
热门标签
热门文章
- 1斯坦福AI2021报告出炉!详解七大热点,论文引用中国首超美国
- 2OpenAI 开发系列(七):LLM提示工程(Prompt)与思维链(CoT)_llm 将高层次指令拆分成子任务
- 32. Transformer相关的原理(2.3. 图解BERT)_bertencoder图
- 4adb devices找不到设备的很多原因
- 5pytorch初学笔记(一):如何加载数据和Dataset实战_python dataset
- 6鸿蒙开发,对于前端开发来说,究竟是福是祸呢?_前端 鸿蒙
- 7宇视VM新BS界面配置告警联动上墙
- 8决策树python源码实现(含预剪枝和后剪枝)_def createdatalh(): data = np.array([['青年', '否', '
- 9hive集群搭建
- 10掌握Go语言:Go语言类型转换,解锁高级用法,轻松驾驭复杂数据结构(30)
当前位置: article > 正文
Utterance-Level Aggregation For Speaker Recognition In The Wild
作者:小丑西瓜9 | 2024-04-02 12:31:41
赞
踩
utterance-level
本文使用NetVLAD,将frame-level聚合为utterance-level。
in the wild: 4s以上的语音
实现流程

将通过Thin ResNet的frame-level通过NetVLAD聚合为utterance-level。
网络输入为R(257×T×1),输出变为了R(1×T/32×512)
NetVLAD: 输出一个K×D的矩阵V,K为聚类类别数,D为每一类的维数。
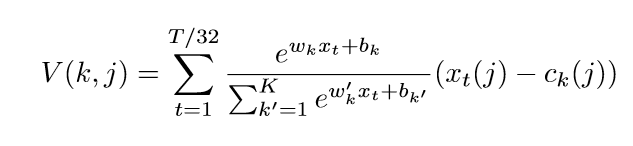
第一项代表了这一帧特征在类别k的权重,第二项代表了其与类中心的残差。
最后将每帧向量L2标准化后连接起来。
在GhostVLAD中,一些类并不参与最后的连接,因此可以剔除一些噪声段
实验

在GhostVLAD中,聚类数与损失函数对结果影响不大。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/352544
推荐阅读
相关标签

