
- 1重启iis,提示帐户名与安全标示间无任何映射_iis 帐户名与安全标识间无任何映射完成
- 2hive中case when的两种使用方法_hive case when
- 3基础数据结构11:哈希_hash.h
- 4Mac OS X、Linux和Windows设备连接至SFTP服务器的方法
- 5毕业一年后,他转行软件测试成功拿到9.5K薪资,直言互联网行业真香_男程序员转行做测试怎么样?
- 6kafka3.X集群安装(不使用zookeeper)_高版本的kafka可以不使用zookeeper
- 7【数据结构】堆的创建_堆构建
- 8读书笔记:人性的弱点读后感
- 9Hadoop3.1.3 伪分布式安装_opt/module/hadoop-3.1.3/libexec/hadoop-functions.s
- 10算法设计与分析(第二版)上机实验题——C语言实现_算法设计 c语言 csdn
基于Ambari的Hadoop集群的搭建(上)_ambari搭建hadoop集群
赞
踩
1选题功能要求
(1)学习并了解 Hadoop 相关基础知识,如 HDFS、YARN、MapReduce 的架构群组成及其相关操作等;
(2)学习并了解 Ambari 相关基础知识,如Ambari-agent、Ambari-server、Ambari-web 的内部架构组成及 Ambari 与 HDP 关系;
(3)掌握 Ambari 服务的安装、配置、启动、停止以及服务状态的查看;
(4)掌握使用 Ambari Web 界面安装与部署大数据组件,如管理 Hadoop 服务的启动和停止,监控每台节点机的服务状态;
(5)掌握 Hadoop 应用环境的测试和使用,对 Map Reduce 并行 wordcount计算编程模型进行测试,以验证基于 Ambari 的 Hadoop 集群的可用性。
2发展背景
随着信息技术的不断发展,现代社会的数据量已经呈现爆炸式增长,现代人类产生的数据量是古代人类的万倍以上,逐渐从互联网时代走向了大数据时代,云存储与云计算技术也成为人们关注的焦点,目前已成为很多领域不可或缺的一门技术。而云技术很大程度上依赖于由Apache开发的一种分布式的Hadoop平台,其在云计算和分布式存储方面表现出很大的优势,是一个用于处理大数据的优秀的分布式计算框架,在各大企业应用非常普遍。
由于Hadoop集群部署需要考虑各组件的兼容性、编译问题及繁琐的组件参数配置,其大数据实验环境搭建的复杂性已经成为很多分布式应用初学者或者大数据的业务应用开发者学习和研究大数据技术一道很难跨越的门槛。然而,Ambari支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeper、Hcatalog等的集中管理,是一种支持Hadoop集群部署、监控和管理的开源工具。针对Hadoop集群部署的复杂性,提出基于Ambari工具部署Hadoop集群各组件的实践方法并讨论了快速部署的若干要点及重要步骤;通过Ambari工具完成了Hadoop生态圈最小化集群大部分常用组件的快速部署,如HDFS、HBase、Hive、Pig、Oozie、Zookeeper、Sqoop、Spark、Storm、Kafka、Flume等;项目实践表明:利用Ambari工具能够在8h内部署完毕Hadoop集群,相比较传统手工部署方式,Ambari工具极大提高了Hadoop集群部署的效率及成功率。
