
- 1python123题目——计算存款利息_在三行中依次输入初始存款金额,存款年限,年利率,每年末计一次利息并转为本金,计算
- 2推荐系统的架构
- 3【NLP】从变形金刚到Transfomer 01
- 4SpringBoot不用重新打包更新服务jar包_对springboot项目代码进行二改需要重新打包吗
- 5开源大模型成功的背后离不开中国研究人员的贡献_陈述中国对该开源系统的贡献有多少?
- 6《新星计划》全新上线,为想要发光发热的你提供助力~~_csdn新星计划怎么样
- 7常用算法库
- 8人际交往心理学 读后感
- 9Pycharm中bertopic库安装记录_pycharm bertopic安装
- 10基于React低代码平台开发:构建高效、灵活的应用新范式_react低代码开发
【面试】浅学Redis_redis 广播
赞
踩
目录
使用 Java Redis 客户端 Jedis 实现栈和队列的示例代码:
秒杀场景为什么要Redis的存储结构hash?不用其他的存储方式?
Redis的设计模式【单节点模式、主从模式、哨兵模式、集群模式】
讲一下你理解的Redis,为什么Redis很快?
Redis:是一种高性能开源的基于内存的,采用键值对存储的非关系型数据库,不保证数据的ACID特性【事务一旦提交,都不会进行回滚】
采用键值对存储数据在内存或磁盘中,可以对关系型数据库起到补充作用,同时支持持久化[可以将数据保存在可掉电设备中],可以将数据同步保存到磁盘
说Redis很快是相对于关系型数据库如mysql来说的,主要有以下因素
-
第一,数据结构简单,所以速度快【采用键值对的方式】
-
第二,基于内存进行存储,不需要存储数据库,所以速度快
-
第三,采用多路IO复用模型,减少网络IO的时间消耗,避免大量的无用操作,所以速度快
-
第四,单线程避免了线程切换和上下文切换产生的消耗,所以速度快
Mysql:关系型数据库--保证数据的ACID特性【事务的四大特性】
【以关系模型创建的数据库(行和列组成的二维表)】,简单理解:有二维表的数据库。【数据保存在磁盘中-持久化(可以保存在可掉电设备当中)】
非关系型数据库(NoSQL)和关系型数据库(SQL)的区别
非关系型数据库(NoSQL)和关系型数据库(SQL)是两种不同的数据库系统,它们的设计思想和适用场景有所不同。
关系型数据库采用基于表结构的数据模型,使用 SQL 语言对数据进行操作,主要特点是具有强一致性(ACID)和可扩展性不强,适用于数据处理规模较小,数据结构规整,并需要数据一致性和安全的场景,如金融、人事管理等。
而非关系型数据库则基于更加灵活的数据模型,以键值对、文档、图或列族等形式存储数据,因此不需要事先定义数据结构,具有高可扩展性、高性能和数据结构灵活等优点。
NoSQL 数据库适用于规模较大,数据结构不确定,读写频繁,数据变化频繁的场景,如移动设备、社交网络、物联网等。
总体来说,关系型数据库在处理固定结构数据方面表现突出,非关系型数据库在处理半结构化及不定形数据方面具有出色性能,因此视具体业务需求而定,我们可以在这两种数据库之间进行选择。
Redis为什么是单线程的?
1、因为Redis的性能很高,官方网站也有,普通笔记本轻松处理每秒几十万的请求。【这也可以解释为什么不需要进行加锁。因为读取很快。】
2、不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除一个对象。这些操作可能就需要加非常多的锁,导致性能很低。
Redis的5种数据存储结构+使用场景
Redis是典型的key-value类型数据库
存储结构包含:String字符串,List列表,Set集合,ZSet有序集合,Hash哈希。
Redis 在互联网产品中使用的场景实在是太多太多,这里分别对 Redis 几种数据类型做了整理:
1)String字符串:缓存(存储图片验证码和手机验证码)、计数器等。
- // 引入Redis依赖
- import redis.clients.jedis.Jedis;
-
- // 连接Redis
- Jedis jedis = new Jedis("localhost", 6379);
-
- // 存储字符串类型的数据
- jedis.set("username", "johndoe");
-
- // 获取字符串类型的数据
- String username = jedis.get("username");
- System.out.println(username); // 输出 johndoe
2)Hash哈希列表:用户信息、用户主页访问量、组合查询等。
- // 引入Redis依赖
- import redis.clients.jedis.Jedis;
-
- // 连接Redis
- Jedis jedis = new Jedis("localhost", 6379);
-
- // 存储哈希类型的数据
- jedis.hset("user:1", "name", "johndoe");
- jedis.hset("user:1", "age", "30");
- jedis.hset("user:1", "gender", "male");
-
- // 获取哈希类型的数据
- Map<String, String> user = jedis.hgetAll("user:1");
- System.out.println(user.get("name")); // 输出 johndoe
- System.out.println(user.get("age")); // 输出 30
- System.out.println(user.get("gender")); // 输出 male
3)List列表:做队列(排队,FIFO)。
- // 引入Redis依赖
- import redis.clients.jedis.Jedis;
-
- // 连接Redis
- Jedis jedis = new Jedis("localhost", 6379);
-
- // 存储列表类型的数据
- jedis.rpush("news", "redis is fast");
- jedis.rpush("news", "java is popular");
- jedis.rpush("news", "python is versatile");
-
- // 获取列表类型的数据
- List<String> news = jedis.lrange("news", 0, -1);
- System.out.println(news); // 输出 [redis is fast, java is popular, python is versatile]
4)Set集合:抽奖小程序(不能重复参与抽奖),点赞和收藏(不能重复进行点赞)。【不能存储重复的数据,底层存储使用的是map的key进行存储数据】
- // 引入Redis依赖
- import redis.clients.jedis.Jedis;
-
- // 连接Redis
- Jedis jedis = new Jedis("localhost", 6379);
-
- // 存储集合类型的数据
- jedis.sadd("fruit", "apple");
- jedis.sadd("fruit", "banana");
- jedis.sadd("fruit", "orange");
-
- // 获取集合类型的数据
- Set<String> fruit = jedis.smembers("fruit");
- System.out.println(fruit); // 输出 [orange, banana, apple]
5)ZSet有序集合:排行榜(可以根据某个字段进行排序)。
- // 引入Redis依赖
- import redis.clients.jedis.Jedis;
-
- // 连接Redis
- Jedis jedis = new Jedis("localhost", 6379);
-
- // 存储有序集合类型的数据
- jedis.zadd("score", 90, "Tom");
- jedis.zadd("score", 80, "Jerry");
- jedis.zadd("score", 70, "Lucy");
-
- // 获取有序集合类型的数据
- Set<String> score = jedis.zrange("score", 0, -1);
- System.out.println(score); // 输出 [Lucy, Jerry, Tom]
Redis如何存储一个java对象?
Redis如何存储一个Java对象【内涵案例】_MXin5的博客-CSDN博客
Redis是不能直接存储java对象的,但是可以将java对象进行序列化转换成二进制数据(byte[]),然后存储到Redis当中,然后通过反序列化将存储的对象进行取出。可以使用原生的方式和第三方的框架如fastjson,jackson等。
因为:Redis是采用key和value键值对的方式进行存储的,key和value都支持二进制安全的字符串。
你们项目是怎么用Redis的?
使用的是Springboot整合的redis,我们项目中主要使用Redis来存储注册时候的图形验证码和手机验证码,还有使用redis存储黑名单列表,还有用Redis的String存储结构来存储首页经常访问的数据,主要是因为Redis是采用键值对的方式将数据存储在内存当中,我们对数据进行查询的时候直接从内存当中获取,减少去数据库进行查询,从而降低数据库的压力,并且提高了查询效率。
Redis为什么进行持久化?
