
- 1网络安全——跨站脚本攻击_java反射型跨站点脚本攻击
- 2从零开始的力扣刷题记录-第五十天_超市正在促销,你可以用 b个空水瓶从超市兑换一瓶水。最开始,你一共购入了 a
- 3java版gRPC实战之四:客户端流_@grpcclient
- 4常见的网页状态码
- 5云从科技资深算法研究员:详解跨镜追踪(ReID)技术实现及难点 | 公开课笔记
- 6CentOS7管理防火墙及开放指定端口_centos防火墙设置与端口开放的方法
- 7系统性能提升70%!华润万家某核心系统数据库升级实践
- 8inputstream 文件 是否存在 java_Java“文件”有效,但“ InputStream”无效
- 9Python 入门编程题(二)答案_for i in range(len(lt)): #遍历你输入类型序列的长度(假设输入stirng
- 10Jellyfin转码和色调映射效率提升:开启处理器低电压模式(GuC/HuC)_jellyfin qsv
重磅!清华ChatGLM2开源!中文榜居首,碾压GPT-4!
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:新智元 | 编辑:桃子 好困
【导读】清华ChatGLM2-6B模型又开始刷圈了!新版本在推理能力上提升了42%,最高支持32k上下文。
ChatGLM-6B自3月发布以来,在AI社区爆火,GitHub上已斩获29.8k星。
如今,第二代ChatGLM来了!
清华KEG和数据挖掘小组(THUDM)发布了中英双语对话模型ChatGLM2-6B。
项目地址:https://github.com/THUDM/ChatGLM2-6B
HuggingFace:https://huggingface.co/THUDM/chatglm2-6b
最新版本ChatGLM2-6B增加了许多特性:
- 基座模型升级,性能更强大
- 支持8K-32k的上下文
- 推理性能提升了42%
- 对学术研究完全开放,允许申请商用授权
值得一提的是,在中文C-Eval榜单中,ChatGLM2以71.1分位居榜首,碾压GPT-4。而最新版本ChatGLM2-6B以51.7分位列第6。
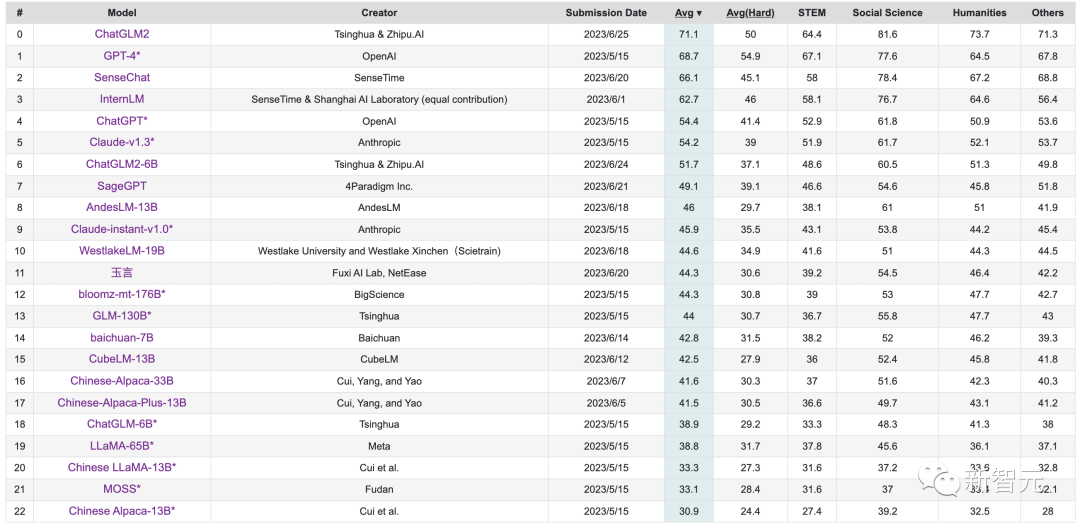
ChatGLM2-6B升级亮点
ChatGLM-6B的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,又增加许多新特性:
1. 更强大的性能
基于ChatGLM初代模型的开发经验,全面升级了ChatGLM2-6B的基座模型。
ChatGLM2-6B使用了GLM的混合目标函数,经过了1.4T中英标识符的预训练与人类偏好对齐训练.
