
- 1C和C++相互调用 error LNK2001: unresolved external symbol_c++unresolved什么意思
- 2利用低代码从0到1开发一款小程序_小程序低代码
- 3Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本_gpt-4的层数和训练参数
- 4使用org.apache.commons.io.FileUtils,IOUtils;工具类操作文件
- 5shell命令-find常用命令_shell find -exec
- 6Gradle 安装和配置教程_gradle-8.3-bin.zip放哪个位置
- 7《最长的一帧》理解01_场景渲染
- 8负载均衡_用户将请求发送给负载均衡
- 9Apriori算法中使用Hash树进行支持度计数_hash树在apriori算法中的作用
- 10glance服务器上传的镜像支持,openstack-理解glance组件和镜像服务
复刻Sora的通用视频生成能力,开源多智能体框架Mora来了_多智能体开源项目
赞
踩
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源

更多资源欢迎关注

何恺明的目标是:探索面向复杂世界的智能。
Sora 是首个引起社会广泛关注的大规模通用视频生成模型。自 OpenAI 在 2024 年 2 月推出以来,没有其他视频生成模型能够在性能或支持广泛视频生成任务的能力上与 Sora 匹敌。此外,完全公开的视频生成模型寥寥无几,大多数都是闭源的。
为了弥补这一差距,来自理海大学、微软研究院的研究者提出了一种多智能体框架 Mora,该框架整合了几种先进的视觉 AI 智能体,以复制 Sora 所展示的通用视频生成能力。特别是,Mora 能够利用多个视觉智能体,在各种任务中成功模仿 Sora 的视频生成能力,例如(1)文本到视频生成,(2)文本条件下的图像到视频生成,(3)扩展生成的视频,(4)视频到视频编辑,(5)连接视频以及(6)模拟数字世界。广泛的实验结果表明,Mora 在各种任务中达到了接近 Sora 的性能。然而,当从整体上评估时,Mora 与 Sora 之间存在明显的性能差距。总之,研究团队希望这个项目能够指导视频生成的未来轨迹,通过协作的 AI 智能体实现。

-
论文链接:https://arxiv.org/abs/2403.13248
-
项目链接:https://github.com/lichao-sun/Mora
先来看下 Mora 的视频生成效果,以文本到视频生成任务为例。输入 prompt:
A vibrant coral reef teeming with life under the crystal-clear blue ocean, with colorful fish swimming among the coral, rays of sunlight filtering through the water, and a gentle current moving the sea plants.
水晶般清澈的蓝色海洋下,珊瑚礁充满了生机,色彩缤纷的鱼儿在珊瑚间游动,阳光透过水面,水在海洋植物间轻柔地流动。
Mora 的生成结果:

输入 prompt:
In the middle of a vast desert, a golden desert city appears on the horizon, its architecture a blend of ancient Egyptian and futuristic elements.The city is surrounded by a radiant energy barrier, while in the air, seve
浩瀚的沙漠中,一座金色的沙漠之城出现在地平线上,它的建筑融合了古埃及和未来元素。这座城市被辐射能量屏障包围,在空中,有七道光柱环绕
Mora 的生成结果:

论文讲述了自 2022 年 11 月 ChatGPT 发布以来,生成性 AI 技术如何标志着交互方式和日常生活及产业各方面的重大转变。尽管图像生成模型(如 Midjourney、Stable Diffusion 和 DALL-E 3)领先于视觉 AI 领域,但视频生成技术相较于图像生成则发展较慢。
近期的视频生成模型虽能产生多样化和高质量的视频,但在生成超过 10 秒视频方面能力有限。OpenAI 推出的 Sora 模型开启了视频生成的新时代,能将文本提示转换为详细视频,展现了复制物理世界动态的显著潜力。Sora 不仅擅长文本到视频生成,还能执行编辑、连接和扩展视频等多种任务,生成内容以多视角透视和忠实于用户指令的特性著称。
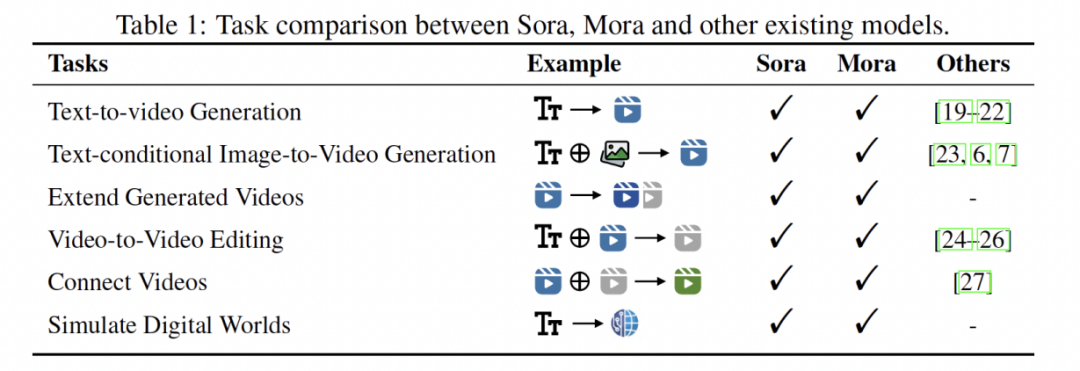
然而,由于视频生成模型大多闭源,Sora 等模型的创新给学术界带来挑战,难以复制或扩展其能力。为此,该工作提出了 Mora,一个多智能体框架,旨在实现类似 Sora 的文本到视频能力。Mora 通过将视频生成任务分解为多个子任务,并为每个子任务分配专门的智能体来执行,例如从文本提示生成图像、基于条件编辑或细化图像、从图像生成制作视频、连接视频等。通过这种灵活的智能体合作,Mora 能完成广泛的视频生成任务,满足用户多样化需求。该工作希望 Mora 项目能通过协作的 AI 智能体,引导视频生成技术的未来发展。
方法概述
Mora 是一个面向视频生成的多智能体框架,它通过将复杂的工作拆解为更小、更具体的任务,利用不同能力的智能体之间的协作来解决视频生成任务。该框架定义了五种基本角色:文本选择与生成智能体、文本到图像生成智能体、图像到图像生成智能体、图像到视频生成智能体和视频到视频智能体。
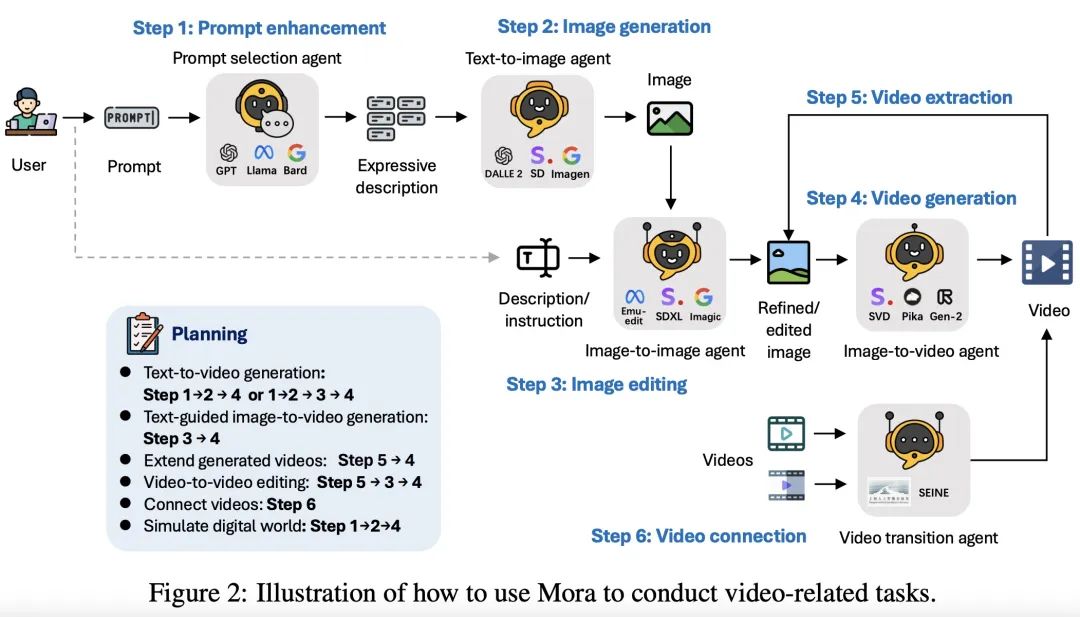
-
智能体的定义:
1. 文本选择与生成智能体:在开始图像生成之前,文本提示经过严格处理和优化,使用大型语言模型(如 GPT-4, Llama)精确分析文本,提取关键信息和动作,从而提高结果图像的相关性和质量。
2. 文本到图像生成智能体:这个智能体将丰富的文本描述转换成高质量的初始图像,深入理解并可视化复杂的文本输入。
3. 图像到图像生成智能体:该智能体根据特定文本指令修改源图像,能够根据文本的意图进行详细识别,并将这些指示转换成视觉上的修改。
4. 图像到视频生成智能体:负责将静态图像转换成连贯的视频序列,分析图像的内容和风格,生成后续帧以确保时间上的稳定性和视觉上的一致性。
5. 视频到视频智能体:创建基于用户提供的两个输入视频的无缝过渡视频,精准识别两个视频中的共同元素和风格,以确保输出的连贯性和视觉吸引力。
-
方法:
Mora 框架通过设定不同智能体的专长和工作方式,精心设计了六种文本到视频生成任务,展现了在视频生成领域的灵活应用和高度定制化。这些任务涵盖了从基础的文本直接生成视频到复杂的视频编辑和世界模拟,充分利用了各智能体之间的互动和协作,为用户提供了一套全面的视频生成解决方案。
1. 文本到视频生成:用户提供详细的文本描述,文本到图像智能体首先根据这些描述生成初始图像。然后,图像到视频智能体基于此图像生成一系列连续帧,逐步展现文本中描述的场景或动作,以形成连贯的视频。
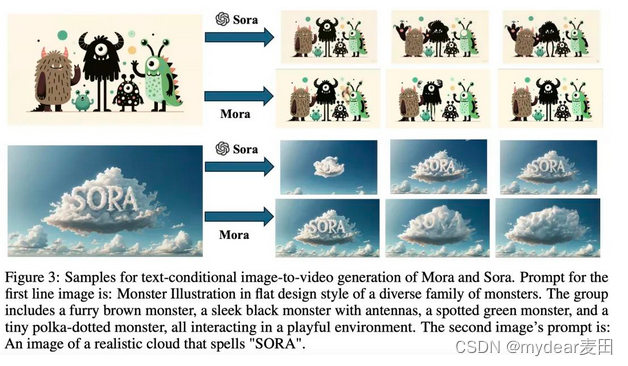
2. 条件文本图像到视频生成:与第一个任务相似,但区别在于输入不仅包括文本描述还包括一个初始图像。这种方法结合了文本和图像的信息,为视频生成提供了更加丰富和具体的上下文。
3. 扩展生成视频:此任务旨在延续已有视频的故事线。通过分析输入视频的最后一帧,视频生成智能体生成新的帧序列,无缝扩展视频内容,创造出更长的叙事视频。
4. 视频到视频编辑:通过图像到图像智能体对视频的第一帧进行编辑(根据用户的文本提示),然后利用这个编辑过的图像作为基础,图像到视频智能体生成反映所需更改的新视频序列。这个任务允许对视频内容进行细微到显著的修改。
5. 连接视频:这个任务使用图像到视频智能体,通过分析第一个视频的最后一帧和第二个视频的第一帧,创造出一个平滑连接两个视频的新视频,确保过渡自然且内容上的连贯性。
6. 模拟数字世界:专注于创造整个视频序列在数字世界风格中的体验。通过在编辑提示中添加特定短语,指示图像到视频智能体按照数字世界的美学生成视频序列,或者使用图像到图像智能体将现实图像转换为数字风格,推动视频生成的边界,创造出沉浸式的数字环境。
每个任务都体现了 Mora 框架中各智能体的特定职能和它们在处理视频生成任务时的互补性,从基本的文本解析到复杂的视觉转换,再到视频内容的延伸和编辑,为用户打造了一个多样化和高效的视频生成平台。
实验
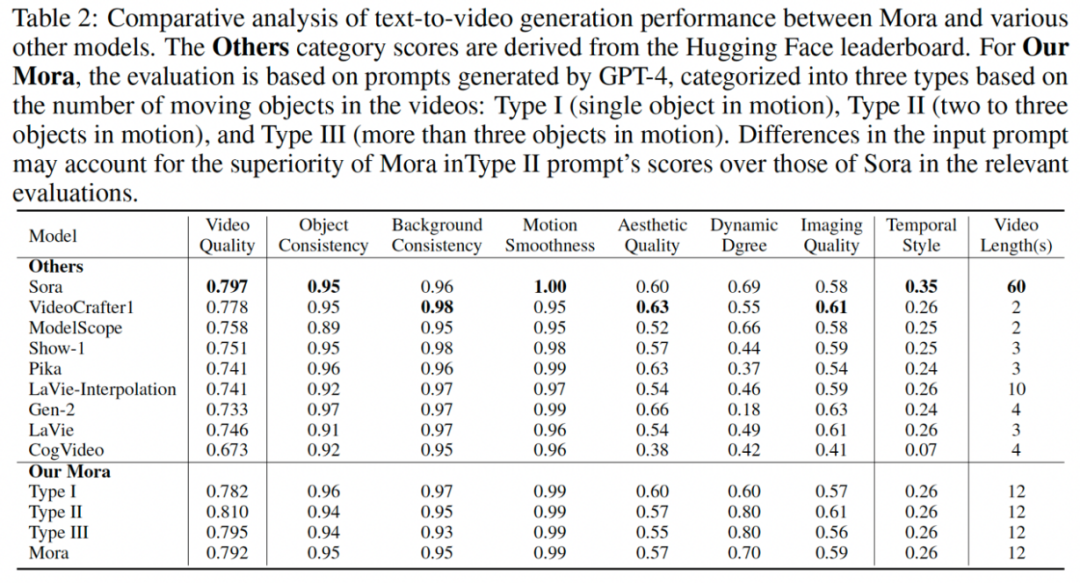
在实验评估中,该研究采用了多个指标来衡量 Mora 的性能,包括视频质量、对象一致性、背景一致性、动态程度、影像质量和时空风格一致性等。下面是一些关键的实验结果和数字,这些结果展现了 Mora 在不同视频生成任务中的性能表现:
1. 文本到视频生成:Mora 在视频质量方面得分为 0.792,接近 Sora 的 0.797,表明其生成的视频质量与 Sora 相近。对象一致性得分为 0.95,与 Sora 相等,显示出在视频中保持对象外观的一致性。动态程度的得分为 0.70,略高于 Sora 的 0.69,这表明 Mora 生成的视频在展现动态变化方面有较好的表现。