因为Redis是存储数据是采用键值对的方式进行存储到内存当中,这样读取数据的速度非常快, 但是一旦服务器宕机,内存中的数据将全部丢失。
因此需要将缓存中数据进行持久化, 通常持久化的方式有两种, RDB快照和
AOF日志。
Redis如何解决高并发?
Redis作为一种高性能、高并发、可扩展的基于内存的数据库,有很多解决高并发问题的方法。以下是常见的几种方式:
-
单线程架构:Redis采用的是单线程架构,即一个Redis进程只会使用一个CPU,单个操作会依次执行,避免了多线程带来的锁竞争和线程切换等开销。同时,对于高并发的情况,Redis会通过线程复用和内部多路复用器来提高性能。
-
持久化机制:Redis支持将数据持久化到硬盘上,以防止系统故障等异常情况导致数据丢失。Redis提供两种持久化方式:RDB和AOF。RDB【Redis DataBase】是将整个数据库快照保存到硬盘上,而AOF是将所有的写操作都实时记录到一个append-only文件中,因此无论何时,Redis都可以通过重放AOF文件的方式来恢复丢失的数据。
-
集群模式:在单节点Redis无法满足高并发需求时,可以将多个Redis服务器组成一个集群,通过分片的方式将数据拆分到不同的节点上,提高系统的并发能力。Redis Cluster是官方提供的一种集群方式,它可以将数据分散在多个节点上,并支持自动故障转移和重新平衡分片等功能。
-
缓存机制:Redis常被用作缓存系统,将常用且需要频繁访问的数据存储到内存中,减少数据库的访问压力。同时,使用缓存的方式可以提高查询速度和响应时间,从而提高系统的并发能力。此外,Redis还提供了数据过期机制、LRU等缓存淘汰策略,从而避免缓存数据过期或者占用内存过大等问题。
-
LUA脚本:Redis支持使用LUA脚本来执行复杂的数据操作,利用LUA的脚本编译器和执行器对脚本进行缓存和预编译,从而提高操作的性能和并发能力。
综上所述,Redis通过单线程架构、持久化机制、集群模式、缓存机制、LUA脚本等方式,提高了系统的并发能力和性能,满足高并发场景的需求。
怎么防止Redis宕机数据丢失问题?
Redis本身是一种基于内存的数据库,数据存储在内存中,因此一旦Redis宕机,之前存储在内存中的数据会全部丢失。为了避免Redis宕机数据丢失问题,可以使用以下几种方法:
-
使用Redis的持久化机制:Redis提供了两种持久化机制,即RDB和AOF。RDB是将整个数据库快照保存到硬盘上,而AOF则是将每个写操作记录到一个append-only文件中。这些持久化文件可以被用来在Redis重启时恢复数据。可以根据实际情况选择合适的持久化方式,并设置定期保存持久化文件的频率,防止数据丢失。
-
启用Redis的主从复制:可以在多台机器上运行Redis,并使用主从复制的方式进行数据备份。将一个Redis实例作为主节点,其余的实例作为从节点,主节点将写操作推送到各个从节点上,保持数据的同步。如果主节点宕机,可以从其中一台从节点上恢复数据。
-
做好备份: 定期将Redis的数据备份到一个可靠的存储介质中,例如硬盘或者云存储。一旦遇到数据丢失的情况,可以通过备份数据来进行数据的恢复。
综上所述,使用持久化机制、主从复制和备份等方式,可以有效避免Redis宕机数据丢失问题。
Redis持久化机制是什么?
Redis持久化机制就是将内存中的数据备份到磁盘的过程,就叫作持久化【数据可保存在可掉电设备当中】
Redis持久化机制主要有两种方式,
-
RDB持久化机制【Redis DataBase】:RDB持久化机制是将Redis存储的数据定期快照到硬盘的过程。当设置了RDB机制后,Redis会根据用户的配置策略,定期将数据集的状态进行持久化,存储于硬盘文件中。默认情况下,Redis会在多长时间之后进行一次全量备份,配置如下:
- save 900 1 # 900秒中至少有1个key被修改过
- save 300 10 # 300秒钟中至少有10个key被修改过
- save 60 10000 # 60秒钟中至少有10000个key被修改过
以上配置表示当Redis检测到一定数量的键被修改后,会触发持久化操作,持久化整个数据集到硬盘上。对于快照的生成,Redis采用fork()操作来生成一个新的进程,然后新进程将当前状态写入磁盘文件,最后通过rename()操作覆盖旧的快照文件,整个过程是在内存中操作,所以性能极高。但是,如果系统宕机,则可能会导致最近一次快照之后的数据丢失。
-
AOF持久化机制【Append Only File】:AOF持久化机制是将Redis执行的每条写入命令追加到一个Append Only 日志文件中,以此来确保数据的持久化。当Redis需要重建数据集的时候,只需要把日志文件中的命令重新执行一遍即可。相比RDB持久化机制,AOF持久化机制更加可靠。在AOF持久化机制下,用户可以配置3种写日志的方式:always(默认)、everysec和no,其中默认的always方式每次写入命令都会同步到硬盘,而everysec只会每秒写入一次,no则表示完全不写入日志。用户也可以在特定的时候通过发送一个BGREWRITEAOF命令来重写日志文件,删除其中的过时命令,从而减小日志的体积。
综上所述,Redis的持久化机制是将内存中的数据写入到磁盘中,以确保Redis的持久性和可靠性。RDB持久化机制通过生成快照来备份数据,虽然性能更为优秀,但是有一定的数据可靠性风险。而AOF持久化机制则通过记录每一次的写入命令来记录数据,可靠性更高,但是需要占用更多的磁盘空间和带来一定的性能损耗。
RDB和AOF的差别?【结合使用,各有所长】
RDB和AOF是Redis用于持久化数据的两种方式,两者的主要区别如下:
-
数据格式: RDB持久化方式会把Redis在内存中的数据以二进制格式写入磁盘文件,而AOF则是以文本格式将Redis所有写命令追加到文件末尾。
-
文件大小: AOF文件会迅速增长,而RDB文件大小相对更小。
-
恢复数据速度: 在Redis重新启动时,使用RDB恢复数据更快,因为Redis只需要简单地加载RDB文件,而不需要逐条执行写命令。然而,由于AOF文件包含的是独立的写命令,因此数据恢复时会更慢,因为需要逐条执行写命令。
-
数据一致性: 由于AOF文件包含每个写命令,因此可以更好地保证数据一致性。 在Redis停机时发生崩溃或宕机时,最后一条命令可能不会完全写入AOF文件中,从而导致数据不一致。 在此情况下,Redis会尝试在重启时自动修复AOF文件,以便尽可能多地恢复数据。
综合来看,AOF持久化方式更适合对Redis中数据的完整性要求较高的应用场景,而RDB持久化方式则更适合那些对数据占用空间较为敏感的应用场景。
Redis内存满了不够了怎么办?
Redis采用键值对的方式将数据存储在内存中.
方式一:增加电脑的物理内存【Redis可以使用电脑物理最大内存,当然我们通常会通过设置在redis.windows.conf 中 maxmemory**参数限制Redis内存的使用】**
方式二:使用淘汰策略,删掉一些老旧数据【下面有】
Volatile:不稳定的 --可以理解为有设置过期时间的。
lru【least recently used】:最近最少使用的。
ttl【time to live】:生存时间,还剩多长时间
allkeys:所有的redis键
-
volatile-lru :从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
-
volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰
-
volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
-
allkeys-lru:从 数据集中 挑选最近最少使用的数据淘汰
-
allkeys-random:从数据集中任意选择数据淘汰
-
no-enviction:不能淘汰数据
方式三:Redis使用集群,多个Redis进行存储数据。【还可以解决高并发问题】
扩展:Redis缓存每命中一次Redis中设置过期时间的数据时,就会给命中的数据增加一定的ttl【过期时间】。一段时间后, 热数据的ttl都会较大, 不会自动失效, 而冷数据基本上过了设定的ttl就马上失效了
Redis怎么实现栈和队列?
