
- 1Flutter使用Texture在安卓端实现Camera预览_flutter camera 预览区
- 2Hadoop-熟悉常用的HDFS操作_hadoop的常用命令实验报告
- 3进阶数据库系列(十六):PostgreSQL 数据库高可用方案_postgresql高可用构架
- 4Element drawer无法上下滚动_arco design drawer弹出其他区域无法滚动
- 5全网最详细的Flutter开发入门基础教程,Flutter跨平台终极之选
- 6在linux下编译安装xvid
- 7动态规划的思想_大事化小小事化了体现出的问题求解思想是
- 8一份面经让你面试成功率加80%,985大佬分享自己的字节三面面经!_字节一面和二面通过率
- 9【python游戏】努力制造阳光,让植物有力量对抗僵尸吧~_pycharm植物大战僵尸
- 10面试官喜欢与岗位匹配度较高的求职者,怎么准备?_面试官问你岗位的匹配度
SqlServer基础学习笔记_sqlsever的笔记
赞
踩
目前工作很少接触数据库,工作之余进行SqlServer基础学习,完善此薄弱之处。

1.SqlServer 简介
1.什么是数据库
数据库是结构化信息或数据(一般以电子形式存储在计算机系统中)的有组织的集合,通常由数据库管理系统 (DBMS) 来控制。在现实中,数据、DBMS 及关联应用一起被称为数据库系统,通常简称为数据库。
为了提高数据处理和查询效率,当今最常见的数据库通常以行和列的形式将数据存储在一系列的表中,支持用户便捷地访问、管理、修改、更新、控制和组织数据。另外,大多数数据库都使用结构化查询语言 ( SQL ) 来编写和查询数据。
2.结构化查询语言 (SQL ) 是什么?
1.简介
SQL 是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。与其他程序设计语言(如 C#语言、Java等)不同的是,SQL 由很少的关键字组成,每个 SQL 语句通过一个或多个关键字构成。
- 一体化:SQL 集数据定义、数据操作和数据控制于一体,可以完成数据库中的全部工作。
- 使用方式灵活:SQL 具有两种使用方式,可以直接以命令方式交互使用;也可以嵌入使用,嵌入 C、C++、Fortran、COBOL、Java 等语言中使用。
- 非过程化:只提操作要求,不必描述操作步骤,也不需要导航。使用时只需要告诉计算机“做什 么”,而不需要告诉它“怎么做”,存储路径的选择和操作的执行由数据库管理系统自动完成。
- 语言简洁、语法简单:该语言的语句都是由描述性很强的英语单词组成,而且这些单词的数目不 多。
SQL 包含以下 几 部分:用来创建或删除数据库以及表等对象,主要包含以下几种命令:
- DROP:删除数据库和表等对象。
- CREATE:创建数据库和表等对象。
- ALTER:修改数据库和表等对象的结构。
2.数据操作语言(Data Manipulation Language,DML)
用来变更表中的记录,主要包含以下几种命令:
- SELECT:查询表中的数据。
- INSERT:向表中插入新数据 。
- UPDATE:更新表中的数据。
- DELETE:删除表中的数据。
3.数据查询语言(Data Query Language,DQL)
用来查询表中的记录,主要包含 SELECT 命令,来查询表中的数据。
用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对数据库中的用户设定权限。主要包含以下几种命令:
- GRANT:赋予用户操作权限。
- REVOKE:取消用户的操作权限。
- COMMIT:确认对数据库中的数据进行的变更。
- ROLLBACK:取消对数据库中的数据进行的变更。
3.数据库的发展历程
目前几乎所有的关系数据库都使用 SQL 编程语言来查询、操作和定义数据,进行数据访问控制。 SQL最初于 20 世纪 70 年代由 IBM 开发,当时 Oracle 是一个主要的贡献者,这推动了 SQL ANSI 标准的实施,而 SQL 的兴起也刺激了 IBM、Oracle 和 Microsoft 等公司开始全面扩张。时至今日,虽然 SQL仍被广泛使用,但是新的编程语言也已经崭露头角。
自 20 世纪 60 年代初诞生至今,数据库已经发生了翻天覆地的变化。最初,人们使用分层数据库(树形模型,仅支持一对多关系)和网络数据库(更加灵活,支持多种关系)这样的导航数据库来存储和操 作数据。这些早期系统虽然简单,但缺乏灵活性。20世纪 80 年代,关系数据库开始兴起;20 世纪 90年代,面向对象的数据库开始成为主流。最近,随着互联网的快速发展,为了更快速地处理非结构化数 据,NoSQL数据库应运而生。现在,云数据库和自治驾驶数据库在数据收集、存储、管理和利用方面 正不断取得新的突破。
4. 数据库与Excel等电子表格有何区别?
数据库和电子表格(例如 Microsoft Excel)都可以便捷地存储信息,两者的主要区别包括:
- 存储和操作数据的方式。
- 谁可以访问数据。
- 可以存储多少数据。
从一开始,电子表格就是专门针对单一用户而设计的,其特性也反映了这一点。电子表格非常适合不需要执行太多高度复杂的数据操作的单一用户或少数用户。另一方面,数据库的设计是为了保存大量有组织的信息,有时是海量的。数据库允许多个用户同时使用高度复杂的逻辑和语言,快速、安全地访问和查询数据。
5.数据库的类型
数据库有很多种,至于各种数据库孰优孰劣,主要取决于企业希望如何使用数据:
- 关系数据库:关系数据库在 20 世纪 80 年代成为主流。关系数据库中的项被组织为一系列具有列和行的表。关系数据库技术为访问结构化信息提供了最有效和灵活的方法。
- 面向对象数据库:面向对象数据库中的信息以对象的形式表示,这与面向对象的编程相类似。
- 分布式数据库:分布式数据库由位于不同站点的两个或多个文件组成。数据库可以存储在多台计算机上,位于同一个物理位置,或分散在不同的网络上(TIDB)。
- 数据仓库:数据仓库是数据的中央存储库,是专为快速查询和分析而设计的数据库。
- NoSQL 数据库:NoSQL 或非关系数据库,支持存储和操作非结构化及半结构化数据(与关系数据库相反,关系数据库定义了应如何组合插入数据库的数据)。随着 Web
应用的日益普及和复杂化, NoSQL 数据库得到了越来越广泛的应用。- 图形数据库:图形数据库根据实体和实体之间的关系来存储数据。
- OLTP 数据库: OLTP 数据库是一种高速分析数据库,专为多个用户执行大量事务而设计。
这些只是目前投入使用的几十种数据库中的一小部分。另外还有许多针对具体的科学、财务或其他功能而定制的不太常见的数据库。除了不同的数据库类型之外,技术开发方法的变化以及云和自动化等重大进步也在推动数据库朝新的方向发展。一些最新的数据库包括:
- 开源数据库:开源数据库系统是指源代码为开放源码的数据库系统,它可以是 SQL 或 NoSQL 数据库。(PostgreSQL,MySql)
- 云数据库:云数据库指位于私有云、公有云或混合云计算平台上的结构化或非结构化数据集合。云数据库模式分为两类:传统模式和数据库即服务 ( DBaaS )。在 DBaaS 中,管理任务和维护由服务 提供商执行。 B站:任我行码农场
- 多模型数据库:多模型数据库将不同类型的数据库模型结合到一个集成的后端中。这意味着它们可以支持各种不同的数据类型。
- 文档/ JSON 数据库:文档数据库专为存储、检索和管理面向文档的信息而设计,是一种以 JSON格式存储数据的现代方法,而不是采用行和列的形式。
- 自治驾驶数据库:基于云的自治驾驶数据库(也称作自治数据库)是一种全新的极具革新性的数据库,它利用机器学习技术自动执行数据库调优、保护、备份、更新,以及传统上由数据库管理员(
DBA ) 执行的其他常规管理任务。
6.数据库软件是什么?
