
- 1第三方打码平台超级鹰图文识别,md5算法加密_打码鹰
- 2uni-app 人脸识别 App端_uniapp人脸采集
- 3泰克Tektronix TDS3034C示波器
- 4【论文笔记】RobotGPT: Robot Manipulation Learning From ChatGPT
- 5VSCode搭建Go语言开发环境_"{ \"resource\": \"/c:/work/go/code/vscode/hello/m
- 6分布式一致性算法(Paxos&Raft)_c# raft
- 7java中计算符号_java中的八种运算符及详解
- 8全球100位最佳工程师,开发人员,编码人员和企业家,可以在线关注他们的github,推特,网站等_mosh hamedani简介
- 9c语言 printf(“%#x”, a)中“#”含义_c语言%#
- 10vue源码系列3响应式系统上_vue响应式ui框架,源代码
「理解C++20协程原理」从Linux线程、线程与异步编程、协程与异步_linux c实现协程
赞
踩
协程不是系统级线程,很多时候协程被称为“轻量级线程”、“微线程”、“纤程(fiber)”等。简单来说可以认为协程是线程里不同的函数,这些函数之间可以相互快速切换。
协程和用户态线程非常接近,用户态线程之间的切换不需要陷入内核,但部分操作系统中用户态线程的切换需要内核态线程的辅助。
协程是编程语言(或者 lib)提供的特性(协程之间的切换方式与过程可以由编程人员确定),是用户态操作。协程适用于 IO 密集型的任务。常见提供原生协程支持的语言有:c++20、golang、python 等,其他语言以库的形式提供协程功能,比如 C++20 之前腾讯的 fiber 和 libco 等等
Linux 线程资源消耗分析
大脑 && 流水线 && 分工
上下文切换可以类比于人脑的工作方式。工作中不断切换工作内容与场景一般非常累且效率低下(这是流水线发明的初衷也是劳动分工要解决的问题),但在同一个场景下有关联的几个子任务之间相互切换并不耗神,这与线程和协程的切换非常相似
人脑支持异步处理,我们的饥饿感可以认为是系统中断;我们的生物钟可以认为是类似于定时器一样的后台硬件;我们的感情、知识、意识都在潜移默化中慢慢发生变化,这说明大脑也有“后台任务”
进程、线程上下文切换
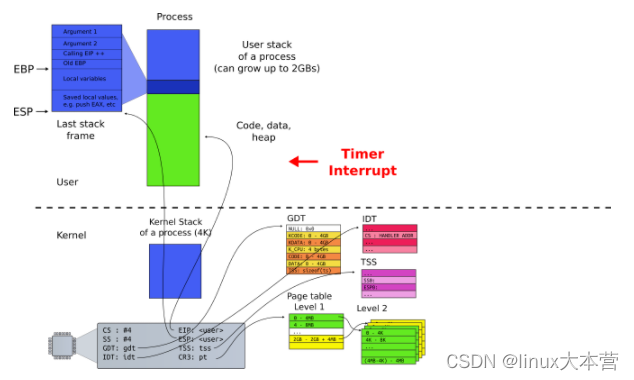
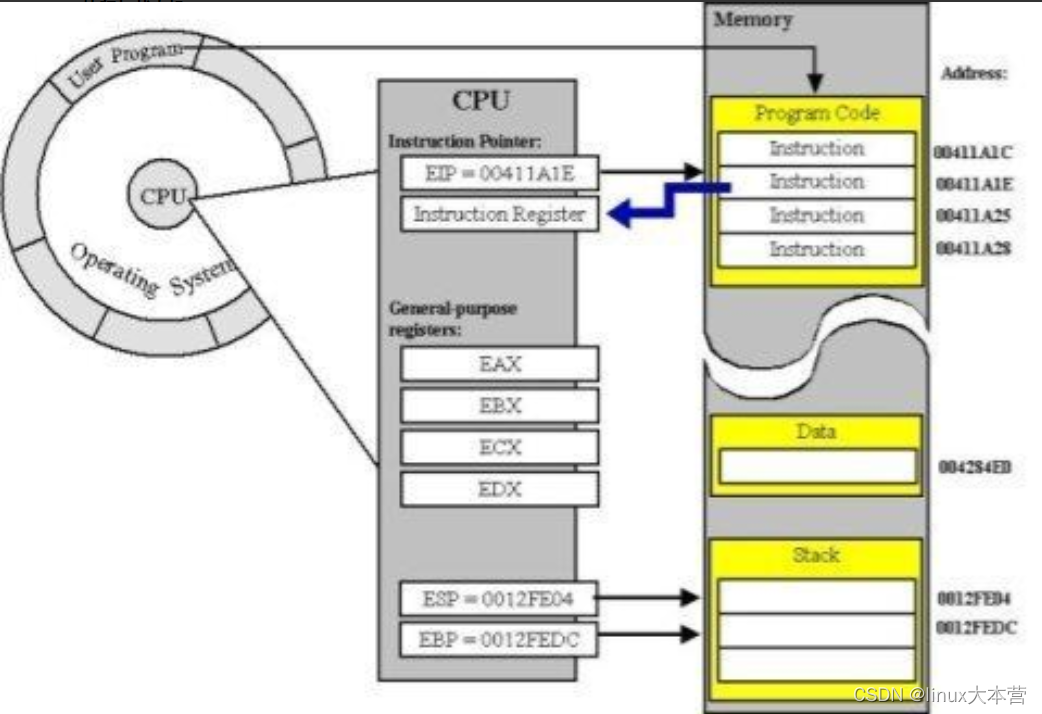
下图展示了进程/线程在运行过程 CPU 需要的一些信息(CPU Context,CPU 上下文),比如通用寄存器、栈信息(EBP/ESP)等。进程/线程切换时需要保存与恢复这些信息
进程/内核态线程切换的时候需要与 OS 内核进行交互,保存/读取 CPU 上下文信息。内核态(Kernel)的一些数据是共享的,读写时需要同步机制,所以操作一旦陷入内核态就会消耗更多的时间
进程需要与操作系统中所有其他进程进行资源争抢,且操作系统中资源的锁是全局的;线程之间的数据一般在进程内共享,所以线程间资源共享相比如进程而言要轻一些。虽然很多操作系统(比如 Linux)进程与线程区别不是非常明显,但线程还是比进程要轻
Linux 线程切换耗时分析
线程的切换(Context Switch)相比于其他操作而言并不是非常耗时,如下图所示(2018 年):
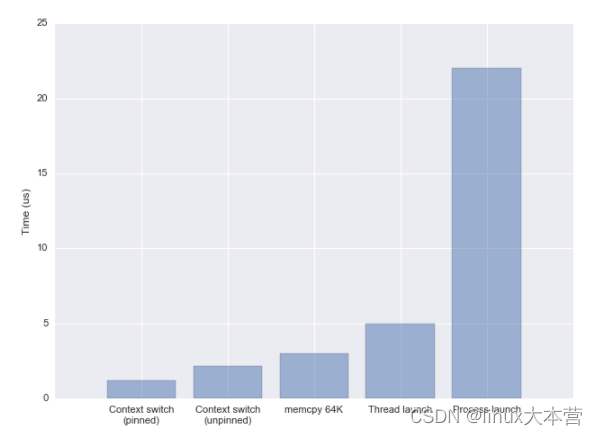
Linux 2.6 之后 Linux 多线程的性能提高了很多,大部分场景下线程切换耗时在 2us 左右。下面是 Linux 下线程切换耗时统计(2013 年)
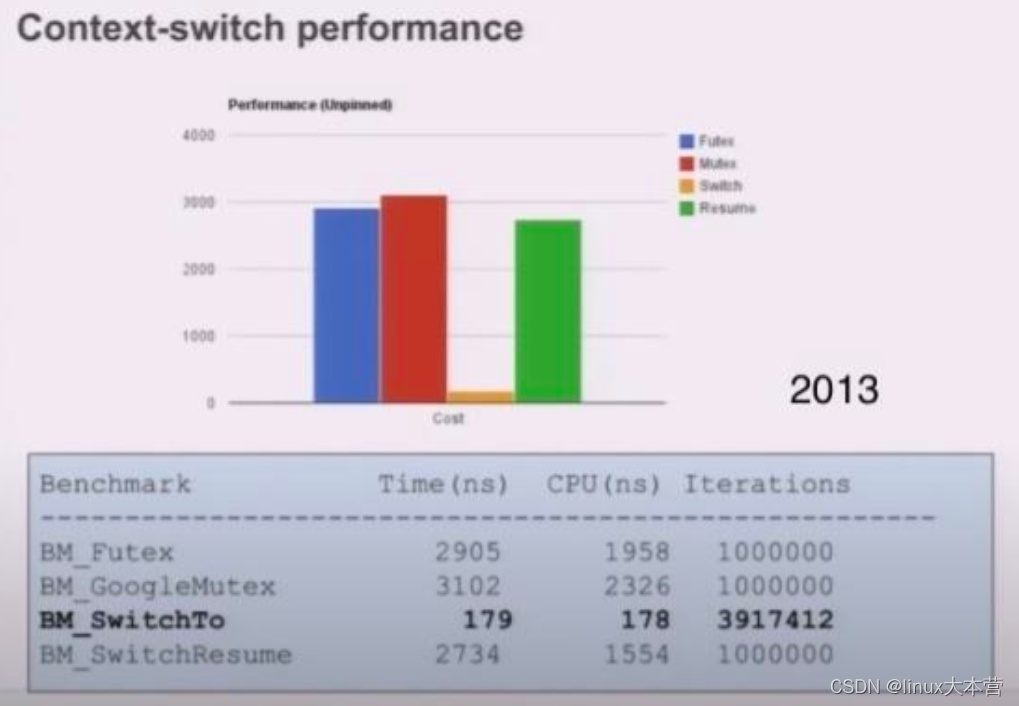
正常情况下线程有用的 CPU 时间片都在数十毫秒级别,线程切换占总耗时的千分之几以内。协程的使用可以将这个损耗进一步降低(主要是去除了其他操作,比如 futex 等)
