
- 1深度学习中初始化权重_tensorflow初始化权重
- 2The cost from the bebe Daniela
- 3Python 房价预测 kaggle 线性回归 SVM 神经网络 随机森林 集成模型_房价预测可以用分类模型么
- 4当 AI 冲击自动化编程,谁将成为受益者?
- 5语言模型评价指标 bpc(bits-per-character)和困惑度ppl(perplexity)
- 6嵌入式Linux学习(入门)— Vim安装、Linux常用命令_安装vim
- 7JTA transaction unexpectedly rolled back (maybe due to a timeout); 解决方法
- 8MAC 删除自带 ABC 输入法的方法_mac删除abc输入法
- 9史上最详细LRW数据集、LRW-1000数据集、LRS2数据集、LRS3-TED数据集、OuluVS2数据集介绍
- 10MaskRCNN源码解析5:损失部分解析_maskrcnn掩膜预测 损失函数
Feature Pyramid Networks for object detection
赞
踩
总述
下图中,蓝色边框表示的是特征图,边框越粗表示该特征图的语义信息越丰富,即在特征层次结构中位置越高。 这四个子图展示了如何在不同层级上提取和融合特征,以便于在不同尺度上进行有效的对象检测。
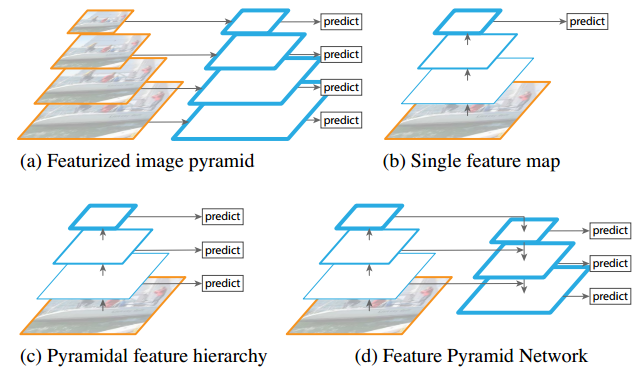
- a) Featurized image pyramid (特征化图像金字塔):
这是传统方法,通过对不同尺度的图像分别计算出一个特征图来构建一个特征金字塔,从而能在多个尺度上进行对象检测。这种方法计算量大,速度慢,因为每个尺度都需要独立计算特征。
- b) Single feature map (单一特征图):
为了提高检测速度,一些现代的检测系统选择只在一个单一的尺度上计算特征并进行预测,避免了特征化图像金字塔的复杂计算过程。但这种方法可能会牺牲对小尺度对象的检测准确性。
- c) Pyramidal feature hierarchy (金字塔特征层级):
这是另一种方法,利用卷积神经网络(ConvNet)内部计算的金字塔特征层级来进行对象检测。它尝试像特征化图像金字塔那样使用这些特征,但并不需要对每个图像尺度独立计算特征,从而可以更快地进行。(卷积神经网络不同卷积层输出的特征图天然有金字塔的特点,就是直接将不同卷积层输出的特征图用于预测)
- d) Feature Pyramid Network (FPN, 特征金字塔网络):
这是本文提出的方法。与单一特征图和金字塔特征层级一样快速,但提供了更高的准确性。FPN通过 自顶向下的路径(Top-down pathway) 和 横向连接(lateral connection) 整合了不同层级的特征,从而在每个层级上都能得到语义较强的特征,用于进行更准确的预测。
1.引言
对图像金字塔的每个级别进行特征化的主要优点是,它产生了一个多尺度特征表示,其中所有级别在语义上都很强,包括高分辨率级别。
然而,图像金字塔并非计算多尺度特征表示的唯一方法。深度卷积神经网络一层一层地计算特征层次结构,通过子采样层,特征层次结构具有固有的多尺度金字塔形状。这种网络内特征层次产生了不同空间分辨率的特征图,但由于深度不同,引入了很大的语义差距。高分辨率的特征图(网络的较浅层)具有低级特征,这损害了它们对目标识别的表示能力。