数据库软件旨用于创建、编辑和维护数据库文件及记录,帮助用户更轻松地执行文件和记录创建、数据录入、数据编辑、更新和报告等操作。除此之外,数据库软件还能处理数据存储、备份和报告以及多路访问控制和安全性等问题。随着当今数据盗窃日益频繁,数据库安全性已变得至为重要。数据库软件有时也称为“数据库管理系统”
(DBMS)。
数据库软件支持用户以结构化形式存储数据然后访问数据,能够极大简化数据管理。它一般会提供图形界面来简化数据创建和管理,在某些情况下,用户可以使用数据库软件来自行构建数据库。
7.数据库管理系统 (DBMS) 是什么?
数据库通常离不开完备的数据库软件程序,也就是数据库管理系统 (DBMS)。DBMS充当数据库与其用户或程序之间的接口,允许用户检索、更新和管理信息的组织和优化方式。此外,DBMS还有助于监督和控制数据库,提供各种管理操作,例如性能监视、调优、备份和恢复。
常见的数据库软件或 DBMS 有 MySQL 、Microsoft Access、 Microsoft SQL Server 、FileMakerPro 、Oracle Database 和 dBASE , ProgreSQL。
8.简单认识 SQL Server
- SQL Server 是 Microsoft 开发的一个关系数据库管理系统( RDBMS ),现在是世界上最为常用的数据库之一;
- SQL Server 是一个高度可扩展的产品,可以从一个单一的笔记本电脑上运行的任何东西或以高倍云服务器网络,或在两者之间任何东西。虽然说是“任何东西”,但是仍然要满足相关的软件和硬件的要求;
- SQL Server 1.0 在1989年发布,至今 SQL Server 已成为一个真正的企业信息化平台。 SQLServer 2014 包括内置的商务智能工具,以及一系列的分析和报告工具,可以创建数据库、备份、复制、安全性更好以及更多。
9.为什么要使用SqlServer ?
- 数据持久化 :指的是 可以存储在磁盘中。
- 高效的存储与查询。
- 数据共享。
- .Net 首选,因为与 SqlServer 同属于微软。
10.SQL Server 基本服务介绍
1.SQL Server 服务器类型
Sql Server 提供了四种服务器类型:
- 数据库引擎 。
- Analysis Services (分析服务 ) 。
- Reporting Services (报告服务)。
- Integration Services (集成服务)。
数据库引擎 (核心服务):
是 Sql Server 的核心服务 他是存储和处理表格关系格式的数据或 xml 文档格式的数据服务。负责完成数据存储,处理,和安全。Analysis Services (分析服务 ) :
Analysis Services 主要是通过服务器和客户端 提供联机分析和处理和数据挖掘功能。(有了它用户可以创建,管理来自于其他数据源的数据结构)(联机事物的处理是由数据库引擎来完成的)。Reporting Services (报表服务):
Reporting Services 用来做基于服务器的解决方案:他可以用来生成各种报表方便工作。Integration Services (集成服务):
Integration Services 是一个数据集成的平台,负责完成有关数据的提取,转换,加载,集成服务包括生成并调试包的图形工具和向导;执行如数据导入、导出, FTP 操作,SQL 语句执行和电子邮件消息传递等工作流功能的任务等。
2.系统数据库
- Master:主系统数据库,记录了系统级别的信息,并且记录了登录账户,系统配置和已连接的服务信息。
- Model:模板数据库.保存了创建数据库所需要的模板信息。
- Tempdb :临时数据库,保存所有的临时表信息和临时存储过程。
- Msdb :记录代理程序的调度信息,警报,作业等信息。
2.数据库操作
1.数据库文件组成
1.主数据文件(.mdf)
- 要数据文件的建议文件扩展名是 .mdf 。
- 主要数据文件包含数据库的启动信息,并指向数据库中的其他文件,存储部分或全部的数据。用户数据和对象可存储在此文件中,也可以存储在次要数据文件中。
- 每个数据库有一个主要数据文件。 mdf 文件并非普通文件,因此不借助相应软件是无法打开 mdf 文件的。打开 mdf 文件的常用虚拟光驱软件,主要有:Daemon Tools 、东方光驱魔术师等。
2.次要数据文件(*.ndf)
- 次要数据文件的建议文件扩展名是 . ndf 。
- 次要数据文件是可选的,由用户定义并存储用户数据,用于存储主数据文件未能存储的剩余数据和一些数据库对象。
- 通过将每个文件放在不同的磁盘驱动器上,次要文件可用于将数据分散到多个磁盘上。
- 如果数据库超过了单个 Windows 文件的最大大小,可以使用次要数据文件,这样数据库就能继续增长。
3.事务日志(*.ldf)
