
- 1机器学习鸢尾花各种模型准确率对比
- 2Python 手写数字识别的实现(pytorch框架) 超详细版本-jupyter notebook_pytorch手写数字识别
- 3双积分型ADC工作原理_双积分ad转换器工作原理简述
- 4软件测试只会“点点点”,凭什么让开发看的起你?_字节做测试是点点点吗
- 5免费PPT网站,这三个就够了_cilipa
- 6Arduino ESP32 基于Web服务端对SD卡网页式文件管理
- 7Intellij IDEA 初学入门图文教程(八) —— IDEA 在提交代码时 Performing Code Analysis 卡死_analyzing code卡住
- 8在Windows下用navicat,连接虚拟机的MySQL_window navicat
- 9KingbaseES数据库insert技巧_数据库insert怎么用
- 10pycharm + conda 安装tensorflow 与 keras环境_from keras.utils import np_utils要加什么包
分布式集群——搭建Hadoop环境以及相关的Hadoop介绍_hadoop集群
赞
踩
系列文章目录
分布式集群——搭建Hadoop环境以及相关的Hadoop介绍
文章目录
IV、SecondaryNameNode节点【辅助管理员信息】
前言
本文主要介绍hadoop的相关概念以及在Linux上面配置Hadoop的具体操作。
一 hadoop的相关概念
1.1 Hadoop概念
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,HDFS、MR、Yarn三个重要的组件组 成。HDFS是GFS的实现(论文必须会),Hadoop的MR是MR的实现(论文稍微了解一下)。

