
- 1微信小程序的组件和相关类型2.0组件文件说明_小程序交易组件2.0是什么
- 2Android 如何从android手机将数据导出,查看数据库_androidx.room 数据库手机上怎么导出
- 3夜神模拟器连接Android Studio
- 4什么是端口映射?
- 5ModuleNotFoundError: No module named ‘tensorboardX‘_linux下无法安装tensorboardx
- 6好的mysql实时同步工具_异构数据库实时同步工具有哪些?
- 7鸿蒙 HarmonyOS应用开发之API:Context
- 8Python期末大作业(学生成绩管理系统)
- 9Ubuntu 16.04 标题栏实时显示上下行网速、CPU及内存使用率_ubuntu16.04显示cpu
- 10一个BP的完整代码实现(供参考与收藏)_bp神经网络降噪代码
详解GPT技术发展脉络_gpt的技术顺序
赞
踩
文章目录
前言
从前几年引起一场资本骚动的元宇宙,到年初的ChatGPT,想必大家也都感受了前所未有的热度;而元宇宙是一个概念,ChatGPT是一个实实在在的产品;后者所能激起的涟漪,我相信比前者更深远;以下是1亿用户的时间图:
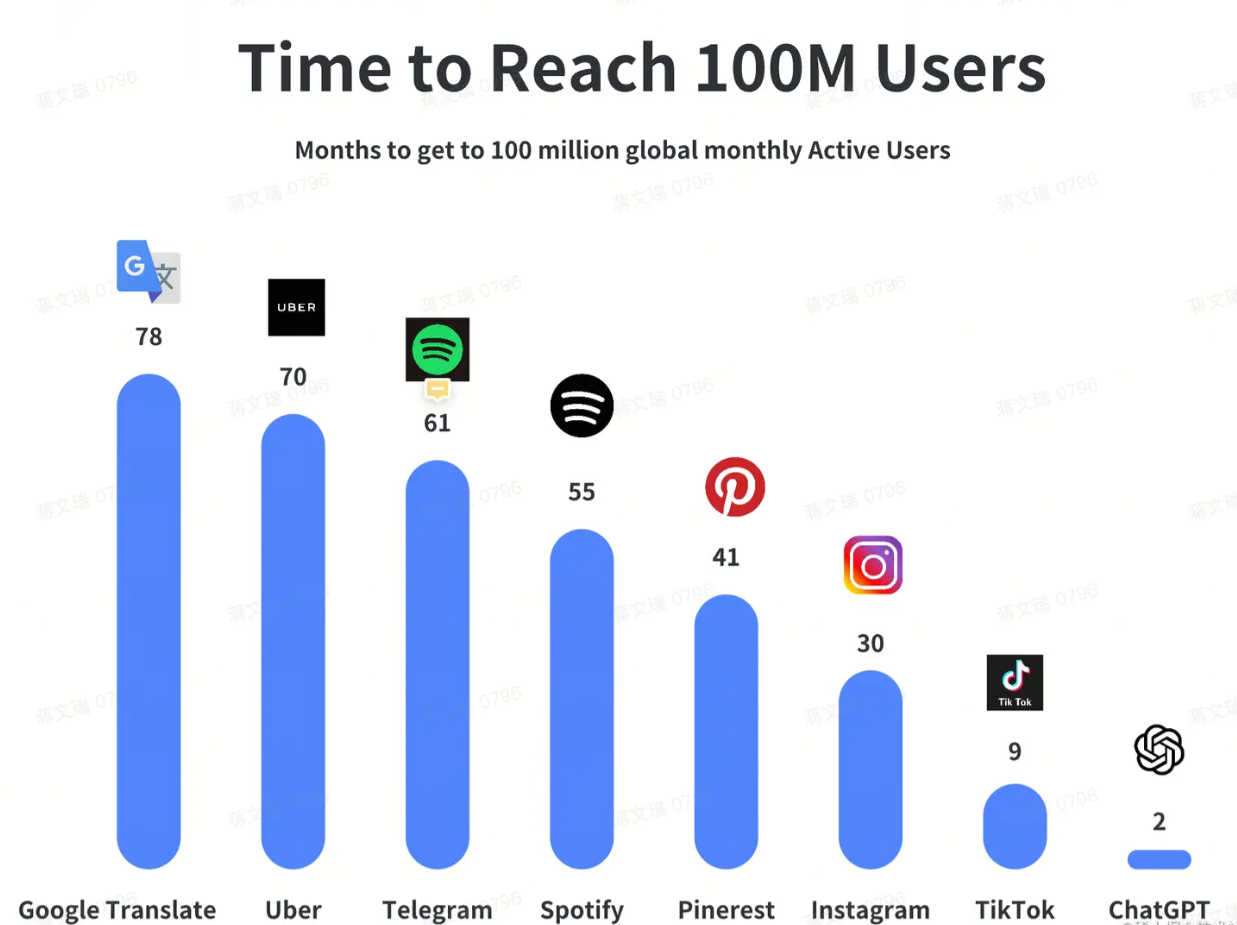
从GPT-1到ChatGPT,再到GPT-4,这中间涌现了太多突现能力,典型如思维链,然而这些让人为之着迷的能力要梳理清楚并不易,尤其是GPT-4那份几百页的技术报告中,没有提到任何重要的能力细节
Elon Musk调侃OpenAI变成了CloseAI
Elon Musk : OpenAI was created as an open source (which is why I named
it “Open” AI), non-profit company to serve as a counterweight to
Google, but now it has become a closed source , maximum-profit company
effectively controlled by Microsoft
基于此,这篇文档希望化零为整,为大家梳理出一份详尽的技术能力报告,让我们以更低的成本建立起对大语言模型的思维图;
这里的梳理来自于:
- 精读了GPT相关的8篇论文
- 吸纳那些优秀的公开博文,比如符尧的文章
- 一些付费的课程
关于AIGC与大模型,我们从以下维度为大家带来一份全局的视野探索
- 详解GPT技术发展脉络
- 视觉AIGC原理
- 如何训练100B以上的大模型
- Prompt提示词工程
本篇作为第一篇,希望为大家清晰的呈现GPT的技术发展脉络
对于ChatGPT事实上也是褒贬不一,有关于一个全新AI时代的呼声:
Bill Gates :The Age of AI has begun;Artificial intelligence is as revolutionary as mobile phones and the Internet.( Origin Blog: The Age of AI has begun )
Jensen Huang :This is the iPhone moment for Artificial Intelligence(Origin Blog: An Interview with Nvidia CEO Jensen Huang About AI’s iPhone Moment )
也有不少学者认为离真正AI还相差甚远,我们来看看人工智能三巨头的评价
Yann LeCun : ChatGPT is ‘not particularly innovative,’ and ‘nothing revolutionary’
Geoffrey Hinton: We’re better at reasoning. We have to extract our knowledge, getting from much less data.
关于我们自身
艾比赫泰德:
对于未来不可控的事情,我们要保持乐观和自信;
对于可控的事情,我们要保持谨慎和节制