3使用工具和相关环境介绍
3.1VMware
3.1.1VMware的简介
VMware全称为Vmware Workstation,是一款功能强大的电脑虚拟机软件,它可以帮助用户轻松的将一个或多个操作系统,它作为虚拟机运行,是一款能够在一台PC上同时运行多个不同的操作系统的软件。它们之间互不干扰,不会产生任何的问题,运行具有不同隐私设置、工具和网络连接配置的第二个安全桌面,或使用取证工具调查操作系统漏洞。而且,该软件还可帮助用户通过创建完全隔离的安全虚拟机来工作。这些虚拟机封装了操作系统及其应用程序,VMware虚拟化层将物理硬件资源映射到虚拟机的资源,因此每个虚拟机都有属于自己的CPU、内存、磁盘和I/O设备,完全等同于标准x86计算机。本课程中大数据集群的虚拟机需要安装的操作系统是centos7。CentOS 7是一个企业级的Linux发行版本,它源于免费公开的Linux源代码进行再发行。
3.1.2VMare的特点
Vmware Workstation允许操作系统(OS)和应用程序(Application)在一台虚拟机内部运行。虚拟机是独立运行主机操作系统的离散环境。在Vmware Workstation中,你可以在一个窗口中加载一台虚拟机,它可以运行自己的操作系统和应用程序。你可以在运行于桌面上的多台虚拟机之间切换,通过一个网络共享虚拟机(例如一个公司局域网),挂起和恢复虚拟机以及退出虚拟机,这一切不会影响你的主机操作和任何操作系统或者其它正在运行的应用程序。
3.2FinalShell
3.2.1FinalShell的简介
Final Shell是一体化的服务器,网络管理软件,不仅是ssh客户端,还是功能强大的开发,运维工具,充分满足开发,运维需求。同时支持Windows,MacOS和Linux,它不单单是一个SSH工具,完整的说法应该叫一体化的服务器,网络管理软件,在很大程度上可以免费替代XShell,是国产中不多见的良心产品,特色功能包括免费海外服务器远程桌面加速,ssh加速,双边tcp加速,内网穿透。
3.2.2 FinalShell的特点
(1)多平台支持 Windows,Mac OS X,Linux;
(2)多标签,批量服务器管理;
(3)支持登录 Ssh 和 Windows 远程桌面;
(4)shell,sftp 同屏显示,同步切换目录;
(5)命令自动提示,智能匹配,输入更快捷,方便;
(6)sftp 支持,通过各种优化技术,加载更快,切换,打开目录无需等待;
(7)服务器网络,性能实时监控,无需安装服务器插件;
(8)内存,Cpu 性能监控,Ping 延迟丢包,Trace 路由监控;
(9)实时硬盘监控;
(10)进程管理器;
(11)快捷命令面板,可同时显示数十个命令;
(12)内置文本编辑器,支持语法高亮,代码折叠,搜索,替换;
(13)ssh 和远程桌面均支持代理服务器;
(14)打包传输, 自动压缩解压。