评测结果显示,与初代模型相比,ChatGLM2-6B在MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
2. 更长的上下文
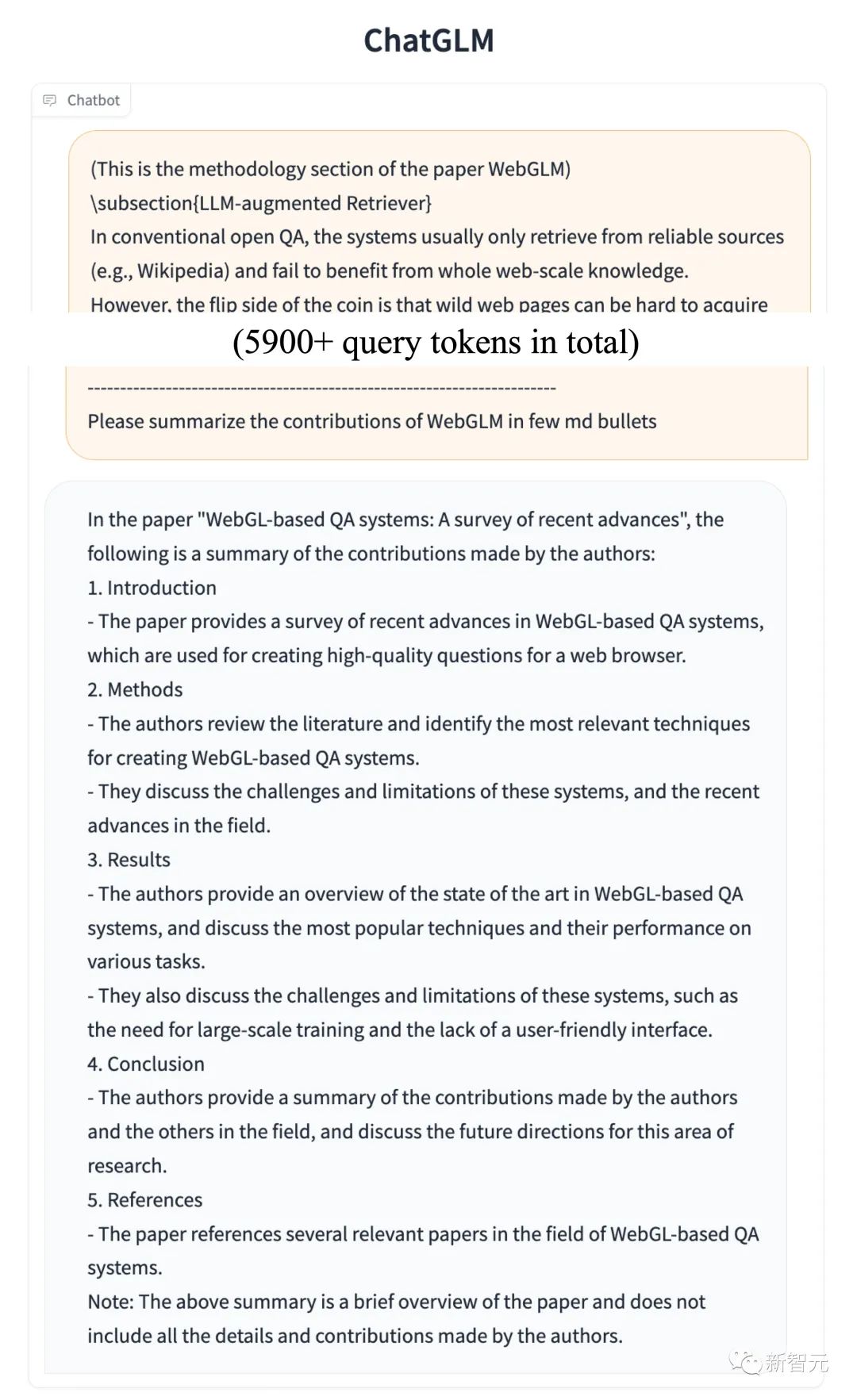
基于 FlashAttention 技术,研究人员将基座模型的上下文长度由 ChatGLM-6B 的2K扩展到了32K,并在对话阶段使用8K的上下文长度训练,允许更多轮次的对话。
但当前版本的ChatGLM2-6B对单轮超长文档的理解能力有限,会在后续迭代升级中着重进行优化。
3. 更高效的推理
基于 Multi-Query Attention 技术,ChatGLM2-6B有更高效的推理速度和更低的显存占用.