关于本篇的分享内容
本篇主要提到的内容包含以下方面:
-
Transformer是如何一统NLP与CV领域?成就了今天在AIGC中的核心地位
-
GPT-(1、2、3、3.5、4)每一代融入了什么核心技术?才发展至今
-
关于大模型的预训练Pre-Training、有监督微调SFT、以及强化手段RLHF
-
关于大模型的复杂推理、涌现能力Emergent Abilities
-
训练大模型有哪些难点?
-
如何从AIGC扩展到AIGA?
大语言模型
大模型
大模型所带来的各项突出能力,包括涌现能力,将使得大模型逐渐成为未来AI的基础设施大模型的大不仅仅是指参数量的大小;
它和小模型对比如下:
| 数据 | 模型 | 训练 | 优 | |
|---|---|---|---|---|
| 小模型 | 大量特定任务的不同标注数据 | N个任务N个模型 | 不同任务反复调试与优化;算法研发碎片化 | - |
| 大模型 | 海量无标注数据 | 统一的多模态大模型 | 少量的特定任务数据做微调或者few-shot; 大模型为基底,研发集中化 | 对比小模型效果更显著;泛化能力强,可应用于多种任务;迁移快,微调或者few-shot;成本低,无监督预训练减少对数据标注的依赖 |
语言模型
人类自身是一个相当脆弱的物种,跑不过马,斗不过熊,嗅觉不如狗,视力不如鹰,能从众多高等动物中脱颖而出的原因就是「语言中积累的世界知识」。
其他高等动物虽然也能通过实践,建构关于世界的认识,获得相应的改造能力,可这些认识仅存在于个体的脑中,会随着个体的死亡而消失,无法代代积累。但语言的发明,允许人类将个体所获得的认识存储在体外,进而打通了整个物种的过去与未来,即使一些个体死亡,该个体的认识,也能依附语言被其他个体继承和发展下去。作为现代人的我们,并没有在生理上比前人更优越,拥有更强能力的原因,只是因为语言中积累的知识比过去更多了。
当人类步入文明社会后,尽管已不必在野外求生,但仍然需要群体协作地「创造知识」「继承知识」和「应用知识」,满足社会的需求,来维持自己的生计,而这三个环节全都是依靠语言来实现的。
随着知识的爆炸式增长,语言处理的成本也相应地飙升。越大的机构,消耗在语言处理上的成本就越高语言处理效率成为了一个亟待解决的问题相比人类,机器处理语言的优势太突出了:处理速度快、工作记忆大、知识覆盖广,可以 7x24 小时不间断处理海量语言内容,而且不受作息和情绪影响。哪怕是些许的效率提升,也会节约大量的成本。
相比于传统的NLP技术,大语言模型LLM展现了人们未曾想过的“理解”能力,这使得我们极有希望真正实现“让机器‘理解’自然语言”这一目标。
我们可以总结为:由于大语言模型所能改善的是:群体协作过程中「创造、继承、应用知识」时的「语言处理效率」;即大语言模型开启了LUI的新篇章;
百花齐放
AIGC关键产品

Transformer
以前视觉用CNN,文本NLP用RNN,而现在Transformer不仅可用于所有的NLP任务,还可以用于图片、音频、视频,像一个“统一的语言”
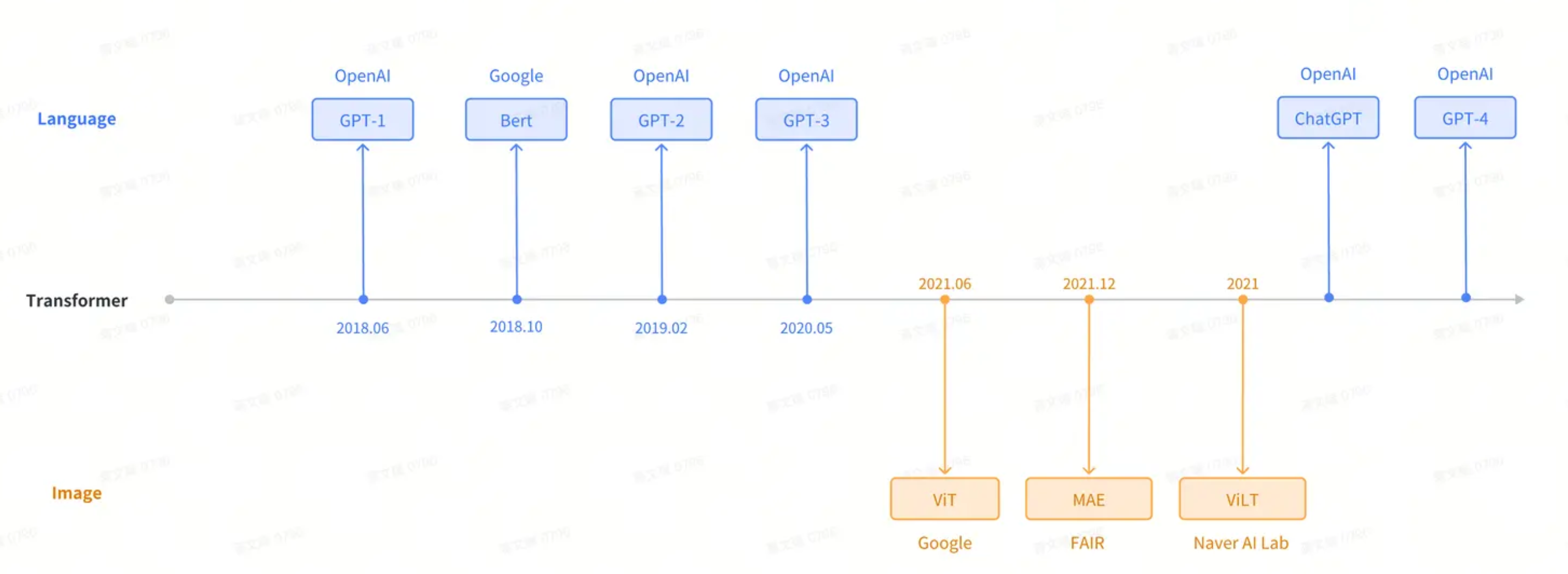
其发展脉络如下所示:
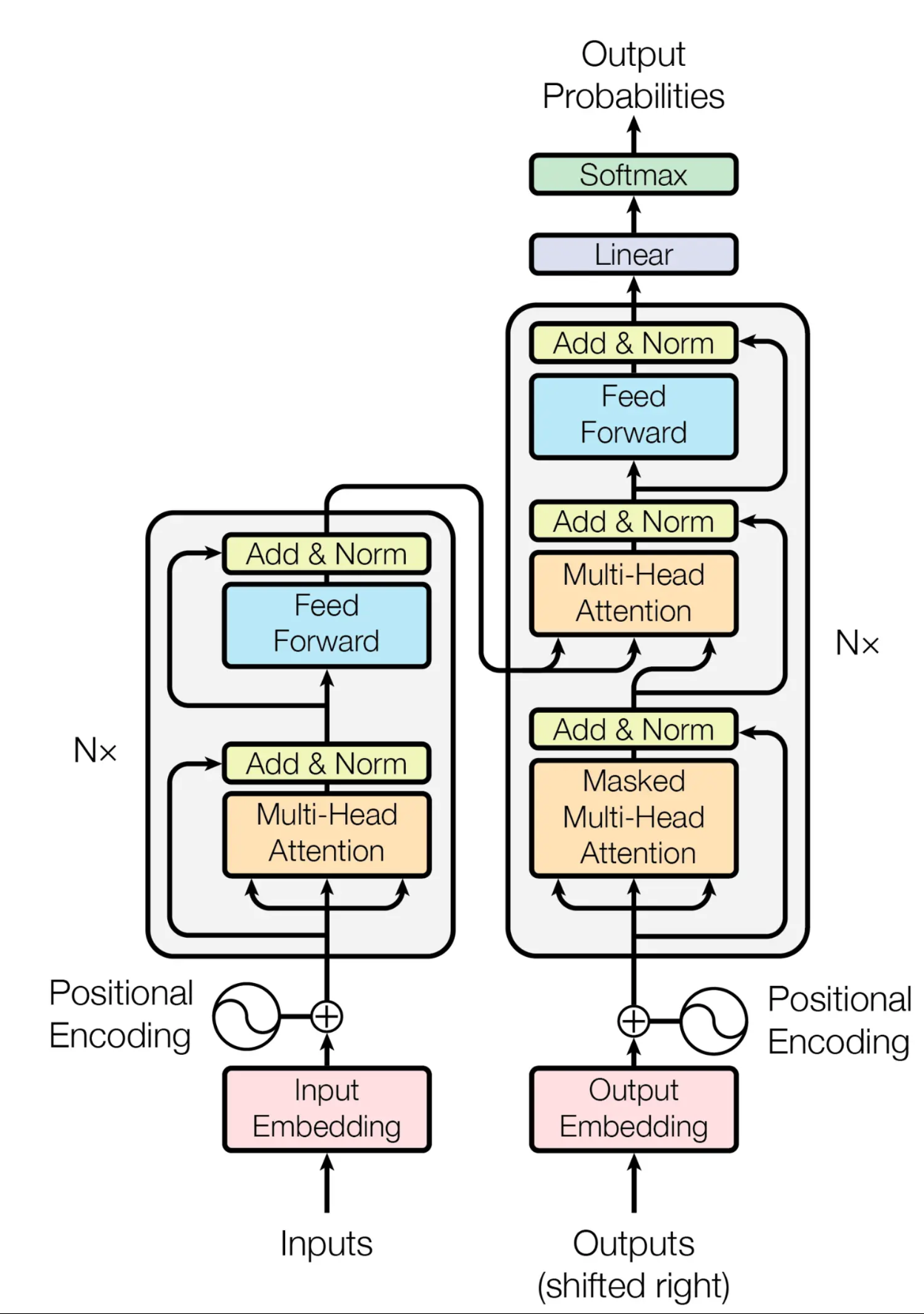
其模型结构如下图所示:
传统的序列问题,采用RNN或者CNN捕捉序列信息,但是这样存在两个问题:
- 无法并行处理
- 长程依赖偏弱
这两个问题我们后续展开介绍
下面介绍Transformer中包含的关键技术
Auto-Regressive
Transformer采用的是自回归模型,过去时刻的输出,也会作为当前时刻的输入
Resnet
Transformer中使用残差链接的目的主要有两点:
- 解决梯度消失的问题
- 解决权重矩阵的退化问题
这里就不展开赘述
Layer-Norm
Transformer中使用的是layer-norm而不是batch-norm
因为batch-norm是垂直向的norm,其对象是batch
相反的,layer-norm是水平向的norm,其对象是样本sample,即:
- batch-norm是把每一个列的均值变0方差变1
- layer-norm是把每一个行的均值变0方差变1