分片是客户端做的,专门的机器来接受请求,真正存节点的是客户端和datanode。
客户端建立通道上传,一次64k上传。存在缓存区。
切片是客户端负责切片,物理上分块,2.0以上为128M以上
目录信息在专门的机器上面,有两处存放位置【硬盘+内存】
读写文件时客户端与机器之间操作
文件需要嵌套缓冲流,
补充:块的存储
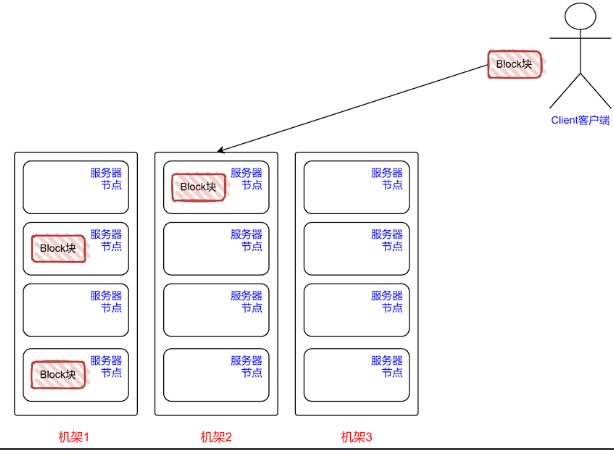
通过机架感知原理 + 网络拓扑结构实现副本摆放
-
第1个副本:优先本机存放,否则就近随机
-
第2个副本:放在与第1个副本就近不同机架上的某一个服务器
-
第3个副本:与第2个副本相同机架的不同服务器。
-
如果还有更多的副本:随机放在各机架的服务器中。
1.2 HDFS是什么
分布式文件系统,适合一次写入,多次查询的情况。不支持并发写,不适用于小文件存储【小文件内容1M,但是存放的时候依旧为128M】。低时延的数据访问。
重要的三个节点
-
NameNode节点
-
DataNode节点
-
SecondaryNameNode节点【辅助源操作信息】
1.3 三种节点的功能
I、NameNode节点
NameNode节点:
-
NameNode负责存储数据文件的元数据
-
NameNode负责管理文件系统目录结构。接受客户端的文件操作请求。
NameNode维护两套数据:
-
一套是文件目录与数据块之间的对应关系【静态】
-
一套是数据块与存储节点之间的对应关系【动态】
前一套数据是静态的,存放在磁盘上,通过fsimage和edits【编辑日志文件】文件来维护;
后一套是动态的,在集群重启时会在内存自动建立这些信息。
-
其中fsimage存储的是某一时段NameNode内存元数据信息(配置时通过hdfs-default.xml中的dfs.name.dir选项设置);【整个文件系统的目录结构以及文件相关信息】
-
edits记录操作日志文件(配置时通过hdfs-default.xml的dfs.name.edits.dir选项设置);fstime保存最近一次checkpoint的时间。
II、fsimage与edits文件存放的内容介绍
-
fsimage:镜像文件实际是存放的目录结构、文件属性等相关信息,是NameNode中关于 元数据的镜像。它是在NameNode启动时对整个文件系统的快照。
-
edits:编辑日志文件,记录对文件或者目录的修改信息,比如删除目录,修改文件等信 息。编辑日志一般命名规则是“edits_*”,它在NameNode启动后,记录对文件系统的改动 序列。
edits文件存放的是hadoop文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
fsimage和edits文件都是经过序列化的,在NameNode启动的时候,它会将fsimage文件中的所有内容加载到内存中,之后再执行edits文件中的各项操作。使得内存中的元数据和实际的数据同步,存在内存中的元数据支持客户端的读操作。
III、DataNode节点
DataNode负责按Block存储数据文件。每一个数据文件都会按照Block大小进行划分。每个Block都会进行多副本备份(一般为三份),通常多个副本会按照一定的策略(机架感知策略)放在不同的DataNode节点上。
IV、SecondaryNameNode节点【辅助管理员信息】
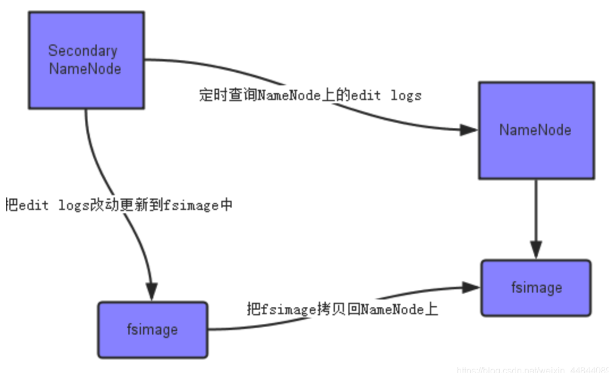
SecondaryNameNode作为NameNode的冷备份。负责合并NameNode上的fsimage和edits文件。集群启动会交给namenode存到内存里面。
SecondaryNameNode的本质作用是辅助NameNode进行fsimage和editlogs的合并操作。
-
首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[注:Secondary NameNode自己的fsimage]
-
一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
-
NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
1.4 HDFS的读写流程
1、读操作
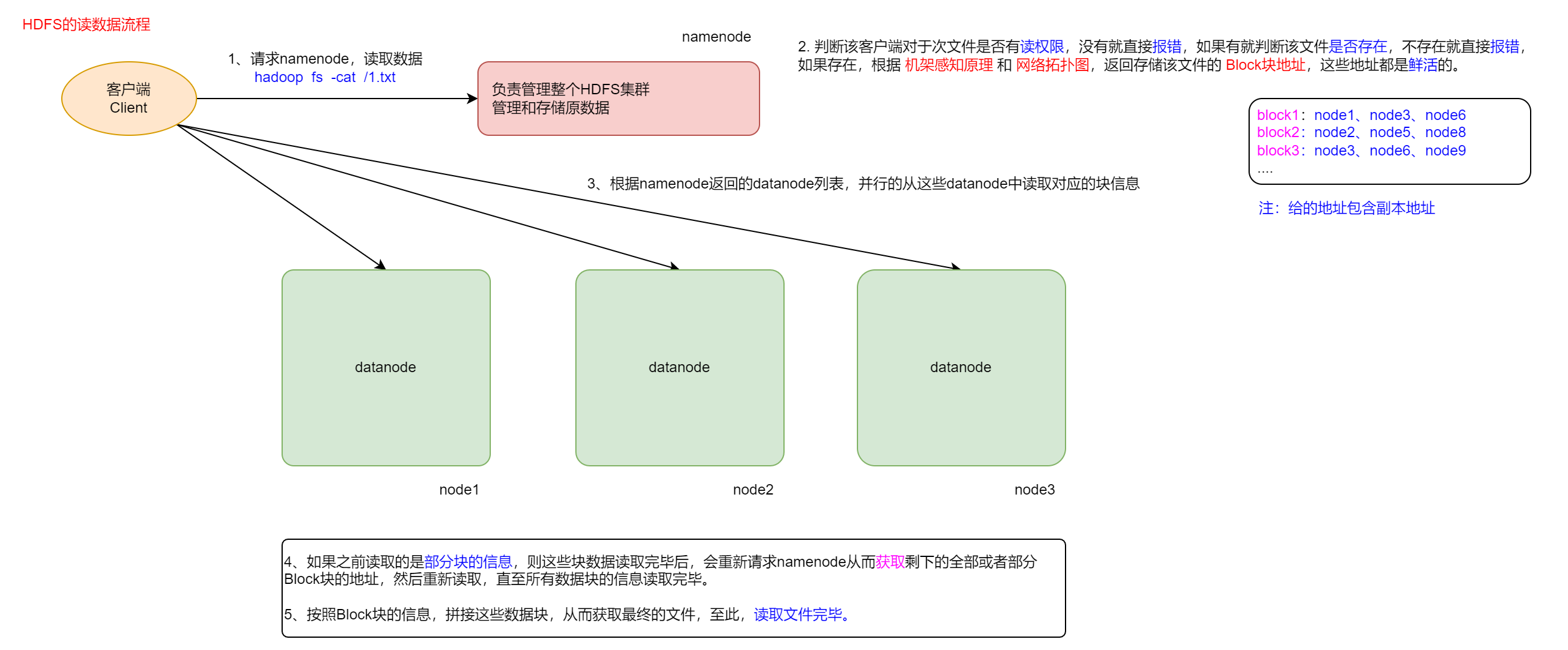
① 客户端向NameNode请求读取文件
② NameNode检查该文件是否存在以及该客户端是否具有读权限,有一个不满足则返回报错信息 两者都有则根据“机架感知原理”和“网络拓补图”,返回存储该文件的块地址(存储该文件的DataNode列表)
③ 客户端拿到返回的块地址后,并行的读取DataNode列表中对应的块信息 如果之前读取的是部分块的信息,则在这些块数据读取完毕后会重新请求NameNode 获取 剩下的块地址重新读取,直至所有数据块的信息读取完毕
⑤ 最后拼接块信息得到最终的文件
至此,读取文件操作完成
2、写操作

