
- 1【时间】 js 根据已知的时间,判断是否是 前天,昨天,今天,明天,后天_js判断今天明天后天
- 2华为畅享6s可以升级鸿蒙,【华为畅享6S评测】华为畅享6S评测:颜值高又好用的千元机就是它了-中关村在线...
- 3运行速度终于变快了!优化VMD参数,五种适应度函数任意切换,最小包络熵、样本熵、信息熵、排列熵、排列熵/互信息熵...
- 4Macbook(苹果电脑) VSCode 创建简单c++程序 配置C++开发环境_mac做c++开发
- 5基于rk3568平台 rk809 codec的介绍
- 6sysbench的用法_sysbench可以设置table name吗
- 7两篇论文被ECML PKDD DC09接收_ecml-pkdd(ccf b类)论文被哪里收集
- 8flutter获取地理定位:geolocator依赖详细用法_flutter geolocator
- 9【自然语言处理】ChatGPT 相关核心算法_chatgpt核心算法
- 10OS系统下 使用MAMP站点配置详解_mamp 导出配置
强化学习——股票预测项目复现_dummyvecenv
赞
踩
1.背景介绍
之前学习百度强化学习7日打卡营-世界冠军带你从零实践时候,最后留下的一个大作业是股票预测环境:https://github.com/kh-kim/stock_market_reinforcement_learning,由于给出的一个推荐github项目是四年前,时间太久远,所以找了另一个,还是中文的,而且步骤看起来很详细。
❤github项目地址:https://github.com/wangshub/RL-Stock
所以在经历失败的复现:https://github.com/forrestneo/stock_reinforcement_learning_PARL之后,决定另外尝试一把。
看了一些issue上的问题,这个github项目也就是一个简单的toy类型的,暂时不纠结那么多证券股票上的概念了,先大概了解下实现。从计算机专业的角度去实现,暂时先不太纠结于经济概念。
2. 代码
2.1 需要的一些关键包
- baostack:股票证券数据集来自于 baostock,一个免费、开源的证券数据平台,提供 Python API。(
后来网上搜,开始有账户了,以后应该也不会免费了)
pip install baostock -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn
- 1
-
Stable Baselines:这个github上有好几个过k的项目
- 1.OpenAI的openai/baselines:https://github.com/openai/baselines
- 确实是没什么更新了,最早的一个都是去年了。
OpenAI Baselines: high-quality implementations of reinforcement learning algorithms
- 2.fork自openai/baselines的一个stable_baselines:https://github.com/hill-a/stable-baselines
- 与OpenAI相比,有文档,更新也还算比较及时。文档链接
A fork of OpenAI Baselines, implementations of reinforcement learning algorithms
- 3.stable_baselines的pytorch版本:https://github.com/DLR-RM/stable-baselines3#implemented-algorithms
- 同样也有文档,(可能因为repo创建晚,所以到目前更新挺频繁的)文档链接
PyTorch version of Stable Baselines, reliable implementations of reinforcement learning algorithms.