batch-norm在CV图像领域这种规则的输入结构中表现较佳,但是NLP文本领域,句子长度参差不齐,一个batch中个样本token长度不对等,如果继续使用batch-norm,其均值、方差抖动相对来说也是比较大的
Mask
主要在解码器,训练时避免t时刻看到了t时刻之后的东西
Scaled Dot-Product Attention
Q是一个向量,K与V是一一对应,是一连串的向量,Output是V的加权求和,其权重是Q与K分别做内积
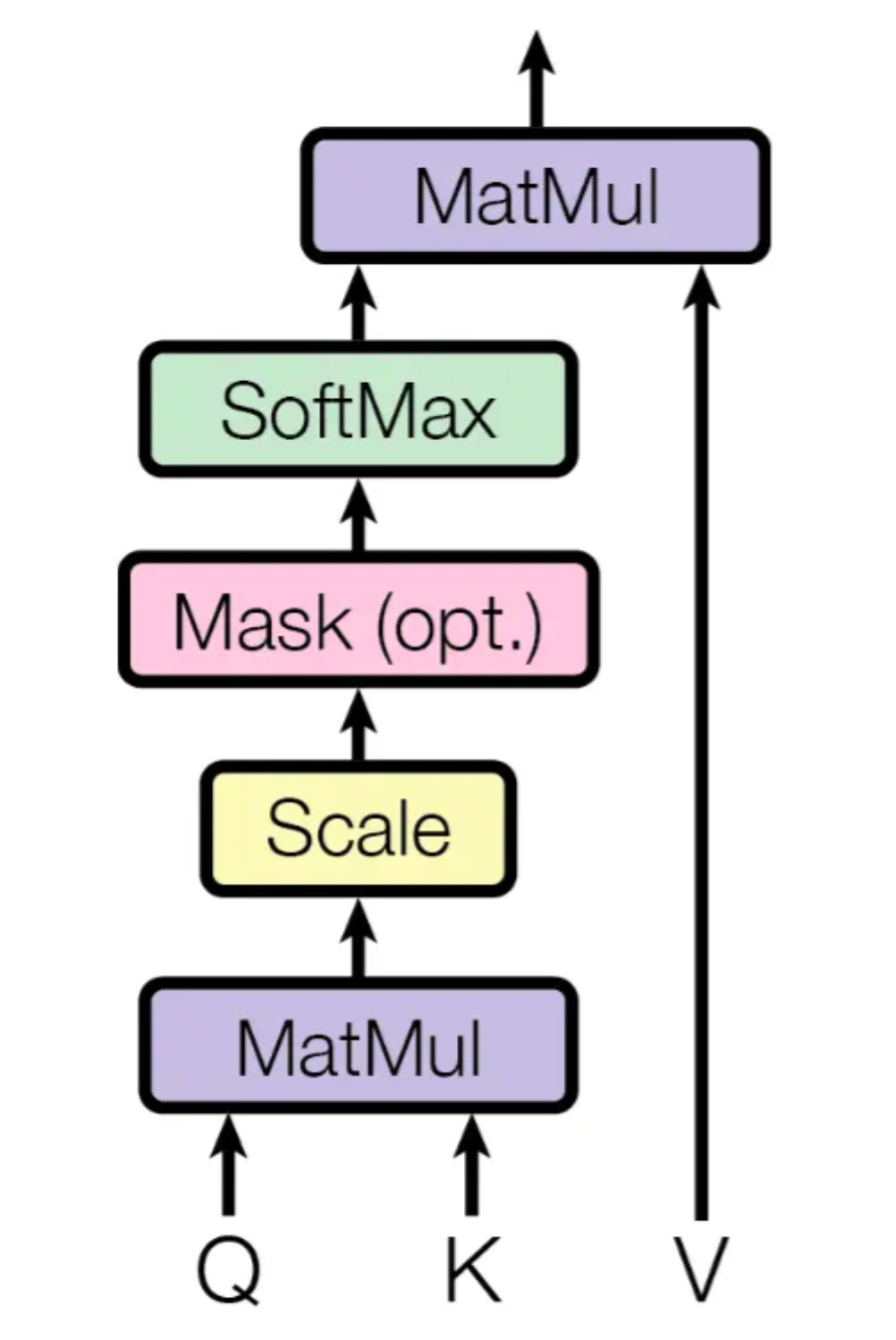
公式化即:

我们对公式图形化展开即:
为什么要除以向量长度做scaled,当dk较大的时候,也就是向量比较长时,内积的值容易出现两极分化的情况,再经过softmax的处理,就会出现一个接近于1,另一者接近于0的情况,出现这种情况时,算梯度的时候会发现梯度比较小;
这里的mask就是避免第t时刻的时候看到了以后时间的东西,即Qt只应该看K1-Kt-1的内容,训练时,实际运算为了矩阵对齐会计算到Kn,这个时候将Kt-Kn的内容mask掉
Multi-Head Attenion
如下图所示:
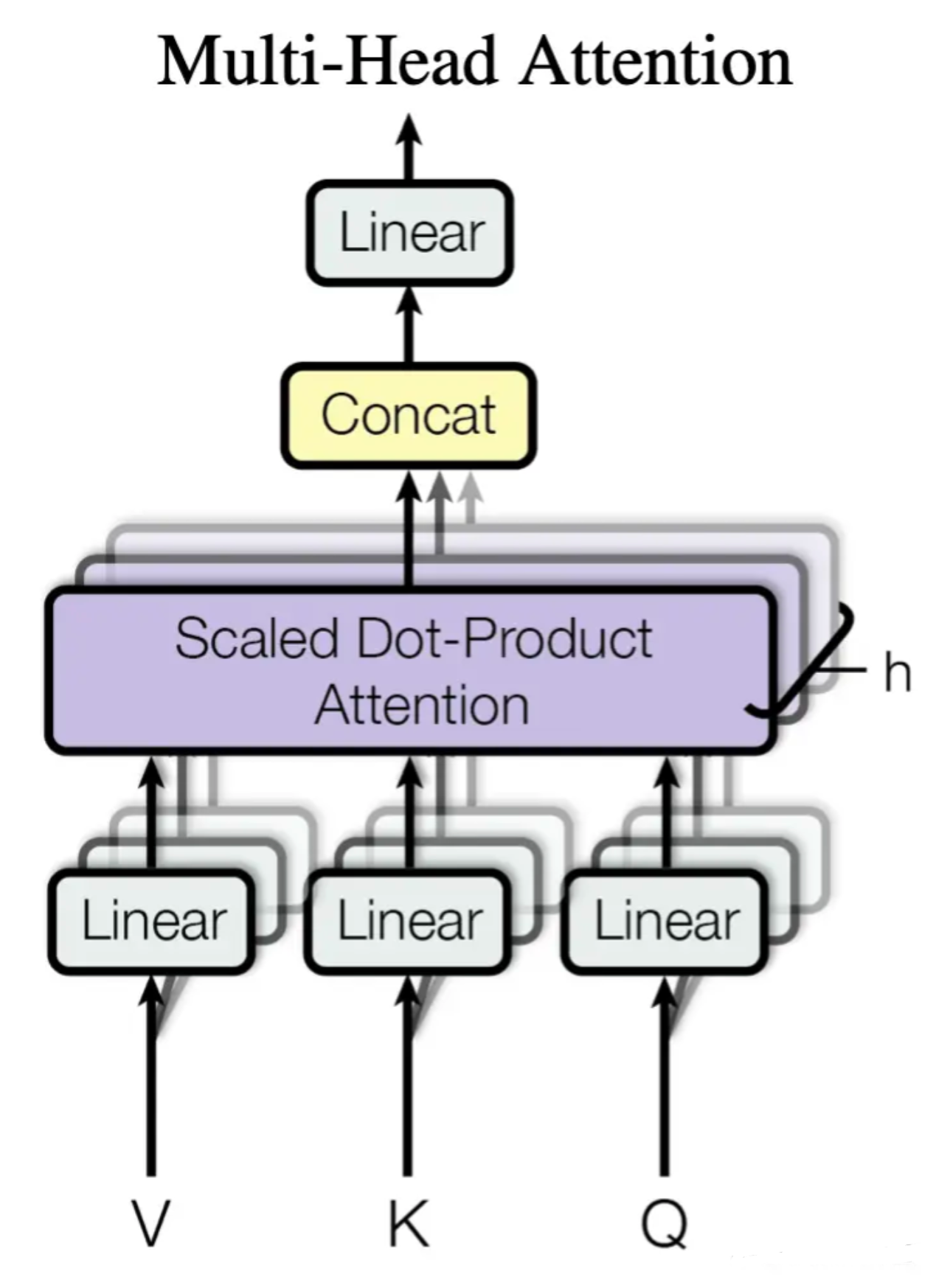
首先经过线性投影层,将KVQ投影到低维度,然后再做h次的Scaled Dot-Product Attention,得到h个输出;
为什么要做多头呢?回过头去看Scaled Dot-Product Attention,它里面是没有什么参数去学习的,有时候为了识别不一样的模式,先让其投影到低维度,这里的投影w是可以学习的,有点类似卷积里面的多个输出通道
Self-Attention
K=V=Q时,我们得到Self-Attention
Transformer中使用Multi-Head Attenion的情况分为三种:
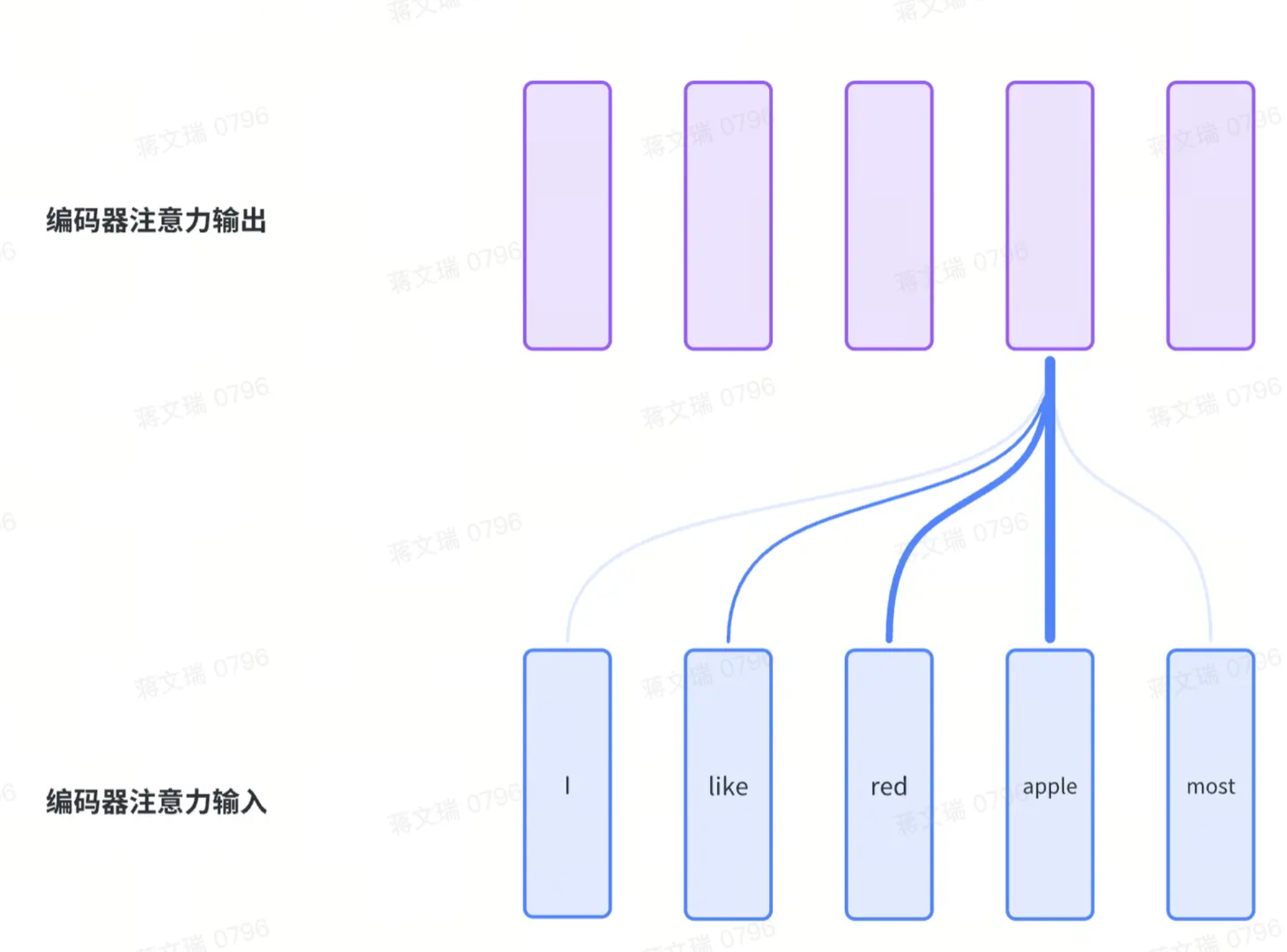
A.编码器的多头自注意力
假设输入是长度为n的句子,那么输入V本质是n个长度为d(=512)的向量;因为有n个Q,所以会有n个输出,这样正好与输入的形态是对齐的;
如下图所示,蓝色部分为输入,紫色部分代表Multi-Head Attenion之后的输出;其中线条粗细代表权重大小,也就是QK的大小:
B.解码器的多头自注意力
其本质和编码器的多头自注意力是一样的,句子总长度为m,唯一的区别是包括mask
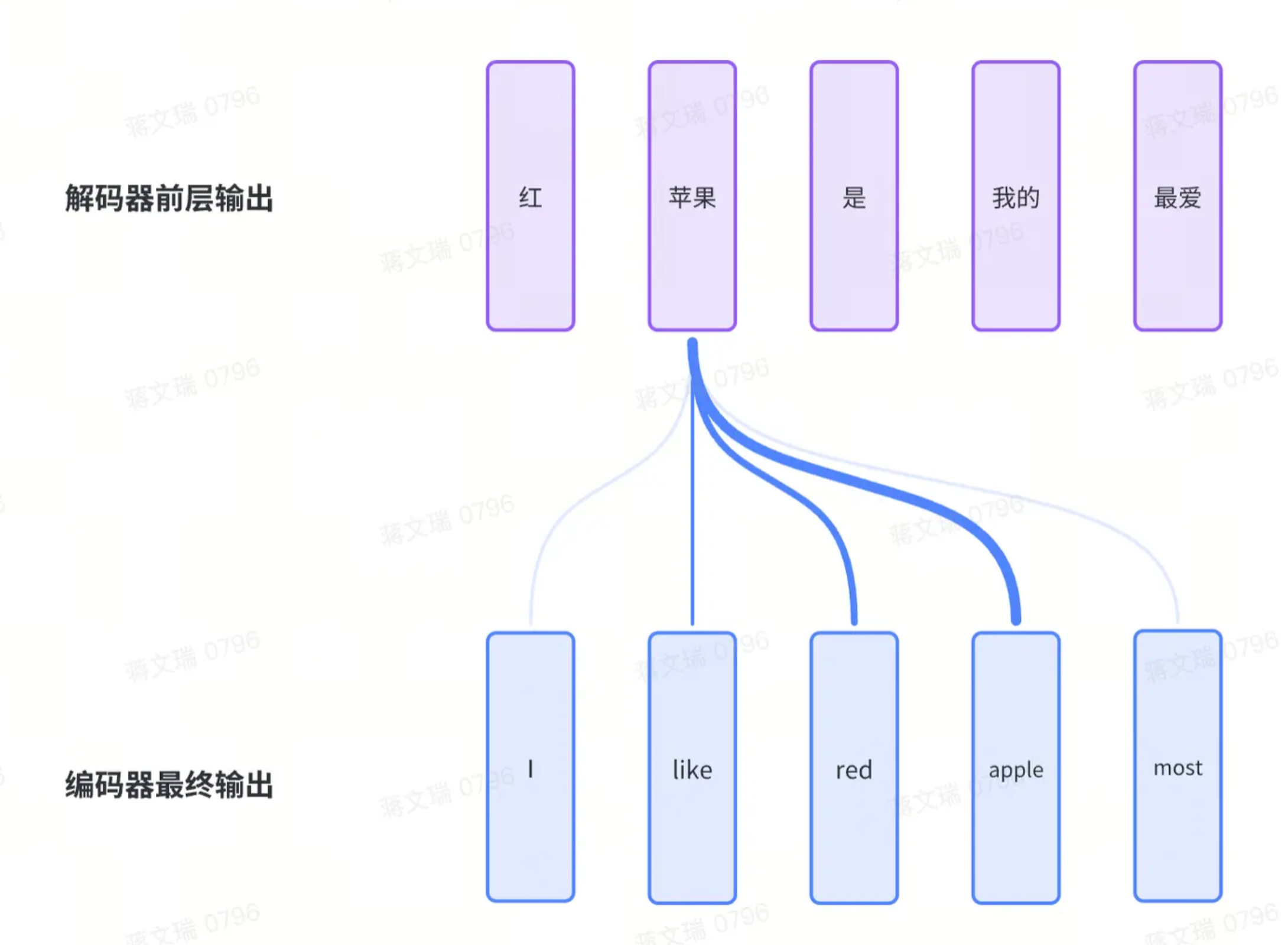
C.解码器的多头注意力
这里不再是自注意力模型;其形态如下:
- K、V来自于编码器的输入
- Q来自于解码器前层多头自注意力的输出
Positional Encoding
因为attention本身是没有捕捉时序信息的,一句话顺序任何打乱之后,attention出来的结构都是一样的;rnn是把上一时刻的输出作为下一时刻的输入,本身就能捕捉时序信息;attention为了把时序信息加入进来,其做法是在输入里面加入时序信息,也就是Positional Encoding,其返回每个词位置的向量信息,向量长度等于词本身向量长度
关于并行计算
Transformer与RNN在处理时序方面的流程如下:

从图中可以看出:
- 在Transformer中,是利用attention全局的去拉取整个序列里面的信息,然后再利用MLP做语义空间的转换
- 而RNN则需要依赖前序输出作为下一序的输入,存在时序依赖,无法做并行计算
它们的共同关注点都是在于如何有效的去利用序列信息
关于长程依赖
关于长程依赖,可以参考Maximum path lengths:
Maximum path lengths:信息从第一个token传递到最后一个token所需要的步伐
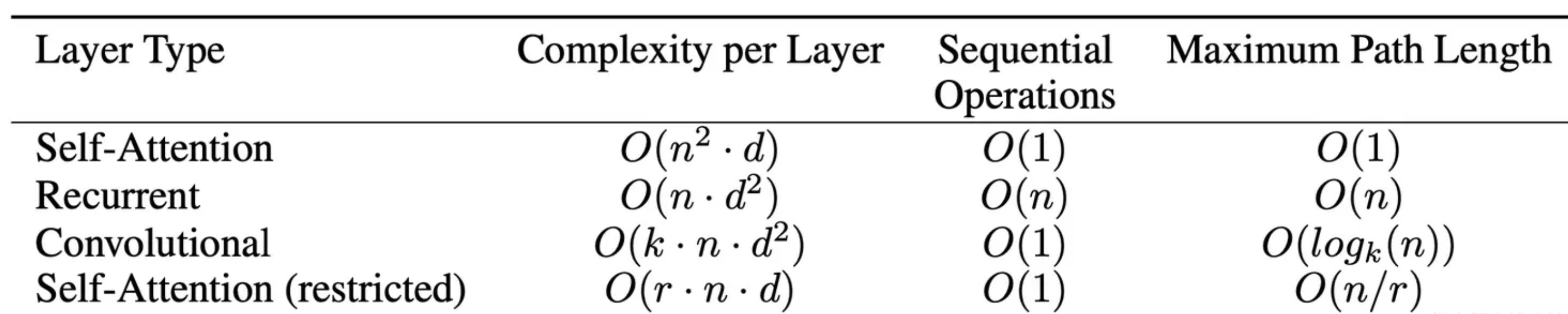
对于RNN,其Maximum path lengths是n(n等于序列长度),而Transformer如上所说,是利用attention全局的去拉取整个序列里面的信息,其Maximum path lengths等于1,故而RNN面对长序列时,信息是有损的,我们说Maximum path lengths越大,信息损耗越大