① 客户端向NameNode请求上传文件
② NameNode检查是否已存在要上传的文件,如果已有则拒绝请求 如文件不存在则继续检查该客户端在待上传的目录下是否有写权限,如果无权限则返回报错信息,有权限则给客户端返回可以上传的信息
③ 客户端接收可以上传的信息后,对文件进行切块
④ 客户端重新请求NameNode,询问第一个数据块的上传位置
⑤ NameNode接收到客户端的请求后,根据副本机制、负载均衡、机架感知原理和网络拓补图,找到存储第一个数据块的DataNode列表(例如node1、node2、node3)后告知客户端
⑥ 客户端根据接收到的DataNode列表,连接就近的节点(例如node1)
⑦ 第一个节点收到请求后会与DataNode列表中的其他节点进行连接,形成“传输管道”,然后客户端通过数据报包(对数据块再进行切分)的方法开始给节点传输第一个数据块
⑧ 节点接收到数据块后,需要告知客户端块信息已上传成功 所以node3接收到信息后会反馈给node2已接收,node2再反馈给node1已接收,最后node1告知客户端已上传成功 这一步也称为【构建反向应答机制】
⑨ 第一个数据块上传完成后,客户端继续请求NameNode询问第二个数据块的上传位置,重复第四到第八步的操作,直至所有的数据块上传成功
至此,写文件操作完成
1.5 HDFS元数据管理机制
HDFS元数据按类型划分为两部分
持久化存储:
-
文件、目录自身的属性信息,例如文件名,目录名,修改信息
-
文件存储的相关信息,例如存储块信息,分块情况,副本个数
非持久化存储: DataNode节点中的数据块信息
1、如何持久化存储数据?
答:通过fsimage和edits log
fsimage(镜像文件)
保存Hadoop文件系统中的所有目录和元数据信息,但不保存文件块位置的信息 文件块位置信息只存储在内存中,是Namenode在DataNode加入集群时询问得到,并且间断的更新
edits log(编辑日志)
保存客户端对Hadoop集群的事务性操作记录(增、删、改)
2、SeconderyNameNode辅助管理元数据的流程
图解

