- 1Python简介及发展历史_python发展历程
- 2matlab实现五子棋,matlab编程(五子棋
- 3阿里云服务器中安装微擎
- 4给jQuery添加vue的响应式简单封装 2022-01-20_jquery实现vue3响应
- 5javaWab07(session&Cookie)
- 6ant-design-vue。下拉框a-select设置样式不显示的_a-select dropdownstyle
- 7flask 教程03--环境安装_安装flask及对应的requires
- 8Python迭代器基本方法iter()及其魔法方法__iter__()原理详解
- 9matlab对矩阵自相关,自相关矩阵和互相关矩阵的matlab实现
- 10vue项目生产环境打包项目时引入外部CDN优化项目
魔搭社区LLM模型部署实践, 以ChatGLM3为例(一)_魔搭选择cpu还是gpu
赞
踩
魔搭社区LLM模型部署实践, 以ChatGLM3为 例
本文以ChatGLM3-6B为例, 主要介绍在魔搭社区如何部署LLM, 主要包括如下内容:
● SwingDeploy - 云端部署, 实现零代码一键部署
● 多端部署 - MAC个人笔记本, CPU服务器
● 定制化模型部署 - 微调后部署
一 、 SwingDeploy - 云端部署, 零代码一键部署
魔搭社区SwingDeploy链接:https://modelscope.cn/my/modelService/deploy
魔搭社区SwingDeploy支持将模型从魔搭社区的模型库一键部署至用户阿里云账号的云资源上, 并根 据模型资源要求为您自动推荐最佳部署配置 。一键即可零代码创建模型部署任务, 并通过API方式调
用心仪的模型, 进行实时推理! 当前魔搭社区已经支持SwingDeploy已接入阿里云 FunctionCompute(FC) 、PAI-EAS两类可用于模型部署推理的云资源。
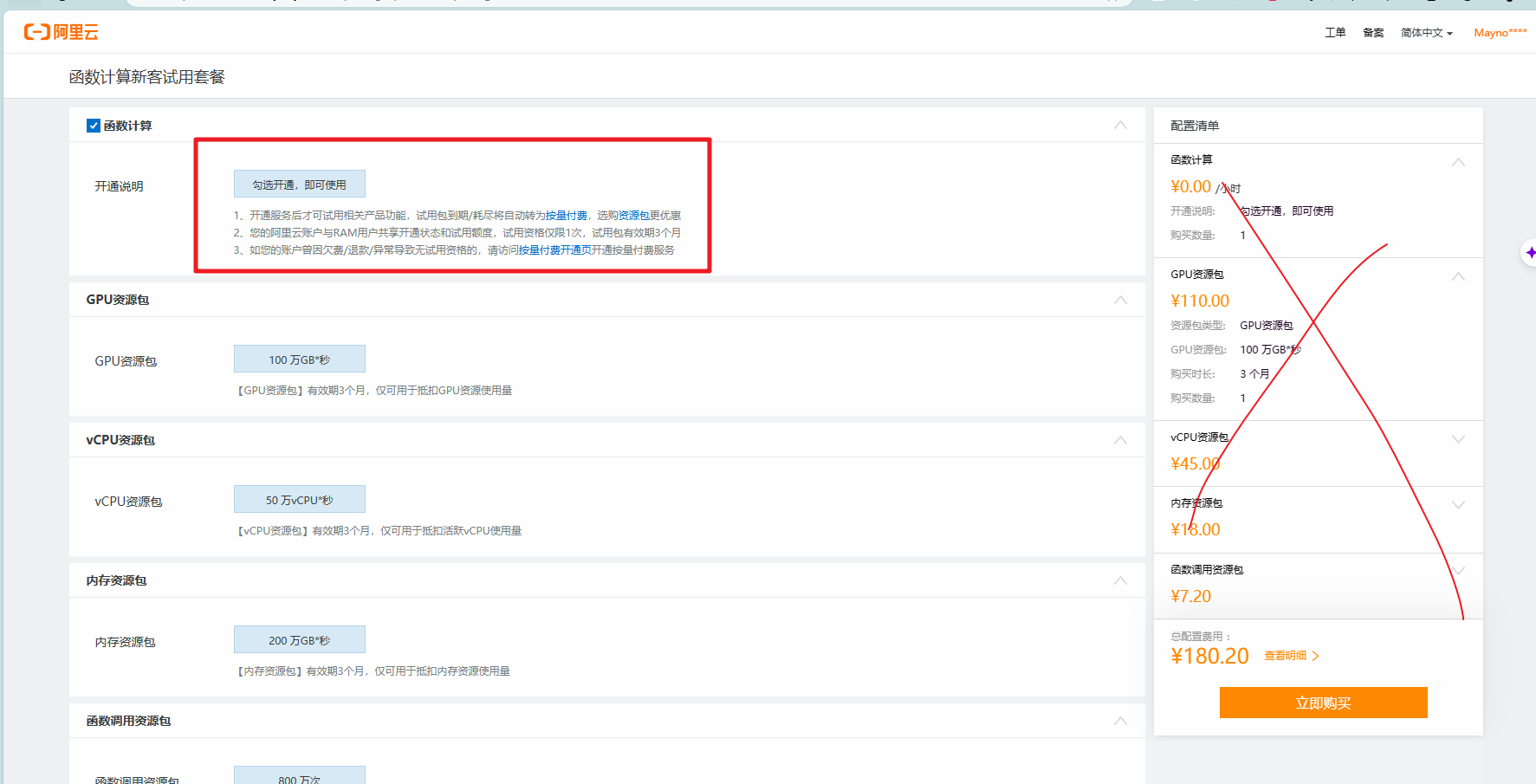
不用付费,勾选开通后跳转页面
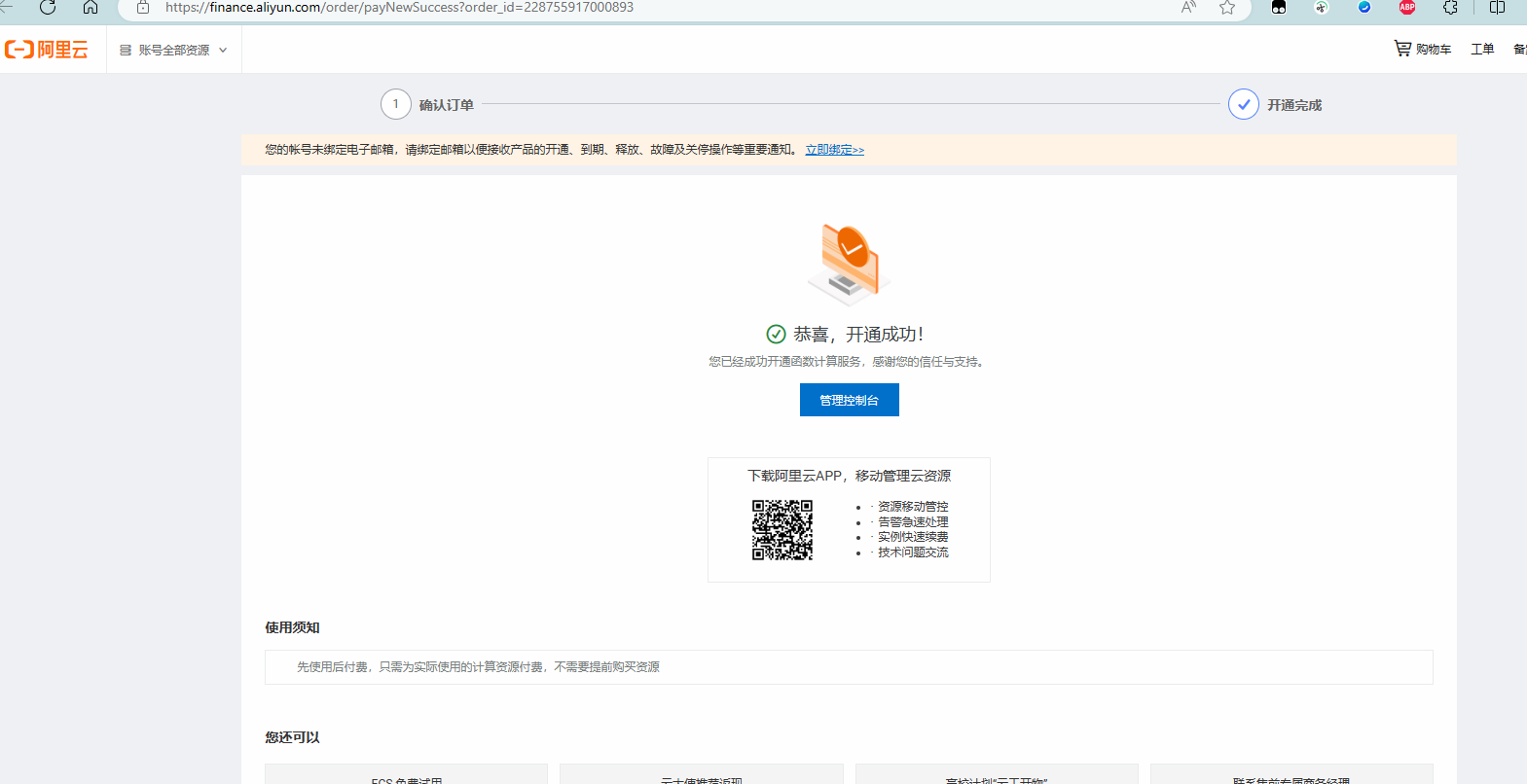
函数计算开通成功
使用SwingDeploy服务可以讲模型部署在云端功能强大的GPU上, 云端负责服务, 扩展, 保护和监控 模型服务, 可以免于运维和管理云上算力等基础设施 。当选择模型并部署时, 系统会选择对应的机器 配置 。按需使用可以在根据工作负载动态的减少资源, 节约机器使用成本 。同时从部署页面进入云资 源管理页面, 。。。。。。。
