
- 1判断list集合中是否包含某个元素_判断list包含某个元素
- 2AI:人工智能领域之大模型部署两大设计方案(本地搭建服务器+调用云厂商服务)、服务器和硬件相关技术的简介(GPU/TPU、GeForce【3090-4090】/Tesla【A800-A100/V100_ai服务器 方案
- 3submodule切换分支_Git-Submodule使用
- 4STM32利用软件I2C通讯读MPU6050的ID号
- 5数据结构:查找与排序
- 6Golang面试题——基础知识_golang基础试题
- 7Ether.js和Web3.js的比较_web3.js ethers.js
- 8【每日短科普】AI中的深度学习、NLP、GANs承当了那些作用呢!?
- 9第二章 西门子数控机床采集方案_西门子840dsl 通过opcua读取
- 10软件提示应用程序无法启动,因为应用程序的并行配置不正确……_无法加载 dll“runtimecorenet100_15.dll”: 应用程序无法启动,因为应用程
OCR多模态模型Vary的论文阅读笔记_ocr vary
赞
踩
项目github地址 https://github.com/Ucas-HaoranWei/Vary
论文地址 https://arxiv.org/pdf/2312.06109.pdf
项目主页 Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models

一、提前的知识
clip模型的原理理解
这个模型是基于clip模型的范式的,因此我们先简单了解一下clip模型的构成。
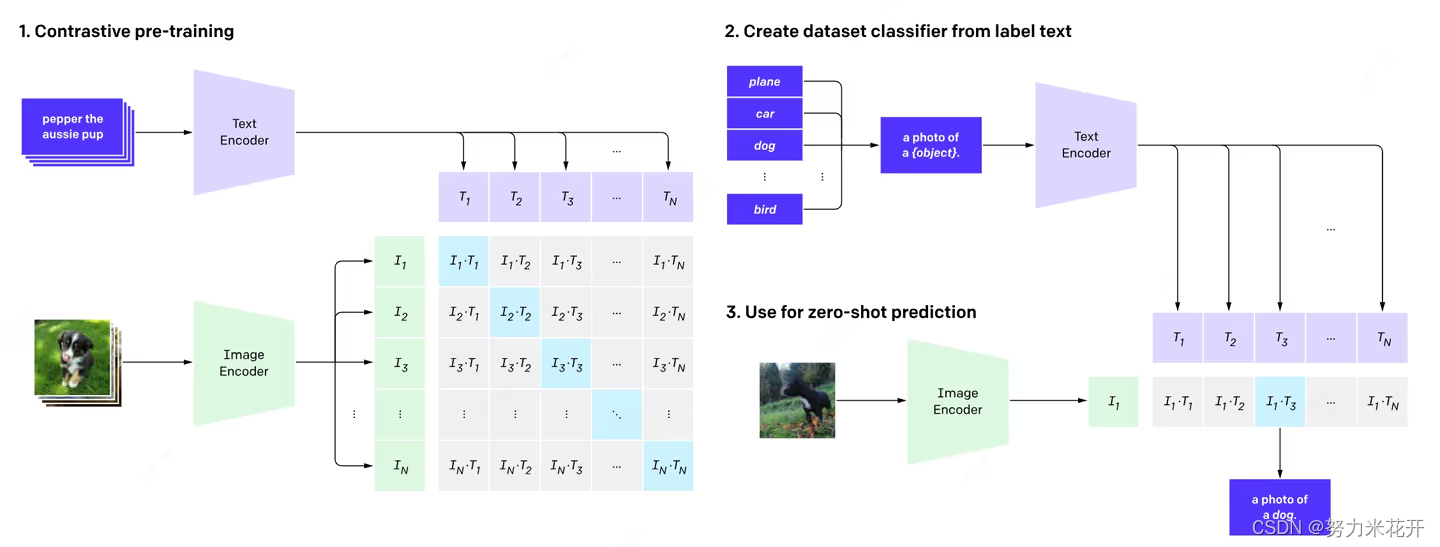
简单的概括clip模型(CLIP 模型解读 - 知乎)
- 用图像编码器把图像编码成向量 a;
- 用文本编码器把文本编码成向量 b;
- 计算 a·b,
- 如果 a 和 b 来自一对儿配对的图和文字,则让 a·b 向 1 靠近;
- 如果 a 和 b 来自不配对儿的图和文字,则让 a·b 向 0 靠近;
clip模型中的text encoder和image encoder展开可以分别分为两个部分,以文本为例,其实可以分为一个text vocabulary,将纯文本首先通过text vocabulary词表得到每个词对应的text ID,然后进行text embedding得到text tokens;类似的image encoder也可以从概念上理解成一个vision vocabulary模块和image embedding模块,得到image tokens,当然这里的vision vacabulary是隐性的。最后clip对齐image token和text tokens的长度,然后计算图片向量和文本向量之间的相似度来判断图片文本之间是否是相似的。
这里需要着重理解一下vision vocabulary这个概念。text vocabulary是显式的,我们可以直接通过bpe等算法得到一批训练预料合适的text vocabulary,如果出现新的单词不在训练预料的text vocabulary中,那么我们说这些文本是out of vocabulary的。那么对于图片来说呢,如果一种图片风格不在原本的训练预料图片风格中(比如原本是采用风景动物等图片做训练,结果出现一个文档图片,需要text encoder来学习文本图片里面的内容,那么我们直观可以认为这也是一种vision vocabulary的out of vocabulary. vision vocabulary可以理解为一个训练好的视觉模型,它能够稳定表示的那些图片。对于不在这个训练集风格范围内的图片,就会泛化能力差,因此这些图片也可以被认为是out of vocabulary.
