
- 1ChatGPT和文心一言哪个更好用?一道题告诉你答案!_文心一言和chatgpt4哪个好
- 2pandas读取nlp_chinese_corpus里面的json类型的数据,一行一个字典的数据_json文件怎么一行一个字典
- 3AIGC专栏1——Pytorch搭建DDPM实现图片生成_diffusion扩散模型学习1——pytorch搭建ddpm实现图片生成
- 4加载bert-base-uncased预训练模型
- 5AI对话软件哪个好?首选这3款堪称神器的AI工具!
- 6chatGPT对SAP各模块顾问需要掌握的技术分析,看看chatGPT对SAP顾问有哪些建议_chat gpt对于sap等系统有啥影响
- 7校园网绕过原理+云免软件使用+GIWIFI普通法(顶替法)理论通用所有校园网_绕过校园网
- 8Chronos: 将时间序列作为一种语言进行学习
- 9OpenHarmony实战:拖拽动画的技术实现
- 10百川大模型AI对话实战——Python开发一个对话机器人_python使用百川大模型示例
opencv-python学习笔记(十一):HOG+SVM进行行人检测全过程_svm+hog+滑窗检测
赞
踩
引言
本次是接着python-opencv学习笔记(七):滑动窗口与图像金字塔 一起在实验楼所做实验,为啥中间隔了四篇才接着发出来,主因是我发文比较随意(懒),当时这部分并没有总结完,至少我感觉我看的相关资料还不够多,整体理解不深,另外就是项目需求,在做很多其它的东西,图像能见度就是当时一个指标,搞了几天,最后看起来效果一般,目前没有上线只是自己测试反馈不多,所以就接着做其它适配任务去了,现在这篇是算结束吧,赶紧总结完,复习去了。
实验流程
- 使用图像金字塔将图片按一定缩放比例生成不同尺寸图片(下图序号 1 所示)。
- 使用滑动窗口在每张不同尺寸的图片上从左至右、从上向下滑动(下图序号 2 所示)。
- 将滑动窗口滑过的每个区域使用方向梯度直方图进行特征描述,获得 HOG 特征(下图序号 3 所示)。
- 将获取到的 HOG 特征使用机器学习分类器(支持向量机)进行分类(下图序号 4 所示)。
- 最后在图片中使用矩形框标记出被分类器认为是人的类别(下图序号 5 所示)。

关于图像金字塔与窗口滑动,已经在第七篇中提到,本篇总结的是后面三步。
HOG 方向梯度直方图
下图中左边的图片是一只猫,我们不仅可以看出猫身体上的特征、颜色、纹理,而且还能看到背景。右边的图片是使用 HOG 来表示的图片,除了可以看到图中能看出猫的外形,其他的细节包括背景几乎都被去除了,故右边的图片是左边图片的一种简化表示形式。HOG 可以用来表示物体的形状、外形特征,将这些特征输入分类器就可以实现目标的分类。

在传统的算法中,使用 HOG 描述图片,可以保留有用信息,剔除无用的信息,这样不仅减少计算量,还使得分类器的效果更好。HOG 可以分为以下几个步骤:预先归一化、计算水平和垂直方向梯度、计算梯度直方图、区域(Blocks)归一化。
预先归一化(Normalization)
在计算梯度前可对图片归一化(Normalization)处理,归一化的目的是使所有的数值落入到统一的范围内,从而使算法能有更好的表现。在 HOG 的原论文中提到使用伽马矫正的方法处理输入图片,伽马矫正可以增加图像的对比度。但是在很多情况下,伽马矫正对提升算法效果不明显,我们可以跳过图片预先归一化,直接计算图片梯度。根据一文讲解方向梯度直方图(hog),可以知道伽玛校正的函数为:
f
(
x
)
=
x
γ
f(x)=x^{\gamma}
f(x)=xγ
即输出图像是输入图像的幂函数,指数为 γ {\gamma} γ 。代码为:
import cv2
import numpy as np
img = cv2.imread('gamma.jpg', 0)
img2 = np.power(img/float(np.max(img)), 1.5)
- 1
- 2
- 3
- 4
自我感觉效果基本上就是向黑白靠拢,这种预处理确实意义不大。
计算梯度
图像的梯度计算是使用卷积核对图像进行卷积操作,例如我们可以使用矩阵 [[-1, 0, 1]] 和 [[-1], [0], [1]] 分别与图像上的每个像素进行运算来获得水平和垂直方向上的梯度。
G
x
=
I
×
W
x
G
y
=