在官方的模型实现下,推理速度相比初代提升了42%,INT4量化下,6G显存支持的对话长度由1K提升到了8K。
4. 更开放的协议
ChatGLM2-6B权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。
效果
相比于初代模型,ChatGLM2-6B在多个维度的能力上,都取得了巨大的提升。
数理逻辑
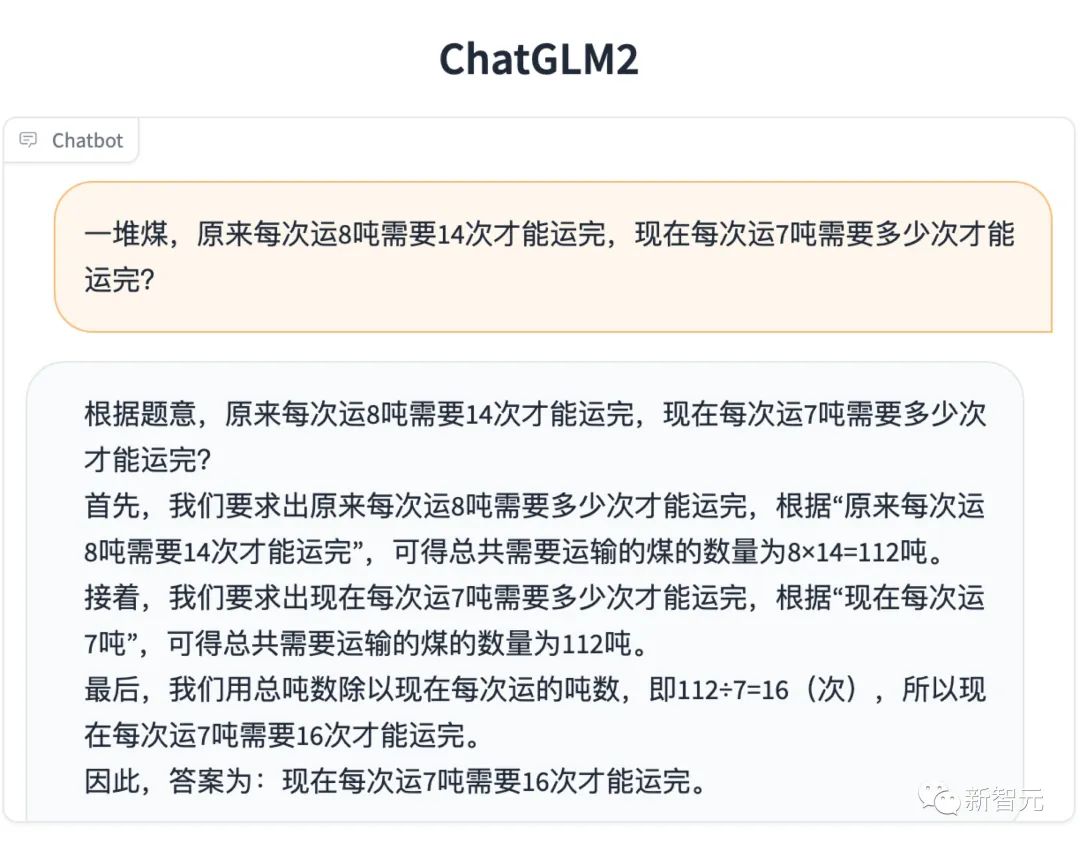
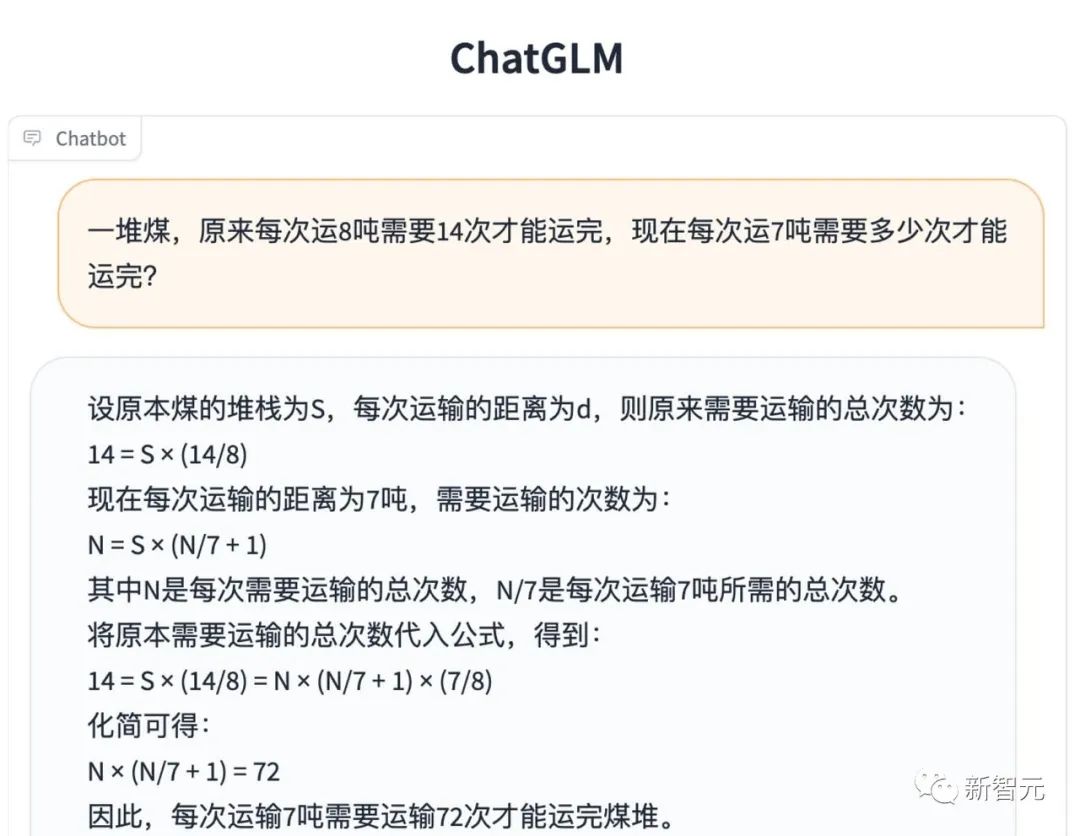
知识推理
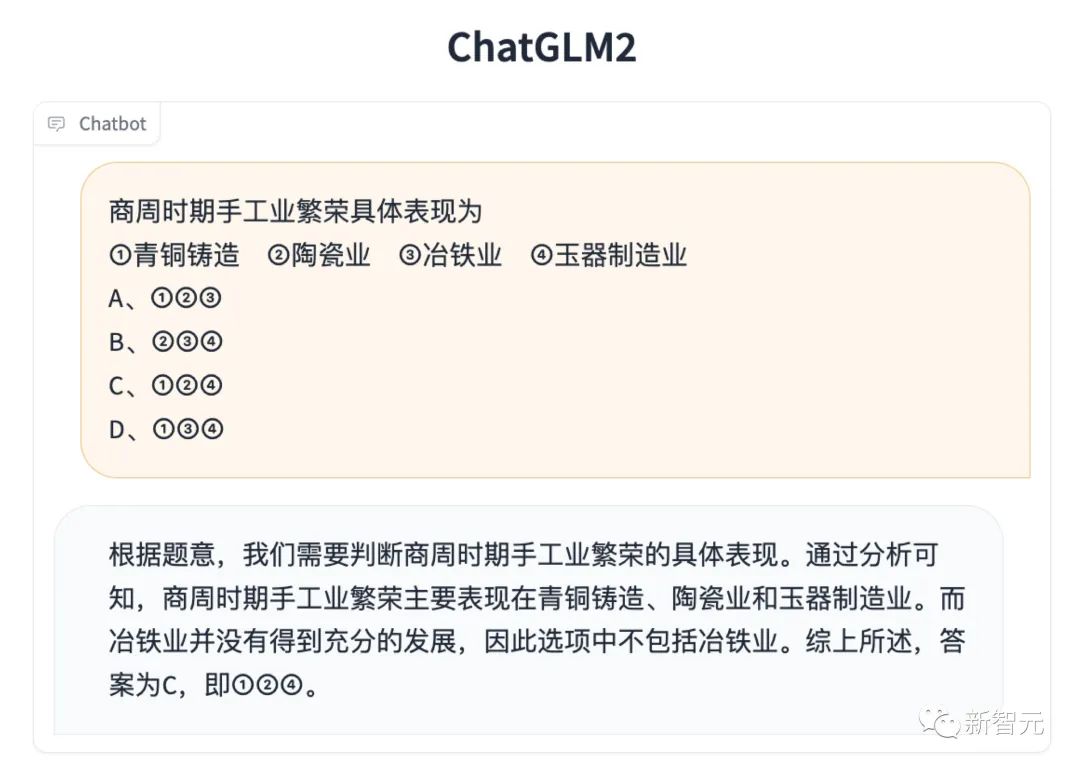
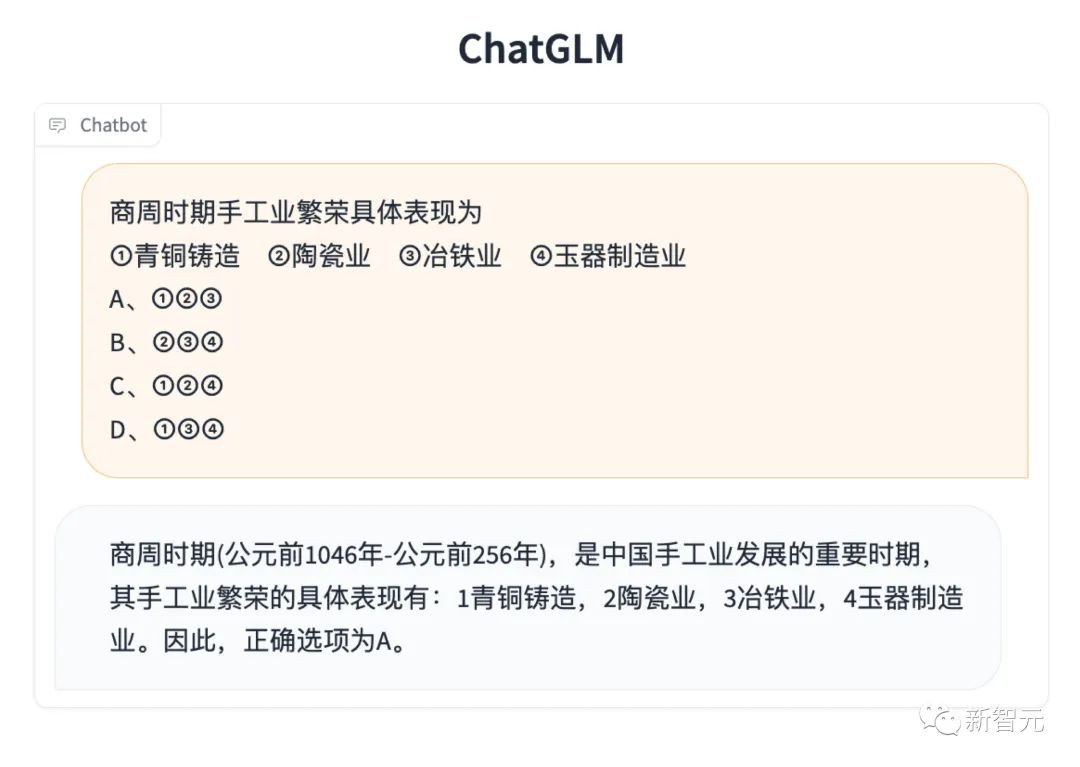
长文档理解

评测结果
