
- 1原生微信小程序全流程(基础知识+项目全流程)_微信小程序原生开发
- 2【转载】EEG中常用的功能连接指标汇总_eegx
- 3MyBatis全局配置属性_mybatis org.apache.ibatis.parsing.propertyparser.e
- 4在windows通过VS Code开发Linux内核驱动程序_vscode如何编译虚拟机的linux驱动
- 5LaTeX绘图GUI工具介绍_latex draw
- 6第一次机器学习经历_tensorflow how_many_training_steps
- 7史上最全的Unity面试题(含答案)_unity 面试题
- 8(二进制安装)k8s1.9 证书过期及开启自动续期方案.md_10250端口证书过期了怎么处理呢
- 9Android Canvas的使用_android canvas.drawcolor
- 10软考中级系统集成项目管理工程师自学好不好过,怎么备考,给点经验
史上最全Zookeeper面试题及答案总结
赞
踩
今天我先从Zookeeper开启这个话题,文末有最全Java面试题答案大合集福利~
ZooKeeper作为 Dubbo的注册中心为大家熟知,其实并不算陌生。
但是,如果面试官想再进一步,会问到除了做注册中心,Zookeeper还可以解决什么样别的场景?内部的实现机制?核心功能?
下面我就通过图文并茂的方式,从面试题的角度,对Zookeeper做一个完整的梳理和总结。
——嘀嘀!上车了!准备上车了!!——