Transformer演化
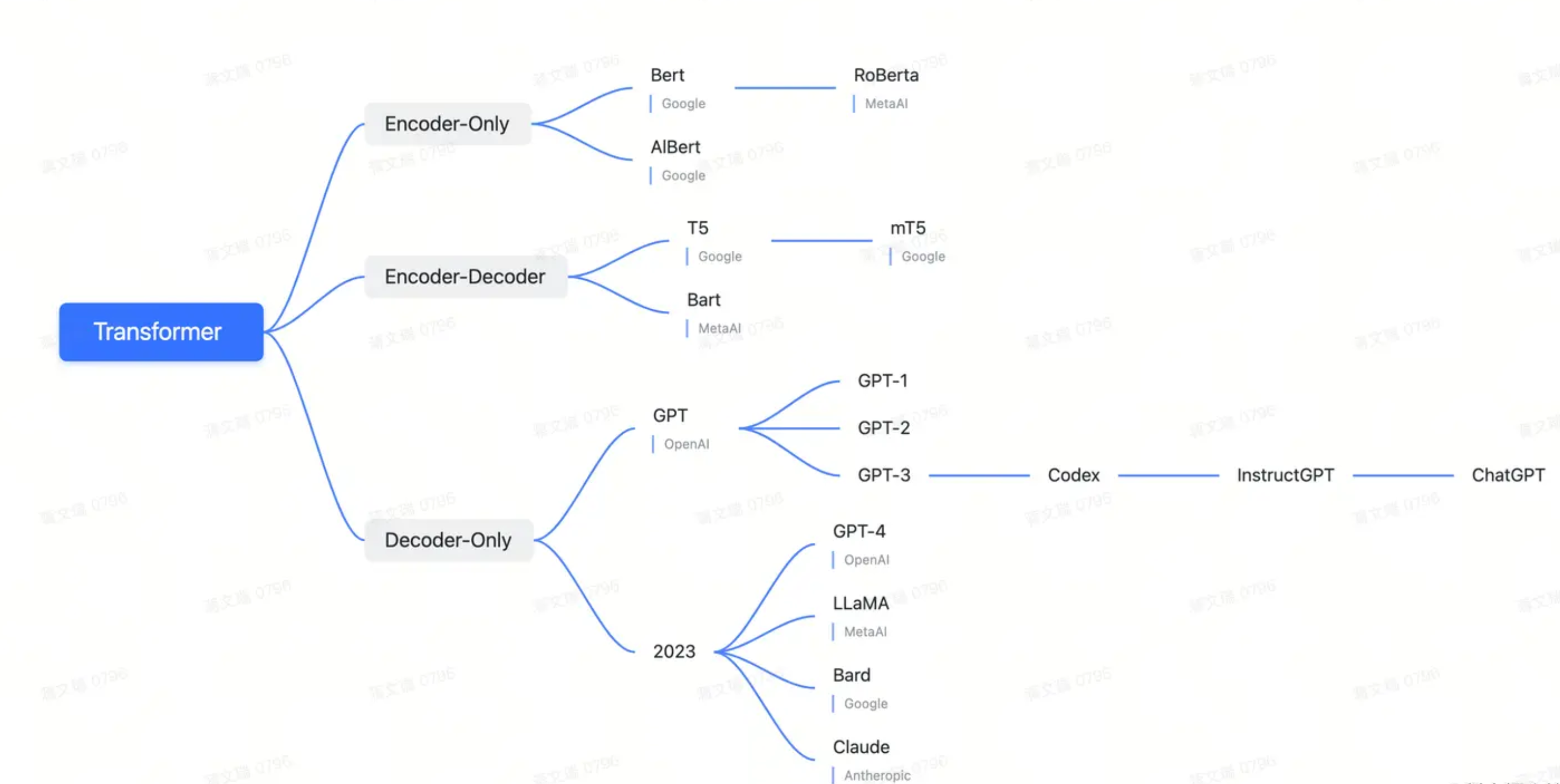
GPT Series
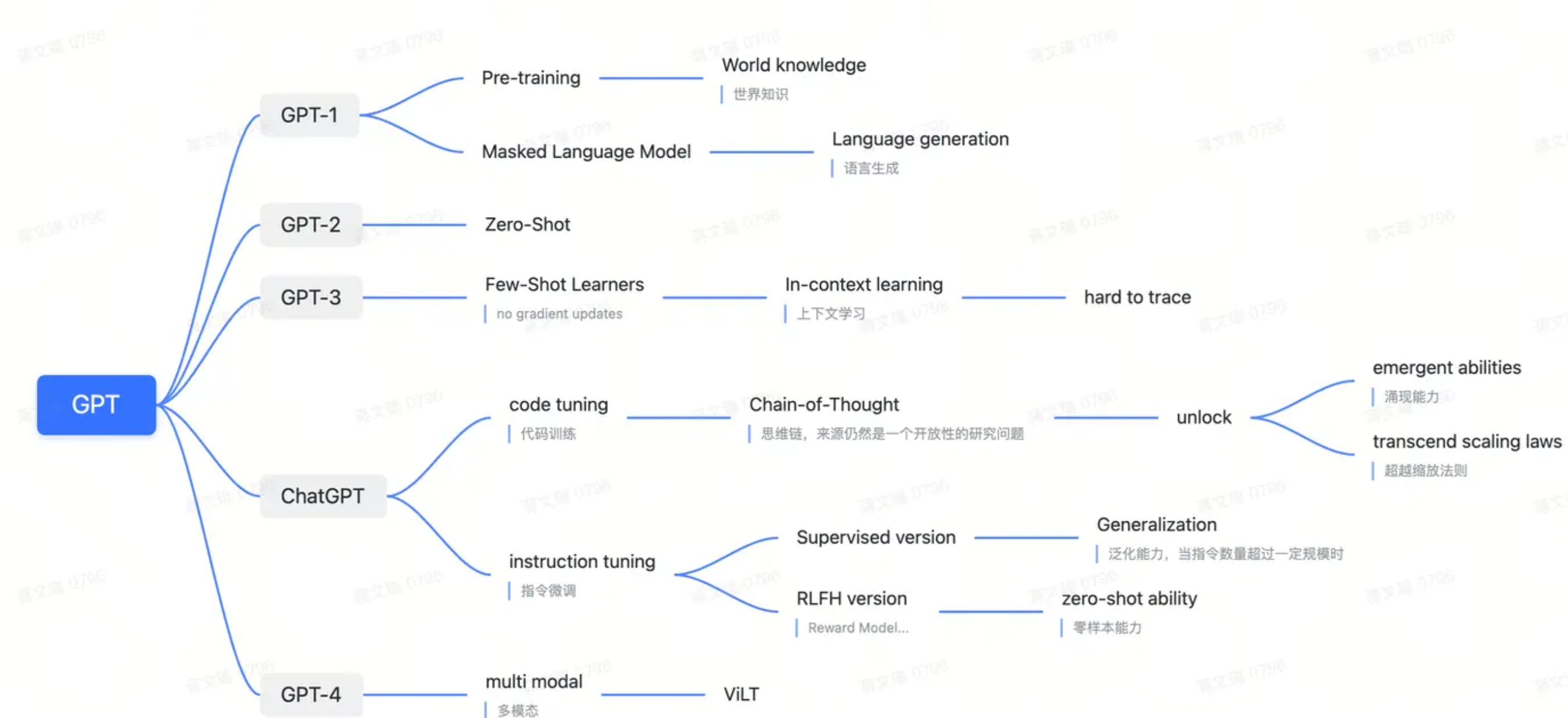
GPT-1
GPT-1打破了小模型在大量任务上反复训练的模式,建立了以下大规模预训练模式:
- Self-supervised pre-training on large text corpus
- Fine-tuning on a smaller task-specific dateset
这里回顾一下预训练的几种方式:
- Self-supervised pre-training(自监督)
- Unsupervised pre-training(无监督)
- Contrastive pre-training(对比学习)
面对这一模式,GPT-1面临着两个问题:
-
如何设计统一的目标函数
-
如何将学习到的信息传递给下游子任务
masked language model
对于如何设计统一的目标函数,作者提出了masked language model
- GPT:对于GPT,其mask的是最后一个词,用模型去预测下一个词,类似于单字接龙
- Bert:对于Bert,其mask的中间的词,依据上下文去预测中间的词,类似于完形填空
除了NLP领域,Transformer也建立起了视觉领域的自监督预训练模式,即masked patch prediction,将图片像素分割为m*n的patch
SFT
有两个目标函数,一个是继续采用无监督时候的目标函数:预测下一个词,另一个是每一个句子序列有一个标号
接下来要考虑的是如何把NLP里面很不一样的子任务表示为上面的形式 ,这里举例了4个任务:分类、蕴含、相似、回答
为什么 GPT 选择了Transformer,而非 RNN ?
作者理解Transformer具备更多的结构化记忆信息,因为长程依赖,所以Transformer能理解更多的句子、段落等语义信息,
为什么 GPT 选择了Transformer的解码器,而非编码器?
因为解码器是带mask的,只能看到时刻i之前的信息,比较符合generative的优化目标范式,也就是standard language modeling objective
而为什么 Bert 选择了Transformer的编码器,而非解码器?
因为bert采用的是用两边的词去预测中间的词,与编码器形态比较接近:编码器能看到所有信息;GPT是单子接龙,而Bert是完形填空;所以二者的本质区别是目标函数的选取;而GPT选择了一个更难的任务,更大的任务(所以GPT得天花板更高),因为预测未来肯定要比完形填空难,所以GPT-1训练难度和效果都不如Bert;
GPT-2
GPT-2最大卖点是zero-shot
我们来对比看
- gpt-1 & bert :Pre-training & SFT;拓展到新任务时是有成本的
- gpt-2:不需要下游任务的标记信息,也不需要去训练模型:训练一个模型,任何地方都能用
gpt-1训练子任务的时候,有起始、分割、结束等特殊符号,现在既然想做zero-shot,就不能引入模型预训练时未见过的符号,这里给出的解决方案就是提示符:prompt (作者对promt的阐述是很多自然文本本身就有出现这些提示词,用这样的预料库进行训练,自然能得到预想的东西)
GPT-3
gpt-2新意性很高,有效性较低,所以gpt-3就是为了解决有效性
gpt-3模型参数很大:175 billion/接近2000亿,所以在子任务上,同样不做fine-tuning or gradient updates
子任务做微调的问题
需要有标号的数据集
微调效果好掩盖了预训练泛化性的问题,有可能微调的子任务只是和预训练信息重合度比较大
人类的学习方式,不需要大量的有监督的数据集去对子任务做学习
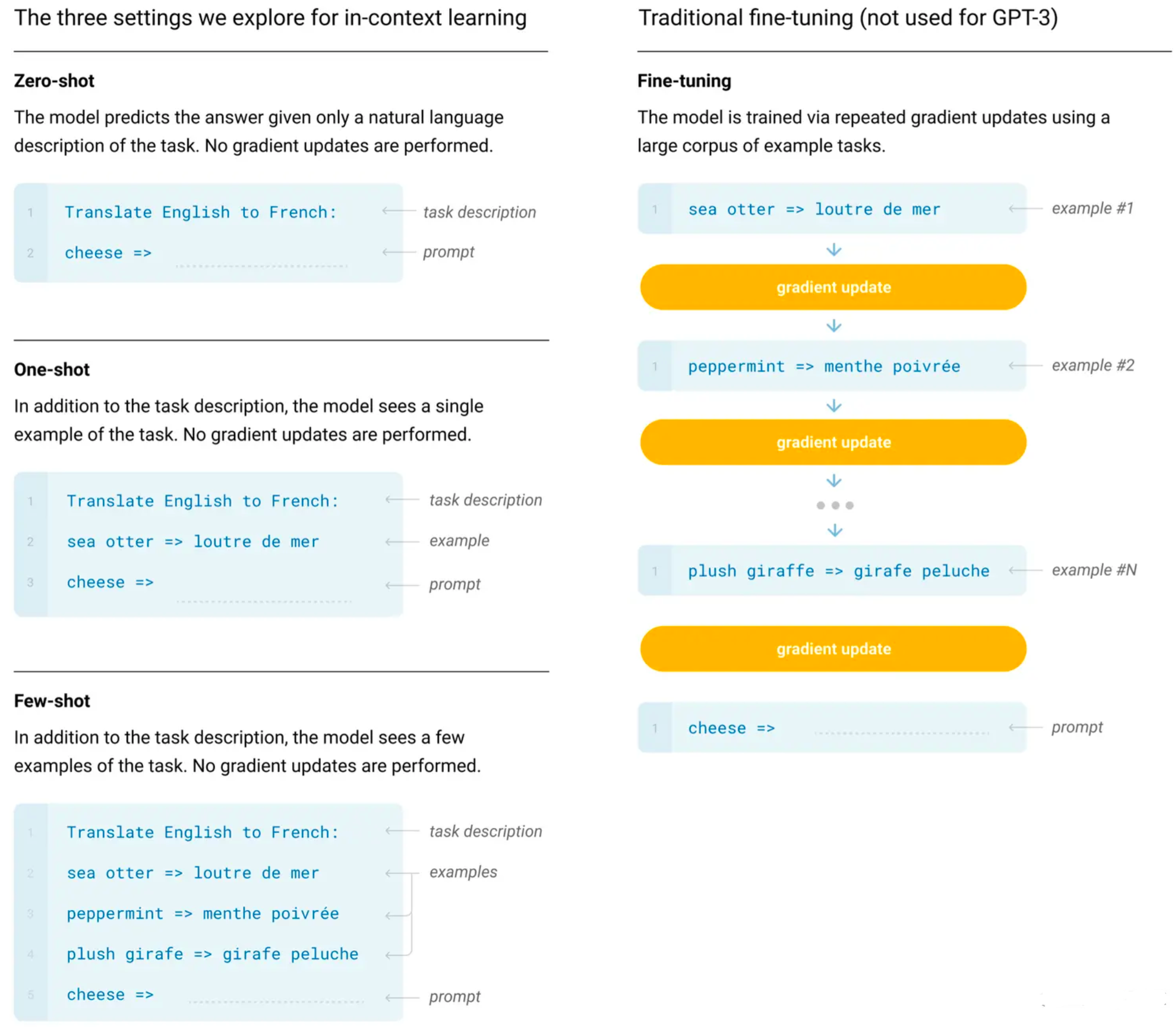
为了解决有效性,GPT-3提出了in-context learning
in-context learning