Redis可以通过列表(List)实现栈和队列的功能,列表是一种支持在左右两端进行快速插入、删除和查询元素的数据结构,因此可以根据插入和删除的方向,实现栈和队列的不同功能。
实现栈的功能,可以通过将列表当做栈来使用,使用Redis的LPUSH和LPOP操作,将元素从左端压入栈中,从左端弹出元素,实现后进先出的效果。
使用 Java Redis 客户端 Jedis 实现栈和队列的示例代码:
- import redis.clients.jedis.Jedis;
-
- public class RedisStackQueueExample {
-
- public static void main(String[] args) {
- // 初始化 Jedis 客户端
- Jedis jedis = new Jedis("localhost");
-
- // 定义列表名称
- String stackName = "my_stack"; //栈
- String queueName = "my_queue"; //队列
-
- // 将元素压入栈中,从栈顶开始插入
- jedis.lpush(stackName, "element1");
- jedis.lpush(stackName, "element2");
- jedis.lpush(stackName, "element3");
-
- // 从栈中弹出元素,从栈顶开始弹出
- System.out.println(jedis.lpop(stackName)); // 输出:element3
- System.out.println(jedis.lpop(stackName)); // 输出:element2
- System.out.println(jedis.lpop(stackName)); // 输出:element1
-
- // 将元素插入队列尾部
- jedis.lpush(queueName, "element1");
- jedis.lpush(queueName, "element2");
- jedis.lpush(queueName, "element3");
-
- // 从队头获取元素
- System.out.println(jedis.rpop(queueName)); // 输出:element1
- System.out.println(jedis.rpop(queueName)); // 输出:element2
- System.out.println(jedis.rpop(queueName)); // 输出:element3
- }
- }
list控制同一边进,同一边出就是栈【先进后出FILO】
list控制一边进,另一边出就是队列【先进先出FIFO】
为什么要对Rdis实现淘汰策略?
因为Redis存储数据是基于内存的,Redis虽然快,但是内存成本还是比较高的,而且基于内存Redis不适合存储太大量的数据。Redis可以使用1电脑物理最大内存,当然我们通常会通过设置maxmemory参数限制Redis内存的使用, 为了让有限的内存空间存储更多的有效数据,2我们可以设置淘汰策略,让Redis自动淘汰那些老旧的,或者不怎么被使用的数据。
Redis的key加一个过期时间,原生的操作命令是什么?
Redis可以为指定的 Key 设置过期时间来控制 Key 的有效期,即在一定的时间后自动删除 Key 和 Value。为 Key 设置过期时间可以使用 EXPIRE 或 EXPIREAT 命令。
EXPIRE key seconds:这个命令用于将指定key的过期时间设置为seconds秒,表示在seconds秒后,指定的key将自动过期并被删除。如果seconds参数设置为0,则表示将指定的key过期时间被清除。示例如下:
EXPIREAT key timestamp:这个命令用于将指定key的过期时间设置为指定的时间戳(timestamp),即指定key所设置的过期时间是一个绝对时间。在指定的timestamp时间点,指定的key将自动过期并被删除。示例如下:
以下是 Java Redis 客户端 Jedis 实现 Key 设置过期时间的示例代码:
- import redis.clients.jedis.Jedis;
-
- public class RedisKeyExpireExample {
-
- public static void main(String[] args) {
- // 初始化 Jedis 客户端
- Jedis jedis = new Jedis("localhost");
-
- // 定义 Key 名称
- String key = "mykey";
-
- // 设置 Key 的过期时间为 60 秒
- jedis.expire(key, 60);
-
- // 设置 Key 的过期时间为指定 Unix 时间戳
- jedis.expireAt(key, 1647654752);
- }
- }
Java Redis 客户端 Jedis 实现永久存储的示例代码:
- import redis.clients.jedis.Jedis;
-
- public class RedisPersistExample {
- public static void main(String[] args) {
- // 初始化 Jedis 客户端
- Jedis jedis = new Jedis("localhost");
-
- // 定义 Key 名称和 Value 值
- String key = "mykey";
- String value = "hello world";
-
- // 存储 Key 值到 Redis 中,并取消 Key 的过期时间
- jedis.set(key, value);
- jedis.persist(key);
- }
- }
当 Key 被取消过期时间之后,该 Key 将永远存在于 Redis 中,除非使用 DEL 命令手动删除。
Redis事务和Mysql事务的区别?
事务的四大特性(ACID):原子性Atomicity 一致性Consistency 隔离性Isolation 持久性Durability
原子性:事务是操作数据库的最小执行单元,只允许出现两种状态,只能同时成功,或者同时失败。
持久性:一旦提交事务不能进行回滚,将数据进行持久化到磁盘中,保证数据不会丢失
隔离性:【事务之间互不影响】两个事务修改同一个数据,必须按顺序执行,并且前一个事务如果未完成,那么中间状态对另一个事务不可见
一致性:【事务执行前后都必须保证数据的总和是一致的】要求任何写到数据库的数据都必须满足预先定义的规则,它基于其他三个特性实现的【【转账的前后金额是一致的,少100,那边就会多100】 】
Mysql的事务是基于undo/redo日志(undolog和redolog日志),记录修改数据前后的状态来实现的.
而Redis的事务是基于队列实现的【Redis中事务不会回滚,就算后面的代码错误,前面的不会因此回滚】
Mysql中的事务满足原子性:即一组操作要么同时成功,要么同时失败,
Redis中的事务不满足原子性和持久性,即一组操作中某些命令执行失败了,其他操作不会回滚.
因此对于比较重要的数据,应该存放在mysql中
使用Redis如何实现消息广播?
理论:
Redis是使用发布和订阅来实现广播的
订阅者通过 SUBSCRIBE channel命令订阅某个频道 , 发布者通过 PUBLISH channel message向该频道发布消息,该频道的所有订阅者都可以收到消息。
使用Java操作Redis的代码示例,实现发布/订阅消息广播:
订阅者:
- import redis.clients.jedis.Jedis;
- import redis.clients.jedis.JedisPubSub;
-
- public class Subscriber {
-
- public static void main(String[] args) {
- Jedis jedis = new Jedis("localhost", 6379);
- jedis.auth("password"); // 如果Redis服务器启用了密码认证,需要先通过该方法进行认证
-
- jedis.subscribe(new JedisPubSub() {
- @Override
- public void onMessage(String channel, String message) {
- System.out.println("[Received] Channel: " + channel + ", Message: " + message);
- }
- }, "channel1");
- }
- }
发布者:
- import redis.clients.jedis.Jedis;
-
- public class Publisher {
-
- public static void main(String[] args) {
- Jedis jedis = new Jedis("localhost", 6379);
- jedis.auth("password"); // 如果Redis服务器启用了密码认证,需要先通过该方法进行认证
-
- jedis.publish("channel1", "Hello, world!");
- }
- }
在实际使用中,需要根据需要修改Redis服务器的IP地址、端口和密码,以及订阅的频道名称和发布的消息内容。同时需要引入Jedis客户端库的依赖,例如在Maven项目中,可以在pom.xml文件中添加以下内容
- <dependency>
- <groupId>redis.clients</groupId>
- <artifactId>jedis</artifactId>
- <version>3.6.3</version>
- </dependency>
为什么要使用Redis做缓存?
