvidia是看一步走一步。
说完AMD卡型号混乱,疯狂马甲炒冷饭,但是A卡还是有自己的优势:
- 拿玩游戏来说A卡确实没有N卡优化的好,但A卡注重图形渲染性能和通用运算性能的提升,画面效果比N卡更好;
- 同级别的价格也N卡便宜些。
3.1 分类
-
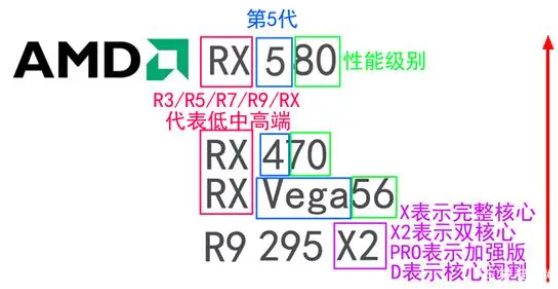
首先是前缀,这几年AMD新显卡的前缀都是RX开头,如RX580、RX5700、RX6900等,
- 三代之前的前缀又分为R9(高端),R7(中端),R5、R3(低端),再往前追溯就是远古时期的HD了。
-
然后就是中间的数字,RX580就表示第5代,这个数字越大越好。后面的数字也是越大越好,
- RX580性能高于RX570,RX570性能高于RX550。
-
最后就是后缀了,X2表示双芯片,这个是AMD同代产品里面最好的,
- 比如R9 295 X2(R9 295 X2虽然是上一代的旗舰但性能比RX590还要强,X表示完整核心,XT超级版,GE BOOST,XT PRO表示加强版,D表示核心阉割)。
-
需要注意的是RX400系与RX500系之后并不是600系,而是RX Vega系列,比如RX Vega56和RX Vega64,对标的是GTX1080。50周年纪念版RX5700、RX5700XT,其对标的是英伟达的RTX2060/2070。
-
看不懂没关系,下面给大家带上一张显卡的天梯度,有点老,你就可以一眼看到各类显卡,不同型号的位置排名,RX 6000>RX 5000>RX 400/500/Vega>Radeon R300>Radeon R200>Radeon HD。(可以点击图片之后放大观看)。

最后也是总结一下,A卡的优势在于:
- 性能比更高,在同价位上性能是强于N卡,同级别的GTX1660和RX590,后面的要便宜几百块。
当然,A卡也有缺点:
- 和游戏厂商的关系没有N卡好,驱动稳定性也差一点。
4. 对比
4.1 AMD 和 Nvidia显卡对比
- 1、GPU流处理器不同。
- amd的显卡: amd显卡的GPU中每个流处理器的5个流处理单元都是固定的,不能拆开重组,每个流处理器只能处理一条4D指令,有一个流处理器单元闲置,但却无法加入其他组合来共同工作。
- 英伟达的显卡:英伟达显卡的GPU中每个流处理器都具有完整的ALU功能,在发出一条操作指令时每个流处理器都能充分工作。
- 2、架构执行不同。
- amd的显卡: amd显卡的架构优势在于理论运算能力,但执行效率不高,对于复杂多变的任务种类适应性不强,需要软件上的支持才能发挥应有性能。
- 英伟达的显卡:英伟达显卡架构执行效率极高,灵活性强,在实际应用中容易发挥应有性能,但功耗较难控制,较少的处理单元也限制了其理论运算能力。
- 3、多屏输出方面不同。
- amd的显卡: amd显卡的强项,A卡可以做到单卡六屏输出,加上架构和显存的特性,即使在多屏高分辨率下,性能衰减也比对手要小。
-英伟达的显卡:英伟达显卡在3D视觉技术方面,前期是N卡占优势,后是A卡占优,由于A卡3D视觉技术是免费开放的,选择性也更高。
- amd的显卡: amd显卡的强项,A卡可以做到单卡六屏输出,加上架构和显存的特性,即使在多屏高分辨率下,性能衰减也比对手要小。
- 4、来源不同。
- N卡来自于nvidia公司,也是现在大部分显卡的开发公司之一。
- A卡来自AMD公司,也是大家比较熟悉的CPU制造商之一。
- 5、架构对比不同。
- n卡主要架构是控制单元,
- a卡的执行单元是1d流处理器,架构上会稍有不同,但也无法说谁优谁劣。
- 6、功耗对比不同。
- n卡的功耗通常要比a卡高一些,
- 因为它的功耗控制比a卡差,但功耗高低通常会决定性能的强弱。
- 7、性能对比不同。
- n卡在3d性能、游戏处理速度上更强一些,
- 而a卡在2d平面画质、渲染的效果上要更强一点。
- 8、侧重点对比不同。
- n卡侧重于3d,a卡侧重于2d,
- 前者的效率高且灵活性也很强,后者的运算能力更强,当然这些是理论上的。
4.2 建议
前面几部分其实也说了,这里直接说结论吧。
- 选择中端和入门机型的时候,A卡N卡都可以用,A卡优先;
- 高端的选N卡,性能好稳定有光追;
- 另外如果搞AI的,建议N卡;
- 或者追求性价比,建议A卡。
参考
【1】https://www.zhihu.com/question/535130416/answer/2922531526
【2】https://www.knowbaike.com/it/60078.html