多模态的传统形式
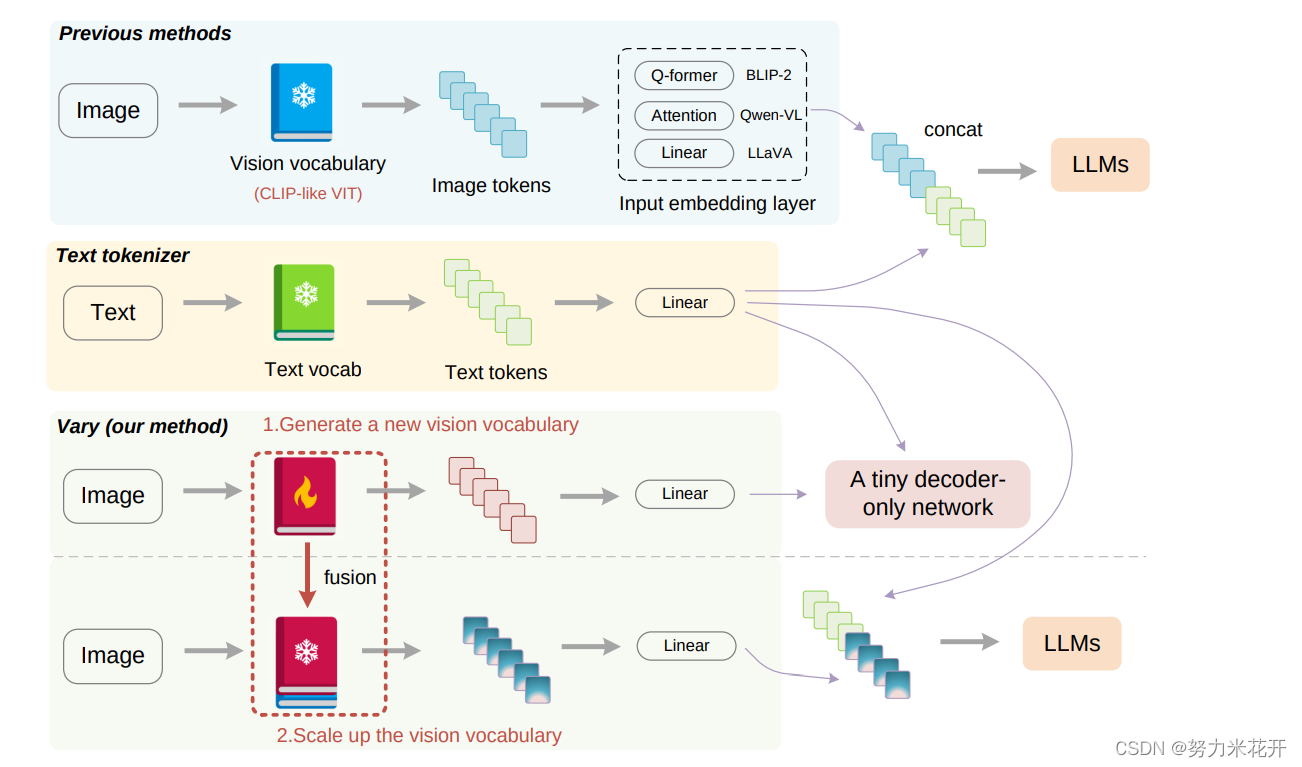
上面两张子图就是多模态的传统形式了。在传统的模式中,首先一个text vocabulary用来处理prompt,然后用text embedding得到text tokens;对于输入的图片,通过vision vocabulary之后叠加一个image embedding来处理输入的image。处理完成的两个tokens对齐之后输入一个大模型实现下游的任务。比如描述图片的内容,分析图中有几个人等等多模态任务。
如果我们想做密集文本或者图标的多模态任务,那么为什么不能直接在原始的vision vocabulary network上进行训练?