3.3 HADOOP
3.3.1 HADOOP 的简介
Hadoop 是 Apache 下的一个开源项目,由 HDFS、MapReduce、HBase、Hive 和 ZooKeeper 等项目组成。Hadoop 平台具有高可伸缩性、低成本、高可靠、方便易 用等特点,Hadoop的核心思想是分布式并行处理。Hadoop技术中的关键技术是HDFS(分布式文件系统)和 Map/Reduce(映射/规约)。HDFS 提供海量数据分布 式存储, Map Reduce 实现分布式计算。
3.3.2 HADOOP 的特点
(1)高可靠性。 Hadoop 按位存储和处理数据的能力值得人们信赖。
(2)高扩展性。Hadoop 是在可用的计算机集簇间分配数据并完成计算任务
的,这些集簇可以方便地扩展到数以千计的节点中。
(3)高效性。 Hadoop 能够在节点之间动态地移动数据, 并保证各个节点的 动态平衡,因此处理速度非常快。
(4)高容错性。 Hadoop 能够自动保存数据的多个副本, 并且能够自动将失
败的任务重新分配。
(5)低成本。与一体机、商用数据仓库以及 QlikView、Yonghong Z-Suite
等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
3.4 HDFS
3.4.1 HDFS 的简介
HDFS作为Hadoop底层的分布式文件系统,有着高容错性的特点,并且设计部署在低廉的硬件上,提供高吞吐量访问应用程序的数据,适合超大数据集的传输与应用。HDFS采用主从(Master/Slave)架构,一个HDFS集群由一个NameNode和多个DataNode组成。NameNode负责文件系统的名字空间的操作,DataNode负责处理客户端的读写请求。用户请求创建文件的指令由NameNode进行接收,NameNode将存储数据的DataNode的IP返回给用户,并通知其他接收副本的DataNode,由用户直接与DataNode进行数据传送。
3.4.2HDFS的特点
(1)高容错性。数据自动保存多个副本,通过增加副本的形式,提高容错性。
(2)适合批处理。它是通过移动计算而不是移动数据。它会把数据位置暴
露给计算框架。
(3)适合大数据处理。数据规模、文件规模、节点规模极大。
(4)流式数据访问。它能保证数据的一致性。
(5)一次写入,多次读取,不能修改,只能追加。
(6)可构建在廉价机器上。如普通PC、Linux系统上。
3.5 HDP
3.5.1 HDP的简介
HDP全称是Hortonworks Data Platform,是由一家美国大数据公司Hortonworks开发的企业级Hadoop平台,是hortonworks的软件栈,里面包含了hadoop生态系统的所有软件项目,比如HBase,Zookeeper,Hive,Pig等等。Hortonworks致力于帮助客户利用Hadoop开源大数据平台管理数据。HDP是完全在开源的环境下设计、开发和构建的,它以YARN作为其架构中心,该平台支持一系列处理方法一一批处理、交互式处理、实时处理。
3.5.2 HDP的功能
