
- 1Python就业课程、书籍汇总、项目分享_黑马程序员python项目
- 2fourkk
- 3python2异步编程_详解python异步编程之asyncio(百万并发)
- 4ElementUI的表格换行符失效、不换行_el-table-column white-space="pre-wrap" 不生效
- 5Cocos Creator 导入其他js文件_cocos引入base.js文件
- 6MySQL中的limit和union_mysql union limit
- 7C# byte[]数组和string的互相转化 (四种方法)_c# byte数组转string
- 8爆肝将近 10 万字进行讲解 Node.Js 超详细教程_nodejs实战教程
- 9前端开发创新实践
- 10Parsing error: Unknown compiler option ‘allowImportingTsExtensions‘.eslint
图文结合丨带你轻松玩转MySQL Shell for GreatSQL_mysqlshell和mysql区别
赞
踩
一、引言
1.1 什么是MySQL Shell ?
MySQL Shell 是 MySQL 的一个高级客户端和代码编辑器,是第二代 MySQL 客户端。第一代 MySQL 客户端即我们常用的 MySQL 。除了提供类似于 MySQL 的 SQL 功能外,MySQL Shell 还提供 JavaScript 和 Python 脚本功能,并包括与 MySQL 一起使用的 API 。MySQL Shell 除了可以对数据库里的数据进行操作,还可以对数据库进行管理,特别是对MGR的支持,使用MySQL Shell 可以非常方便的对MGR进行搭建、管理、配置等
1.2 什么是MySQL Shell for GreatSQL ?
MySQL Shell for GreatSQL 的出现是因为在 GreatSQL 8.0.25-16 版本的时候引入了MGR仲裁节点(投票节点)的新特性,MySQL提供的MySQL Shell无法识别该特性,因此我们提供了 MySQL Shell for GreatSQL 版本,以下就称为MySQL Shell for GreatSQL
但是!因为 JS 库中含有商业库,所以GreatSQL社区在编译的时候就没有加上 JS 的脚本功能。
大家使用的时候不要一直输入
\js说怎么切换不过去了 :)
不过Python模式的语法和JavaScript模式的语法是大同小异的,举个例子:
| JavaScript 语法 | Python 语法 |
|---|---|
| var c=dba.getCluster() | c=dba.get_cluster() |
| c.status() | c.status() |
| c.setPrimaryInstance() | c.set_primary_instance() |
不过就是变量名命名风格些许不同而已,本质上是没有区别的。本文也将使用 GreatSQL Shell-8.0.25-16 中 Python 模式来带你玩转 MySQL Shell for GreatSQL
二、安装与配置
2.1 安装 MySQL Shell for GreatSQL
首先我们先下载MySQL Shell for GreatSQL,下载地址在GreatSQL的gitee仓库,和我们的GreatSQL 8.0.32-24新版本放在一起:https://gitee.com/GreatSQL/GreatSQL/releases/tag/GreatSQL-8.0.32-24。进入下载文件列表最下方就是我们的MySQL Shell for GreatSQL,大家按机器和架构下载对应版本~
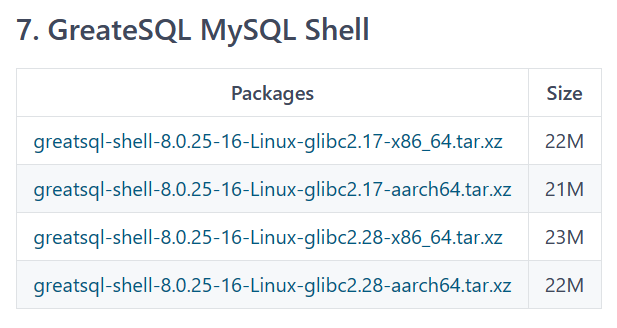
本文机器环境是CentOS7.9-x86-64所以下载第一个即可
$ cat /etc/system-release
