
- 1【计算机使用技能积累】双系统卸载Ubuntu,释放磁盘并合并分区_ubuntu16.04 双分区合并
- 2JAVA中的异常处理_java异常处理
- 355.常用shell之 df - 显示磁盘使用情况 的用法及衍生用法
- 4微信小程序:小程序服务器域名配置合法域名_微信小程序要求请求的域名必须在小程序的后台管理中配置为合法域名才能正常访问。
- 5网页视频下载(TS流下载合成)_ts视频下载
- 6python3多线程实战(python3经典编程案例)_python3 多线程
- 7Anaconda 如何切换Python版本 + Pycharm的设置_anaconda切换python
- 8Android12 ---- Material You 应用_com.google.android.material:material
- 9最小二乘法的一般形式和矩阵形式原理推导和代码实现_最小二乘矩阵迭代
- 1002_Pandas基本使用
详解ResNet(深度残差网络)
赞
踩
引言
深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件,让我们先看一下ResNet在ILSVRC和COCO 2015上的战绩:

ResNet取得了5项第一,并又一次刷新了CNN模型在ImageNet上的历史:
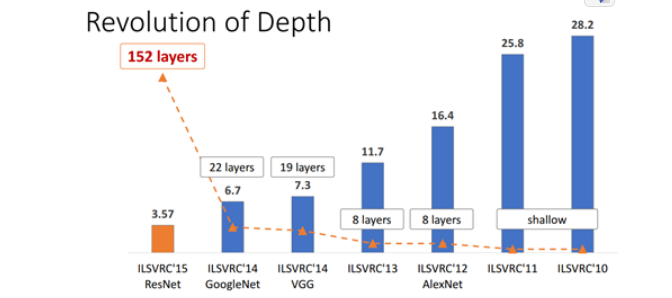
ResNet的作者何凯明也因此摘得CVPR2016最佳论文奖,当然何博士的成就远不止于此,感兴趣的可以去搜一下他后来的辉煌战绩。那么ResNet为什么会有如此优异的表现呢?其实ResNet是解决了深度CNN模型难训练的问题,从图2中可以看到14年的VGG才19层,而15年的ResNet多达152层,这在网络深度完全不是一个量级上,所以如果是第一眼看这个图的话,肯定会觉得ResNet是靠深度取胜。事实当然是这样,但是ResNet还有架构上的trick,这才使得网络的深度发挥出作用,这个trick就是残差学习(Residual learning)。下面详细讲述ResNet的理论及实现。
深度网络的退化问题
从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果,从图2中也可以看出网络越深而效果越好的一个实践证据。但是更深的网络其性能一定会更好吗?实验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。这个现象可以在图3中直观看出来:56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。

残差学习
深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。好吧,你不得不承认肯定是目前的训练方法有问题,才使得深层网络很难去找到一个好的参数。
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为 H ( x ) H(x) H(x)时其学习到的特征记为 F ( x ) = H ( x ) − x F(x) = H(x)-x F(x)=H(x)−x ,现在我们希望其可以学习到残差 F ( x ) + x F(x)+x F(x)+x,这样其实原始的学习特征是 [公式] 。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图4所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。

其中 x l x_l xl和 x l + 1 x_{l+1} xl+1分别表示的是第 l l l个残差单元的输入和输出,注意每个残差单元一般包含多层结构。 F F F 是残差函数,表示学习到的残差,而 h ( x l ) = x l h(x_l) = x_l h(xl)=xl表示恒等映射, f f f 是ReLU激活函数。基于上式,我们求得从浅层 l l l 到深层 L L L的学习特征为:
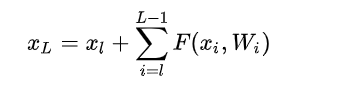

