
- 1Linux ping --测试与目标主机的连通性_测试宿主机与linux的连通性
- 2AutoGPT 全功能API 接入指南 (云记忆、联网、语音朗读、图像生成)_openai-api key是收费的
- 3[独有源码]springboot协同过滤推荐的餐厅点菜系统b2033借鉴他人经验,找到适合自己的毕业设计_协同过滤算法的智能点餐系统
- 4Android进阶——Android Studio把库Module打包成jar包和aar包小结_android studio 打包aar classes.jar是空的
- 5jieba&hanlp(分词、命名实体识别、词性标注)_jieba命名实体识别
- 6Nodejs 制作命令行工具
- 7Google C++编码规范_谷歌编码规范cpp
- 8MLU370-M8跑大大大规模模型!!!Qwen-72b-chat_怎么判断mlu370-m8对应的compute platform
- 9本地部署GPT的实战方案_公司部署gpt
- 10Kafka——可靠的数据传递_kafka 实时数据传输
自学大语言模型之GPT_题目gpt大语言模型
赞
踩
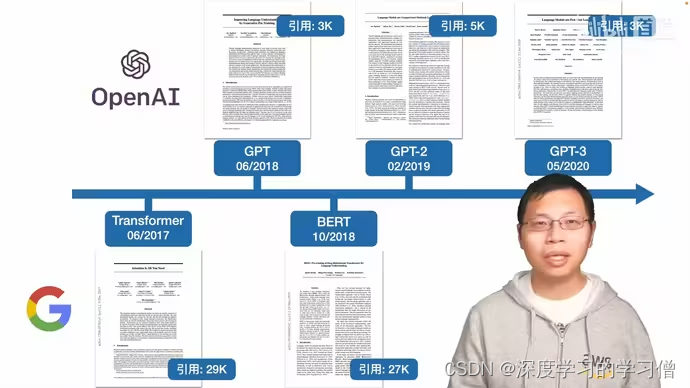
GPT火爆的发展史
-
2017年6月OpenAI联合DeepMind首次正式提出的:Deep Reinforcement Learning from Human Preferences,即基于人类偏好的深度强化学习,简称RLHF
-
2017年7月的OpenAI团队提出的对TRPO算法的改进:PPO算法
-
GPT-1:GPT-1是由OpenAI于2018年发布的第一个版本。它采用了Transformer的编码器架构,通过自回归语言模型的方式进行预训练。GPT-1在多个语言任务上取得了很好的效果,但其生成的文本可能存在一些不连贯或缺乏逻辑性的问题。
-
GPT-2:GPT-2是于2019年发布的第二个版本,相较于GPT-1有了重大的改进。GPT-2采用了更大的模型规模和更多的训练数据,使得模型具备了更强的生成能力。它在多个自然语言处理任务上取得了令人印象深刻的结果,并且引起了广泛的关注。利用了Zero-Shot方法,指直接给模型任务输入让它输出任务结果。
-
Zero-shot Learming则相当于没有练手/预热、没有参考样例/演示/范本,学完知识/方法之后直接答题!
-
One shot Learning (单样本学习),顾名思义,是指在只有一个样本/示例的情况下,预训练语言模型完成特定任务
-
Few-shot Learning (少样本或小样本学习),类似的,是指在只有少量样本/示例的情况下,预训练语言模型完成特定任务
-
GPT-3:GPT-3是于2020年发布的第三个版本,也是目前最先进的版本。GPT-3采用了比GPT-2更大规模的模型和更多的训练数据。它具备了惊人的生成能力和语言理解能力,在各种语言任务上表现出色。GPT-3成为了人们关注的焦点,被认为是自然语言处理领域的重要里程碑。GPT3:In-context learning正式开启prompt新范式(小样本学习)。从传统的离散、连续的Prompt的构建、走向面向超大规模模型的In-Context Learning、Instruction-tuning和Chain-of-Thought。

-
-
2022年11月chatGPT公布,是OpenAI在GPT-3的基础上提出了GPT-3.5版本,23年3月中旬,OpenAI正式对外发布GPT-4,增加了多模态(支持图片的输入形式),且ChatGPT底层的语言模型直接从GPT3.5升级到了GPT4,回答问题的准确率大幅提升,进一步提升了模型的性能和效果。此外,还有一些学术界和工业界的研究者在GPT模型上进行了各种改进和应用,使得GPT模型在自然语言处理领域发挥着重要的作用。
-
23年3月17日,微软推出Microsoft 365 Copilot,集成GPT4的能力,实现自动化办公,通过在Word PPT Excel等办公软件上输入一行指令,瞬间解决一个任务。
-
23年3月24日,OpenAI宣布推出插件功能,赋予ChatGPT使用工具(数学问题精准计算)、联网(获取实时最新消息,底层知识不再只截止到21年9月份)的能力。
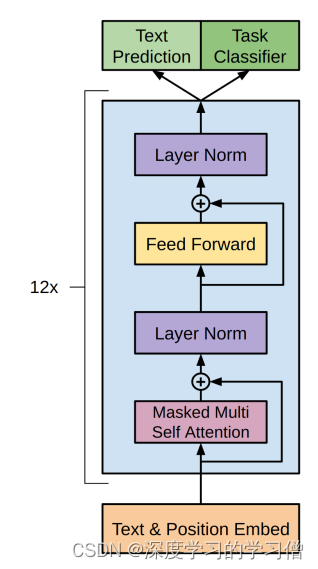
GPT:基于Transformer Decoder预训练 + 微调/Finetune
在模型finetune中,需要根据不同的下游任务来处理输入,主要的下游任务可分为以下四类:
- 分类(Classification):给定一个输入文本,将其分为若干类别中的一类,如情感分类、新闻分类等;
- 蕴含(Entailment):给定两个输入文本,判断它们之间是否存在蕴含关系(即一个文本是否可以从另一个文本中推断出来);
- 相似度(Similarity):给定两个输入文本,计算它们之间的相似度得分;
- 多项选择题(Multiple
choice):给定一个问题和若干个答案选项,选择最佳的答案。
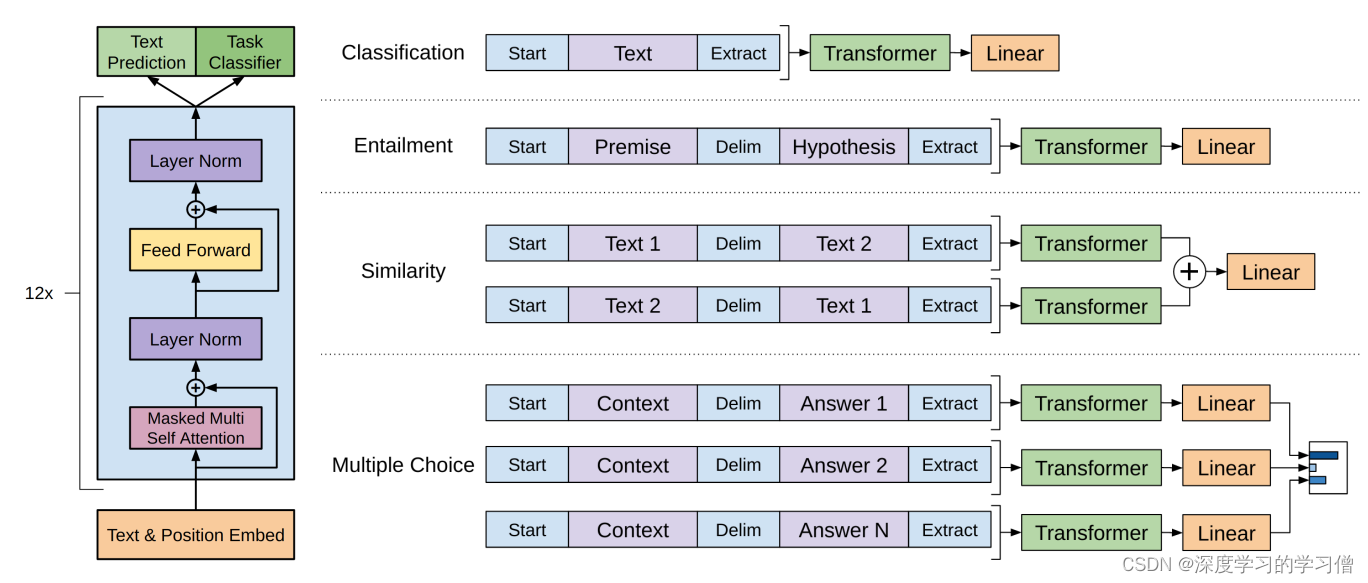
GPT结构图:
GPT2 =基于Transformer Decoder预训练 + 初版prompt
GPT2是在GPT1的基础上进行了进一步的探索和改进,旨在实现零样本学习和小样本学习的能力。传统的预训练加微调模式需要在特定任务上对模型进行适配和微调,而GPT2试图摆脱这种依赖,使模型能够直接应用于不同任务,无需额外的任务适配。
其中,零样本学习(Zero-shot Learning)是指在没有任何样本或示例的情况下,让预训练语言模型完成特定任务。GPT2通过大规模多领域数据的预训练,使模型具备广泛的知识和语言理解能力,在给定任务的输入情况下,模型能够自主地推断并生成相应的任务输出。虽然在某些任务上,GPT2在零样本学习方面的表现可能不如一些最先进的模型,但它已经超越了一些简单的模型,并展现出巨大的潜力。
类似地,一样学习(One-shot Learning)和少样本学习(Few-shot Learning)也是针对有限的样本情况下的学习问题。一样学习指的是在只有一个样本或示例的情况下,预训练语言模型完成特定任务。少样本学习则是指在只有少量样本或示例的情况下,预训练语言模型完成特定任务。这些学习方式旨在让模型更好地适应有限的数据情况,并在给定的样本下做出准确的预测或生成。
通过这些不同的学习方式,GPT2开创了一种新的学习模式,使得语言模型能够更加灵活和适应各种任务,而无需进行额外的适配或微调。这种能力的实现具有巨大的潜力,使得模型能够更加自主地学习和推理,为自然语言处理任务带来了新的可能性。

代码实现过程
import os import logging import numpy as np import mindspore from mindspore import nn from mindspore import ops from mindspore import Tensor from mindspore.common.initializer import initializer, Normal from mindnlp.models.gpt.gpt_config import GPTConfig from mindnlp._legacy.nn import Dropout from mindnlp.abc import PreTrainedModel from mindnlp.models.utils.utils import Conv1D, prune_conv1d_layer, find_pruneable_heads_and_indices from mindnlp.models.utils.utils import SequenceSummary from mindnlp.models.utils.activations import ACT2FN from mindnlp import GPTConfig # Feed-Forward 实现 class MLP(nn.Cell): r""" GPT MLP """ def __init__(self, n_state, config): super().__init__() n_embd = config.n_embd self.c_fc = Conv1D(n_state, n_embd) self.c_proj = Conv1D(n_embd, n_state) self.act = ACT2FN[config.afn] self.dropout = Dropout(p=config.resid_pdrop) def construct(self, x): h = self.act(self.c_fc(x)) h2 = self.c_proj(h) return self.dropout(h2) # Multi-head attention 实现 class Attention(nn.Cell): r""" GPT Attention """ def __init__(self, nx, n_positions, config, scale=False): super().__init__() n_state = nx # in Attention: n_state=768 (nx=n_embd) # [switch nx => n_state from Block to Attention to keep identical to TF implementation] if n_state % config.n_head != 0: raise ValueError(f"Attention n_state shape: {n_state} must be divisible by config.n_head {config.n_head}") self.bias = Tensor(np.tril(np.ones((n_positions, n_positions))), mindspore.float32).view(1, 1, n_positions, n_positions) self.n_head = config.n_head self.split_size = n_state self.scale = scale self.c_attn = Conv1D(n_state * 3, n_state) self.c_attn = Conv1D(n_state * 3, n_state) self.c_proj = Conv1D(n_state, n_state) self.attn_dropout = Dropout(p=config.attn_pdrop) self.resid_dropout = Dropout(p=config.resid_pdrop) self.pruned_heads = set() self.output_attentions = config.output_attentions def prune_heads(self, heads): """ Prunes heads of the model. """ if len(heads) == 0: return head_size = self.split_size//self.n_head heads, index = find_pruneable_heads_and_indices(heads, self.n_head, head_size, self.pruned_heads) index_attn = ops.cat([index, index + self.split_size, index + (2 * self.split_size)]) # Prune conv1d layers self.c_attn = prune_conv1d_layer(self.c_attn, index_attn, axis=1) self.c_proj = prune_conv1d_layer(self.c_proj, index, axis=0) # Update hyper params self.split_size = (self.split_size // self.n_head) * (self.n_head - len(heads)) self.n_head = self.n_head - len(heads) self.pruned_heads = self.pruned_heads.union(heads) def _attn(self, q, k, v, attention_mask=None, head_mask=None): w = ops.matmul(q, k) if self.scale: w = w / ops.sqrt(ops.scalar_to_tensor(v.shape[-1])) b = self.bias[:, :, : w.shape[-2], : w.shape[-1]] w = w * b + -1e9 * (1 - b) if attention_mask is not None: w = w + attention_mask w = ops.softmax(w) w = self.attn_dropout(w) if head_mask is not None: w = w * head_mask outputs = (ops.matmul(w, v),) if self.output_attentions: outputs += (w,) return outputs def merge_heads(self, x): """merge heads""" x = x.transpose(0, 2, 1, 3) new_x_shape = x.shape[:-2] + (x.shape[-2] * x.shape[-1],) return x.view(new_x_shape) def split_heads(self, x, k=False): """split heads""" new_x_shape = x.shape[:-1] + (self.n_head, x.shape[-1] // self.n_head) x = x.view(new_x_shape) if k: return x.transpose(0, 2, 3, 1) return x.transpose(0, 2, 1, 3) def construct(self, x, attention_mask=None, head_mask=None): x = self.c_attn(x) query, key, value = ops.split(x, self.split_size, axis=2) query = self.split_heads(query) key = self.split_heads(key, k=True) value = self.split_heads(value) attn_outputs = self._attn(query, key, value, attention_mask, head_mask) a = attn_outputs[0] a = self.merge_heads(a) a = self.c_proj(a) a = self.resid_dropout(a) outputs = (a,) + attn_outputs[1:] return outputs # transformer decoder block实现 class Block(nn.Cell): r""" GPT Block """ def __init__(self, n_positions, config, scale=False): super().__init__() nx = config.n_embd self.attn = Attention(nx, n_positions, config, scale) self.ln_1 = nn.LayerNorm((nx,), epsilon=config.layer_norm_epsilon) self.mlp = MLP(4 * nx, config) self.ln_2 = nn.LayerNorm((nx,), epsilon=config.layer_norm_epsilon) def construct(self, x, attention_mask=None, head_mask=None): output_attn = self.attn( x, attention_mask=attention_mask, head_mask=head_mask ) a = output_attn[0] n = self.ln_1(x + a) m = self.mlp(n) h = self.ln_2(n + m) outputs = (h,) + output_attn[1:] return outputs # GPT pretrained model实现 class GPTPreTrainedModel(PreTrainedModel): """BertPretrainedModel""" convert_torch_to_mindspore = torch_to_mindspore pretrained_model_archive_map = PRETRAINED_MODEL_ARCHIVE_MAP config_class = GPTConfig base_model_prefix = 'transformer' def _init_weights(self, cell): """Initialize the weights""" if isinstance(cell, nn.Dense): # Slightly different from the TF version which uses truncated_normal for initialization # cf https://github.com/pytorch/pytorch/pull/5617 cell.weight.set_data(initializer(Normal(self.config.initializer_range), cell.weight.shape, cell.weight.dtype)) if cell.has_bias: cell.bias.set_data(initializer('zeros', cell.bias.shape, cell.bias.dtype)) elif isinstance(cell, nn.Embedding): embedding_table = initializer(Normal(self.config.initializer_range), cell.embedding_table.shape, cell.embedding_table.dtype) if cell.padding_idx is not None: embedding_table[cell.padding_idx] = 0 cell.embedding_table.set_data(embedding_table) elif isinstance(cell, nn.LayerNorm): cell.gamma.set_data(initializer('ones', cell.gamma.shape, cell.gamma.dtype)) cell.beta.set_data(initializer('zeros', cell.beta.shape, cell.beta.dtype)) class GPTModel(GPTPreTrainedModel): """ The bare GPT transformer model outputting raw hidden-states without any specific head on top """ def __init__(self, config): super().