主要是读取数据快。Redis是采用键值对的方式将数据存储到缓存当中,客户端可以直接从缓存中获取数据,避免去数据库中进行获取数据,提高了数据的查询效率,降低了对数据库的压力。
我们一般会将经常查询的热点数据,不会经常改变的热点数据,保存到缓存中,提高响应速度,从而提高用户的体验度。
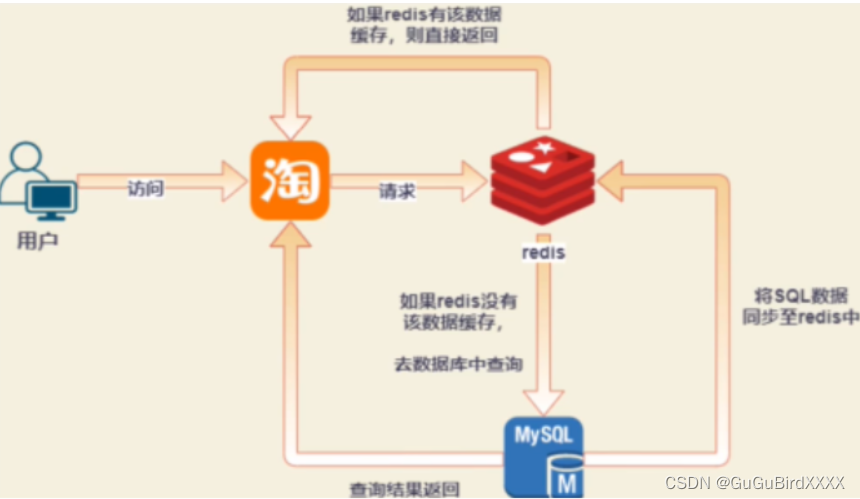
缓存的执行流程?
1.客户端发起查询的请求
2.会首先判断缓存中是否有数据
-
如果有,直接返回
-
如果没有,就从数据库查询,再把数据同步到缓存
3.返回数据给客户端
4.当下一次同样的请求访问时,就直接从缓存中获取数据。
你们怎么保证Redis和Mysql的数据一致性?
如果是对数据进行查询,首先会去缓存中进行查询,如果有就直接返回数据给客户端,如果没有我们就会去数据库进行查询,然后将数据返回给客户端,并且将数据同步到缓存中。
如果是对数据库进行增删改操作时,会在执行完增删改过后,将Redis中的缓存数据进行删除,然后下一次查询数据就去数据库进行查询,将最新的数据同步到缓存中。但是有一个极端问题就是在增删改成功过后,准备去删除Redis中的缓存数据代码之间,如果有查询请求依然会查询到Redis中的老数据,但是这种情况非常极端,而且我们的业务也能容忍这种短暂的脏数据【这些数据没有很大的影响--比如点赞数,浏览量】。
如何解决这个问题呢?保证增删改方法和删除Redis中缓存数据方法的原子性即可,将两行代码变成一行代码,要么都成功,要么都失败。
使用阿里的canal组件监听Mysql事务日志自动同步Redis等
自己的想法:要保证增删改数据库数据要和Redis的一致性,从而可以在增删改方法和删除redis缓存方法入手,保证原子性即可,就是删除这段时间,其他线程不能进行增删改,就是采用加锁的方式【锁住增删改方法和删除redis缓存的方法--效率很低,但是能够保证数据一致性】。
SpringCache常用注解
cache:缓存,evict:驱逐(删除)
springcache是一种基于注解的缓存技术框架。
@EnableCaching:打在主启动类上,开启缓存功能
@Cacheable:【先查询缓存中是否有,有就直接返回,没有就去数据库进行查询,并同步到缓存中】
@CacheEvict:【执行目标方法过后,并删除缓存】
@CachePut:更新缓存(先调用目标方法修改数据库的数据,并更新缓存。)
@Caching:【组合多个注解进行使用】
@CacheConfig:【抽取类中的所有@CachePut@Cacheable@CacheEvict的公共配置】
举一个例子来说明Spring Cache
假设我们有一个UserService服务,它提供了查询用户信息的方法getUserById,这个方法接受一个用户ID,返回一个User对象。我们希望这个方法的性能比较高,所以想使用缓存来优化它。
首先,在UserService类中添加@EnableCaching注解,开启缓存功能:
- @Service
- @EnableCaching
- public class UserService {
- ...
- }
然后,在getUserById方法上添加@Cacheable注解,表示使用缓存:
- @Service
- @EnableCaching
- public class UserService {
- @Cacheable(value = "userCache", key = "#userId")
- public User getUserById(Long userId) {
- // 从数据库中查询用户信息,并返回User对象
- }
- }
这个注解表示使用userCache这个缓存,这个缓存的key是根据用户ID(userId)生成的。
接着,在Spring的配置文件中,我们需要配置一个缓存管理器,例如Ehcache:
- <bean id="cacheManager" class="org.springframework.cache.ehcache.EhCacheCacheManager">
- <property name="cacheManager">
- <bean class="org.springframework.cache.ehcache.EhCacheManagerFactoryBean">
- <property name="configLocation" value="classpath:ehcache.xml" />
- </bean>
- </property>
- </bean>
这个缓存管理器使用了Ehcache库,并且配置文件为ehcache.xml。
最后,在web层调用UserService服务的getUserById方法,就可以使用缓存了:
- @RestController
- public class UserController {
- @Autowired
- private UserService userService;
-
- @GetMapping("/user/{userId}")
- public User getUserById(@PathVariable Long userId) {
- return userService.getUserById(userId);
- }
- }
当第一次调用getUserById方法时,缓存中没有数据,方法会从数据库中查询用户信息,并返回User对象。在返回之前,Spring Cache会将这个对象存储到缓存中。之后再次调用getUserById方法时,Spring Cache会先检查缓存中是否有对应的数据,如果有则直接返回缓存中的数据,从而提高了方法的性能。
Redis缓存击穿,穿透,雪崩?如何解决?
什么是Redis缓存 雪崩、穿透、击穿?【详解】_redis什么是熔断器_MXin5的博客-CSDN博客
缓存击穿:
指的是Redis中某个热点数据,在高并发的情况下,这个热点数据过期了或被淘汰了,导致本来访问这个热点的请求中打到数据库上,导致数据库压力剧增。
-
解决方案:
-
1.加互斥锁,只能允许一个线程访问数据库,然后将数据同步到缓存当中,然后其他线程就可以在缓存中拿
-
2.不设置过期时间,但是有些占内存空间。
缓存穿透:
缓存穿透指查询不存在的数据。用户访问的数据在Redis缓存中和数据库中都没有这样的数据,然后用户不断地使用脚本发送这个请求【查询数据库中id为-1的数据,数据库中的id是自增长从0开始的,没有负数】,这种数据直接穿透缓存,打到数据库上,导致数据库压力剧增。
-
解决方案:
-
1.布隆过滤器来判断数据库中有没有这个key,没有的话,直接返回不存在的结果。
-
2.对参数进行合法校验。
-
3.直接对这个ip进行拉黑,因为基本上都是恶意攻击。
-
4.使用Hystrix熔断器,采用熔断机制和降级策略,直接返回一个兜底数据同步到缓存中,当后续再来请求,直接返回,避免去数据库进行查询。
缓存雪崩:
就是大量的redis在同一时间大面积的失效,大量的请求直接打到数据库上【导致数据库压力飙升】,这种现象就是缓存雪崩
-
解决方案:
-
1.为key设置不同的过期时间
-
2.不设置过期时间
-
3.采用熔断降级策略,返回兜底数据
-
4.使用Redis集群部署,避免单节点出现问题导致整个系统不可以。
你们Redis用来做什么?使用的什么结构?
