
热门标签
热门文章
- 1在百度AIstudio上运行自己PaddleDetection所遇到的问题及解决方案_can't call main_program when full_graph=false. use
- 2二维背包问题_dp = [[0] * (m+1) for _ in range(n+1)]
- 3了解uni-app只需这一篇就足够了
- 4预处理编译汇编链接(程序运行过程中的细节)_可以在汇编文件.s中使用预编译吗
- 5微博指定日期舆情数据爬虫获取—基于中文金融词典(python)_python爬微博利用关键字爬每天信息条数
- 6深度学习零基础学习之路——第二章 数据处理Dataset类的使用_深度学习dataset
- 7开题报告:基于java的高校固定资产管理系统设计与实现_高校固定资产管理系统开题报告
- 8算法与数据结构 --- 串,数组与广义表 --- 数组_二维数组和多维数组是特殊的线性结构吗
- 9【IoTDB 线上小课 01】我们聊聊“金三银四”下的开源
- 10python爬虫requestsget_【Python】【爬虫】Requests库详解
当前位置: article > 正文
Python爬虫入门案例(二)电影票房数据库爬取(request+XPath+csv)_电影票房排行榜数据爬取——理科
作者:小丑西瓜9 | 2024-04-14 08:55:55
赞
踩
电影票房排行榜数据爬取——理科
大家学完第一个案例爬取豆瓣电影数据之后,对爬虫的基本概念以及流程有了大体的了解。其实我个人认为,爬虫的流程都是一样的,只不过方法不同而已。
今天我们就来学习第二个案例,爬取电影票房数据库中的电影数据信息。
网站地址:http://58921.com/
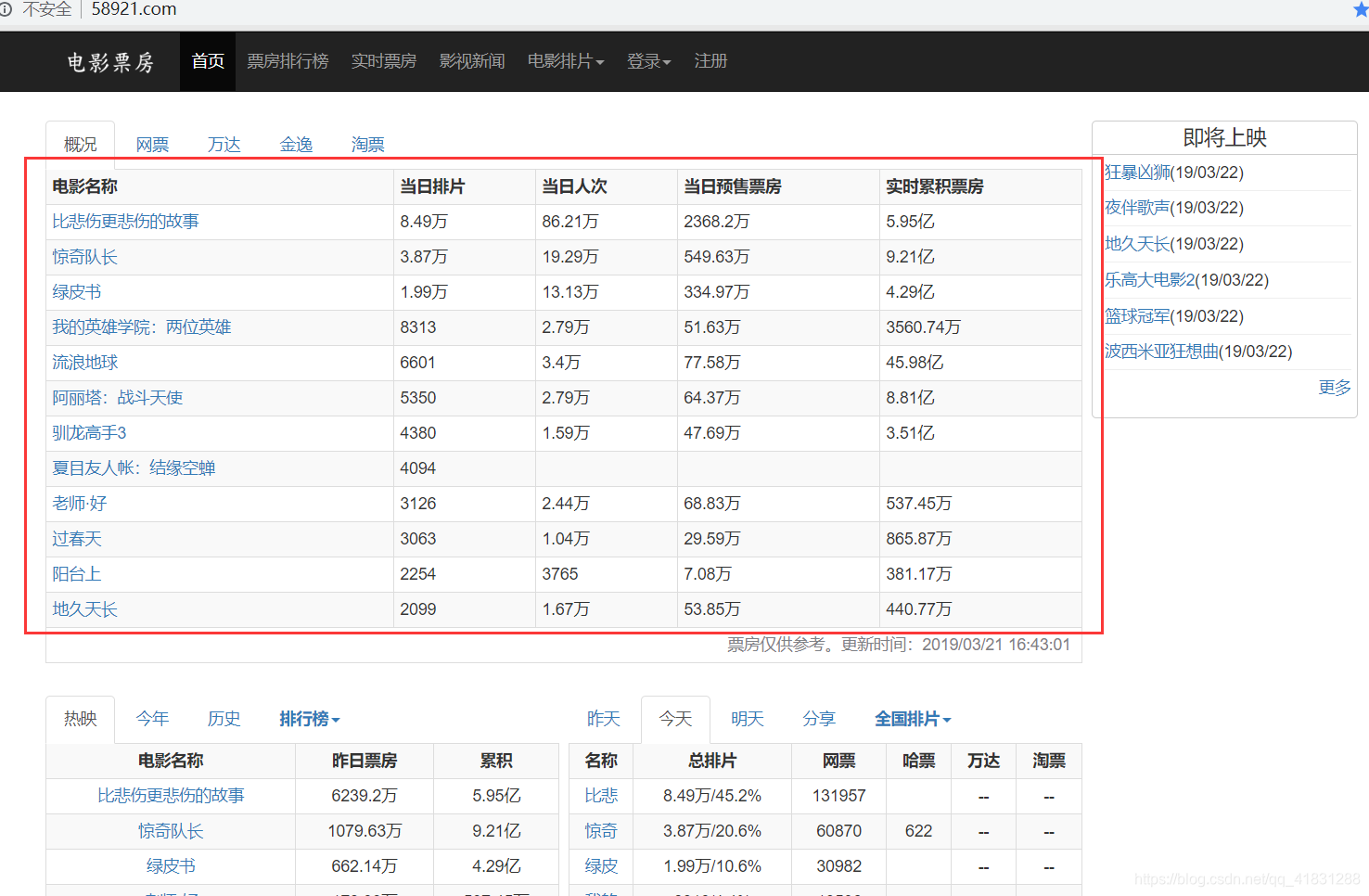
下面就开始爬取。大概分为三步;
一:获取网页响应
二:获取网页所需内容
三:保存数据
1.获取相应。获取相应的方式与第一个案例一致,直接上代码。
def get_response(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36'}
response = requests.get(url,headers=headers)
response.encoding = 'UTF-8'
return response.text
- 1
- 2
- 3
- 4
- 5
2.分析源码,通过xpath获取我们需要的内容
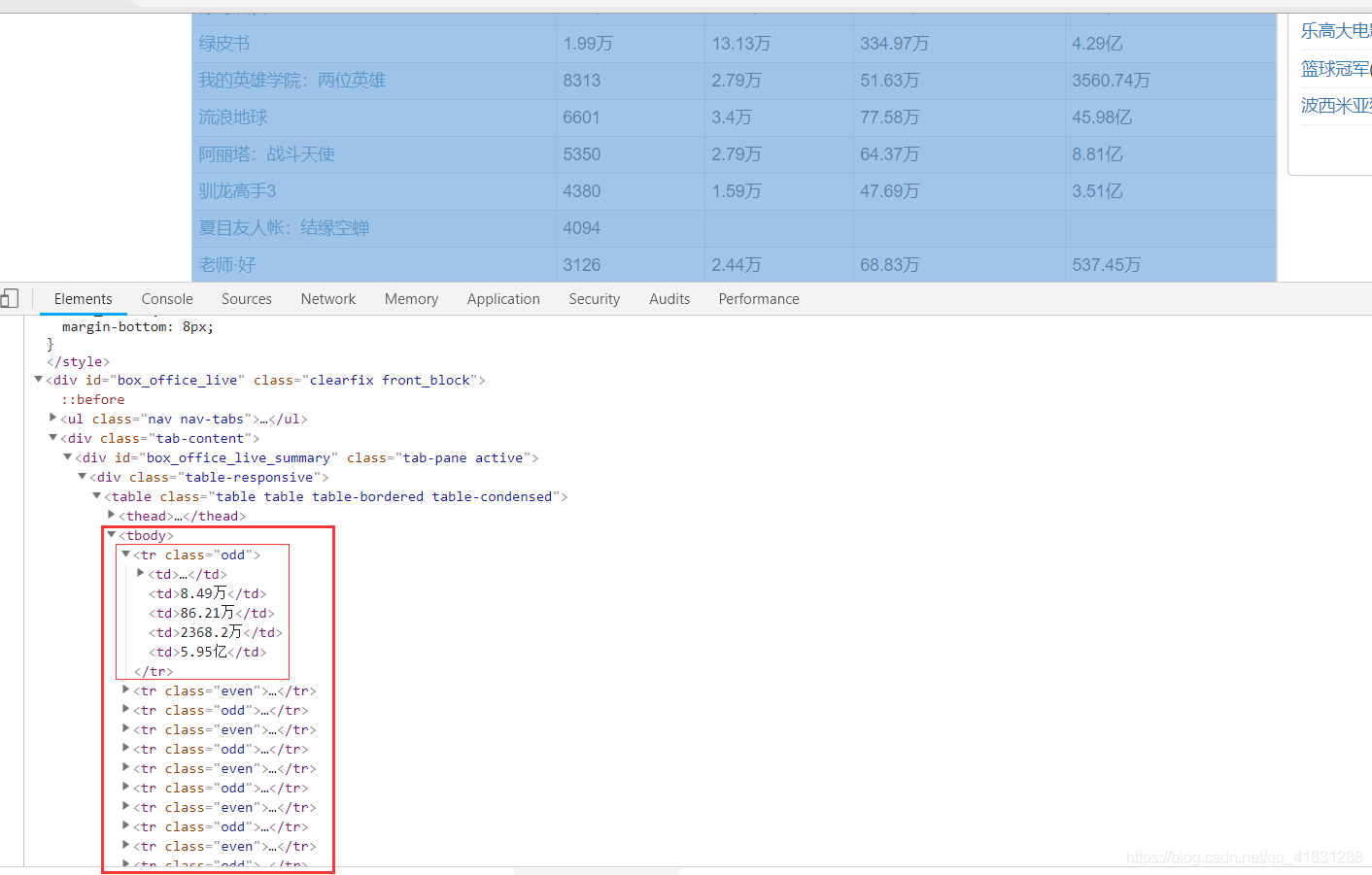
通过分析源码,我们可以看到,每一条电影数据,都存在一个tr标签中,且存入的格式都非常规范。所以我们可以通过锁定这里的tr标签来获取数据。单数需要注意的一点是,tr标签的属性是有不同的,有even有odd。所以在这里我们需要加一个and判断。
nodes = text.xpath('//div[@class="clearfix front_block"]//tr[@class="odd"] | //div[@class="clearfix front_block"]//tr[@class="even"]')