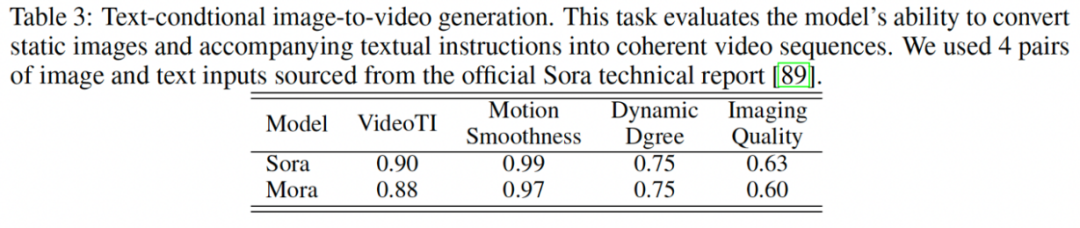
2. 文本条件下的图像到视频生成:在这个任务中,Mora 的视频与文本整合性(VideoTI)得分为 0.88,略低于 Sora 的 0.90,但依然表现出良好的文本理解和视频生成能力。动态程度(Dynamic Degree)得分为 0.75,与 Sora 持平,说明 Mora 能够在此任务中生成具有活动感的视频。
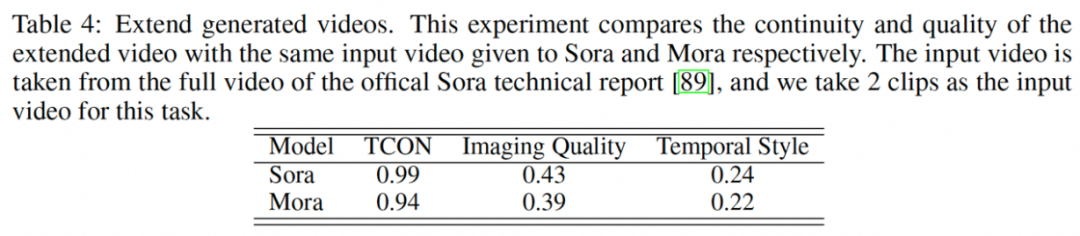
3. 扩展生成的视频:Mora 在时空一致性(Temporal Consistency)上的得分为 0.94,略低于 Sora 的 0.99,但仍显示出其能够有效延续视频内容的能力。影像质量得分为 0.39,显示出在扩展视频时保持较高视觉质量的能力。

