
热门标签
当前位置: article > 正文
LoRA原理解析_lora 原理
作者:小丑西瓜9 | 2024-03-15 15:25:06
赞
踩
lora 原理
1、LoRA(Low-Rank Adaptation of Large Language Models)是什么?
LoRA 的全称是 “Low-Rank Adaption”, 看到 “low-rank”,线性代数玩家们应该会神经反射性地联系到低秩矩阵。Binggo! 这里就是这个意思。你问我 LoRA 的中文名?Em… 就叫它“低秩(自)适应”吧,虽然英文里没有 “self”, 但根据 LoRA 的思想和做法及其带来的效果,它就是自适应的意思。概括地来说,LoRA 是一项主要用于微调 LLMs 的技术,它额外引入了可训练的低秩分解矩阵,同时固定住预训练权重。这个玩法的重点在于:预训练权重不需训练,因此没有梯度,仅训练低秩矩阵那部分的参数。
2、LoRA灵感来源
作者在 paper 中提到:以往的一些工作表明,模型通常是过参数化(over-parametrized的,它们在优化过程中参数更新的部分通常“驻扎”(reside)在低维子空间中。基于此,作者就顺理成章地提出假设:预训练模型在下游任务中微调而更新参数时,也符合这样的规律。
3、LoRA是如何做的?
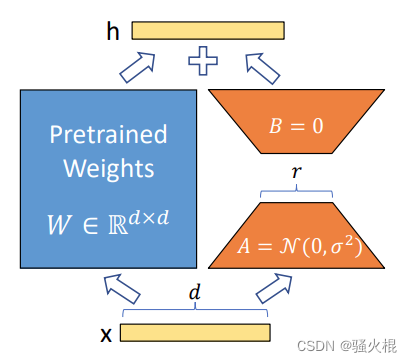
引入低秩矩阵
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/242341
推荐阅读
相关标签