- 1
- 2
爬取内容代码:
def get_nodes(html):
text = etree.HTML(html)
nodes = text.xpath('//div[@class="clearfix front_block"]//tr[@class="odd"] | //div[@class="clearfix front_block"]//tr[@class="even"]')
infos = []
for node in nodes:
key = {}
key['movieName'] = str(node.xpath('.//td/a/@title')).strip("[']")
key['moviePaiPian'] = str(node.xpath('.//td[2]/text()')).strip("[']")
key['moviePeople'] = str(node.xpath('.//td[3]/text()')).strip("[']")
key['movieAdvance'] = str(node.xpath('.//td[last()-1]/text()')).strip("[']")
key['movieAccumulate'] = str(node.xpath('.//td[last()]/text()')).strip("[']")
infos.append(key)
return infos
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.保存数据。在这里我们通过csv方法将数据存入csv文件中。csv文件可以通过excel表格查看,非常方便。所以一般格式化的数据我们都喜欢存入csv文件,这样看起来数据非常规范整齐。
def save_file(infos):
headers = ['电影名称', '当日排片', '当日人次','当日预售票房','累计票房']
with open('movieDataBase.csv','a+',encoding='UTF-8',newline='') as fp:
writer = csv.writer(fp)
writer.writerow(headers)
for key in infos:
writer.writerow([key['movieName'],key['moviePaiPian'],key['moviePeople'],key['movieAdvance'],key['movieAccumulate']])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这样我们的爬虫就写好了。运行一下看一下结果吧。(后附加文件效果以及完整代码)
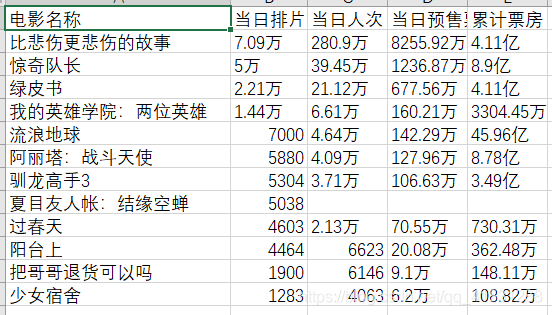
完整代码
