
- 1PS应该学哪些内容和技术?_ps主要学哪些内容
- 2修改选中_React native-IOS修改项目名与包名
- 3Unity Android 5.0上 JNI DETECTED ERROR IN APPLICATION: jclass is an invalid local reference
- 4宝塔服务的安装_宝塔安装命令
- 5【华为机试】2023年真题C卷(python)-内存冷热标记
- 6【Android】进程通信IPC——Messenger_fstack ipc message error
- 7计算机网络知识点_联网交换点 ixp 允许两个 isp 直接相连而不用经过第三个 isp。
- 8【鸿蒙开发】第十四章 Stage模型应用组件-任务Mission
- 9HTTP代理扫描的技术解析(HTTP代理扫描的技术原理和使用方法)
- 10RTSP/Onvif摄像机web直播遇到的时间戳问题导致的卡顿解决方案
如何画lda投影结果_FlyAI小课堂:隐含狄利克雷分布(LDA)(6)
赞
踩


在开始学习之前推荐大家可以多在FlyAI竞赛服务平台多参加训练和竞赛,以此来提升自己的能力。FlyAI是为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
目录
- LDA概述
- 基础知识
- LDA主题模型
- 总结
一句话简述:2003年提出的,LDA是一种无监督的词袋式隐含主题模型,LDA给出文档属于每个主题的概率分布,同时给出每个主题上词的概率分布。在文本主题识别、文本分类、文本相似度计算和文章相似推荐等方面都有应用。
一、LDA概述
在机器学习领域,LDA是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和 隐含狄利克雷分布(Latent Dirichlet Allocation)。本文的LDA仅指代Latent Dirichlet Allocation. LDA 在主题模型中占有非常重要的地位,常用来文本分类。
LDA是基于贝叶斯模型的,涉及到贝叶斯模型离不开"先验分布","数据(似然)"和"后验分布"三块。在贝叶斯学派中有:先验分布 + 数据(似然)= 后验分布
这点其实很好理解,因为这符合我们人的思维方式,比如你对好人和坏人的认知,先验分布为:100个好人和100个的坏人,即你认为好人坏人各占一半,现在你被2个好人(数据)帮助了和1个坏人骗了,于是你得到了新的后验分布为:102个好人和101个的坏人。现在你的后验分布里面认为好人比坏人多了。这个后验分布接着又变成你的新的先验分布,当你被1个好人(数据)帮助了和3个坏人(数据)骗了后,你又更新了你的后验分布为:103个好人和104个的坏人。依次继续更新下去
二、基础知识
2.1 词袋模型
LDA 采用词袋模型。所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现,而不考虑其出现的顺序。在词袋模型中,"我喜欢你"和"你喜欢我"是等价的。与词袋模型相反的一个模型是n-gram,n-gram考虑了词汇出现的先后顺序。
2.2 二项分布
伯努利分布是只有两种可能结果的单次随机试验,二项分布(Binomial distribution)是n重伯努利试验成功次数的离散概率分布,即为X ~ B(n, p). 概率密度公式为:
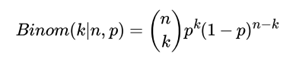
2.3 二项分布与Beta分布
beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出所有概率出现的可能性大小。
我们希望这个先验分布和数据(似然)对应的二项分布集合后,得到的后验分布在后面还可以作为先验分布!就像上面例子里的"102个好人和101个的坏人",它是前面一次贝叶斯推荐的后验分布,又是后一次贝叶斯推荐的先验分布。也即是说,我们希望先验分布和后验分布的形式应该是一样的,这样的分布我们一般叫共轭分布。在我们的例子里,我们希望找到和二项分布共轭的分布。二项分布共轭的分布其实就是Beta分布。Beta分布的表达式为:
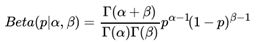
其中 是Gamma函数,满足 Γ(x) = (x − 1)!