- 事务日志的建议文件扩展名是 . ldf 。
- 事务日志文件保存用于恢复数据库的事务日志信息。数据库的插入、删除、更新等操作都会记录在日志文件中,而查询不会记录在日志文件中。整个的数据库有且仅有一个日志文件。
- 每个数据库必须至少有一个日志文件。
2.文件组
不同的文件可以存分布到不同的物理硬盘上,这样便于分散硬盘IO,提高数据的读取速度。 数据文件的组合,称作文件组(File Group),数据库不能直接设置存储数据的数据文件,而是通过文件组来指定。
1.文件和文件组的关系
SQL Server 的数据存储在文件中,文件是实际存储数据的物理实体,文件组是逻辑对象, SQL Server 通过文件组来管理文件。
一个数据库有一个或多个文件组,其中主文件组(Primary File Group)是系统自动创建的,用户可以根据需要添加文件组。每一个文件组管理一个或多个文件,其中主文件组中包含主要数据文件(*. mdf),主文件组中也可以包含次要数据文件。(主要数据文件是系统默认生成的,并且在数据库中是唯一的;次要数据文件是用户根据需要添加的。)除了主文件组之外,其他文件组只能包含辅助文件。如下示例数据库,系统已自动创建主文件组 PRIMARY,勾选 Default 表示将主文件组设置为默认文件组,即如果在 create table 和 create index时没有指定 FileGroup 选项,那么 SQL Server 将使用默认的 PRIMARY 文件组来存储数据。
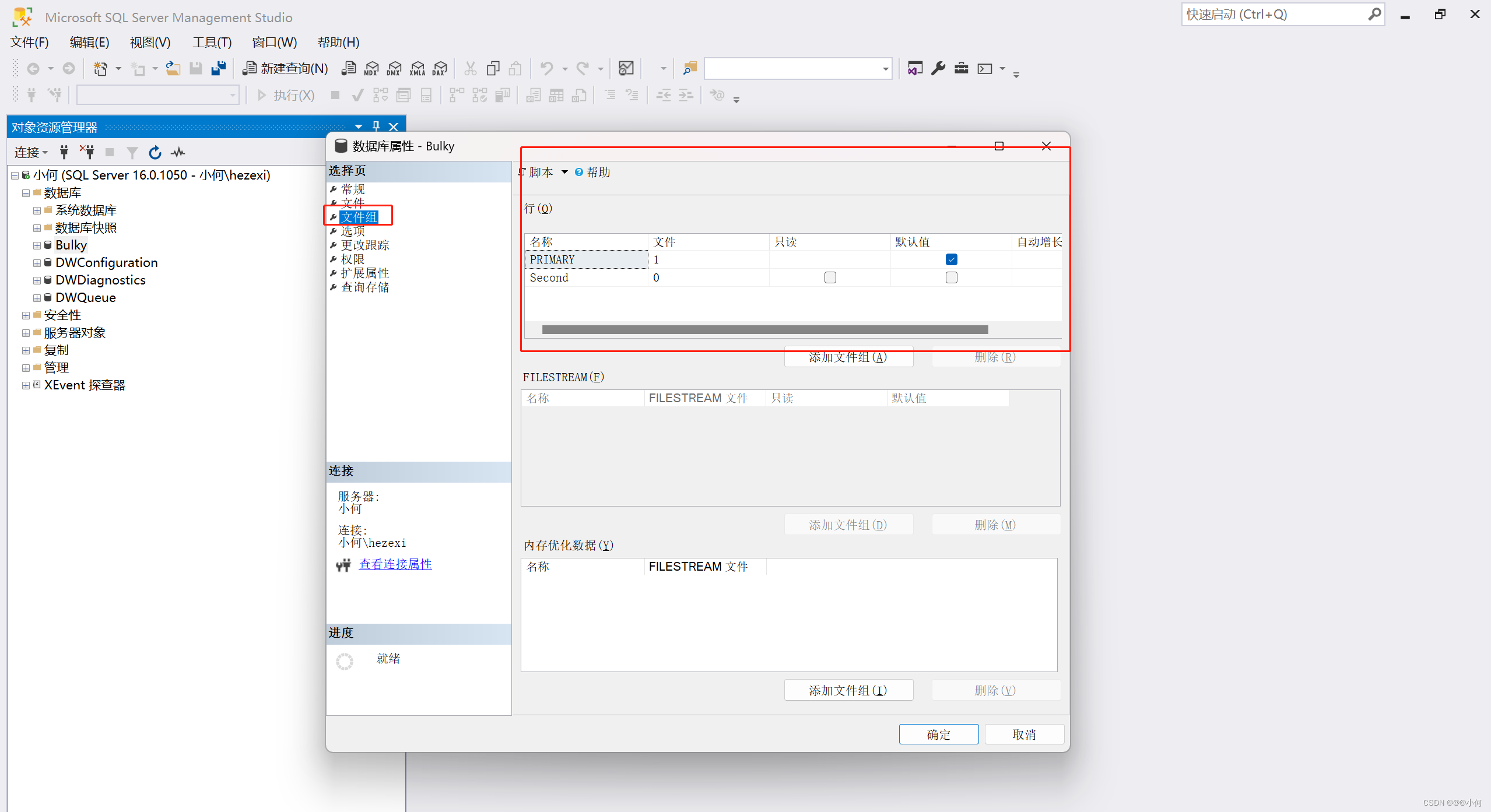
文件组是一个逻辑实体,实际上,数据存储在文件中( .mdf和.ndf )中,每一个文件组中都包含文件。
2.使用文件组的优势
在实际开发数据库的过程中,通常情况下,用户需要关注文件组,而不用关心文件的物理存储,即使DBA改变文件的物理存储,用户也不会察觉到,也不会影响数据库去执行查询。除了逻辑文件和物理文件的分离之外, SQL Server使用文件组还有一个优势,那就是分散IO负载,其实现的原理是:对于单分区表,数据只能存到一个文件组中。如果把文件组内的数据文件分布在不同的物理硬盘上,那么 SQL Server能同时从不同的物理硬盘上读写数据,把IO负载分散到不同的硬盘上。对于多分区表,每个分区使用一个文件组,把不同的数据子集存储在不同的磁盘上,SQL Server 在读写某一个分组的数据时,能够调用不同的硬盘IO。
3.数据库操作
1.使用SSMS 方式
SSMS : Microsoft SqlServer Management Studio , 也就是数据库管理软件。
就是上图这种通过图形化界面来创建数据库的方式。
2.T-SQL方式
1.创建数据库
-- 创建数据库
create database 第二单元测试
-- 指定数据文件存储的文件组 on:在。。。。这上,primary:主文件组
on primary
(
-- 数据库的逻辑名称:相当于是某人的外号
Name = '第二单元测试', -- 逻辑名称需要是唯一
filename = 'D:\test\第二单元测试_物理名称.mdf', -- 物理名称
size=5mb, -- 文件初始大小,初始化必须>=5 ,因为创建数据库的model 模板信息 必须是
5mb以上
filegrowth = 4mb, -- 每次增长多少
maxsize =200mb -- 文件的最大值
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.创建次文件
alter database 第二单元测试
add file
(
-- 数据库的逻辑名称:相当于是某人的外号
Name = '第二单元测试_次文件',
filename = 'E:\test\第二单元测试_次文件.ndf', -- 物理名称
size=5mb, -- 文件初始大小,初始化必须>=5 ,因为创建数据库的model 模板信息 必须是
5mb以上
filegrowth = 4mb, -- 每次增长多少
maxsize =200mb -- 文件的最大值
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.简化创建数据库(初学者推荐)
-- create database <数据库名称>;
create database 任我行教学管理系统
- 1
- 2
4.删除数据库
-- 切换数据库
use master;
-- drop database <数据库名称>;
drop database 任我行教学管理系统;
- 1
- 2
- 3
- 4
5.查看数据库信息
-- exec sp_helpdb '<数据库名称>'
exec sp_helpdb 'Soa模拟考试'
- 1
- 2
6.修改数据库名称