HDP的功能包括数据管理、数据访问、数据管制与集成、运营、安全性。
3.6 Ambari
3.6.1 Ambari 的简介
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、HBase、Zookeeper、Sqoop等。Ambari框架采用Server/Client模式,主要由 Ambari-Server、Ambari-Agent、Ambari-Common、Ambari Web和Ambari-Views 等组成。其中Ambari-Server和Ambari-Agent为Ambari框架的核心。在Ambari系统架构中,Ambari-Server 开放的Rest API为Ambari-Web提供监控管理服务,并且与Ambari-Agent交互,接受Ambari-Agent向Ambari-Server发送心跳请求。
3.6.2 Ambari 的功能
(1)通过一步一步的安装向导简化了集群供应;
(2)预先配置好关键的运维指标(metrics),可以直接查看Hadoop Core
(HDFS 和 MapReduce)及相关项目是否健康;
(3)支持作业与任务执行的可视化与分析,能够更好地查看依赖和性能;
(4)通过一个完整的RESTFUL API把监控信息暴露出来,集成现有的运维
工具;
(5)用户界面非常直观,用户可以轻松有效地查看信息并控制集群。
4基础环境搭建
4.1 软件环境
表 4‑1 软件环境
| 软件名称 | 版本号 |
| VMWARE | 17.0 |
| FINALSHELL | |
| JDK | 1.8.0_171 |
| AMBARI | |
| HDP | |
| HDP-UTILS | |
| MySQL | 1.5.7 |
4.2 硬件环境
表 4‑2 硬件环境
| IP 地址 | 操作系统 | 主机名 | 节点类型 |
| Centos-7 | hdp01 | 主节点 | |
| Centos-7 | hdp02 | 从节点 | |
| Centos-7 | hdp03 | 从节点 |
4.3 修改主机名和配置 FQDN
(1)搭建三台虚拟机并完成基本配置
搭建三台名称分别为 hdp01、hdp02、hdp03 的三台虚拟机, 内存设置为 4112M, 硬盘容量越大越好,考虑到后续 HDP 和 ambari 下载和解压所需内存的问题,将 内存设置为 100G,CPU 设置为默认值 1C。
(2)修改主机名(三台主机分别修改主机名)
vi /etc/hostname #将内容改为 hdp01,保存退出
#其余两台机器完成同样操作,内容分别为 hdp02、hdp03
(3)vi /etc/sysconfig/network #编辑 i 键插入
NETWORKING=yes
HOSTNAME=hdp01.bigdata.com

图 4-1FQDN 配置内容
# 其余两台机器完成同样操作,HOSTNAME的内容不同分别为 hdp02.bigdata.com、hdp03.bigdata.com
4.4 配置网卡
(1)vi /etc/sysconfig/network-scripts/ifcfg-ens33