即Few-shot,虽然给到少量训练样本,但是不做gradient updates,即prompting vs finetuning
其对比如下
InstructGPT
暂时无法在飞书文档外展示此内容
InstructGPT最大的目的:align with user(存在对齐税),三个目标
- helpful
- harmless
- honest
InstructGPT参数只有1.3B,确到达了和GPT-3类似的效果,甚至略微好一些
transformer的本质就是对数据集做压缩,压缩进模型参数中,所以数据信噪比较好时,需要的模型参数也就是较少,所以需要平衡一下算力需求和人类标注的代价
GPT-3最大的问题:语言模型目标函数与人类的目标是没有对齐的
InstructGPT可以类比为经过了以下三个阶段的学习
- 开卷有益/ 无监督学习
也就是预训练,训练文本非常大
本质是无监督学习
开卷有益阶段:让ChatGPT对「海量互联网文本」做单字接龙,以扩充模型的词汇量、语言知识、世界的信息与知识。使ChatGPT从“哑巴鹦鹉”变成“脑容量超级大的懂王鹦鹉”。
- 模板规范/ 监督学习
即优质对话范例,同时支持各类任务(符合应答模式)
本质是监督学习
也就是Supervised fine-tuning (SFT)
模板规范阶段:让ChatGPT对「优质对话范例」做单字接龙,以规范回答的对话模式和对话内容。使ChatGPT变成“懂规矩的博学鹦鹉”。
- 创意 引导/强化学习
Reward model,自由回答,给以奖励,也就是创意引导,超越模板
本质是强化学习
也就是Reward Model & PPO
创意引导阶段:让ChatGPT根据「人类对它生成答案的好坏评分」来调节模型,以引导它生成人类认可的创意回答。使ChatGPT变成“既懂规矩又会试探的博学鹦鹉”。
其整个过程如下所示:

其三阶段学习如下所示:
- SFT
- RM
- PPO
SFT
InstructGPT虽然又用回了微调,但是之前是有区别的,之前微调是用于子任务,而InstructGPT的微调和之前做预训练是没什么区别的
这一阶段,也称之为指令微调,或者监督微调
RM
RLHF
SFT不可能涵盖所有方面,而RLHF采用的标注成本更低:
让SFT针对prompt生成多个答案response(=9),然后人类排序,训练出RM,RM训练好保持不变
最后一步便是利用RM去继续微调SFT,即用RM对不断更新的SFT产生的(prompt, response)去打一个reward score
也就是说在SFT阶段,如果我们能够生成足够多的人工答案,那其实不要后面两个阶段也是可以的,但是生成式的标注毕竟成本较高
所以加入RM的好处是数据标注的成本大大降低
数据标注
用户先标注一些数据,然后训练一个模型出来,这个模型不一定要特别的好,告诉大家是一个内测版模型,让大家玩一玩,大家玩了之后收集更多数据(用户玩的时候产生prompt,然后labeler标注工给出答案response),进一步提升模型质量
其中,labeler是需要做一个筛选和测试,并且与标注者签订了合同工,而非临时标准者
RM
这里不同于图中的4个序;实际中是标注的9个序,然后产生36个pair,采用pair-wise ranking loss(9个序的标注成本并不会比4个序高太多,但是生成的pair更多)
PPO
policy就是model,加了KL散度,细节这里不做展开
总结
OpenAI 不太可能故意牺牲了上下文学习的能力换取零样本能力 —— 上下文学习能力的降低更多是指令学习的一个副作用,OpenAI 管这叫对齐税
生成中立、客观的能力、安全和翔实的答案来自与人类的对齐。具体来说:
如果是监督学习版,得到的模型是text-davinci-002
如果是强化学习版 (RLHF) ,得到的模型是text-davinci-003(text-davinci-003恢复了 text-davinci-002 所牺牲的上下文学习能力, 提高零样本的能力)
无论是有监督还是 RLHF ,模型在很多任务的性能都无法超过 code-davinci-002 ,这种因为对齐而造成性能衰退的现象叫做对齐税。
对话能力也来自于 RLHF(ChatGPT),具体来说它牺牲了上下文学习的能力,来换取:
建模对话历史
增加对话信息量
拒绝模型知识范围之外的问题
GPT-4
关于GPT-4,我们主要介绍其新引入的多模态能力:Multi-Modal
Vision Transformer
ViT的诞生,打破了cv和nlp在模型上的壁垒
NLP的通用做法:
- Self-supervised pre-training on large text corpus(比如GPT使用language modeling做自监督)
- Fine-tuning on a smaller task-specific dateset
Transformer的优势:计算有效性与可扩展性;并且随着模型与数据集的增长,依然没有出现性能饱和
Transformer用于视觉问题的难点
把像素铺平:序列长度N=224224=50176,负责度太高;像素更高时就更高了
ViT如何解决?
不按照像素铺平,而是按照patch铺平;224224像素的图片分割为patch大小1616,总有1414的patch
铺平之后长度就是14*14=196
那么一个patch类比于NLP中的一个token(单词)
结构上就是Transformer的encoder
masked patch prediction
大规模预训练,就可以媲美state-of-art CNNs
不过,Transformer缺少CNN特有的归纳偏置(inductive biases),比如
- locality局部性(越近的东西相关性越强)
- 平移等变性
但是在足够的大数据上,ViT能够打败inductive biases
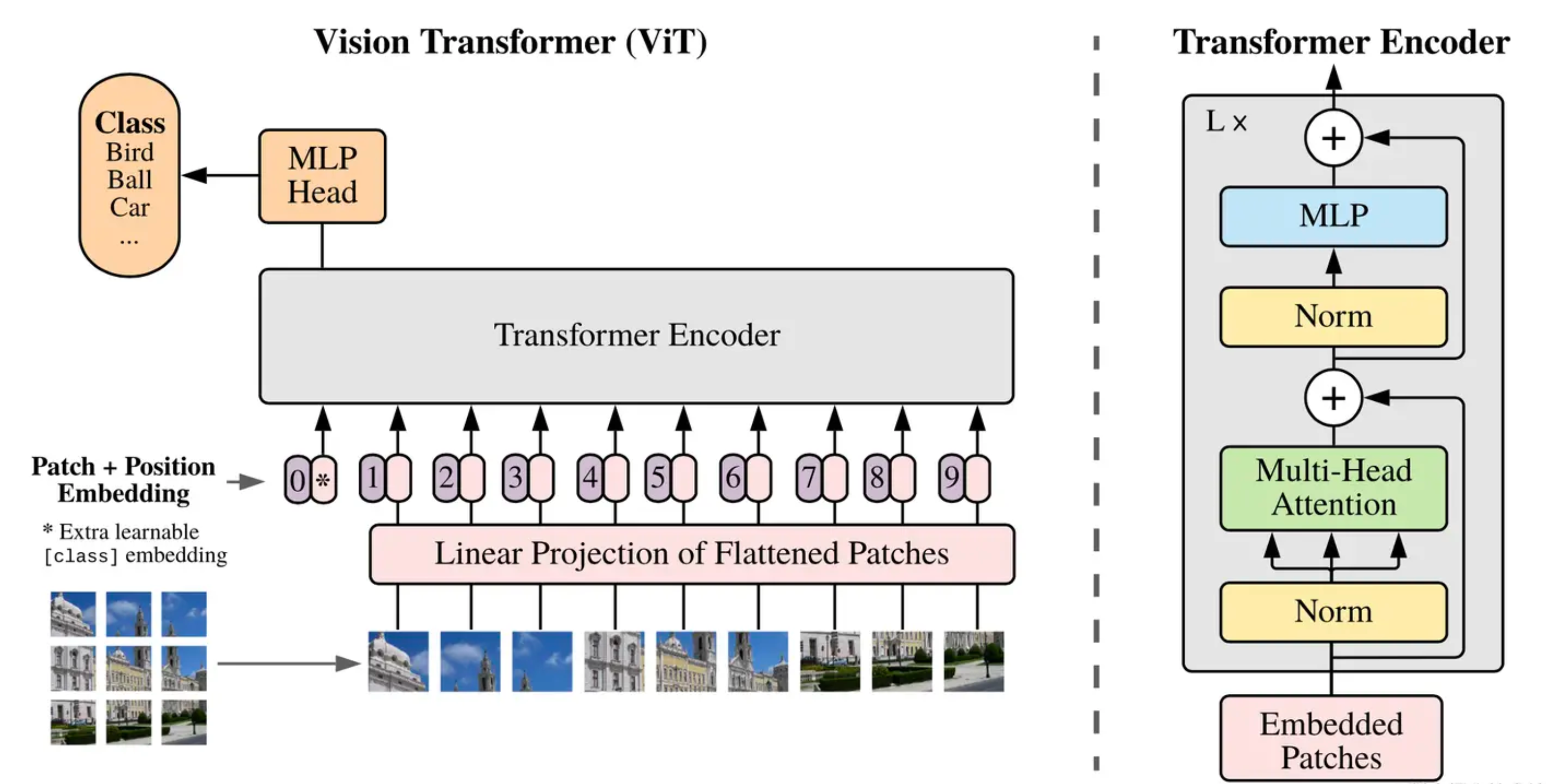
假设图片 :2242243
我们把他做成1414的patch,每个patch包含信息量 16163=768
Linear projection就是全链接层,其大小是768768,然后得到196个token,每个patch token维度是768,大小:(196768),再加上cls embedding就是(197768)
Transformer encoder最终输出的依然是(197*768)
为了能够分类,这里是借鉴了bert的class token,这个cls token经过Transformer encoder处理之后,对应的embedding就是整个图片的embedding表征了,后续加一个MLP的分类头即可
为什么不借鉴CNN的做法,用一个GAP(global average pooling)做(196768)做池化操作得到一个(1768)
而是非得要弄一个(1*768)的cls token?
作者实验过两种,效果相当,最终为了尽可能的与Transformer结构保持一致,采用了cls token
Position embedding
文章采用的1-D编码,作者也尝试过2-D编码,以及relative Position embedding
ViT整体没有用过多的归纳偏置;即它的全局建模能力比较强;所以中小数据集不如cnn是可以理解的
ViT的一个局限是,因为Position embedding的缘故,想要对更大的图片做微调,可能出现位置信息失效的情况
性能对比
vit在中小数据集上效果远不如resnet,原因就是vit没有利用先验知识,没有做归纳偏置;当用大数据集,比如JFT-300M的时候,vit就全面超过resnet了
Multi-Modal
多模态现在也采取一种预训练+微调的方式
难点:如何把图像的像素变成带有语义性的、离散型的特征
Visual embedding如何做?
-
Region Feature
-
Grid Feature(依赖于预训练好的CNN)
-
Patch Projection
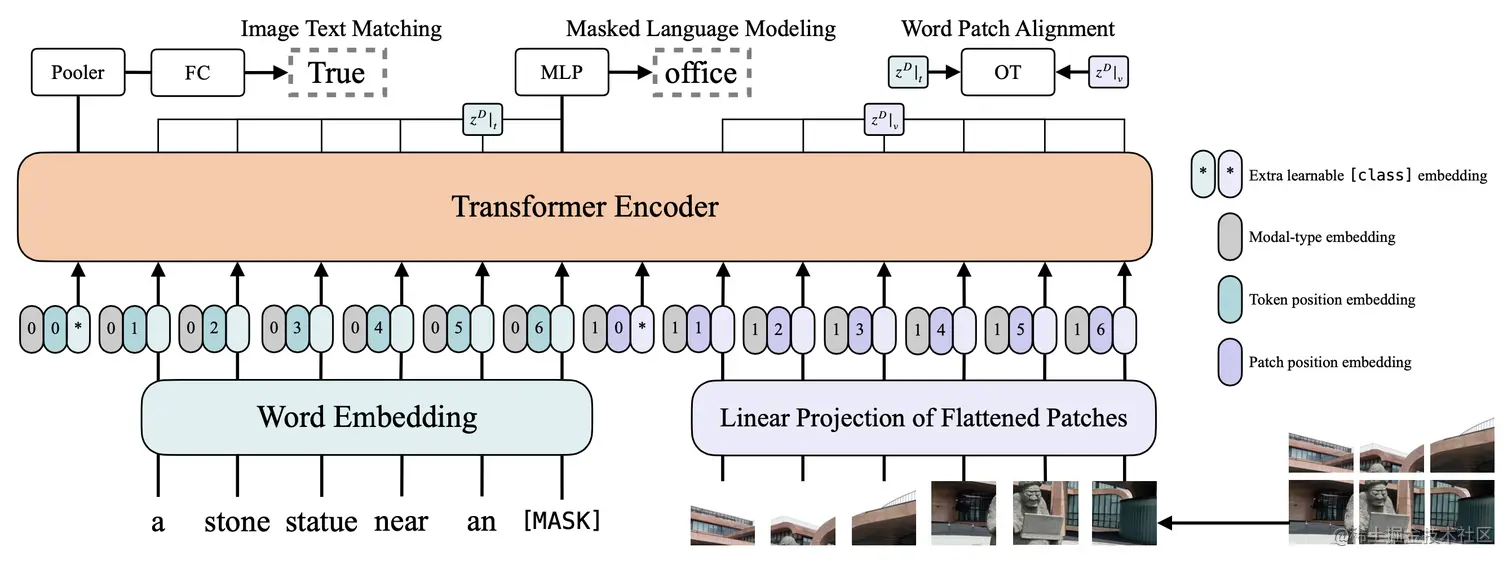
多模态结构如下图所示:
Masked Language&Patch Modeling
Emergent Abilities ★
定义
Emergence is when quantitative changes in a system result in qualitative changes in behavior.