I
×
W
y
Gx=I×WxGy=I×Wy
然后再计算x和y方向梯度的合梯度,包括幅值 G G G和方向 θ \theta θ:
g
=
g
x
2
+
g
y
2
θ
=
arctan
g
y
g
x
g=√g2x+g2yθ=arctangygx
上述的代码可以看Normalization中的链接,这里就不再引用,演示效果为:
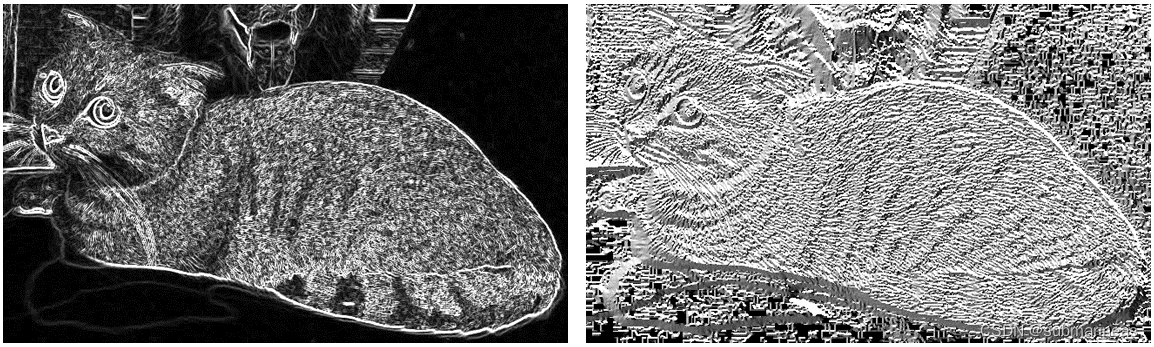
上面左图是合并水平、垂直方向上的梯度获得的梯度幅值,可以看到相较于水平、垂直方向上的图片,左图中猫的轮廓更清晰明显。右图表示图片中的梯度方向。代码很简单,就是利用两个sobel算子,得到水平与垂直方向的梯度,然后利用cv2.cartToPolar,输入参数为 G x G_{x} Gx 和 G y G_{y} Gy,输出为向量的大小和角度值,即上面公式所得,具体的可以看如下链接:
方向梯度直方图
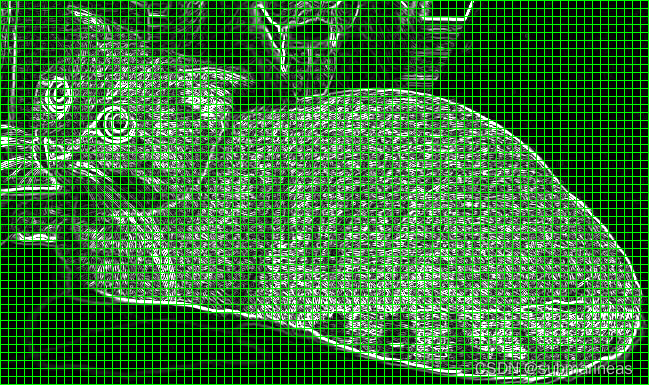
现在我们已经有了梯度幅值 G G G 和梯度方向 θ \theta θ,接下来我们就可以计算方向梯度直方图了。在计算方向梯度直方图之前,我们需要将图片分成若干个小方格(Cells),为避免歧义下文皆书写为 Cell 或 Cells 。例如,下图是一张宽高为 649 × 385 649\times 385 649×385 的图片,我们将其平均分割成若干个 Cells,每个 Cell 内包含 8 × 8 8\times 8 8×8 个像素,所以图片的高被分为 ⌊ 385 ÷ 8 ⌋ = 48 \lfloor 385\div8 \rfloor = 48 ⌊385÷8⌋=48 份,图片的宽被分为 ⌊ 649 ÷ 8 ⌋ = 81 \lfloor 649\div8 \rfloor = 81 ⌊649÷8⌋=81 份( ⌊ ⌋ \lfloor\quad\rfloor ⌊⌋ 表示向下取整),故整张图片有 48 × 81 48\times 81 48×81 个 Cells。
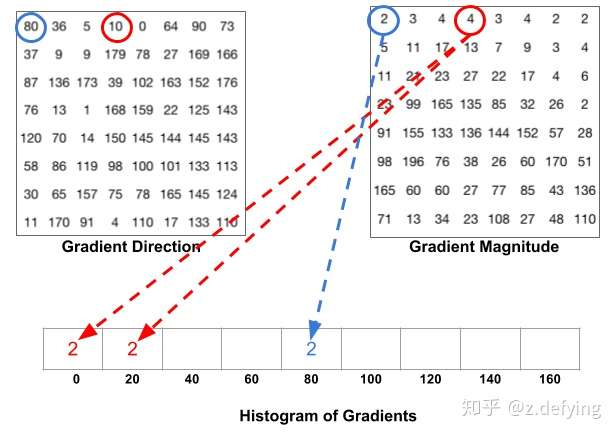
至此我们已经将图片分成许多 Cells,对于每一个 Cell,一般梯度方向范围可分为 0 到 180 度(无符号)和 0 到 360 度(有符号),通常使用 0 到 180 度的范围。然后将 0 到 180 度按每 20 度分为9个区间,此即为梯度直方图,对应于角度0、20、40、60… 160,下面引出上述参考贴对应规则的图片:
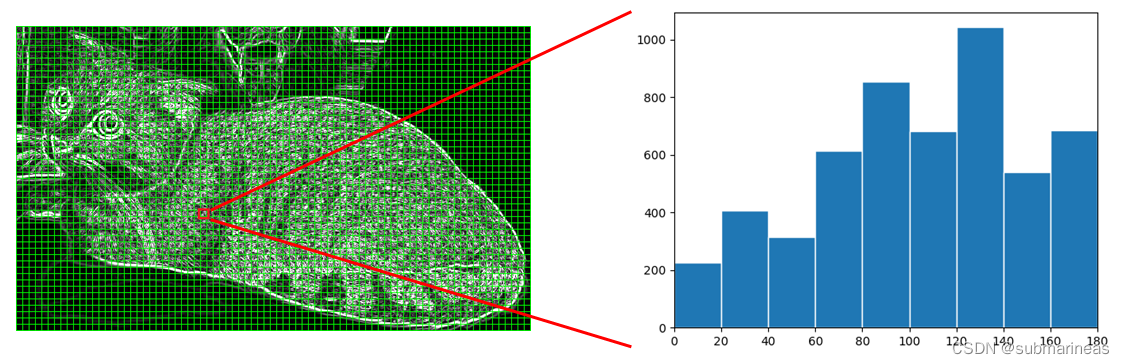
下图是一个计算方向梯度图的例子,对于红色方框中的像素,假设其中有些像素对应的梯度方向落在 0 到 20 区间,那么将这些像素对应的梯度幅值在 0 到 20 区间内进行累加,同理其他区间也做同样的运算,最终得到下图中右边的方向梯度直方图。同样地,整张图片中的所有 Cells 都用同样的方法计算方向梯度直方图:
区域(Blocks)归一化
HOG将8×8的一个区域作为一个cell,再以2×2个cell作为一组,称为block。由于每个cell有9个值,2×2个cell则有36个值,HOG是通过滑动窗口的方式来得到block的,我们用红色矩形框表示一个 Blcok,红色矩形框在图上向右滑动一个 Cell 的步长后我们就得到了蓝色矩形框,如下图所示:

而接下来我们要对图像的每个block进行区域归一化处理,归一化的目的是减少光照变化对图像梯度的影响,那对于这种归一化方法,原参考链接中给出了一个例子。
假设我们有一个向量 [128,64,32],向量的长度为 12 8 2 + 6 4 2 + 3 2 2 = 146.64 \sqrt{128^{2}+64^{2}+32^{2}}=146.64 1282+642+322 =146.64 ,这叫做向量的 L 2 L2 L2 范数。将这个向量的每个元素除以146.64就得到了归一化向量 [0.87, 0.43, 0.22]。
事实上HOG确实是使用
L
2
L2
L2 范数会比
L
1
L1
L1 范数更好,它的归一化公式为:
v
=
v
i
∑
i
=
1
n
v
i
2
+
ϵ
2
v=\frac{v_{i}}{\sqrt{\sum_{i=1}^{n} v_{i}^{2}+\epsilon^{2}}}
