
- 1android释放res内存,android - 尝试在空对象引用上调用虚方法'android.content.res.AssetManager android.content.res.Resourc...
- 2逐步回归选取特征及GAM模型的使用==college数据集(统计学习导论)_college数据集回归分析
- 3thinkphp连接sqlserver 2008(同时支持windows和linux环境)_thinkphp6 链接sqlserver 2008
- 4java技术有哪些优点优势_java使用方法的优点有哪些
- 5计算机网络-第一章测试题及答案_计算机网络基础第一章基础试题
- 6信息安全意识-密码安全_常见的密码攻击安全事件频发
- 7前视声呐目标识别定位(三)-部署至机器人
- 8超详细VMware15、16虚拟机下载与安装_vmvare哪个版本好 csdn
- 9flstudio_win64_21.2.30.3842正式发布啦,支持 Cloud 在线采样和 AI 编曲_flstudio21.2
- 10QT中字符串的比较_qt 字符串比较
机器学习人工智能算法——支持向量机(Support Vector Machine, SVM)_人工智能负荷预测支持向量机法属于什么类型
赞
踩
首先,我们先来了解一下什么是支持向量机(Support Vector Machine, SVM),我们使用SVM既可以解决分类问题,也可以解决回归问题,本篇文章我们主要讲SVM在分类问题中的应用,在后续文章分享中会讲解如何将SVM用于回归问题。

大家可以看上图,是一个二维特征平面,上面的数据点分成了两类,分别用红色的点和蓝色的点表示,我们所说的分类问题,就是要找到一个决策边界,如下图中的所示,决策边界的上方是红色的点,下方是蓝色的点。