复杂系统学科里已经对涌现现象做过很久的相关研究。那么,什么是“涌现现象”?当一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象,就可以称之为“涌现现象”。
在日常生活中也有一些涌现现象,比如雪花的形成:雪花的构成是水分子,水分子很小,但是大量的水分子如果在外界温度条件变化的前提下相互作用,在宏观层面就会形成一个很规律、很对称、很美丽的雪花。
这种涌现能力,有时候也被称之为复杂推理能力,在 GPT-4 发布博客中,作者写道:“在一次随意的谈话中,GPT-3.5 和 GPT-4 之间的区别可能是微妙的。当任务的复杂程度达到足够的阈值时,差异就会显现出来。” 这意味着复杂任务很可能是大型和小型语言模型的关键差异因素。
GPT中主要表现了两种涌现能力:
- In-Context Learning
- Chain-of-Thought
In-Context Learning
In Context Learning也叫Few-Shot Prompt,其具体含义是:
in-context learning, where an LM “learns” to do a task simply by conditioning on a prompt containing input-output pairs
即用户给出几个例子,大模型不需要调整模型参数,就能够处理好任务
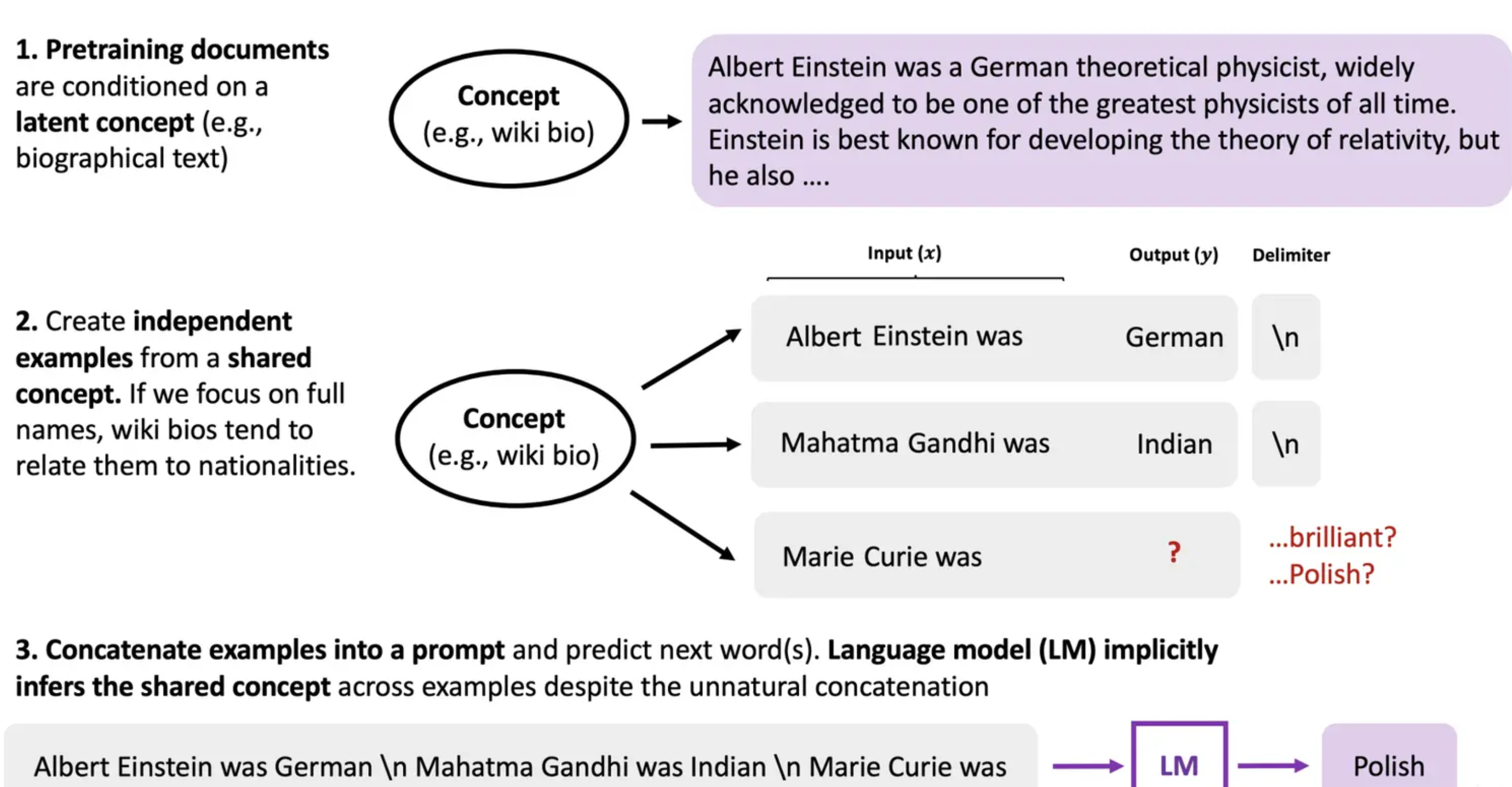
那么In Context Learning是如何起作用的呢?
- Xie et. al. 2021. An Explanation of In-context Learning as Implicit Bayesian Inference
有过相关的揭示:语言模型在提示中的示例之间推断出一个潜在概念,并进入相应的任务模式
Chain-of-Thought
CoT 本质上也算是一种特殊的 few shot prompt,就是说对于某个复杂的比如推理问题,用户把一步一步的推导过程写出来,并提供给大语言模型(如下图蓝色文字内容所示),这样大语言模型就能做一些相对复杂的推理任务
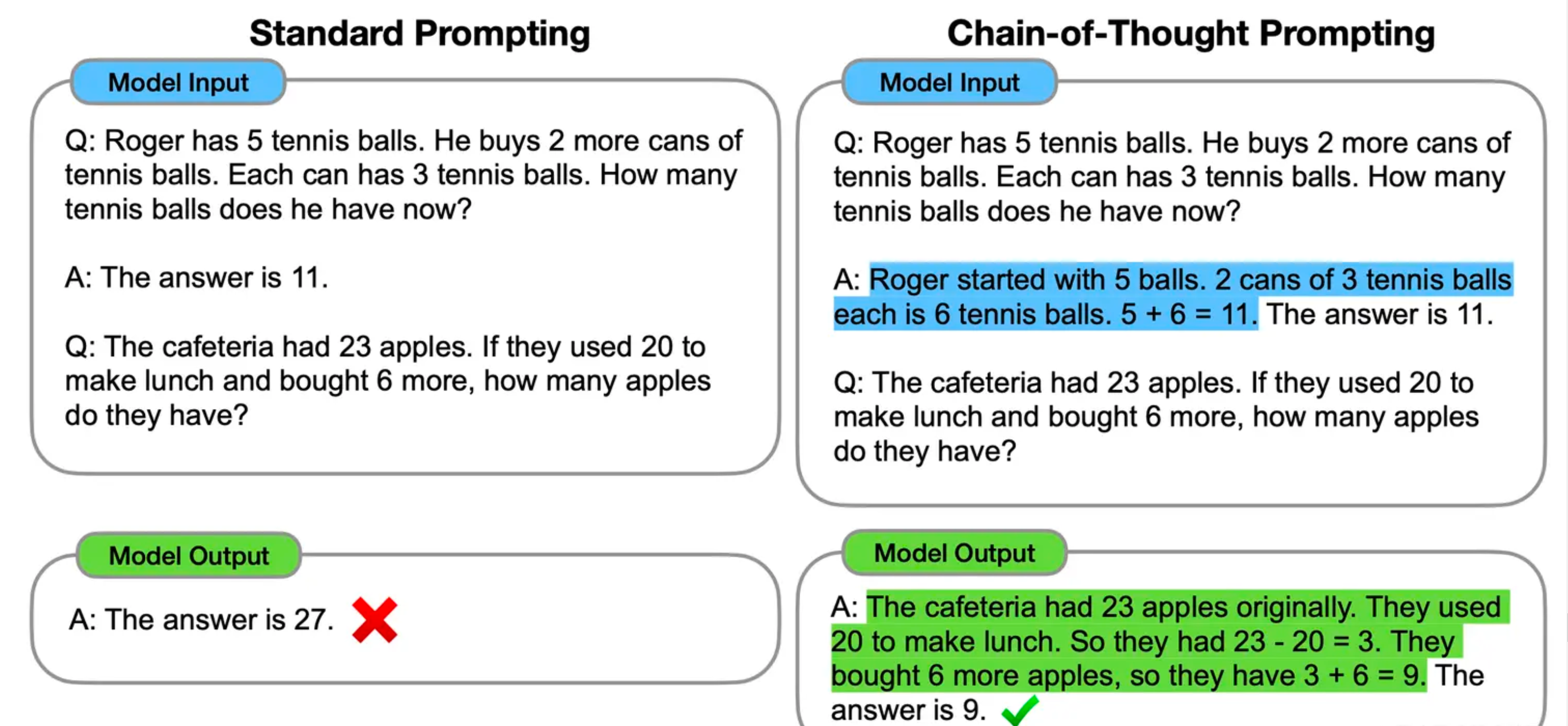
那么 CoT 如何而来的呢?