字符串(String)
-
字符串类型适用于存储简单的数值型数据或字符串型数据,如缓存、计数器、最近登录用户、订单号等等。
实际需求:用 Redis 储存商品库存数据,当销售一件商品时,实时减少库存。
- // 获取 Redisson 实例
- RedissonClient redisson = Redisson.create();
-
- // 获取字符串对象
- String stockKey = "stock:001";
-
- // 设置库存数量
- redisson.getBucket(stockKey).set("100");
-
- // 模拟销售一件商品
- long decrement = redisson.getBucket(stockKey).decrementAndGet();
-
- if (decrement < 0) {
- System.out.println("商品库存不足,无法完成交易");
- }
列表(List)
-
列表类型适用于缓存商品列表、文章列表,最新的操作历史记录、消息队列等,也可用于实现Java中的栈和队列。
实际需求:用 Redis 储存商品订单数据,按照购买时间排序。
- // 获取 Redisson 实例
- RedissonClient redisson = Redisson.create();
-
- // 获取列表对象
- String orderListKey = "orders";
-
- // 添加订单数据到列表中
- Order order = new Order("001", new Date());
- redisson.getList(orderListKey).add(order);
-
- // 按照购买时间排序
- redisson.getList(orderListKey).sortBy(new Comparator<Order>() {
- @Override
- public int compare(Order o1, Order o2) {
- return o1.getPurchaseTime().compareTo(o2.getPurchaseTime());
- }
- });
集合(Set)
-
集合类型适用于去重查询场景,如某个商店的颜色集合、喜好集合等,适合实现朋友圈等互相关注场景。
实际需求:用 Redis 储存用户关注列表数据,实现互相关注查询。
- // 获取 Redisson 实例
- RedissonClient redisson = Redisson.create();
-
- // 获取集合对象
- String followingSetKey = "user:001:following";
- String followersSetKey = "user:001:followers";
-
- // 增加关注
- redisson.getSet(followingSetKey).add("user:002");
-
- // 获取关注列表
- Set<String> followingSet = redisson.getSet(followingSetKey).readAll();
-
- // 获取粉丝列表
- Set<String> followersSet = redisson.getSet(followersSetKey).readAll();
-
- // 判断是否互相关注
- if (followingSet.contains("user:002") && followersSet.contains("user:002")) {
- System.out.println("互相关注");
- }
有序集合(Sorted Set)
-
有序集合类型适用于按照分数或者权重进行排序、筛选场景,如商品积分排名、排行榜、热搜词等,实现Java中的 TreeMap 和 PriorityQueue。
实际需求:用 Redis 储存商品评价数据,按照评分分值排序。
- // 获取 Redisson 实例
- RedissonClient redisson = Redisson.create();
-
- // 获取有序集合对象
- String reviewSortedSetKey = "product:001:reviews";
-
- // 添加评价数据到有序集合中
- Review review = new Review("user:001", 4.5);
- redisson.getScoredSortedSet(reviewSortedSetKey).add(review.getScore(), review);
-
- // 获取评价列表(按照评分从高到低排序)
- Set<Review> reviewSet = redisson.getScoredSortedSet(reviewSortedSetKey).valueRangeReversed(0, -1);
哈希表(Hash)
-
哈希表类型适用于存储和查询更复杂的场景,如各种用户信息,人物角色的属性信息,等等。
总体而言,基于五种不同的 Redis 数据结构,在 Java 开发过程中可以方便地实现缓存、计数器、用户列表、排行榜、点赞、粉丝、朋友圈等各种数据存储需求,并且能够获取到快速的性能以及灵活性。
实际需求:用 Redis 储存用户信息数据,根据邮箱地址查询用户数据。
- // 获取 Redisson 实例
- RedissonClient redisson = Redisson.create();
-
- // 获取哈希表对象
- String userHashKey = "user:001";
-
- // 增加用户信息数据到哈希表中
- User user = new User("user@mail.com", "用户", "123456");
- Map<String, String> userMap = new HashMap<>();
- userMap.put("name", user.getName());
- userMap.put("password", user.getPassword());
- redisson.getMap(userHashKey).putAll(userMap);
-
- // 根据邮箱查询用户信息数据
- Map<String, String> userInfo = redisson.getMap(userHashKey).getAll(Set.of("name", "password
项目是如何做服务降级的?
比如在商品业务中,需要实时从redis中查询库存,通过设置hystrix的最大信号量,以此来防止redis雪崩。当并发过高,请求数超过最大信号量,触发降级,直接向客户端返回兜底数据:”活动太火爆啦,请稍候重试“。
下面用一个实际代码进行举例:
假设我们有一个用户登录系统,该系统的登录接口每秒可以支持数万的并发请求。如果在某一天突然出现大量黑客攻击或者异常高的请求量,超出了系统的承载范围,此时系统可能会发生宕机或者崩溃。为了保证服务的稳定性和可用性,我们可以采用服务降级的方式来解决此问题。
在这种情况下,我们可以使用熔断降级技术来进行服务降级,具体实现步骤如下:
- 定义一个熔断器组件,用于监测接口请求的相应时间和调用失败的比例,并根据一定的阈值触发熔断机制。
- // CircuitBreaker类:熔断器组件,用于监测接口请求的相应时间和调用失败的比例,并根据一定的阈值触发熔断机制。
- public class CircuitBreaker {
- private int consecutiveFailures = 0; // 连续失败次数
- private int failuresThreshold; // 失败次数阈值
- private long coolDownTime; // 熔断恢复时间
- private boolean isTripped; // 是否处于熔断状态
-
- // 构造函数,初始化熔断器组件。
- public CircuitBreaker(int failuresThreshold, long coolDownTime) {
- this.failuresThreshold = failuresThreshold;
- this.coolDownTime = coolDownTime;
- isTripped = false; // 初始化熔断器状态为未熔断
- }
-
- // 记录接口成功相应的方法,重置连续失败次数,并恢复熔断器状态。
- public synchronized void recordSuccess() {
- consecutiveFailures = 0;
- if (isTripped) { // 如果当前处于熔断状态,则恢复熔断器状态
- System.out.println("熔断器恢复正常...");
- isTripped = false;
- }
- }
-
- // 记录接口失败的方法,增加连续失败次数,并触发熔断机制。
- public synchronized void recordFailure() {
- consecutiveFailures++; // 连续失败次数+1
- if (consecutiveFailures >= failuresThreshold && !isTripped) { // 如果连续失败次数超过了阈值,并且当前未处于熔断状态,则触发熔断机制
- System.out.println("接口熔断..."); // 打印熔断日志信息
- isTripped = true; // 设置熔断器状态为已熔断
- new Thread(() -> { // 使用新线程进行熔断器恢复操作
- try {
- Thread.sleep(coolDownTime); // 等待熔断恢复时间
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
-
- isTripped = false; // 恢复熔断器状态
- consecutiveFailures = 0; // 重置连续失败次数
- System.out.println("熔断器恢复正常...");
- }).start();
- }
- }
-
- // 获取当前熔断器状态。
- public boolean isTripped() {
- return isTripped;
- }
- }
- 在登录接口中添加熔断器组件,监测接口请求的相应时间和调用失败的比例。
- // LoginService类:用户登录系统的接口服务类。
- public class LoginService {
- private CircuitBreaker circuitBreaker; // 引入熔断器组件
-
- // 构造函数,初始化熔断器组件。
- public LoginService() {
- circuitBreaker = new CircuitBreaker(10, 5000); // 连续失败次数阈值为10,熔断恢复时间为5000毫秒
- }
-
- // 用户登录接口,返回登录结果。
- public boolean login(String username, String password) {
- // 如果当前熔断器状态为已熔断,则直接返回错误信息。
- if (circuitBreaker.isTripped()) {
- System.out.println("接口已被熔断,请稍后再试...");
- return false;
- }
-
- try {
- // 模拟登录接口,随机抛出异常
- if (Math.random() < 0.8) {
- throw new RuntimeException("系统异常...");
- }
- // 模拟登录验证
- if (username.equals("admin") && password.equals("123456")) {
- circuitBreaker.recordSuccess(); // 登录成功,记录接口成功相应
- System.out.println("登录成功...");
- return true;
- } else {
- circuitBreaker.recordFailure(); // 登录失败,记录接口失败相应
- System.out.println("用户名或密码错误...");
- return false;
- }
- } catch (Exception e) { // 登录失败,记录接口失败相应
- circuitBreaker.recordFailure();
- System.out.println("系统异常...");
- return false;
- }
- }
- }
通过上述实现,当连续失败次数超过阈值时,接口请求会被熔断,此时将直接返回错误信息,保证系统的稳定性和可用性。当熔断器状态恢复后,接口请求会被重新响应。
基于Redis实现的分布式锁?