Zookeeper的理解?

Zookeeper 是一个开源的分布式 协调服务框架,它是一个为分布式应用提供一致性服务的软件。
Zookeeper 致力于提供一个高性能、高可用,且具备严格的顺序访问控制能力的分 布式协调服务,是雅虎公司创建,是 Google 的 Chubby 一个开源的实现。
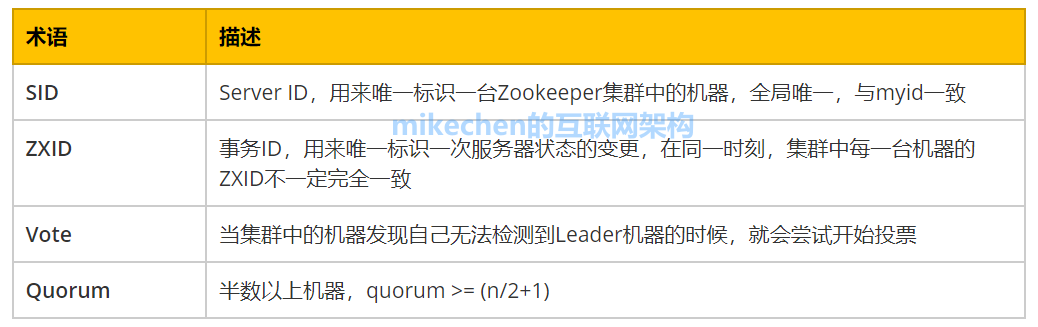
Zookeeper的核心功能?
主要提供了三个核心功能:
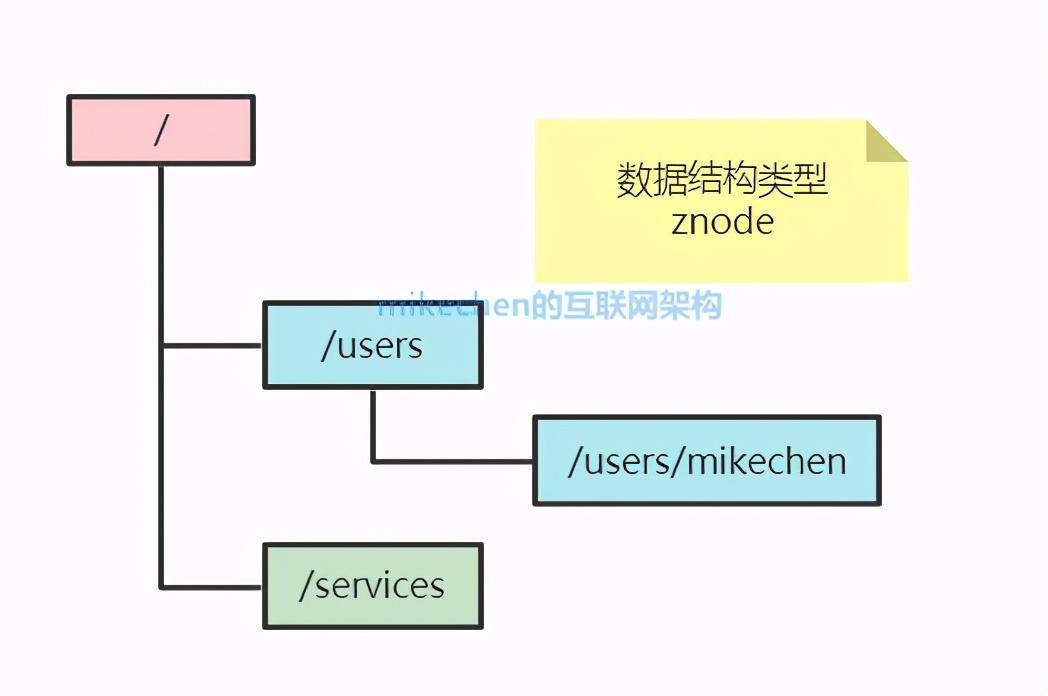
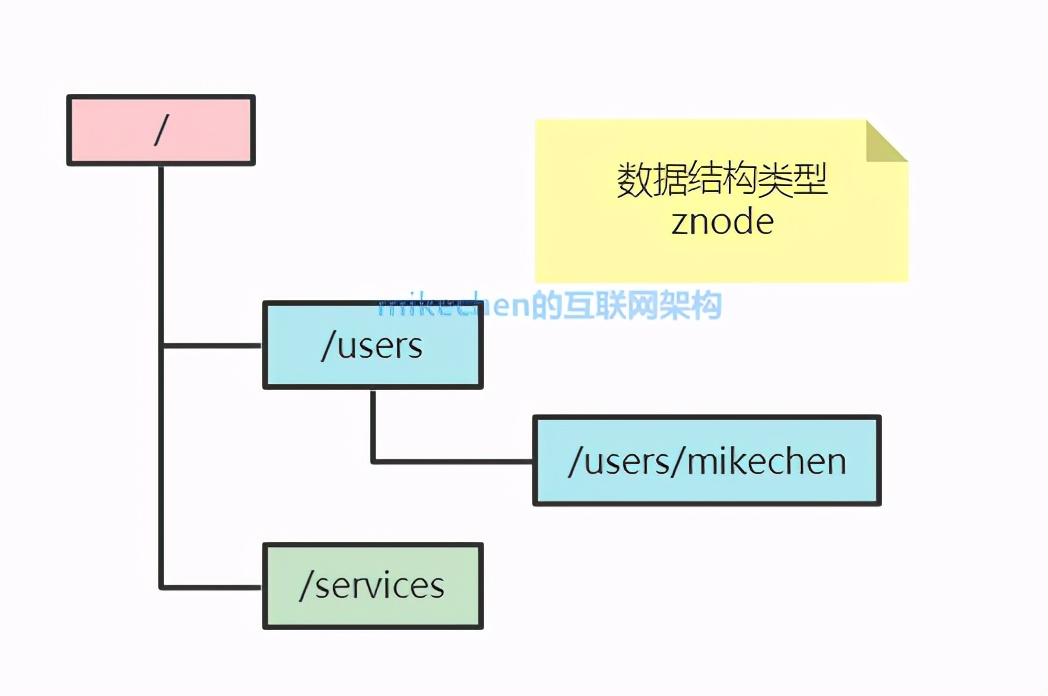
1.文件系统
zk的存储的数据的结构,类似于一个文件系统。
每个节点称为znode,每个znode都是一个类似于KV的结构,每个节点名称相当于key,每个节点中都保存了对应的数据,类似于Key对应的value。每个znode下面都可以有多个子节点,就这样一直延续下去,构成了类似于Linux文件系统的架构。
3.集群管理
当某个client监听某个节点时,当该节点发生变化时(有可能是增加子节点,或者节点值变了等),zk就会通知监听该节点的客户端来处理。
3.集群管理机制
zk本身是一个集群结构,有一个leader节点,负责写请求,多个follower负责响应读请求。并且在leader节点故障时,会自动根据选举机制从剩下的follower中选出新的leader。
Zookeeper的应用场景?
