
- 1【本地化部署大模型方案二:fastchat+llm(vllm)】_fastchat vllm
- 2蒙特卡洛分析_马尔可夫链蒙特卡洛方法MCMC
- 3python文本相似度分析:TF-IDF方法_tf-idf相似度
- 4Linux-ntp-ptp-gptp
- 5机器学习周记(第三十二周:文献阅读-时空双通路框架)2024.3.25~2024.3.31
- 6python nltk中文_NLTK中文词性标注
- 7第5章 信息系统工程
- 8边缘计算盒子 | 什么是边缘计算盒子?选型要看哪些参数?
- 9指纹图像的分割_指纹识别图像分割
- 10Linux(CentOS7)离线安装mysql_libaio-devel-0.3.109 (x86_64).下载
知识图谱入门 (八) 语义搜索_搜索语义理解
赞
踩
欢迎大家关注我的博客 http://pelhans.com/ ,所有文章都会第一时间发布在那里哦~
本节对语义搜索做一个简单的介绍,而后介绍语义数据搜索、混合搜索。该部分理解不深,后续会进一步补充。
语义搜索简介
什么是语义搜索,借用万维网之父Tim Berners-Lee的解释 “语义搜索的本质是通过数学来拜托当今搜索中使用的猜测和近似,并为词语的含义以及它们如何关联到我们在搜索引擎输入框中所找的东西引进一种清晰的理解方式,
不同的搜索模式之间的技术差异可以分为:
- 对用户需求的表示(query model)
- 对底层数据的表示(data model)
- 匹配方法(matching technique)
以前常用的搜索是基于文档的检索(document retrieval )。信息检索(IR)支持对文档的检索,它通过轻量级的语法模型表示用户的检索需求和资源内容,如 AND OR。即目前占主导地位的关键词模式:词袋模型。它对主题搜索的效果很好,但不能应对更加复杂的信息检索需求。
数据库(DB) 和知识库专家系统(Knowledge-based Expert System)可以提供更加精确的答案(data retrieval)。它使用表达能力更强的模型来表示用户的需求、利用数据之间的内在结构和语义关联、允许复杂的查询、返回精确匹配查询的具体答案。
语义搜索答题可分为两类:
DB 和KB 系统属于重量级语义搜索系统,它对语义显示的和形式化的建模,例如 ER图或 RDF(S) 和OWL 中的知识模型。主要为语义的数据检索系统。
基于语义的IR 系统属于轻量级的语义搜索系统。采用轻量级的语义模型,例如分类系统或者辞典。语义数据(RDF)嵌入文档或者与文档关联。它是基于语义的文档检索系统。
随着结构化和语义数据的可用性越来越高,数据Web搜索和文档Web搜索有逐渐融合的趋势。
对于Web搜索,采用传统上应用于IR 领域的,扩展性较好的方法,来处理WEb 数据的质量问题,和与长文本描述相关的数据元素。
对于文档Web搜索,数据库和语义搜索技术被应用到IR系统中,以便在搜索过程中结合运用日益增加的,高度结构化和表达能力强的数据。
语义搜索的流程图如下图所示:
语义数据搜索
语义数据搜索具有以下难点:
- 可扩展性: 语义数据搜索对链接数据的有效利用要求基础架构能扩展和应用在大规模和不断增长的内链数据上。