虽然线程切换对于常见业务而言并不重要,但不是所有语言或者系统都支持一次创建很多线程。32 位系统即使使用了虚内存空间,因为进程能访问的虚内存空间大概是 3GB,所以单进程最多创建 300 多条线程(假设系统为每条线程分配 10M 栈空间)。太多线程也有线程切换触发了缺页中断的风险
创建很多线程(比如 64 位系统下创建 1 万条线程),不考虑优先级且假设 CPU 有 10 个核心,那么每个线程每秒有 1ms 的时间片,整个业务的耗时大概是 (n-1) * 1 + n * 0.001(n−1)∗1+n∗0.001 秒(n 是线程在处理业务的过程中被调度的次数),如果大量线程之间存在资源竞争,那么系统行为将难以预测。所以在有限的资源下创建大量线程是不合理的,服务线程的个数和 CPU 核心数应该在一个合理的比例内。
内存资源占用
默认情况下 Linux 系统给每条线程分配的栈空间最大是 6~8MB,这个大小是上限,也是虚内存空间,并不是每条线程真实的栈使用情况。线程真实栈内存使用会随着线程执行而变化,如果线程只使用了少量局部变量,那么真实线程栈可能只有几十个字节的大小。系统在维护线程时需要分配额外的空间,所以线程数的增加还是会提高内存资源的消耗
总结
如果线程之间没有竞争关系、线程占用的内存资源较少且对延时不是非常敏感或者说线程创建不频繁(数分钟创建一次),那么直接在使用的时候创建新的线程(std::thread+detach/std::async)也是不错的选择
如果业务处理时间远小于 IO 耗时,线程切换非常频繁,那么使用协程是不错的选择
协程的优势并不仅仅是减少线程之间切换,从编程的角度来看,协程的引入简化了异步编程。协程为一些异步编程提供了无锁的解决方案,这些将在下文进行介绍
线程与异步编程
同步与异步
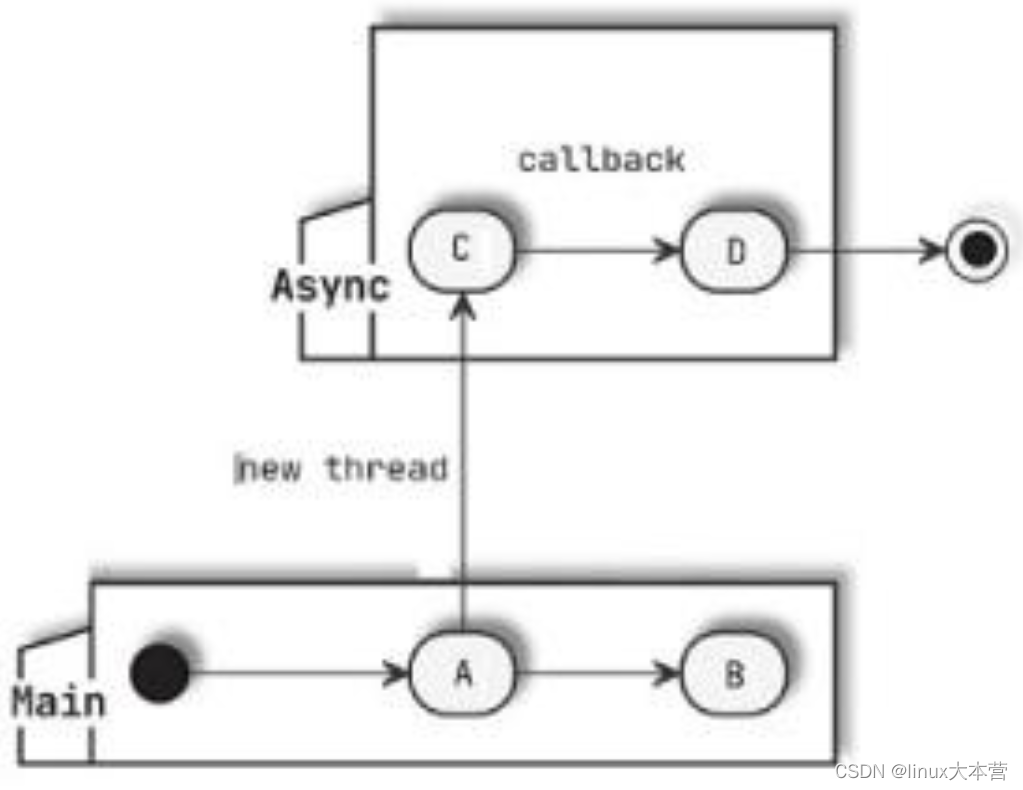
同步与异步的区别是顺序与并行,同步编程意味着只有前置操作执行完成才能执行后续流程,如上图 AB 和 CD;异步说明二者可以同时执行,如上图中的 AC(这里不区分并发、并行的区别)
相关视频推荐
【C++后台开发】4个小时搞定C++ 协程,从协程原理到实现
[linux]一个让性能飞起的解决方案,异步处理到底有哪些不一样
免费学习地址:C/C++Linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加群812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
常见异步编程方式
C++11 async && future
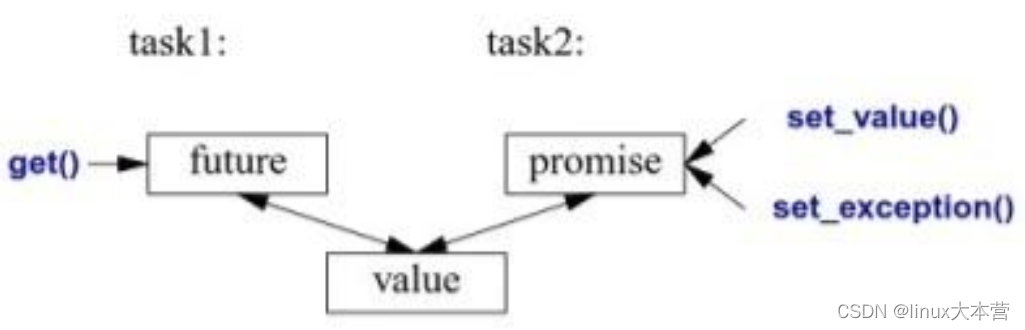
async 与 future 相关知识可参考其他文章,这里不做详细介绍。术语 future(期货)&& promise(承诺) 源自金融领域
下面代码使用多线程实现数据的累加。线程的创建/调度与其他操作会造成了一些消耗,所以少量数据不建议使用多线程
- int64_t multi_thread_acc(const std::vector<int>& data) {
- if (data.size() < ELEM_NUM_MULTI_TH_LIMIT) { // 少于一定数量的累加直接使用单线程会更好
- return std::accumulate(data.begin(), data.end(), int64_t(0));
- } else {
- auto step = data.size() / USED_CORE_NUM; // or std::hardware_currency
- std::vector<std::future<int64_t>> ret_vec;
- ret_vec.reserve(USED_CORE_NUM);
- for (int i = 0; i < USED_CORE_NUM; i++) {
- auto lhs_it = data.begin() + i * step;
- auto rhs_it = (i == USED_CORE_NUM - 1) ? data.end() : lhs_it + step;