但有些数据也会存在一个问题,那就是决策边界不唯一,对于这种决策边界不唯一的问题,有一个术语是“不适定问题”。
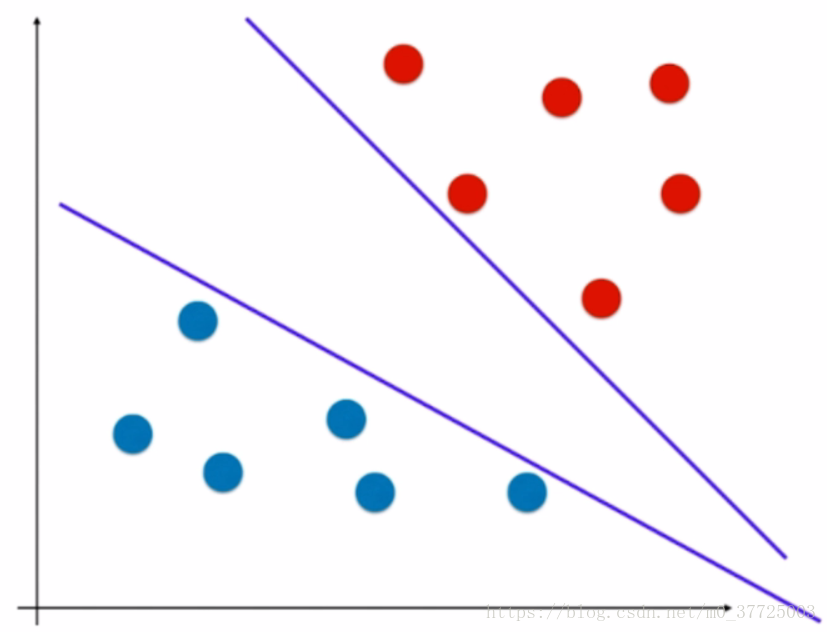
我们可以回忆一下之前讲过的逻辑回归算法是如何解决这个不适定的问题的。逻辑回归解决的思路是定义了一个概率函数,也就是我们之前讲过的sigmoid函数,根据这个概率函数进行建模,形成了一个损失函数,我们最小化这个损失函数,从而求出一条决策边界,这就是逻辑回归解决问题的思路,在这里的损失函数是完全由我们的训练数据集所决定的,SVM解决问题的思路稍微有一些不同。
对于机器学习有一个非常重要的能力,也就是泛化能力,换句话说,当我们求出了这个决策边界后,这个决策边界对于没有看见的样本,它还是不是一个好的决策边界?它能不能得到那些未知数据的分类结果呢?对未知的数据进行预测、判断和分类是机器学习算法真正的目的。那怎样找出一条泛化能力好的决策边界呢?
我们希望我们找出的决策边界离红色的点和蓝色的点都越远越好,也就是说,能够很好地区分两个类别,所以我们就得到了这样的决策边界。
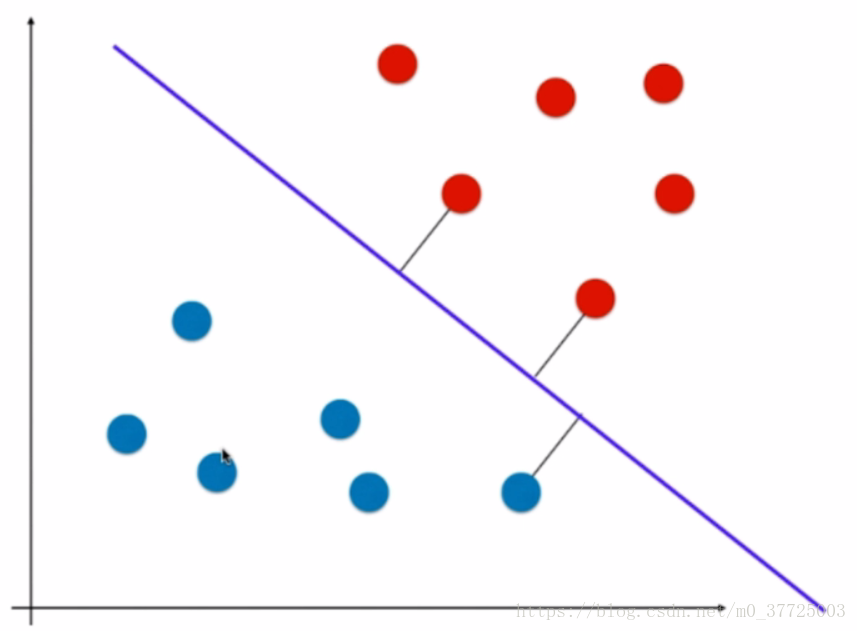
SVM没有把增强泛化能力冀望在数据的预处理阶段,或对模型正则化的方式,而是把对泛化能力的考量放在了算法内部,也就是说,我们要找到一个决策边界,这个决策边界离我们的分类数据都要尽可能的远,我们直观来看,这样的决策边界泛化能力就是好的,其实,这不仅仅是我们直观上的感受,它的背后也是有数学的理论依据的,有兴趣的宝宝们可以下来交流讨论。也就是因为这个原因,SVM在统计学中也是非常重要的一种方法,它的背后有极强的统计理论的支撑,所以宝宝们都知道,SVM在我们机器学习领域是非常常用也非常重要的一种方法。
回到算法本身,那让决策边界尽可能的离两类数据点更远是什么意思呢?其实就是让距离决策边界最近的点离决策边界的距离尽可能的远,那我们可以看到,这些距离决策边界最近的点有定义出了两条直线,这两条直线和我们定义的SVM的决策边界是平行的,这两条直线定义出了一个区域,在这个区域内不再有任何数据点,而我们SVM最终得到的决策边界其实就是两条直接中间的那条线。

到目前,我们解决了线性可分(Hard Margin SVM)的问题,但真实的情况是我们的很多数据是线性不可分的,在这种情况下我们可以对我们的SVM做出改进得到(Soft Margin SVM)这样的算法。
Hard Margin SVM
我们接下来看看用数学语言来表达SVM要最大化margin是怎样实现的。我们从上一个图可以看出,margin=2d,那最大化margin,就是要最大化d,首先我们先来回忆一下解析几何中,如何计算点到直线的距离