原理
第一阶段:启动NameNode
-
① 如果是首次启动namenode格式化,则新建fsimage(镜像文件)和edits log(编辑日志) 如果是非首次启动,则直接加载fsimage和edits log到内存中
-
② 客户端对元数据的增删改操作会实时的写入到edits log
第二阶段:SecondaryNameNode开始工作
-
③ SecondaryNameNode会实时检查edits log的状态,只要满足一定阈值时(1小时或修改达到100W次)后就通知NameNode重新生成一个新的edits log文件,后续将操作记录写入新文件中
-
④ SecondaryNameNode通过HTTP协议拉取NameNode中的fsimage和edits log到本地
-
⑤ 对拉取过来的edits log和fsimage加载到内存中进行合并操作(这个过程也成为Checkpoint),形成新的fsimage文件
-
⑥ 把新的fsimage推送给NameNode,替换旧fsimage
3. 小细节
-
① 产生的edits log和fsiamge不会被立即删除,而是在集群重启或者这些文件达到一定量级后才会删除
-
② 对edits log和fsimage的合并操作实在SecondaryNameNode实现的,整个过程NameNode不参与
-
③ 实际开发中,NameNode和SecondaryNameNode一般部署在不同的服务器上,两者的配置几乎一样,只是SecondaryNameNode内存要稍微大点
-
④ 紧急情况下,SecondaryNameNode可以用来恢复NameNode的元数据
二 HDFS的五大机制
1、切片机制
HDFS中的文件在物理上是分块(block)存储的,块的大小可以通过配置参数来规定,在hadoop2.x版本中默认大小是128M
2、汇报机制
① HDFS集群重新启动的时候,所有的DataNode都要向NameNode汇报自己的块信息 ② 当集群在正常工作的时,间隔一定时间(6小时)后DataNode也要向NameNode汇报一次自己的块信息
3、心跳检测机制
NameNode与DataNode依靠心跳检测机制进行通信
① DataNode每3秒给NameNode发送自己的心跳信息 ② 如果NameNode没有收到心跳信息,则认为DataNode进入“假死”状态。DataNode在此阶段还会再尝试发送10次(30s)心跳信息 ③ 如果NameNode超过最大间隙时间(10分钟)还未接收到DataNode的信息,则认为该DataNode进入“宕机”状态 ④ 当检测到某个DataNode宕机后,NameNode会将该DataNode存储的所有数据重新找台活跃的新机器做备份
4、负载均衡
让集群中所有的节点(服务器)的利用率和副本数尽量都保持一致或在同一个水平线上
5、副本机制
① 副本的默认数量为3 ② 当某个块的副本小于3份时,NameNode会新增副本 ③ 当某个块的副本大于3份时,NameNode会删除副本 ④ 当某个块的副本数小于3份且无法新增的时候,此时集群会强制进入安全模式(只能读,不能写)
三 Hadoop安装
3.1 集群规划列表

检查我们的hadoop包对本地库的支持:切换到hadoop安装目录下,执行bin/hadoopchecknative回车即可。
3.2 上传压缩包
上传我们编译好的apache hadoop包并解压缩(下图红色标记的)

解压hadoop的压缩包

修改配置文件 /etc/profile ,后使用source命令使其生效。

3.3 配置相关的文件
(1)修改core-site.xml配置文件
vim /opt/hadoop的安装路径/etc/hadoop/core-site.xml
定义hadoop集群系统的文件类型是一个分布式文件系统
- 定义hadoop集群系统的文件类型是一个分布式文件系统
- <property>
- 定义hadoop集群中文件的类型,说明我们用的是分布式文件系统,该文件系统的主节点的node01节点上,分布式文件系统的服务端口号为8020。
- <name>fs.default.name</name>
- <value>hdfs://node01:8020</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/software/hadoop-2.7.5/hadoopDatas/tempDatas</value>
- </property>
- 定义文件缓冲区大小,实际工作中根据服务器性能动态调整
- <property>
- <name>io.file.buffer.size</name>
- <value>4096</value>
- </property>
- 开启hdfs垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位:分钟
- 删除掉的文件会先放在垃圾桶里面,而不是立刻从机器上删除掉。10080是七天,也就是说7天之后,会清理垃圾桶中超过7天的数据。一天是1440.
- <property>
- <name>fs.trash.interval</name>
- <value>10080</value>
- </property>

