
- 1.gitignore文件设置了忽略但不生效_gitignore 忽略没用
- 2腾讯音乐雇主品牌负责人李宇航:如何从雇主名牌,到雇主品牌?_腾讯 品牌传播负责人
- 3git添加.gitignore后不生效问题_git ignore不生效
- 4windows版sourceTree 免登录安装,小白教程,超级简单_sourcetree免登录版window
- 5哈希表总结-C语言版_c语言自带的hash函数
- 6官方 gpt3.5, gpt4.0、github copilot chat、gpt3.5 api、gpt4 api 对比
- 7盘点10款Linux发行版,最后一款深受程序员喜欢
- 8人工智能应用开发全流程的成本分析_ai企业模成本
- 9Gitlab本地上传时,账号密码输入错误后,无法再次输入,错误详情:Authentication failed for ‘http://192.168.137.128:8090/root‘_git authentication failed之后如何重新输账号密码
- 10傻瓜教程:MacOS系统安装Anaconda+Spyder+TensorFlow_mac如何安装红蜘蛛
【自然语言处理】NLP入门(七):1、正则表达式与Python中的实现(7):常用正则表达式、re模块:findall、match、search、split、sub、compile_nlp开发环境和正则表达式的应用
赞
踩
一、前言
本文将介绍常用正则表达式、re模块常用方法:findall、match、search、split、sub、compile等
二、正则表达式与Python中的实现
1、字符串构造
2、字符串截取
【自然语言处理】NLP入门(一):1、正则表达式与Python中的实现(1):字符串构造、字符串截取
3、字符串格式化输出
【自然语言处理】NLP入门(二):1、正则表达式与Python中的实现(2):字符串格式化输出(%、format()、f-string)
4、字符转义符
【自然语言处理】NLP入门(三):1、正则表达式与Python中的实现(3):字符转义符
5、字符串常用函数
在Python中有很多内置函数可以对字符串进行操作。如len()、ord()、chr()、max()、min()、bin()、oct()、hex()等。
【自然语言处理】NLP入门(四):1、正则表达式与Python中的实现(4):字符串常用函数
6、字符串常用方法
由于字符串属于不可变序列类型,常用方法中涉及到返回字符串的都是新字符串,原有字符串对象不变
【自然语言处理】NLP入门(五):1、正则表达式与Python中的实现(5):字符串常用方法:对齐方式、大小写转换详解
【自然语言处理】NLP入门(六):1、正则表达式与Python中的实现(6):字符串常用方法:find()、rfind()、index()、rindex()、count()、replace()
7、正则表达式
正则表达式是一个特殊的字符序列,利用事先定义好的一些特定字符以及它们的组合组成一个“规则”,检查一个字符串是否与这种规则匹配来实现对字符的过滤或匹配。
- Python中,re模块提供了正则表达式操作所需要的功能。
- 元字符是一些在正则表达式中有特殊用途、不代表它本身字符意义的一组字符。
/^1[34578][0-9]$/
- 1
1. 常用正则表达式
至于各种元字符及其使用规则,详见后文~
- 用户名:
- 只允许使用字母、数字和下划线:
^[a-zA-Z0-9_]+$
- 1
- 密码:
- 至少包含一个大写字母、一个小写字母和一个数字,长度至少为8个字符:
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d).{8,}$
- 1
- 十六进制值:
- 匹配有效的十六进制颜色值(6个十六进制字符):
^#([A-Fa-f0-9]{6})$
- 1
- 电子邮箱:
- 匹配常见的电子邮箱格式:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
- 1
- URL:
- 匹配常见的URL格式,包括http、https和www:
^(https?://)?(www\.)?[a-zA-Z0-9-]+\.[a-zA-Z]{2,}(/.*)?$
- 1
- IP地址:
- 匹配IPv4地址:
^([1-9]|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])(\.([0-9]|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])){3}$
- 1