- 4.百度的PARL,https://github.com/PaddlePaddle/PARL
PARL是一个主打高性能、稳定复现、轻量级的强化学习框架。
使用场景
想要在实际任务中尝试使用强化学习解决问题
想快速调研下不同强化学习算法在同一个问题上的效果
强化学习算法训练速度太慢,想搭建分布式强化学习训练平台
python的GIL全局锁限制了多线程加速,想加速python代码- 在百度PARL的英文文档中,可以看到其对标的是RLlib
- 5.RLlib,属于Ray框架下的一部分,用于并行,https://github.com/ray-project/ray
- 根据知乎回答以及github项目作者的邮箱,这个也是谷歌出品的。
2.2 RL要素说明
2.2.1状态/观测信息
主要就是来自于从baostack中下载下来的数据字段,主要包括一下内容(我在2021.1.26下载下来的数据和那个github上登记的信息有部分出入,所以这个作者也就是随便搞搞。。。)
或者直接去看官网(也有很直接的描述表格):
http://baostock.com/baostock/index.php/A股K线数据
使用的是获取历史A股K线数据:query_history_k_data_plus()这个函数,所以返回数据示例如下:
| 参数名称 | 参数描述 | 说明 |
|---|---|---|
| date | 交易所行情日期 | 格式:1991/1/2 YYYY/MM/DD |
| code | 证券代码 | 格式:sh.600000。sh:上海,sz:深圳 |
| open | 今开盘价格 | 精度:小数点后2位;单位:人民币元 |
| high | 最高价 | 精度:小数点后2位;单位:人民币元 |
| low | 最低价 | 精度:小数点后2位;单位:人民币元 |
| close | 今收盘价 | 精度:小数点后2位;单位:人民币元 |
| volume | 成交数量 | 单位:股 |
| amount | 成交金额 | 精度:整数,小数点后0位;单位:人民币元 |
| adjustflag | 复权状态 | 默认不复权:3;1:后复权;2:前复权 |
| turn | 换手率 | 精度:小数点后6位;单位:% [指定交易日的成交量(股)/指定交易日的股票的流通股总股数(股)]*100% |
| tradestatus | 交易状态 | 1:正常交易 0:停牌 |
| pctChg | 涨跌幅(百分比) | 精度:小数点后6位 |
| peTTM | 滚动市盈率 | 精度:小数点后6位 |
| pbMRQ | 市净率 | 精度:小数点后6位 |
| psTTM | 滚动市销率 | 精度:小数点后6位 |
| pcfNcfTTM | 滚动市现率 | 精度:小数点后6位 |
| isST | 是否ST股 | 1是,0否 |
动作信息
2.3 代码部分
2.3.1 数据获取部分
get_stock_data.py:基本就是参考baostack网站给出的访问方式:http://baostock.com/baostock/index.php/A股K线数据
Downloader类的__init__函数中有开始日期和结束日期,开始日期不用变,结束日期可以换成自己附近的时间,主要在main函数中改一下测试集和训练集的一个划分(根据时间划分的)
比如:
if __name__ == '__main__':
# 获取全部股票的日K线数据
mkdir('./stockdata/train')
downloader = Downloader('./stockdata/train', date_start='1990-01-01', date_end='2019-11-29')
downloader.run()
mkdir('./stockdata/test')
downloader = Downloader('./stockdata/test', date_start='2019-12-01', date_end='2021-1-25')
downloader.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
此外,由于股票的名称可能会含有*这样的字符,比如*ST博信,而如果此时将股票名称作为文件名进行保存,就会由于包含非法字符而报出IOError错误,所以可以加一个函数:
def validateTitle(title):
rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |'
new_title = re.sub(rstr, "_", title) # 替换为下划线
return new_title
- 1
- 2
- 3
- 4
然后把Downloader类的run方法中的
df_code.to_csv(f'{self.output_dir}/{row["code"]}.{row["code_name"]}.csv', index=False)
改成
df_code.to_csv(f'{self.output_dir}/{row["code"]}.{validateTitle(row["code_name"])}.csv', index=False)
- 1
- 2
- 3
然后去运行等着就好了,会保存非常多的股票信息。和get_stock_data同级文件夹下会产生一个叫stockdata的文件夹,里面再有一个train和test文件夹
就是根据时间分的,下载到了不同的文件夹。(所以可以看到两个文件夹中股票名称和代码都是一样的,只是csv中数据的时段不一样,所以每个股票都可以用来分别进行训练和测试)
相当于每只股票都向baostack发了两次请求,其实也可以一次请求,然后自己再去excel里分开作为训练集和测试集。
2.3.2 环境部分
- 环境部分这个github其实主要是参考了下面的github:
https://github.com/notadamking/Stock-Trading-Environment - 相应的博文链接:
https://medium.com/@adamjking3/creating-a-custom-openai-gym-environment-for-stock-trading-be532be3910e - 不翻墙看不了,找到一篇中文介绍的博客:0基础创建自定义gym环境-以股票市场为例
- 就是大致说明了一下使用
gym定义自己的环境需要实现的基本函数。翻译一下好了
2.3.2.1 gym自定义环境的基本接口
import gym from gym import spaces class CustomEnv(gym.Env): """遵循gym的接口来创建自定义的环境""" metadata = {'render.modes': ['human']} def __init__(self, arg1, arg2, ...): super(CustomEnv, self).__init__() """ 定义动作和状态空间时,这两个要素必须是gym.spaces对象 使用离散动作的例子: """ self.action_space = spaces.Discrete(N_DISCRETE_ACTIONS) """ 使用图像作为输入的状态的例子 """ self.observation_space = spaces.Box(low=0, high=255, shape= (HEIGHT, WIDTH, N_CHANNELS), dtype=np.uint8) def step(self, action): """ 在环境中执行一步 """ ... def reset(self): """ 重置环境状态为初始状态 """ ... def render(self, mode='human', close=False): """ (将环境渲染到屏幕上)将环境进行可视化 """ ...