1. 训练容易让模型覆盖原始的vocabulary,大概率会遗忘通用的image encoder能力
2. 原始模型是vision vocabulary之后叠加一个大模型,在这种模式下,不容易训练前面的vision vocabulary,训练效率低
3. 一般在大模型训练中不支持迭代多次训练,因为大模型的超强记忆能力,容易导致模型的过拟合。
VARY提供的vision vocabulary训练方法
这里采用的text vocabulary/vision vocabulary/text embedding/vision embedding模块一般是预训练完成的。如果我们希望扩充下游任务,且这个下游任务的图片和预训练任务中的希望扩充vision vocabulary怎么办?这里vary提供了一种范式:
1. 生成新的vision vocabulary: 首先训练一个生成式自回归的图片生成文本的模型;
2. 融合旧的vision vocabulary模型,训练基础模型和下游任务: 然后把这个模型的vision vocabulary部分拎出来,将这个部分和原本的vision vocabulary一起组成一个新的vision vocabulary,用这个vision vocabulary来作为image encoder的一部分,继续按照传统的多模态范式,进行模型的pretrain/sft和下游任务的训练。
vary的主要内容就是上面提到的两个模型。下面展开说说每个模型的训练模型、训练目标、训练数据、输入和输出信息。
二、模型方案
2.1 生成新的vision Vocabulary模型
2.1.1 模型结构
这个模型在论文中被称为 vary tiny.整个模型的结构如下所示
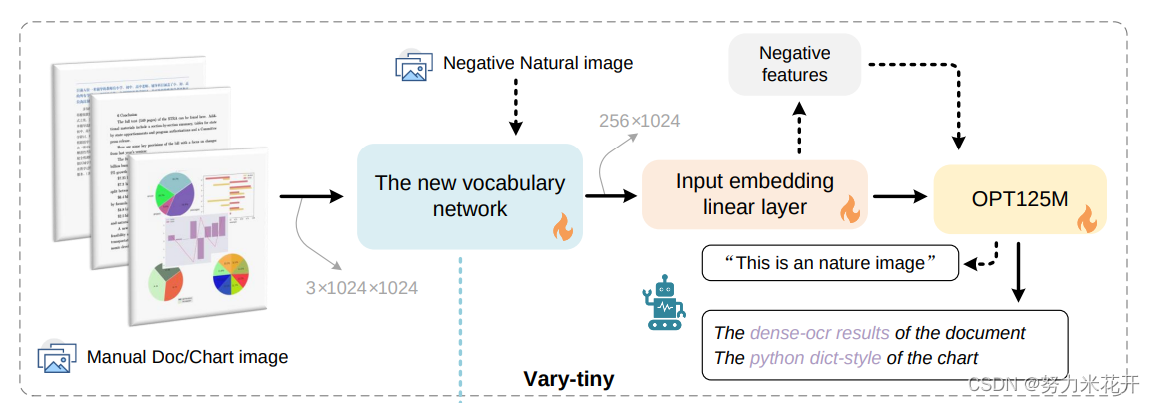
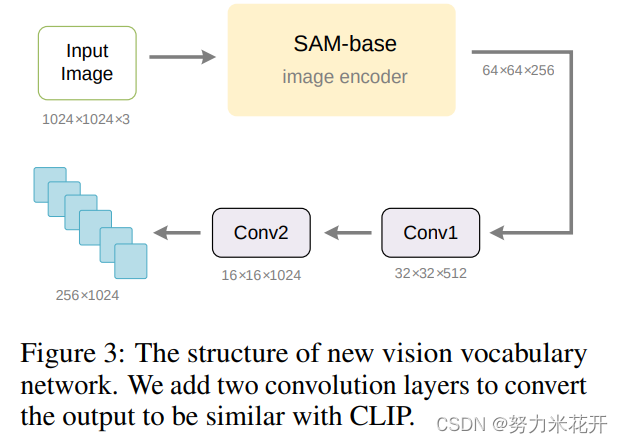
1. 一个基于SAM预训练的VitDet模型作为vision vocabulary network;输入的input size 为3*1024*1024;输出的维度为64*64*256;
2. Input embedding linear layer 用于将前面得到的64*64*256的image tokens对齐CLIP-L的输出维度 256*1024。本质是叠加了两个卷积层。具体看下面的结构图
