
- 1没有“安卓成份“的鸿蒙还能行吗?
- 2数据分析-Pandas如何观测数据的中心趋势度
- 3Win10系统- 远程桌面使用及出现的 问题_远程连接凭据密码是什么
- 4vue中的插槽详细介绍_ant design of vue的树结构如何使用插槽
- 5iOS-组件化 —— 路由设计思路分析_ios 组件化 —— 路由设计思路分析
- 6鸿蒙 Scroll 页面滑动,顶部慢慢出现顶部搜索框_鸿蒙搜索框设计
- 7什么是生成式AI系统?
- 8set android.defaultConfig.javaCompileOptions.annotationProcessorOptions.includeCompileClasspath = t
- 9微信小程序--分享如何与ibeacon蓝牙信标建立联系
- 10软件测试周刊(第14期):质量保障的趋势
Amazon SageMaker 机器学习之旅的助推器
赞
踩
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道。
一、前言
在当今的数字化时代,人工智能和机器学习已经成为推动社会进步的重要引擎。亚马逊云科技在 2023 re:Invent 全球大会上,宣布推出五项 Amazon SageMaker 新功能:

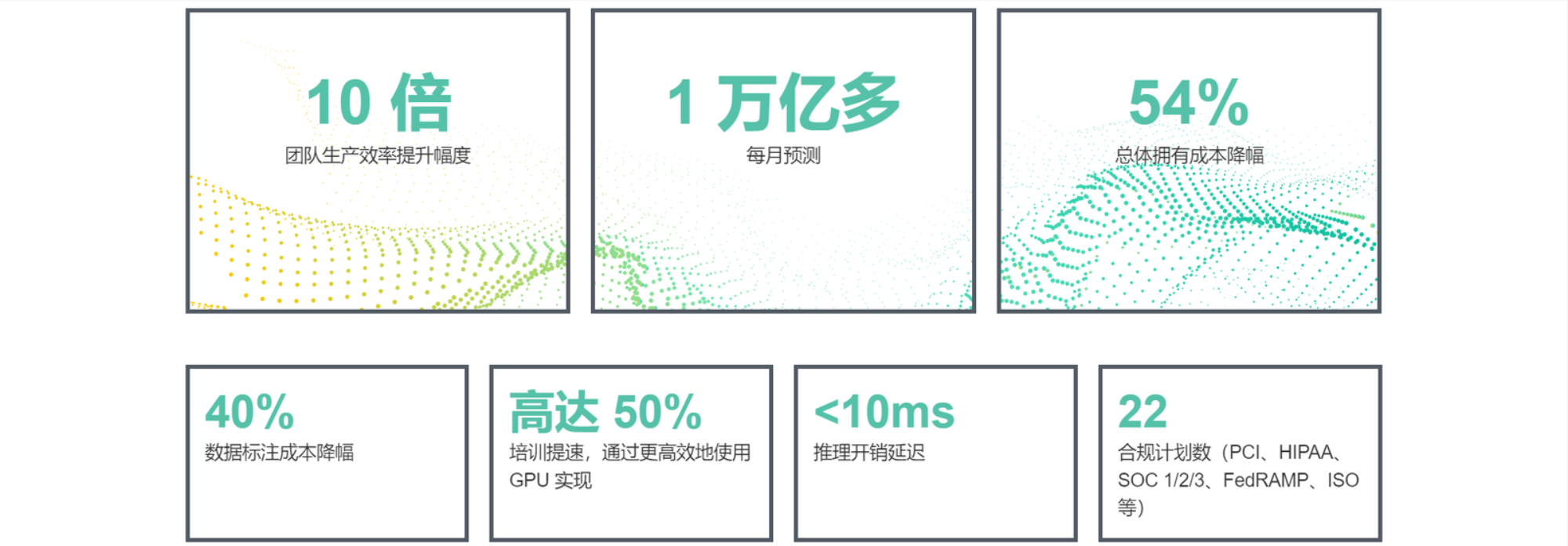
Amazon SageMaker HyperPod 通过为大规模分布式训练提供专用的基础架构,将基础模型的训练时间缩短了高达40%;
-
Amazon SageMaker Inference 通过优化加速器的使用,平均降低50%的基础模型部署成本,并平均缩短了20%的延迟时间;
-
Amazon SageMaker Clarify 能够让客户更轻松地根据支持负责任的 AI 的参数,迅速评估和选择基础模型;
-
Amazon SageMaker Canvas 功能帮助客户通过自然语言指令加速数据准备,并仅需几次点击即可使用基础模型进行模型定制;
-
宝马集团(BMW)、缤客(Booking.com)、Hugging Face、Perplexity、Salesforce、Stability AI 和先锋领航集团(Vanguard)等已开始使用新的 Amazon SageMaker 功能