仔细观察Beta分布和二项分布,可以发现两者的密度函数很相似,区别仅仅在前面的归一化的阶乘项。那么它如何做到先验分布和后验分布的形式一样呢?后验分布 P (p|n, k, α, β)推导如下:
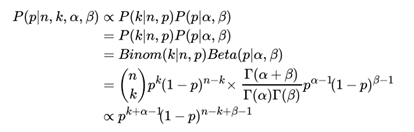
将上面最后的式子归一化以后,得到我们的后验概率为:
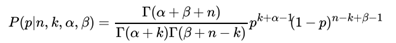
可见我们的后验分布的确是Beta分布,而且我们发现:
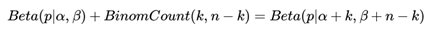
这个式子完全符合我们在上一节好人坏人例子里的情况,我们的认知会把数据里的好人坏人数分别加到我们的先验分布上,得到后验分布,Beta分布 Beta(p|α, β)的期望:
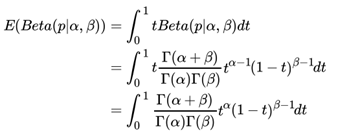
由于上式最右边的乘积对应Beta分布Beta(p|α + 1, β) ,因此有
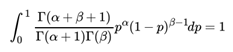
这样我们的期望可以表达为:

这个结果也很符合我们的思维方式。
2.4 多项分布
多项式分布(Multinomial Distribution)是二项式分布的推广。二项式做n次伯努利实验,规定了每次试验的结果只有两个,如果现在还是做n次试验,只不过每次试验的结果可以有多k个,且k个结果发生的概率互斥且和为1,则发生其中一个结果X次的概率就是多项式分布。概率密度函数为:
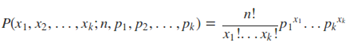
2.5. 多项分布与Dirichlet 分布
现在我们回到上面好人坏人的问题,假如我们发现有第三类人,不好不坏的人,这时候我们如何用贝叶斯来表达这个模型分布呢?之前我们是二维分布,现在是三维分布。由于二维我们使用了Beta分布和二项分布来表达这个模型,则在三维时,以此类推,我们可以用三维的Beta分布来表达先验后验分布,三项的多项分布来表达数据(似然)。
三项的多项分布好表达,我们假设数据中的第一类有 m1个好人,第二类有 m2个坏人,第三类为m3=n-m1-m2 个不好不坏的人,对应的概率分别为p1, p2, p3 = 1 − p1 − p2 ,则对应的多项分布为:
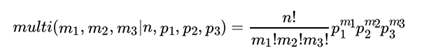
那三维的Beta分布呢?超过二维的Beta分布我们一般称之为狄利克雷(以下称为Dirichlet )分布。也可以说Beta分布是Dirichlet 分布在二维时的特殊形式。从二维的Beta分布表达式,我们很容易写出三维的Dirichlet分布如下:
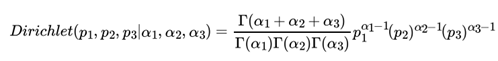
同样的方法,我们可以写出4维,5维,。。。以及更高维的Dirichlet 分布的概率密度函数。为了简化表达式,我们用向量来表示概率和计数, 。
一般意义上的K维Dirichlet 分布表达式为:
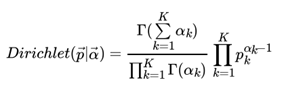
多项分布和Dirichlet 分布也满足共轭关系,这样我们可以得到和上一节类似的结论:
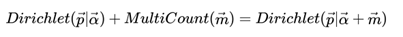
对于Dirichlet 分布的期望,也有和Beta分布类似的性质:
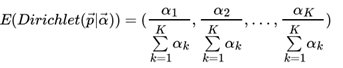
三、LDA主题模型
3.1 LDA的特点:
- 它是一种无监督的贝叶斯模型。
- 是一种主题模型,它可以将文档集中的每篇文档按照概率分布的形式给出。
- 是一种无监督学习,在训练时不需要手工标注的训练集,需要的是文档集和指定主题的个数。
- 是一种典型的词袋模型,它认为一篇文档是由一组词组成的集合,词与词之间没有顺序和先后关系。
3.1 LDA的简单理解
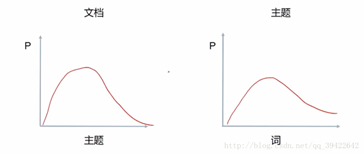
同一主题下,某个词出现的概率,以及同一文档下,某个主题出现的概率,两个概率的乘积,可以得到某篇文档出现某个词的概率,我们在训练的时候,只需要调整这两个分布。具体如下图所示
LDA生成文档的流程如下:
- 按照先验概率p(di)选择一篇文档di
- 从Dirichlet分布α中取样生成文档di的主题分布θi,主题分布θi由超参数为α的Dirichlet分布生成
- 从主题的多项式分布θi中取样生成文档di第 j 个词的主题zi,j
- 从Dirichlet分布β中取样生成主题zi,j对应的词语分布ϕzi,j,词语分布ϕzi,j由参数为β的Dirichlet分布生成
- 从词语的多项式分布ϕzi,j中采样最终生成词语ωi,j
3.2 LDA的数学理解
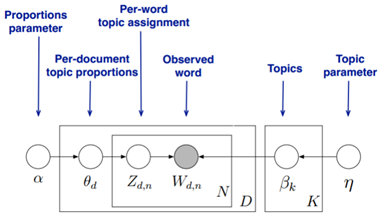
1)上图从:
文档主题的先验分布(狄利克雷分布)和每一个主题的多项式分布
LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档d , 其主题分布 为:
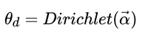
其中α 为分布的超参数,是一个K维向量。K代表文档中主题词的个数。
对于数据中任一一篇文档 d中的第 n个词,我们可以从主题分布 中得到它的主题编号 的分布为:
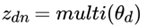
理解LDA主题模型的主要任务就是理解上面的这个模型。这个模型里,我们有 M个文档主题的Dirichlet分布,而对应的数据有M个主题编号的多项分布。
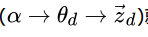