CentOS Linux release 7.9.2009 (Core)
$ uname -a
Linux hy 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux- 1
- 2
- 3
- 4
下载完成后解压:
$ tar -xvf greatsql-shell-8.0.25-16-Linux-glibc2.17-x86_64.tar.xz接着把 bin 目录添加到环境变量中:
$ echo "export PATH=$PATH:/usr/local/greatsql-shell-8.0.25-16-Linux-glibc2.17-x86_64/bin" >> /root/.bash_profileMySQL Shell for GreatSQL 需要 Python 3.6 的环境,如果没有环境的话,需要安装yum install python3 -y
$ python3 -V
Python 3.6.8- 1
一切准备就绪!就可以开始使用 MySQL Shell for GreatSQL 了
$ mysqlsh2.2 界面特征
MySQL Shell for GreatSQL 的界面如下:
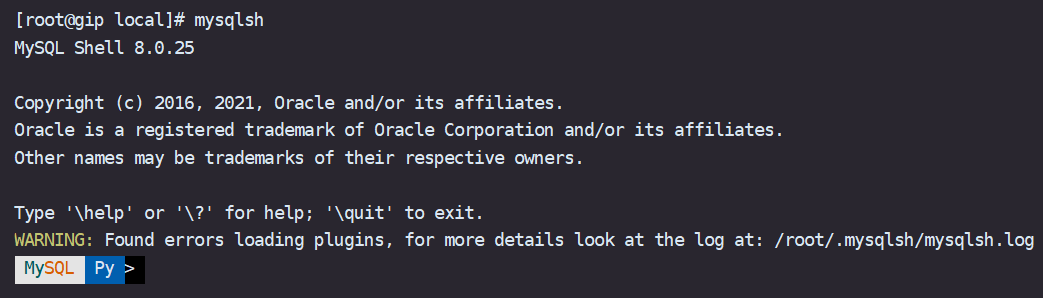
细心的同学就会发现,有一个 WARNING ,没关系我们根据提示看下 mysqlsh.log
$ cat /root/.mysqlsh/mysqlsh.log在日志中发现这样一段提示,意思就是少了一个 Python 的模块 certifi
ModuleNotFoundError: No module named 'certifi'解决方法就是用pip来安装下这个缺失的模块即可:
$ pip3.6 install --user certifi再次进入MySQL Shell for GreatSQL $ mysqlsh
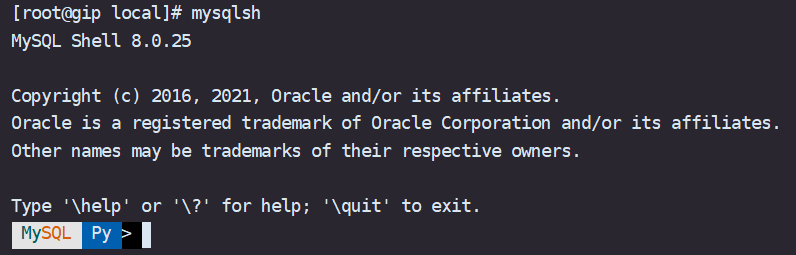
现在就没有讨厌的 WARNING 了 :)
MySQL Shell for GreatSQL 同时也是支持定义自己的提示符的,在 promt 目录下,有许多的模板可供使用
$ ls /usr/local/GreatSQLshell/greatsql-shell-8.0.25-16-Linux-glibc2.17-x86_64/share/mysqlsh/prompt
prompt_16.json prompt_256.json prompt_256pl.json prompt_dbl_256.json prompt_dbl_256pl.json README.prompt
prompt_256inv.json prompt_256pl+aw.json prompt_classic.json prompt_dbl_256pl+aw.json prompt_nocolor.json- 1
- 2
使用方式如下,例如我想换成这个模板prompt_16.json
$ export MYSQLSH_PROMPT_THEME=/usr/local/GreatSQLshell/greatsql-shell-8.0.25-16-Linux-glibc2.17-x86_64/share/mysqlsh/prompt/prompt_16.json 再进入 MySQL Shell for GreatSQL 看看已经变了个样子
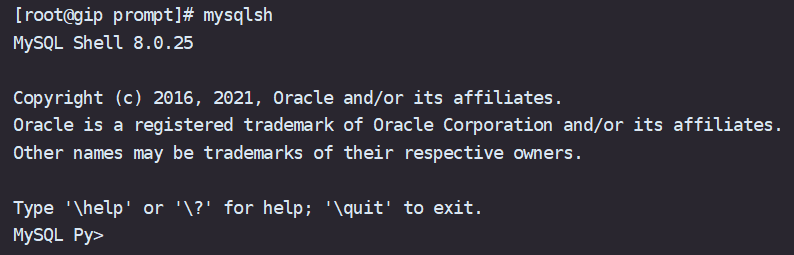
当然也可以自行修改.json文件,修改成你喜欢的自定义配置,这都是没问题的
现在的 MySQL Shell for GreatSQL 是没法使用的,因为我们是用 $ mysqlsh 命令直接登录到 Shell 环境,由于未携带登录验证信息(user、host、password)等处于未连接服务状态,在内部使用 \c \h 等简易命令外,执行其它获取服务器信息的命令会报 Not Connected.