实现分布式锁的三种方式_nacos分布式锁_MXin5的博客-CSDN博客
Redis如何实现分布式锁,用什么命令?
可以使用setnx来加锁 ,但是需要设置锁的自动删除来防止死锁,所以要结合expire使用.为了保证setnx和expire两个命令的原子性,可以使用set命令组合。
- // 返回值为1表示获取锁成功,返回值为0表示获取锁失败,已经有线程获取到锁了。
- if(jedis.setnx(lock_stock,1) == 1){ //获取锁
- expire(lock_stock,5) //设置锁超时
- try {
- 业务代码
- } finally {
- jedis.del(lock_stock) //释放锁
- }
- }
- // 用来解决原子性问题,在设置锁过期时间之前出现异常,导致没有设置锁过期时间,出现死锁。
- if(set(lock_stock,1,"NX","EX",5) == 1){ //获取锁并设置超时
- try {
- 业务代码
- } finally {
- del(lock_stock) //释放锁
- }
- }
项目中怎么使用分布式锁的?
自己封装Redis的分布式锁是很麻烦的,我们可以使用Redissoin来实现分布式锁,Redissoin已经封装好了Redis实现分布式锁的步骤。
使用场景:比如说订单支付成功和订单超时取消不能同时执行,必须等待前者或后者执行完成才能执行,就可以使用Redission的分布式锁。【再比如吃饭和拉便便的两个业务方法,只能一个先一个后,不然就会出现冲突和出现bug。】
进行代码举例说明Redission实现分布式锁:
本例中测试类中创建了3个线程,分别对共享资源进行访问,通过设置分布式锁,保证同一时刻只能有一个线程对资源进行访问。
- import org.redisson.Redisson;
- import org.redisson.api.RLock;
- import org.redisson.api.RedissonClient;
- import org.redisson.config.Config;
-
- import java.util.concurrent.TimeUnit;
-
- public class RedissonTest {
-
- public static void main(String[] args) {
- // 创建Redisson客户端
- Config config = new Config();
- config.useSingleServer().setAddress("redis://127.0.0.1:6379");
- RedissonClient redissonClient = Redisson.create(config);
-
- // 定义锁的名称
- String lockName = "my_lock";
-
- // 创建三个线程,同时访问共享资源
- Thread t1 = new Thread(() -> {
- // 获取分布式锁
- RLock lock = redissonClient.getLock(lockName);
- lock.lock();
- try {
- System.out.println("Thread 1 start executing");
- Thread.sleep(5000); // 模拟业务执行时间
- System.out.println("Thread 1 finish executing");
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- // 释放锁
- lock.unlock();
- }
- });
-
- Thread t2 = new Thread(() -> {
- // 获取分布式锁
- RLock lock = redissonClient.getLock(lockName);
- lock.lock();
- try {
- System.out.println("Thread 2 start executing");
- Thread.sleep(5000); // 模拟业务执行时间
- System.out.println("Thread 2 finish executing");
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- // 释放锁
- lock.unlock();
- }
- });
-
- Thread t3 = new Thread(() -> {
- // 获取分布式锁
- RLock lock = redissonClient.getLock(lockName);
- lock.lock();
- try {
- System.out.println("Thread 3 start executing");
- Thread.sleep(5000); // 模拟业务执行时间
- System.out.println("Thread 3 finish executing");
- } catch (InterruptedException e) {
- e.printStackTrace();
- } finally {
- // 释放锁
- lock.unlock();
- }
- });
-
- // 启动三个线程
- t1.start();
- t2.start();
- t3.start();
- }
- }
运行上述代码,输出结果如下:
- Thread 1 start executing
- Thread 1 finish executing
- Thread 2 start executing
- Thread 2 finish executing
- Thread 3 start executing
- Thread 3 finish executing
可以看到,通过设置分布式锁,确保了同一时刻只有一个线程能够对共享资源进行访问(谁获取到了就谁用),从而避免了竞态条件。
Redission的看门狗原理?
Redisson对基于Redis实现分布式锁进行了封装,对于锁超时问题 【Redission在设置的过期时间以内还没有执行完对共享资源的操作,锁就过期了】,它提供了看门狗原理,负责定时检测所有key的过期时间,根据需要自动进行过期key的删除和对key到期时间没有完成任务对锁的及时续期。该功能的主要作用是防止Redis服务器因未及时删除过期key而导致的内存泄漏。
接口幂等一般怎么设计?
接口的幂等性怎么设计?_Mark66890620的博客-CSDN博客_接口的幂等性怎么设计
接口幂等就是客户端发送重复的请求时,服务器能够返回的结果是一样的。
接口幂等一般可以通过以下方式实现:
-
唯一标识符:为每个请求分配唯一的标识符,可以使用UUID等机制生成唯一标识符。在接收到客户端请求时,服务器会先检查该请求是否已经处理过,如果已经处理,则直接返回之前的响应。否则,服务器会执行该请求并缓存响应结果和标识符,以便后续的重复请求可以直接返回之前的响应。
该示例为每个请求生成一个UUID作为唯一标识符,在处理请求时,首先从缓存中检查这个UUID是否已经存在,如果已经存在,则返回之前的响应;否则,处理请求并缓存响应结果和UUID。
- public class IdempotenceDemo {
- private final Map<String, String> cache = new ConcurrentHashMap<>();
-
- public String handleRequest(String request) {
- // 生成一个唯一id
- String uuid = UUID.randomUUID().toString();
-
- // 检查请求是否已被处理
- if (cache.containsKey(uuid)) {
- return cache.get(uuid);
- }
-
- // 处理请求(这里简单返回请求本身作为响应)
- String response = request;
-
- // 将响应和唯一标识符存入缓存
- cache.put(uuid, response);
-
- return response;
- }
- }
-
版本号:在每个请求中添加一个版本号字段,每次更新接口时,同时更新版本号,确保新版本的接口不会与旧版本的接口冲突。
该示例为每个请求添加一个版本号字段,在处理请求时,检查版本号是否与当前接口版本一致,如果一致则处理请求;否则,返回版本不匹配的错误响应。
- public class IdempotenceDemo {
- private final int API_VERSION = 1;
-
- public String handleRequest(int version, String request) {
- // 检查版本号是否匹配
- if (version != API_VERSION) {
- return "error: unsupported version";
- }
-
- // 处理请求(这里简单返回请求本身作为响应)
- String response = request;
-
- return response;
- }
- }
-
Token机制:在每个请求中添加一个Token字段,Token是一个随机字符串,由服务器生成并发送给客户端,客户端发送请求时,带上该Token,服务器每次处理请求前,都会检查Token是否合法。
该示例使用Java的UUID类生成一个Token,并将其作为响应头发送给客户端。客户端在发送请求时需要带上这个Token,服务器端在处理请求时,检查Token是否正确,如果正确则处理请求;否则,返回Token不匹配的错误响应。
- public class IdempotenceDemo {
- private final String headerName = "X-Idempotence-Token";
-
- public void sendToken(HttpServletResponse response) {
- // 为每个请求生成一个token
- String token = UUID.randomUUID().toString();
-
- // 把token添加到响应头
- response.setHeader(headerName, token);
- }
-
- public String handleRequest(HttpServletRequest request) {
- // 从请求头中获取token
- String token = request.getHeader(headerName);
-
- // 检查token是否存在
- if (token == null || token.isEmpty()) {
- return "error: missing token";
- }
-
- // 处理请求(这里简单返回请求本身作为响应)
- String response = request.toString();
-
- return response;
- }
- }
-
乐观锁机制:在涉及到更新操作时,使用乐观锁机制,通过对数据加版本号等方式,确保每次更新操作是基于最新的数据进行的。当并发请求发生时,只有一个请求会成功更新数据,其他请求会获取到更新失败的结果。
该示例使用Java的synchronized关键字来控制并发请求的处理,确保只有一个请求能够成功更新数据。使用版本号确保每个操作都基于最新的数据进行,如果版本号不匹配,则返回操作失败的错误响应。
- public class IdempotenceDemo {
- private int data;
- private int version;
-
- public synchronized String modifyData(int newVersion, int newData) {
- // 检查版本号是否匹配
- if (newVersion != version) {
- return "error: version mismatch";
- }
-
- // 更新数据和版本号
- data = newData;
- version++;
-
- // 返回新数据和版本号
- return "data: " + data + ", version: " + version;
- }
- }
Redission的信号量?