研究团队选取了部分中英文典型数据集进行了评测,以下为ChatGLM2-6B模型在MMLU(英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。
MMLU
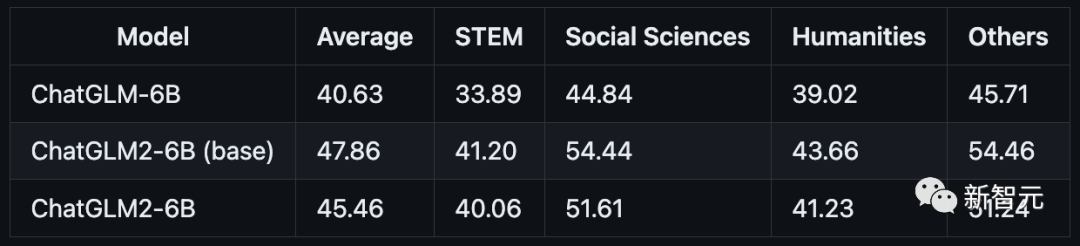
C-Eval
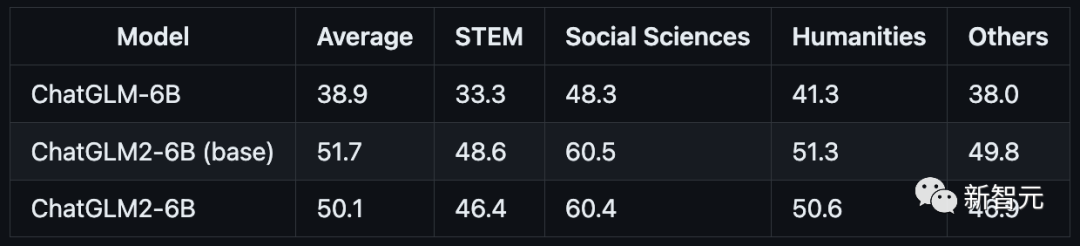
GSM8K
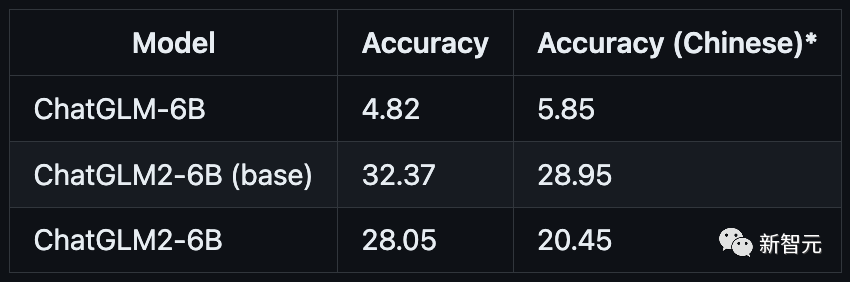
BBH

推理性能
ChatGLM2-6B使用 Multi-Query Attention,提高了生成速度。生成2000个字符的平均速度对比如下:
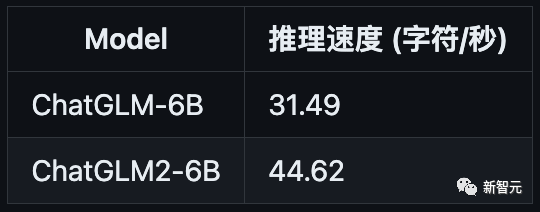
Multi-Query Attention同时也降低了生成过程中KV Cache的显存占用。
此外,ChatGLM2-6B采用Causal Mask进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。