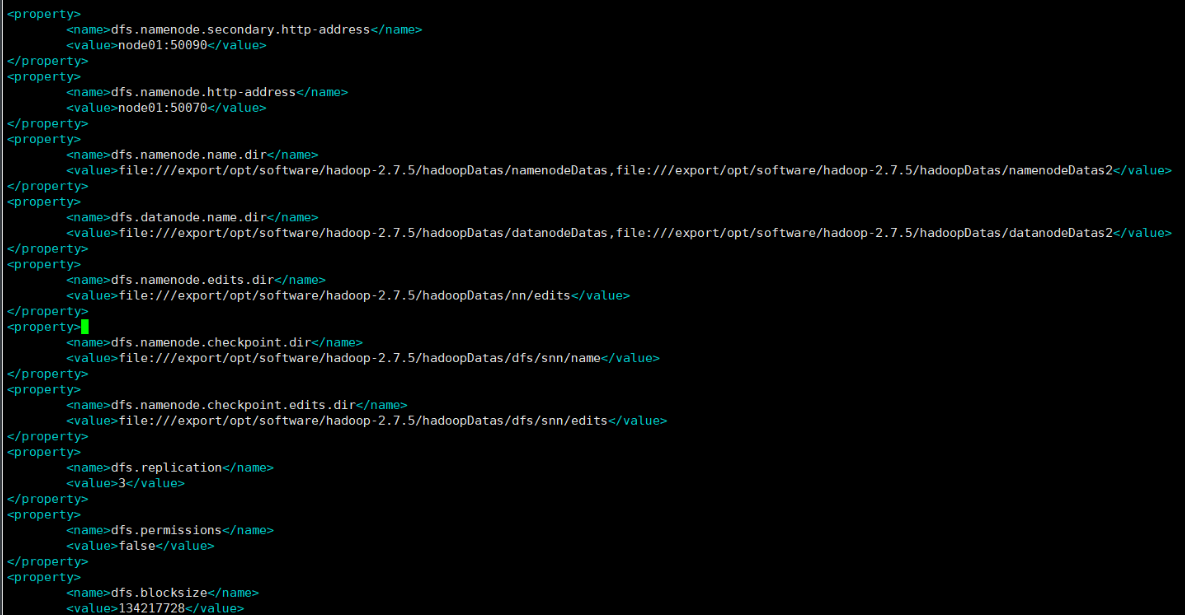
(2)修改hdfs-site.xml
- 设定辅助管理节点的主机和端口号
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>node01:50090</value>
- </property>
- 设定NameNode(HDFS)主节点的访问地址(即:主机和端口号)——会非常常用可以通过网页查看分布式文件系统中的数据。
- <property>
- <name>dfs.namenode.http-address</name>
- <value>node01:50070</value>
- </property>
- 指定namdenode存储元数据的位置,这个文件是不存在的,我们需要创建它。
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:///export/opt/software/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/opt/software/hadoop-
- 2.7.5/hadoopDatas/namenodeDatas2</value>
- </property>
- 定义datanode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割。
- <property>
- <name>dfs.datanode.name.dir</name>
- <value>file:///export/opt/software/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/opt/software/hadoop-
- 2.7.5/hadoopDatas/datanodeDatas2</value>
- </property>
- 定义namenode编辑日志文件的存放目录
- <property>
- <name>dfs.namenode.edits.dir</name>
- <value>file:///export/opt/software/hadoop-2.7.5/hadoopDatas/nn/edits</value>
- </property>
- 定义检查点的存放位置(定期从活动的NameNode下载fsimage和editlog,在本地合并它
- 们,并将新映像上传回活动的NameNode)
- <property>
- <name>dfs.namenode.checkpoint.dir</name>
- <value>file:///export/opt/software/hadoop-2.7.5/hadoopDatas/dfs/snn/name</value>
- </property>
- <property>
- <name>dfs.namenode.checkpoint.edits.dir</name>
- <value>file:///export/opt/software/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
- </property>
- 指定一个文件切片存储的副本个数
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
- 设置HDFS文件权限,暂时关闭,后期需要,可以再开启
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- 指定一个文件切片的大小,这里面指定的大小为128M
- <property>
- <name>dfs.blocksize</name>
- <value>134217728</value>
- </property>
(3)配置hadoop-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_281
(4)配置mapred-site.xml
开启mapreduce的小任务模式,该模式是 2.x 开始引入的;以Uber模式运行 MR 作业,所
有的 Map Tasks 和 Reduce Tasks 将会在 ApplicationMaster 所在的容器(container)中运行。如果数据量不是非常大,我们就可以开启小任务模式,这样可以提高2-3倍的效率。
- <property>
- <name>mapreduce.job.ubertask.enable</name>
- <value>true</value>
- </property>
- 历史任务服务器的主机地址,通过该地址可以访问到我们曾经计算过的任务、结果及信
- 息。
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>node01:10020</value>
- </property>
- 设置通过网页访问历史任务的主机和端口
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>node01:19888</value>
- </property>