Redission的信号量的作用:就是在高并发的场景下,防止多个线程对同一个资源进行修改,从而避免数据不一致的问题。
具体来说,信号量可以用于以下场景:
- 控制并发访问:在高并发场景下,多个线程可能同时访问同一个资源,使用信号量可以控制同时访问该资源的线程数量,防止资源被过度消耗或冲突。
- 限流:在流量控制场景下,使用信号量可以限制同时处理的请求数量,防止系统负载过高。
- 分布式锁:信号量也可以作为分布式锁的一种实现方式,防止不同节点的多个线程同时访问共享资源。
当一个系统中某些接口需要限制同时访问的请求数量时,可以使用 Redisson 的信号量作为限流工具。
下面是一个简单的 Java 代码例子,通过 Redisson 信号量实现对某个 API 的访问率限制:
- import org.redisson.Redisson;
- import org.redisson.api.RSemaphore;
- import org.redisson.api.RedissonClient;
- import org.redisson.config.Config;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
-
- import java.util.concurrent.TimeUnit;
-
- public class ApiRateLimiter {
-
- private final static Logger logger = LoggerFactory.getLogger(ApiRateLimiter.class);
-
- // 最大访问并发数
- private static final int MAX_CONCURRENT_REQUESTS = 10;
-
- // 每秒最大访问次数
- private static final int MAX_ACCESS_PER_SECOND = 5;
-
- // 创建 Redisson 客户端
- private static RedissonClient redissonClient = getRedissonClient();
-
- private static RedissonClient getRedissonClient() {
- Config config = new Config();
- config.useSingleServer()
- .setAddress("redis://localhost:6379")
- .setDatabase(0)
- .setConnectionMinimumIdleSize(5)
- .setConnectionPoolSize(100);
- return Redisson.create(config);
- }
-
- public boolean tryAcquire(String api, long timeout, TimeUnit unit) throws InterruptedException {
- // 使用 API 名称作为信号量的名称
- RSemaphore semaphore = redissonClient.getSemaphore(api);
-
- // 尝试获取信号量,等待一定时间
- boolean success = semaphore.tryAcquire(MAX_ACCESS_PER_SECOND, timeout, unit);
-
- if (!success) {
- logger.info("API \"" + api + "\" is overloaded.");
- return false;
- }
-
- return true;
- }
- }
在上述示例代码中,我们通过 Redisson 的 RSemaphore 获取了一个信号量对象,以 API 名称作为信号量的名称,并且设置信号量的初始值为 5(为了防止第一次请求直接超出最大访问次数)。接着,在 tryAcquire 方法中,通过 tryAcquire 方法尝试获取信号量,等待指定时间。
如果成功获取信号量,则可以访问 API,否则等待时间到期仍未获取到信号量,则认为 API 超负荷,并且返回 false。
常见的秒杀场景使用到Redission的信号量:
Redisson 的信号量可以用于秒杀活动的库存控制。下面是一个简单的 Java 代码例子,演示如何使用 Redisson 的信号量来实现秒杀活动的库存控制:
- import org.redisson.Redisson;
- import org.redisson.api.RSemaphore;
- import org.redisson.api.RedissonClient;
- import org.redisson.config.Config;
- import org.slf4j.Logger;
- import org.slf4j.LoggerFactory;
-
- import java.util.concurrent.TimeUnit;
-
- public class SeckillService {
-
- private final static Logger logger = LoggerFactory.getLogger(SeckillService.class);
-
- // 秒杀商品的库存
- private static final int INVENTORY = 100;
-
- // 秒杀活动的名称,作为 Redisson 信号量的名称
- private static final String SECKILL_EVENT = "seckill_event";
-
- // 创建 Redisson 客户端
- private static final RedissonClient redissonClient = getRedissonClient();
-
- private static RedissonClient getRedissonClient() {
- Config config = new Config();
- config.useSingleServer()
- .setAddress("redis://localhost:6379")
- .setDatabase(0)
- .setConnectionMinimumIdleSize(5)
- .setConnectionPoolSize(100);
- return Redisson.create(config);
- }
-
- public void seckill(String userId) throws Exception {
- // 获取 Redisson 信号量
- RSemaphore semaphore = redissonClient.getSemaphore(SECKILL_EVENT);
-
- // 尝试获取信号量,等待 1 秒钟
- boolean success = semaphore.tryAcquire(1, TimeUnit.SECONDS);
-
- if (!success) {
- logger.info(userId + " - Seckill Failed: Stock is empty.");
- throw new Exception("Stock is empty.");
- }
-
- try {
- // 进行秒杀业务逻辑处理
- if (INVENTORY > 0) {
- logger.info(userId + " - Seckill Success: inventory = " + INVENTORY);
- INVENTORY--;
- } else {
- logger.info(userId + " - Seckill Failed: Stock is empty.");
- throw new Exception("Stock is empty.");
- }
- } finally {
- // 释放 Redisson 信号量
- semaphore.release();
- }
- }
- }
在上述示例代码中,我们先设置了秒杀商品的库存 INVENTORY 为 100,然后利用 Redisson 的信号量功能,通过 redissonClient.getSemaphore 获取名称为 SECKILL_EVENT 的信号量对象。
在 seckill 方法中,我们首先通过 tryAcquire 尝试获取 Redisson 信号量,等待 1 秒钟,如果没有获取到,则表示没有库存了,直接抛出异常并返回。如果获取到了信号量,则进行秒杀业务逻辑处理,在业务处理完成后,通过 release 方法释放 Redisson 信号量。
这样,当用户同时发起多个秒杀请求时,只有有限的请求能够成功获取 Redisson 信号量,进而执行秒杀业务逻辑,然后释放 Redisson 信号量,其他请求则被拦截并抛出异常。这样,可以有效地避免因高并发而导致的商品超卖等问题。
秒杀场景为什么要Redis的存储结构hash?不用其他的存储方式?