__init__(config) self.config = config self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) self.drop = nn.Dropout(p=config.embd_pdrop) self.h = nn.CellList([Block(config.n_positions, config, scale=True) for _ in range(config.n_layer)]) self.position_ids = ops.arange(config.n_positions) self.n_layer = self.config.n_layer self.output_attentions = self.config.output_attentions self.output_hidden_states = self.config.output_hidden_states def get_input_embeddings(self): """ return the input embeddings layer """ return self.tokens_embed def set_input_embeddings(self, value): """ set the input embeddings layer """ self.tokens_embed = value def _prune_heads(self, heads_to_prune): """ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} """ for layer, heads in heads_to_prune.items(): self.h[layer].attn.prune_heads(heads) def construct( self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, ): if input_ids is not None and inputs_embeds is not None: raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time") if input_ids is not None: input_shape = input_ids.shape input_ids = input_ids.view(-1, input_shape[-1]) elif inputs_embeds is not None: input_shape = inputs_embeds.shape[:-1] else: raise ValueError("You have to specify either input_ids or inputs_embeds") if position_ids is None: # Code is different from when we had a single embedding matrix from position and token embeddings position_ids = self.position_ids[None, : input_shape[-1]] if attention_mask is not None: attention_mask = attention_mask.unsqueeze(1).unsqueeze(2) attention_mask = attention_mask.to(dtype=next(self.parameters()).dtype) attention_mask = (1.0 - attention_mask) * Tensor(np.finfo(mindspore.dtype_to_nptype(self.dtype)).min, self.dtype) # Prepare head mask if needed head_mask = self.get_head_mask(head_mask, self.n_layer) if inputs_embeds is None: inputs_embeds = self.tokens_embed(input_ids) position_embeds = self.positions_embed(position_ids) if token_type_ids is not None: token_type_ids = token_type_ids.view(-1, token_type_ids.shape[-1]) token_type_embeds = self.tokens_embed(token_type_ids) else: token_type_embeds = 0 hidden_states = inputs_embeds + position_embeds + token_type_embeds hidden_states = self.drop(hidden_states) output_shape = input_shape + (hidden_states.shape[-1],) all_attentions = () all_hidden_states = () for i, block in enumerate(self.h): if self.output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) outputs = block(hidden_states, attention_mask, head_mask[i]) hidden_states = outputs[0] if self.output_attentions: all_attentions = all_attentions + (outputs[1],) hidden_states = hidden_states.view(*output_shape) # Add last layer if self.output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) return (hidden_states, all_hidden_states, all_attentions)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
HuggingFace版GPT
在HuggingFace当中GPT的代码是如何构建
class OpenAIGPTModel(OpenAIGPTPreTrainedModel): def __init__(self, config): super().__init__(config) self.tokens_embed = nn.Embedding(config.vocab_size, config.n_embd) #初始化词嵌入层 self.positions_embed = nn.Embedding(config.n_positions, config.n_embd) #位置嵌入层 self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList([Block(config.n_positions, config, scale=True) for _ in range(config.n_layer)]) #构建模型组容器,用于保存多个nn.Module子模块,并且可以像普通的Python列表一样进行索引和迭代。 self.register_buffer("position_ids", torch.arange(config.n_positions)) #,在模型中注册了一个名为position_ids的缓冲区。缓冲区是模型中用于存储持久化数据的一种特殊张量。 # Initialize weights and apply final processing self.post_init() def get_input_embeddings(self): return self.tokens_embed def set_input_embeddings(self, new_embeddings): self.tokens_embed = new_embeddings def _prune_heads(self, heads_to_prune): """ 修剪模型中的注意力头。heads_to_prune是一个字典,其键为层号,值为需要在该层修剪的注意力头列表heads_to_prune: dict of {layer_num: list of heads to prune in this layer} """ for layer, heads in heads_to_prune.items(): self.h[layer].attn.prune_heads(heads) @add_start_docstrings_to_model_forward(OPENAI_GPT_INPUTS_DOCSTRING) @add_code_sample_docstrings( checkpoint=_CHECKPOINT_FOR_DOC, output_type=BaseModelOutput, config_class=_CONFIG_FOR_DOC, ) def forward( self, input_ids: Optional[torch.LongTensor] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ) -> Union[Tuple[torch.Tensor], BaseModelOutput]: output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions output_hidden_states = ( output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states ) return_dict = return_dict if return_dict is not None else self.config.use_return_dict if input_ids is not None and inputs_embeds is not None: raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time") elif input_ids is not None: input_shape = input_ids.size() input_ids = input_ids.view(-1, input_shape[-1]) elif inputs_embeds is not None: input_shape = inputs_embeds.size()[:-1] else: raise ValueError("You have to specify either input_ids or inputs_embeds") if position_ids is None: # Code is different from when we had a single embedding matrix from position and token embeddings position_ids = self.position_ids[None, : input_shape[-1]] # Attention mask. if attention_mask is not None: # We create a 3D attention mask from a 2D tensor mask. # Sizes are [batch_size, 1, 1, to_seq_length] # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length] # this attention mask is more simple than the triangular masking of causal attention # used in OpenAI GPT, we just need to prepare the broadcast dimension here. attention_mask = attention_mask.unsqueeze(1).unsqueeze(2) # Since attention_mask is 1.0 for positions we want to attend and 0.0 for # masked positions, this operation will create a tensor which is 0.0 for # positions we want to attend and the dtype's smallest value for masked positions. # Since we are adding it to the raw scores before the softmax, this is # effectively the same as removing these entirely. attention_mask = attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min # Prepare head mask if needed head_mask = self.get_head_mask(head_mask, self.config.n_layer) if inputs_embeds is None: inputs_embeds = self.tokens_embed(input_ids) position_embeds = self.positions_embed(position_ids) if token_type_ids is not None: token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) token_type_embeds = self.tokens_embed(token_type_ids) else: token_type_embeds = 0 hidden_states = inputs_embeds + position_embeds + token_type_embeds hidden_states = self.drop(hidden_states) output_shape = input_shape + (hidden_states.size(-1),) all_attentions = () if output_attentions else None all_hidden_states = () if output_hidden_states else None for i, block in enumerate(self.h): if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) outputs = block(hidden_states, attention_mask, head_mask[i], output_attentions=output_attentions) hidden_states = outputs[0] if output_attentions: all_attentions = all_attentions + (outputs[1],) hidden_states = hidden_states.view(*output_shape) # Add last layer if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) if not return_dict: return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None) return BaseModelOutput( last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions, )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
GPT2
# coding=utf-8 # Copyright 2018 The OpenAI Team Authors and HuggingFace Inc. team. # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. """PyTorch OpenAI GPT-2 model.""" import math import os import warnings from dataclasses import dataclass from typing import Optional, Tuple, Union import torch import torch.utils.checkpoint from torch import nn from torch.cuda.amp import autocast from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss from ...activations import ACT2FN from ...modeling_outputs import ( BaseModelOutputWithPastAndCrossAttentions, CausalLMOutputWithCrossAttentions, QuestionAnsweringModelOutput, SequenceClassifierOutputWithPast, TokenClassifierOutput, ) from ...modeling_utils import PreTrainedModel, SequenceSummary from ...pytorch_utils import Conv1D, find_pruneable_heads_and_indices, prune_conv1d_layer from ...utils import ( ModelOutput, add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings, ) from ...utils.model_parallel_utils import assert_device_map, get_device_map from .configuration_gpt2 import GPT2Config logger = logging.get_logger(__name__) _CHECKPOINT_FOR_DOC = "gpt2" _CONFIG_FOR_DOC = "GPT2Config" GPT2_PRETRAINED_MODEL_ARCHIVE_LIST = [ "gpt2", "gpt2-medium", "gpt2-large", "gpt2-xl", "distilgpt2", # See all GPT-2 models at https://huggingface.co/models?filter=gpt2 ] def load_tf_weights_in_gpt2(model, config, gpt2_checkpoint_path): """Load tf checkpoints in a pytorch model""" try: import re import tensorflow as tf except ImportError: logger.error( "Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see " "https://www.tensorflow.org/install/ for installation instructions." ) raise tf_path = os.path.abspath(gpt2_checkpoint_path) logger.info(f"Converting TensorFlow checkpoint from {tf_path}") # Load weights from TF model init_vars = tf.train.list_variables(tf_path) names = [] arrays = [] for name, shape in init_vars: logger.info(f"Loading TF weight {name} with shape {shape}") array = tf.train.load_variable(tf_path, name) names.append(name) arrays.append(array.squeeze()) for name, array in zip(names, arrays): name = name[6:] # skip "model/" name = name.split("/") pointer = model for m_name in name: if re.fullmatch(r"[A-Za-z]+\d+", m_name): scope_names = re.split(r"(\d+)", m_name) else: scope_names = [m_name] if scope_names[0] == "w" or scope_names[0] == "g": pointer = getattr(pointer, "weight") elif scope_names[0] == "b": pointer = getattr(pointer, "bias") elif scope_names[0] == "wpe" or scope_names[0] == "wte": pointer = getattr(pointer, scope_names[0]) pointer = getattr(pointer, "weight") else: pointer = getattr(pointer, scope_names[0]) if len(scope_names) >= 2: num = int(scope_names[1]) pointer = pointer[num] try: assert ( pointer.shape == array.shape ), f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched" except AssertionError as e: e.args += (pointer.shape, array.shape) raise logger.info(f"Initialize PyTorch weight {name}") pointer.data = torch.from_numpy(array) return model class GPT2Attention(nn.Module): def __init__(self, config, is_cross_attention=False, layer_idx=None): super().