本文的目标是利用卷积神经网络自然地特征层次的金字塔形状,同时创建一个在所有尺度上都具有强语义的特征金字塔。为了实现这一目标,作者依赖于一种架构,该架构通过自上而下的途径和横向连接将低分辨率、语义强的特征与高分辨率、语义弱的特征结合起来(图1(d))。结果是一个特征金字塔,在所有级别上都具有丰富的语义,并且可以从单个输入图像规模快速构建。换句话说,作者展示了如何在不牺牲表示能力、速度或内存的情况下创建可用于替换特征图像金字塔的 in-network feature pyramids。
作者提出的模型,既适用于 Bounding Box Proposals ,也可以扩展到 Masked Proposals。
此外,作者提出的 FPN 结构可以在所有尺度上进行端对端训练,并在训练/测试时一致使用,这对于传统的图像金字塔来说是不可行的。
2.相关工作
这张图2展示了两种不同的深度学习架构,用于对象检测任务中的特征提取和预测过程。
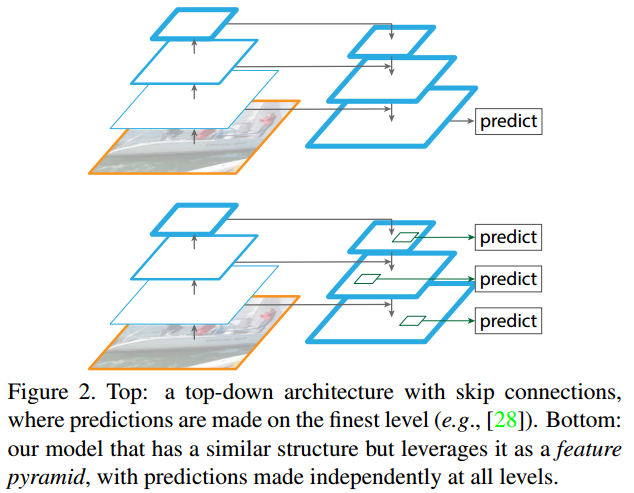
顶部图(Top)显示的是一种自顶向下的架构,该架构带有跳过连接(skip connections)。在这种架构中,预测仅在最细的层级(即空间分辨率最高的特征图)上进行。这样做的一个例子是文献 [28] 中的方法。这种方式 通过自顶向下的路径传递信息,同时利用跳过连接保留细节信息,这对于图像分割任务非常有用。但对于对象检测,尤其是在需要检测不同尺寸的对象时,可能不够有效。
底部图(Bottom)展示的是论文提出的特征金字塔网络(FPN)。它具有与顶部图相似的结构,但它是作为一个特征金字塔(feature pyramid)使用,其中在所有层级上都独立进行预测。这意味着FPN不仅利用自顶向下的结构来提取强语义的特征,并且通过横向连接将这些特征与来自卷积网络低层次的高分辨率特征结合起来。因此,FPN能够在每个层级上都生成具有丰富语义信息的特征图,这使得在不同尺度上的对象检测更加准确和有效。
这张图清楚地说明了FPN的核心优势,即能够结合来自不同深度层次的特征,从而在多尺度对象检测任务中取得好的效果。它避免了仅在单个尺度上进行预测的限制,同时又不需要像传统的特征化图像金字塔那样繁琐地计算每个尺度上的特征。
3. Feature Pyramid Networks
在本文中,作者重点关注滑动窗口提议器(区域提议网络,简称RPN)和基于区域的检测器(Fast R-CNN)
作者的方法采用任意大小的单尺度图像作为输入,并在多个级别输出按比例大小的特征图,以一种完全卷积的方式。
在本文中,作者展示了使用ResNets的结果。作者的金字塔结构包括自下而上的途径,自上而下的途径和横向连接,如下所述。
Bottom-up pathway
自底向上路径是卷积神经网络 backbone 的前馈计算,计算由多个尺度的特征图组成的特征层次结构,缩放步长为 2。通常有许多层产生相同大小的输出图,称这些层处于相同的网络阶段 (stage)。
对于作者提出的特征金字塔,为每个阶段定义一个金字塔级别。选择每个阶段最后一层的输出作为特征图的参考集,将对其进行丰富以创建金字塔。这种选择是很自然的,因为每个阶段的最深层应该拥有最强大的功能。