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 在构造函数
_init__中,需要先定义好动作空间和状态空间的type和shape。 - 每调用一次
step函数,都需要提供一个action,然后环境执行这个动作,返回下一个状态state以及刚刚执行action的reward。循环往复,当到达终点/目标之后,一轮结束,使用reset重置环境,开始下一轮episode
2.3.2.2 自定义股票环境要素说明
首先要考虑的就是构造函数中动作空间和状态空间如何定义
- 关于
状态空间:获取到的股票数据一共有17个属性,其中大部分属性都是连续的,只有几个是离散的。为了简化问题,就不使用那么多属性来作为状态空间了,先选几个。 - 选择作为
状态空间的有:开盘价、最高价、最低价、收盘价、日成交量(或者可以根据baostack中数据的属性再加几个) - ?:但是原博中说的账户信息,这个github上repo中的数据集中也没有账户信息。。。接着往下看代码吧
动作空间(action_space)包含三种可能:买入、卖出或无操作- 此外,还需要知道每次买卖股票的数量。所以需要用gym的
Box空间, - 创建一个
离散类型的动作,主要包括:买、卖、持有这三个操作 - 再创建一个
连续类型动作,用于表示买卖数量(账户余额/仓位大小的0-100%) - 虽然在
持有这个动作下 ,并不需要买卖数量(不存在交易动作),但是还是会提供,一开始agent不清楚,但是学习一段时间后就会得到这一信息。 - 最后关于
reward,这里对那些可以形成持续盈利的动作,给予更高的奖励
2.3.2.3 env.py 代码分析
脚本一开始定义了一些变量,不难分析出
MAX_ACCOUNT_BALANCE = 2147483647 """最大账户余额""" MAX_NUM_SHARES = 2147483647 """最大股票数量""" MAX_SHARE_PRICE = 5000 """最高股价""" MAX_OPEN_POSITIONS = 5 """ 敞口头寸 (open position) 指尚未对冲或交割的头寸,即持仓者承诺要买入或卖出某些未履约的商品,或买入或卖出没有相反方向相配的商品。 """ MAX_STEPS = 20000 """最多操作数量""" INITIAL_ACCOUNT_BALANCE = 10000 """初始账户余额""" """修改过的那个代码是添加了以下几个变量""" MAX_VOLUME = 1000e8 MAX_AMOUNT = 3e10 MAX_DAY_CHANGE = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
关于构造函数,如下
def __init__(self, df):
super(StockTradingEnv, self).__init__()
self.df = df
"""定义奖励的范围,账户余额 0-规定的最大账户余额"""
self.reward_range = (0, MAX_ACCOUNT_BALANCE)
"""动作空间定义:买XX,卖XX,持有"""
self.action_space = spaces.Box(low=np.array([0, 0]), high=np.array([3, 1]), dtype=np.float16)
# 使用近五日的OHCL作为状态
self.observation_space = spaces.Box(
low=0, high=1, shape=(6, 6), dtype=np.float16)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 假设交易共有买入、卖出和保持 3 种操作,定义动作(action)为长度为 2 的数组
- action[0] 为操作类型;
- action[1] 表示
买入或卖出百分比;
| 动作类型 action[0] | 说明 |
|---|---|
| 1 | 买入 action[1] |
| 2 | 卖出 action[1] |
| 3 | 保持 |
注意,当动作类型 action[0] = 3 时,表示不买也不抛售股票,此时 action[1] 的值无实际意义,网络在训练过程中,Agent 会慢慢学习到这一信息。
关于step函数,是由两个函数构成的,一个是_next_observation函数,用于返回下一个观测值,一个是_take_action函数,用于更新奖励