__init__() max_positions = config.max_position_embeddings self.register_buffer( "bias", torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view( 1, 1, max_positions, max_positions ), ) self.register_buffer("masked_bias", torch.tensor(-1e4)) self.embed_dim = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.embed_dim // self.num_heads self.split_size = self.embed_dim if self.head_dim * self.num_heads != self.embed_dim: raise ValueError( f"`embed_dim` must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:" f" {self.num_heads})." ) self.scale_attn_weights = config.scale_attn_weights self.is_cross_attention = is_cross_attention # Layer-wise attention scaling, reordering, and upcasting self.scale_attn_by_inverse_layer_idx = config.scale_attn_by_inverse_layer_idx self.layer_idx = layer_idx self.reorder_and_upcast_attn = config.reorder_and_upcast_attn if self.is_cross_attention: self.c_attn = Conv1D(2 * self.embed_dim, self.embed_dim) self.q_attn = Conv1D(self.embed_dim, self.embed_dim) else: self.c_attn = Conv1D(3 * self.embed_dim, self.embed_dim) self.c_proj = Conv1D(self.embed_dim, self.embed_dim) self.attn_dropout = nn.Dropout(config.attn_pdrop) self.resid_dropout = nn.Dropout(config.resid_pdrop) self.pruned_heads = set() def prune_heads(self, heads): if len(heads) == 0: return heads, index = find_pruneable_heads_and_indices(heads, self.num_heads, self.head_dim, self.pruned_heads) index_attn = torch.cat([index, index + self.split_size, index + (2 * self.split_size)]) # Prune conv1d layers self.c_attn = prune_conv1d_layer(self.c_attn, index_attn, dim=1) self.c_proj = prune_conv1d_layer(self.c_proj, index, dim=0) # Update hyper params self.split_size = (self.split_size // self.num_heads) * (self.num_heads - len(heads)) self.num_heads = self.num_heads - len(heads) self.pruned_heads = self.pruned_heads.union(heads) def _attn(self, query, key, value, attention_mask=None, head_mask=None): attn_weights = torch.matmul(query, key.transpose(-1, -2)) if self.scale_attn_weights: attn_weights = attn_weights / torch.full( [], value.size(-1) ** 0.5, dtype=attn_weights.dtype, device=attn_weights.device ) # Layer-wise attention scaling if self.scale_attn_by_inverse_layer_idx: attn_weights = attn_weights / float(self.layer_idx + 1) if not self.is_cross_attention: # if only "normal" attention layer implements causal mask query_length, key_length = query.size(-2), key.size(-2) causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length] mask_value = torch.finfo(attn_weights.dtype).min # Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`. # Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device` mask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(attn_weights.device) attn_weights = torch.where(causal_mask, attn_weights.to(attn_weights.dtype), mask_value) if attention_mask is not None: # Apply the attention mask attn_weights = attn_weights + attention_mask attn_weights = nn.functional.softmax(attn_weights, dim=-1) # Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op otherwise attn_weights = attn_weights.type(value.dtype) attn_weights = self.attn_dropout(attn_weights) # Mask heads if we want to if head_mask is not None: attn_weights = attn_weights * head_mask attn_output = torch.matmul(attn_weights, value) return attn_output, attn_weights def _upcast_and_reordered_attn(self, query, key, value, attention_mask=None, head_mask=None): # Use `torch.baddbmm` (a bit more efficient w/ alpha param for scaling -- from Megatron-LM) bsz, num_heads, q_seq_len, dk = query.size() _, _, k_seq_len, _ = key.size() # Preallocate attn_weights for `baddbmm` attn_weights = torch.empty(bsz * num_heads, q_seq_len, k_seq_len, dtype=torch.float32, device=query.device) # Compute Scale Factor scale_factor = 1.0 if self.scale_attn_weights: scale_factor /= float(value.size(-1)) ** 0.5 if self.scale_attn_by_inverse_layer_idx: scale_factor /= float(self.layer_idx + 1) # Upcast (turn off autocast) and reorder (Scale K by 1 / root(dk)) with autocast(enabled=False): q, k = query.reshape(-1, q_seq_len, dk), key.transpose(-1, -2).reshape(-1, dk, k_seq_len) attn_weights = torch.baddbmm(attn_weights, q.float(), k.float(), beta=0, alpha=scale_factor) attn_weights = attn_weights.reshape(bsz, num_heads, q_seq_len, k_seq_len) if not self.is_cross_attention: # if only "normal" attention layer implements causal mask query_length, key_length = query.size(-2), key.size(-2) causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length] mask_value = torch.finfo(attn_weights.dtype).min # Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`. # Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device` mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device) attn_weights = torch.where(causal_mask, attn_weights, mask_value) if attention_mask is not None: # Apply the attention mask attn_weights = attn_weights + attention_mask attn_weights = nn.functional.softmax(attn_weights, dim=-1) # Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op if otherwise if attn_weights.dtype != torch.float32: raise RuntimeError("Error with upcasting, attn_weights does not have dtype torch.float32") attn_weights = attn_weights.type(value.dtype) attn_weights = self.attn_dropout(attn_weights) # Mask heads if we want to if head_mask is not None: attn_weights = attn_weights * head_mask attn_output = torch.matmul(attn_weights, value) return attn_output, attn_weights def _split_heads(self, tensor, num_heads, attn_head_size): """ Splits hidden_size dim into attn_head_size and num_heads """ new_shape = tensor.size()[:-1] + (num_heads, attn_head_size) tensor = tensor.view(new_shape) return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features) def _merge_heads(self, tensor, num_heads, attn_head_size): """ Merges attn_head_size dim and num_attn_heads dim into hidden_size """ tensor = tensor.permute(0, 2, 1, 3).contiguous() new_shape = tensor.size()[:-2] + (num_heads * attn_head_size,) return tensor.view(new_shape) def forward( self, hidden_states: Optional[Tuple[torch.FloatTensor]], layer_past: Optional[Tuple[torch.Tensor]] = None, attention_mask: Optional[torch.FloatTensor] = None, head_mask: Optional[torch.FloatTensor] = None, encoder_hidden_states: Optional[torch.Tensor] = None, encoder_attention_mask: Optional[torch.FloatTensor] = None, use_cache: Optional[bool] = False, output_attentions: Optional[bool] = False, ) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]: if encoder_hidden_states is not None: if not hasattr(self, "q_attn"): raise ValueError( "If class is used as cross attention, the weights `q_attn` have to be defined. " "Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`." ) query = self.q_attn(hidden_states) key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2) attention_mask = encoder_attention_mask else: query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2) query = self._split_heads(query, self.num_heads, self.head_dim) key = self._split_heads(key, self.num_heads, self.head_dim) value = self._split_heads(value, self.num_heads, self.head_dim) if layer_past is not None: past_key, past_value = layer_past key = torch.cat((past_key, key), dim=-2) value = torch.cat((past_value, value), dim=-2) if use_cache is True: present = (key, value) else: present = None if self.reorder_and_upcast_attn: attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask) else: attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask) attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim) attn_output = self.c_proj(attn_output) attn_output = self.resid_dropout(attn_output) outputs = (attn_output, present) if output_attentions: outputs += (attn_weights,) return outputs # a, present, (attentions) class GPT2MLP(nn.Module): def __init__(self, intermediate_size, config): super().__init__() embed_dim = config.hidden_size self.c_fc = Conv1D(intermediate_size, embed_dim) self.c_proj = Conv1D(embed_dim, intermediate_size) self.act = ACT2FN[config.activation_function] self.dropout = nn.Dropout(config.resid_pdrop) def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.FloatTensor: hidden_states = self.c_fc(hidden_states) hidden_states = self.act(hidden_states) hidden_states = self.c_proj(hidden_states) hidden_states = self.dropout(hidden_states) return hidden_states class GPT2Block(nn.Module): def __init__(self, config, layer_idx=None): super().__init__() hidden_size = config.hidden_size inner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_size self.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon) self.attn = GPT2Attention(config, layer_idx=layer_idx) self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon) if config.add_cross_attention: self.crossattention = GPT2Attention(config, is_cross_attention=True, layer_idx=layer_idx) self.ln_cross_attn = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon) self.mlp = GPT2MLP(inner_dim, config) def forward( self, hidden_states: Optional[Tuple[torch.FloatTensor]], layer_past: Optional[Tuple[torch.Tensor]] = None, attention_mask: Optional[torch.FloatTensor] = None, head_mask: Optional[torch.FloatTensor] = None, encoder_hidden_states: Optional[torch.Tensor] = None, encoder_attention_mask: Optional[torch.FloatTensor] = None, use_cache: Optional[bool] = False, output_attentions: Optional[bool] = False, ) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]: residual = hidden_states hidden_states = self.ln_1(hidden_states) attn_outputs = self.attn( hidden_states, layer_past=layer_past, attention_mask=attention_mask, head_mask=head_mask, use_cache=use_cache, output_attentions=output_attentions, ) attn_output = attn_outputs[0] # output_attn: a, present, (attentions) outputs = attn_outputs[1:] # residual connection hidden_states = attn_output + residual if encoder_hidden_states is not None: # add one self-attention block for cross-attention if not hasattr(self, "crossattention"): raise ValueError( f"If `encoder_hidden_states` are passed, {self} has to be instantiated with " "cross-attention layers by setting `config.add_cross_attention=True`" ) residual = hidden_states hidden_states = self.ln_cross_attn(hidden_states) cross_attn_outputs = self.crossattention( hidden_states, attention_mask=attention_mask, head_mask=head_mask, encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_attention_mask, output_attentions=output_attentions, ) attn_output = cross_attn_outputs[0] # residual connection hidden_states = residual + attn_output outputs = outputs + cross_attn_outputs[2:] # add cross attentions if we output attention weights residual = hidden_states hidden_states = self.ln_2(hidden_states) feed_forward_hidden_states = self.mlp(hidden_states) # residual connection hidden_states = residual + feed_forward_hidden_states if use_cache: outputs = (hidden_states,) + outputs else: outputs = (hidden_states,) + outputs[1:] return outputs # hidden_states, present, (attentions, cross_attentions) class GPT2PreTrainedModel(PreTrainedModel): """ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained models. """ config_class = GPT2Config load_tf_weights = load_tf_weights_in_gpt2 base_model_prefix = "transformer" is_parallelizable = True supports_gradient_checkpointing = True _no_split_modules = ["GPT2Block"] def __init__(self, *inputs, **kwargs): super().