- ret_vec.emplace_back(
- // 持续创建少量线程并不会给系统造成太大的压力
- std::async([lhs_it, rhs_it] {
- return std::accumulate(lhs_it, rhs_it, int64_t(0));
- }));
- }
- int64_t ret = 0;
- // 阻塞调用
- for (auto& fu : ret_vec) {
- ret += fu.get();
- }
- return ret;
- }
- }

从上面的代码中可以看出,常规的异步编程手段还是需要一个同步的过程来搜集异步线程的执行结果
Reactor/Proactor

网络编程的发展与模式大概有下面几种:
- 每个请求一个线程/进程,阻塞式 IO
- 阻塞式 IO,线程池
- 非阻塞式 IO && IO 复用,类似于 Reactor
- Leader/Folloer 等模式
Reactor 编程模式是事件驱动的,并以回调(handle)的方式完成具体业务,Reactor 有几个基本概念
- nonblockingIO+IOmultiplexing,请参考 epoll
- Event loop,一个监控事件源(epoll fd)的“死循环”
- // ... 前置设置略
- while(true) { // event loop
- nfds = epoll_wait(epollFd, events, MAX_EVENTS, -1);
- if(nfds == -1){
- printf("epoll_wait failed\n");
- exit(EXIT_FAILURE);
- }
- for(int i = 0; i < nfds; i++){
- if(events[i].data.fd == listenFd){
- connectFd = accept(listenFd, (sockaddr*)NULL, NULL);
- printf("Connected ...\n");
- pthread_t thread;
- // 使用线程池可以减少系统消耗
- pthread_create(&thread, NULL, handleConnection, (void *) &connectFd);
- }
- else {
- if() // readable
- if() // writeable
- }
- }
- }
优点与缺点
优点:
- 线程数目基本固定,可以在程序启动的时候设置,不会频繁创建与销毁
- 可以很方便地在线程间调配负载
- IO 事件发生的线程是固定的,同一个 TCP 连接不必考虑事件并发
缺点:
基于事件的模型有个非常明显的缺陷,回调函数(handle)不能阻塞(非抢占式调度),否则线程或者进程有耗尽的风险,即使不耗尽,也会给系统带来负担。参考上文的介绍,创建大量进程/线程是不合理的
响应式编程(基于回调)
响应式编程( Reactive Programming)主要关注的是数据流的变换和流转,因此它更注描述数据输入和输出之间 的关系。输入和输出之间用函数变换来连接,函数之间也只对输入输出负责,因此我们可以很轻松地通过将这些 函数调用分发到其他线程上的方法来实现异步
响应式编程中的逻辑单元也不能阻塞,否则也有耗尽工作线程的风险;非阻塞式 handle 又有陷入回调地狱的风险
回调地狱
大部分异步编程框架都是基于回调的,当一个业务需要多个步骤时回调函数会分布在不同的执行单元中,这对代码的维护与理解造成了压力。当执行链条非常长时回调链路也会很深
基于事件与回调的编码风格将业务割裂到不同的 handle 函数中,理解与维护起来比较麻烦
Coroutine
通过上面的叙述,在资源有限的前提下,高性能服务需要解决的问题如下:
- 减少线程的重复高频创建
- 常规解决办法:线程池
- 尽量避免线程的阻塞
- Reactor && 非阻塞回调,解决问题的能力有限