三、基本操作和使用
3.1 连接数据库实例
MySQL Shell for GreatSQL 提供了多种连接实例登录方式,可以根据自己喜好选择
$ mysqlsh --help
...上面省略部分...
Usage examples:
$ mysqlsh root@localhost/schema
$ mysqlsh mysqlx://root@some.server:3307/world_x
$ mysqlsh --uri root@localhost --py -f sample.py sample param
$ mysqlsh root@targethost:33070 -s world_x -f sample.js
$ mysqlsh -- util check-for-server-upgrade root@localhost --output-format=JSON
$ mysqlsh mysqlx://user@host/db --import ~/products.json shop- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这里选择MySQL Shell for GreatSQL sock的方式连接数据库实例
$ mysqlsh -S/data/GreatSQL/mgr01/mysql.sock root@localhost用sock方式连接数据库实例会让输入密码,然后会问是否保存密码
Please provide the password for 'root@localhost': //这里输入密码
Save password for 'root@localhost'? [Y]es/[N]o/Ne[v]er (default No): y //是否保存密码- 1
一旦存储了服务器 URL 的密码,每当 MySQL Shell for GreatSQL 打开会话时,它都会从已配置的 Secret Store Helper 中检索密码,登录到服务器,而无需交互输入密码。MySQL Shell for GreatSQL 执行的脚本也是如此。如果未配置任何 Secret Store Helper,则以交互方式请求密码。
注意!MySQL Shell for GreatSQL 仅通过 Secret Store 保留服务器 URL 和密码,而不自行保留密码。
密码只有在 手动输入 时才会保留。如果在运行 MySQL Shell for GreatSQL 时使用类似于服务器 URI 的连接字符串或在命令行中提供了密码,则该密码不会保留。
连接到 MySQL Shell for GreatSQL 所接受的最大密码长度为128个字符。
3.2 基本命令
MySQL Shell for GreatSQL 的由于命令需要独立于执行模式而可用,因此它们以转义序列 \ 字符开头,简单列举几个:
| 命令 | 别名或缩写 | 描述 |
|---|---|---|
| \help | \h or ? | 帮助 |
| \quit | \q or \exit | 退出 |
| \status | \s | 显示当前状态 |
| \py | 切换为 Python 语言模式 | |
| \sql | 切换为 SQL 语言模式 | |
| \history | 查看和编辑命令行历史记录 | |
| \connet | \c | 连接到 GreatSQL 服务器 |
| \reconnect | 重新连接到 GreatSQL 服务器 |
3.3 基本用法
Ⅰ、切换SQL模式 \sql,在 SQL 模式下按 Tab键 可以实现自动补全哦!
GreatSQL Py > \sql
Switching to SQL mode... Commands end with ;- 1
Ⅱ、可在任何语言状态执行操作系统命令 \system
GreatSQL Py > \system ls /usr/local
greatsql-shell-8.0.25-16-Linux-glibc2.17-x86_64.tar.xz GreatSQL8.0.32- 1
Ⅲ、查看历史命令 \history ,选项 history.maxSize 为 MySQL Shell for GreatSQL 的最大存储条数,默认为 1000 条轮替。
GreatSQL Py > \history
1 \system ls /usr/local
2 /history
3 history
4 help()
5 /hasattr()- 1
- 2
- 3
- 4
- 5
默认历史只能保存当前会话命令,全局不可见,退出后自动删除。可通过启用 history.autoSave 选项保存会话之间的历史记录。
3.4 全局对象
MySQL Shell for GreatSQL 启动时,可以使用以下模块和对象
dba:用于InnoDB Cluster、ReplicaSet 管理;mysql:支持使用经典 MySQL 协议连接到 MySQL 服务器,允许执行 SQL;mysqlx:用于通过 MySQL X DevAPI 处理 X 协议会话;os:允许访问允许与操作系统交互的功能;session:代表当前打开的MySQL会话;shell:允许访问通用功能和属性;sys:允许访问系统特定的参数;util:对诸如升级检查器和JSON导入之类的各种工具进行了分组;
四、备份和恢复
MySQL Shell for GreatSQL有Dump & Load工具,比 mydumper 更快的逻辑备份工具,与 myloader 不一样的是,MySQL Shell for GreatSQL Load 是通过 LOAD DATA LOCAL INFILE 命令来导入数据的。 而 LOAD DATA 操作,按照官方文档的说法,比 INSERT 操作快 20 倍。该序列工具包括:
util.dump_instance():备份整个数据库实例,包括用户util.dump_schemas():备份指定数据库 schemautil.dump_tables():备份指定的表或视图util.load_dump():恢复备份
我们来动手操作下,准备一个表空间有 724MB 的表内含七百万条数据
greatsql> select count(*) from student1;
+----------+
| count(*) |
+----------+
| 7000000 |
+----------+
1 row in set (2.62 sec)
greatsql> system ls -l /data/GreatSQL/mgr01/test
-rw-r----- 1 mysql mysql 759169024 7月 25 12:15 student1.ibd- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.1 备份整个数据库实例,包括用户
dump_instance(outputUrl[, options]),备份整个数据库实例,包括用户
- outputUrl 是备份目录,不能为空。
- options 是可指定的选项
options 有什么选项可以使用\? dump_instance查看
GreatSQL Py > \? dump_instance
The following options are supported://找到这句下面就是- 1
使用起来也是有限制的,官方原文:
Requirements
- MySQL Server 5.7 or newer is required.