(5)配置yarn-site.xml文件
- 配置yarn主节点的位置
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>node01</value>
- </property>
- NodeManager上运行的附属服务,只有我们配置为下方的值,才可以运行MR程序,默
- 认值是””。
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- 开启日志聚合功能,将各种日志汇总在一起,进行显示。
- <property>
- <name>yarn.log-aggregation-enable</name>
- <value>true</value>
- </property>
- 设置聚合日志保存的时间(单位:秒)
- <property>
- <name>yarn.log-aggregation.retain-seconds</name>
- <value>604800</value>
- </property>
- 设置yarn集群的内存分配方案
- 表示在节点上Yarn可使用的物理内存(M)
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>20480</value>
- </property>
- 单个容器可申请的最小与最大内存
- <property>
- <name>yarn.scheduler.minimum-allocation-mb</name>
- <value>2048</value>
- </property>
- 在物理内存不够用的情况下,如果占用了大量虚拟内存并且超过了一定阈值,那么就认
- 为当前集群的性能比较差,直接让你的终端报个错提醒你。
- <property>
- <name>yarn.nodemanager.vmem-pmem-ratio</name>
- <value>2.1</value>
- </property>

(6)修改mapred-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_281
(7)修改slaves(配置我们的从机)
node01
node02
node03
(8)前面配置好后,我们需要自己创建目录
目录结构如下:

- [root@node01 hadoop-2.7.5]# mkdir hadoopDatas
- [root@node01 hadoop-2.7.5]# cd hadoopDatas/
- [root@node01 hadoopDatas]# ls
- [root@node01 hadoopDatas]# mkdir datanodeDatas
- [root@node01 hadoopDatas]# mkdir datanodeDatas2
- [root@node01 hadoopDatas]# mkdir namenodeDatas2
- [root@node01 hadoopDatas]# mkdir namenodeDatas
- [root@node01 hadoopDatas]# mkdir -p dfs/snn
- [root@node01 hadoopDatas]# cd dfs/snn/
- [root@node01 snn]# mkdir edits
- [root@node01 snn]# mkdir name
- [root@node01 snn]# cd ..
- [root@node01 dfs]# cd ..
- [root@node01 hadoopDatas]# mkdir -p nn/edits
- [root@node01 hadoopDatas]# mkdir tempDatas
- [root@node01 hadoopDatas]# tree
- .
- ├── datanodeDatas
- ├── datanodeDatas2
- ├── dfs
- │?? └── snn
- │?? ├── edits
- │?? └── name
- ├── namenodeDatas
- ├── namenodeDatas2
- ├── nn
- │?? └── edits
- └── tempDatas
- 11 directories, 0 files
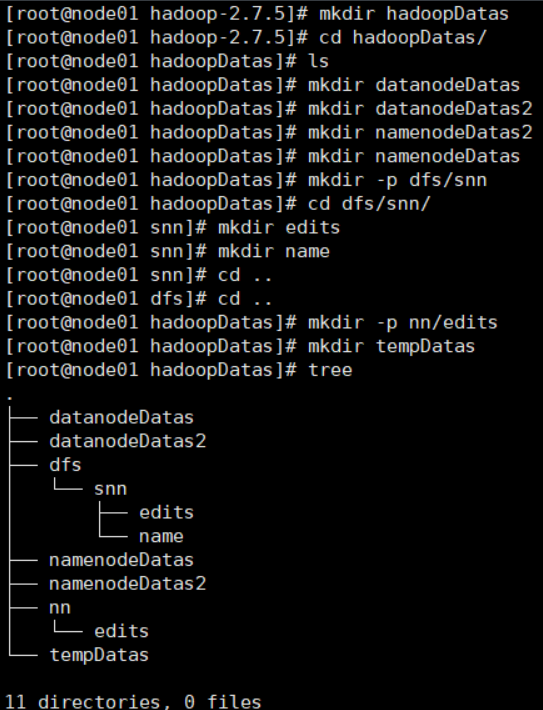
PS:注意此处的文件夹在你的Hadoop安装路径下面
(9)分发安装内容
做一个文件的分发,将整个hadoop安装目录分发给node02和node03节点上去。 进入opt目录后,执行分发命令:
scp -r hadoop-2.7.5 node02:/opt/software![]()
此处选择需要Copy到node02节点的那个目录当中。
scp -r hadoop-2.7.5 node03:/opt/software(10)三台机器配置hadoop环境变量
- export JAVA_HOME=/opt/software/jdk1.8.0_281
- export ZOOKEEPER_HOME=/opt/software/zookeeper
- export HADOOP_HOME=/opt/software/hadoop-2.7.5
- export PATH=:$JAVA_HOME/bin:$PATH:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
别忘记用source /etc/profile使环境变量生效。
(11)启动集群
概述:主要是启动两个模块,hdfs和yarn。一定要注意:首次启动HDFS的时候,一定要对其进行格式化操作。本质上是一些清理和准备工作(会准备一些集群必备的文件等),因为此时的HDFS在物理上还是不存在的。 第一台机器执行如下操作: 进入到hadoop的安装目录中
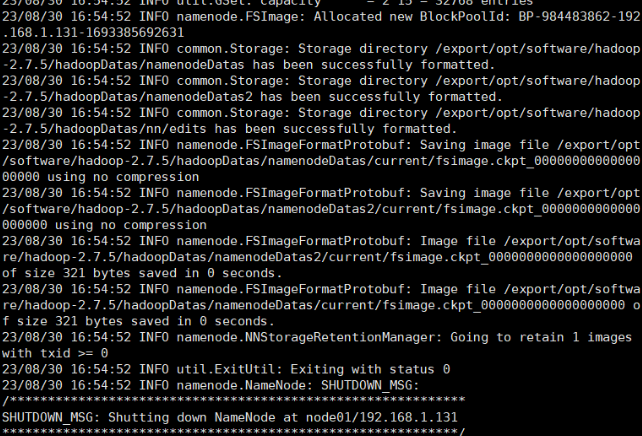
cd /opt/software/hadoop-2.7.5进行格式化
- bin/hdfs namenode -format
- sbin/start-dfs.sh
停止命令只要把start换成stop即可 从节点,用jps看一下,启动成功,有一个DataNode。
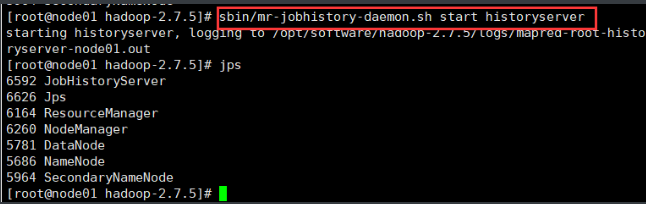
- sbin/start-yarn.sh
- sbin/mr-jobhistory-daemon.sh start historyserver

三个端口查看界面
- http://node01:50070/explorer.html# 查看hdfs
- http://node01:8088/cluster 查看yarn集群
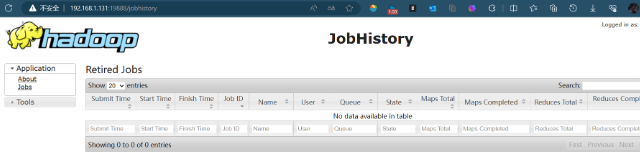
- http://node01:19888/jobhistory 查看历史完成的任务
windows访问不到node01,所以需要配置hosts 可以换成
- http://192.168.1.131:50070/explorer.html#/
- http://192.168.1.131:8088/cluster
- http://192.168.1.131:19888/jobhistory
备注:配置文件太多,所以,我们要远程修改Linux的文件,太麻烦了,所以,我们采用npp进行远程登录。


总结
以上就是今天的内容~
欢迎大家点赞
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