具体而言,对于 ResNets \text{ResNets} ResNets,作者使用每个阶段最后一个残差块输出的特征激活。对于 conv2, conv3, conv4 \text{conv2, conv3, conv4} conv2, conv3, conv4 和 conv5 \text{conv5} conv5 ,将这些最后的残差块的输出表示为 C 2 , C 3 , C 4 , C 5 {C_2, C_3, C_4, C_5} C2,C3,C4,C5,注意到它们相对于输入图像的步长为 4 , 8 , 16 , 32 {4,8,16,32} 4,8,16,32 像素。作者并没有将 conv1 \text{conv1} conv1 包含在金字塔中,因为它占用了大量内存。
Top-down pathway and lateral connections
自上而下的路径通过对来自更高金字塔级别的空间上更粗糙但语义上更强的特征图进行上采样来产生更高分辨率的特征。然后,这些特征通过横向连接通过自下而上通路的特征得到增强。每个横向连接都合并了自底向上路径和自顶向下路径中相同空间大小的特征图。自底向上的特征图具有较低级的语义,但它的激活定位更准确,因为它的子采样次数更少。
图3显示了构建自顶向下特征图的构建块。对于较粗分辨率的特征图,作者将空间分辨率上采样2倍 (为了简单起见,使用最近邻上采样)。
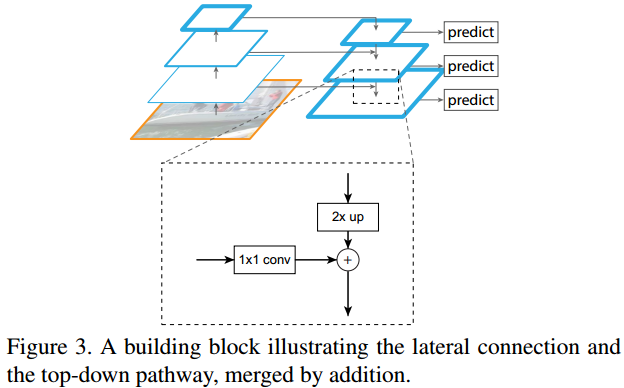
上采样后的特征图然后通过元素级加法 ( element-wise addition \text{element-wise addition} element-wise addition) 与相应的自下而上特征图合并(该特征图经过 1 × 1 1×1 1×1卷积层以减少通道维度)。这个过程反复进行,直到生成最精细的分辨率特征图。
为了开始迭代,作者简单地在 C 5 C_5 C5上附加一个 1 × 1 1×1 1×1 卷积层来生成最粗略的分辨率特征图。最后,在每个合并的特征图上附加 3 × 3 3×3 3×3 卷积来生成最终的特征图,这是为了减少上采样的混叠效应。最后一组特征图称为 P 2 , P 3 , P 4 , P 5 {P_2, P_3, P_4, P_5} P2,P3,P4,P5,分别对应具有相同空间大小的 C 2 , C 3 , C 4 , C 5 {C_2, C_3, C_4, C_5} C2,C3,C4,C5
由于金字塔的所有层次都像传统的特征图像金字塔一样使用共享的分类器/回归器,因此作者固定了所有特征图中的特征维度(通道数,记为 d d d)。作者在本文中设置 d = 256 d = 256 d=256,因此所有额外的卷积层都有 256 256 256 通道输出。在这些额外的层中没有非线性,作者的经验发现这些非线性的影响很小。
简单是作者设计的核心,作者发现其模型对于许多设计选择都是健壮的。作者已经尝试了更复杂的块(例如,使用多层残差块作为连接),并观察到稍微更好的结果。设计更好的连接模块不是本文的重点,因此作者选择了上面描述的简单设计。
4. 应用
用于 RPN
用于 Fast R-CNN
核心代码复现
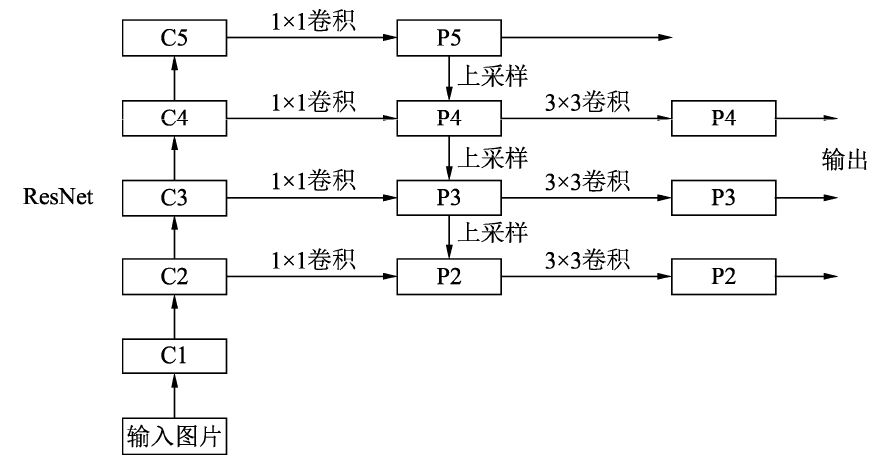
FPN网络结构
ResNet Bottleneck
在残差网络中,主路径和残差路径的输出必须具有相同的尺寸和通道数,才能进行element-wise相加 !!