- File size limit for files uploaded to the OCI bucket is 1.2 TiB.
- Columns with data types which are not safe to be stored in text form
(i.e. BLOB) are converted to Base64, hence the size of such columns
cannot exceed approximately 0.74 * max_allowed_packet bytes, as
configured through that system variable at the target server.
- Schema object names must use latin1 or utf8 character set.
- Only tables which use the InnoDB storage engine are guaranteed to be
dumped with consistent data.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
简单来说就是
"最好是INNODB的数据引擎""版本在5.7及以上""必须使用latin1或utf8字符集""要有BACKUP_ADMIN权限"
话不多说,开始动手尝试吧
GreatSQL Py > util.dump_instance("/data/backups",{"compression": "none","threads":"16"}) Acquiring global read lock Global read lock acquired Gathering information - done All transactions have been started Locking instance for backup Global read lock has been released Writing global DDL files Writing users DDL ...中间省略 1 thds dumping - 109% (19.00M rows / ~17.37M rows), 263.77K rows/s, 54.42 MB/s Duration: 00:01:05s Schemas dumped: 3 Tables dumped: 11 Data size: 3.05 GB Rows written: 19000005 Bytes written: 3.05 GB Average throughput: 46.80 MB/s

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
注意!compression: “none” 指的是不压缩,这里设置为不压缩主要是为了方便查看数据文件的内容。线上使用建议开启压缩
开启16线程,速度还是蛮快的,接下来我们看下数据目录
$ ll /data/backups/
#有好多这里就列举几个
-rw-r----- 1 root root 5773 8月 2 11:28 @.done.json
-rw-r----- 1 root root 1119 8月 2 11:27 @.json
-rw-r----- 1 root root 231 8月 2 11:27 @.post.sql
-rw-r----- 1 root root 231 8月 2 11:27 @.sql
-rw-r----- 1 root root 458 8月 2 11:27 test.json
-rw-r----- 1 root root 24536863 8月 2 11:27 test@student1@0.tsv- 1
- 2
- 3
- 4
- 5
- 6
- 7
@.done.json:会记录备份的结束时间,备份集的大小,备份结束时生成。@.json:会记录备份的一些元数据信息,包括备份时的一致性位置点信息:binlogFile,binlogPosition 和 gtidExecuted,这些信息可用来建立复制。@.sql,@.post.sql:这两个文件只有一些注释信息。不过在通过 util.loadDump 导入数据时,我们可以通过这两个文件自定义一些 SQL。其中,@.sql 是数据导入前执行,@.post.sql 是数据导入后执行。sbtest.json:记录 sbtest 中已经备份的表、视图、定时器、函数和存储过程。*.tsv:数据文件。
我们看看数据文件的内容:
$ head -3 test@student1@0.tsv
1 Kathleen Ford F 344 Jiangnan West Road, Haizhu District 139-1119-0424 163 lin4brNtHD 918
2 David Mitchell M 355 Papworth Rd, Trumpington 5892 672144 702 qoA6axcT6u 218
3 Lin Yunxi M 620 Hanover Street 7091 590385 194 Tl4LY3UmgY 765- 1
- 2
- 3
TSV 格式,每一行储存一条记录,字段与字段之间用制表符(\t)分隔。
test@student1.json:记录了表相关的一些元数据信息,如列名,字段之间的分隔符(fieldsTerminatedBy)等。test@student1.sql:sbtest.sbtest1 的建表语句。test.sql:建库语句。如果这个库中存在存储过程、函数、定时器,也是写到这个文件中。@.users.sql:创建账号及授权语句。默认不会备份 mysql.infoschema,mysql.session,mysql.sys 这三个内部账号。
4.2 备份指定数据库
util.dump_schemas(schemas, outputUrl[, options])备份指定库的数据。