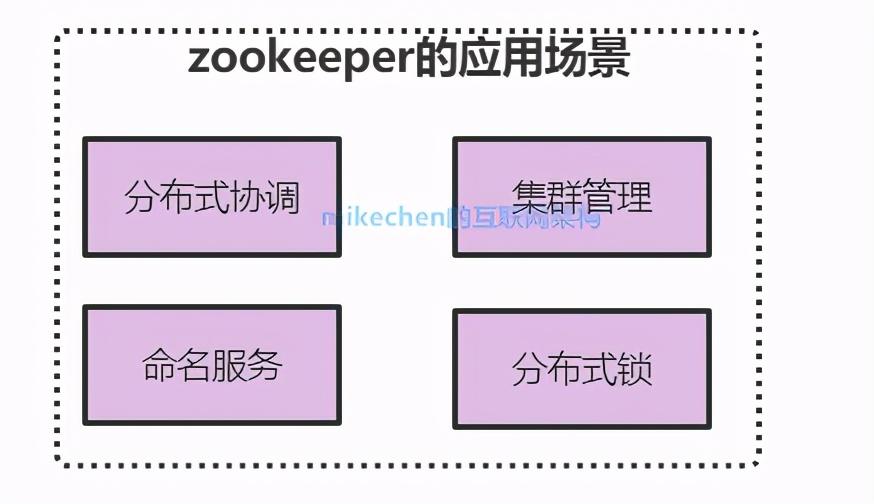
1.命名服务Name Service
依赖Zookeeper可以生成全局唯一的节点ID,来对分布式系统中的资源进行管理。
2.分布式协调
这是Zookeeper的核心使用了,利用Watch的监听机制,一个系统的某个节点状态发生改变,另外系统可以得到通知。
3.集群管理
分布式集群中状态的监控和管理,使用Zookeeper来存储。
4.分布式锁
利用Zookeeper创建临时顺序节点的特性。
Zookeeper使用什么协议?
使用ZAB协议,全称 Zookeeper Atomic Broadcast,从名字可以看出,Zab 协议是一种原子性的消息广播协议。
Zab 协议借鉴了 Paxos 算法,具有一些相似之处,从设计上看,ZAB协议和 Raft 很类似,是一种通用的分布式一致性算法,它是特别为 Zookeeper 设计的支持崩溃恢复的原子广播协议。
如果觉得对Paxos 协议难以理解,建议学习Raft协议,ZAB本质与Raft是类似的。
Zookeeper的工作模式?
1.Zookeeper从设计模式的角度理解,是一个基于观察者模式设计的分布式服务管理框架。
2.基于事件监听通知,监听注册到上面的节点的动向(修改、新增、删除),会实时的通知访问客户端。
3.选举机制,中心化思想,分为主从操作,进行分布式控制所有slave之间的同步决策。
Zookeeper的角色?
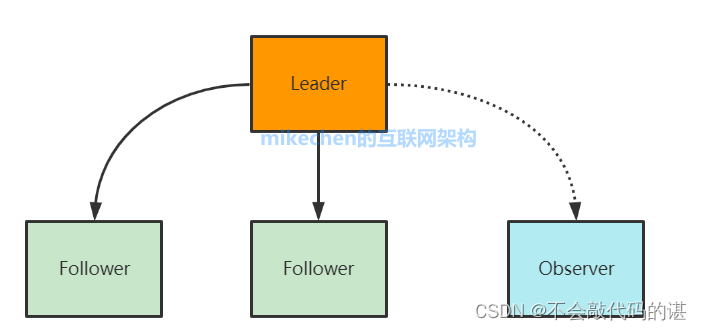
1.leader角色
处理所有的事务请求(写请求),可以处理读请求,集群中只能有一个Leader
2. Follower角色
只能处理读请求,同时作为 Leader的候选节点,即如果Leader宕机,Follower节点要参与到新的Leader选举中,有可能成为新的Leader节点。
3. Observer角色
Observer:只能处理读请求,不能参与选举。
Zookeeper节点类型?
提供了四种类型的数据节点 Znode:

1.持久节点
除非手动删除,否则节点一直存在于Zookeeper上
2.持久顺序节点
基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字
3.临时节点
客户端与Zookeeper断开连接后,该节点被删除
4.临时顺序节点
基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字
Zookeeper的架构与集群规则?

集群为2N+1台,N>0,比如N为1的情况就是3台。
为什么是3台而不是2台呢?因为集群需要一半以上的机器可用,所以,3台挂掉1台还能工作,2台不能。
ZAB协议经历哪些核心阶段?
Zab 协议的原理可细分为四个阶段:选举(Leader Election)、发现(Discovery)、同步(Synchronization)和广播(Broadcast)。
1.Leader election(选举阶段)
节点在一开始都处于选举阶段,只要有一个节点得到超过半数节点的票数,它就可以当选准 Leader。
2.Discovery(发现阶段)
在这个阶段,Followers跟准Leader进行通信,同步Followers最近接收的事务提议。
3.Synchronization(同步阶段)
同步阶段主要是利用Leader前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准Leader才会成为真正的Leader。
4.Broadcast(广播阶段)
到了这个阶段,Zookeeper集群才能正式对外提供事务服务,并且Leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
Zookeeper 的数据模型?