- 响应式编程,容易陷入回调地狱,割裂业务逻辑
- 其他方法,例如协程
- 提升代码的可维护与可理解性,尽量避免回调地狱
- 少使用回调函数,减少回调链深度
使用协程可以解决上面 2/3 两个问题。协程可以用同步编程的方式实现异步编程才能实现的功能
协程与状态机
A computer is a state machine. Threads are for people who can’t program state machines ——Alan Cox
无栈协程是对计算机是状态机的实践
协程的原理
协程的切换和线程进程的切换机制是相似的(CPU 上下文与栈信息的保存与恢复),协程在切换出去的时候需要保存当前的运行状态,比如 CPU 寄存器、栈信息等等
Stackless && Stackful
有栈协程与无栈协程是协程的两种实现方式,这里的栈是“逻辑栈”,不是内存栈
比如协程 A 调用了协程 B,如果只有 B 完成之后才能调用 A 那么这个协程就是 Stackful,此时 A/B 是非对称协程;如果 A/B 被调用的概率相同那么这个协程就是 Stackless,此时 A/B 是对称协程
下面主要介绍无栈协程的实现方法,如果对有栈协程有兴趣,可以看 libco 等库等实现。C++20 引入的是无栈协程
使用 setjmp/longjmp 实现的简单协程
下面代码模拟了单线程并发执行两个 while(true){...} 函数,细节可以查看原始 文档 和 代码
setjmp/longjmp 不能作为协程实现的底层机制,因为 setjmp/longjmp 对栈信息的支持有限
- int max_iteration = 9;
- int iter;
-
- jmp_buf Main;
- jmp_buf PointPing;
- jmp_buf PointPong;
-
- void Ping(void);
- void Pong(void);
-
- int main(int argc, char* argv[]) {
- iter = 1;
- if (setjmp(Main) == 0) Ping();
- if (setjmp(Main) == 0) Pong();
- longjmp(PointPing, 1);
- }
-
- void Ping(void) {
- if (setjmp(PointPing) == 0) longjmp(Main, 1); // 可以理解为重置,reset the world
- while (1) {
- printf("%3d : Ping-", iter);
- if (setjmp(PointPing) == 0) longjmp(PointPong, 1);
- }
- }
-
- void Pong(void) {
- if (setjmp(PointPong) == 0) longjmp(Main, 1);
- while (1) {
- printf("Pong\n");
- iter++;
- if (iter > max_iteration) exit(0);
- if (setjmp(PointPong) == 0) longjmp(PointPing, 1);
- }
- }
通过命令 gcc test.c 编译后执行 ./a.out 7 ,输出如下:
- 1 : Ping-Pong
- 2 : Ping-Pong
- 3 : Ping-Pong
- 4 : Ping-Pong
- 5 : Ping-Pong
- 6 : Ping-Pong
- 7 : Ping-Pong
协程的特点
- 协程可以自动让出 CPU 时间片。注意,不是当前线程让出 CPU 时间片,而是线程内的某个协程让出时间片供同线程内其他协程运行
- 协程可以恢复 CPU 上下文。当另一个协程继续执行时,其需要恢复 CPU 上下文环境
- 协程有个管理者,管理者可以选择一个协程来运行,其他协程要么阻塞,要么 ready,或者 died
- 运行中的协程将占有当前线程的所有计算资源