def step(self, action): """在环境中执行一个动作""" self._take_action(action) # 执行动作,更新奖励 self.current_step += 1 # 当前步数+1,不能超过MAX_STEPS = 20000 if self.current_step > len(self.df.loc[:, 'Open'].values) - 6: self.current_step = 0 # 同时,如果剩下的数据不足5条,置为0 delay_modifier = (self.current_step / MAX_STEPS) reward = self.balance * delay_modifier # net_worth是在_take_action中定义的 done = self.net_worth <= 0 obs = self._next_observation() return obs, reward, done, {} def _take_action(self, action): """将当前价格设置为基于当前时间步的一个随机值(范围区间在开盘价和收盘价之间)""" current_price = random.uniform(self.df.loc[self.current_step, "Open"], self.df.loc[self.current_step, "Close"]) """采取动作:交易类型 交易量""" action_type = action[0] amount = action[1] if action_type < 1: """动作类型<1 买入X%份额""" total_possible = int(self.balance / current_price) shares_bought = int(total_possible * amount) prev_cost = self.cost_basis * self.shares_held additional_cost = shares_bought * current_price self.balance -= additional_cost self.cost_basis = ( prev_cost + additional_cost) / (self.shares_held + shares_bought) self.shares_held += shares_bought elif action_type < 2: """动作类型1<x<2 卖出X%份额""" shares_sold = int(self.shares_held * amount) self.balance += shares_sold * current_price self.shares_held -= shares_sold self.total_shares_sold += shares_sold self.total_sales_value += shares_sold * current_price """ 不然就是持有 不进行操作 net worth 净资产 =原有的余额+持有的股票(可能更新了)*股票当前价格 """ self.net_worth = self.balance + self.shares_held * current_price if self.net_worth > self.max_net_worth: self.max_net_worth = self.net_worth if self.shares_held == 0: self.cost_basis = 0 def _next_observation(self): """获取过去5天股票数据,归一化到0-1之间""" frame = np.array([ self.df.loc[self.current_step: self.current_step + 5, 'Open'].values / MAX_SHARE_PRICE, self.df.loc[self.current_step: self.current_step + 5, 'High'].values / MAX_SHARE_PRICE, self.df.loc[self.current_step: self.current_step + 5, 'Low'].values / MAX_SHARE_PRICE, self.df.loc[self.current_step: self.current_step + 5, 'Close'].values / MAX_SHARE_PRICE, self.df.loc[self.current_step: self.current_step + 5, 'Volume'].values / MAX_NUM_SHARES, ]) """ 