-- exec sp_renamedb '<需要修改的数据库的名称>','<新的数据库名称>' ;
exec sp_renamedb
'第二单元测试', -- 需要修改的数据库的名称
'第二单元' -- 新的数据库名称
- 1
- 2
- 3
- 4
7.切换数据库
-- use <数据库名称>
use 任我行教学管理系统;
- 1
- 2
4.备份与还原
可能有一天,数据库遭黑客攻击,数据库遭破坏,这个时候就需要时常的做文件的备份。也有可能公司来了一个马大哈,把数据库给删除(删库跑路),这个时候也需要备份。
1.备份
-- backup database <数据库名称> to disk = '磁盘路径';
backup database 第二单元测试 to disk ='D:\test\第二单元测试.bak';
- 1
- 2
2.还原
- 数据库不存在的情况下:
-- restore database <数据库名称> from disk = '磁盘路径'
restore database 第二单元测试 from disk = 'D:\test\第二单元测试.bak'
- 1
- 2
- 数据库存在的情况下:
-- with replace:替换
-- restore database <数据库名称> from disk = '磁盘路径' with replace;
restore database 第二单元测试 from disk = 'E:\test\第二单元测试.bak' with
replace;
- 1
- 2
- 3
- 4
5. 附加与分离
假设我有一个比较好的数据库,大家都想要,我可以发给你们,但是直接发送不了,因为会提示“这个文件在数据库 SqlServer 中打开”,这个时候就需要使用分离,将这个数据库文件从SqlServer 中 分离出去。
现在数据库已经分离并且数据库也发给你们了,我自己也想要用这个数据库,这个时候就要重新的附加到 SQLSERVER 中来。
1.分离
-- execute:执行
-- sp_detach_db:分离的存储过程(理解为一个函数)
-- execute sp_detach_db '<数据库名称>'
execute sp_detach_db 'Soa模拟考试'
- 1
- 2
- 3
- 4
2.附加
-- 附加
-- sp_attach_db:附加的存储过程
-- exec sp_attach_db '<数据库名称>','<数据库文件所在路径>' ;
exec sp_attach_db 'Soa模拟考试','C:\Program Files\Microsoft SQL
Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\Soa模拟考试.mdf'
- 1
- 2
- 3
- 4
- 5
3.数据类型与表操作
1.数据类型
1.Character 字符串

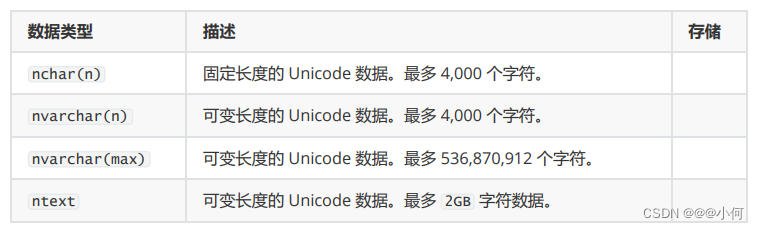
2.Unicode 字符串
3.Binary 类型

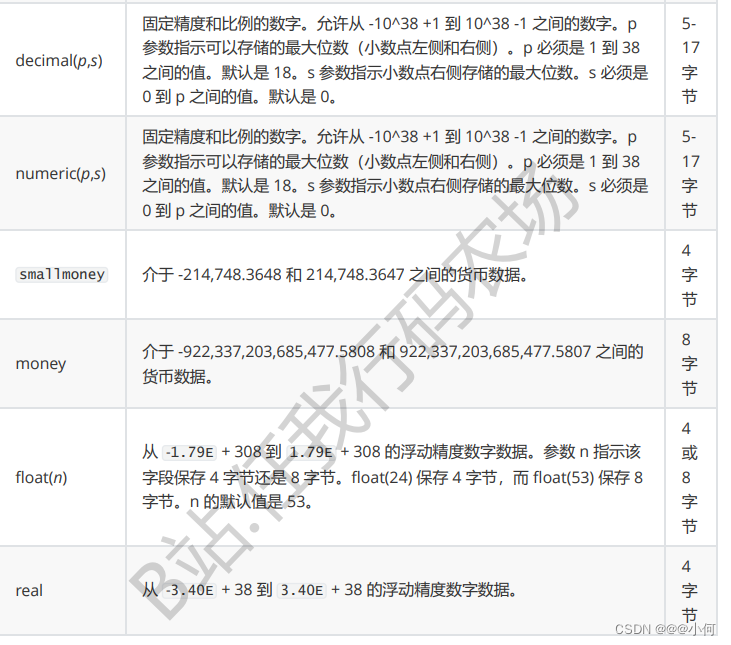
4.Number 类型

5.Date 类型
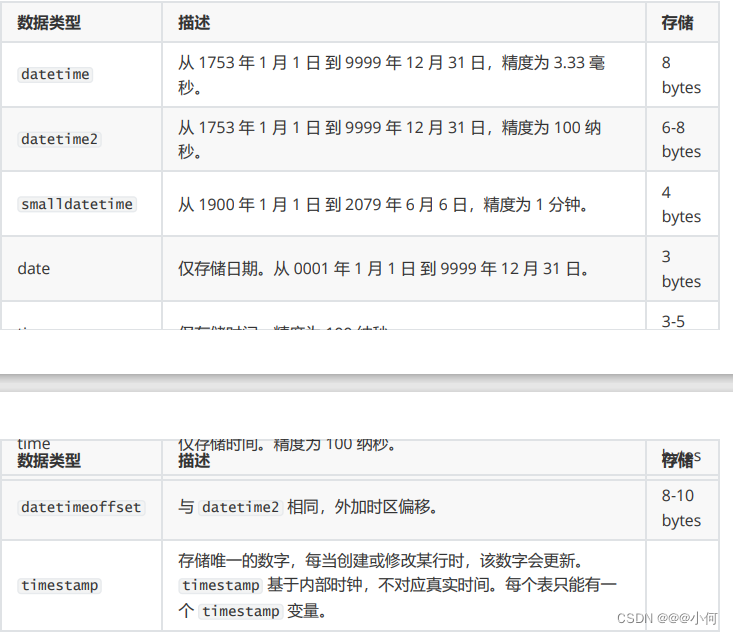
6.其他数据类型
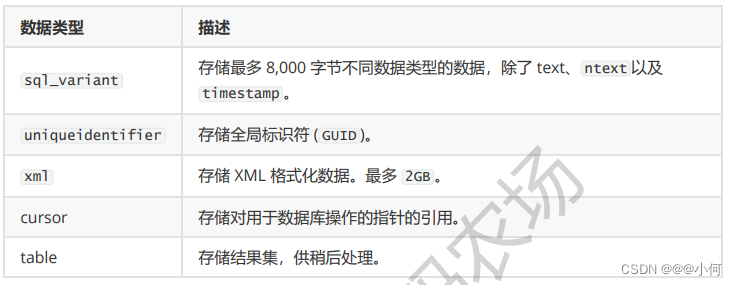
1.C# 中的 类型 对应的 Sql 类型
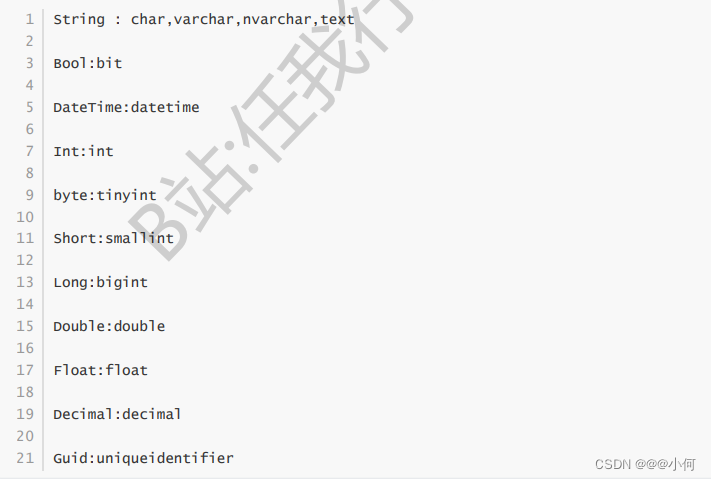
2. Binary 类型可以存储的类型有哪些
音频,视频,文件(图片)
- 1
3.常用的数据库类型有哪些

7.sql 中的Character和Unicode 区别
CHAR(n)类型
将 int ASCII 代码转换为字符的字符串函数。参数n是介于 0 和 255 之间的整数。如果整数表达式不在此范围内,将返回 NULL 值。
nchar 和 nvarchar nchar 是固定长度 Unicode 数据的数据类型, nvarchar 是可变长度 Unicode
数据的数据类型,二者 均使用 UNICODE UCS-2 字符集。
nchar(n) 类型 包含 n 个字符的固定长度 Unicode 字符数据。n 的值必须介于 1 与 4,000 之间。存储大小为 n
字节的 两倍。 nchar 在 SQL-92 中的同义词为 national char 和 national character。
nvarchar(n) 类型 包含 n 个字符的可变长度 Unicode 字符数据。n 的值必须介于 1 与 4,000
之间。字节的存储大小是所 输入字符个数的两倍。所输入的数据字符长度可以为零。 nvarchar 在 SQL-92 中的同义词为
national char varying 和 national character varying。