- 协程天生有栈属性,而且是 lock free
其他协程库
ucontext,CPU 上下文管理
下面关于 ucontext 的介绍源自:
http://pubs.opengroup.org/onlinepubs/7908799/xsh/ucontext.h.html 。ucontext lib 已经不推荐使用了,但依旧是不错的协程入门资料。其他底层协程库实现可以查看 Boost.Context / tbox 等,协程库的对比可以参考:https://github.com/tboox/benchbox/wiki/switch
linux 系统一般都有 ucontext 这个 c 语言库,这个库主要用于操控当前线程下的 CPU 上下文。和 setjmp/longjmp 不同,ucontext 直接提供了设置函数运行时栈的方式(makecontext),避免不同函数栈空间的重叠
ucontext 只操作与当前线程相关的 CPU 上下文,所以下文中涉及 ucontext 的上下文均指当前线程的上下文。一般 CPU 有多个核心,一个线程在某一时刻只能使用其中一个,所以 ucontext 只涉及一个与当前线程相关的 CPU 核心
ucontext.h 头文件中定义了 ucontext_t 这个结构体,这个结构体中至少包含以下成员:
- ucontext_t *uc_link // next context
- sigset_t uc_sigmask // 阻塞信号阻塞
- stack_t uc_stack // 当前上下文所使用的栈
- mcontext_t uc_mcontext // 实际保存 CPU 上下文的变量,这个变量与平台&机器相关,最好不要访问这个变量
同时,ucontext.h 头文件中定义了四个函数,下面分别介绍:
- int getcontext(ucontext_t *); // 获得当前 CPU 上下文
- int setcontext(const ucontext_t *);// 重置当前 CPU 上下文
- void makecontext(ucontext_t *, (void *)(), int, ...); // 修改上下文信息,比如设置栈指针
- int swapcontext(ucontext_t *, const ucontext_t *);
getcontext & setcontext
- #include <ucontext.h>
- int getcontext(ucontext_t *ucp);
- int setcontext(ucontext_t *ucp);
getcontext 函数使用当前 CPU 上下文初始化 ucp 所指向的结构体,初始化的内容包括 CPU 寄存器、信号 mask 和当前线程所使用的栈空间
返回值:getcontext 成功返回 0,失败返回 -1。注意,如果 setcontext 执行成功,那么调用 setcontext 的函数将不会返回,因为当前 CPU 的上下文已经交给其他函数或者过程了,当前函数完全放弃了 对 CPU 的“所有权”
应用:当信号处理函数需要执行的时候,当前线程的上下文需要保存起来,随后进入信号处理阶段。可移植的程序最好不要读取与修改 ucontext_t 中的 uc_mcontext,因为不同平台下 uc_mcontext 的实现是不同的
makecontext & swapcontext
- #include <ucontext.h>
- void makecontext(ucontext_t *ucp, (void *func)(), int argc, ...);
- int swapcontext(ucontext_t *oucp, const ucontext_t *ucp);
makecontext 修改由 getcontext 创建的上下文 ucp。如果 ucp 指向的上下文由 swapcontext 或 setcontext 恢复,那么当前线程将执行传递给 makecontext 的函数 func(...)