旨在帮助客户加速构建、训练和部署大型语言模型和其他基础模型,这些新功能将助力用户更快的进行模型开发和应用部署,提供更强大的工具和资源。本文将对 Amazon SageMaker 进行实际体验,以揭示其如何助力机器学习之旅。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
二、Amazon SageMaker 概述

通过传统的方式创建机器学习模型,开发人员需要从数据准备过程开始,经过可视化、选择算法、设置框架、训练模型、调整数百万个可能的参数、部署模型并监视其性能,这个过程往往需要重复多次,非常繁琐且特别耗时。
以下是创建机器学习模型的典型工作流程:
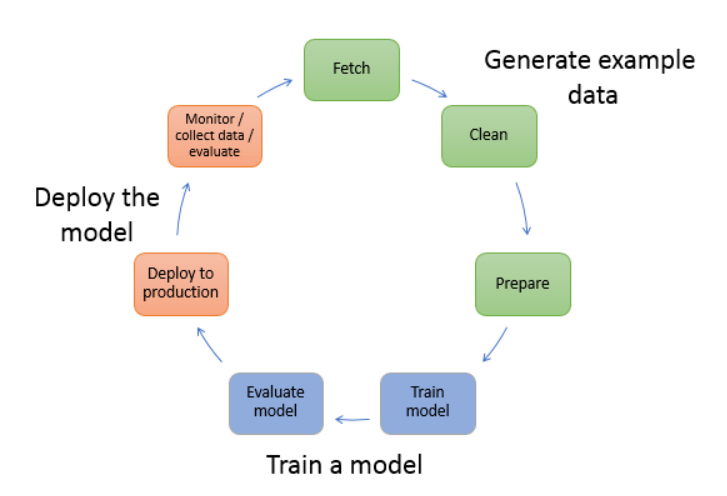
那么 Amazon SageMaker 是一项完全托管的服务,它提供了一站式的机器学习开发环境,从数据准备、模型训练到模型部署,所有这些都可以在云端完成,十分方便快捷,能够带来巨大的效能提升。以下是 Amazon SageMaker 提供的几种机器学习开发环境:
-
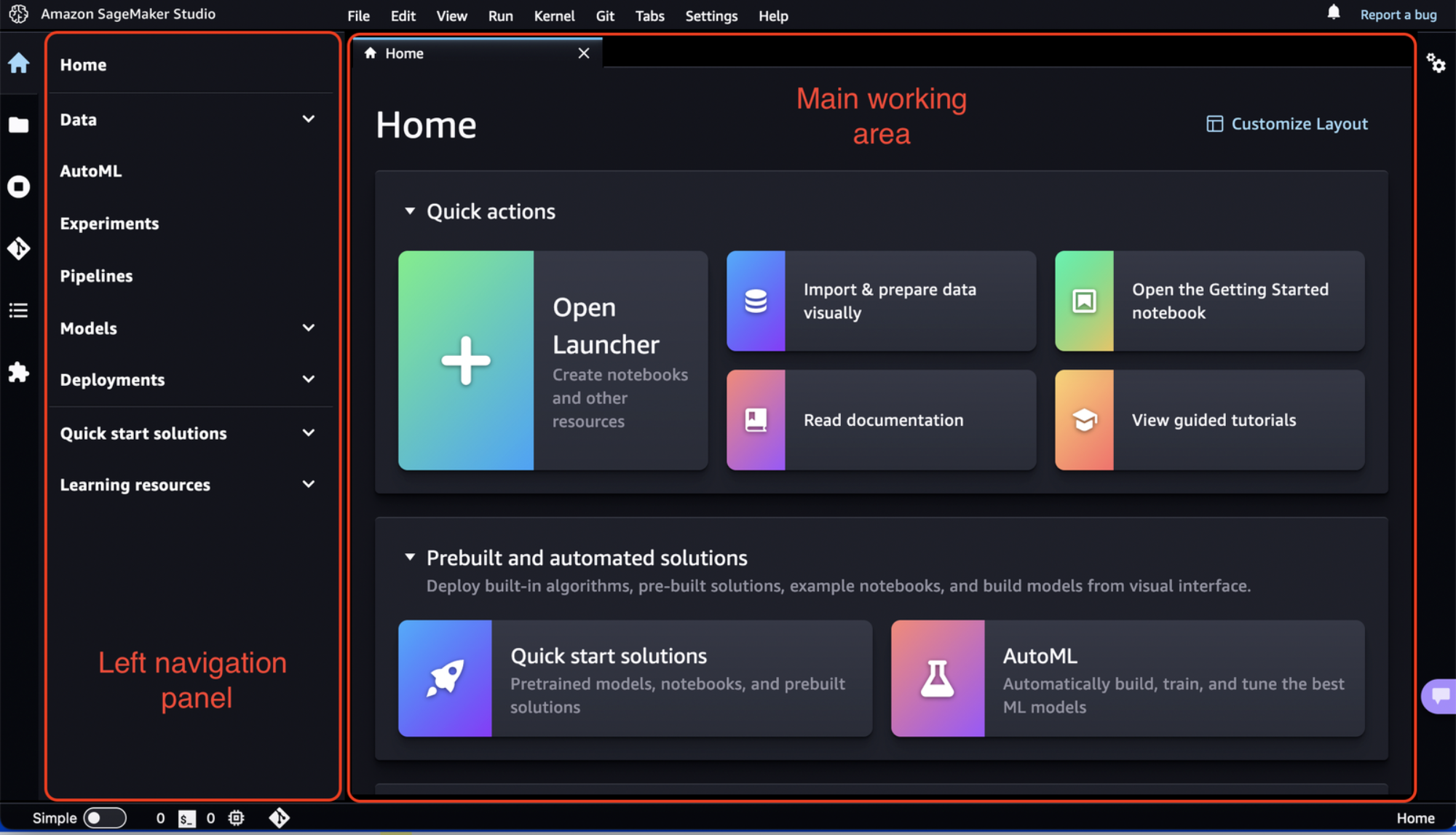
Amazon SageMaker Studio:允许您构建、训练、调试、部署和监控您的机器学习模型。
-
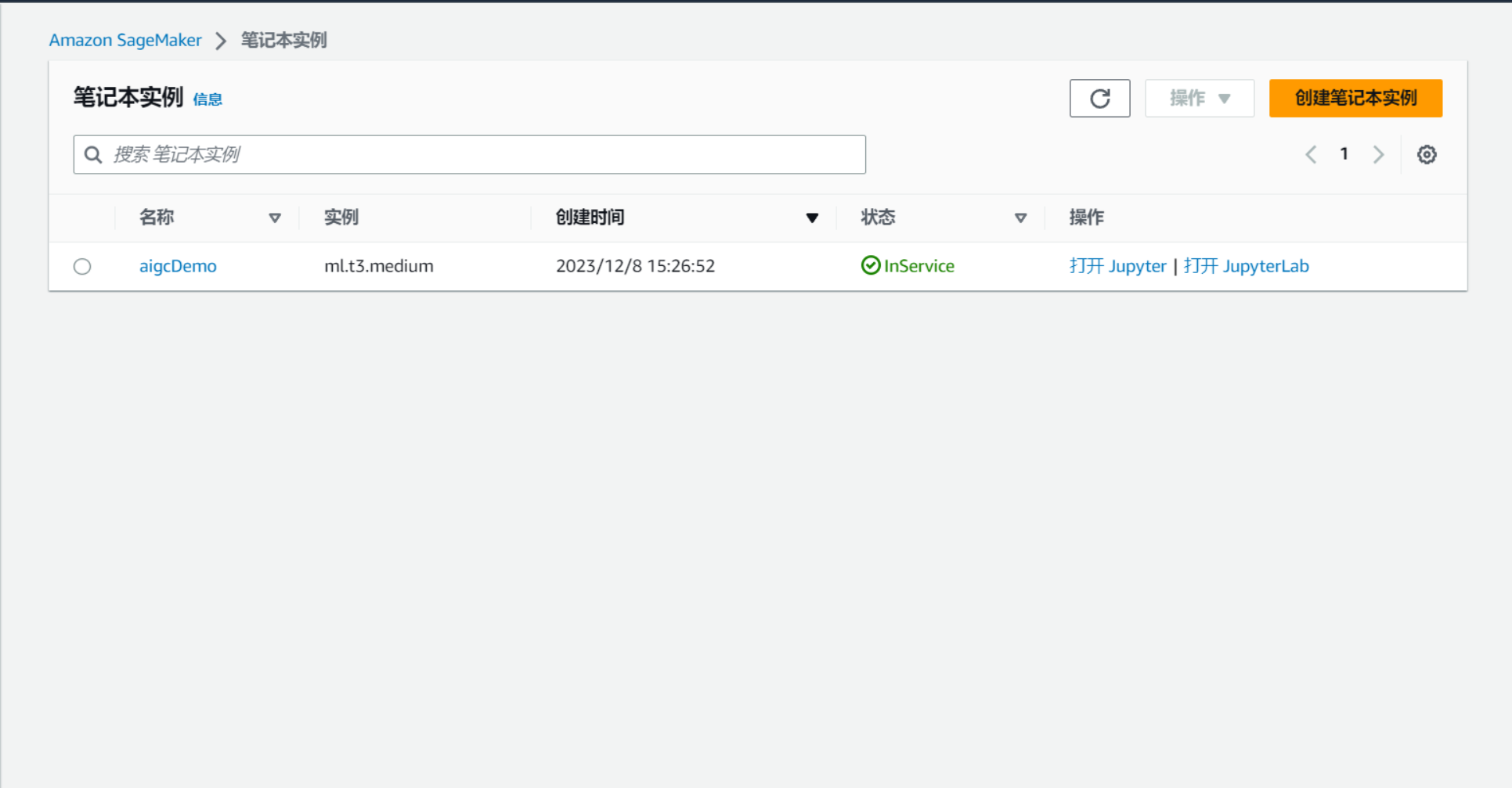
亚马逊 SageMaker 笔记本实例:允许您准备和处理数据,以及从运行 Jupyter Notebook 应用程序的计算实例训练和部署机器学习模型。
-
Amazon SageMaker Studio Lab:Studio Lab 是一项免费服务,可让您在基于开源的环境中访问亚马逊云科技计算资源 JupyterLab,无需亚马逊云科技账户。
-
Amazon SageMaker Canvas:使您能够使用机器学习来生成预测,而无需编写代码。
-
Amazon SageMaker 地理空间:使您能够构建、训练和部署地理空间模型。
-
Amazon rStud ioSageMaker:rStudio 是 R 的 IDE,它具有支持直接执行代码的控制台、语法突出显示编辑器以及用于绘图、历史记录、调试和工作区管理的工具。
对于不想处理硬件、软件和基础架构等方面问题,希望简化操作机器学习模型开发流程,灵活选择算法和模型及资源以满足不同业务需求的,可以放心的选择 Amazon SageMaker!