v=∑i=1nvi2+ϵ2
vi
其中 v i v_{i} vi 表示 Block 内的向量, ϵ \epsilon ϵ 的作用是防止出现分母为 0 的情况,它是一个很小的值。
从上图中可以看出每一个 Cell 不止出现在一个 Block 内,也就是说一个 Cell 将被重复的用于归一化计算中,这样做会看似比较冗余,但是会提高特征描述的表现。最后对所有的 Block 完成归一化计算,合并所有获得的归一化后的向量,这样我们就完成了图像的 HOG 特征化表示。
代码实现
这里还是引用原链接的demo,然后加入了一些结合自己理解的注释:
from skimage import feature, exposure import cv2 image = cv2.imread('xxxxx') """ image:输入图像 orientations:一个cell对应梯度范围,这里为9个区间,即 0 到 180 度; pixels_per_cell:一个cell里包含的像素个数,需要传递一个元组给该参数,我们将 (8, 8) 传递给该参数; cells_per_block:一个block包含的cell个数; transform_sqrt:伽马校正,将 True 传递给该参数表示使用伽马校正预先对图片进行归一化处理; visualize:表示可视化,将 True 传递给该参数表示返回 HOG 图像。 """ fd, hog_image = feature.hog(image, orientations=9, pixels_per_cell=(16, 16), cells_per_block=(2, 2), transform_sqrt=True, visualize=True) # Rescale histogram for better display """ hog_image:前面获取的可视化二维数组 out_range:将输入图片的像素强度拉伸到设定的范围,这里是将hog_image中的每个元素值拉伸到 (0, 10) 范围内。建议是(0,255),不然会和原文中的显示图一样,归一化后的点因为拉伸太小,直接就变成了线 """ hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10)) cv2.imshow('img', image) cv2.imshow('hog', hog_image_rescaled) cv2.waitKey(0)==ord('q')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
那么这大概就是HOG的整个原理介绍,当然本文的重点不在这里,HOG只是一种提取图像特征的算法,在很多检测领域会经常出现,它的优缺点都非常突出,优点在于算法比较简单直观,归一化抑制了光照颜色等影响,而缺点在于算法运行非常慢,主要是算子生成速度慢,基本不能运用于视频上,而且整个过程没有处理过噪声,对于遮挡问题都有很大影响。
针对HOG的缺点,接下来会根据它提取到的特征,训练一个SVM的模型,这也是opencv官方都给出的说明,但在此之前,可以看一个直接使用opencv实现猫狗识别的例子,这是根据这里的HOG还有前面第七篇滑动窗口与图像金字塔就能理解的很短的demo。
使用opencv实现猫狗识别
我记得很久之前,很多自媒体,比如公众号,某站等,都会起一个很雷人的标题:震惊!如此容易!不到20行的人脸 or 猫狗识别代码,关于人脸,我上一篇已经写过关于特征点的耳鼻喉检测,这里同样,有一个官方的代码:
# -*- coding=utf-8 -*- import cv2 # 加载猫脸检测器 catPath = "haarcascade_frontalcatface.xml" faceCascade = cv2.CascadeClassifier(catPath) # 读取图片并灰度化 img = cv2.imread("xxx.jpg") gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 猫脸检测 faces = faceCascade.detectMultiScale( gray, # 灰度图,可以加快检测速度 scaleFactor= 1.02, # 