执行 makecontext 后需要为新上下文分配一个栈空间,如果不创建,那么新函数func执行时会使用旧上下文的栈,而这个栈可能已经不存在了。argc 必须和 func 中整型参数的个数相等。
swapcontext 将当前上下文信息保存到 oucp 中并使用 ucp 重置 CPU 上下文
返回值:swapcontext 成功则返回 0,失败返回 -1 并置 errno。如果 ucp 所指向的上下文没有足够的栈空间以执行余下的过程,swapcontext 将返回 -1
进一步学习
有很多协程库的实现是基于 ucontext 的,我们可以在学习这些库的时候顺便学习一下 ucontext 库的使用方法
coroutine,简单的 C 协程库
coroutine 是基于 ucontext 的一个 C 语言协程库实现。包含示例代码在内,全部代码行数不超过 300 行,Mac&&Linux 可以直接编译运行
下面是一段示例代码:
- #include <stdio.h>
- #include "coroutine.h"
-
- struct args { int n; };
-
- static void foo(struct schedule* S, void* ud) {
- struct args* arg = ud;
- int start = arg->n;
- int i;
- for (i = 0; i < 5; i++) {
- printf("coroutine %d : %d\n", coroutine_running(S), start + i);
- coroutine_yield(S);
- }
- }
-
- int main() {
- struct schedule* S = coroutine_open(); // 创建协程管理对象
-
- struct args arg1 = {0};
- struct args arg2 = {100};
-
- int co1 = coroutine_new(S, foo, &arg1); // 注册协程函数
- int co2 = coroutine_new(S, foo, &arg2);
- printf("main start\n");
- while (coroutine_status(S, co1) || coroutine_status(S, co2)) {
- coroutine_resume(S, co1); // 执行协程
- coroutine_resume(S, co2);
- }
- printf("main end\n");
- coroutine_close(S);
-
- return 0;
- }
fiber/libco 等
协程常用于异步编程,libco 等库利用协程劫持并封装了底层网络 IO 相关的函数,以同步编程的方式实现了网络事件的异步处理
具体细节请参考其他资料,本文不展开介绍
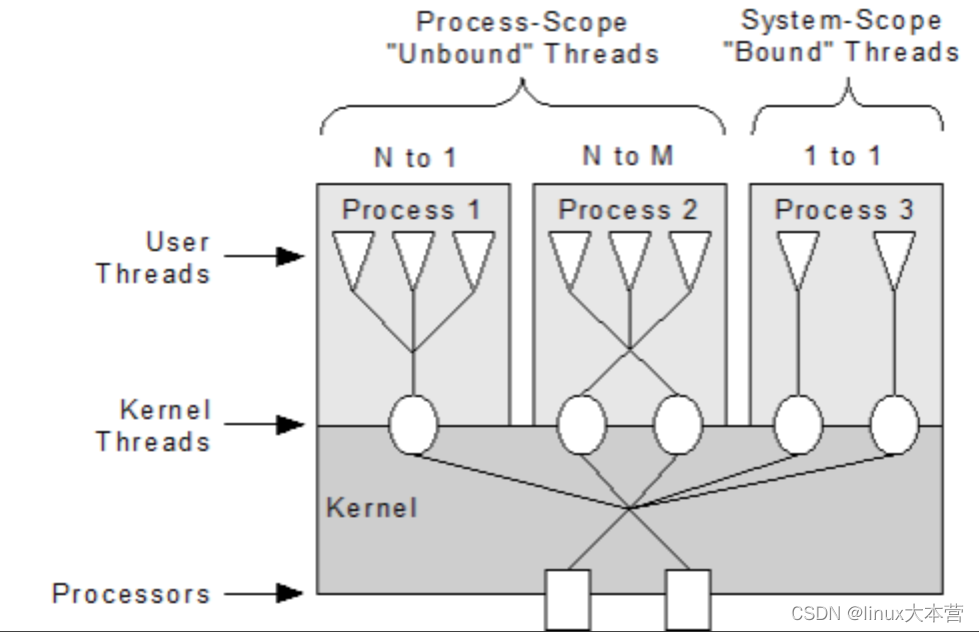
N:1 && N:M 协程
和线程绑定的协程只有在对应线程运行的时候才有被执行的可能,如果对应线程中的某一个协程完全占有了当前线程,那么当前线程中的其他所有协程都不会被执行
协程的所有信息都保存在上下文(Contex)对象中,将不同上下文分发给不同的线程就可以实现协程的跨线程执行,如此,协程被阻塞的概率将减小
借用 BRPC 中对 N:M 协程的介绍,来解释下什么是 N:M 协程
我们常说的协程特指 N:1 线程库,即所有的协程运行于一个系统线程中,计算能力和各类 eventloop 库等价。由于不跨线程,协程之间的切换不需要系统调用,可以非常快(100ns-200ns),受 cache 一致性的影响也小。但代价是协程无法高效地利用多核,代码必须非阻塞,否则所有的协程都被卡住…… bthread 是一个 M:N 线程库,一个 bthread 被卡住不会影响其他 bthread。关键技术两点:work stealing 调度和 butex,前者让 bthread 更快地被调度到更多的核心上,后者让 bthread 和 pthread 可以相互等待和唤醒。这两点协程都不需要。更多线程的知识查看这里
总结
协程的组成
通过上面的描述,N:M 模式下的协程其实就是可用户确定调度顺序的用户态线程。与系统级线程对照可以将协程框架分为以下几个模块
- 协程上下文,对应操作系统中的 PCB/TCB(Process/Thread Control Block)
- 保存协程上下文的容器,对应操作系统中保存 PCB/TCB 的容器,一般是一个列表。协程上下文容器可以使用一个也可以使用多个,比如普通协程队列、定时的协程优先队列等
- 协程的执行器
- 协程的调度器,对应操作系统中的进程/线程调度器
- 执行协程的 worker 线程,对应实际线程/进程所使用的 CPU 核心
协程的调度
协程的调度与 OS 线程调度十分相似,如下图协程调度示例所示
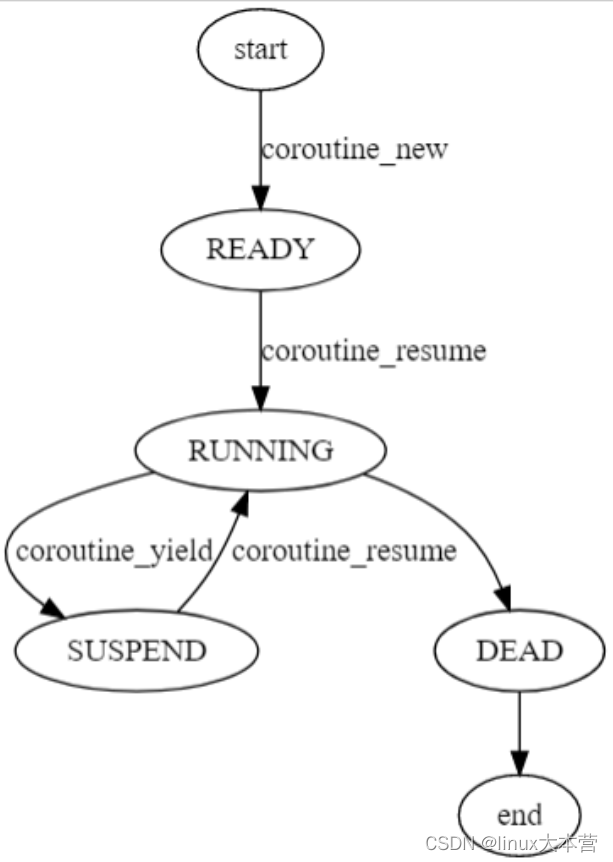
协程工具