- 异构性: 数据源的异构性、多数据源查询、合并多数据源的查询结果。
- 不确定性: 用户需求的表示不完整
下面介绍一些基于三元组存储的语义数据搜索最佳实践及其对应原理。
基于IR:Sindice, FalconS;是单一数据结构和查询算法,针对文本数据进行排序检索来优化。它的数据是高度可压缩的,可访问的。排序是组成部分。但不能处理简单的select,join等操作。
基于DB:Oracle的RDF扩展,DB2的SOR;具有各种索引和查询算法,以适应各种对结构化数据的复杂查询。优点是能够完成复杂的selects,joins,…(SQL, SPARQL),能够对高动态场景(许多插入/删除)。缺点是由于使用B+树,空间的开销大和访问的局限性。同时来自叶子节点的结果没有集成对检索结果的排序。
原生存储(Native stores):Dataplore, YARS, RDF-3x;优点是高度可压缩,可访问。类似于IR的检索排序。类似于DB的selects和joins操作。可在亚秒级实践内在单台机器上完成对TB数据的查询。支持高动态操作。缺点是没有事务、恢复等。
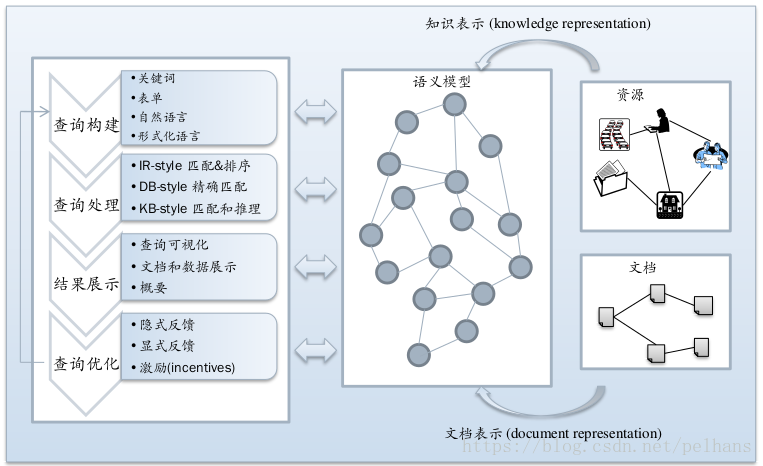
存储和索引(Semplore,Dataplore的前身)
重用IR 索引来索引语义数据。它的核心想法是将RDF转换称具有fields 和terms的虚拟文档。IR索引基于以下概念:
- 文档
- 字段(field),例如标题、摘要、正文、作者….
- 词语(terms)
- Posting list 和Position list
下面以一个例子来理解上面的术语:
当新插入元素时,不可能完全重建索引,因此需要使用增量索引。当前的增量索引需要遍历Posting list,非常耗时,因此需要将Posting list 进行分块,但更多的快需要更多的随机访问来定位这些块,同时更多的快需要更多的空间开销。因此需要权衡索引更新,搜索和索引大小。
排序和索引
上面建立的索引并存储。现在我们需要对其进行检索,对于检索我们需要支持四种基本的操作:
- 基础的检索:(f, t)
- 归并排序:m(S1, op, S2)
概念表达式计算:
λ(C) ,如λ(AmericanFilm∩"war")=m((type,AmericanFilm),∩,(text,"war")) 关系扩展(Relation Expansion):
⋈(S1,R,S2) ,
如y|∃x:x∈S1∧(x,R,y)∧y∈S2 ,这个是需要我们去完善的
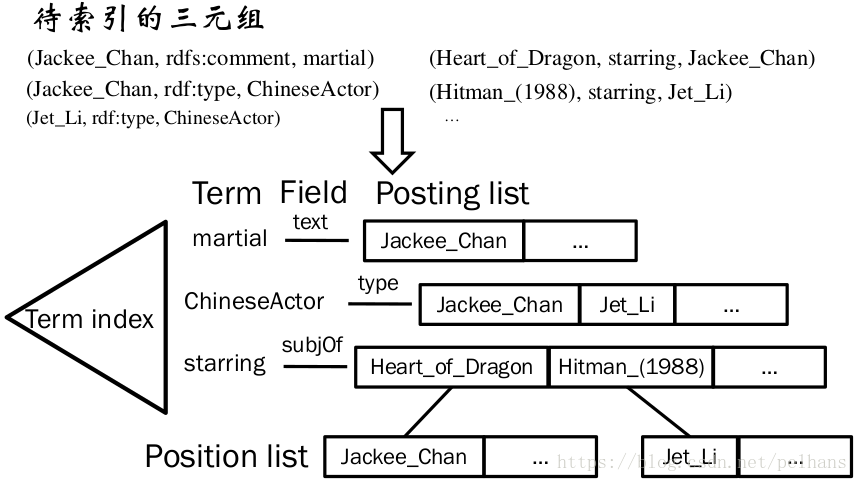
那么如何进行复杂的查询呢?下图给出一个例子:
其大致流程为先从x0出发到x1,x1返回结果到x0,在将该结果传到x2进行查找,最终再返回x0。 遍历图的方式为深度优先遍历查询。
查询时我们还需要对其进行排序,排序有两个原则:
- 质量传播原则:一个元素的分数可以看成是其质量(quality)的度量,质量传播即通过更新这个分数同时反应该元素的相邻元素的质量。
- 数量聚合:除质量外,还考虑邻居的数量。因此,如果有更多的邻居,元素排名会更高。
如何将排序紧密结合到基本操作中呢?