3. OPT-125M模型作为一个decoder-only的自生成模型,生成输出结果。
2.1.2 训练输出规范
输入文本图片,输出文本图片中的密集ocr内容
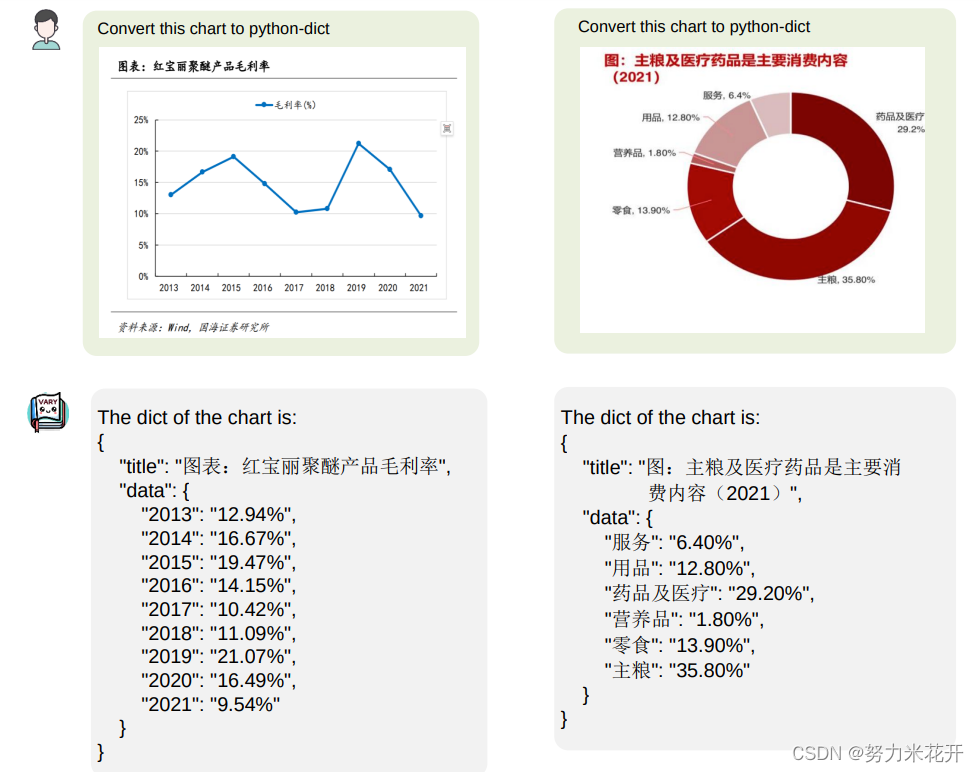
输入图表,输出图表的字典格式的
输入一张自然图片,输出"It’s an image of nature"; "Here’s a naturepicture"; "It’s a nature photo"; "This is a natural image"; "That’s a shot from nature"
2.1.3 训练数据来源
1. (未开源,需要自行收集整理制作)文本图片:需要高质量的密集文本图片-文字对;作者自行收集了arXiv上和CC-MAIN-2021-31-PDFUNTRUNCATED上的英文pdf;中文电子书;然后通过pdf2image转为图片;通过fitz转出每页的文本;一共收集转换了一百万中文训练集,一百万英文训练集。
2. (未开源,需要自行收集整理制作)表格图片:作者发现现有的模型不能很好的理解表单数据,尤其是中文表单。因此训练vision vocabulary的时候也采用的表单数据。应该是自行制造了25万中文表单图片-文本对和25万英文表单图片-文本对。表单中的文本信息通过自然语言随机生成。
3.(开源,可以直接用)自然图片:选择了coco中的12万图片。
2.1.4 训练细节
1024*1024*3的图片,batchsize=512;训练3epoch
2.1.5 训练目的
这轮训练的目标是提取训练之后模型里面的vision vocabulary network模块。这里通过充分的文档训练,vision Voabulary模块可以适应并有效的提取文档的image tokens
2.2 融合旧的vision vocabulary模型
在上面一轮训练中,得到了新的能够适应文本和表单的vision vocabulary,接下来就是将这个vision vocabulary融合到多模态大模型中。
2.2.1 模型结构
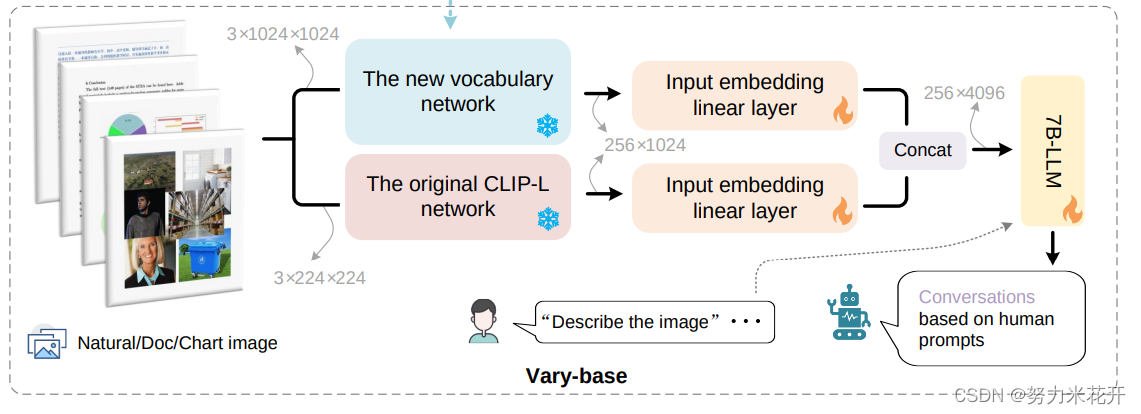