系统级线程有锁(mutex)、条件变量(condition)等工具,协程也有对应的工具。比如 libgo 提供了协程之间使用的锁 Co_mutex/Co_rwmutex 。不同协程框架对工具的支持程度不同,实现方式也不尽相同,本文不做深入介绍
系统级线程和协程处于不同的系统层级,所以两者的同步工具不完全通用,如果在协程中使用了线程的锁(例如:std::mutex),则整个线程将会被阻塞,当前线程将不会再调度与执行其他协程
协程 vs 线程
- 调度方式
- 协程由编程者控制,协程之间可以有优先级;线程由系统控制,一般没有优先级
- 调度速度
- 协程几乎比线程快一个数量级。协程调用由编码者控制,可以减少无效的调度
- 资源占用
- 协程可以控制内存占用量,灵活性更好;线程由系统控制
- 创建数量
- 协程的使用更灵活(有优先级控制、资源使用可控),调度速度更快,相比于线程而言调度损耗更小,所以真实可创建且有效的协程数量可以比线程多很多,这是使用协程实现异步编程的重要基础。同样因为调度与资源的限制,有效协程的数量也是有上限的
协程与异步
C++20 只引入了协程需要的底层支持,所以直接使用相对比较难,不过很多库已经提供了封装,比如 ASIO 和 cppcoro 。C++20 协程的性能还是非常高的,等 C++23 提供简化后的 lib,就可以方便使用协程了
编译协程相关代码需要 g++10 或者更高版本(clang++12 对协程支持有限)
- Mac,brew install gcc@10
- Ubuntu,apt install gcc-10 / apt install g++-10
将协程的使用做了封装,大部分情况下我们都不会和底层协程工具打交到,代码的编写风格和常规的同步编码风格相同
协程对 CPU/IO 的影响
协程的目的在于剔除线程的阻塞,尽可能提高 CPU 的利用率
很多服务在处理业务时需要请求第三方服务,向第三方服务发起 RPC 调用。RPC 调用的网络耗时一般耗时在毫秒级别,RPC 服务的处理耗时也可能在毫秒级别,如果当前服务使用同步调用,即 RPC 返回后才进行后续逻辑,那么一条线程每秒处理的业务数量是可以估算的
假设每次业务处理花费在 RPC 调用上的耗时是 20ms,那么一条线程一秒最多处理 50 次请求。如果在等待 RPC 返回时当前线程没有被系统调度转换为 Ready 状态,那当前 CPU 核心就会空转,浪费了 CPU 资源。通过增加线程数量提高系统吞吐量的效果非常有限,而且创建大量线程也会造成其他问题
协程虽然不一定能减少一次业务请求的耗时,但一定可以提升系统的吞吐量:
- 当前业务只有一次第三方 RPC 的调用,那么协程不会减少业务处理的耗时,但可以提升 QPS
- 当前业务需要多个第三方 RPC 调用,同时创建多个协程可以让多个 RPC 调用一起执行,则当前业务的 RPC 耗时由耗时最长的 RPC 调用决定
ASIO C++ 网络编程(同步/异步/协程)
ASIO 是一个跨平台的 C++ 网络库,有非常大的可能进入 C++ 标准库。ASIO 不仅仅提供了网络功能(TCP/UDP/ICMP 等)也提供了很多编程工具,比如串口、定时器等。ASIO 可以脱离 Boost 编译,且只需要[头文件](
https://sourceforge.net/projects/asio/files/asio/1.19.2 (Development)/),使用起来很方便。下面的代码均基于 [ASIO 1.19.2](https://sourceforge.net/projects/asio/files/asio/1.19.2 (Development)/)
阻塞型网络服务(Echo)
参考代码:blocking_tcp_echo_server ,每个请求一个线程。海量请求对系统而言负担比较重
- // g++-10 -I. echo_server.cpp
- void session(tcp::socket sock) {
- // 同步读写操作,下面代码忽略了错误处理逻辑
- for (;;) {
- size_t length = sock.read_some(asio::buffer(data), error);
- asio::write(sock, asio::buffer(data, length));
- }
- }
-
- void server(asio::io_context& io_context, unsigned short port) {
- tcp::acceptor a(io_context, tcp::endpoint(tcp::v4(), port));
- // 注意这里的 a.accept() 是阻塞型操作,accept 返回后才会创建线程
- for (;;) std::thread(session, a.accept()).detach();
- }
-
- int main(int argc, char* argv[]) {
- asio::io_context io_context;
- server(io_context, std::atoi(argv[1]));
- return 0;
- }
非阻塞型 Echo
参考代码:async_tcp_echo_server ,基于事件与回调。所有回调函数中都有对其他接口的调用(比如 do_read 中调用了 do_write),业务逻辑被割裂在不同的回调中