#修改配置文件
BOOTPROTO=static
ONBOOT=yes
#添加以下内容
IPADDR=192.168.111.175
GATEWAY=192.168.222.2
NETMASK=255.255.255.0
DNS1=192.168.111.175
DNS2=8.8.8.8
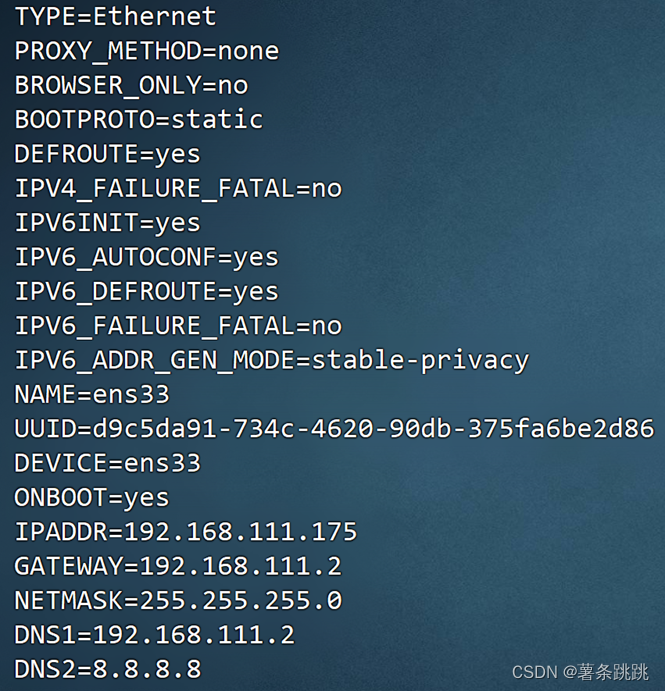
图 4-2 网卡配置内容
(2)重新启动网络配置
service network restart
# 看到 Restarting network (via systemctl): [ OK ] 为成功

图 4-3 网络服务重启成功
4.5 关闭防火墙
systemctl stop firewalld # 关闭防火墙
systemctl disable firewall # 关闭防火墙开机自启
systemctl status firewalld #通过此命令查看防火墙状态
注意:在三台虚拟机上都要关闭防火墙!(这里以 ntp01 为例)
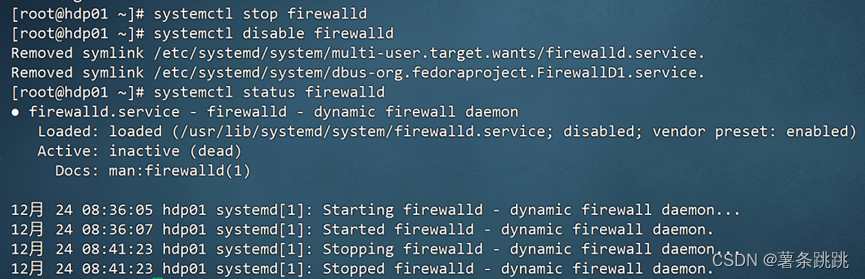
4-4 关闭防火墙
4.6 进行 NTP 时间同步
注意:选一台服务器作时间服务器,这里以 hdp01 作为时间服务器,其他
服务器以时间服务器时间为准。
(a)hdp01(时间服务器)
(1)安装 ntp 服务
yum install -y ntp
图 4-5 安装 ntp 服务
(2)修改 ntp 配置文件
vi /etc/ntp.conf
#设置允许 hdp02 和 hdp03 机器可以从这台机器上查询和同步时间
restrict hdp02 mask 255.255.255.0 nomodify notrap
restrict hdp03 mask 255.255.255.0 nomodify notrap
# 注释以下代码
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
# 添加以下代码(当该节点丢失网络连接, 依然可以采用本地时间作为时间#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
# 添加以下代码(当该节点丢失网络连接, 依然可以采用本地时间作为时间
服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
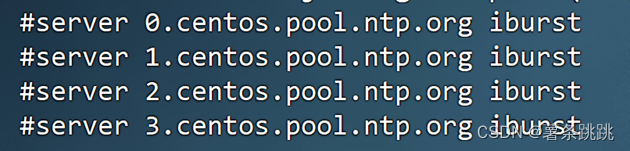
图 4-6 在 ntp 配置文件中注释代码

图 4-7 在 ntp 配置文件中添加代码
(3)启动 ntp 服务并设置开机自启
systemctl start ntpd # 启动 ntpd 服务
systemctl enable ntpd# 配置 ntpd 服务开机自启
(b) hdp02、hdp03
(1)安装 ntpdate 服务
yum install -y ntpdate
(2)同步时间
ntpdate hdp01
(3)定时同步时间
crontab -e