三、Amazon SageMaker 在生产环境中的应用优势
在机器学习的应用过程中,将模型部署到生产环境是一项关键任务。生产环境不仅要求模型具有高性能,还要求模型具备高可用性和可扩展性。本文将深入探讨 Amazon SageMaker 在生产环境中应用的优势和挑战。
-
高性能:Amazon SageMaker 可以利用亚马逊云科技的计算资源,为用户提供高性能的机器学习模型训练和部署。它支持多种深度学习框架,包括 TensorFlow、PyTorch 等,可以满足不同类型的应用需求。
-
高可用性:通过自动扩展群集和跨多个可用性区域的数据存储,Amazon SageMaker 可以保证模型的高可用性。这意味着即使在流量高峰期或服务器故障的情况下,模型也能保持稳定运行。
-
自动化:Amazon SageMaker 提供了自动化的模型部署工具,可以自动将训练好的模型转换为生产就绪的版本,并部署到云端或边缘设备上。这大大降低了模型部署的复杂性和人工错误率。
-
安全性:Amazon SageMaker 提供了完善的安全性控制,包括数据加密、访问控制和安全审计等功能,可以保护用户的数据和模型的安全性。
四、Amazon SageMaker 如何把机器学习的能力赋能每一个企业角色
相信对于很多计算机领域的开发者来说,利用 Amazon SageMaker 来进行机器学习的构建应该是轻车熟路,那么对于非计算机领域背景的人能够使用 Amazon SageMaker 的强大功能来进行机器学习并且应用到他们的日常业务场景中呢,答案是肯定的。Amazon SageMaker Canvas 使您能够使用机器学习来生成预测,而无需编写任何代码。接下来,我将会以公开的糖尿病患者数据集(包含历史数据),这个数据集包括超过15个与患者和医院结果相关的特征,共计16,000行数据量,使用 Amazon SageMaker Canvas 零代码来构建模型预测高危糖尿病患者是否有可能在30天内、30天后或根本不入院。接下来我来指导大家怎么操作和使用:
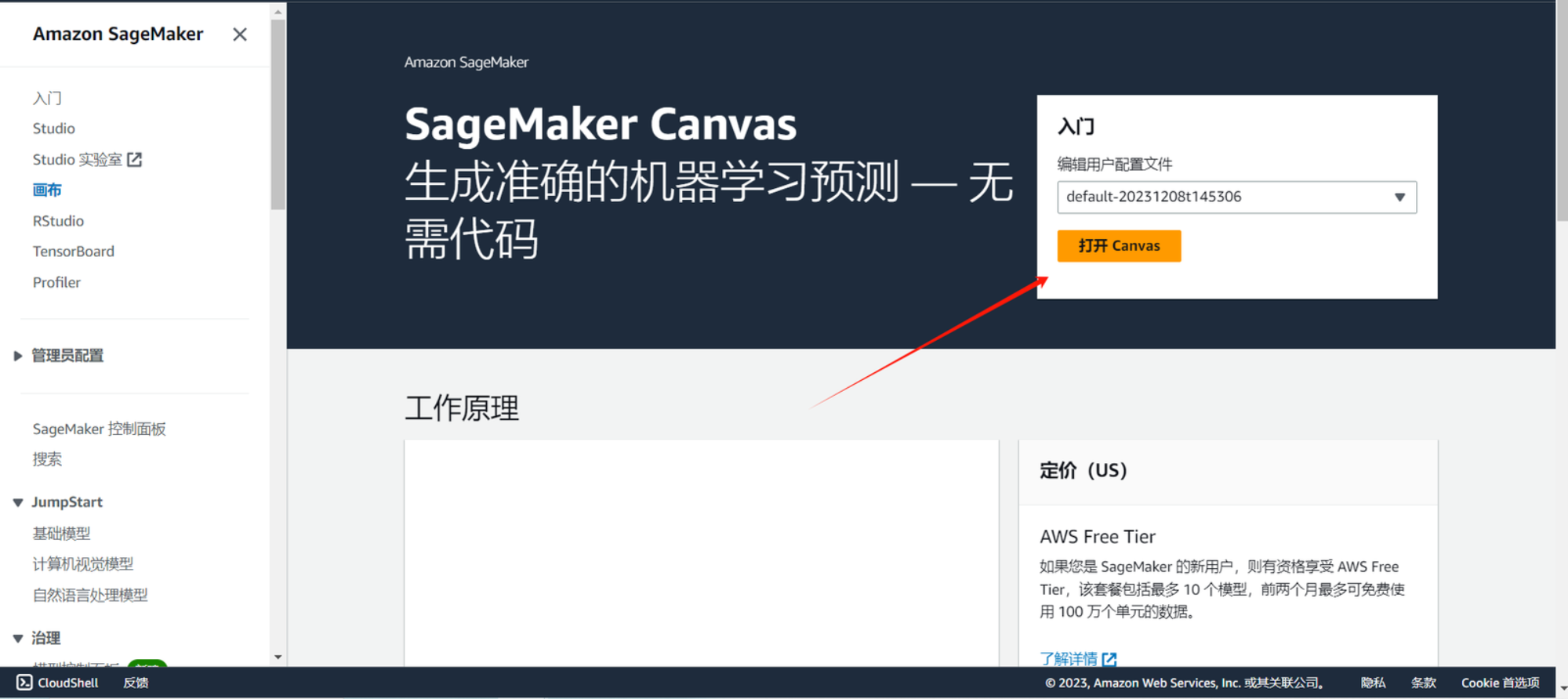
1、在 Amazon SageMaker 控制台选择画布,并点击 canvas
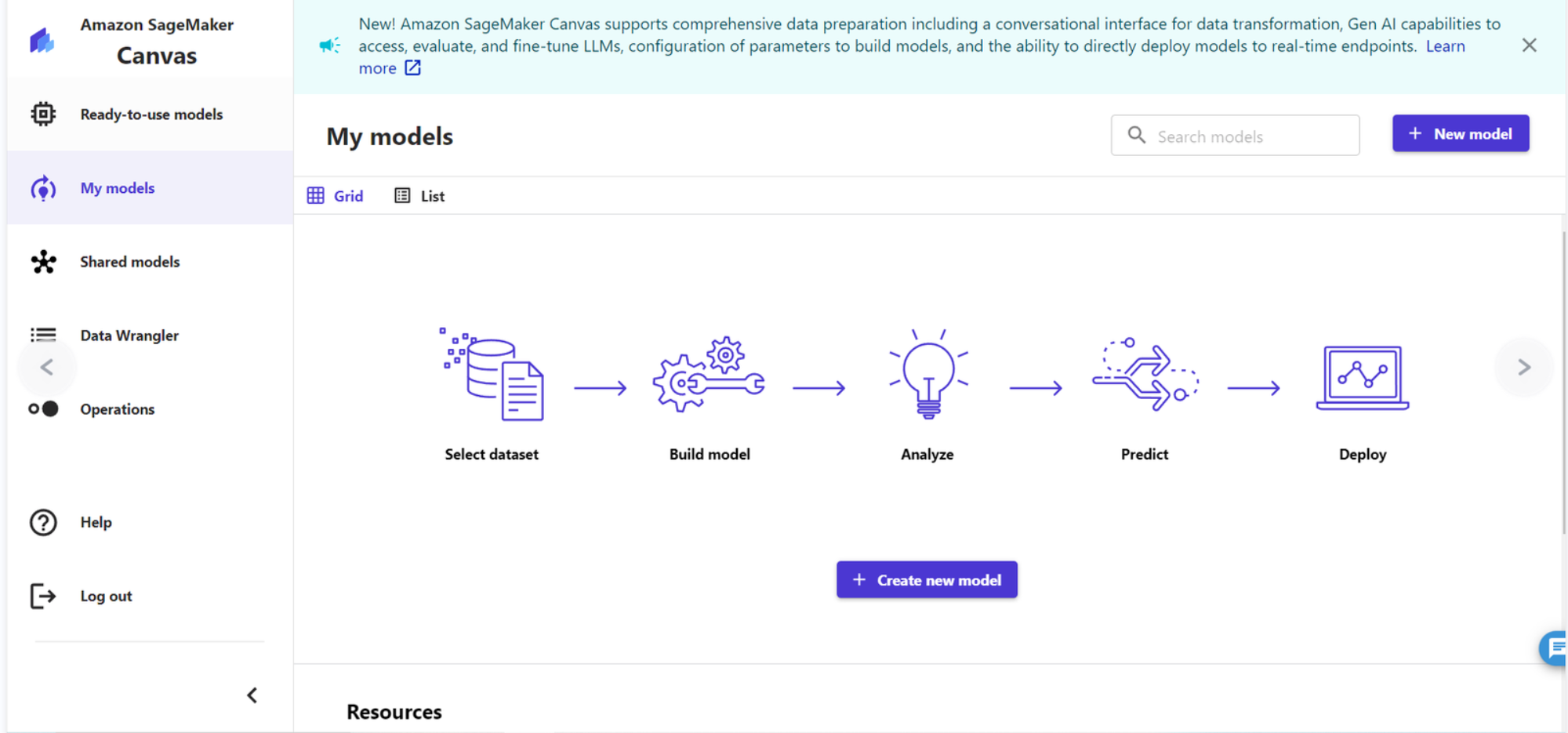
2、进入到 Amazon SageMaker Canvas 界面后回有一个引导提示:数据集管理、建模、预测