其中,第一个schemas参数必须为数组,第二个是备份目录
GreatSQL Py > util.dump_schemas(["test"],"/data/backup_schemas",{"threads":"16"}) Acquiring global read lock Global read lock acquired Gathering information - done All transactions have been started ...中间省略... 1 thds dumping - 109% (19.00M rows / ~17.37M rows), 530.98K rows/s, 49.34 MB/s uncompressed, 22.02 MB/s compressed Duration: 00:00:58s Schemas dumped: 1 Tables dumped: 4 Uncompressed data size: 3.05 GB Compressed data size: 1.57 GB Compression ratio: 1.9 Rows written: 19000000 Bytes written: 1.57 GB Average uncompressed throughput: 52.35 MB/s Average compressed throughput: 26.96 MB/s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
当然从MySQL Shell 8.0.28版本开始,可直接使用 util.dumpInstance 中的 includeSchemas 选项进行指定库的备份。
下面展示下在MySQL Shell version 8.0.34版本下的内容和介绍
- includeSchemas: list of strings (default: empty) - List of schemas to
be included in the dump.- 1
GreatSQL Py > util.dump_instance("/data/backups",{"includeSchemas":["test"],"threads":"16"})如果想要更高的版本的MySQL Shell for GreatSQL,可以参考文章“MySQL Shell 8.0.32 for GreatSQL编译安装 https://mp.weixin.qq.com/s/TzR-Szitdd2ocOqwJaaqEQ”
4.3 备份指定表
util.dump_tables(schema, tables, outputUrl[, options])备份指定表的数据
用法和上面两个相同,tables参数必须为数组
GreatSQL localhost Py > util.dump_tables("test",["student1"],"/data/backup_table",{"threads":"16"}) Acquiring global read lock Global read lock acquired Gathering information - done All transactions have been started ...中间省略... 1 thds dumping - 110% (7.00M rows / ~6.31M rows), 539.12K rows/s, 44.17 MB/s uncompressed, 18.75 MB/s compressed Duration: 00:00:12s Schemas dumped: 1 Tables dumped: 1 Uncompressed data size: 572.88 MB Compressed data size: 242.92 MB Compression ratio: 2.4 Rows written: 7000000 Bytes written: 242.92 MB Average uncompressed throughput: 44.50 MB/s Average compressed throughput: 18.87 MB/s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
当然从 MySQL Shell 8.0.28 开始,可直接使用 util.dumpInstance 中的 includeTables 选项进行指定表的备份。
- includeTables: list of strings (default: empty) - List of tables or
views to be included in the dump in the format of schema.table.- 1
GreatSQL Py > util.dump_instance("/data/backups",{"includeTables":["test.test"],"threads":"16"})4.4 导入生成的备份
util.load_dump(url[, options])用于导入通过 dump 命令生成的备份集
导入前,记得先打开”local_infile“参数设置
set global local_infile = ON;
GreatSQL Py > util.load_dump("/data/backup_table",{"threads":"16"})如果想再导入一次,要把 resetProgress 设置为 True
GreatSQL Py > util.load_dump("/data/backup_table",{"threads":"16","resetProgress":True})当然,我们也做过导入速度测试,下附测试结果,详细对比文章见”myloader导入更快吗?并没有... https://mp.weixin.qq.com/s/b3q27ZMmWJ0tX5wQkzFpIQ“