因此,使用6GB显存的显卡进行INT4量化的推理时,初代的ChatGLM-6B模型最多能够生成1119个字符就会提示显存耗尽,而ChatGLM2-6B能够生成至少8192个字符。
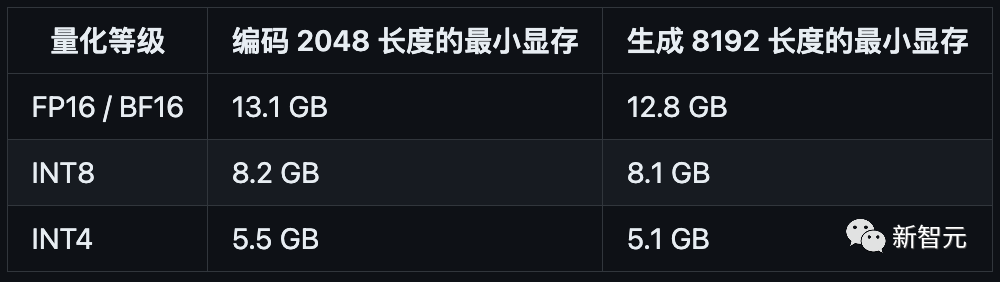
研究团队也测试了量化对模型性能的影响。结果表明,量化对模型性能的影响在可接受范围内。
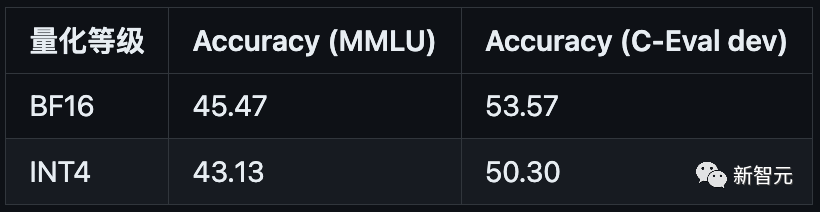
使用方法
环境安装
首先需要下载本仓库:
- git clone https://github.com/THUDM/ChatGLM2-6B
- cd ChatGLM2-6B
然后使用pip安装依赖:pip install -r requirements.txt,其中transformers库版本推荐为4.30.2,torch推荐使用 2.0 以上的版本,以获得最佳的推理性能。
代码调用
可以通过如下代码调用ChatGLM2-6B模型来生成对话:

从本地加载模型
在从Hugging Face Hub下载模型之前,需要先安装Git LFS,然后运行:
git clone https://huggingface.co/THUDM/chatglm2-6b如果checkpoint的下载速度较慢,可以只下载模型实现:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b然后,手动下载模型参数文件,并将文件替换到本地的chatglm2-6b目录下。
地址:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/
模型下载到本地之后,将以上代码中的THUDM/chatglm2-6b替换为本地的chatglm2-6b文件夹的路径,即可从本地加载模型。
参考资料:
https://github.com/THUDM/ChatGLM2-6B
https://huggingface.co/THUDM/chatglm2-6b
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- 目标检测和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者ransformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲扫码或加微信号: CVer333,进交流群
- CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
-
- ▲扫码进星球
- ▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()