可以看到,第一个卷积层和第三个卷积层之间,通道数的变化是倍增 4,所以 expansion = 4 \text{expansion = 4} expansion = 4
64,64和256表示的是对应卷积层的输出通道数
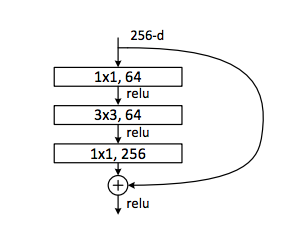
- 第一个1x1卷积层将输入通道数减少到64,这是一个降维操作,它的目的是减少参数数量和计算量。
- 然后是一个3x3的卷积层,它在64个通道上进行操作,这是
Bottleneck的核心部分,用于提取特征。 - 最后一个1x1卷积层再次将通道数增加,这次增加到256,这是一个升维操作,为后续的层提供更多的特征信息。
在此结构中,残差连接(也就是图中的弯曲箭头)直接连接输入和最后一个1x1卷积层的输出。如果输入的通道数不是256,残差连接上通常会有一个1x1卷积用于匹配通道数,这样才能将输入和输出相加。ReLU激活函数应用于每个卷积层之后,以及最终的相加操作之后。
class Bottleneck(nn.Module): # 输出通道倍增数 expansion = 4 def __init__(self, inchannels, outchannels, stride=1, downsample=None): super(Bottleneck, self).__init__() self.bottleneck = nn.Sequential( # 第一个1*1卷积核降低通道维度 nn.Conv2d(inchannels, outchannels, kernel_size=1, bias=False), nn.BatchNorm2d(outchannels), nn.ReLU(inplace=True), # 第二个3*3卷积核特征提取 nn.Conv2d(outchannels, outchannels, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(outchannels), nn.ReLU(inplace=True), # 第三个1*1卷积核升高通道维度 nn.Conv2d(outchannels, self.expansion * outchannels, kernel_size=1, bias=False), nn.BatchNorm2d(self.expansion * outchannels) ) self.relu = nn.ReLU(inplace=True) self.downsample = downsample def forward(self, x): identity = x out = self.bottleneck(x) if self.downsample is not None: identity = self.downsample(x) out += identity out = self.relu(out) return out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
完整代码
import torch import torch.nn as nn import torch.nn.functional as F import math from torchsummary import summary class Bottleneck(nn.Module): # 输出通道倍增数 expansion = 4 def __init__(self, inchannels, outchannels, stride=1, downsample=None): super(Bottleneck, self).__init__() self.bottleneck = nn.Sequential( # 第一个1*1卷积核降低通道维度 nn.Conv2d(inchannels, outchannels, kernel_size=1, bias=False), nn.BatchNorm2d(outchannels), nn.ReLU(inplace=True), # 第二个3*3卷积核特征提取 nn.Conv2d(outchannels, outchannels, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(outchannels), nn.ReLU(inplace=True), # 第三个1*1卷积核升高通道维度 nn.Conv2d(outchannels, self.expansion * outchannels, kernel_size=1, bias=False), nn.BatchNorm2d(self.expansion * outchannels) ) self.relu = nn.ReLU(inplace=True) self.downsample = downsample def forward(self, x): identity = x out = self.bottleneck(x) # stride!=1 或者输入通道和输出通道数不一致时,downsample不为空 if self.downsample is not None: identity = self.downsample(x) # 在残差网络中,主路径和残差路径的输出必须具有相同的尺寸和通道数,才能进行element-wise相加!! # 如果不对x进行下采样,那identity的空间尺寸或通道数是和out不一致的 out += identity out = self.relu(out) return out class FPN(nn.Module): #接收的参数layers是一个列表,每个元素数值代表不同阶段bottleneck块的数量 def __init__(self, layers): super(FPN, self).__init__() self.inplanes = 64 # 处理C1模块,如果输入空间尺寸是224*224,经过conv1之后尺寸变为112*112 self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) # maxpool将特征图大小改变为 56*56 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 搭建自底向上的C2,C3,C4,C5模块 #resnet50 中 layers[0] = 3,layers[1] = 4,layers[2] = 6,layers[3] = 3, # layers[i]代表各个阶段Bottleneck块的数量 # 64,128,256,512 是输出通道数,_make_layers会返回各个阶段包含的一系列Bottleneck块, #conv2_x的输入通道64,conv3_x的输入通道128,conv4_x的输入通道256,conv5_x的输入通道512 self.layer1 = self._make_layers(64, layers[0]) #构建C2 self.layer2 = self._make_layers(128, layers[1], stride=2) #构建C3 self.layer3 = self._make_layers(256, layers[2], stride=2) #构建C4 self.layer4 = self._make_layers(512, layers[3], stride=2) #构建C5 # 定义toplayer层,用于后面对C5降低输出通道数,得到P5, #这里输入通道是2048是因为resnet50及以上的模型经过conv5_x之后输出的通道数是2048 self.toplayer = nn.Conv2d(in_channels=2048, out_channels=256, kernel_size=1, stride=1, padding=0) # 3*3卷积融合,目的是消除上采样过程带来的重叠效应,以生成最终的特征图 self.smooth1 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1) self.smooth2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1) self.smooth3 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1) # 横向连接 self.latlayer1 = nn.Conv2d(in_channels=1024, out_channels=256, kernel_size=1, stride=1, padding=0) self.latlayer2 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=1, stride=1, padding=0) self.latlayer3 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=1, stride=1, padding=0) # blocks参数代表各个阶段Bottleneck块的数量,来自于layers列表中的元素 # stride参数在第一个Bottleneck块中使用,用于控制特征图的空间尺寸是否减半。 # 如果stride等于2,各个阶段第一个Bottleneck块将会使特征图的高度和宽度减半。 def _make_layers(self, inchannels, blocks, stride=1): downsample = None # stride!=1时需要对特征图进行下采样, # 输入通道数和输出通道数不等时,需要使用1*1卷积核进行通道数调整。 #在残差网络中,主路径和残差路径的输出必须具有相同的尺寸和通道数,才能进行element-wise相加!! if stride != 1 or self.inplanes != Bottleneck.expansion * inchannels: downsample = nn.Sequential( nn.Conv2d(self.inplanes, Bottleneck.expansion * inchannels, kernel_size=1, stride=stride, bias = False), nn.BatchNorm2d(Bottleneck.expansion * inchannels) ) # layers是一个Python列表,它用于存储一系列的Bottleneck块。 # 这些Bottleneck块在一起构成了ResNet的一个阶段(stage),其中每个阶段的输出特征图大小可能会减半,而通道数可能会增加 # 这里的layers和上面的layers不一样, layers = [] layers.append(Bottleneck(self.inplanes, inchannels, stride, downsample)) # 因为经过第一个Bottleneck之后,第二个Bottleneck块的输入通道数是第一个Bottleneck块的输出通道数, # 所以需要通道倍增 self.inplanes = inchannels * Bottleneck.expansion for i in range(1, blocks): # 这里没有指定stride=stride,所以是默认的stride=1 layers.append(Bottleneck(self.inplanes, inchannels)) return nn.Sequential(*layers) def _upsample_and_add(self, x, y): _,_,H,W = y.shape # x是较高层的特征图,上采样到和较低层y一样的空间尺寸后,和y进行元素级加法 return F.upsample(x, size=(H,W), mode='bilinear') + y def forward(self, x): # 自下而上 c1 = self.maxpool(self.relu(self.bn1(self.conv1(x)))) #c2是conv2_x阶段经过一些列bottleneck块的输出,输出通道数为256 c2 = self.layer1(c1) #c3是conv3_x阶段经过一些列bottleneck块的输出,输出通道数为512 c3 = self.layer2(c2) #c4是conv4_x阶段经过一些列bottleneck块的输出,输出通道数为1024 c4 = self.layer3(c3) #c5是conv5_x阶段经过一些列bottleneck块的输出,输出通道数为2048 c5 = self.layer4(c4) # 自顶向下和横向连接 # toplayer使用1*1卷积核调整通道数为256,latlayer1,2,3的通道数都是256 p5 = self.toplayer(c5) #c4输出的通道数是1024,所以latlayer1的输入通道数是1024,同理latlayer2,3也是 p4 = self._upsample_and_add(p5, self.latlayer1(c4)) p3 = self._upsample_and_add(p4, self.latlayer2(c3)) p2 = self._upsample_and_add(p3, self.latlayer3(c2)) # 卷积融合,平滑处理 p4 = self.smooth1(p4) p3 = self.smooth2(p3) p2 = self.smooth3(p2) return p2, p3, p4, p5 if __name__ == '__main__': fpn = FPN([3, 4, 6, 3]).cuda() summary(fpn, (3, 224, 224)) ''' if __name__ == '__main__': model = FPN([3, 4, 6, 3]) print(model) input = torch.randn(1, 3, 224, 224) out = model(input) # 遍历输出tuple中的每个元素,并打印其尺寸信息 for i, feature_map in enumerate(out): print(f"Feature map {i} size: {feature_map.size()}") '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
执行之后的打印信息:
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 64, 112, 112] 9,408 BatchNorm2d-2 [-1, 64, 112, 112] 128 ReLU-3 [-1, 64, 112, 112] 0 MaxPool2d-4 [-1, 64, 56, 56] 0 Conv2d-5 [-1, 64, 56, 56] 4,096 BatchNorm2d-6 [-1, 64, 56, 56] 128 ReLU-7 [-1, 64, 56, 56] 0 Conv2d-8 [-1, 64, 56, 56] 36,864 BatchNorm2d-9 [-1, 64, 56, 56] 128 ReLU-10 [-1, 64, 56, 56] 0 Conv2d-11 [-1, 256, 56, 56] 16,384 BatchNorm2d-12 [-1, 256, 56, 56] 512 Conv2d-13 [-1, 256, 56, 56] 16,384 BatchNorm2d-14 [-1, 256, 56, 56] 512 ReLU-15 [-1, 256, 56, 56] 0 Bottleneck-16 [-1, 256, 56, 56] 0 Conv2d-17 [-1, 64, 56, 56] 16,384 BatchNorm2d-18 [-1, 64, 56, 56] 128 ReLU-19 [-1, 64, 56, 56] 0 Conv2d-20 [-1, 64, 56, 56] 36,864 BatchNorm2d-21 [-1, 64, 56, 56] 128 ReLU-22 [-1, 64, 56, 56] 0 Conv2d-23 [-1, 256, 56, 56] 16,384 BatchNorm2d-24 [-1, 256, 56, 56] 512 ReLU-25 [-1, 256, 56, 56] 0 Bottleneck-26 [-1, 256, 56, 56] 0 Conv2d-27 [-1, 64, 56, 56] 16,384 BatchNorm2d-28 [-1, 64, 56, 56] 128 ReLU-29 [-1, 64, 56, 56] 0 Conv2d-30 [-1, 64, 56, 56] 36,864 BatchNorm2d-31 [-1, 64, 56, 56] 128 ReLU-32 [-1, 64, 56, 56] 0 Conv2d-33 [-1, 256, 56, 56] 16,384 BatchNorm2d-34 [-1, 256, 56, 56] 512 ReLU-35 [-1, 256, 56, 56] 0 Bottleneck-36 [-1, 256, 56, 56] 0 Conv2d-37 [-1, 128, 56, 56] 32,768 BatchNorm2d-38 [-1, 128, 56, 56] 256 ReLU-39 [-1, 128, 56, 56] 0 Conv2d-40 [-1, 128, 28, 28] 147,456 BatchNorm2d-41 [-1, 128, 28, 28] 256 ReLU-42 [-1, 128, 28, 28] 0 Conv2d-43 [-1, 512, 28, 28] 65,536 BatchNorm2d-44 [-1, 512, 28, 28] 1,024 Conv2d-45 [-1, 512, 28, 28] 131,072 BatchNorm2d-46 [-1, 512, 28, 28] 1,024 ReLU-47 [-1, 512, 28, 28] 0 Bottleneck-48 [-1, 512, 28, 28] 0 Conv2d-49 [-1, 128, 28, 28] 65,536 BatchNorm2d-50 [-1, 128, 28, 28] 256 ReLU-51 [-1, 128, 28, 28] 0 Conv2d-52 [-1, 128, 28, 28] 147,456 BatchNorm2d-53 [-1, 128, 28, 28] 256 ReLU-54 [-1, 128, 28, 28] 0 Conv2d-55 [-1, 512, 28, 28] 65,536 BatchNorm2d-56 [-1, 512, 28, 28] 1,024 ReLU-57 [-1, 512, 28, 28] 0 Bottleneck-58 [-1, 512, 28, 28] 0 Conv2d-59 [-1, 128, 28, 28] 65,536 BatchNorm2d-60 [-1, 128, 28, 28] 256 ReLU-61 [-1, 128, 28, 28] 0 Conv2d-62 [-1, 128, 28, 28] 147,456 BatchNorm2d-63 [-1, 128, 28, 28] 256 ReLU-64 [-1, 128, 28, 28] 0 Conv2d-65 [-1, 512, 28, 28] 65,536 BatchNorm2d-66 [-1, 512, 28, 28] 1,024 ReLU-67 [-1, 512, 28, 28] 0 Bottleneck-68 [-1, 512, 28, 28] 0 Conv2d-69 [-1, 128, 28, 28] 65,536 BatchNorm2d-70 [-1, 128, 28, 28] 256 ReLU-71 [-1, 128, 28, 28] 0 Conv2d-72 [-1, 128, 28, 28] 147,456 BatchNorm2d-73 [-1, 128, 28, 28] 256 ReLU-74 [-1, 128, 28, 28] 0 Conv2d-75 [-1, 512, 28, 28] 65,536 BatchNorm2d-76 [-1, 512, 28, 28] 1,024 ReLU-77 [-1, 512, 28, 28] 0 Bottleneck-78 [-1, 512, 28, 28] 0 Conv2d-79 [-1, 256, 28, 28] 131,072 BatchNorm2d-80 [-1, 256, 28, 28] 512 ReLU-81 [-1, 256, 28, 28] 0 Conv2d-82 [-1, 256, 14, 14] 589,824 BatchNorm2d-83 [-1, 256, 14, 14] 512 ReLU-84 [-1, 256, 14, 14] 0 Conv2d-85 [-1, 1024, 14, 14] 262,144 BatchNorm2d-86 [-1, 1024, 14, 14] 2,048 Conv2d-87 [-1, 1024, 14, 14] 524,288 BatchNorm2d-88 [-1, 1024, 14, 14] 2,048 ReLU-89 [-1, 1024, 14, 14] 0 Bottleneck-90 [-1, 1024, 14, 14] 0 Conv2d-91 [-1, 256, 14, 14] 262,144 BatchNorm2d-92 [-1, 256, 14, 14] 512 ReLU-93 [-1, 256, 14, 14] 0 Conv2d-94 [-1, 256, 14, 14] 589,824 BatchNorm2d-95 [-1, 256, 14, 14] 512 ReLU-96 [-1, 256, 14, 14] 0 Conv2d-97 [-1, 1024, 14, 14] 262,144 BatchNorm2d-98 [-1, 1024, 14, 14] 2,048 