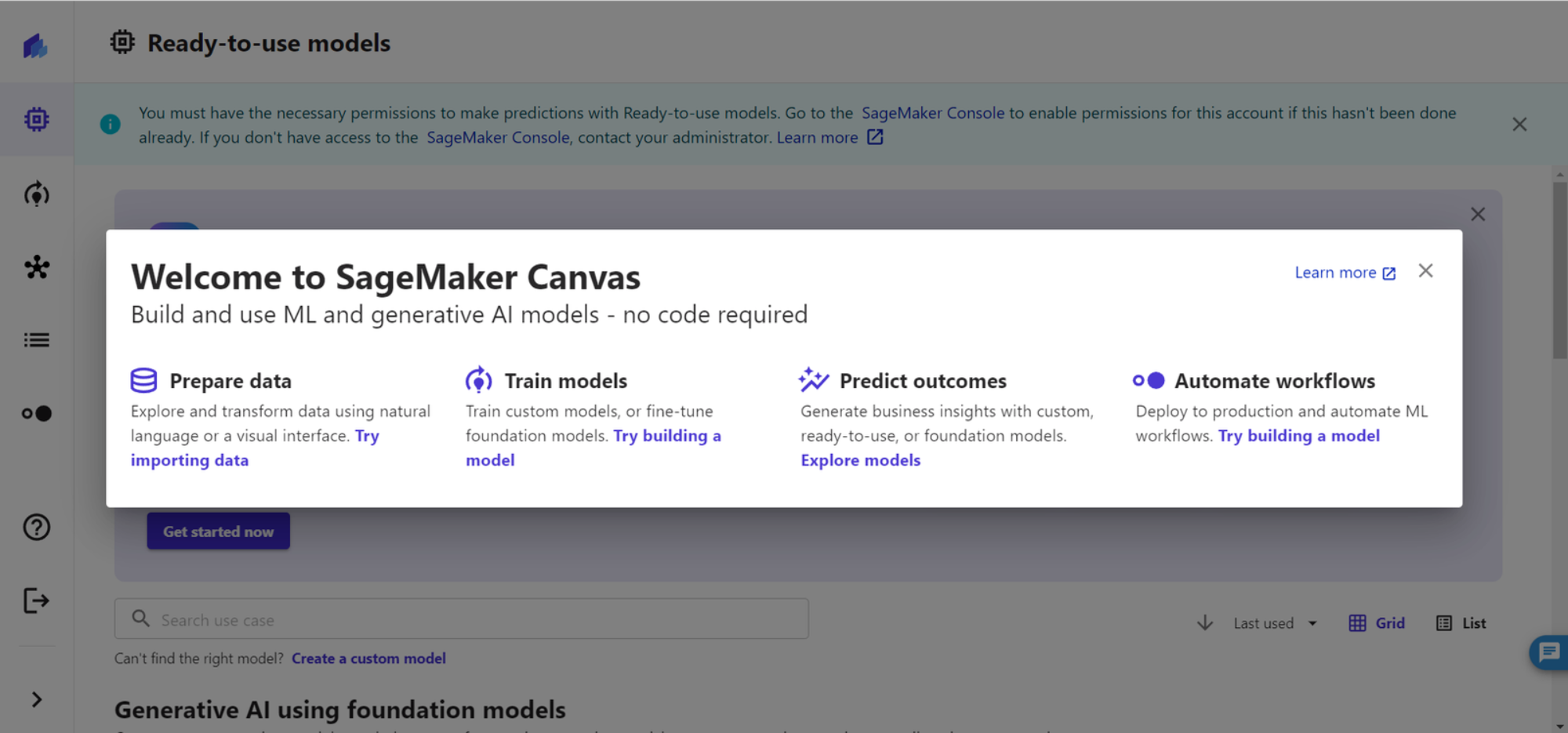
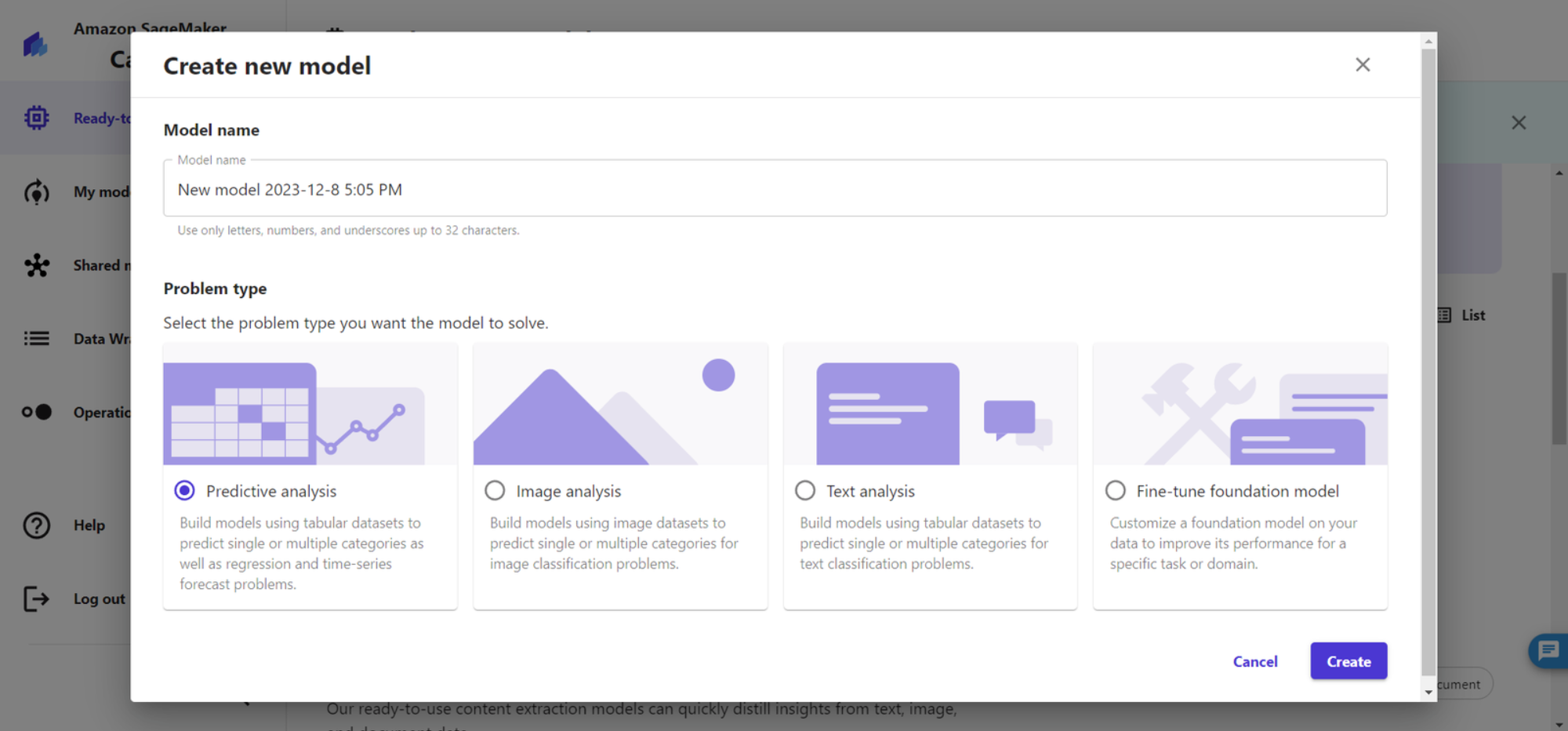
3、选择 New model 并创建一个新的模型
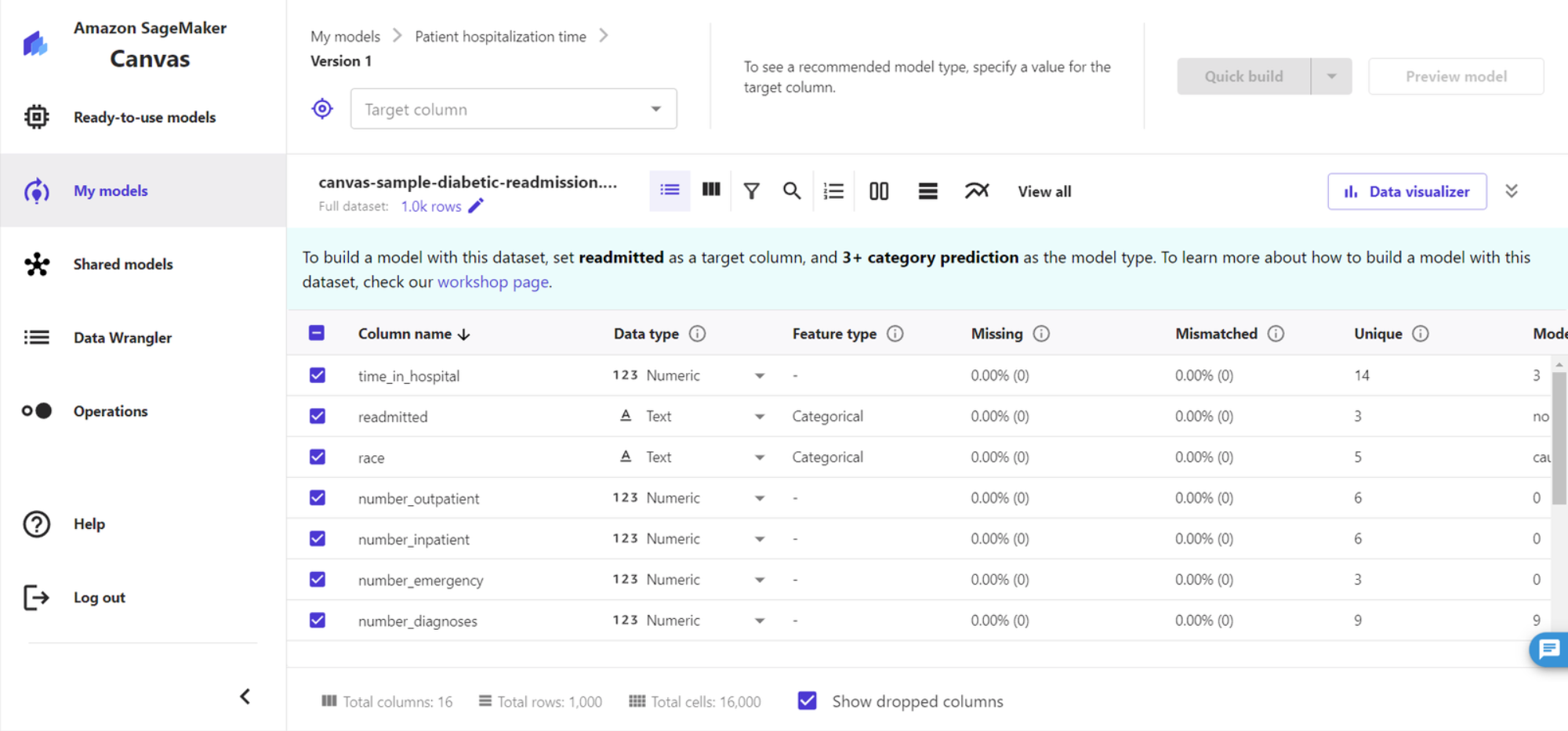
4、导入数据集和预览,数据集包含了15个与患者和医院结果相关的特征字段
5、系统提供了两种构建模式:标准模式、快速模式。快速构建模型模式,模型构建速度更快,精确度则要低一些。标准模式则反之,模型构建耗时更多,精准度则要高一些。
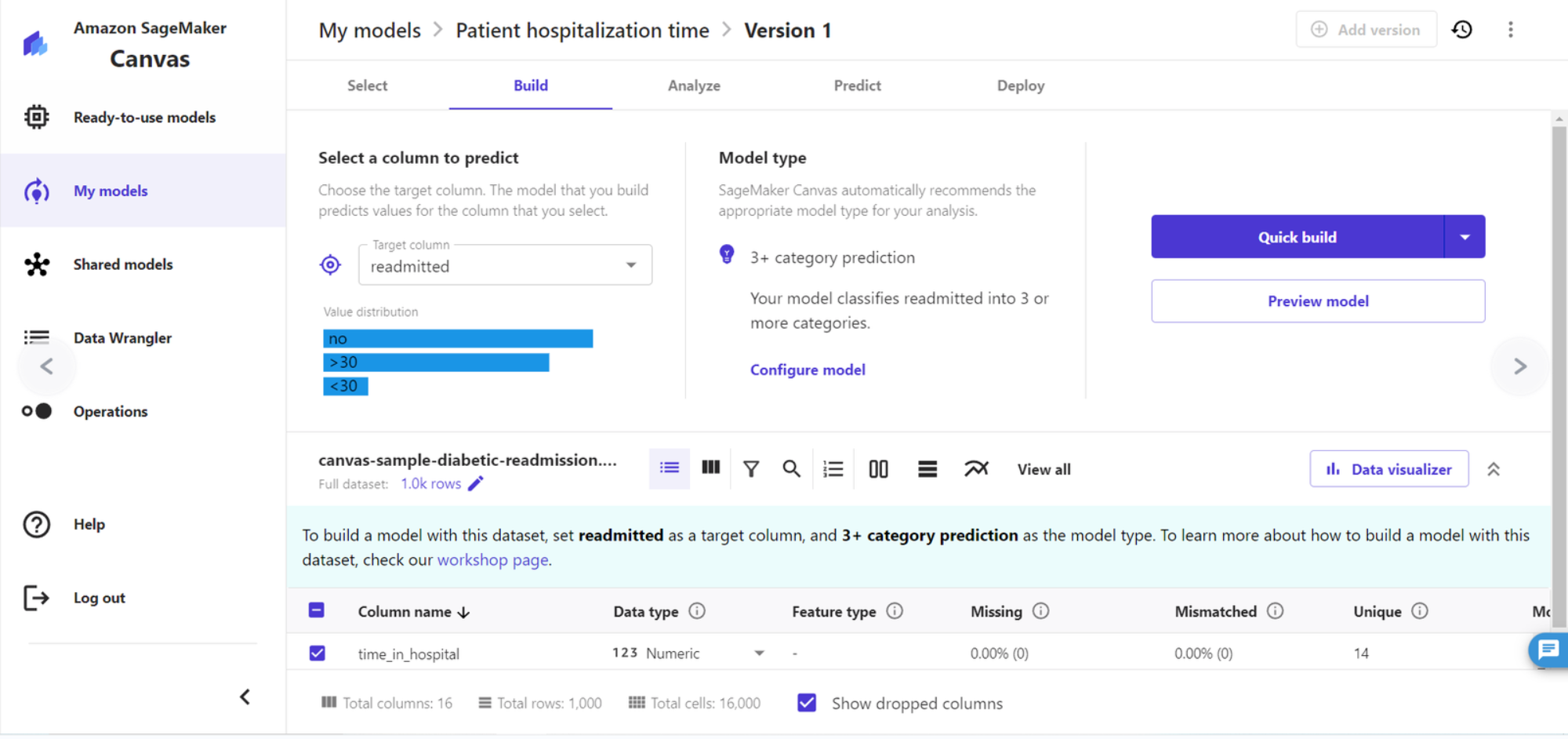
6、选择我们目标字段 readmitted (重新入院)字段来作为我们的预测字段
我们可以在下方的预览中查看到每一个特征值,是否存在缺失值以及与目标值的相关性,并根据需要进行特征值或特征组合的筛选。通过查看特征分布,我们可以查看特征是否存在偏移和不均衡的问题。Amazon Canvas 可以自动识别数据中的缺失值并用相邻值进行填补。通过结合业务逻辑和与目标值的相关性,我们可以初步选定特征组合。