式子的第一个因子
∂
l
o
s
s
∂
x
L
\frac{\partial{loss}}{\partial{x_L}}
∂xL∂loss 表示的损失函数到达
L
L
L 的梯度,小括号中的1表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
ResNet的网络结构
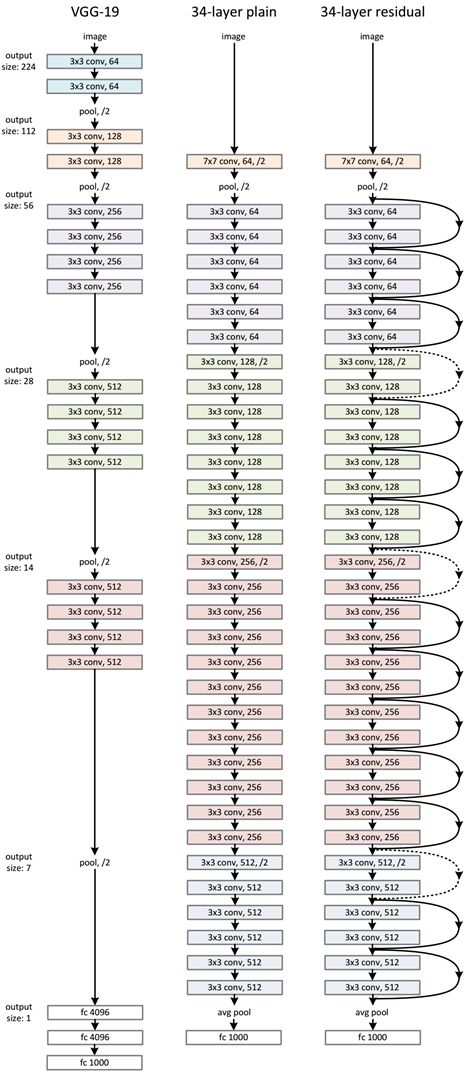
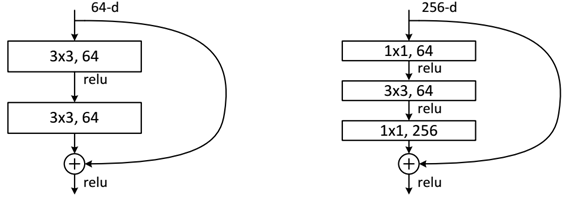
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。

作者对比18-layer和34-layer的网络效果,如图7所示。可以看到普通的网络出现退化现象,但是ResNet很好的解决了退化问题。


ResNet的TensorFlow实现
这里给出ResNet50的TensorFlow实现,模型的实现参考了Caffe版本的实现,核心代码如下:
class ResNet50(object): def __init__(self, inputs, num_classes=1000, is_training=True, scope="resnet50"): self.inputs =inputs self.is_training = is_training self.num_classes = num_classes with tf.variable_scope(scope): # construct the model net = conv2d(inputs, 64, 7, 2, scope="conv1") # -> [batch, 112, 112, 64] net = tf.nn.relu(batch_norm(net, is_training=self.is_training, scope="bn1")) net = max_pool(net, 3, 2, scope="maxpool1") # -> [batch, 56, 56, 64] net = self._block(net, 256, 3, init_stride=1, is_training=self.is_training, scope="block2") # -> [batch, 56, 56, 256] net = self._block(net, 512, 4, is_training=self.is_training, scope="block3") # -> [batch, 28, 28, 512] net = self._block(net, 1024, 6, is_training=self.is_training, scope="block4") # -> [batch, 14, 14, 1024] net = self._block(net, 2048, 3, is_training=self.is_training, scope="block5") # -> [batch, 7, 7, 2048] net = avg_pool(net, 7, scope="avgpool5") # -> [batch, 1, 1, 2048] net = tf.squeeze(net, [1, 2], name="SpatialSqueeze") # -> [batch, 2048] self.logits = fc(net, self.num_classes, "fc6") # -> [batch, num_classes] self.predictions = tf.nn.softmax(self.logits) def _block(self, x, n_out, n, init_stride=2, is_training=True, scope="block"): with tf.variable_scope(scope): h_out = n_out // 4 out = self._bottleneck(x, h_out, n_out, stride=init_stride, is_training=is_training, scope="bottlencek1") for i in range(1, n): out = self._bottleneck(out, h_out, n_out, is_training=is_training, scope=("bottlencek%s" % (i + 1))) return out def _bottleneck(self, x, h_out, n_out, stride=None, is_training=True, scope="bottleneck"): """ A residual bottleneck unit""" n_in = x.get_shape()[-1] if stride is None: stride = 1 if n_in == n_out else 2 with tf.variable_scope(scope): h = conv2d(x, h_out, 1, stride=stride, scope="conv_1") h = batch_norm(h, is_training=is_training, scope="bn_1") h = tf.nn.relu(h) h = conv2d(h, h_out, 3, stride=1, scope="conv_2") h = batch_norm(h, is_training=is_training, scope="bn_2") h = tf.nn.relu(h) h = conv2d(h, n_out, 1, stride=1, scope="conv_3") h = batch_norm(h, is_training=is_training, scope="bn_3") if n_in != n_out: shortcut = conv2d(x, n_out, 1, stride=stride, scope="conv_4") shortcut = batch_norm(shortcut, is_training=is_training, scope="bn_4") else: shortcut = x return tf.nn.relu(shortcut + h)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
完整实现可以参见GitHub。
总结
ResNet通过残差学习解决了深度网络的退化问题,让我们可以训练出更深的网络,这称得上是深度网络的一个历史大突破吧。也许不久会有更好的方式来训练更深的网络,让我们一起期待吧!
这里仅仅是转载,原文在
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/195892
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