8.Char 与 varchar 对比
- CHAR的长度是不可变的,而VARCHAR的长度是可变的,也就是说,定义一个CHAR[10]和
VARCHAR[10],如果存进去的是‘ABCD’, 那么CHAR所占的长度依然为10,除了字符‘ABCD’外,后面 跟六个空格,而VARCHAR的长度变为4了,取数据的时候,CHAR类型的要用trim()去掉多余的空 格,而VARCHAR类型是不需要的。- CHAR的存取速度要比VARCHAR快得多,因为其长度固定,方便程序的存储与查找;但是CHAR 为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可以说是以空间换取时间效率,而VARCHAR则是以空间效率为首位的。
- CHAR的存储方式是,一个英文字符(ASCII)占用1个字节,一个汉字占用两个字节;而 VARCHAR的存储方式是,一个英文字符占用2个字节,一个汉字也占用2个字节。
- 两者的存储数据都是非unicode的字符数据。
2.数据表- table
数据表:相当于是C#中的类,是用于存储数据的数据库对象。
1.SSMS方式
在数据库管理软件中以图形化的方式来创建表。
2.T-SQL 方式
通过代码来创建表。
use step2_unit2; --创建表格 create table Student ( Id int, StudentNo char(11), Phone char(11), Sex nchar(4) ); --修改表格,添加姓名字段,varcahr(20) alter table Student add NickName varchar(20); --修改字段类型,将NickName更改为nvarchar(30) alter table Student alter column NickName nvarchar(30); --删除字段 alter table Student drop column NickName;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4.表约束
为了维护数据表的数据完整性而设定的一系列规则,防止用户在数据表中插入一些错误的数据。
1.表约束分类
- 主键约束:保证数据的完整性,唯一性,原子性(Id:编号)。
- 外键约束
例如:
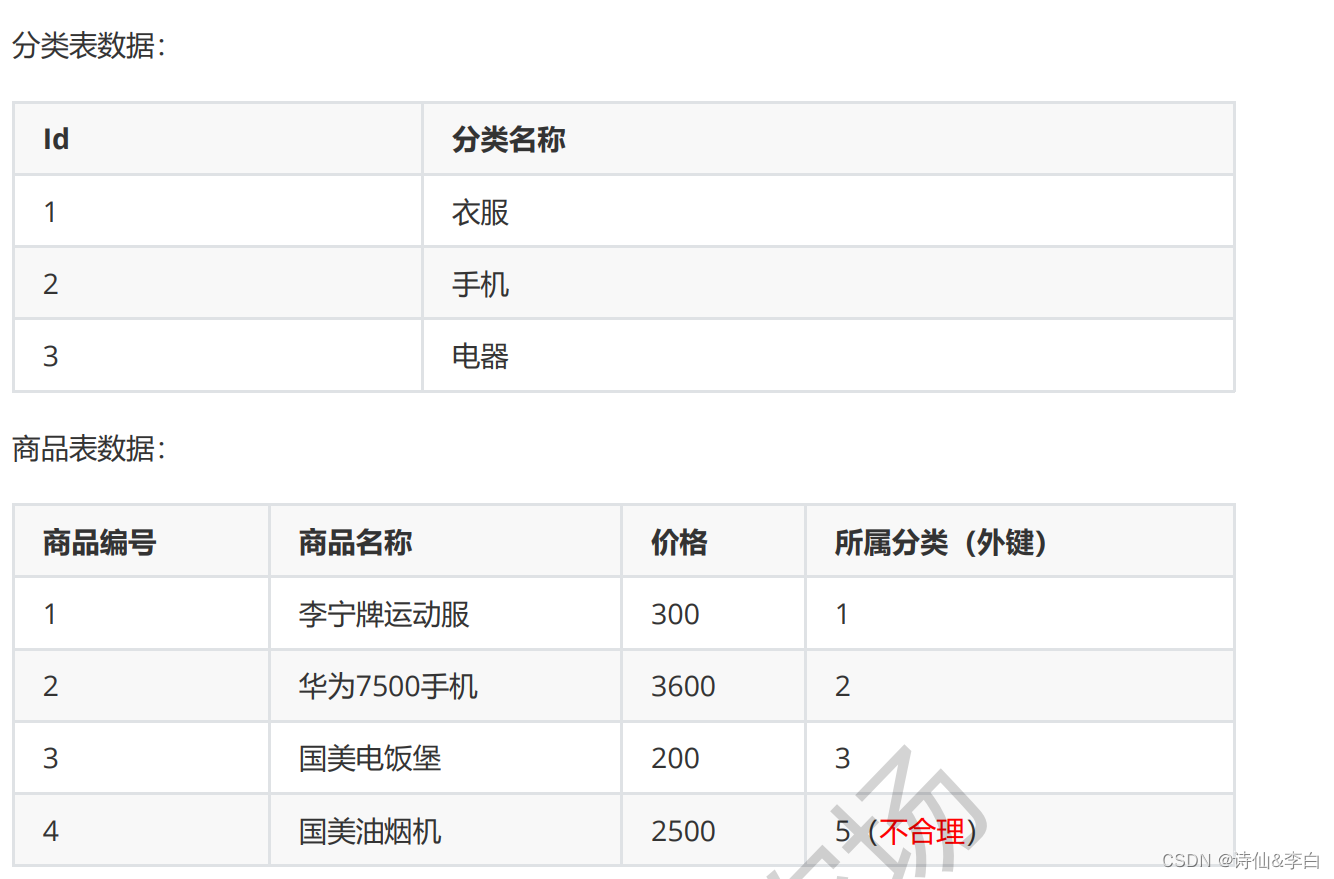
- 唯一约束。
- 检查约束。
- 默认值约束。
- 非空约束。
2.主键约束
1.简介
主键只能有一个,但是可以由1-n个字段组成,多个字段组成的主键叫复合主键。
-- 在表中添加主键约束 create database 第四单元; -- 简写的创建数据库的语法,数据库的相关参数都是默认值 -- 切换数据库 use 第四单元; -- 第一种写法 create table Category ( -- 列级约束 Id int primary key identity, -- 商品分类编号, primary key 是主键约束 CategoryName varchar(20) ) -- 第二种写法 create table Category2 ( Id int identity, CategoryName varchar(20), --primary key(Id) -- 表级约束 constraint pk_category2_id primary key(id) ) -- 第三种写法,假设表已经创建完毕,突然发现,主键忘记创建了 create table Category3 ( Id int identity, -- 商品分类编号, primary key 是主键约束 CategoryName varchar(20) ) -- 表级约束 alter table Category3 add constraint pk_category3_id primary key(Id)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.表级约束,列级约束
列约束是对某一个特定列的约束,包含在列定义中,直接跟在该列的其他定义之后,用空格分隔,不必指定列名。
表约束与列定义相互独立,不包括在列定义中,通常用于对多个列一起进行约束,与列定义用’,’分隔,定义表约束时必须指出要约束的那些列的名称。
区别:
如果完整性约束涉及到该表的多个属性列,必须定义在表级上,否则既可以定义在列级也可以定义在表级。简而言之:
- 列级约束:列级约束是行定义的一部分,只能应用于一列上。
- 表级约束:表级约束是独立于列的定义,可以应用在一个表中的多列上。
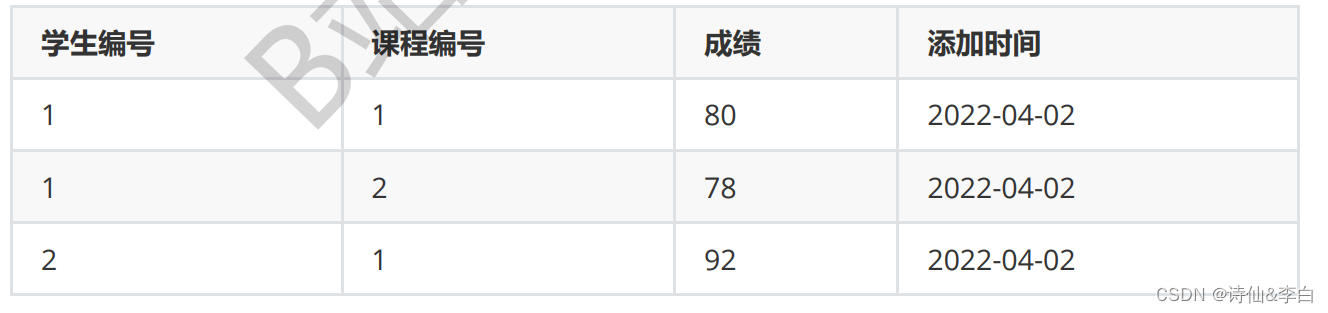
3.复合主键
