
- 1明峰医疗IPO终止:亏损超过14亿元,王瑶法、潘华素夫妇为实控人_明峰医疗 孙蔚
- 2基于 VSCode下的 Flutter 开发
- 3GFS2+ISCSI+CLVM分布式文件系统集群搭建记录_clvm环境搭建
- 4阿里云Maven和Gradle仓库最新配置_gradle 阿里云
- 5springboot的代码生成器mybatis-plus-generator-ui_springboot代码生成器
- 6升级AndrOid4.3,谷歌发布Android 4.3系统 今日开始升级
- 7Uni-App - JSSDK Debug 技巧_buguisdk.js
- 8【已解决】anaconda配环境“solving environment“卡住(linux)_anaconda一直solving environment
- 9[译] Swift 5 强制独占性原则
- 10Android应用接入支付宝支付详细教程_android接入支付宝支付
3D模型分割新方法解放双手!不用人工标注,只需一次训练,未标注类别也能识别|港大&字节...
赞
踩
丁润语 投稿
量子位 | 公众号 QbitAI
3D模型分割现在也解放双手了!
香港大学和字节梦幻联动,搞出了个新方法:
不需要人工标注,只需要一次训练,就能让3D模型理解语言并识别未标注过的类别。
比如看下面这个例子,未标注的(unannotated)黑板和显示器,3D模型经过这个方法训练之后,就能很快“抓准”目标进行划分。
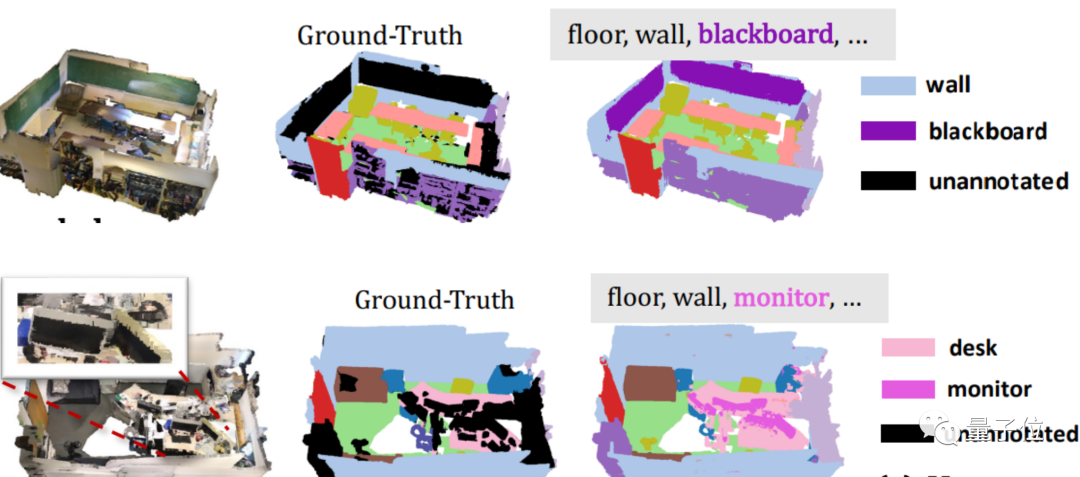
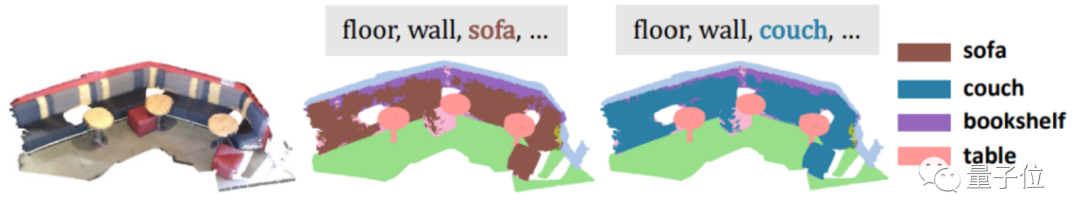
再比如,给它分别输入sofa、cough这类同义词刁难一下,也是轻松拿下。
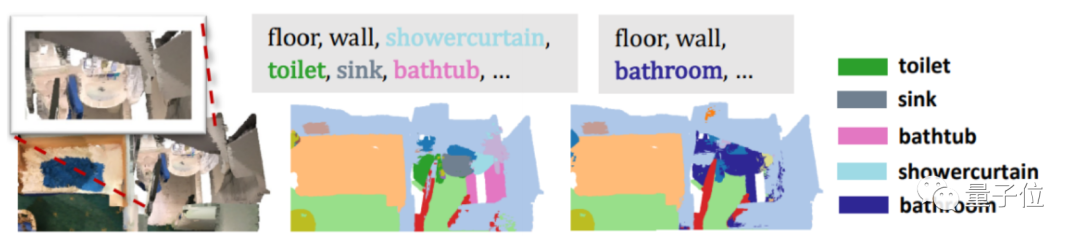
甚至连浴室(bathroom)这类抽象分类也能搞定。
这个新方法名叫PLA (Point-Language Assocation),是一种结合点云(目标表面特性的海量点集合)和⾃然语⾔的方法。
目前,该论文已经被CVPR 2023接收。

不过话说回来,不需要⼈⼯标注,只进行⼀次训练,同义词抽象分类也能识别……这可是重重buff叠加。
要知道一般方法使用的3D数据和⾃然语⾔并不能够直接从⽹上免费获取,往往需要昂贵的⼈⼯标注,而且一般方法也⽆法根据单词之间的语义联系识别新类别。
那PLA又是如何做到的呢?一起来看~
具体原理
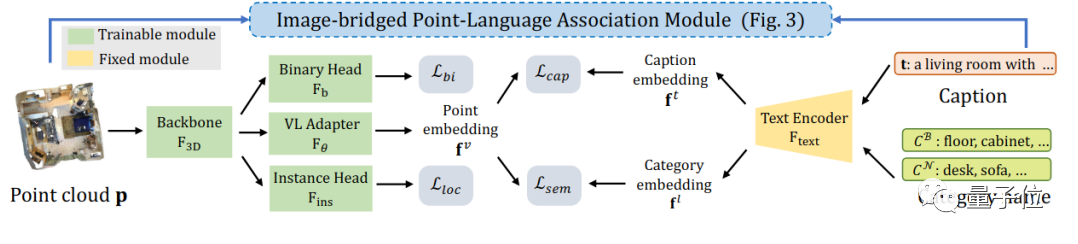
其实说白了,要成功实现3D模型划分,最重要的一步就是让3D数据也能理解⾃然语⾔。
专业点来说,就是要给3D点云引⼊⾃然语⾔的描述。
那怎么引入?