作为一个学过机器学习的,这个归一化的方式直接除以自己设定的一个最大值 (都不是从数据里提取的最大值),这个归一化方式不是很合适吧 """ """ 添加一些额外的数据,也要保证归一化到0-1之间 下面这部分属性,没有现成的数据,确实只能是自己定一个最大值去归一化, 只要最大值标准一样,也算吧 """ obs = np.append(frame, [[ self.balance / MAX_ACCOUNT_BALANCE, self.max_net_worth / MAX_ACCOUNT_BALANCE, self.shares_held / MAX_NUM_SHARES, self.cost_basis / MAX_SHARE_PRICE, self.total_shares_sold / MAX_NUM_SHARES, self.total_sales_value / (MAX_NUM_SHARES * MAX_SHARE_PRICE), ]], axis=0) return obs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
关于reset()函数和render()函数,都比较简单,这里的render函数并不是图形化的,而是打印出文字信息,如果需要可视化的话,可以自己改改。
2.3.3 模型部分
从requirment.txt文件中,可以知道,使用的是stable-baselines==2.10.0这个库。
2.3.3.1 安装包
参考安装文档:
https://stable-baselines.readthedocs.io/en/master/guide/install.html#prerequisites
- 如果是在Windows下,则需要下载一个
MPI for Windowsmsmpisetup.exe
然后因为可能会用到这些算法:
需要使用OpenMPI并行训练的算法:GAIL, DDPG, TRPO和PPO1
所以安装如下:pip install stable-baselines[mpi] -i https://pypi.tuna.tsinghua.edu.cn/simple pip install tensorflow==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple # 如果报超时错误,就多试几遍- 1
- 2
- 3
- 截止到我安装的时候,python3.7默认安装的版本是
stable-baselines==2.10.1,版本差的不多 - 安装了stable-baselines之后,在运行代码的时候,报错没有tf(所以这个库的依赖包有TensorFlow,再去安装一下)。。。
- 仔细看github上的安装说明,有一句是:
Note: Stable-Baselines supports Tensorflow versions from 1.8.0 to 1.14.0. Support for Tensorflow 2 API is planned.
2.3.3.2 代码说明
from stable_baselines.common.policies import MlpPolicy from stable_baselines.common.vec_env import DummyVecEnv from stable_baselines import PPO2 import pandas as pd df = pd.read_csv('./data/AAPL.csv') df = df.sort_values('Date') """ PPO2这个算法需要接收一个向量化的环境, 将env传递给这个包装器就可以把env自动包一层了 env = DummyVecEnv([lambda: env]) """ env = DummyVecEnv([lambda: StockTradingEnv(df)]) model = PPO2(MlpPolicy, env, verbose=1) model.learn(total_timesteps=20000) obs = env.reset() for i in range(2000): action, _states = model.predict(obs) obs, rewards, done, info = env.step(action) env.render()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这里的代码主要涉及到stable-baselines这个库的使用,参考:stable-baselines-Getting Started