- Ascending IntegerStream (AIS)
- 基本检索:给定field f和 term t, b(f, t) 从倒排索引中检索出posting list, 并输出一个Ascending Integer List (AIS)。
- 归并排序:S1 和 S2 是两个AIS ,
m(S1∪S2) 计算S1 and S2的交集 - 关系扩展:给定关系R和AIS S,计算集合
o|∃s:s∈S∧(s,R,o) 并将其作为AIS返回
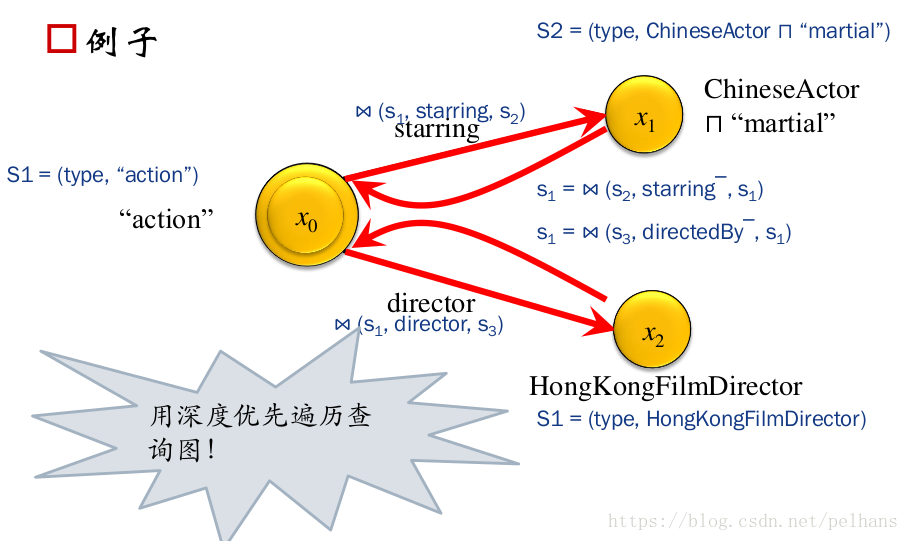
基于结构的分区和查询
基于结构的索引和分区,需要将结构上相似的节点聚合到一起,同时结构上相似的节点在硬盘上连续存储。基于结构感知(Structure-aware)的查询处理需要分两阶段匹配,第一个是只检索出匹配所查询的结构的数据,第二个是通过剪枝减少join和IO。其流程如下图所示
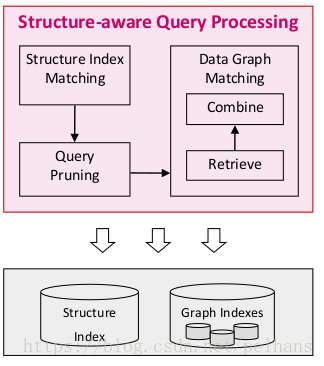
一个数据图的索引建立和查询例子如下图所示:


首先用结构索引匹配查询在答案空间里检索和join,产生一组包含的数据元素匹配查询中的结构的结构索引。而后根据匹配的结构索引计算最终答案,其中剪枝仅包含非标识(non-distinguished)变量的树形查询部分。在资源空间检索和join:验证答案空间匹配中的元素是否也匹配具体的查询实体,即常量和标识(distinguished)变量。