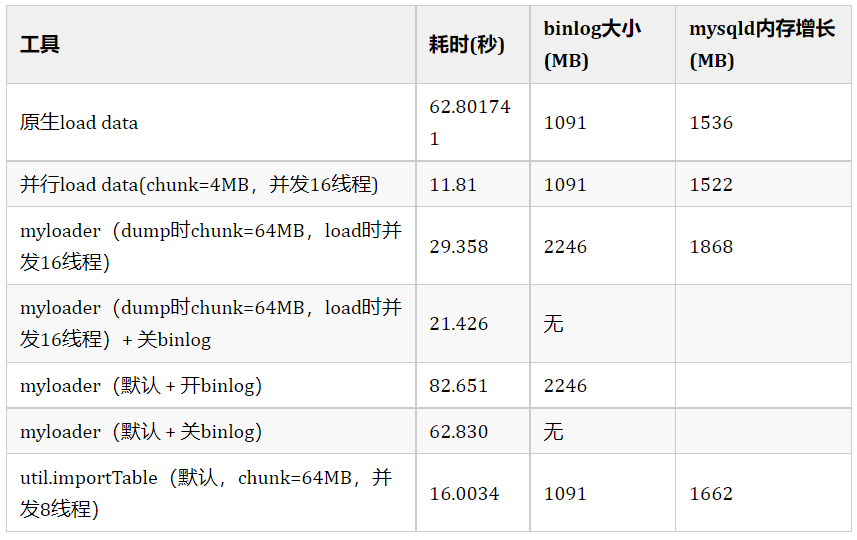
从上面图表看出,虽然util.load_dump很快,但还是比GreatSQL 8.0.32-24 自带的并行load data速度慢了一些,并行load data适用于频繁导入大批量数据的应用场景,性能可提升约20+倍。详情可见5-enhance/5-1-highperf-parallel-load.md · 万里数据库/GreatSQL-Manual - Gitee.com
4.5 参数解析
analyzeTables:可选参数 on/off/histogram;表加载完毕后,是否执行 ANALYZE TABLE 操作。默认是 off(不执行),histogram(只对有直方图信息的表执行)characterSet:字符集,无需显式设置,默认会从备份集中获取。createInvisiblePKs:是否创建隐式主键,默认从备份集中获取。deferTableIndexes:可选参数 off(不延迟)/fulltext(只延迟创建全文索引,默认值)/all(延迟创建所有索引);是否延迟(数据加载完毕后)创建二级索引。dryRun:试运行。此时只会打印备份信息,不会执行备份操作。excludeSchemas:忽略某些库的备份,多个库之间用逗号隔开excludeSchemas: ["db1", "db2"]excludeTables:忽略某些表的备份,表必须是 库名.表名 的格式,多个表之间用逗号隔开excludeTables: ["sbtest.sbtest1", "sbtest.sbtest2"]excludeUsers:忽略某些账号的备份,可指定多个账号。ignoreExistingObjects:是否忽略已经存在的对象,默认为 off。ignoreVersion:忽略 MySQL 的版本检测。默认情况下,要求备份实例和导入实例的大版本一致。includeSchemas:指定某些库的备份。includeTables:指定某些表的备份。includeUsers:指定某些账号的备份,可指定多个账号。loadData:是否导入数据,默认为 true。loadDdl:是否导入 DDL 语句,默认为 true。loadIndexes:与 deferTableIndexes 一起使用,用来决定数据加载完毕后,最后的二级索引是否创建,默认为 true。loadUsers:是否导入账号,默认为 false。注意,即使将 loadUsers 设置为 true,也不会导入当前正在执行导入操作的用户。progressFile:在导入的过程中,会在备份目录生成一个progressFile,用于记录加载过程中的进度信息,这个进度信息可用来实现断点续传功能。默认为 load-progress…progress。resetProgress:如果备份目录中存在progressFile,默认会从上次完成的地方继续执行。如果要从头开始执行,需将 resetProgress 设置为 true。该参数默认为 off。schema:将表导入到指定 schema 中,适用于通过 util.dumpTables 创建的备份。showMetadata:导入时是否打印一致性备份时的位置点信息。showProgress:是否打印进度信息。skipBinlog:是否设置 sql_log_bin=0 ,默认 false。这一点与 mysqldump、mydumper 不同,后面这两个工具默认会禁用 Binlog。threads:并发线程数,默认为 4。updateGtidSet:更新 GTID_PURGED。可设置:off(不更新,默认值), replace(替代目标实例的 GTID_PURGED), append(追加)。waitDumpTimeout:util.loadDump 可导入当前正在备份的备份集。处理完所有文件后,如果备份还没有结束(具体来说,是备份集中没有生成 @.done.json),util.loadDump 会报错退出,可指定 waitDumpTimeout 等待一段时间,单位秒。osBucketName:osNamespace,ociConfigFile,ociProfile,ociParManifest,ociParExpireTime:OCI 对象存储相关。osNamespace:OCI 对象存储相关。ociConfigFile:OCI 对象存储相关。ociProfile:OCI 对象存储相关。
4.6 使用注意事项
- 导入时,注意 max_allowed_packet 的限制,导入之前,需将目标实例的 local_infile 设置为 ON。
- 该工具属于客户端工具,生成的文件在客户端。
- 导出的时候,导出路径下不能有文件。
- 表上存在主键或唯一索引才能进行 chunk 级别的并行备份。字段的数据类型不限。不像 mydumper,分片键只能是整数类型。
- 对于不能进行并行备份的表,目前会备份到一个文件中。如果该文件过大,不用担心大事务的问题,util.loadDump 在导入时会自动进行切割。
- util.dumpInstance 只能保证 InnoDB 表的备份一致性。
- 默认不会备份 information_schema,mysql,ndbinfo,performance_schema,sys。
- 备份实例支持 GreatSQL/MySQL 5.6 及以上版本,导入实例支持 GreatSQL/MySQL 5.7 及以上版本。
- 备份的过程中,会将 BLOB 等非文本安全的列转换为 Base64,由此会导致转换后的数据大小超过原数据。
五、快速搭建MGR集群
可以用MySQL Shell for GreatSQL来搭建 MGR集群 或接管现有集群非常的方便快捷。加上GreatSQL针对MGR做了大量的改进和提升工作,进一步提升MGR的高可靠等级。
快捷的部署 + 好用的GreatSQL MGR为什么不用呢?