env = DummyVecEnv([lambda: env])。PPO2这个算法需要接收一个向量化的环境, 将env传递给这个包装器就可以把env自动包一层了MlpPolicyPolicy object that implements actor critic, using a MLP (2 layers of 64)。MlpPolicy指的是使用MLP(两层神经网络)的一个actor-critic网络verbosethe verbosity level: 0 none, 1 training information, 2 tensorflow debug(详细信息级别:0 没有;1 训练信息;2 TensorFlow debug信息)
2.3.4 运行过程中的错误
运行的项目是这个
❤github项目地址:
https://github.com/wangshub/RL-Stock
上面涉及的别的是为了看懂这个代码
错误1:
tensorflow.python.framework.errors_impl.NotFoundError: Failed to create a directory: ./log\PPO2_1; No such file or directory
解决:
参考github的issue:
tensorflow.python.framework.errors_impl.NotFoundError: Failed to create a directory: ./tensorboard\PPO2_1; No such file or directory #33
虽然是来自另一个github,但是都是和TensorFlow相关的。
具体github上代码修改部分的链接是:
fix issue with file path forward slash in Windows
主要是因为不同操作系统,路径中斜杠的使用方式不一致造成的。如果是Windows下,进行如下修改:
from pathlib import Path
model = PPO2(MlpLnLstmPolicy, train_env, verbose=0, nminibatches=1,
tensorboard_log="./tensorboard", **model_params)
改为: tensorboard_log=Path("./tensorboard").name, **model_params)
- 1
- 2
- 3
- 4
2.3.5 运行结果
运行的项目是这个
❤github项目地址:
https://github.com/wangshub/RL-Stock
上面涉及的别的是为了看懂这个代码
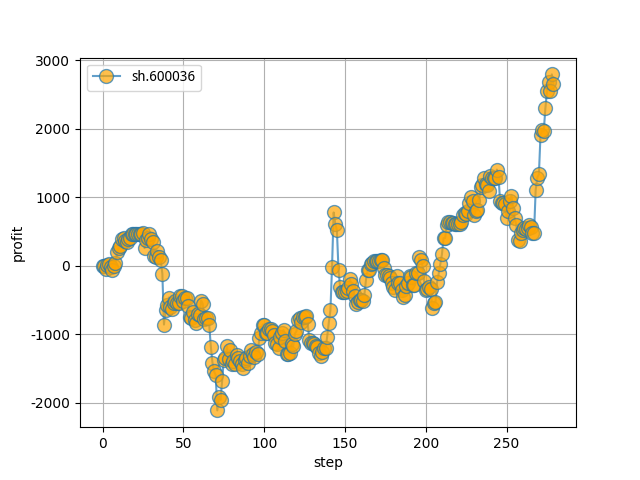
ax.plot(daily_profits, '-o', label=stock_code, marker='o', ms=10, alpha=0.7, mfc='orange')
- 1
- 这是测一只股票每天的一个收益,蓝色线就是那个折线图,橙色圆点是每个点的标签。
model = PPO2(MlpPolicy, env, verbose=1, tensorboard_log=Path('./log').name)
- 1
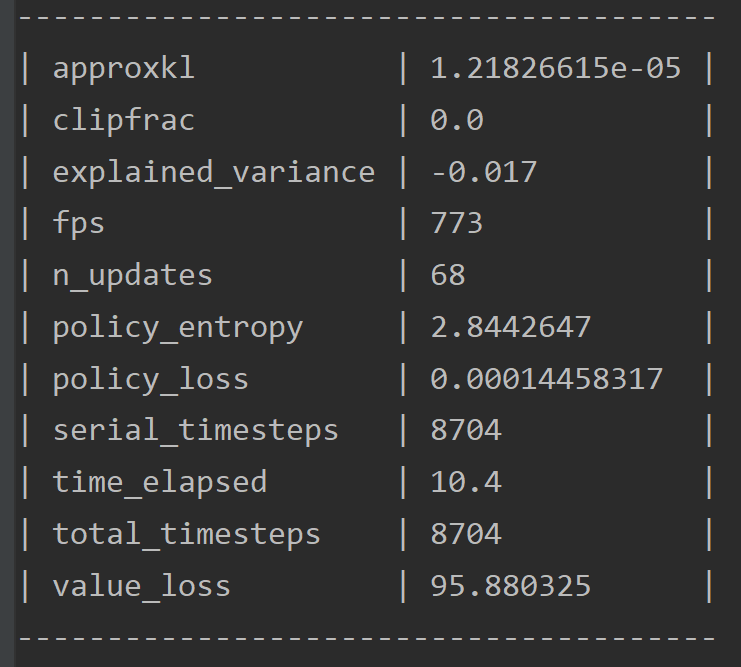
- 可以把上面的
verbose=0改成1(代码里最初是0),然后可以看到比较详细的训练信息。类似:
3. 强化学习框架调研
- 目前最好用的大规模强化学习算法训练库是什么? - fmxFranky的回答 - 知乎
https://www.zhihu.com/question/377263715/answer/1120555103 - 同样问题下还有其他回答也可以看看。有几个说的很好,做这方面的目前也确实还比较少,所以框架都是各行其道。
4. gym自定义环境
这个似乎有些复杂,需要仔细研究一波,暂时记录在这里,主要参考:
- 知乎专栏:手把手教你如何定制OpenAI Gym学习环境(一)
- CSDN博客:OpenAI Gym构建自定义强化学习环境
- 关于gym的env类,可以去查看对应的源文件:https://github.com/openai/gym/blob/master/gym/core.py
这个脚本文件中包含一些例子和代码说明,以及wrapper环境的方式。 - gym的github给出的自定义环境的文档,目前只有:
- 主要是介绍gym含有哪些环境
- How to create new environments for Gym:这里主要是提供了一个范例,鼓励大家参考https://github.com/openai/gym-soccer这个去照猫画虎