ReLU-99 [-1, 1024, 14, 14] 0 Bottleneck-100 [-1, 1024, 14, 14] 0 Conv2d-101 [-1, 256, 14, 14] 262,144 BatchNorm2d-102 [-1, 256, 14, 14] 512 ReLU-103 [-1, 256, 14, 14] 0 Conv2d-104 [-1, 256, 14, 14] 589,824 BatchNorm2d-105 [-1, 256, 14, 14] 512 ReLU-106 [-1, 256, 14, 14] 0 Conv2d-107 [-1, 1024, 14, 14] 262,144 BatchNorm2d-108 [-1, 1024, 14, 14] 2,048 ReLU-109 [-1, 1024, 14, 14] 0 Bottleneck-110 [-1, 1024, 14, 14] 0 Conv2d-111 [-1, 256, 14, 14] 262,144 BatchNorm2d-112 [-1, 256, 14, 14] 512 ReLU-113 [-1, 256, 14, 14] 0 Conv2d-114 [-1, 256, 14, 14] 589,824 BatchNorm2d-115 [-1, 256, 14, 14] 512 ReLU-116 [-1, 256, 14, 14] 0 Conv2d-117 [-1, 1024, 14, 14] 262,144 BatchNorm2d-118 [-1, 1024, 14, 14] 2,048 ReLU-119 [-1, 1024, 14, 14] 0 Bottleneck-120 [-1, 1024, 14, 14] 0 Conv2d-121 [-1, 256, 14, 14] 262,144 BatchNorm2d-122 [-1, 256, 14, 14] 512 ReLU-123 [-1, 256, 14, 14] 0 Conv2d-124 [-1, 256, 14, 14] 589,824 BatchNorm2d-125 [-1, 256, 14, 14] 512 ReLU-126 [-1, 256, 14, 14] 0 Conv2d-127 [-1, 1024, 14, 14] 262,144 BatchNorm2d-128 [-1, 1024, 14, 14] 2,048 ReLU-129 [-1, 1024, 14, 14] 0 Bottleneck-130 [-1, 1024, 14, 14] 0 Conv2d-131 [-1, 256, 14, 14] 262,144 BatchNorm2d-132 [-1, 256, 14, 14] 512 ReLU-133 [-1, 256, 14, 14] 0 Conv2d-134 [-1, 256, 14, 14] 589,824 BatchNorm2d-135 [-1, 256, 14, 14] 512 ReLU-136 [-1, 256, 14, 14] 0 Conv2d-137 [-1, 1024, 14, 14] 262,144 BatchNorm2d-138 [-1, 1024, 14, 14] 2,048 ReLU-139 [-1, 1024, 14, 14] 0 Bottleneck-140 [-1, 1024, 14, 14] 0 Conv2d-141 [-1, 512, 14, 14] 524,288 BatchNorm2d-142 [-1, 512, 14, 14] 1,024 ReLU-143 [-1, 512, 14, 14] 0 Conv2d-144 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-145 [-1, 512, 7, 7] 1,024 ReLU-146 [-1, 512, 7, 7] 0 Conv2d-147 [-1, 2048, 7, 7] 1,048,576 BatchNorm2d-148 [-1, 2048, 7, 7] 4,096 Conv2d-149 [-1, 2048, 7, 7] 2,097,152 BatchNorm2d-150 [-1, 2048, 7, 7] 4,096 ReLU-151 [-1, 2048, 7, 7] 0 Bottleneck-152 [-1, 2048, 7, 7] 0 Conv2d-153 [-1, 512, 7, 7] 1,048,576 BatchNorm2d-154 [-1, 512, 7, 7] 1,024 ReLU-155 [-1, 512, 7, 7] 0 Conv2d-156 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-157 [-1, 512, 7, 7] 1,024 ReLU-158 [-1, 512, 7, 7] 0 Conv2d-159 [-1, 2048, 7, 7] 1,048,576 BatchNorm2d-160 [-1, 2048, 7, 7] 4,096 ReLU-161 [-1, 2048, 7, 7] 0 Bottleneck-162 [-1, 2048, 7, 7] 0 Conv2d-163 [-1, 512, 7, 7] 1,048,576 BatchNorm2d-164 [-1, 512, 7, 7] 1,024 ReLU-165 [-1, 512, 7, 7] 0 Conv2d-166 [-1, 512, 7, 7] 2,359,296 BatchNorm2d-167 [-1, 512, 7, 7] 1,024 ReLU-168 [-1, 512, 7, 7] 0 Conv2d-169 [-1, 2048, 7, 7] 1,048,576 BatchNorm2d-170 [-1, 2048, 7, 7] 4,096 ReLU-171 [-1, 2048, 7, 7] 0 Bottleneck-172 [-1, 2048, 7, 7] 0 Conv2d-173 [-1, 256, 7, 7] 524,544 Conv2d-174 [-1, 256, 14, 14] 262,400 Conv2d-175 [-1, 256, 28, 28] 131,328 Conv2d-176 [-1, 256, 56, 56] 65,792 Conv2d-177 [-1, 256, 14, 14] 590,080 Conv2d-178 [-1, 256, 28, 28] 590,080 Conv2d-179 [-1, 256, 56, 56] 590,080 ================================================================ Total params: 26,262,336 Trainable params: 26,262,336 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.57 Forward/backward pass size (MB): 302.71 Params size (MB): 100.18 Estimated Total Size (MB): 403.47 ----------------------------------------------------------------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