# 添加如下内容
29,59 * * * * /usr/sbin/ntpdate hdp01# 每小时的第 29 分和 59 分同步
一次时间

图 4-8 添加定时同步时间的代码
4.7 修改并查看主机 selinux 状态
注意:在三台虚拟机中都执行以下操作,此处以 hdp01 为例
(1)vi /etc/selinux/config
SELINUX=disabled # 修改执行该命令后重启机器生效
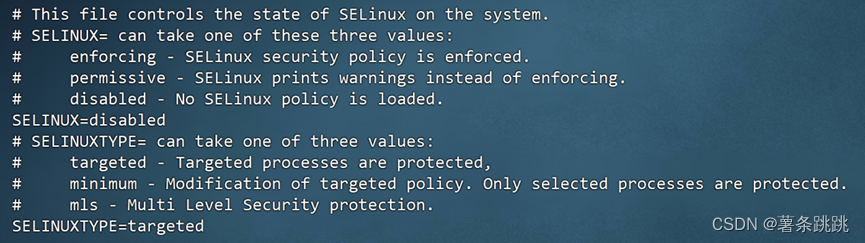
图 4-9 修改 selinux 状态
(2)重启系统
shutdown -r now
图 4-10 重启系统
(3)查看 selinux 状态
getenforce

图 4-11 查看 selinux 状态
4.8 SSH 免密登陆配置
注意:在三台虚拟机中都执行以下操作,此处以 hdp01 为例
(1)生成公钥和私钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
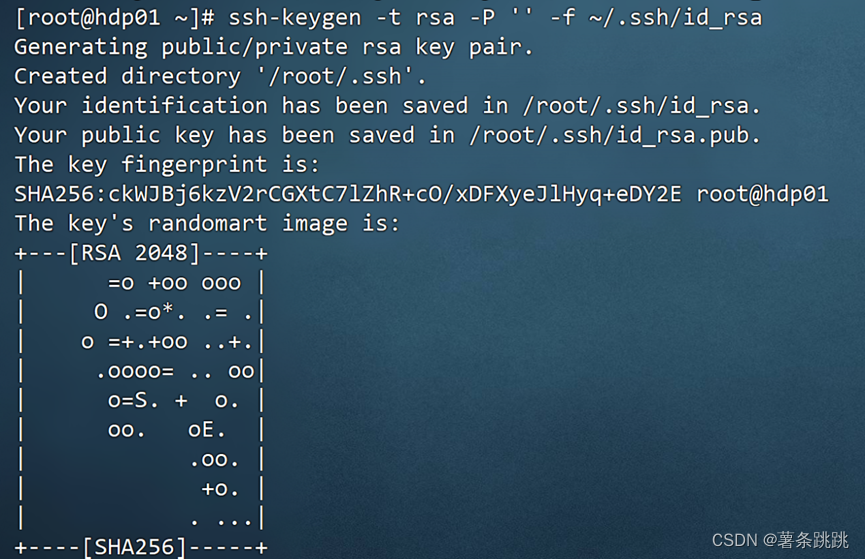
图 4-12 生成公钥和私钥
(2)合并公钥包
(a)cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(b)chmod 600 ~/.ssh/authorized_keys

图 4-13 合并公钥包
(3 ) 把 各 个 主 机 上 公 钥 id_rsa.pub 文 件 内 容 放 到 各 个 主 机authorized_keys 中
(a)将远程 id_rsa.pub 文件发送到除本机外的其他主机
# hdp01
scp ~/.ssh/id_rsa.pub root@192.168.222.172:/root/.ssh/
id_rsa.pub.hdp01
scp ~/.ssh/id_rsa.pub root@192.168.222.173:/root/.ssh/
id_rsa.pub.hdp01
# hdp02
scp ~/.ssh/id_rsa.pub root@192.168.222.171:/root/.ssh
/id_rsa.pub.hdp02
scp ~/.ssh/id_rsa.pub root@192.168.222.173:/root/.ssh
/id_rsa.pub.hdp02
# hdp03
scp ~/.ssh/id_rsa.pub root@192.168.222.172:/root/.ssh
/id_rsa.pub.hdp03
scp ~/.ssh/id_rsa.pub root@192.168.222.171:/root/.ssh
/id_rsa.pub.hdp03
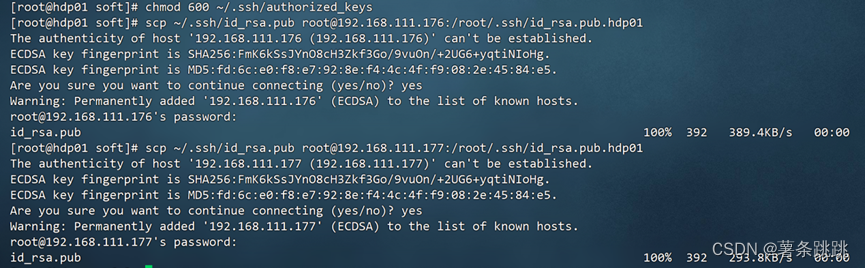
图 4-14 将远程 id_rsa.pub 文件发送到除本机外的其他主机
(b)再次合成公钥包
# hdp01
cat ~/.ssh/id_rsa.pub.hdp02 >> ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub.hdp03 >> ~/.ssh/authorized_keys