__init__(*inputs, **kwargs) def _init_weights(self, module): """Initialize the weights.""" if isinstance(module, (nn.Linear, Conv1D)): # Slightly different from the TF version which uses truncated_normal for initialization # cf https://github.com/pytorch/pytorch/pull/5617 module.weight.data.normal_(mean=0.0, std=self.config.initializer_range) if module.bias is not None: module.bias.data.zero_() elif isinstance(module, nn.Embedding): module.weight.data.normal_(mean=0.0, std=self.config.initializer_range) if module.padding_idx is not None: module.weight.data[module.padding_idx].zero_() elif isinstance(module, nn.LayerNorm): module.bias.data.zero_() module.weight.data.fill_(1.0) # Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme: # > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale # > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers. # > -- GPT-2 :: https://openai.com/blog/better-language-models/ # # Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py for name, p in module.named_parameters(): if name == "c_proj.weight": # Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block p.data.normal_(mean=0.0, std=(self.config.initializer_range / math.sqrt(2 * self.config.n_layer))) def _set_gradient_checkpointing(self, module, value=False): if isinstance(module, GPT2Model): module.gradient_checkpointing = value @dataclass class GPT2DoubleHeadsModelOutput(ModelOutput): """ Base class for outputs of models predicting if two sentences are consecutive or not. Args: loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided): Language modeling loss. mc_loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `mc_labels` is provided): Multiple choice classification loss. logits (`torch.FloatTensor` of shape `(batch_size, num_choices, sequence_length, config.vocab_size)`): Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). mc_logits (`torch.FloatTensor` of shape `(batch_size, num_choices)`): Prediction scores of the multiple choice classification head (scores for each choice before SoftMax). past_key_values (`Tuple[Tuple[torch.Tensor]]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`): Tuple of length `config.n_layers`, containing tuples of tensors of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding. hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`): Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer plus the initial embedding outputs. attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`): Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length, sequence_length)`. GPT2Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads. """ loss: Optional[torch.FloatTensor] = None mc_loss: Optional[torch.FloatTensor] = None logits: torch.FloatTensor = None mc_logits: torch.FloatTensor = None past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None hidden_states: Optional[Tuple[torch.FloatTensor]] = None attentions: Optional[Tuple[torch.FloatTensor]] = None GPT2_START_DOCSTRING = r""" This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.) This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior. Parameters: config ([`GPT2Config`]): Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights. """ GPT2_INPUTS_DOCSTRING = r""" Args: input_ids (`torch.LongTensor` of shape `(batch_size, input_ids_length)`): `input_ids_length` = `sequence_length` if `past_key_values` is `None` else `past_key_values[0][0].shape[-2]` (`sequence_length` of input past key value states). Indices of input sequence tokens in the vocabulary. If `past_key_values` is used, only `input_ids` that do not have their past calculated should be passed as `input_ids`. Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for details. [What are input IDs?](../glossary#input-ids) past_key_values (`Tuple[Tuple[torch.Tensor]]` of length `config.n_layers`): Contains precomputed hidden-states (key and values in the attention blocks) as computed by the model (see `past_key_values` output below). Can be used to speed up sequential decoding. The `input_ids` which have their past given to this model should not be passed as `input_ids` as they have already been computed. attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*): Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`: - 1 for tokens that are **not masked**, - 0 for tokens that are **masked**. If `past_key_values` is used, `attention_mask` needs to contain the masking strategy that was used for `past_key_values`. In other words, the `attention_mask` always has to have the length: `len(past_key_values) + len(input_ids)` [What are attention masks?](../glossary#attention-mask) token_type_ids (`torch.LongTensor` of shape `(batch_size, input_ids_length)`, *optional*): Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`: - 0 corresponds to a *sentence A* token, - 1 corresponds to a *sentence B* token. [What are token type IDs?](../glossary#token-type-ids) position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*): Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.max_position_embeddings - 1]`. [What are position IDs?](../glossary#position-ids) head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*): Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`: - 1 indicates the head is **not masked**, - 0 indicates the head is **masked**. inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*): Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This is useful if you want more control over how to convert `input_ids` indices into associated vectors than the model's internal embedding lookup matrix. If `past_key_values` is used, optionally only the last `inputs_embeds` have to be input (see `past_key_values`). use_cache (`bool`, *optional*): If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see `past_key_values`). output_attentions (`bool`, *optional*): Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned tensors for more detail. output_hidden_states (`bool`, *optional*): Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for more detail. return_dict (`bool`, *optional*): Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. """ PARALLELIZE_DOCSTRING = r""" This is an experimental feature and is a subject to change at a moment's notice. Uses a device map to distribute attention modules of the model across several devices. If no device map is given, it will evenly distribute blocks across all devices. Args: device_map (`Dict[int, list]`, optional, defaults to None): A dictionary that maps attention modules to devices. Note that the embedding module and LMHead are always automatically mapped to the first device (for esoteric reasons). That means that the first device should have fewer attention modules mapped to it than other devices. For reference, the gpt2 models have the following number of attention modules: - gpt2: 12 - gpt2-medium: 24 - gpt2-large: 36 - gpt2-xl: 48 Example: ```python # Here is an example of a device map on a machine with 4 GPUs using gpt2-xl, which has a total of 48 attention modules: model = GPT2LMHeadModel.from_pretrained("gpt2-xl") device_map = { 0: [0, 1, 2, 3, 4, 5, 6, 7, 8], 1: [9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], 2: [22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34], 3: [35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47], } model.parallelize(device_map) ``` """ DEPARALLELIZE_DOCSTRING = r""" Moves the model to cpu from a model parallel state. Example: ```python # On a 4 GPU machine with gpt2-large: model = GPT2LMHeadModel.from_pretrained("gpt2-large") device_map = { 0: [0, 1, 2, 3, 4, 5, 6, 7], 1: [8, 9, 10, 11, 12, 13, 14, 15], 2: [16, 17, 18, 19, 20, 21, 22, 23], 3: [24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35], } model.parallelize(device_map) # Splits the model across several devices model.deparallelize() # Put the model back on cpu and cleans memory by calling torch.cuda.empty_cache() ``` """ @add_start_docstrings( "The bare GPT2 Model transformer outputting raw hidden-states without any specific head on top.", GPT2_START_DOCSTRING, ) class GPT2Model(GPT2PreTrainedModel): _keys_to_ignore_on_load_missing = ["attn.masked_bias"] def __init__(self, config): super().