表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10% minNeighbors=3, # 表示构成检测目标的相邻矩形的最小个数(默认为3个)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除 minSize=(150, 150), # 目标的最小尺寸 flags=cv2.CASCADE_SCALE_IMAGE # 一般都为默认值,或者canny,即选用什么边缘检测器来排除边缘过多或过少的区域,不过最新的版本好像没有这个参数了,但目前我这边还能用 ) # 框出猫脸并加上文字说明 for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+h), (0, 0, 255), 2) cv2.putText(img,'Cat',(x,y-7), 3, 1.2, (0, 255, 0), 2, cv2.LINE_AA) # 显示图片并保存 cv2.imshow('Cat?', img) cv2.imwrite("cat.jpg",img) c = cv2.waitKey(0) # 关于detectMultiScale更详细的参数解释,可以看如下Stack Overflow链接讨论的内容 # https://stackoverflow.com/questions/36218385/parameters-of-detectmultiscale-in-opencv-using-python
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
关于haarcascade_frontalcatface.xml这个文件,可以在opencv官方提供的xml中找到,大概1.3M左右的样子,代码强行扩展到24行,其实整个函数核心就2行,一个cv2.CascadeClassifier加载,一个 faceCascade.detectMultiScale检测,具体的我按自己的理解加上了注解,而根据图像识别猫脸的代码及详解 一文中提到的,该模型可能会出现很多个框被判定为cat,这个其实就是没有做极大值抑制的结果,


import cv2 as cv ########## hog+svm 行人检测 ##################### src = cv.imread('xxxx') cv.imshow("input", src) hog = cv.HOGDescriptor() # opencv的 默认的 hog+svm行人检测器 hog.setSVMDetector(cv.HOGDescriptor_getDefaultPeopleDetector()) # Detect people in the image (rects, weights) = hog.detectMultiScale(src, winStride=(2, 4), padding=(8, 8), scale=1.2, useMeanshiftGrouping=False) for (x, y, w, h) in rects: cv.rectangle(src, (x, y), (x + w, y + h), (0, 255, 0), 2) cv.imshow("hog-detector", src) cv.imwrite("hog-detector.jpg", src) cv.waitKey(0) cv.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这个程序用的就是HOG的检测器,其中scale、padding参数也是图像金字塔的一些步长设置,虽然目前我看起来好像结果相对比较准确,但就测试了几张图片,看到2020年以前用这种方法的,都说结果不太准确,感觉可能是opencv后来又对当前模型进行了改进,一般情况下也会出现如上haar特征提取器出现的情况,即很多框,这是用这类提取器的通病。


所以后面两节,按照opencv官方推荐的资料与实验楼的实验顺序,重新训练一个SVM模型,并使用nms进行剔除大部分不准确的标定。
SVM模型训练与测试
SVM训练