在 Zookeeper 中,可以说 Zookeeper 中的所有存储的数据是由 znode 组成的,节点也称为 znode,并以 key/value 形式存储数据。
整体结构类似于 linux 文件系统的模式以树形结构存储。其中根路径以 / 开头。
Zookeeper如何选举新的leader?
当Zookeeper集群在启动时,或者当leader节点出现网络中断、崩溃等情况时,Zookeeper就会进入恢复模式并选举产生新的 Leader。
第一步:每个Server发出一个投票
第二步:接收来自各个服务器的投票
第三步:PK选票并更新选票
第四步:统计所有投票,判断是否有过半机器接收到相同的投票信息
第五步:改变服务器状态
一旦确定Leader,每个服务器更新自己的状态
Zookeeper如何实现分布式锁?
常见的分布式锁实现方案里面,除了使用redis来实现之外,使用Zookeeper也可以实现分布式锁。
Zookeeper 分布式锁是基于 临时顺序节点 来实现的,锁可理解为 Zookeeper 上的一个节点,当需要获取锁时,就在这个锁节点下创建一个临时顺序节点。
当存在多个客户端同时来获取锁,就按顺序依次创建多个临时顺序节点,但只有排列序号是第一的那个节点能获取锁成功,其他节点则按顺序分别监听前一个节点的变化,当被监听者释放锁时,监听者就可以马上获得锁。
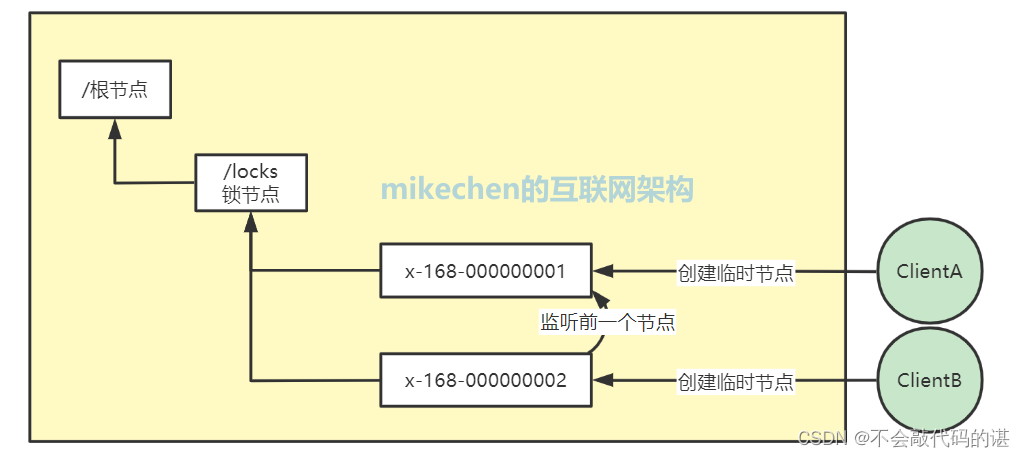
如上图:ClientA 和 ClientB 同时想获取锁,所以都在 locks 节点下创建了一个临时节点 1 和 2,而 1 是当前 locks 节点下排列序号第一的节点,所以 ClientA 获取锁成功,而 ClientB 处于等待状态,这时 Zookeeper 中的 2 节点会监听 1 节点,当 1节点锁释放(节点被删除)时,2 就变成了 locks 节点下排列序号第一的节点,这样 ClientB 就获取锁成功了。
Zookeeper通知机制,Watch实现?
客户端注册监听他关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,Zookeeper会通知客户端。
client端会对某个znode建立一个watcher事件,当该znode发生变化时,zk会主动通知watch这个znode的client,然后client根据znode的变化来做出业务上的改变等。
watch的整体流程如下图所示:

主要流程如下:
1.客户端先向Zookeeper服务端成功注册想要监听的节点状态。
2.同时客户端本地会存储该监听器相关的信息在WatchManager中。
3.当Zookeeper服务端监听的数据状态发生变化时,Zookeeper就会主动通知发送相应事件信息给相关会话客户端,从WatherManager中取出对应Wather对象执行回调逻辑。
以上就是关于Zookeeper的总结!