__init__(config) self.embed_dim = config.hidden_size self.wte = nn.Embedding(config.vocab_size, self.embed_dim) self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim) self.drop = nn.Dropout(config.embd_pdrop) self.h = nn.ModuleList([GPT2Block(config, layer_idx=i) for i in range(config.num_hidden_layers)]) self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon) # Model parallel self.model_parallel = False self.device_map = None self.gradient_checkpointing = False # Initialize weights and apply final processing self.post_init() @add_start_docstrings(PARALLELIZE_DOCSTRING) def parallelize(self, device_map=None): # Check validity of device_map warnings.warn( "`GPT2Model.parallelize` is deprecated and will be removed in v5 of Transformers, you should load your" " model with `device_map='balanced'` in the call to `from_pretrained`. You can also provide your own" " `device_map` but it needs to be a dictionary module_name to device, so for instance {'h.0': 0, 'h.1': 1," " ...}", FutureWarning, ) self.device_map = ( get_device_map(len(self.h), range(torch.cuda.device_count())) if device_map is None else device_map ) assert_device_map(self.device_map, len(self.h)) self.model_parallel = True self.first_device = "cpu" if "cpu" in self.device_map.keys() else "cuda:" + str(min(self.device_map.keys())) self.last_device = "cuda:" + str(max(self.device_map.keys())) self.wte = self.wte.to(self.first_device) self.wpe = self.wpe.to(self.first_device) # Load onto devices for k, v in self.device_map.items(): for block in v: cuda_device = "cuda:" + str(k) self.h[block] = self.h[block].to(cuda_device) # ln_f to last self.ln_f = self.ln_f.to(self.last_device) @add_start_docstrings(DEPARALLELIZE_DOCSTRING) def deparallelize(self): warnings.warn( "Like `parallelize`, `deparallelize` is deprecated and will be removed in v5 of Transformers.", FutureWarning, ) self.model_parallel = False self.device_map = None self.first_device = "cpu" self.last_device = "cpu" self.wte = self.wte.to("cpu") self.wpe = self.wpe.to("cpu") for index in range(len(self.h)): self.h[index] = self.h[index].to("cpu") self.ln_f = self.ln_f.to("cpu") torch.cuda.empty_cache() def get_input_embeddings(self): return self.wte def set_input_embeddings(self, new_embeddings): self.wte = new_embeddings def _prune_heads(self, heads_to_prune): """ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} """ for layer, heads in heads_to_prune.items(): self.h[layer].attn.prune_heads(heads) @add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING) @add_code_sample_docstrings( checkpoint=_CHECKPOINT_FOR_DOC, output_type=BaseModelOutputWithPastAndCrossAttentions, config_class=_CONFIG_FOR_DOC, ) def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, encoder_hidden_states: Optional[torch.Tensor] = None, encoder_attention_mask: Optional[torch.FloatTensor] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]: output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions output_hidden_states = ( output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states ) use_cache = use_cache if use_cache is not None else self.config.use_cache return_dict = return_dict if return_dict is not None else self.config.use_return_dict if input_ids is not None and inputs_embeds is not None: raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time") elif input_ids is not None: input_shape = input_ids.size() input_ids = input_ids.view(-1, input_shape[-1]) batch_size = input_ids.shape[0] elif inputs_embeds is not None: input_shape = inputs_embeds.size()[:-1] batch_size = inputs_embeds.shape[0] else: raise ValueError("You have to specify either input_ids or inputs_embeds") device = input_ids.device if input_ids is not None else inputs_embeds.device if token_type_ids is not None: token_type_ids = token_type_ids.view(-1, input_shape[-1]) if position_ids is not None: position_ids = position_ids.view(-1, input_shape[-1]) if past_key_values is None: past_length = 0 past_key_values = tuple([None] * len(self.h)) else: past_length = past_key_values[0][0].size(-2) if position_ids is None: position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device) position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1]) # GPT2Attention mask. if attention_mask is not None: if batch_size <= 0: raise ValueError("batch_size has to be defined and > 0") attention_mask = attention_mask.view(batch_size, -1) # We create a 3D attention mask from a 2D tensor mask. # Sizes are [batch_size, 1, 1, to_seq_length] # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length] # this attention mask is more simple than the triangular masking of causal attention # used in OpenAI GPT, we just need to prepare the broadcast dimension here. attention_mask = attention_mask[:, None, None, :] # Since attention_mask is 1.0 for positions we want to attend and 0.0 for # masked positions, this operation will create a tensor which is 0.0 for # positions we want to attend and the dtype's smallest value for masked positions. # Since we are adding it to the raw scores before the softmax, this is # effectively the same as removing these entirely. attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min # If a 2D or 3D attention mask is provided for the cross-attention # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length] if self.config.add_cross_attention and encoder_hidden_states is not None: encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size() encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length) if encoder_attention_mask is None: encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device) encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask) else: encoder_attention_mask = None # Prepare head mask if needed # 1.0 in head_mask indicate we keep the head # attention_probs has shape bsz x n_heads x N x N # head_mask has shape n_layer x batch x n_heads x N x N head_mask = self.get_head_mask(head_mask, self.config.n_layer) if inputs_embeds is None: inputs_embeds = self.wte(input_ids) position_embeds = self.wpe(position_ids) hidden_states = inputs_embeds + position_embeds if token_type_ids is not None: token_type_embeds = self.wte(token_type_ids) hidden_states = hidden_states + token_type_embeds hidden_states = self.drop(hidden_states) output_shape = input_shape + (hidden_states.size(-1),) if self.gradient_checkpointing and self.training: if use_cache: logger.warning_once( "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..." ) use_cache = False presents = () if use_cache else None all_self_attentions = () if output_attentions else None all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None all_hidden_states = () if output_hidden_states else None for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)): # Model parallel if self.model_parallel: torch.cuda.set_device(hidden_states.device) # Ensure layer_past is on same device as hidden_states (might not be correct) if layer_past is not None: layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past) # Ensure that attention_mask is always on the same device as hidden_states if attention_mask is not None: attention_mask = attention_mask.to(hidden_states.device) if isinstance(head_mask, torch.Tensor): head_mask = head_mask.to(hidden_states.device) if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) if self.gradient_checkpointing and self.training: def create_custom_forward(module): def custom_forward(*inputs): # None for past_key_value return module(*inputs, use_cache, output_attentions) return custom_forward outputs = torch.utils.checkpoint.checkpoint( create_custom_forward(block), hidden_states, None, attention_mask, head_mask[i], encoder_hidden_states, encoder_attention_mask, ) else: outputs = block( hidden_states, layer_past=layer_past, attention_mask=attention_mask, head_mask=head_mask[i], encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_attention_mask, use_cache=use_cache, output_attentions=output_attentions, ) hidden_states = outputs[0] if use_cache is True: presents = presents + (outputs[1],) if output_attentions: all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],) if self.config.add_cross_attention: all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],) # Model Parallel: If it's the last layer for that device, put things on the next device if self.model_parallel: for k, v in self.device_map.items(): if i == v[-1] and "cuda:" + str(k) != self.last_device: hidden_states = hidden_states.to("cuda:" + str(k + 1)) hidden_states = self.ln_f(hidden_states) hidden_states = hidden_states.view(output_shape) # Add last hidden state if output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) if not return_dict: return tuple( v for v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions] if v is not None ) return BaseModelOutputWithPastAndCrossAttentions( last_hidden_state=hidden_states, past_key_values=presents, hidden_states=all_hidden_states, attentions=all_self_attentions, cross_attentions=all_cross_attentions, ) @add_start_docstrings( """ The GPT2 Model transformer with a language modeling head on top (linear layer with weights tied to the input embeddings). """, GPT2_START_DOCSTRING, ) class GPT2LMHeadModel(GPT2PreTrainedModel): _keys_to_ignore_on_load_missing = [r"attn.masked_bias", r"attn.bias", r"lm_head.weight"] def __init__(self, config): super().__init__(config) self.transformer = GPT2Model(config) self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False) # Model parallel self.model_parallel = False self.device_map = None # Initialize weights and apply final processing self.post_init() @add_start_docstrings(PARALLELIZE_DOCSTRING) def parallelize(self, device_map=None): warnings.warn( "`GPT2LMHeadModel.parallelize` is deprecated and will be removed in v5 of Transformers, you should load" " your model with `device_map='balanced'` in the call to `from_pretrained`. You can also provide your own" " `device_map` but it needs to be a dictionary module_name to device, so for instance {'transformer.h.0':" " 0, 'transformer.h.1': 1, ...