- HTML标签:
- 匹配HTML标签(包括可选的属性):
^<([a-zA-Z][a-zA-Z0-9]*)\s*([^>]*)>*<\/\1>$
- 1
- 删除代码注释:
- 删除/* */形式的代码注释:
/\*([^*]|[\r\n]|(\*+([^*/]|[\r\n])))*\*+/
- 1
- Unicode编码中的汉字范围:
- 匹配Unicode编码中的中文字符范围:[\u4E00-\u9FFF]
[\u4E00-\u9FFF]
- 1
2. 常用正则表达式元字符
.匹配任意单个字符,除了换行符^匹配字符串开头$匹配字符串结尾*匹配前一个字符0次或多次+匹配前一个字符1次或多次?匹配前一个字符0次或1次[]匹配括号内的任一字符()分组\d匹配数字\w匹配字母数字或下划线\s匹配空白字符
具体使用方法详见后文:【自然语言处理】NLP入门(八):1、正则表达式与Python中的实现(8):正则表达式元字符详解
3. re模块
re.findall()
re.findall(pattern, string, flags=0)方法用于在字符串中查找所有与正则表达式pattern匹配的子串,并以列表形式返回。如果没有找到匹配项,则返回空列表。
- 格式:
- re.findall (pattern , string , [flags])
- 说明:
- pattern: 模式字符串
- string:要匹配的字符串
- flags:可选参数,比如re.I 不区分大小写
import re
# 匹配所有数字
print(re.findall(r'\d+', 'a1b2c3d4')) # ['1', '2', '3', '4']
# 匹配所有单词
print(re.findall(r'\w+', 'He is a good man.')) # ['He', 'is', 'a', 'good', 'man']
# 使用分组
matches = re.findall(r'(\w+)\s*=\s*(\d+)', 'x=8 y=9 z=10')
print(matches) # [('x', '8'), ('y', '9'), ('z', '10')]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

re.match()
- re.match(pattern, string, flags=0)
- 尝试从字符串的起始位置匹配一个模式,如果匹配成功,返回一个匹配对象,否则返回None。
import re
pattern = r'ab'
string = 'abcdef'
match_obj = re.match(pattern, string)
print("Match found:", match_obj.group())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
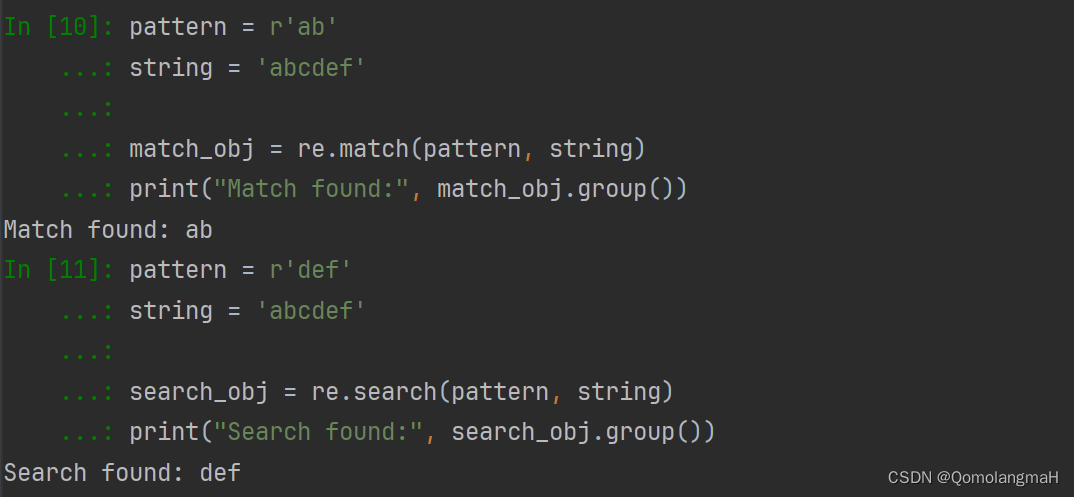
re.search()
- re.search(pattern, string, flags=0)
- 扫描整个字符串,寻找匹配模式的第一个位置,返回一个匹配对象。
import re
pattern = r'def'
string = 'abcdef'
search_obj = re.search(pattern, string)
print("Search found:", search_obj.group())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
re.split()
- re.split(pattern, string, maxsplit=0, flags=0)
- 利用正则表达式对字符串进行分割,返回一个列表。
import re
pattern = r'\s' # 以空白字符为分隔符
string = 'This is a sentence.'
split_list = re.split(pattern, string)
print(split_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

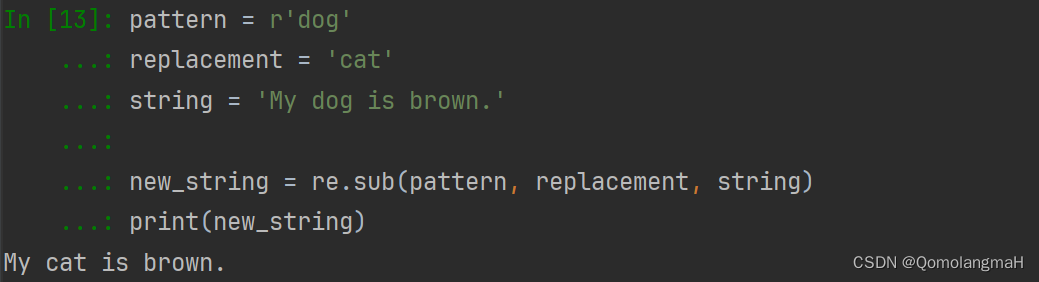
re.sub()
- re.sub(pattern, repl, string, count=0, flags=0)
- 在字符串中替换所有匹配正则表达式的子串。
import re
pattern = r'dog'
replacement = 'cat'
string = 'My dog is brown.'