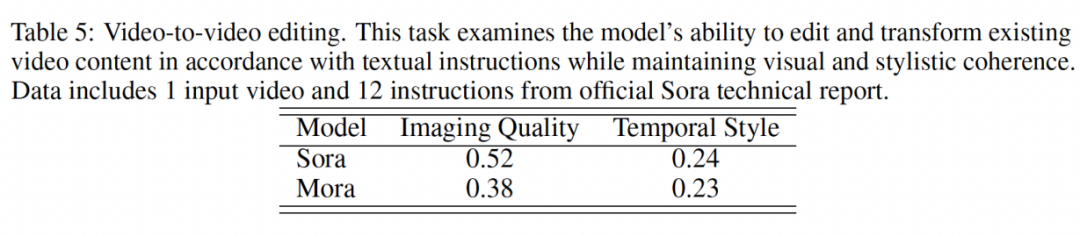
4. 视频到视频编辑:在这个任务中,Mora 的影像质量得分为 0.38,虽然低于 Sora 的 0.52,但考虑到 Mora 是一个开源模型,这一分数仍反映了其在视频编辑方面的潜力。

5. 连接视频:Mora 在连接视频任务中的影像质量得分为 0.42,低于 Sora 的 0.52。这表明在生成流畅过渡视频方面,Mora 与 Sora 之间存在一定的性能差距。

6. 模拟数字世界:在这项任务中,Mora 的影像质量得分为 0.52,略低于 Sora 的 0.62,但在外观风格(Appearance Style)得分方面与 Sora 持平,均为 0.23。


这些实验结果表明,尽管 Mora 在一些视频生成任务中与 Sora 存在性能差距,但在多个方面仍表现出了强大的性能和潜力。特别是,Mora 在文本到视频生成任务中表现出了与其他领先模型相当的性能,同时还具有开放源代码的优势,为未来的研究和开发提供了广阔的可能性。
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源
更多资源欢迎关注