5.1 部署准备
| IP | 端口 | 角色 |
|---|---|---|
| 172.17.139.77 | 3306 | mgr1 |
| 172.17.139.77 | 3307 | mgr2 |
采用的是一个单机多实例的部署方式,如何部署单机多实例可以前往6-oper-guide/6-6-multi-instances.md · 万里数据库/GreatSQL-Manual - Gitee.com
接下来再把MySQL Shell for GreatSQL下载安装完成,即可开始部署。
注意!本次部署皆采用Shell 的 Python 模式
5.2 开始部署
利用MySQL Shell for GreatSQL构建MGR集群比较简单,主要有几个步骤:
- 检查实例是否满足条件。
- 创建并初始化一个集群。
- 逐个添加实例。
首先,用管理员账号 root 连接到第一个节点:
$ mysqlsh -S/data/GreatSQL/mgr01/mysql.sock root@localhost
MySQL Shell 8.0.25- 1
使用\s命令查看当前节点状态,确保连接正常可用
执行 dba.configure_instance() 命令开始检查当前实例是否满足安装MGR集群的条件,如果不满足可以直接配置成为MGR集群的一个节点:
GreatSQL Py > dba.configure_instance()
Configuring local MySQL instance listening at port 3306 for use in an InnoDB cluster...
This instance reports its own address as 172.17.139.77:3306
#提示当前的用户是管理员,不能直接用于MGR集群,需要新建一个账号
ERROR: User 'root' can only connect from 'localhost'. New account(s) with proper source address specification to allow remote connection from all instances must be created to manage the cluster.
1) Create remotely usable account for 'root' with same grants and password
2) Create a new admin account for InnoDB cluster with minimal required grants
3) Ignore and continue
4) Cancel
Please select an option [1]: 2 #这里选择2,即创建一个最小权限账号- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
接着输入要创建用户的用户名、密码即可
Please provide an account name (e.g: icroot@%) to have it created with the necessary privileges or leave empty and press Enter to cancel. Account Name: GreatSQL #用户名 Password for new account: #密码 Confirm password: #确认密码 applierWorkerThreads will be set to the default value of 4. The instance '172.17.139.77:3306' is valid to be used in an InnoDB cluster. Cluster admin user 'GreatSQL'@'%' created. The instance '172.17.139.77:3306' is already ready to be used in an InnoDB cluster. # 这个警告消息是告诉你正在使用的系统变量@@slave_parallel_workers已经被弃用,将在未来的版本中被移除,建议你使用新的变量名replica_parallel_workers来替换。 WARNING: '@@slave_parallel_workers' is deprecated and will be removed in a future release. Please use replica_parallel_workers instead. (Code 1287). Successfully enabled parallel appliers.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
完成检查并创建完新用户后,退出当前的管理员账户,并用新创建的MGR专用账户登入,准备初始化创建一个新集群:
GreatSQL Py > exit()
$ mysqlsh --uri GreatSQL@172.17.139.77:3306
MySQL Shell 8.0.25- 1
- 2
- 3
这时候就可以使用我们的dba工具了,定义一个变量名c,方便下面引用
GreatSQL 172.17.139.77:3306 ssl Py > c = dba.create_cluster('MGR1'); A new InnoDB cluster will be created on instance '172.17.139.77:3306'. Validating instance configuration at 172.17.139.77:3306... This instance reports its own address as 172.17.139.77:3306 Instance configuration is suitable. NOTE: Group Replication will communicate with other members using '172.17.139.77:33061'. Use the localAddress option to override. Creating InnoDB cluster 'MGR1' on '172.17.139.77:3306'... Adding Seed Instance... Cluster successfully created. Use Cluster.addInstance() to add MySQL instances. At least 3 instances are needed for the cluster to be able to withstand up to one server failure.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这就完成了MGR集群的初始化并加入第一个节点(引导节点)。接下来,用同样方法先用 root 账号分别登入到另外两个节点,完成节点的检查并创建最小权限级别用户(此过程略过...注意各节点上创建的用户名、密码都要一致),之后回到第一个节点,执行 addInstance() 添加另外两个节点。
GreatSQL 172.17.139.77:3306 ssl Py > c.add_instance('GreatSQL@172.17.139.77:3307');
#这里要指定MGR专用账号
...省略...