new_string = re.sub(pattern, replacement, string)
print(new_string)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
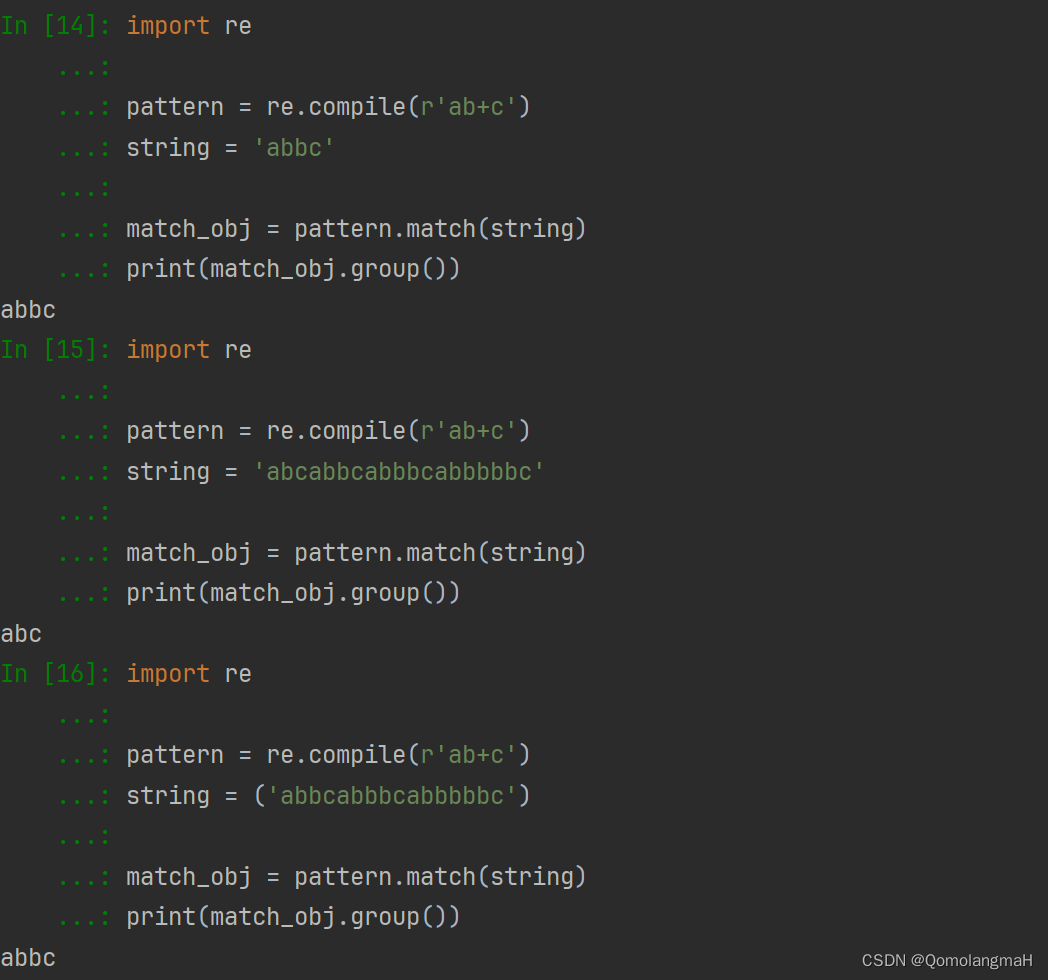
re.compile()
- re.compile(pattern, flags=0)
- 将正则表达式的模式预编译为一个模式对象,可被多次使用。
import re
pattern = re.compile(r'ab+c')
string = 'abbc'
match_obj = pattern.match(string)
print(match_obj.group())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
合体示例
import re # re.match 从头开始匹配 print(re.match(r'\d+', '18abc')) # <re.Match object; span=(0, 2), match='18'> print(re.match(r'\d+', 'a18bc')) # None # re.search 扫描整个字符串查找匹配 print(re.search(r'\d+', 'a18bc')) # <re.Match object; span=(1, 3), match='18'> # re.split 根据模式分割字符串 print(re.split(r'\d+', 'a1b2c3d')) # ['a', 'b', 'c', 'd'] # re.sub 替换匹配的子串 print(re.sub(r'\d+', 'X', 'a1b2c3d')) # aXbXcXd # 预编译模式对象 pattern = re.compile(r'\d+') print(pattern.match('18abc')) # <re.Match object; span=(0, 2), match='18'>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