根据我们之前的定义可以知道,两类中最近的点里决策边界的距离都要大于等于d,我们把一类数据看做1,一类数据看做-1,于是可以得到以下公式
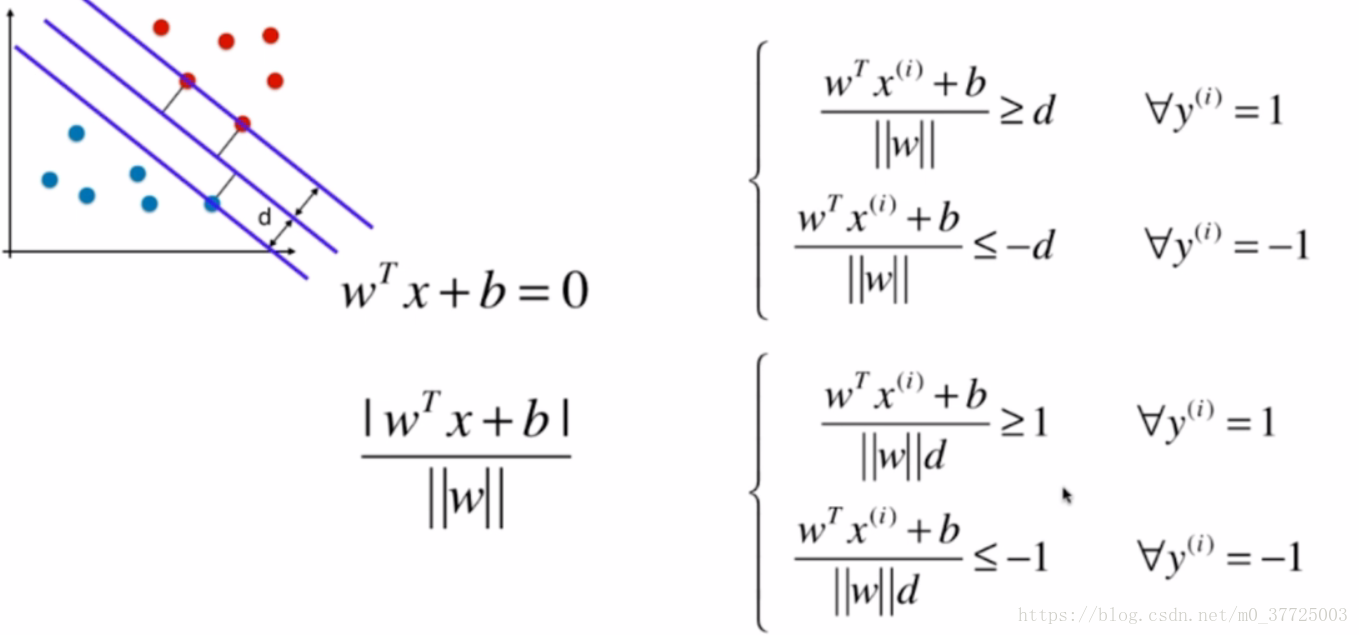
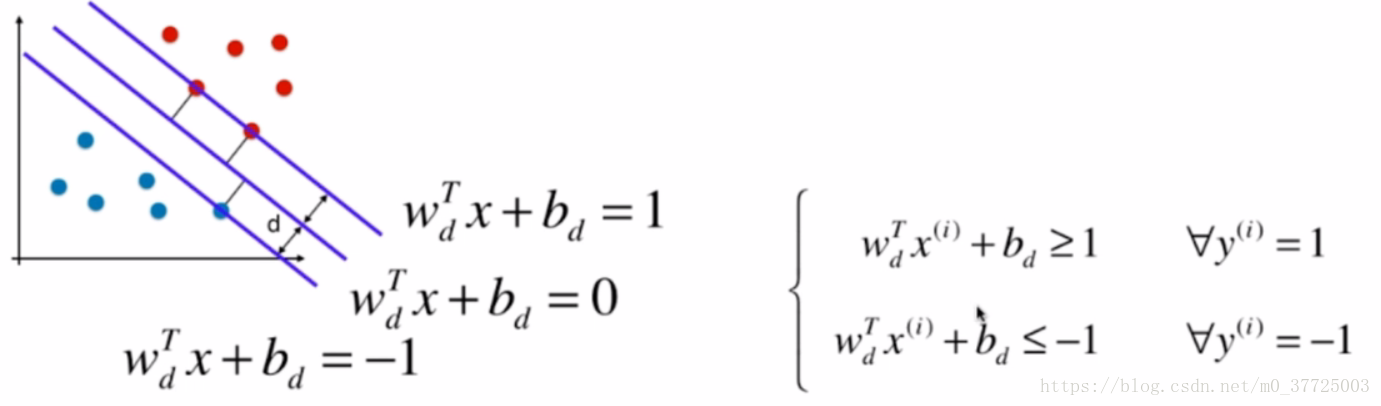
简化后
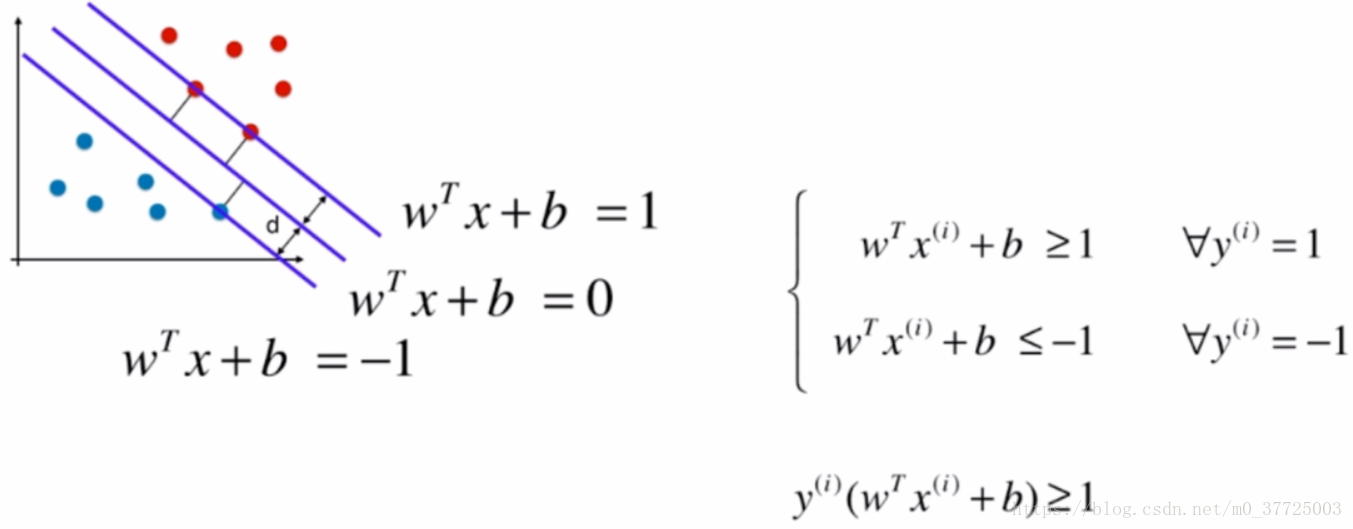
那怎样最大化d呢?