create table score
(
studentId int,
courseId int,
score int,
addTime datetime,
primary key(studentId,courseId) -- 复合主键
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
例如:
5.表数据操作
1.SSMS 方式
在数据库管理软件中以图形化的方式来添加编辑数据。
2.T-SQL 方式
1.添加数据
数字不需要加单引号(加了也不会报错,但不建议这么干),字符类型要加单引号(C#是双引号表示字符串)。
create table Student ( Id int primary key identity, -- 每添加一条数据,Id从1开始,每次自增1 NickName nvarchar(15), -- unicode StudentNo char(11) , -- 学号 Sex nchar(2), Account varchar(20), -- 账号 [Password] varchar(50) -- 密码 ); create table Student ( Id int primary key identity(2,2), -- 每添加一条数据,Id从2开始,每次自增2 NickName nvarchar(15), -- unicode StudentNo char(11) , -- 学号 Sex nchar(2), Account varchar(20), -- 账号 [Password] varchar(50) -- 密码 ); insert into Student values ('娜娜','2002','女','user3','123456'), ('娜娜','2002','女','user3','123456'), ('娜娜','2002','女','user3','123456');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.修改数据
-- 1.将密码修改为 666666 -- 修改的语法结构:update 表 set 要修改的字段1= 字段1值,字段2 = 字段2值 update UserInfo set Pwd='666666' -- 这样修改会把所有的数据都修改了 -- 现在将 编号为3,2 的用户姓名 分别修改为 张三,李四 -- 语法结构: update 表 set 要修改的字段1= 字段1值,字段2 = 字段2值 where 条件字段 =条件值 update UserInfo set UserName='张三' where Id=3 update UserInfo set UserName='李四' where Id=2 -- 将密码为 666666 并且姓张的同学的 年龄 修改为 25 -- %:0-n 个任意字符 update UserInfo set Age=25 where Pwd='666666' and UserName like '张%' -- 将性别为男并且姓黄的同学的角色 修改为 超级管理员 -- 0:男 1:女 2:未知 3:保密 update UserInfo set RoleId='853d469f-7906-4eb6-9034-e4e1314db331' where Sex=0 and UserName like '黄%' -- 将 账号包含了 admin 并且 年龄大于30岁的同学的 密码修改为 1qaz2wsx 年龄 修改为 25 岁 update UserInfo set Pwd='1qaz2wsx',Age=25 where Account like '%admin%' and Age>30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.删除数据
-- 删除用户表中的数据
delete from Userinfo
select * from UserInfo -- 查询用户表
-- 删除张三,李四两位用户
Delete from UserInfo where UserName='张三' or UserName= '李四'
-- in:在...里面
delete from UserInfo where UserName in('张三','李四')
-- 删除用户编号为:4,5,6 并且 性别 =3 的用户信息
delete from UserInfo where Id in('4','5','6') and Sex='3'
或者
delete from UserInfo where Id in(4,5,6) and Sex=3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
什么情况下,一定需要加引号?