查看FPN模型信息
if __name__ == '__main__':
model = FPN([3, 4, 6, 3])
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
# 遍历输出tuple中的每个元素,并打印其尺寸信息
for i, feature_map in enumerate(out):
print(f"Feature map {i} size: {feature_map.size()}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
打印信息如下:
FPN( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): Bottleneck( (bottleneck): Sequential( (0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (bottleneck): Sequential( (0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bottleneck): Sequential( (0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) ) (layer2): Sequential( (0): Bottleneck( (bottleneck): Sequential( (0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (bottleneck): Sequential( (0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bottleneck): Sequential( (0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (3): Bottleneck( (bottleneck): Sequential( (0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) ) (layer3): Sequential( (0): Bottleneck( (bottleneck): Sequential( (0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (bottleneck): Sequential( (0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bottleneck): Sequential( (0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (3): Bottleneck( (bottleneck): Sequential( (0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (4): Bottleneck( (bottleneck): Sequential( (0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (5): Bottleneck( (bottleneck): Sequential( (0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) ) (layer4): Sequential( (0): Bottleneck( (bottleneck): Sequential( (0): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) (downsample): Sequential( (0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Bottleneck( (bottleneck): Sequential( (0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) (2): Bottleneck( (bottleneck): Sequential( (0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (2): ReLU(inplace=True) (3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): ReLU(inplace=True) (6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False) (7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (relu): ReLU(inplace=True) ) ) (toplayer): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1)) (smooth1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (smooth2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (smooth3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (latlayer1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1)) (latlayer2): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1)) (latlayer3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1)) ) D:\Miniconda\envs\SINet_01\lib\site-packages\torch\nn\functional.py:3769: UserWarning: nn.functional.upsample is deprecated. Use nn.functional.interpolate instead. warnings.warn("nn.functional.upsample is deprecated. Use nn.functional.interpolate instead.") Feature map 0 size: torch.Size([1, 256, 56, 56]) Feature map 1 size: torch.Size([1, 256, 28, 28]) Feature map 2 size: torch.Size([1, 256, 14, 14]) Feature map 3 size: torch.Size([1, 256, 7, 7])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251