当前训练图像选取自官方的pedestrian.zip数据集,解压文件后我们会看到文件夹包含 people 和 background 两个子文件夹,表示两个类别。这个文件夹内各包含两千多张图片,people 文件夹内都是人的图片,backgorund 内都是一些背景图片。我们将使用这个数据集训练一个用于分辨人和背景的分类模型。
这里过程不再详述,因为使用的是sklearn里的SVM进行训练,基本就那一套东西,只是数据预处理需要提一下。
首先我们创建一个 preprocessing 函数,这个函数用于读取数据集中所有图片的路径以及每张图片对应的标签:
def preprocessing(datasetpath):
dataset = []
labels = []
categories = [join(datasetpath, i) for i in listdir(datasetpath)]
for i in categories:
dataset.extend([join(i, f) for f in listdir(i)])
labels = [i.split("/")[1] for i in dataset]
return (dataset, labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
然后定义提取特征函数,这里是将上述HOG封装成一个类来表示,这也是opencv中关于HOG的samples这么定义的:
class HOG:
def __init__(self, orientations = 9, pixelsPerCell = (8, 8),
cellsPerBlock = (3, 3), transform = False):
self.orienations = orientations
self.pixelsPerCell = pixelsPerCell
self.cellsPerBlock = cellsPerBlock
self.transform = transform
def describe(self, image):
hist = feature.hog(image, orientations = self.orienations,
pixels_per_cell = self.pixelsPerCell,
cells_per_block = self.cellsPerBlock,
transform_sqrt = self.transform)
return hist
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
然后就可以训练模型了:
from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.svm import LinearSVC import joblib import cv2 import numpy as np (dataset, labels) = preprocessing("pedestrian") L = LabelEncoder() # 将n个类别编码为0~n-1之间的整数(包括0和n-1) labels = L.fit_transform(labels) # 对labels编码 hog = HOG(transform = True) # 实例化一个HOG类 data = [] for i in dataset: # 提取HOG特征,存入data image = cv2.imread(i) gray = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY) resized = cv2.resize(gray, (64, 128), interpolation = cv2.INTER_AREA) hist = hog.describe(resized) data.append(hist) (trainData, testData, trainLabels, testLabels) = train_test_split( np.array(data), np.array(labels), test_size=0.15, random_state=42) # 划分数据集 print("### Training model...") model = LinearSVC() # 利用sklearn中的svm进行训练 model.fit(trainData, trainLabels) print("### Evaluating model...") predictions = model.predict(testData) print(classification_report(testLabels, predictions, target_names=L.classes_)) joblib.dump(model, "model")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
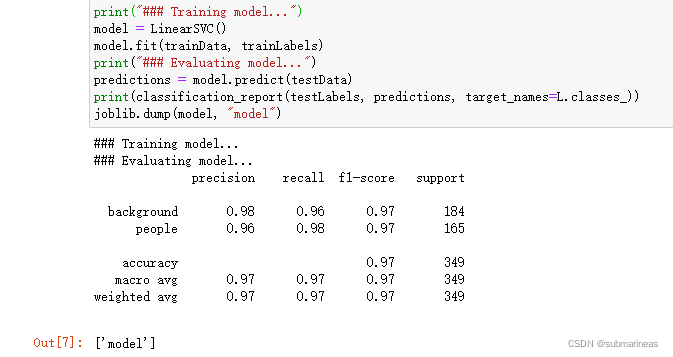
上面是我在jupyter上训练的结果,因为图片很少,而且类别很少,基本几秒就完成,然后通过joblib.dump存储模型,关于这种调用方式,可以看我之前写的一篇lightgbm的笔记,基本都是用这种方式去做导入和保存的一些实例(然后我现在才发现本来还有一篇二的,写了一点,后来发现忘了,emmm):
那有模型了,就可以进行预测与测试。
模型预处理
承接上面的HOG类,引出第七篇笔记中提到的图像金字塔和滑动窗口,以及再添加一个自定义resize函数做图像过滤:
def sliding_window(image, window = (64, 128), step = 4):
for y in range(0, image.shape[0] - window[1], step):
for x in range(0, image.shape[1] - window[0], step):
yield (x, y, image[y:y + window[1], x:x + window[0]])
def pyramid(image, top = (224, 224), ratio = 1.5):
yield image
while True:
(w, h) = (int(image.shape[1] / ratio), int(image.shape[0] / ratio))
image = cv2.resize(image, (w, h), interpolation = cv2.INTER_AREA)
if w < top[1] or h < top[0]:
break
yield image
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
python-opencv学习笔记(七):滑动窗口与图像金字塔
在处理数据集和检测时我们都需要对图片进行缩放,同时我们会希望图片在缩放后它的宽和高的比例保持不变,即不产生失真,所以自定义resize函数为:
def resize(image, height = None, width = None):
h, w = image.shape[:2]
dim = None
if width is None and height is None:
return image
if width is None:
dim = (int(w * (height / h)), height)
else:
dim = (width, int(h * (width / w)))
resized = cv2.resize(image, dim, interpolation = cv2.INTER_AREA)
return resized
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
坐标变换函数:
因为上面用了resize,滑动窗口如果是对缩放图进行滑动,而最终返回的是原图格式,那么很有可能出现框出现漂移,或者根本就没有框柱的情况,如下图所示:

绿色矩形框内只有背景而没有人,而我们希望的是绘制右图中红色的矩形框。为了解决这个问题,我们就需要进行坐标变换,为coordinate_transformation 函数:
def coordinate_transformation(height, width, h, w, x, y, roi):
if h is 0 or w is 0:
print("divisor can not be zero !!")