使用结构索引做结构匹配的有点是降低IO开销和union 和join操作的次数。
多数据源搜索–以Hermes 为例
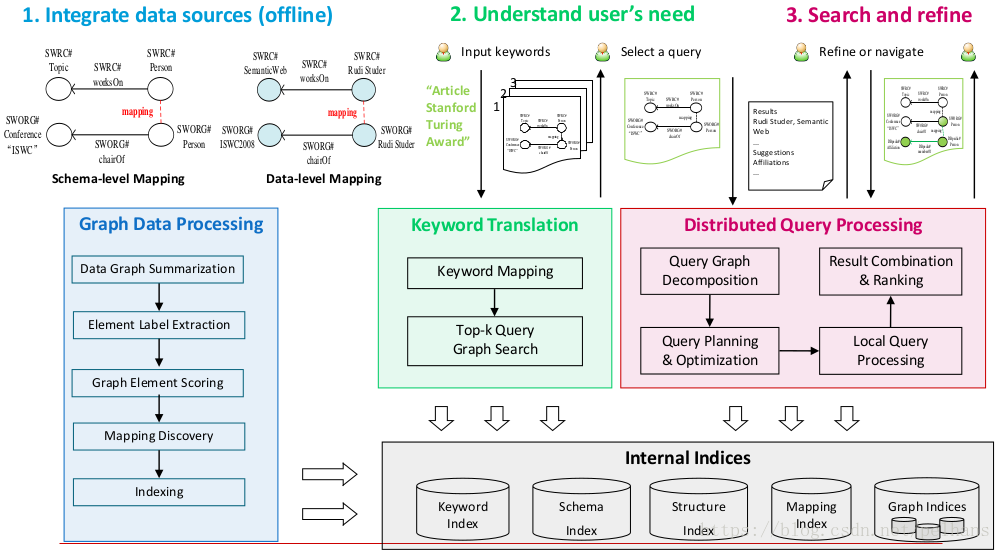
可以看出其大体分为三块,第一部分是数据源融合部分,第二部分是理解用户需求,最终是搜索和提炼。
其知识融合部分流程为:

混合语义搜索
下一代语义搜索系统结合了一系列技术,从基于统计的IR排序方法,有效索引和查询处理的数据库方法,到推理的复杂推理技术等等。一个混合的语义搜索系统应:
- 结合文本,结构化和语义数据
- 以整体的方式管理不同类型的资源
- 支持结果为信息单元(文档,数据)的集成的检索。
一个典型的系统架构是
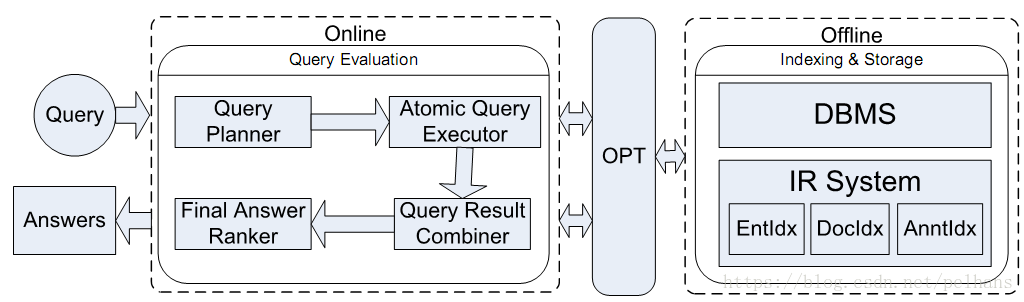
上图中的OPT(occur probity table, 发生概率表)分为线上和线下两个步骤。对于线下步骤,数据图存储于DBMS中,除Entldx中的三元组(个体,关键词,”xxx”)外,Doc 图存储在Docldx中,注释存储在Anntldx中。线上步骤将混合查询分解为一组原子查询(atomic queries);使用DB和IR引擎执行原子查询;根据生成的查询树合并部分结果;对最后的答案排序。