CoT本身可以通过特定格式的Data做监督训练而得,但是在GPT-3.5中,涌现能力更像是一个“意外之喜”,初步推测这种能力来自于Codex:
- 代码注释是自然存在的链式思维数据
- 面向过程编程类似于逐步解决任务。这适用于简单和中等复杂度的任务
- 面向对象编程类似于将任务分解为较小的任务,然后分别解决它们。这适用于较高复杂度的任务。
初代GPT-3模型通过预训练获得生成能力、世界知识和in-context learning。然后通过instruction tuning的模型分支获得了遵循指令和能泛化到没有见过的任务的能力。经过代码训练的分支模型则获得了代码理解的能力,作为代码训练的副产品,模型同时潜在地获得了复杂推理的能力(CoT)。结合这两个分支,code-davinci-002似乎是具有所有强大能力的最强GPT-3.5模型。接下来通过有监督的instruction tuning和 RLHF通过牺牲模型能力换取与人类对齐,即对齐税。RLHF 使模型能够生成更翔实和公正的答案,同时拒绝其知识范围之外的问题。即:
CoT 的行为逻辑
-Wang et. al. 2022. Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
文中揭示:即使提示中的推理错误,模型仍然可以正确推理,但提示的相关性和推理步骤的顺序更为重要 —— 这再次表明,模型更受提示的格式影响,而不是提示的意义
难点
Data
数据永远是重要的一环,在InstructGPT中如果有足够的SFT数据,是不需要过重的RM
以GPT-3为例,它采用了GPT-2中丢弃的common crawl,采用了三个步骤做数据清洗:
过滤,正例是gpt-2从reddit上爬下来的数据,负例是来自于common crawl训练一个二分类,然后对common crawl做预测,如果比较偏向于正例,就保留,否则丢弃
去重,如果一篇文章与另一篇相似度较高的话,就去掉,采用lsh算法
补充,加了一些已知的高质量数据集,比如bert等等
Predictable Scaling
对于大模型,如果是跑完(可能得需要一两个月,即使有钱,时间也等不起),才知道结果好不好,才知道参数好不好,才知道这个想法是否work,这个花销就太大了,一般我们需要在较小的模型或者较小的数据集上做消融实验,看哪个work了,再去大模型上去做实验,但是在LLM有一个问题:
- 模型扩展太大,往往导致我们在小模型上做的实验能work,但是换到大模型就work
- 并且大模型特有的涌现能力,在小模型那边也观测不到
那么我们就需要一套系统,能够准确的预测,在小规模的计算成本下的模型,能够准确的预估如果把这个计算成本扩大,模型最终的性能会怎么样;这一点就是openai厉害的地方:炼丹的技术炉火纯青;
如果做这样的类比的话:
- 草药 - 数据
- 丹炉 - 算力
- 丹方 - 模型
在openai这项能力被称之为predictable scaling(可预测的扩展性):build a deep learning stack that scales predictably.
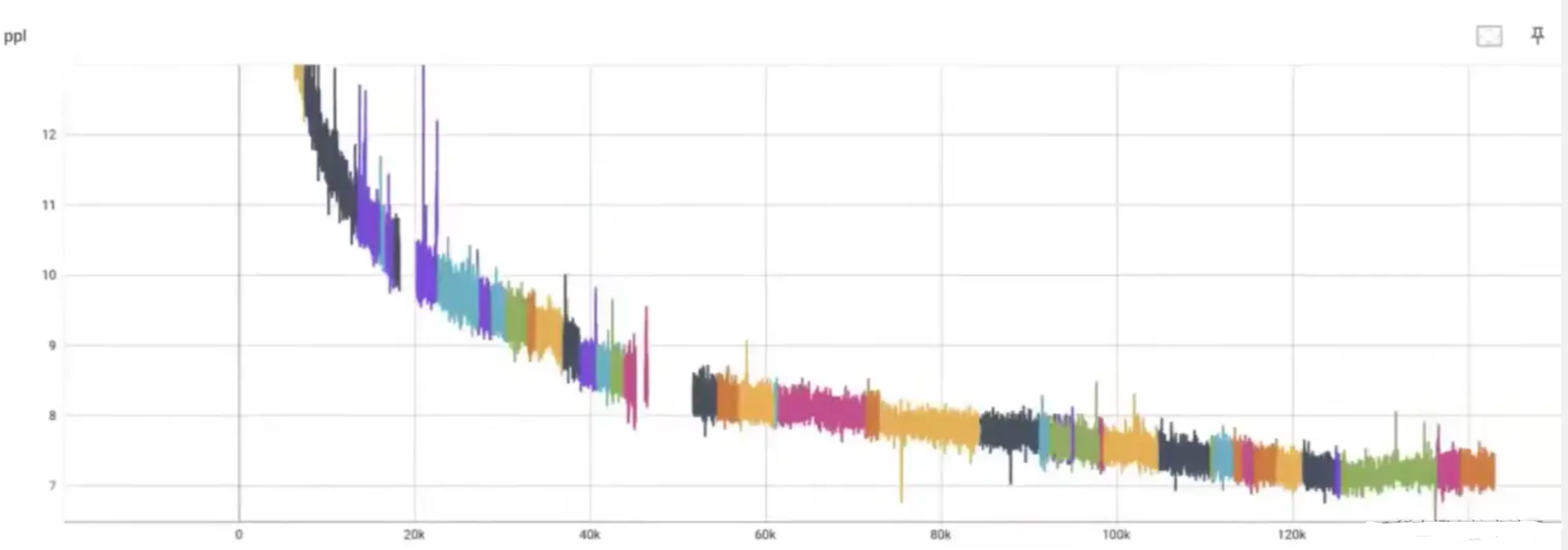
这里是OPT-170B的一个例子,训练过程中因为各种各样的因素,出现了机器崩了,网络断了,loss跑飞了等等各种问题;中间断了50多次,有50多次的重启;
从AIGC到AIGA
什么是AIGA?
决策是指希望跟一个环境或者其他智能体有一个交互的过程,这个交互的过程中,有一个核心就是你要做出一个决策或者动作,并在环境中得到一些执行,然后还可以从环境中得到一些反馈,重复多步之后直到完成一个特定的任务
自然语言/多模态预训练大模型为强化学习/交互决策提供了泛化的可能性与基础
任务的演化:
-
认知型
-
生成式
-
决策式
ChatGPT这类大语言模型不仅可以生成文本/图片信息,同时给它一些自然语言的输入,还可以翻译成形式化的语言(比如程序的一些接口), 然后形式化语言翻译成一个可执行的动作/指令,这些指令与动作与现实环境做交互,并且给到强化决策or决策,提供一个比较好的泛化基础
即:自然语言输入 -> 形式化语言(第三方应用的 API 接口或者程序的接口) -> 可执行的动作/指令
所以针对标准环境场景,AIGA的一个范式:
以大语言模型为中心,配合API选择的决策,详细如下图所示:
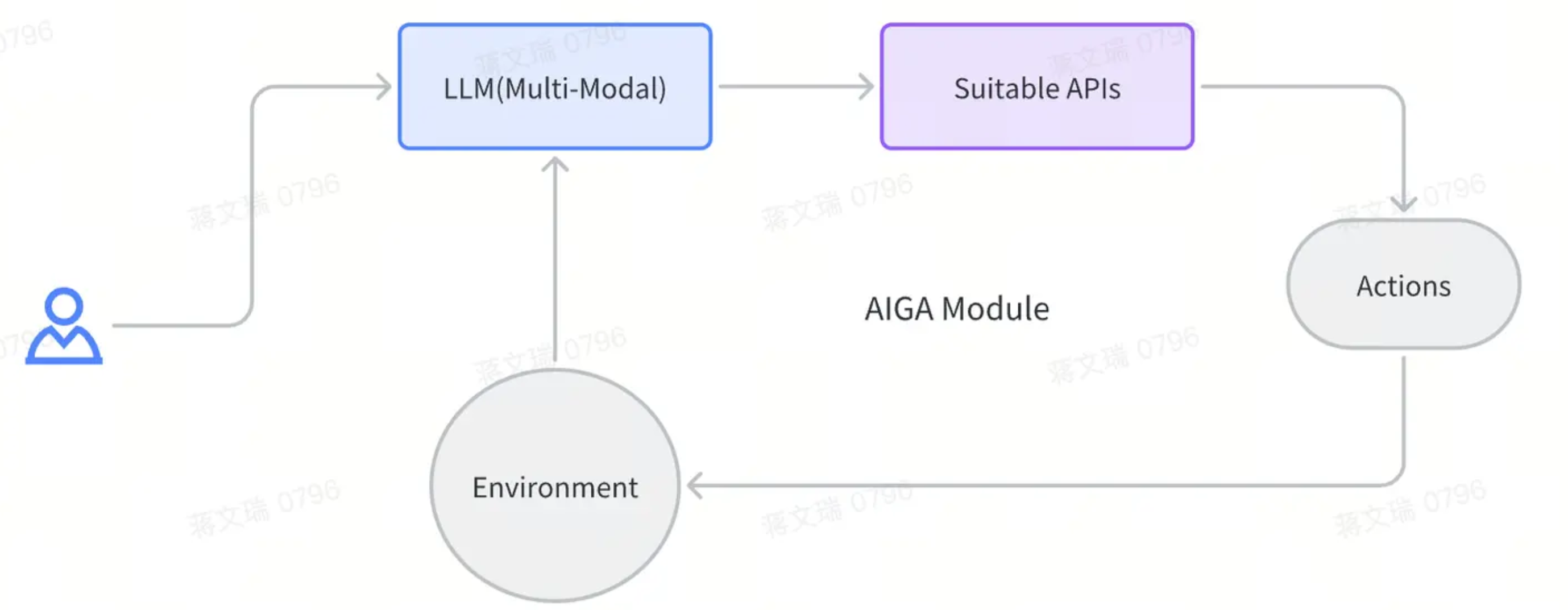
举例:
-
HuggingGPT(Jarvis):让ChatGPT控制AI模型
-
谷歌机器人团队利用语言模型控制机器人
- 论文《Grounded Decoding: Guiding Text Generation with Grounded Models for Robot Control》讨论了如何在具身智能体的设置中应用大型语言模型,以便利用语义知识解决复杂、长期的任务。作者指出,虽然大型语言模型有能力学习和利用互联网规模的知识,但将其应用于机器人等具身智能体的设置是具有挑战性的,因为这些实体缺乏与物理世界的经验,无法解析非语言观察结果,并且不了解机器人可能需要的奖励或安全约束。为了克服这些问题,作者提出了一种方法,即构建一k个既符合语言模型又符合环境的可实现的动作序列,从而利用两个模型的知识来解决复杂、长时段的具身任务。该论文的实验结果表明,引导解码策略能够有效地解决具身智能体的设置中的任务。该论文的详细信息可在该项目的网站上找到。
而对于非标准备场景,AIGA的一个范式:
以决策大模型为中心的泛化决策控制
举例:
-
Gato(论文精读)
-
Ada