img_h = int(height/h * roi[1])
img_w = int(width/w * roi[0])
img_y = int(height/h * y)
img_x = int(width/w * x)
return (img_x, img_y, img_w, img_h)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
SVM模型检测
这里不再多说,读取需要检测的图像源,然后加载模型,将上述函数都加入预测机制中,具体代码为:
import joblib img_path = "man.jpg" """ 图像金字塔与滑动窗口参数 """ ratio = 1.5 i_roi = (64, 128) step = 20 top = (128, 128) model = joblib.load("model") # 加载模型对象 hog = HOG(transform = True) # 实例化HOG对象,并将 transform 参数设为 True image = cv2.imread(img_path) resized = resize(image, height = 500) gray = cv2.cvtColor(resized, cv2.COLOR_BGR2GRAY) height, width = gray.shape[:2] roi_loc = [] # 空列表,为了存储人的特征信息 for image in pyramid(gray, top = (128, 128), ratio = ratio): # 每层滑动窗口进行resize,然后使用HOG将提取到的特征传给hist h, w = image.shape[:2] for (x, y, roi) in sliding_window(image, window = i_roi, step = step): roi = cv2.resize(roi, (64, 128), interpolation = cv2.INTER_AREA) hist = hog.describe(roi) if model.predict([hist])[0]: # 如果预测结果为真,也就是1,将进行下一步坐标变换 img_x, img_y, img_w, img_h = coordinate_transformation(height, width, h, w, x, y, i_roi) roi_loc.append([img_x, img_y, img_w, img_h]) # 将顶点坐标、宽、高存入上述rol_loc中,等待标定
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
然后我们用矩形框标记出被分类器认为是人的区域,并将其画出:
for (x, y, w, h) in roi_loc:
cv2.rectangle(resized, (x, y), (x + w, y + h), (0, 255, 0), 2)
- 1
- 2
- 3
然后利用matplotlib进行imshow:
from matplotlib import pyplot as plt
%matplotlib inline
plt.figure(figsize = (10,10))
resized = resized[:,:,::-1]
plt.imshow(resized)
- 1
- 2
- 3
- 4
- 5
- 6
我们可以用几张图测试一下,结果如下:
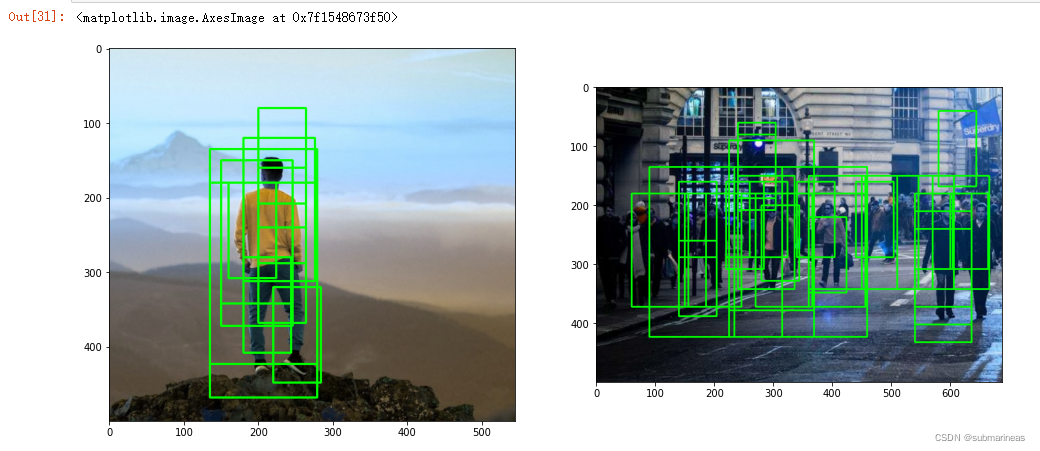
这里就会看到有很多的标定,如果将上面的动物图重新进行检测,基本也会是这个效果,那么怎么将这些没有检测到最大匹配的框去除呢?这就引出了非极大值抑制的方法,剔除冗余的矩形框。
NMS(非极大值抑制)
非极大值抑制(Non Maximum Suppression)以下简称 NMS,的主要作用是去除目标检测过程中产生的冗余矩形框。要实现 NMS 首先需要计算矩形框之间的交并比(Intersection over Union),以下简称 IoU。下图以直观的例子展示计算 IoU 的方法,左图中的目标(人)同时被两个矩形框标记,为了剔除多余的矩形框需要计算两个矩形框的 IoU。IoU 的计算的方法如下图中间的公式所示,即两个框的交集(红色区域)与两个框的并集(绿色区域)的比值。如果计算后的 IoU 大于事先设定的阈值,则剔除较小的矩形框(下图中最右边图片所示),通过这个过程我们就达到了剔除冗余的矩形框的目的。接下来我们将通过代码来实现一个 NMS 函数。