}", FutureWarning, ) self.device_map = ( get_device_map(len(self.transformer.h), range(torch.cuda.device_count())) if device_map is None else device_map ) assert_device_map(self.device_map, len(self.transformer.h)) self.transformer.parallelize(self.device_map) self.lm_head = self.lm_head.to(self.transformer.first_device) self.model_parallel = True @add_start_docstrings(DEPARALLELIZE_DOCSTRING) def deparallelize(self): warnings.warn( "Like `parallelize`, `deparallelize` is deprecated and will be removed in v5 of Transformers.", FutureWarning, ) self.transformer.deparallelize() self.transformer = self.transformer.to("cpu") self.lm_head = self.lm_head.to("cpu") self.model_parallel = False torch.cuda.empty_cache() def get_output_embeddings(self): return self.lm_head def set_output_embeddings(self, new_embeddings): self.lm_head = new_embeddings def prepare_inputs_for_generation(self, input_ids, past_key_values=None, inputs_embeds=None, **kwargs): token_type_ids = kwargs.get("token_type_ids", None) # only last token for inputs_ids if past is defined in kwargs if past_key_values: input_ids = input_ids[:, -1].unsqueeze(-1) if token_type_ids is not None: token_type_ids = token_type_ids[:, -1].unsqueeze(-1) attention_mask = kwargs.get("attention_mask", None) position_ids = kwargs.get("position_ids", None) if attention_mask is not None and position_ids is None: # create position_ids on the fly for batch generation position_ids = attention_mask.long().cumsum(-1) - 1 position_ids.masked_fill_(attention_mask == 0, 1) if past_key_values: position_ids = position_ids[:, -1].unsqueeze(-1) else: position_ids = None # if `inputs_embeds` are passed, we only want to use them in the 1st generation step if inputs_embeds is not None and past_key_values is None: model_inputs = {"inputs_embeds": inputs_embeds} else: model_inputs = {"input_ids": input_ids} model_inputs.update( { "past_key_values": past_key_values, "use_cache": kwargs.get("use_cache"), "position_ids": position_ids, "attention_mask": attention_mask, "token_type_ids": token_type_ids, } ) return model_inputs @add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING) @add_code_sample_docstrings( checkpoint=_CHECKPOINT_FOR_DOC, output_type=CausalLMOutputWithCrossAttentions, config_class=_CONFIG_FOR_DOC, ) def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, encoder_hidden_states: Optional[torch.Tensor] = None, encoder_attention_mask: Optional[torch.FloatTensor] = None, labels: Optional[torch.LongTensor] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ) -> Union[Tuple, CausalLMOutputWithCrossAttentions]: r""" labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*): Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]` """ return_dict = return_dict if return_dict is not None else self.config.use_return_dict transformer_outputs = self.transformer( input_ids, past_key_values=past_key_values, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, encoder_hidden_states=encoder_hidden_states, encoder_attention_mask=encoder_attention_mask, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) hidden_states = transformer_outputs[0] # Set device for model parallelism if self.model_parallel: torch.cuda.set_device(self.transformer.first_device) hidden_states = hidden_states.to(self.lm_head.weight.device) lm_logits = self.lm_head(hidden_states) loss = None if labels is not None: # move labels to correct device to enable model parallelism labels = labels.to(lm_logits.device) # Shift so that tokens < n predict n shift_logits = lm_logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() # Flatten the tokens loss_fct = CrossEntropyLoss() loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) if not return_dict: output = (lm_logits,) + transformer_outputs[1:] return ((loss,) + output) if loss is not None else output return CausalLMOutputWithCrossAttentions( loss=loss, logits=lm_logits, past_key_values=transformer_outputs.past_key_values, hidden_states=transformer_outputs.hidden_states, attentions=transformer_outputs.attentions, cross_attentions=transformer_outputs.cross_attentions, ) @staticmethod def _reorder_cache( past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor ) -> Tuple[Tuple[torch.Tensor]]: """ This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or [`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct beam_idx at every generation step. """ return tuple( tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past) for layer_past in past_key_values ) @add_start_docstrings( """ The GPT2 Model transformer with a language modeling and a multiple-choice classification head on top e.g. for RocStories/SWAG tasks. The two heads are two linear layers. The language modeling head has its weights tied to the input embeddings, the classification head takes as input the input of a specified classification token index in the input sequence). """, GPT2_START_DOCSTRING, ) class GPT2DoubleHeadsModel(GPT2PreTrainedModel): _keys_to_ignore_on_load_missing = [r"attn.masked_bias", r"attn.bias", r"lm_head.weight"] def __init__(self, config): super().__init__(config) config.num_labels = 1 self.transformer = GPT2Model(config) self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False) self.multiple_choice_head = SequenceSummary(config) # Model parallel self.model_parallel = False self.device_map = None # Initialize weights and apply final processing self.post_init() @add_start_docstrings(PARALLELIZE_DOCSTRING) def parallelize(self, device_map=None): warnings.warn( "`GPT2DoubleHeadsModel.parallelize` is deprecated and will be removed in v5 of Transformers, you should" " load your model with `device_map='balanced'` in the call to `from_pretrained`. You can also provide your" " own `device_map` but it needs to be a dictionary module_name to device, so for instance" " {'transformer.h.0': 0, 'transformer.h.1': 1, ...}", FutureWarning, ) self.device_map = ( get_device_map(len(self.transformer.h), range(torch.cuda.device_count())) if device_map is None else device_map ) assert_device_map(self.device_map, len(self.transformer.h)) self.transformer.parallelize(self.device_map) self.lm_head = self.lm_head.to(self.transformer.first_device) self.multiple_choice_head = self.multiple_choice_head.to(self.transformer.first_device) self.model_parallel = True @add_start_docstrings(DEPARALLELIZE_DOCSTRING) def deparallelize(self): warnings.warn( "Like `parallelize`, `deparallelize` is deprecated and will be removed in v5 of Transformers.", FutureWarning, ) self.transformer.deparallelize() self.transformer = self.transformer.to("cpu") self.lm_head = self.lm_head.to("cpu") self.multiple_choice_head = self.multiple_choice_head.to("cpu") self.model_parallel = False torch.cuda.empty_cache() def get_output_embeddings(self): return self.lm_head def set_output_embeddings(self, new_embeddings): self.lm_head = new_embeddings def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs): token_type_ids = kwargs.get("token_type_ids", None) # only last token for inputs_ids if past is defined in kwargs if past_key_values: input_ids = input_ids[:, -1].unsqueeze(-1) if token_type_ids is not None: token_type_ids = token_type_ids[:, -1].unsqueeze(-1) attention_mask = kwargs.get("attention_mask", None) position_ids = kwargs.get("position_ids", None) if attention_mask is not None and position_ids is None: # create position_ids on the fly for batch generation position_ids = attention_mask.long().cumsum(-1) - 1 position_ids.masked_fill_(attention_mask == 0, 1) if past_key_values: position_ids = position_ids[:, -1].unsqueeze(-1) else: position_ids = None return { "input_ids": input_ids, "past_key_values": past_key_values, "use_cache": kwargs.get("use_cache"), "position_ids": position_ids, "attention_mask": attention_mask, "token_type_ids": token_type_ids, } @add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING) @replace_return_docstrings(output_type=GPT2DoubleHeadsModelOutput, config_class=_CONFIG_FOR_DOC) def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, mc_token_ids: Optional[torch.LongTensor] = None, labels: Optional[torch.LongTensor] = None, mc_labels: Optional[torch.LongTensor] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, **kwargs, ) -> Union[Tuple, GPT2DoubleHeadsModelOutput]: r""" mc_token_ids (`torch.LongTensor` of shape `(batch_size, num_choices)`, *optional*, default to index of the last token of the input): Index of the classification token in each input sequence. Selected in the range `[0, input_ids.size(-1) - 1]`. labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*): Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set `labels = input_ids`. Indices are selected in `[-100, 0, ..., config.vocab_size - 1]`. All labels set to `-100` are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size - 1]` mc_labels (`torch.LongTensor` of shape `(batch_size)`, *optional*): Labels for computing the multiple choice classification loss. Indices should be in `[0, ..., num_choices]` where *num_choices* is the size of the second dimension of the input tensors. (see *input_ids* above) Return: Example: ```python >>> import torch >>> from transformers import AutoTokenizer, GPT2DoubleHeadsModel >>> tokenizer = AutoTokenizer.from_pretrained("gpt2") >>> model = GPT2DoubleHeadsModel.from_pretrained("gpt2") >>> # Add a [CLS] to the vocabulary (we should train it also!) >>> num_added_tokens = tokenizer.add_special_tokens({"cls_token": "[CLS]"}) >>> # Update the model embeddings with the new vocabulary size >>> embedding_layer = model.resize_token_embeddings(len(tokenizer)) >>> choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"] >>> encoded_choices = [tokenizer.encode(s) for s in choices] >>> cls_token_location = [tokens.index(tokenizer.cls_token_id) for tokens in encoded_choices] >>> input_ids = torch.tensor(encoded_choices).unsqueeze(0) # Batch size: 1, number of choices: 2 >>> mc_token_ids = torch.tensor([cls_token_location]) # Batch size: 1 >>> outputs = model(input_ids, mc_token_ids=mc_token_ids) >>> lm_logits = outputs.logits >>> mc_logits = outputs.mc_logits ```""" return_dict = return_dict if return_dict is not None else self.config.use_return_dict transformer_outputs = self.transformer( input_ids, past_key_values=past_key_values, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) hidden_states = transformer_outputs[0] # Set device for model parallelism if self.model_parallel: torch.cuda.set_device(self.transformer.first_device) hidden_states = hidden_states.to(self.lm_head.weight.device) lm_logits = self.lm_head(hidden_states) mc_logits = self.multiple_choice_head(hidden_states, mc_token_ids).squeeze(-1) mc_loss = None if mc_labels is not None: loss_fct = CrossEntropyLoss() mc_loss = loss_fct(mc_logits.view(-1, mc_logits.size(-1)), mc_labels.view(-1)) lm_loss = None if labels is not None: labels = labels.to(lm_logits.device) shift_logits = lm_logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() loss_fct = CrossEntropyLoss() lm_loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) if not return_dict: output = (lm_logits, mc_logits) + transformer_outputs[1:] if mc_loss is not None: output = (mc_loss,) + output return ((lm_loss,) + output) if lm_loss is not None else output return GPT2DoubleHeadsModelOutput( loss=lm_loss, mc_loss=mc_loss, logits=lm_logits, mc_logits=mc_logits, past_key_values=transformer_outputs.past_key_values, hidden_states=transformer_outputs.hidden_states, attentions=transformer_outputs.attentions, ) @staticmethod def _reorder_cache( past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor ) -> Tuple[Tuple[torch.Tensor]]: """ This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or [`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct beam_idx at every generation step. """ return tuple( tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past) for layer_past in past_key_values ) @add_start_docstrings( """ The GPT2 Model transformer with a sequence classification head on top (linear layer). [`GPT2ForSequenceClassification`] uses the last token in order to do the classification, as other causal models (e.g. GPT-1) do. Since it does classification on the last token, it requires to know the position of the last token. If a `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in each row of the batch). """, GPT2_START_DOCSTRING, ) class GPT2ForSequenceClassification(GPT2PreTrainedModel): _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.masked_bias", r"lm_head.weight"] def __init__(self, config): super().__init__(config) self.num_labels = config.num_labels self.transformer = GPT2Model(config) self.score = nn.Linear(config.n_embd, self.num_labels, bias=False) # Model parallel self.model_parallel = False self.device_map = None # Initialize weights and apply final processing self.post_init() @add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING) @add_code_sample_docstrings( checkpoint="microsoft/DialogRPT-updown", output_type=SequenceClassifierOutputWithPast, config_class=_CONFIG_FOR_DOC, ) def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, labels: Optional[torch.LongTensor] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ) -> Union[Tuple, SequenceClassifierOutputWithPast]: r""" labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*): Labels for computing the sequence classification/regression loss. Indices should be in `[0, ..., config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If `config.num_labels > 1` a classification loss is computed (Cross-Entropy). """ return_dict = return_dict if return_dict is not None else self.config.use_return_dict transformer_outputs = self.transformer( input_ids, past_key_values=past_key_values, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) hidden_states = transformer_outputs[0] logits = self.score(hidden_states) if input_ids is not None: batch_size, sequence_length = input_ids.shape[:2] else: batch_size, sequence_length = inputs_embeds.shape[:2] assert ( self.config.pad_token_id is not None or batch_size == 1 ), "Cannot handle batch sizes > 1 if no padding token is defined." if self.config.pad_token_id is None: sequence_lengths = -1 else: if input_ids is not None: sequence_lengths = (torch.ne(input_ids, self.config.pad_token_id).sum(-1) - 1).to(logits.device) else: sequence_lengths = -1 logger.warning( f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be " "unexpected if using padding tokens in conjunction with `inputs_embeds.`" ) pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths] loss = None if labels is not None: if self.config.problem_type is None: if self.num_labels == 1: self.config.problem_type = "regression" elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int): self.config.problem_type = "single_label_classification" else: self.config.problem_type = "multi_label_classification" if self.config.problem_type == "regression": loss_fct = MSELoss() if self.num_labels == 1: loss = loss_fct(pooled_logits.squeeze(), labels.squeeze()) else: loss = loss_fct(pooled_logits, labels) elif self.config.problem_type == "single_label_classification": loss_fct = CrossEntropyLoss() loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1)) elif self.config.problem_type == "multi_label_classification": loss_fct = BCEWithLogitsLoss() loss = loss_fct(pooled_logits, labels) if not return_dict: output = (pooled_logits,) + transformer_outputs[1:] return ((loss,) + output) if loss is not None else output return SequenceClassifierOutputWithPast( loss=loss, logits=pooled_logits, past_key_values=transformer_outputs.past_key_values, hidden_states=transformer_outputs.hidden_states, attentions=transformer_outputs.attentions, ) @add_start_docstrings( """ GPT2 Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """, GPT2_START_DOCSTRING, ) class GPT2ForTokenClassification(GPT2PreTrainedModel): def __init__(self, config): super().__init__(config) self.num_labels = config.num_labels self.transformer = GPT2Model(config) if hasattr(config, "classifier_dropout") and config.classifier_dropout is not None: classifier_dropout = config.classifier_dropout elif hasattr(config, "hidden_dropout") and config.hidden_dropout is not None: classifier_dropout = config.hidden_dropout else: classifier_dropout = 0.1 self.dropout = nn.Dropout(classifier_dropout) self.classifier = nn.Linear(config.hidden_size, config.num_labels) # Model parallel self.model_parallel = False self.device_map = None # Initialize weights and apply final processing self.post_init() @add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING) # fmt: off @add_code_sample_docstrings( checkpoint="brad1141/gpt2-finetuned-comp2", output_type=TokenClassifierOutput, config_class=_CONFIG_FOR_DOC, expected_loss=0.25, expected_output=["Lead", "Lead", "Lead", "Position", "Lead", "Lead", "Lead", "Lead", "Lead", "Lead", "Lead", "Lead"], ) # fmt: on def forward( self, input_ids: Optional[torch.LongTensor] = None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, labels: Optional[torch.LongTensor] = None, use_cache: Optional[bool] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ) -> Union[Tuple, TokenClassifierOutput]: r""" labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*): Labels for computing the sequence classification/regression loss. Indices should be in `[0, ..., config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If `config.num_labels > 1` a classification loss is computed (Cross-Entropy). """ return_dict = return_dict if return_dict is not None else self.config.use_return_dict transformer_outputs = self.transformer( input_ids, past_key_values=past_key_values, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) hidden_states = transformer_outputs[0] hidden_states = self.dropout(hidden_states) logits = self.classifier(hidden_states) loss = None if labels is not None: labels = labels.to(logits.device) loss_fct = CrossEntropyLoss() loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1)) if not return_dict: output = (logits,) + transformer_outputs[2:] return ((loss,) + output) if loss is not None else output return TokenClassifierOutput( loss=loss, logits=logits, hidden_states=transformer_outputs.hidden_states, attentions=transformer_outputs.attentions, ) @add_start_docstrings( """ The GPT-2 Model transformer with a span classification head on top for extractive question-answering tasks like SQuAD (a linear layer on top of the hidden-states output to compute `span start logits` and `span end logits`). """, GPT2_START_DOCSTRING, ) class GPT2ForQuestionAnswering(GPT2PreTrainedModel): _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.masked_bias", r"h\.\d+\.attn\.bias", r"lm_head.weight"] def __init__(self, config): super().