选择SwingDeploy部署模型, 选择模型, 如智谱AI提供的ChatGLM3, 系统会自动匹配该模型最新的 版本, 以及推荐的部署资源规格。
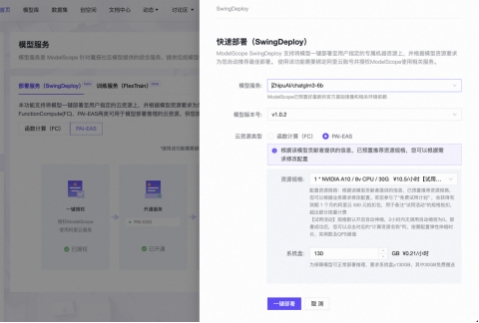
点击一键部署, 系统将从社区拉取模型, 并打包成镜像部署到指定配置的实例, 根据模型大小和实例 类型, 部署通常几分钟内能完成。
另外除了在ModelScope上能设置基础的部署配置以外, 部署完成以后, 也点击计算资源名称( 以 EAS为例), 进入云资源管理页面, 进行更多的操作, 比如支持扩缩容策略, 配置高速链接等。
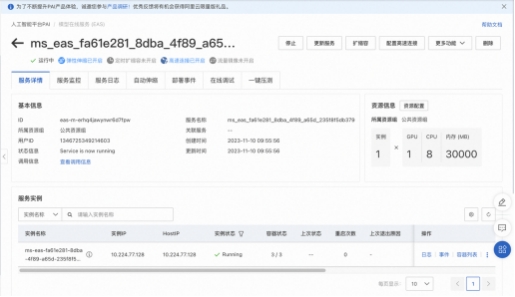
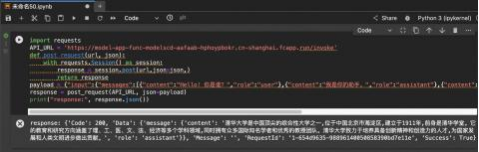
服务状态显示“部署成功”后, 点击立即使用, 可以复制Python代码直接进行服务的调用。
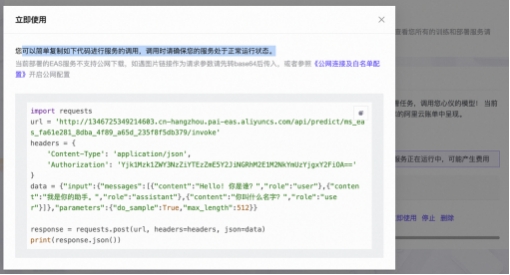
粘贴立即使用代码, 进入魔搭免费算力PAI-DSW, 选择CPU类型, 粘贴示例代码, 测试部署模型的推 理效果。