在查询的时候需要查询单个商品和商品集合的,还有可能需要对商品进行修改,使用hash的好处就是直接通过key去获取单个对象或者集合。
其他的存储结构,查询单个都不是很方便,需要进行遍历查询,非常损耗性能,这时候使用hash直接使用key就可以进行获取。
查询单个商品使用get【redisTemplate.opsForHash().get】,
查询集合列表使用values【redisTemplate.opsForHash().values】。
Redis的设计模式【单节点模式、主从模式、哨兵模式、集群模式】
Redis四种部署模式(原理、优缺点及解决方案)_少年做自己的英雄的博客-CSDN博客_redis部署模式
一、单节点模式
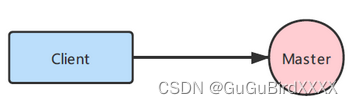
总结归纳:只有一个主节点Master,简单但是会出现单点故障且不能实现高可用。
二、主从模式
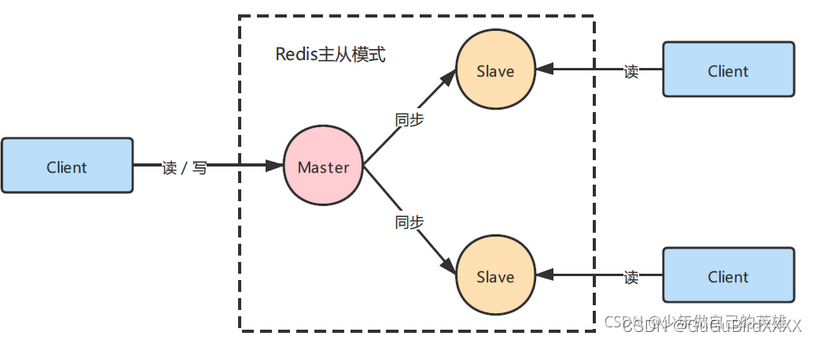
主从模式是一种高可用的解决方案,是一种复制方式,它分为一个主节点服务器和一个或多个从节点服务器。主节点负责所有的写请求和部分读请求,从节点只负责读请求并复制主节点的数据。当主节点发生故障的时候,需要手动的可以将其中的一个从节点提升至主节点,保证系统的高可用。
解决了:主从模式解决了Redis的读取的压力,但不能解决写的压力,不能解决单点故障。
三、哨兵模式
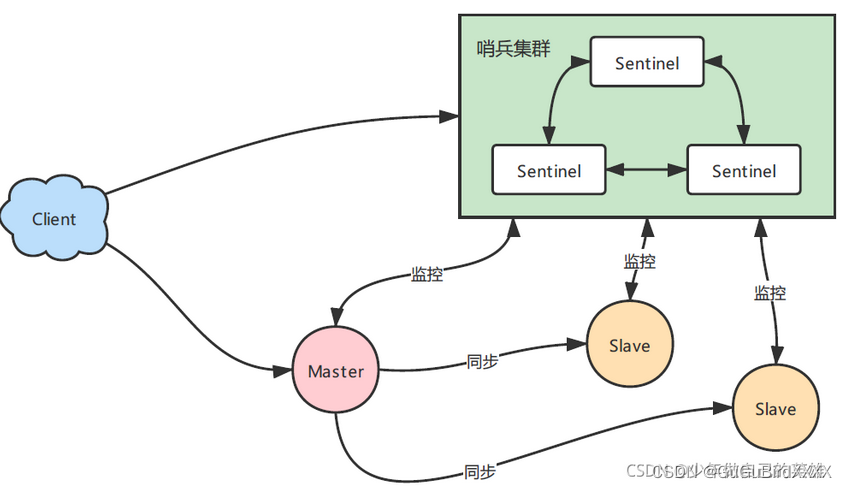
哨兵模式的出现用于解决主从模式中无法自动升级主节点的问题,一个哨兵是一个节点,用于监控主从节点的状态,当主节点挂掉的时候,自动选择一个最优从节点升级为主节点【选举】。
但哨兵如果挂了怎么办?于是哨兵一般都会是一个集群,是集群高可用的心脏,一般由3-5个节点组成,即使个别节点挂了,集群还可以正常运行。
四、 集群模式
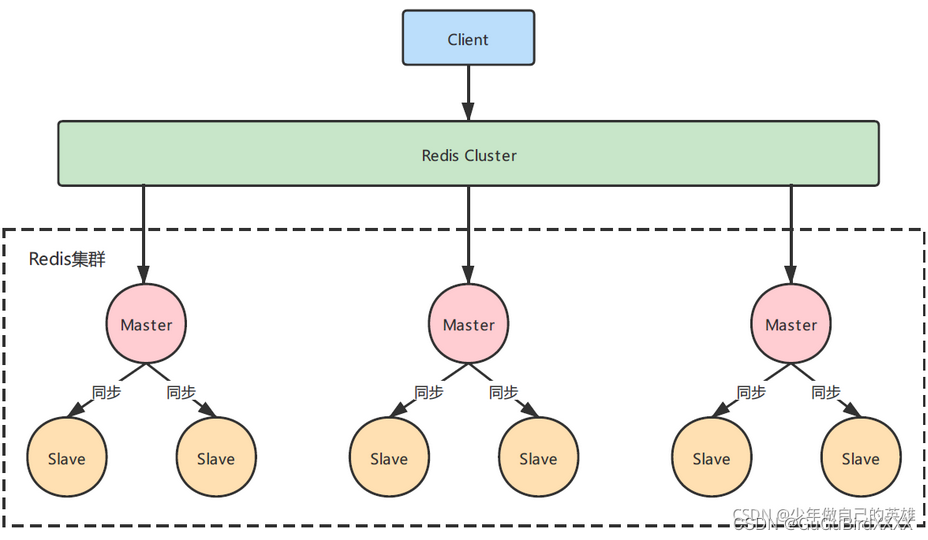
Redis集群模式是通过将数据分散存储到多个主从节点上,从而实现分布式的数据存储和访问。Redis集群分为两种模式:分片式集群和复制式集群。在分片式集群中,数据被分为多个片段,不同的数据片段存储在不同的节点上。在复制式集群中,每个节点都是数据的完整的副本。
什么情况下Redis集群不可用?
-
网络问题:Redis的可用性依赖于网络的稳定性和可靠性,如果网络出现故障、延迟、丢包等问题,可能导致Redis集群不可用。
-
硬件故障:硬件故障是造成Redis集群不可用的常见原因之一。例如,硬盘故障或者内存故障都可能导致Redis实例崩溃并且数据丢失。
-
磁盘空间不足:Redis需要足够的磁盘空间来存储数据和日志文件,如果磁盘空间不足,Redis可能无法工作。
-
错误的配置:一些错误的配置选项可能导致Redis集群不可用。例如,如果Redis集群的最大客户端连接数限制设置过低,可能导致Redis无法正常处理客户端请求。
-
Redis版本问题:某些版本的Redis存在已知的bug或性能问题,在使用时需要注意避免这些问题导致Redis集群不可用。
-
高负载:Redis集群的性能容量与负载有关,在过高的负载下,Redis集群可能出现慢查询、负载不均衡、内存溢出等问题,导致Redis集群不可用。
Redis存储结构底层有没有了解?什么是SDS
Redis的数据存储结构是多种多样的,包括字符串、列表、集合、哈希表、有序集合等。
SDS(Simple Dynamic String)是Redis中常用的一种字符串实现方式。SDS除了存储字符串内容之外,还维护了字符串长度、可用容量以及类型信息等元数据。这使得Redis可以在不重新分配内存的情况下进行字符串的长度修改、拼接、截取等操作,同时也方便了Redis进行数据类型判断和内存管理。
SDS的底层实现主要包括以下几个部分:
-
头部信息:SDS的头部信息保存了该字符串的字节数、已经使用的空间大小以及使用次数等元数据。
-
字符数组:存储实际字符串内容的字符数组。
-
空间管理器:Redis使用空间管理器(如SDS header、tail、free等指针)来跟踪SDS的空间分配和释放情况,以及管理SDS扩容和缩小的行为。
总之,SDS是一种支持可变长度字符串的数据结构,并且能够提供高效的字符串操作和内存管理。Redis使用SDS作为字符串的底层实现,这也体现了Redis在性能和可扩展性方面的优越性能