import requests from lxml import etree import csv def get_response(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36'} response = requests.get(url,headers=headers) response.encoding = 'UTF-8' return response.text def get_nodes(html): text = etree.HTML(html) nodes = text.xpath('//div[@class="clearfix front_block"]//tr[@class="odd"] | //div[@class="clearfix front_block"]//tr[@class="even"]') infos = [] for node in nodes: key = {} key['movieName'] = str(node.xpath('.//td/a/@title')).strip("[']") key['moviePaiPian'] = str(node.xpath('.//td[2]/text()')).strip("[']") key['moviePeople'] = str(node.xpath('.//td[3]/text()')).strip("[']") key['movieAdvance'] = str(node.xpath('.//td[last()-1]/text()')).strip("[']") key['movieAccumulate'] = str(node.xpath('.//td[last()]/text()')).strip("[']") infos.append(key) return infos def save_file(infos): headers = ['电影名称', '当日排片', '当日人次','当日预售票房','累计票房'] with open('movieDataBase.csv','a+',encoding='UTF-8',newline='') as fp: writer = csv.writer(fp) writer.writerow(headers) for key in infos: writer.writerow([key['movieName'],key['moviePaiPian'],key['moviePeople'],key['movieAdvance'],key['movieAccumulate']]) if __name__ == '__main__': url = 'http://58921.com/' html = get_response(url) infos = get_nodes(html) save_file(infos)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
希望看完之后会对大家学习爬虫有帮助,如果有问题可以留言,评论,如果能点个赞就是最大的支持了。
每天进步一点点,Keep Going!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/421240
推荐阅读
相关标签