字符串,一定需要加引号,还有日期,时间,中文。
数字:可加可不加, 建议不要加。
4.清空数据
1.用法
-- 如何清空数据
delete from RoleInfo
-- 删除用户表中的数据
delete from Userinfo
select * from UserInfo -- 查询用户表
-- 清空数据
truncate table UserInfo ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.truncate 与 delete 的区别
truncate 是真正意义上的清空, 不能加任何查询条件,自增id 会重置
delete 只是删除数据,如果Id是自增,则自增种子不会从头开始。
5.联级删除,联级更新
-- 角色表 create table RoleInfo ( Id uniqueidentifier primary key, RoleName varchar(50) not null , CreateTime datetime not null default getdate() ); go -- 用户表 create table UserInfo ( Id int primary key identity, UserName varchar(50) not null, -- 联级删除:on delete cascade,联级更新 RoleId uniqueidentifier not null foreign key references RoleInfo(Id) on delete cascade on update cascade, Account varchar(50) not null, Pwd varchar(50) not null , Sex tinyint not null , Age tinyint not null ); go
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
6.简单查询
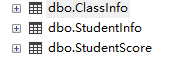
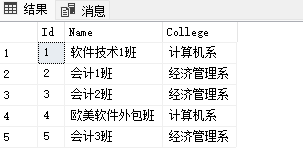
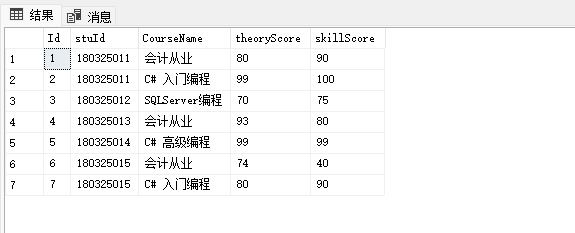
create database step2; go use step2; go -- 学生表 create table StudentInfo ( stuId char(10) primary key, -- 主键 stuName varchar(20), -- 姓名 ClassId int, -- 班级编号,逻辑外键,并不是真正的外键约束 stuPhone char(11), -- 电话号码 stuSex char(4), -- 性别 stuBirthday datetime -- 生日 ); go -- 班级表 create table ClassInfo ( Id int primary key identity, -- 班级的主键 Name varchar(30), -- 班级名称 College varchar(20) -- 学院 ); go -- 成绩表 create table StudentScore ( Id int primary key identity, -- 成绩的主键 stuId char(10), -- 学生外键 CourseName varchar(20), -- 课程 theoryScore int, -- 理论成绩 skillScore int -- 技能成绩 ); INSERT INTO dbo.StudentInfo(stuId,stuName,ClassId,stuPhone,stuSex,stuBirthday)VALUES ('180325011','任我行',5,'13823204456','男', '1999-09-09'), ('180325012','张三',4,'13823204452','女', '1998-08-08'), ('180325013','李四',2,'18899251152','男', '1997-07-07'), ('180325014','王五',1,'13597445645','女', '1998-08-08'), ('180325015','帅天行',5,'13814204456','男', '1998-06-06'), ('180325016','叶星辰',5,'17623204936','男', '1998-05-05'), ('180325017','赵日天',0,'13922044932','男', '1997-07-15'); go INSERT INTO dbo.ClassInfo(Name,College)VALUES ('软件技术1班', '计算机系' ), ('会计1班', '经济管理系' ), ('会计2班', '经济管理系' ), ('欧美软件外包班', '计算机系' ), ('会计3班', '经济管理系' ); go INSERT INTO dbo.StudentScore(stuId,CourseName,theoryScore,skillScore)VALUES ( '180325011', '会计从业', 80, 90 ), ( '180325011', 'C# 入门编程', 99, 100 ), ( '180325012', 'SQLServer编程', 70, 75 ), ( '180325013', '会计从业', 93, 80 ), ( '180325014', 'C# 高级编程', 99, 99 ), ( '180325015', '会计从业', 74, 40 ), ( '180325015', 'C# 入门编程', 80, 90 ); --1.如何查看表中所有数据? -- 查看学生表 -- select: 查询 -- *:代表表中所有的列 select * from StudentInfo -- * 号,在数据库优化的章节中,不建议使用*号,因为系统要解析这个*号,需要一点点时间 -- 实际开发中,如果字段过多,我们查询时,只查出业务中所需要的字段 select stuName,stuId from StudentInfo -- 查询班级表,执行 select id,Name,College from ClassInfo --2.如何查询指定几个字段的值? -- 查询学生的姓名,性别,生日,班级 select stuName,stuSex,stuBirthday,ClassId from StudentInfo --3.如何给字段取别名?(可以省略as) -- 把学生表中所有的字段都取别名 select stuId as 学生主键,stuName as 姓名,ClassId 班级编号,stuPhone 电话号码,stuSex 性别,stuBirthday 生日 from StudentInfo --4.distinct的用法?多个字段的用法? -- distinct:去除重复项 select distinct ClassId from StudentInfo select distinct stuSex from StudentInfo -- 指的是两个字段组合在一起,不会重复 select distinct stuSex,ClassId from StudentInfo -- 这两个结果集为什么会一样? select stuId,CourseName from StudentScore -- disctinct 后面跟着几个字段,表示 去除这几个字段(组合在一起)重复的意思 select distinct stuId,CourseName from StudentScore -- 这样写会去除重复吗? select distinct * from StudentInfo -- 这样写没有意义,反而增加系统的开销 --5.top 的用法? -- 取前3条数据 -- top :前。。。条 select top 3 * from StudentInfo --6.top ... percent(百分比)? -- 查询前30%的学生数据 -- 从这个故事告诉我们,数据没有半条,向上取整 select top 30 percent * from StudentInfo --7.查询年龄大于20岁的? -- year():获取年份 -- 年龄 = 当前年份 - 生日所在年份 select * from StudentInfo where (year(getdate())-year(stuBirthday))>20 -- 查询学生的,姓名,性别,年龄 所有字段取别名 -- 年龄 = 当前年份 - 生日所在年份 select stuName as 姓名,stuSex as 性别,(year(getdate())-year(stuBirthday)) as 年龄 from StudentInfo -- 查询80 后的女生 -- 80后:1980-1989 select * from StudentInfo where year(stuBirthday)>=1980 and year(stuBirthday)<=1989 and stuSex='女' --9.查询姓李的学生信息 -- like:模糊查询,中文意思是:像。。。 select * from StudentInfo where stuName like '李%' --10.列出技能成绩大于90分的成绩单 select * from StudentScore where skillScore>=90 --11.查询课程包含”SqlServer”的成绩信息 select * from StudentScore where CourseName like '%SqlServer%' --12.查询每个学生不同的成绩列表 select distinct stuId,skillScore from StudentScore --15.查询年龄大于20岁前3条学生的姓名,年龄,所有字段取别名 select top 3 stuName as 姓名,stuSex as 性别 from StudentInfo where (year(getdate())-year(stuBirthday))>20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