这里的融合方式是新的vision vocabulary和旧的clip-L 模型独立并行,然后将输出结果进行融合,最终输入到大模型中去。这样不会干扰原本的vision vocabulary的能力*(也就是这里的CLIP-L network),在训练阶段,new vocabulary network和CLIP-L network的权重都是冻结的,然后训练其他的层。
大模型的选择,中文效果较好的话,选择了QWen-7B;英文效果的话,选择Vicuna-7B
2.2.2 训练数据来源
1. 2.1.3中提到的数据
2. (未开源)生成Latex格式的文档:从arxiv上收集tex后缀的源文件,然后从源文件中通过正则抽取biaoge/公式、纯文本;然后通过pdflatex实现重新版面排布。一共收集了10+模板来生成新文本,一共生成了50万英文文本和40万中文文本
3. (未开源)表单数据:2.1.3中的表单数据是没有上下文语义信息的,因为是随机生成的文本。但是在这里因为需要分析表单数据,因此表单数据需要具有比较强的文本关联能力,因此使用GPT-4,输入相关的语料上下文,生成表单信息。一共生成了20万表单图片和文本对信息
4. (开源)通用数据:从LAION-COCO中收集400万图片-文本对用于预训练,在SFT阶段采用了 LLaVA-80k、LLaVA-CC665k、DocVQA,ChartQA数据。这些数据都是开源的。
2.2.3 训练任务
这里的训练需要分两步走,首先是预训练任务。
预训练任务采用训练数据1、2、3、4的通用数据实现。
sft任务通过微调DocVQA, ChartQA数据实现。
2.2.4 训练细节
预训练:固定CLIP-L和new vision vocabulary的权重,全量训练其余的全部的权重。batchsize-size=256,预训练一个epoch
sft:batchsize-size=256,预训练一个epoch
结语
论文后面附带了一些实验效果和demo演示效果。vary项目的主页本身提供了可以试用的demo页面,但是很可惜,1月17日的时候尝试打开已经打不开了。github主页上也删除了可以下载权重的地方。目前无法实际测试真实的效果。
从模型的训练结构上看,还是比较清晰的训练步骤。难度在于用于训练image vocabulary的数据和训练多模态大模型的数据都没有开源,因此如果需要复现的话,数据整理的难度较大。
其次是训练代码,目前看来这个训练代码在没有中间权重提供的情况下,很难运行起来,需要进行一定的修改,而且如果需要在多张GPU卡上并行训练,这个代码需要进行改动。