这里直接引出整个nms的代码,根据实验资料,与我自己的理解,直接在代码基础上添加了相应注释:
def NMS(boxes, threshold): if len(boxes) == 0: # 边界判断,如果没有检测到任何目标,返回空列表,即不做nms return [] boxes = np.array(boxes).astype("float") # 将numpy中的每个元素转换成float类型 x1 = boxes[:,0] # 左上角顶点的横坐标 y1 = boxes[:,1] # 左上角顶点的纵坐标 w1 = boxes[:,2] # 矩形框的宽 h1 = boxes[:,3] # 矩形框的高 x2 = x1 + w1 # 右下角顶点横坐标的集合 y2 = y1 + h1 # 纵坐标的集合 area = (w1 + 1) * (h1 + 1) # 计算每个矩形框的面积,这里分别加1是为了让IOU匹配不出现0的情况 temp = [] idxs = np.argsort(h1) # 将 h1 中的元素从小到大排序并返回每个元素在 h1 中的下标 while len(idxs) > 0: last = len(idxs) - 1 i = idxs[last] temp.append(i) x1_m = np.maximum(x1[i], x1[idxs[:last]]) # 将其他矩形框的左上角横坐标两两比较 y1_m = np.maximum(y1[i], y1[idxs[:last]]) # 其他矩形框的左上角纵坐标两两比较 """两个矩形框重叠的部分是矩形,这一步的目的是为了找到这个重叠矩形的左上角顶点""" x2_m = np.minimum(x2[i], x2[idxs[:last]]) y2_m = np.minimum(y2[i], y2[idxs[:last]]) """目的是为了找出这个重叠矩形的右下角顶点""" w = np.maximum(0, x2_m - x1_m + 1) # 计算矩形的宽 h = np.maximum(0, y2_m - y1_m + 1) # 计算矩形的高 """剔除掉没有相交的矩形,因为两个矩形框相交,则 x2_m - x1_m + 1 和 y2_m - y1_m + 1 大于零,如果两个矩形框不相交则这两个值小于零""" over = (w * h) / area[idxs[:last]] # 计算重叠矩形面积和 area 中的面积的比值 idxs = np.delete(idxs, np.concatenate(([last], np.where(over > threshold)[0]))) # 剔除重叠的矩形框 return boxes[temp].astype("int")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
封装好nms函数后,这里改变上述画框逻辑,对roi_loc保存的矩形框先进行nms后再cv2.rectangle:
for (x, y, w, h) in NMS(roi_loc, threshold=0.3):
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
- 1
- 2
最后与上面的方法一样,利用matplotlib显示图像,我用subplot将两张图显示在了一起:
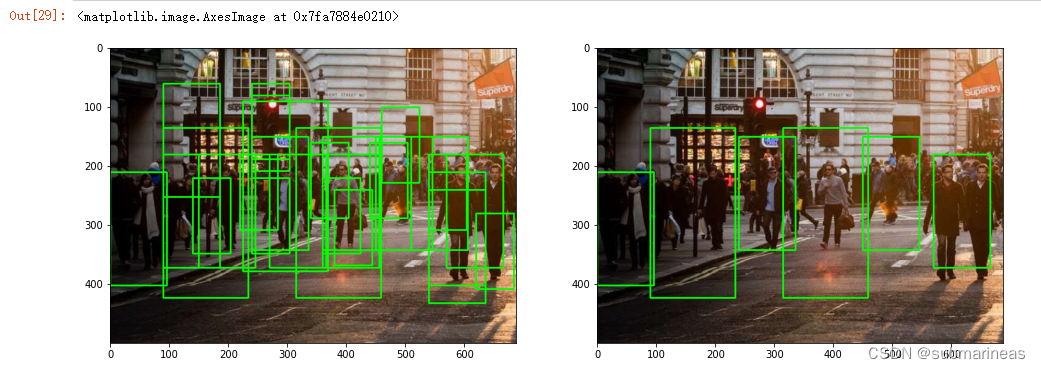
另一张图为:

至此,我们剔除了冗余的矩形框并使得目标只被一个矩形框标记。
reference
最后,这里总结一些我去看相关原理与说明,除文中提到的图片引用链接,还有一些内容,有一些我觉得很有意思的文章这里分享一下,虽然没有引用相关东西,比如说HOG加svm,我看到有些作者对此进行了详细的扩展,我看完感到很有意思,但因为我这里不是重点,所以这里贴出来Mark一下。
[1]. Histogram of Oriented Gradients and Object Detection
[2]. HOG detectMultiScale parameters explained
[3]. 【入門者向け解説】openCV顔検出の仕組と実践(detectMultiScale)
[4]. https://gist.github.com/jotathebest/291827084275f799a2262b6a45888abd