__init__(config) self.num_labels = config.num_labels self.transformer = GPT2Model(config) self.qa_outputs = nn.Linear(config.hidden_size, 2) # Model parallel self.model_parallel = False self.device_map = None self.gradient_checkpointing = False # Initialize weights and apply final processing self.post_init() @add_start_docstrings_to_model_forward(GPT2_INPUTS_DOCSTRING.format("batch_size, sequence_length")) @add_code_sample_docstrings( checkpoint=_CHECKPOINT_FOR_DOC, output_type=QuestionAnsweringModelOutput, config_class=_CONFIG_FOR_DOC, real_checkpoint=_CHECKPOINT_FOR_DOC, ) def forward( self, input_ids: Optional[torch.LongTensor] = None, attention_mask: Optional[torch.FloatTensor] = None, token_type_ids: Optional[torch.LongTensor] = None, position_ids: Optional[torch.LongTensor] = None, head_mask: Optional[torch.FloatTensor] = None, inputs_embeds: Optional[torch.FloatTensor] = None, start_positions: Optional[torch.LongTensor] = None, end_positions: Optional[torch.LongTensor] = None, output_attentions: Optional[bool] = None, output_hidden_states: Optional[bool] = None, return_dict: Optional[bool] = None, ) -> Union[Tuple, QuestionAnsweringModelOutput]: r""" start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*): Labels for position (index) of the start of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence are not taken into account for computing the loss. end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*): Labels for position (index) of the end of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence are not taken into account for computing the loss. """ return_dict = return_dict if return_dict is not None else self.config.use_return_dict outputs = self.transformer( input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) sequence_output = outputs[0] logits = self.qa_outputs(sequence_output) start_logits, end_logits = logits.split(1, dim=-1) start_logits = start_logits.squeeze(-1).contiguous() end_logits = end_logits.squeeze(-1).contiguous() total_loss = None if start_positions is not None and end_positions is not None: # If we are on multi-GPU, split add a dimension if len(start_positions.size()) > 1: start_positions = start_positions.squeeze(-1).to(start_logits.device) if len(end_positions.size()) > 1: end_positions = end_positions.squeeze(-1).to(end_logits.device) # sometimes the start/end positions are outside our model inputs, we ignore these terms ignored_index = start_logits.size(1) start_positions = start_positions.clamp(0, ignored_index) end_positions = end_positions.clamp(0, ignored_index) loss_fct = CrossEntropyLoss(ignore_index=ignored_index) start_loss = loss_fct(start_logits, start_positions) end_loss = loss_fct(end_logits, end_positions) total_loss = (start_loss + end_loss) / 2 if not return_dict: output = (start_logits, end_logits) + outputs[2:] return ((total_loss,) + output) if total_loss is not None else output return QuestionAnsweringModelOutput( loss=total_loss, start_logits=start_logits, end_logits=end_logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions, )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
- 648
- 649
- 650
- 651
- 652
- 653
- 654
- 655
- 656
- 657
- 658
- 659
- 660
- 661
- 662
- 663
- 664
- 665
- 666
- 667
- 668
- 669
- 670
- 671
- 672
- 673
- 674
- 675
- 676
- 677
- 678
- 679
- 680
- 681
- 682
- 683
- 684
- 685
- 686
- 687
- 688
- 689
- 690
- 691
- 692
- 693
- 694
- 695
- 696
- 697
- 698
- 699
- 700
- 701
- 702
- 703
- 704
- 705
- 706
- 707
- 708
- 709
- 710
- 711
- 712
- 713
- 714
- 715
- 716
- 717
- 718
- 719
- 720
- 721
- 722
- 723
- 724
- 725
- 726
- 727
- 728
- 729
- 730
- 731
- 732
- 733
- 734
- 735
- 736
- 737
- 738
- 739
- 740
- 741
- 742
- 743
- 744
- 745
- 746
- 747
- 748
- 749
- 750
- 751
- 752
- 753
- 754
- 755
- 756
- 757
- 758
- 759
- 760
- 761
- 762
- 763
- 764
- 765
- 766
- 767
- 768
- 769
- 770
- 771
- 772
- 773
- 774
- 775
- 776
- 777
- 778
- 779
- 780
- 781
- 782
- 783
- 784
- 785
- 786
- 787
- 788
- 789
- 790
- 791
- 792
- 793
- 794
- 795
- 796
- 797
- 798
- 799
- 800
- 801
- 802
- 803
- 804
- 805
- 806
- 807
- 808
- 809
- 810
- 811
- 812
- 813
- 814
- 815
- 816
- 817
- 818
- 819
- 820
- 821
- 822
- 823
- 824
- 825
- 826
- 827
- 828
- 829
- 830
- 831
- 832
- 833
- 834
- 835
- 836
- 837
- 838
- 839
- 840
- 841
- 842
- 843
- 844
- 845
- 846
- 847
- 848
- 849
- 850
- 851
- 852
- 853
- 854
- 855
- 856
- 857
- 858
- 859
- 860
- 861
- 862
- 863
- 864
- 865
- 866
- 867
- 868
- 869
- 870
- 871
- 872
- 873
- 874
- 875
- 876
- 877
- 878
- 879
- 880
- 881
- 882
- 883
- 884
- 885
- 886
- 887
- 888
- 889
- 890
- 891
- 892
- 893
- 894
- 895
- 896
- 897
- 898
- 899
- 900
- 901
- 902
- 903
- 904
- 905
- 906
- 907
- 908
- 909
- 910
- 911
- 912
- 913
- 914
- 915
- 916
- 917
- 918
- 919
- 920
- 921
- 922
- 923
- 924
- 925
- 926
- 927
- 928
- 929
- 930
- 931
- 932
- 933
- 934
- 935
- 936
- 937
- 938
- 939
- 940
- 941
- 942
- 943
- 944
- 945
- 946
- 947
- 948
- 949
- 950
- 951
- 952
- 953
- 954
- 955
- 956
- 957
- 958
- 959
- 960
- 961
- 962
- 963
- 964
- 965
- 966
- 967
- 968
- 969
- 970
- 971
- 972
- 973
- 974
- 975
- 976
- 977
- 978
- 979
- 980
- 981
- 982
- 983
- 984
- 985
- 986
- 987
- 988
- 989
- 990
- 991
- 992
- 993
- 994
- 995
- 996
- 997
- 998
- 999
- 1000
- 1001
- 1002
- 1003
- 1004
- 1005
- 1006
- 1007
- 1008
- 1009
- 1010
- 1011
- 1012
- 1013
- 1014
- 1015
- 1016
- 1017
- 1018
- 1019
- 1020
- 1021
- 1022
- 1023
- 1024
- 1025
- 1026
- 1027
- 1028
- 1029
- 1030
- 1031
- 1032
- 1033
- 1034
- 1035
- 1036
- 1037
- 1038
- 1039
- 1040
- 1041
- 1042
- 1043
- 1044
- 1045
- 1046
- 1047
- 1048
- 1049
- 1050
- 1051
- 1052
- 1053
- 1054
- 1055
- 1056
- 1057
- 1058
- 1059
- 1060
- 1061
- 1062
- 1063
- 1064
- 1065
- 1066
- 1067
- 1068
- 1069
- 1070
- 1071
- 1072
- 1073
- 1074
- 1075
- 1076
- 1077
- 1078
- 1079
- 1080
- 1081
- 1082
- 1083
- 1084
- 1085
- 1086
- 1087
- 1088
- 1089
- 1090
- 1091
- 1092
- 1093
- 1094
- 1095
- 1096
- 1097
- 1098
- 1099
- 1100
- 1101
- 1102
- 1103
- 1104
- 1105
- 1106
- 1107
- 1108
- 1109
- 1110
- 1111
- 1112
- 1113
- 1114
- 1115
- 1116
- 1117
- 1118
- 1119
- 1120
- 1121
- 1122
- 1123
- 1124
- 1125
- 1126
- 1127
- 1128
- 1129
- 1130
- 1131
- 1132
- 1133
- 1134
- 1135
- 1136
- 1137
- 1138
- 1139
- 1140
- 1141
- 1142
- 1143
- 1144
- 1145
- 1146
- 1147
- 1148
- 1149
- 1150
- 1151
- 1152
- 1153
- 1154
- 1155
- 1156
- 1157
- 1158
- 1159
- 1160
- 1161
- 1162
- 1163
- 1164
- 1165
- 1166
- 1167
- 1168
- 1169
- 1170
- 1171
- 1172
- 1173
- 1174
- 1175
- 1176
- 1177
- 1178
- 1179
- 1180
- 1181
- 1182
- 1183
- 1184
- 1185
- 1186
- 1187
- 1188
- 1189
- 1190
- 1191
- 1192
- 1193
- 1194
- 1195
- 1196
- 1197
- 1198
- 1199
- 1200
- 1201
- 1202
- 1203
- 1204
- 1205
- 1206
- 1207
- 1208
- 1209
- 1210
- 1211
- 1212
- 1213
- 1214
- 1215
- 1216
- 1217
- 1218
- 1219
- 1220
- 1221
- 1222
- 1223
- 1224
- 1225
- 1226
- 1227
- 1228
- 1229
- 1230
- 1231
- 1232
- 1233
- 1234
- 1235
- 1236
- 1237
- 1238
- 1239
- 1240
- 1241
- 1242
- 1243
- 1244
- 1245
- 1246
- 1247
- 1248
- 1249
- 1250
- 1251
- 1252
- 1253
- 1254
- 1255
- 1256
- 1257
- 1258
- 1259
- 1260
- 1261
- 1262
- 1263
- 1264
- 1265
- 1266
- 1267
- 1268
- 1269
- 1270
- 1271
- 1272
- 1273
- 1274
- 1275
- 1276
- 1277
- 1278
- 1279
- 1280
- 1281
- 1282
- 1283
- 1284
- 1285
- 1286
- 1287
- 1288
- 1289
- 1290
- 1291
- 1292
- 1293
- 1294
- 1295
- 1296
- 1297
- 1298
- 1299
- 1300
- 1301
- 1302
- 1303
- 1304
- 1305
- 1306
- 1307
- 1308
- 1309
- 1310
- 1311
- 1312
- 1313
- 1314
- 1315
- 1316
- 1317
- 1318
- 1319
- 1320
- 1321
- 1322
- 1323
- 1324
- 1325
- 1326
- 1327
- 1328
- 1329
- 1330
- 1331
- 1332
- 1333
- 1334
- 1335
- 1336
- 1337
- 1338
- 1339
- 1340
- 1341
- 1342
- 1343
- 1344
- 1345
- 1346
- 1347
- 1348
- 1349
- 1350
- 1351
- 1352
- 1353
- 1354
- 1355
- 1356
- 1357
- 1358
- 1359
- 1360
- 1361
- 1362
- 1363
- 1364
- 1365
- 1366
- 1367
- 1368
- 1369
- 1370
- 1371
- 1372
- 1373
- 1374
- 1375
- 1376
- 1377
- 1378
- 1379
- 1380
- 1381
- 1382
- 1383
- 1384
- 1385
- 1386
- 1387
- 1388
- 1389
- 1390
- 1391
- 1392
- 1393
- 1394
- 1395
- 1396
- 1397
- 1398
- 1399
- 1400
- 1401
- 1402
- 1403
- 1404
- 1405
- 1406
- 1407
- 1408
- 1409
- 1410
- 1411
- 1412
- 1413
- 1414
- 1415
- 1416
- 1417
- 1418
- 1419
- 1420
- 1421
- 1422
- 1423
- 1424
- 1425
- 1426
- 1427
- 1428
- 1429
- 1430
- 1431
- 1432
- 1433
- 1434
- 1435
- 1436
- 1437
- 1438
- 1439
- 1440
- 1441
- 1442
- 1443
- 1444
- 1445
- 1446
- 1447
- 1448
- 1449
- 1450
- 1451
- 1452
- 1453
- 1454
- 1455
- 1456
- 1457
- 1458
- 1459
- 1460
- 1461
- 1462
- 1463
- 1464
- 1465
- 1466
- 1467
- 1468
- 1469
- 1470
- 1471
- 1472
- 1473
- 1474
- 1475
- 1476
- 1477
- 1478
- 1479
- 1480
- 1481
- 1482
- 1483
- 1484
- 1485
- 1486
- 1487
- 1488
- 1489
- 1490
- 1491
- 1492
- 1493
- 1494
- 1495
- 1496
- 1497
- 1498
- 1499
- 1500
- 1501
- 1502
- 1503
- 1504
- 1505
- 1506
- 1507
- 1508
- 1509
- 1510
- 1511
- 1512
- 1513
- 1514
- 1515
- 1516
- 1517
- 1518
- 1519
- 1520
- 1521
- 1522
- 1523
- 1524
- 1525
- 1526
- 1527
- 1528
- 1529
- 1530
- 1531
- 1532
- 1533
- 1534
- 1535
- 1536
- 1537
- 1538
- 1539
- 1540
- 1541
- 1542
- 1543
- 1544
- 1545
- 1546
- 1547
- 1548
- 1549
- 1550
- 1551
- 1552
- 1553
- 1554
- 1555
- 1556
- 1557
- 1558
- 1559
- 1560
- 1561
- 1562
- 1563
- 1564
- 1565
- 1566
- 1567
- 1568
- 1569
- 1570
- 1571
- 1572
- 1573
- 1574
- 1575
- 1576
- 1577
- 1578
- 1579
- 1580
- 1581
- 1582
- 1583
- 1584
- 1585
- 1586
- 1587
- 1588
- 1589
- 1590
- 1591
- 1592
- 1593
- 1594
- 1595
- 1596
- 1597
- 1598
- 1599
- 1600
- 1601
- 1602
- 1603
- 1604
- 1605
- 1606
- 1607
- 1608
- 1609
- 1610
- 1611
- 1612
- 1613
- 1614
- 1615
- 1616
- 1617
- 1618
- 1619
- 1620
- 1621
- 1622
- 1623
- 1624
- 1625
- 1626
- 1627
- 1628
- 1629
- 1630
- 1631
- 1632
- 1633
- 1634
- 1635
- 1636
- 1637
- 1638
- 1639
- 1640
- 1641
- 1642
- 1643
- 1644
- 1645
- 1646
- 1647
- 1648
- 1649
- 1650
- 1651
- 1652
- 1653
- 1654
- 1655
- 1656
- 1657
- 1658
- 1659
- 1660
- 1661
- 1662
- 1663
- 1664
- 1665
- 1666
- 1667
- 1668
- 1669
- 1670
- 1671
- 1672
- 1673
- 1674
- 1675
- 1676
- 1677
- 1678
- 1679
- 1680
- 1681
- 1682
- 1683
- 1684
- 1685
- 1686
- 1687
- 1688
- 1689
- 1690
- 1691
- 1692
- 1693
- 1694
- 1695
GPT3:In-context learning正式开启prompt新范式(小样本学习)
Prompt技术的升级与创新:指令微调技术(IFT)与思维链技术(CoT)
未完待续!