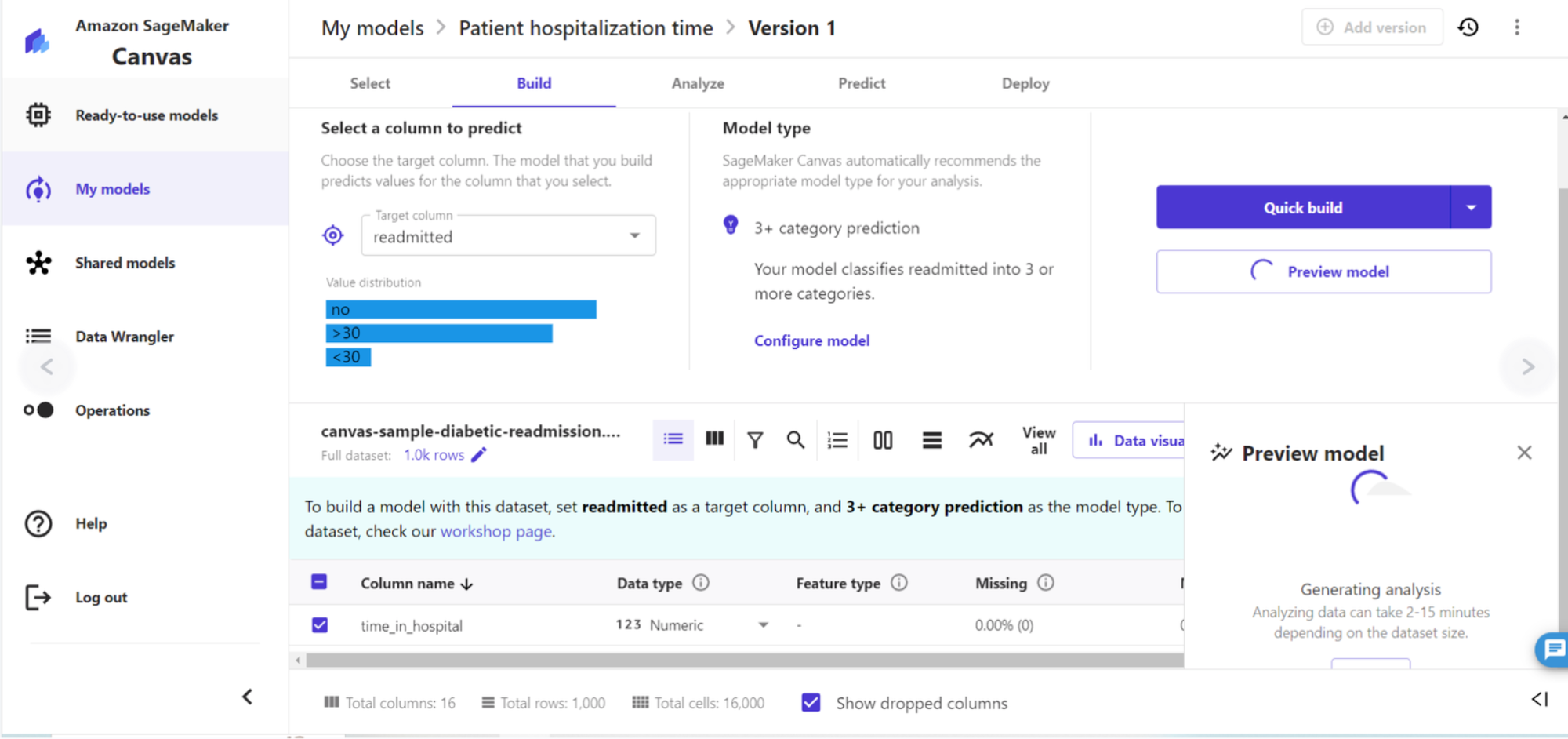
7、与此同时,我们还可以通过选择快速模式 Preview model 快速预测当前配置下模型的效果并查看每一个特征的影响力,从而实现动态交互优化
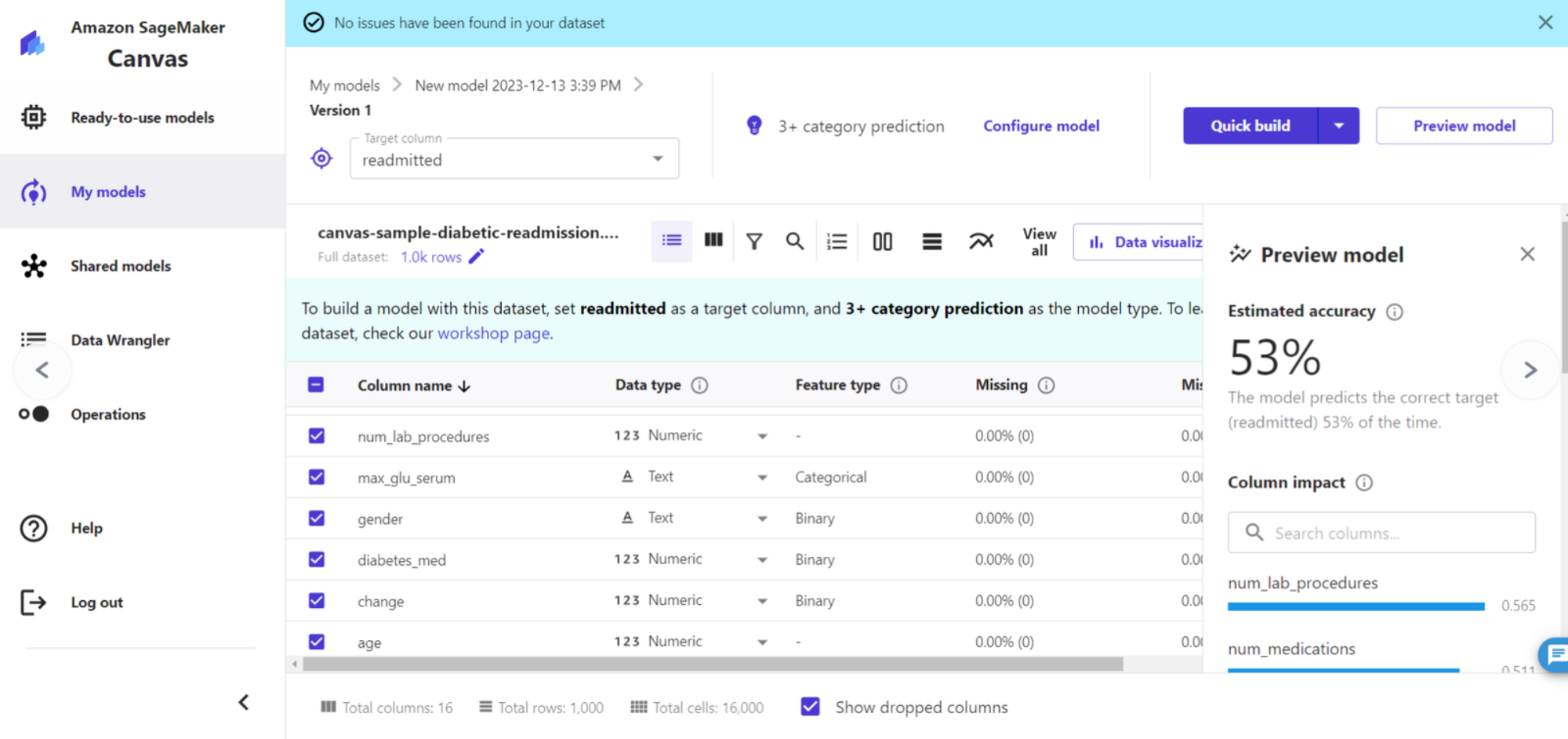
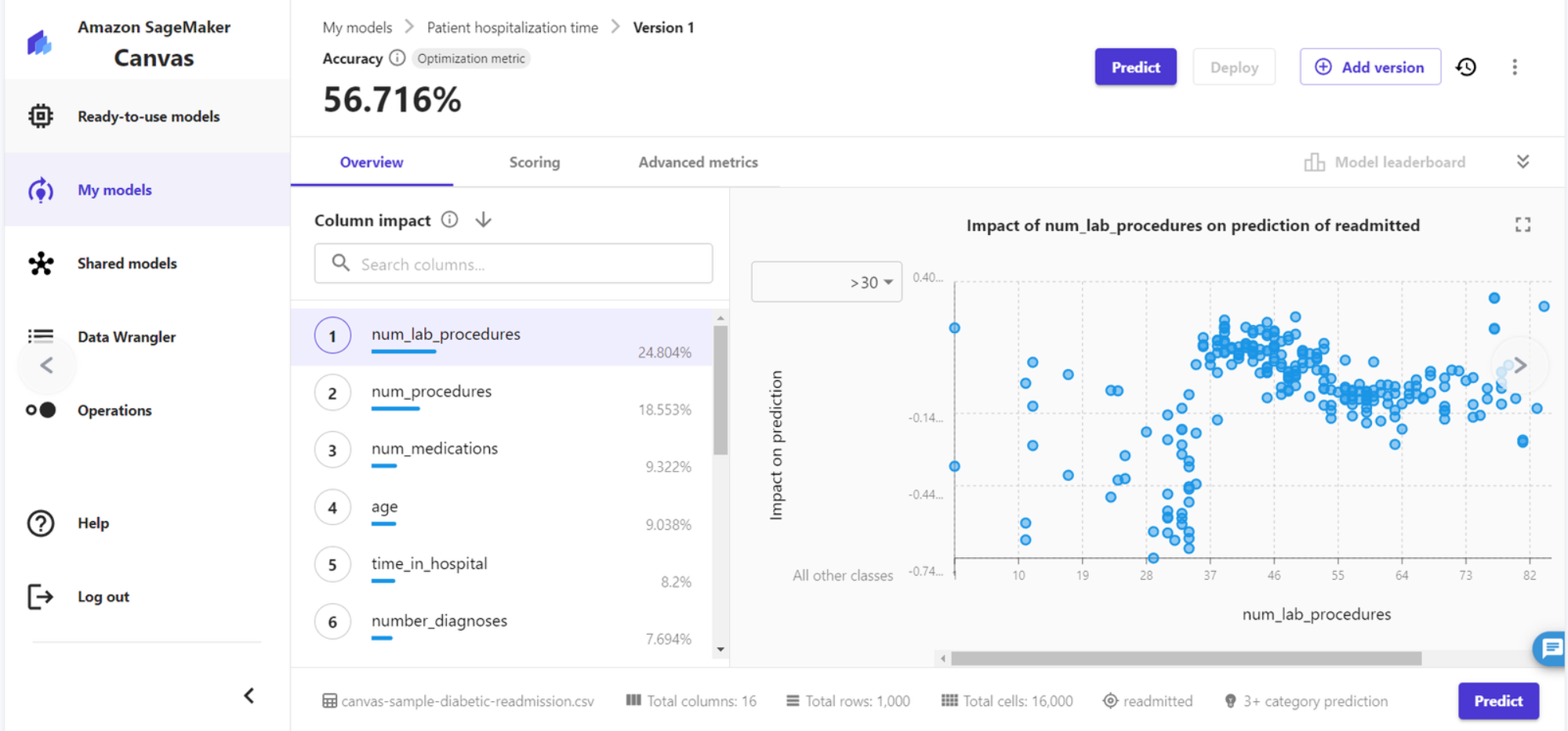
我们可以看到 num-lab-precedures(实验室程序次数)、num-medication(药物次数)等对预测结果的影响是比较大的;而患者性别等字段则关联较小,我们在后续的模型训练当中可以将影响小的字段去掉。
8、在选定特征组合之后我们就可以开始构建模型了
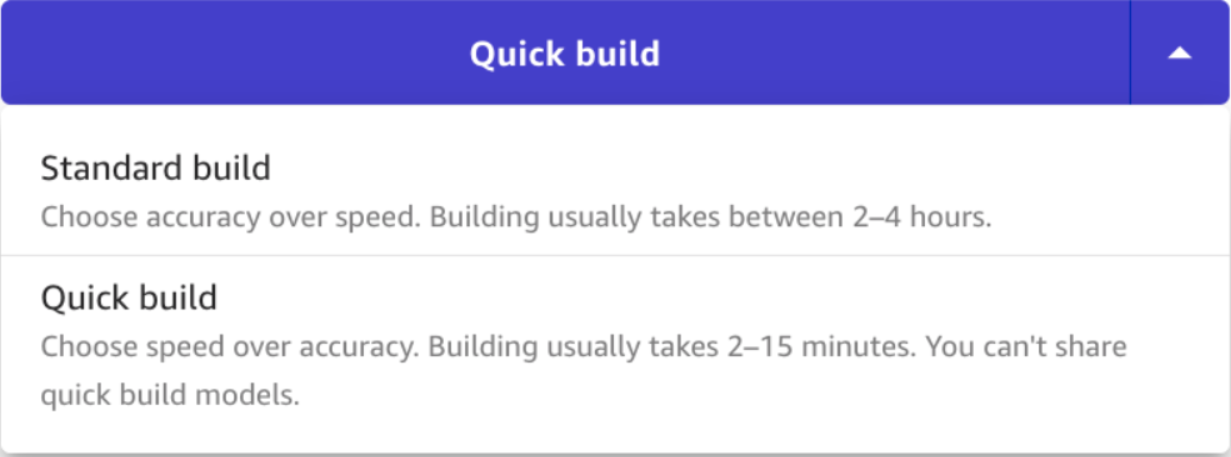
SageMaker Canvas 可以自动完成数据清洗,构建最多250个模型,并从中选取最优的模型。我们可以选择 Quick build 或者 Standard build 两种模式训练模型:Quick build 通常只需要2-15分钟;而 Standard build 则需要2-4个小时,但是可以提供更高准确率并能一键分享给 SageMaker Studio。实际训练过的模型精度理论上要高于我们前面预测的效果