# hdp02
cat ~/.ssh/id_rsa.pub.hdp01 >> ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub.hdp03 >> ~/.ssh/authorized_keys
# hdp03
cat ~/.ssh/id_rsa.pub.hdp02 >> ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub.hdp01 >> ~/.ssh/authorized_keys

图 4-15 再次合成公钥包
(4)测试是否可以相互 SSH 成功
ssh hdp01
exit
ssh hdp02
exit
ssh hdp03
exit
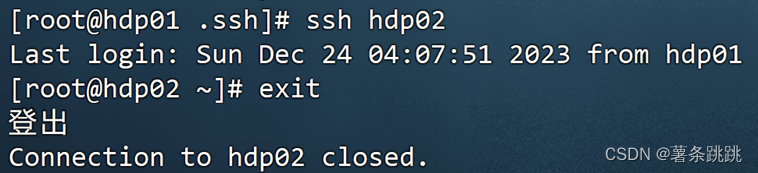
图 4-16 测试是否可以相互 SSH 成功
4.9 安装 JDK8
注意:三台机器上都要安装!(这里以 hdp01 为例)
(1)上传并解压压缩包
mkdir -p /opt/soft
mkdir -p /usr/java
cd /opt/soft
ls
tar -zxvf jdk-8u171-linux-x64..gz -C /usr/java
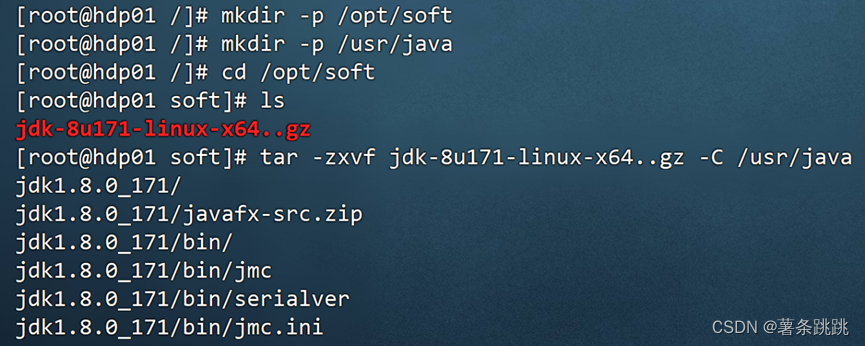
图 4-17 上传并解压压缩包
(2)配置环境变量
vi /etc/profile
# MY JAVA-------------------------------------------------------- export JAVA_HOME=/usr/java/jdk1.8.0_171
export CLASSPATH=.:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin

图 4-18 配置环境变量的内容
(3)更新配置
source /etc/profile
(4)验证 jdk 是否安装成功
[root@hdp01 ~]# java -version
#得到如下结果:
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)

图 4-19 验证 jdk 是否安装成功
4.10 MySQL 数据库安装
注意:只在 hdp01 上安装 MySQL 服务器
(1) 安装 MySQL 服务器
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 #补丁
![]()
图 4-20 安装 MySQL 补丁
rpm -ivh mysql57-community-release-el7-8.noarch.rpm
yum -y install mysql-community-server

图 4-21 安装 MySQL 服务器
(2)MySQL 数据库设置
systemctl daemon-reload #重载被 MySQL 安装修改了的文件