Please select a recovery method [C]lone/[A]bort (default Abort): Clone <-- 选择用Clone方式从第一个节点全量复制数据
Validating instance configuration at 172.17.139.77:3306...
...省略...
The instance '172.17.139.77:3306' was successfully added to the cluster.- 1
- 2
- 3
- 4
- 5
- 6
这样节点就加入成功了!用c.describe()看下集群状态,如果要显示更详细信息可以使用c.status()
GreatSQL 172.17.139.77:3306 ssl Py > c.describe() { "clusterName": "mgr1", "defaultReplicaSet": { "name": "default", "topology": [ { "address": "172.17.139.77:3306", "label": "172.17.139.77:3306", "role": "HA" }, { "address": "172.17.139.77:3307", "label": "172.17.139.77:3307", "role": "HA" } ], "topologyMode": "Single-Primary" } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
列出下DBA对象所有的命令:
GreatSQL 172.17.139.77:3306 ssl Py > \help dba*
Found several entries matching dba*- 1
dba:命令本身提供对集群管理和实例管理的高级功能的访问。dba.check_instance_configuration:检查GreatSQL实例的配置是否符合InnoDB集群的要求。dba.configure_instance:配置实例以加入InnoDB集群,调整设置以满足集群要求。dba.configure_local_instance:配置本地GreatSQL实例以便用于InnoDB集群。dba.configure_replica_set_instance:配置副本集实例以满足副本集的要求。dba.create_cluster:创建一个新的InnoDB集群。dba.create_replica_set:创建一个新的GreatSQL副本集。dba.delete_sandbox_instance:删除一个现有的沙箱实例。dba.deploy_sandbox_instance:在本地计算机上部署一个沙箱GreatSQL Server实例。dba.drop_metadata_schema:删除现有的InnoDB集群元数据模式。dba.get_cluster:获取现有的InnoDB集群的引用。dba.get_replica_set:取现有GreatSQL副本集的引用。dba.help:显示dba模块的帮助信息。dba.kill_sandbox_instance:杀死沙箱GreatSQL实例。dba.reboot_cluster_from_complete_outage:从完全停机状态重新启动InnoDB集群。dba.session:获取当前GreatSQL会话的引用。dba.start_sandbox_instance:启动沙箱GreatSQL实例。dba.stop_sandbox_instance:停止沙箱GreatSQL实例。dba.upgrade_metadata:升级集群的元数据模式以使其与当前版本的MySQL Shell for GreatSQL兼容。dba.verbose: 用于控制dba命令的详细输出。
如果要更详细的某个命令的帮助手册,则可以 \help 后接具体的命令:
GreatSQL 172.17.139.77:3306 ssl Py > \help dba.get_cluster我们GreatSQL社区有”深入浅出MGR系列文章“其中就有使用Shell部署[第四篇]MGR以及管理[第五篇]:
系列文章地址:GreatSQL-Doc: GreatSQL-Doc - Gitee.com
利用MySQL Shell安装部署MGR集群:https://mp.weixin.qq.com/s/51ESDPgeuXqsgib6wb87iQ
MGR管理维护:https://mp.weixin.qq.com/s/D5obkekTClZEdN2KQ9xiXg
有对MGR想了解的或深入学习的,都可以去阅读下。
六、总结
MySQL Shell for GreatSQL以其强大的功能、灵活性和先进的工具集,确实为数据库管理人员和开发者打开了全新的大门。从基本的数据库操作到复杂的集群管理。
对于想要充分利用 GreatSQL 功能的任何人来说,掌握MySQL Shell for GreatSQL都是一项必备技能。无论你是新手还是经验丰富的数据库专家,希望这篇文章都能为你的GreatSQL旅程提供宝贵的指导和灵感。
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:

社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群:
QQ群:533341697
微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。