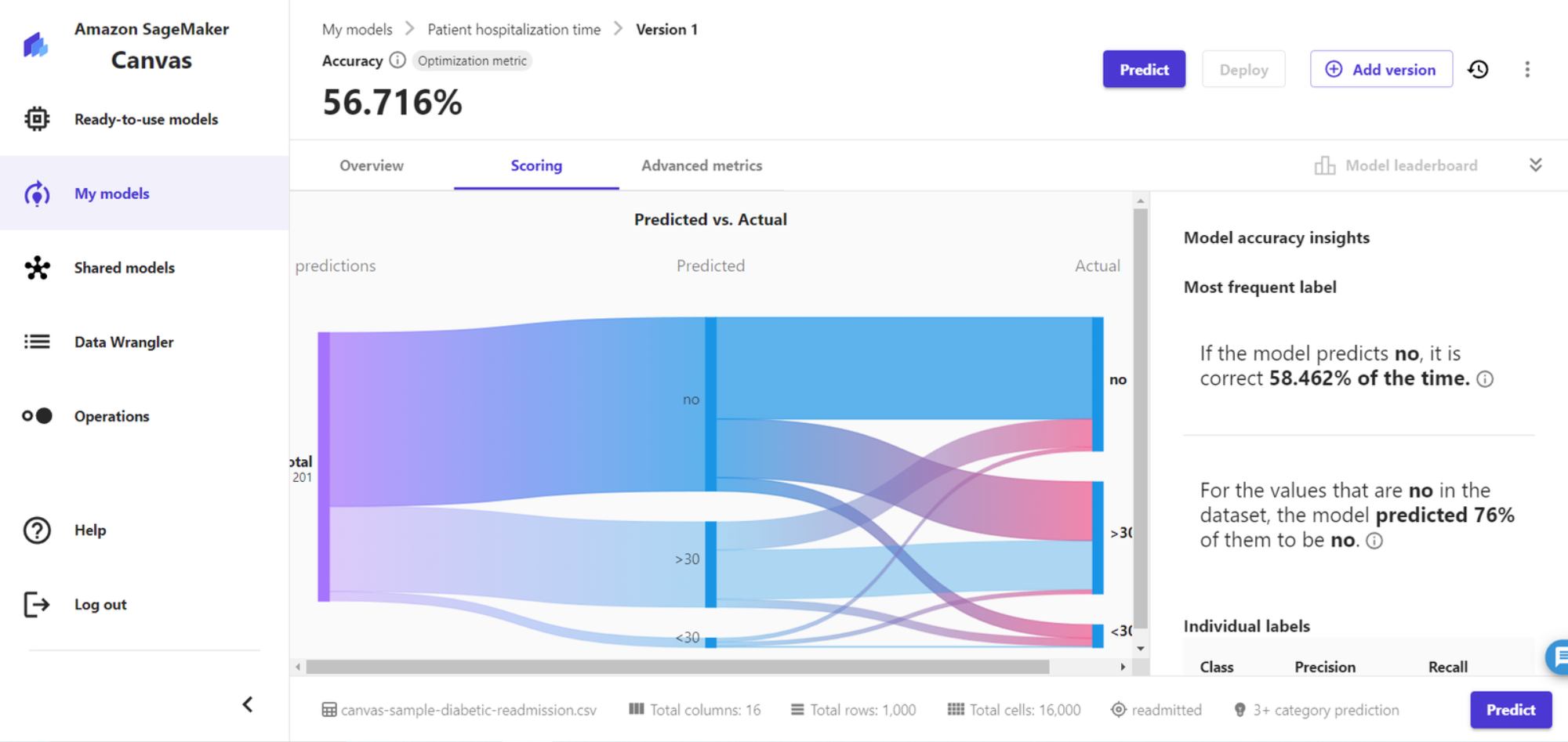
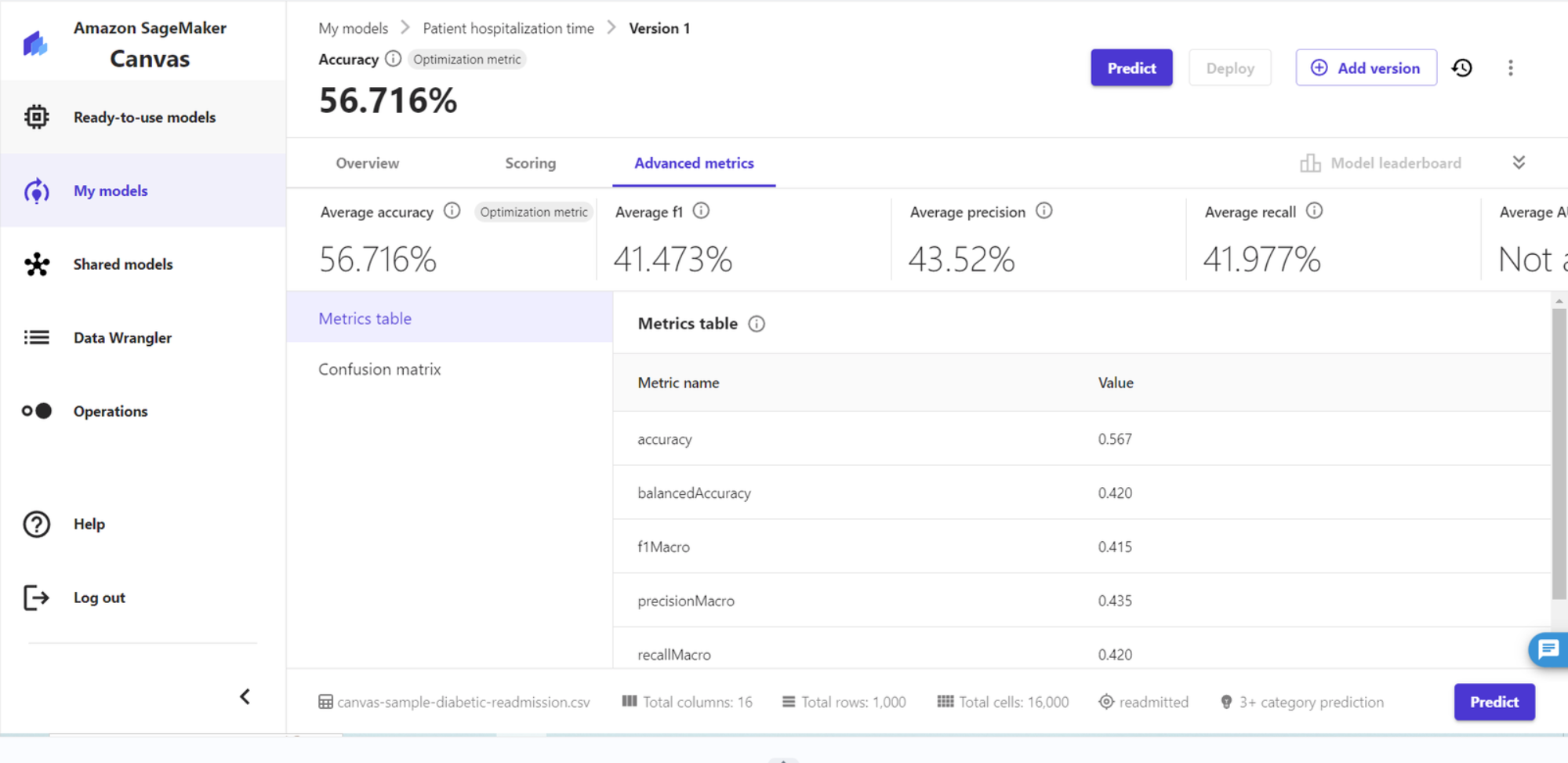
9、模型构建结果,在概览页可以看到预测的精准度为56.716%,也可以看到各个特征的影响值。在得分页,可以看到具体的预测准确数和错误数。
10. 利用模型进行预测
模型构建完成后,就可以利用模型对单个数据进行预测了
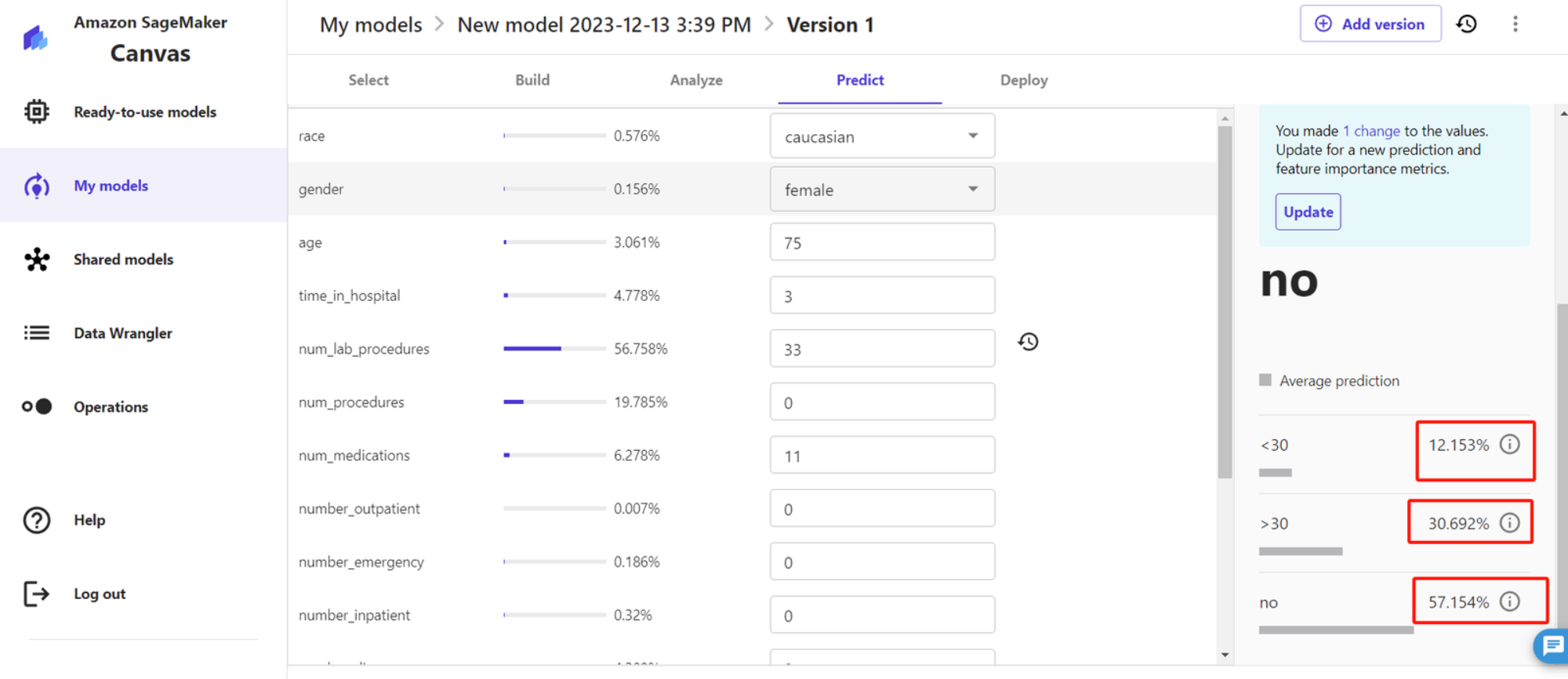
由此我们可以通过这个模型预测来清晰地看到哪些指标对高危糖尿病患者是否有可能在30天内、30天后或根本不入院的影响比较大,从而来正反馈患者在之前应该注意哪些健康事项,从而避免再次入院,对于医疗健康领域有很大的研究帮助。
11、感悟
以上就是 Amazon SageMaker Canvas 使用的全部操作流程了,使用过程中给我留下了几个比较印象深刻的点:
1. 预览数据 导入数据进行构建后,数据分析师能快速地了解数据的大体质量,不同特征的数据类型,有无缺失值,均值、众数等信息,大大减少了因为数据质量问题引发的后续的问题。
2. 构建后的简单特征关联度分析 通常情况下,特征的选取,是基于业务经验,系统也对这方面给出了快捷的特征影响分析,帮助分析师能筛除不必要的特征,加快模型构建速度。
3、普通用户也能自己上手使用 整体来说,需要使用数据分析的客户能全靠自己摸索走完整个模型创建、分析和预测的流程,实际体会一下机器学习在业务分析中的作用,还是有很大帮助的,也真正做到了让机器学习有效赋能企业的每个部门,把机器学习的能力交到每一个企业角色手中。
五、结语
当然你在使用 Amazon SageMaker 的过程中,我们也可以使用 Data Wrangler 对用户行为数据进行预处理和清洗;使用 Studio 进行模型训练,并利用 AutoML 功能自动化了部分模型优化过程;最后将训练好的模型部署到生产环境中,并利用 Amazon SageMaker 的监控功能对模型进行实时监控和管理。
总的来说,Amazon SageMaker 是一款强大而全面的机器学习服务。它为用户提供了从数据准备到模型部署的一站式解决方案,极大地简化了机器学习的过程。无论你是初学者还是经验丰富的开发者,Amazon SageMaker 都能帮助你快速、轻松地迈入机器学习的世界。