问题最终被简化为优化以下这个有条件的目标函数

Soft Margin和SVM的正则化
在真实情况下,大多数的数据都是线性不可分的,这时我们需要SVM有一定的容错能力,也就是Soft Margin,那Soft Margin具体是怎样实现的呢?其实就是把我们Hard Margin里面的条件宽松化

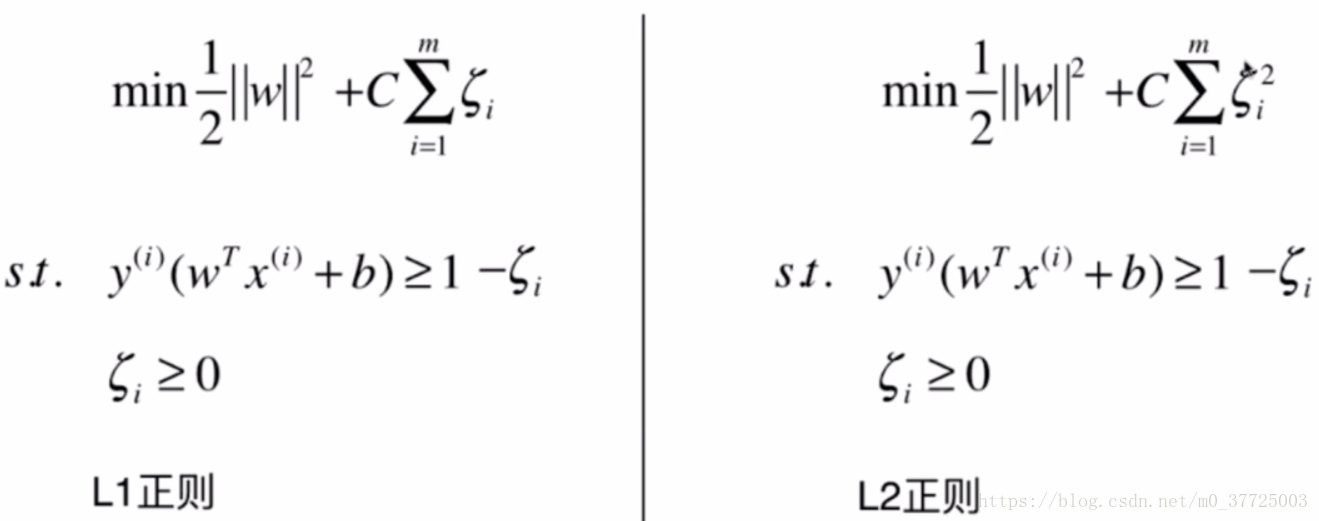
到这里,我们就已经了解了线性数据分类的SVM理论部分。