systemctl start mysqld.service #启动 MySQL
systemctl status mysqld.service #查看 MySQL 运行状态
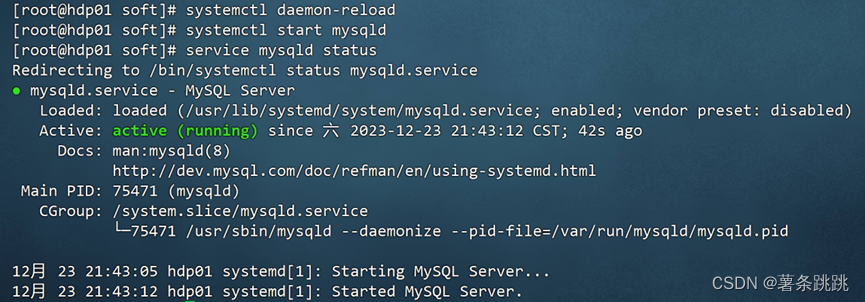
图 4-22 MySQL 数据库设置
grep "password" /var/log/mysqld.log #查密码
![]()
图 4-23 查密码
mysql -uroot –p # 回车后提示输入密码,粘贴临时密码
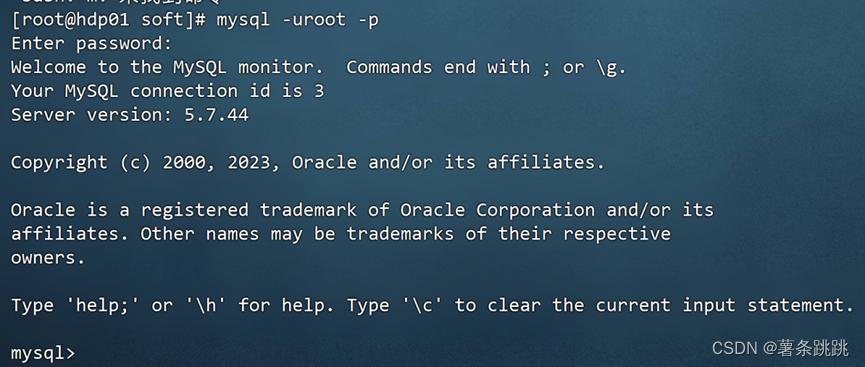
图 4-24 回车后提示输入密码,粘贴临时密码
(3)MySQL 修改密码
(a)MySQL 修改密码权限
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=1;
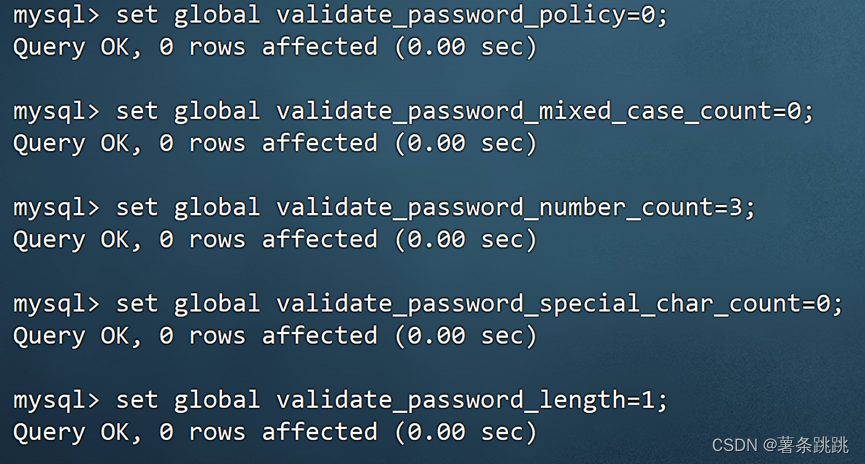
图 4-25 MySQL 修改密码权限
(b) MySQL 修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';

图 4-26 MySQL 修改密码
(4)配置远程登录
mysql>create user 'root'@'%' identified by'123456';
mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION; # 然后刷新权限
mysql>flush privileges;
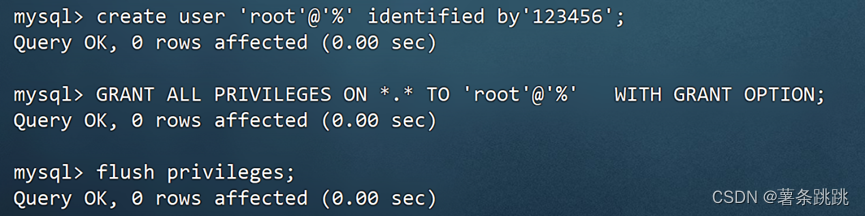
图 4-27 配置远程登录
(5)验证远程登录配置成功
mysql>use mysql; 查看 mysql 的服务器与用户
mysql>select host, user from user;
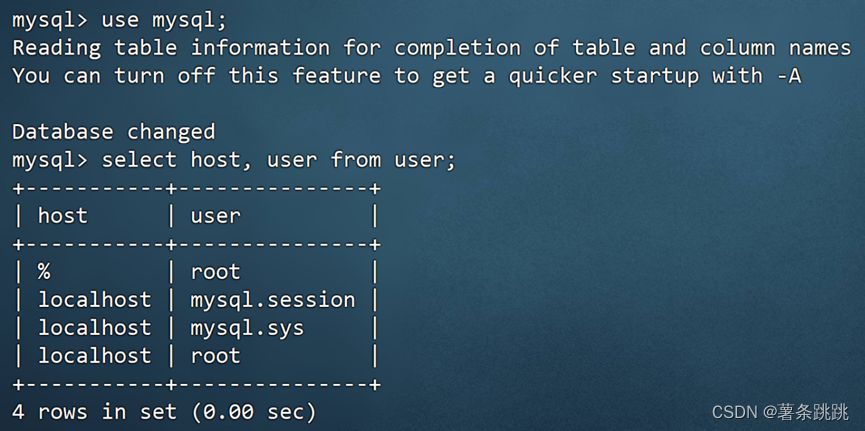
图 4-28 验证远程登录配置成功
(6)创建 ambari 数据库
mysql>create database ambari character set utf8 ;
mysql>CREATE USER 'ambari'@'%'IDENTIFIED BY 'Ambari-123'; mysql>GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'%';
mysql>FLUSH PRIVILEGES;
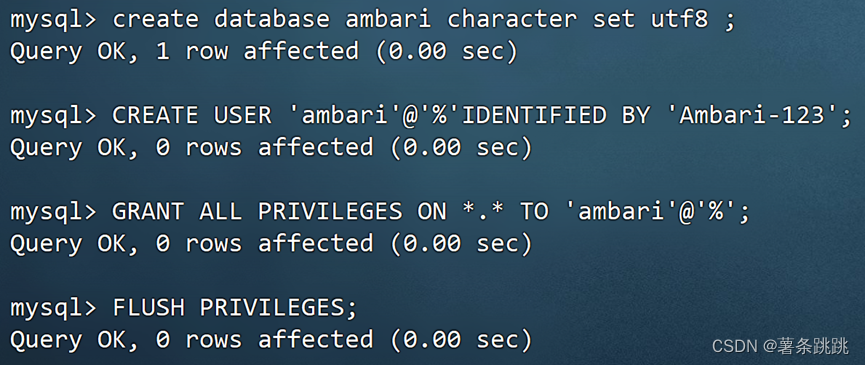
图 4-29 创建 ambari 数据库
(7)安装 mysql-connector-java
yum install mysql-connector-java
图 4-30 安装 mysql-connector-java
4.11 检查并修改最大打开文件描述符数量
注意:在三台机器上都执行!(此处以 htp 为例)
ulimit -Sn
ulimit -Hn
ulimit -n 10000
图 4-31 检查并修改最大打开文件描述符数量

