
- 1多模态是什么意思,在生活工业中有哪些应用?_多模态是什么意思?
- 2python-pytorch基础之加载bert模型获取字向量_pytorch加载本地bert模型
- 3Android自定义View基础--Paint设置PorterDuffXfermode图形混合模式实现遮罩效果,例如头像展示_android view遮罩 mpaint.setxfermode
- 4gcc流程及鲜有人知的参数_-fvolatile
- 5使用vim编写golang_vim中编译go语言文件的命令
- 6Ubuntu16.04+python3+Spyder+qt5(python3)的安装
- 7R语言使用caret包的confusionMatrix函数计算混淆矩阵、基于混淆矩阵的信息手动编写函数计算f1指标_r语言 f1 score
- 8有道词典笔3新增功能扫读和点读是怎么集成的?_词典笔是什么原理
- 9【8个Python数据清洗代码,拿来即用】_python进行文本清洗时的去除噪声的代码
- 10任意文件上传下载漏洞_nginx防止php文件被下载
AI赋能视频译制,微软和人大提出自动视频译制技术VideoDubber
赞
踩


简介
目前,依赖人工方法的视频译制流程繁琐,通常制作周期长、成本高。未来借助人工智能技术,视频译制有望自动完成。近日,微软亚洲研究院和微软 Azure 认知服务团队联合中国人民大学高瓴人工智能学院提出了自动视频译制技术 VideoDubber,研究成果发表在 AAAI 2023 上。VideoDubber 在保证翻译质量的同时,提升了视频译制的同步性,大大简化了视频译制流程,降低了制作成本。
视频译制(video dubbing)一般指将视频中语音由原始语言翻译为目标语言,并保证翻译后语音与画面的一致性。通常视频译制可通过级联的多个系统组成,包括语音识别,机器翻译和语音合成。为保证翻译后的语音与原始视频对应,通常先在机器翻译阶段控制文本长度,再在语音合成阶段调整合成语音的长度(如图 1 所示)。
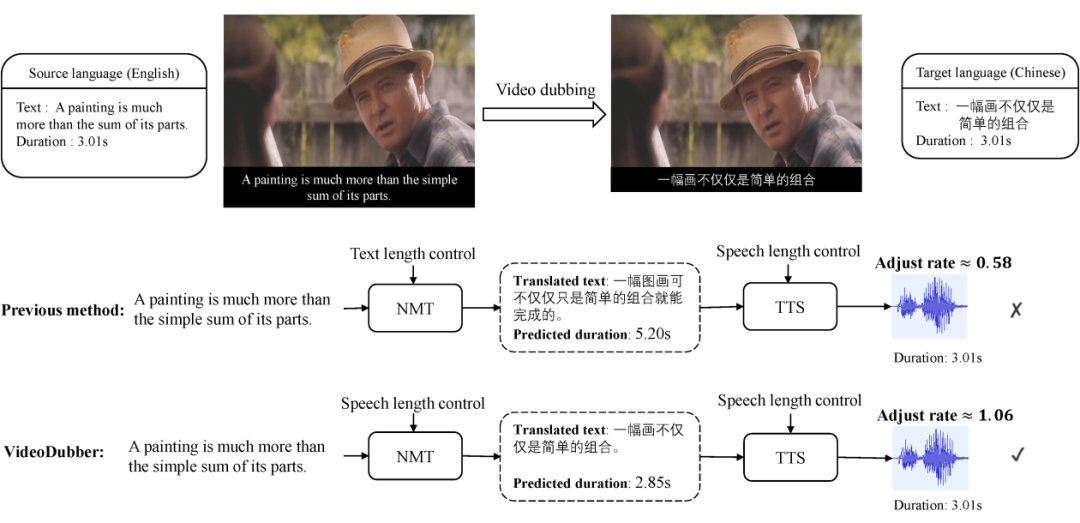
▲ 图1:英文→中文的视频译制示例。在翻译原文“A painting is much more than the simple sum of its parts”。在机器翻译阶段,其对应的原始语音时长为3.01s。以往的方法仅在翻译阶段控制字数,可能会导致生成的语音与原始语音时长相差很大。VideoDubber直接考虑语音长度,从而生成时长非常接近原始语音的翻译结果。在此基础上,语音合成模型只需要稍作调整就能得到理想的语音翻译结果。
以往的工作通常只在机器翻译阶段控制翻译后的单词/字母的数量,而不考虑在不同语言中单词/字符发音持续时间的不同。在这篇工作中,研究团队提出了一个为视频配音任务量身定制的机器翻译方法 VideoDubber,它直接考虑翻译中每个 token 的语音时长(duration),以匹配目标语音的长度。
具体来说,研究团队通过使用时长信息来引导每个单词的预测,从而控制生成句子的语音长度。实验结果表明,VideoDubber 在四个语言方向(德语→英语、西班牙语→英语、汉语↔英语)上的视频译制同步性方面优于基线模型。此外,由于真实视频译制数据集的不足,研究团队还构建了一个从电影中收集的真实场景测试集,对视频译制任务进行综合评价。

论文标题:
VideoDubber: Machine Translation with Speech-Aware Length Control for Video Dubbing, AAAI 2023
论文作者&#x