鉴于目前2D图像的划分已经有比较成功的方法,研究团队决定从2D图像入手。
首先,把3D点云转换为对应的2D图像,然后作为2D多模态⼤模型的输⼊,并从中提取对于图像的语⾔描述。
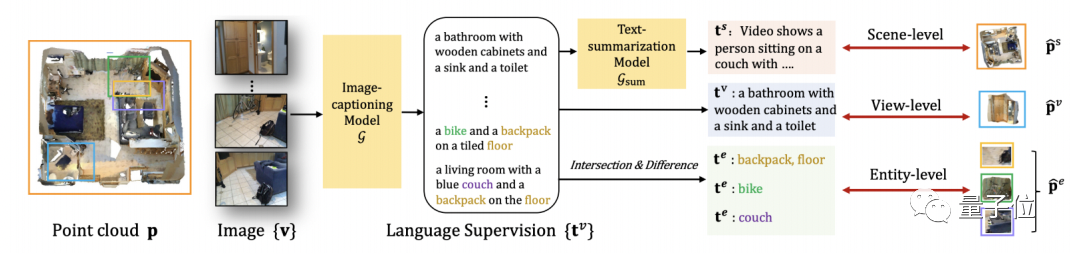
紧接着,利⽤图⽚和点云之间的投影关系,图⽚的语言描述也就自然能够关联到3D点云数据了。
并且,为了兼容不同粒度的3D物体,PLA还提出了多粒度的3D点云-⾃然语⾔关联方法。
对于整个3D场景⽽⾔,PLA将场景对应所有图⽚提取的语⾔描述进⾏总结,并⽤这个总结后的语⾔关联整个3D场景。
对于每个图像视⻆对应的部分3D场景⽽⾔,PLA直接利⽤图像作为桥梁来关联对应的3D点云和语⾔。
对于更加细粒度的3D物体⽽⾔,PLA通过⽐较不同图像对应点云之间的交集和并集,以及语⾔描述部分的交集和并集,提供了⼀种更加细粒度的3D-语⾔关联⽅式。
这样一来,研究团队就能够得到成对的3D点云-⾃然语⾔,这一把直接解决了人工标注的问题。
PLA用得到的“3D点云-⾃然语⾔”对和已有的数据集监督来让3D模型理解检测和分割问题定义。
具体来说,就是利⽤对⽐学习来拉近每对3D点云-⾃然语⾔在特征空间的距离,并推远不匹配的3D点云和⾃然语⾔描述。
讲了这么多原理,那PLA在具体分割任务中表现到底如何?
语义分割任务超越基准65%
研究⼈员通过测试3D开放世界模型在未标注类别的性能作为主要衡量标准。
先是在ScanNet和S3DIS的语义分割任务上,PLA超过以前的基线⽅法35%~65%。
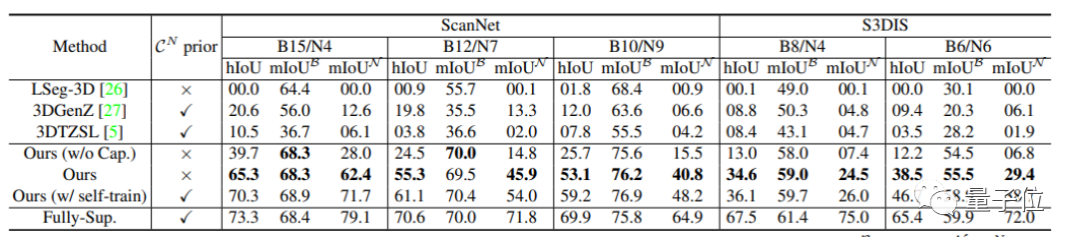
在实例分割任务中,PLA也有提升,对比之前的方法,PLA提升幅度15%~50%不等。

研究团队
这个项目的研究团队来自香港大学的CVMI Lab和字节跳动。
CVMI Lab是香港大学的一个人工智能实验室,实验室2020年2月1日成立。
研究范围涵盖了计算机视觉与模式识别,机器学习/深度学习,图像/视频内容分析以及基于机器智能的工业大数据分析。

论⽂地址:
https://arxiv.org/pdf/2211.16312.pdf
项⽬主⻚:
https://github.com/CVMI-Lab/PLA
— 完 —
3月29日「中国AIGC产业峰会」
抢票开启
「中国AIGC产业峰会」定档3月29日,线下会场抢票开启!
百度袁佛玉、智源林咏华、澜舟科技周明、小冰徐元春、科大讯飞高建清、启元世界袁泉、云舶科技梅嵩、特赞王喆、微软关玮雅、源码资本黄云刚、元语智能朱雷、无界Ai马千里、Tiamat青柑、峰瑞资本陈石等来自产学研界大咖嘉宾,还有重磅嘉宾陆续确认中。
扫描下方二维码,报名峰会线下会场啦~

点这里 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/291394
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