- // g++-10 -I. echo_server.cpp
- class session : public std::enable_shared_from_this<session> {
- public:
- session(tcp::socket socket) : socket_(std::move(socket)) {}
- void start() { do_read(); }
-
- private:
- void do_read() {
- auto self(shared_from_this());
- socket_.async_read_some(asio::buffer(data_, max_length),
- [this, self](...) { if (!ec) do_write(length);});
- }
-
- void do_write(std::size_t length) {
- auto self(shared_from_this());
- asio::async_write(socket_, asio::buffer(data_, length),
- [this, self](...) { if (!ec) do_read(); });
- }
-
- tcp::socket socket_;
- enum { max_length = 1024 };
- char data_[max_length];
- };
-
- class server {
- public:
- server(asio::io_context& io_context, short port)
- : acceptor_(io_context, tcp::endpoint(tcp::v4(), port)) { do_accept(); }
-
- private:
- void do_accept() {
- acceptor_.async_accept([this](std::error_code ec, tcp::socket socket) {
- if (!ec) std::make_shared<session>(std::move(socket))->start();
- do_accept();
- });
- }
-
- tcp::acceptor acceptor_;
- };
-
- int main(int argc, char* argv[]) {
- asio::io_context io_context;
- server s(io_context, std::atoi(argv[1]));
- io_context.run();
- return 0;
- }
协程版 Echo
ASIO 1.19.2 已经支持 C++20 的协程,作者 github 仓库中已经包含了协程的使用示例(coroutines_ts),下面是其中 echo_server 的示例,使用支持 C++20 标准的编译器可直接编译运行
- // g++-10 -fcoroutines -std=c++20 -I. echo_server.cpp
- awaitable<void> echo(tcp::socket socket) {
- try {
- char data[1024];
- size_t n = 0;
- for (;;) {
- n = co_await socket.async_read_some(asio::buffer(data), use_awaitable);
- co_await async_write(socket, asio::buffer(data, n), use_awaitable);
- }
- } catch (std::exception& e) { ... }
- }
-
- awaitable<void> listener() {
- auto executor = co_await this_coro::executor;
- tcp::acceptor acceptor(executor, {tcp::v4(), 55555});
- for (;;) {
- tcp::socket socket = co_await acceptor.async_accept(use_awaitable);
- co_spawn(executor, echo(std::move(socket)), detached);
- }
- }
-
- int main() {
- asio::io_context io_context(1);
- asio::signal_set signals(io_context, SIGINT, SIGTERM);
- signals.async_wait([&](auto, auto) { io_context.stop(); });
- co_spawn(io_context, listener(), detached);
- io_context.run();
- return 0;
- }