就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。
如果在第d个文档中,第k个主题的词的个数为: , 则对应的多项分布的计数可以表示为
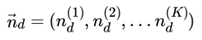
利用Dirichlet-multi共轭,得到 的后验分布为:
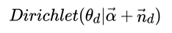
2)上图从 :
主题中词的先验分布(狄利克雷分布)和每一个词的多项式分布。
LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题 k , 其词分布为:
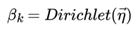
其中,η 为分布的超参数,是一个V 维向量。 V代表词汇表里所有词的个数
而对于该主题编号,得到我们看到的词 的概率分布为
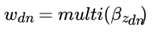
同样的道理,对于主题与词的分布,我们有 个主题与词的Dirichlet分布,而对应的数据有 个主题编号的多项分布
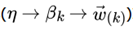
就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的主题词的后验分布。
如果在第k个主题中,第v个词的个数为:: , 则对应的多项分布的计数可以表示为
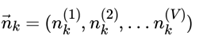
利用Dirichlet-multi共轭,得到 的后验分布为:
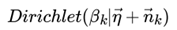
由于主题产生词不依赖具体某一个文档,因此文档主题分布和主题词分布是独立的。理解了上面这M+K组Dirichlet-multi共轭,就理解了LDA的基本原理了
具体的LDA模型求解采用Gibbs采样算法,现成的库可以用gensim,gensim.models.ldamodel.LdaModel()类可以生成LDA模型。
四、总结
LDA可以看作是由四个概率分布组成的(两个狄利克雷分布和多项式分布),也可以看作是两个狄利克雷-多项式共轭分布组成的。所以这四个概率分布如下:
- 第一个狄利克雷分布生成主题分布模型,且该主题分布模型服从多项式分布(相当于主题分布有多种)
- 第一个多项式分布用来生成某一个主题(获得某一个确定的主题分布之后就可以获得确定的主题)
- 第二个狄利克雷分布生成词分布模型,且该词服从多项式分布(相当于词分布有多种)
- 第二个多项式分布用来生成某一个词(获得某一个确定的词分布之后就可以获得确定的词,该确定的词分布是和确定的主题有关的)
4.1 补充说明:
1) LDA后可以继续对不同文本进行基于隐含主题的分类,聚类等
2)文档-主题分布和主题-词分布是独立的,也就是说,主题-词分布并不依赖某一个具体的文档,而对应的是语料集中的主题词分布。所以这里没有表述成"这篇文档的主题词分布".
3)P(文档-主题)是狄利克雷分布,采样确定文档,得到P(主题)是多项式分布,对P(主题)进行采样得到确定的主题z;
P(主题-词)是狄利克雷分布,根据已经确定的z,得到P(词)是多项式分布,对P(词)进行采样得到确定的词w
4)对于任何一个文档d,在先验分布Dir(a)采样得到θd(这里是一个K维向量,代表每个主题的概率),由这些概率得到主题分布(多项式分布),再由这个多项式分布采样得到第n个词的主题编号Zd,n(这个主题编号为一个值,而不是向量形式)
对于任何一个主题t,而在先验分布Dir(η)中采样得到βt(一个V维度向量,代表每个词的概率),由这些概率得到词分布(多项式分布),这样假设一共K个主题,β就一共有K个。现在有了文档d的第n个词的主题编号Zd,n(他属于K个β中的一个)对应就可以生成文档d的第n个词
4.2 常见疑惑
1)"第d个文档中,第k个主题的词的个数为:n(k)d" 中n(k)d如何计算得到呢。
答:文档d中的主题分布符合Dirichlet分布,然后Gibbs采样得到各个主题的概率,进一步根据文档d中词的总数N,乘以概率得到每个主题的词的个数
2)可以把LDA理解为朴素贝叶斯模型的一种加强吗?能简要介绍下二者的区别和各自优缺点吗?
答:两个算法都用到了一些贝叶斯学派的理论。如果LDA是用Gibbs采样求解,那么只用到了很少的贝叶斯学派的理论,如果是LDA变分推断算法,那么就完全是贝叶斯学派的思路了。
两者的共性就是都用到了贝叶斯的先验分布,后验分布和似然的概念。两者都经常用于NLP文本分析。
不过一个用于监督学习的分类,另一个用于非监督学习的主题模型寻找,要解决的问题差异还是很大的。
3)现在语料里面有很多不同领域的语料,我想对语料进行分类,比如说政治领域 体育领域 社会领域 然后学习的过程中将这些个领域信息成为先验知识 我该如何去加这个约束呢?
答:LDA的主题模型是隐含的主题,并不能直接将主题映射成你自己定义的政治领域 体育领域 社会领域等。所以你是没有办法直接加这个LDA约束的,建议尝试标记数据,用分类模型来解决你的问题
参考文献
【1】beta分布:https://blog.csdn.net/a358463121/article/details/52562940
文本主题模型之LDA(一) LDA基础www.cnblogs.com
更多精彩内容请访问FlyAI-AI竞赛服务平台;为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台;每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
挑战者,都在FlyAI!!!

