
- 1高并发下的redis加锁的几种实现方式_针对于并发怎么设置redis锁
- 2java动作神作_画质高、剧情好、操作爽,这6款单机游戏堪称动作类游戏神作!...
- 3论文解读:使用带门控卷积进行生成式深层图像修复方法_结果表明,即使面对大量异常通道,deepfillv2模型仍然可以很好地修复图像的颜色和细
- 4学习Git小结--HEAD、master、branch和git常用命令_branch master
- 5nodejs 捕获 promise 未处理的 reject_process.on('unhandledrejection',function(err,promi
- 6Spring Boot的静态资源自动配置原理
- 7(原创)机器学习之矩阵论(三)
- 8一个正整数能被表示为几个连续素数和的方案C++,C_c++求连续质数和
- 9linux命令_ll | awk '{prinf $1}
- 10嵌入式 linux 蓝牙 C开发_linux 蓝牙设备端编程
ARM整形算力计算_arm算力值怎么换算
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
之前做人工智能使用RK3399的CPU去推理,发现效果不理想,现在基本上是采用NPU来推理了。我内心不禁萌生一个想法,ARM的CPU算力到底有多少,为什么推理方面干不过NPU,这里我借用经常使用的RK3399来对比下
一、RK3399规格?
RK3399是国产厂商瑞芯微设计的一款ARM产品,基于Cortex-A72+Cortex-A53的大小核架构设计,算是半国产产品吧,Cortex-A72数量2颗,主频1800Mhz;Cortex-A53数量4颗,主频1500Mhz。
二、开始计算
1.参考
我们需要参考官方给出的实际算力表,见下表
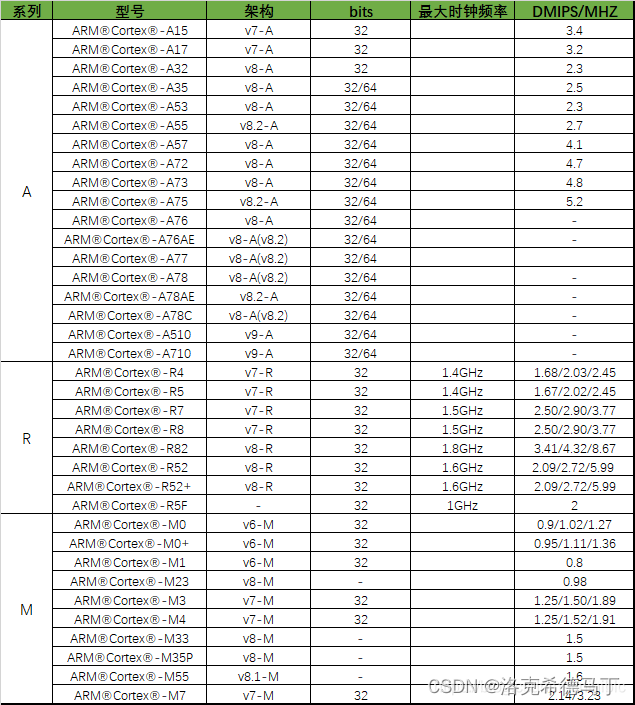
表里我们看出
Cortex-A72的DMIPS/MHZ是4.7,也就是每秒,每MHZ执行4.7百万个整数计算指令
Cortex-A53的DMIPS/MHZ是2.3,也就是每秒,没MHZ执行2.3百万个整数计算指令
有了这些数据,我们开始计算实际的整数算力。
2.计算
MOPS:megaOPS,每秒10^6次整数运算,相当于每秒一百万次整数运算
GOPS:gigaOPS,每秒10^9次整数运算,相当于每秒十亿次整数运算
TOPS:teraOPS,每秒10^12次整数运算,相当于每秒一万亿次整数运算
POPS:petaOPS,每秒10^15次整数运算,相当于每秒一千万亿次整数运算
EOPS:exaOPS,每秒10^18次整数运算,相当于每秒一百亿亿次整数运算
有了这些数据,我们就可以开始计算RK3399的算力了,这里我们抛弃其它的干扰,只计算官方给出的数据,结果可能有一定的偏差。
计算公式:频率(MHZ)x核心数xDMIPS/MHZ
Cortex-A72: 1800x2x4.7=16920 DMIPS
Cortex-A53: 1500x4x2.3=13800 DMIPS
合计:30720 DMIPS
这个算力在GOPS核TOPS中间,实际307.2GOPS或0.3072TOPS,看起来和动辄3TOPS的NPU比起来还是有差距的。
总结
1、市面上很多模型都是基于INT8的,精度和FLOAT肯定是差一些的,大多数人都是采用牺牲一些精度换取大量的性能提升,这个是目前边端设备上的主流做法。
2、没有测试GPU,RK3399这个GPU在嵌入式设备上还是蛮强的,但是实际上在推理场景发挥有限,至少我是没有获得过巨大的性能提升。
3、边端设备上推理还是采用NPU更划算,单纯依靠CPU还是不太现实,或者只能满足受限制的小场景。