7.条件查询和分组查询
1.条件查询
条件查询是通过where子句进行检索的查询方式。
select 字段名1, 字段名2, …, 字段名n from 数据表名 where 查询条件
- 1
1.如何使用排序(升序,降序)
asc :表示升序(默认排序方式) desc :降序
排序语法:select … from 表名 [条件] order by 要排序的字段 asc/desc
-- 将成绩从高到低进行排序
select * from StudentScore order by (theoryScore+skillScore)
-- 查询学生表,按姓名升序显示
select * from StudentInfo order by stuName asc -- asc 可以省略
- 1
- 2
- 3
- 4
2.多字段如何排序
语法: select … from 表名 [条件] order by 第一要排序的字段 asc/desc , 第二要排序的字段
asc/desc
-- 查询成绩表,先按学生编号从低到高排序,再按成绩从高到低显示
select * from StudentScore order by stuId asc,(theoryScore+skillScore) desc
-- 查询学生信息,先按班级进行升序,再按生日进行降序
select * from StudentInfo order by ClassId asc ,stuBirthday desc
- 1
- 2
- 3
- 4
3.如何使用关系表达式查询(大于,小于,等于)
-- 查询 班级编号 在 1,3,5,7 里的学生信息
select * from StudentInfo where ClassId in(1,3,5,7)
-- 查询班级编号 不是偶数的学生信息
select * from StudentInfo where ClassId%2!=0
-- 查询技能成绩大于90分的成绩信息
select * from StudentScore where skillScore>90
- 1
- 2
- 3
- 4
- 5
- 6
4.如何使用between…and 的语法
between … and :在…之间,应用范围:数字类型
-- 查询技能成绩在60-80之间的成绩信息
-- 写法1
select * from StudentScore where skillScore between 60 and 80
-- 写法2
select * from StudentScore where skillScore>=60 and skillScore<=80
- 1
- 2
- 3
- 4
- 5
5.如何统计个数,平均分,最大数,最小数,求和
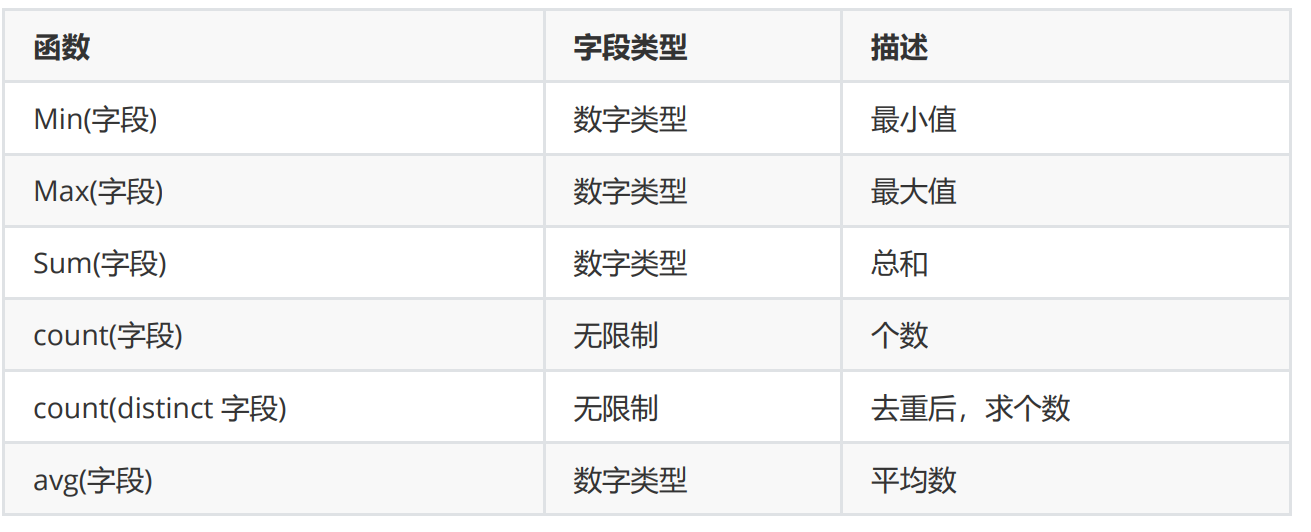
-- 统计学生的个数 select count(stuId) from StudentInfo -- 统计女生的个数 select count(stuId) as 女生个数 from StudentInfo where stuSex='女' -- 查询学生平均分 select avg(skillScore+theoryScore) from StudentScore -- 查询课程名称为'C# 入门编程'的平均分 select avg(skillScore+theoryScore) from StudentScore where CourseName='C# 入门编程' -- 查询班级编号最大的班级 -- 写法1 select max(classId) from StudentInfo -- 写法2 select top 1 (skillScore+theoryScore) from StudentScore order by (skillScore+theoryScore) desc -- 计算最低分 -- 写法1 select min(skillScore+theoryScore) from StudentScore -- 写法2 select top 1 (skillScore+theoryScore) from StudentScore order by (skillScore+theoryScore) asc -- 计算技能总分 select sum(skillScore) from StudentScore -- 计算学生编号为180325011 的技能总分 select sum(skillScore) from StudentScore where stuId='180325011' -- 查询有多少个人参加了考试 select count(distinct stuId) from StudentScore
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.聚合函数
将所有聚合函数写在一起。
select count(distinct stuId) 学生数量,Min(skillScore) 最小值,Max(skillScore) 最大值,Sum(skillScore) 总和 from StudentScore
- 1
3.exists 查询
功能:用于嵌套查询。
exists后的查询语句有结果则为真,无结果则为假,如果为真,则执行外层查询,否则外层查询不执行。
语法格式:
select 字段名1, 字段名2, …, 字段名n from 数据表名 where exists(select 字段名 from 数据表名 where …)
- 1
-- 如果存在大于20岁,则查询结果,
select * from StudentInfo where exists (select * from StudentInfo where year(getdate())-year(stuBirthday)>20)
- 1
- 2
--如果班级里面有两个以上的老王,则把老王的信息查询出来
select * from StudentInfo where exists (select * from(select count(stuId) as 数量 from StudentInfo where stuName like '王%') a where a.数量>=1)
- 1
- 2
4.分组查询
如何使用分组查询?他们的关键字分别是什么?
语法:select 要分组的字段,聚合函数 from 表名 group by 要分组的字段
--9.计算每门课程的平均分 select CourseName, avg(skillScore) as 平均分 from StudentScore group by CourseName --10.统计每个学生的平均分 select stuId,avg(skillScore+theoryScore) from StudentScore group by stuId -- 统计每个班级有多少个学生 select ClassId,Count(stuId) as 个数 from StudentInfo group by ClassId -- 统计每门课程有多少位同学在学习 select CourseName,count(stuId) from StudentScore group by CourseName -- 统计每个学生学习了多少门课程 select stuId,count(CourseName) from StudentScore group by stuId --11.查看每一门课程的平均分,总分,最高分,最低分 select CourseName,avg(skillScore),sum(skillScore),max(skillScore),min(skillScore) from StudentScore group by CourseName -- 11.1 查询每门课程,每个学生的最低分 select CourseName,stuId,min(skillScore) from StudentScore group by CourseName,stuId --12.统计每门课程的最低分,并且查询出70分以上的 -- having:在分组的基础之上进行数据过滤 select CourseName,min(skillScore) from StudentScore group by CourseName having min(skillScore)>70 --13.统计每门课程,但不包含课程C# 入门编程的最低分,并且查询出70分以上的 -- 13.1统计每门课程最低分 select CourseName,min(skillScore) from StudentScore group by CourseName -- 13.2 在统计之前加上where 课程!=C# 入门编程 select CourseName,min(skillScore) from StudentScore where CourseName!='C# 入门编程' group by CourseName -- 13.3 在统计之后加上having 最低分>=70 select CourseName,min(skillScore) from StudentScore where CourseName!='C# 入门编程' group by CourseName having min(skillScore)>70 --14.查询每门课程学习的人数大于等于2人的课程名称与学习人数。 select CourseName,count(stuId) from StudentScore group by CourseName having count(stuId)>=2 -- 15.查询不只学了一门课程的学生编号与学习的课程数 -- 翻译成人话:每个学生学习的课程数,并且学习的数量大于1 select stuId,count(CourseName) from StudentScore group by stuId having count(CourseName)>1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
5.作业
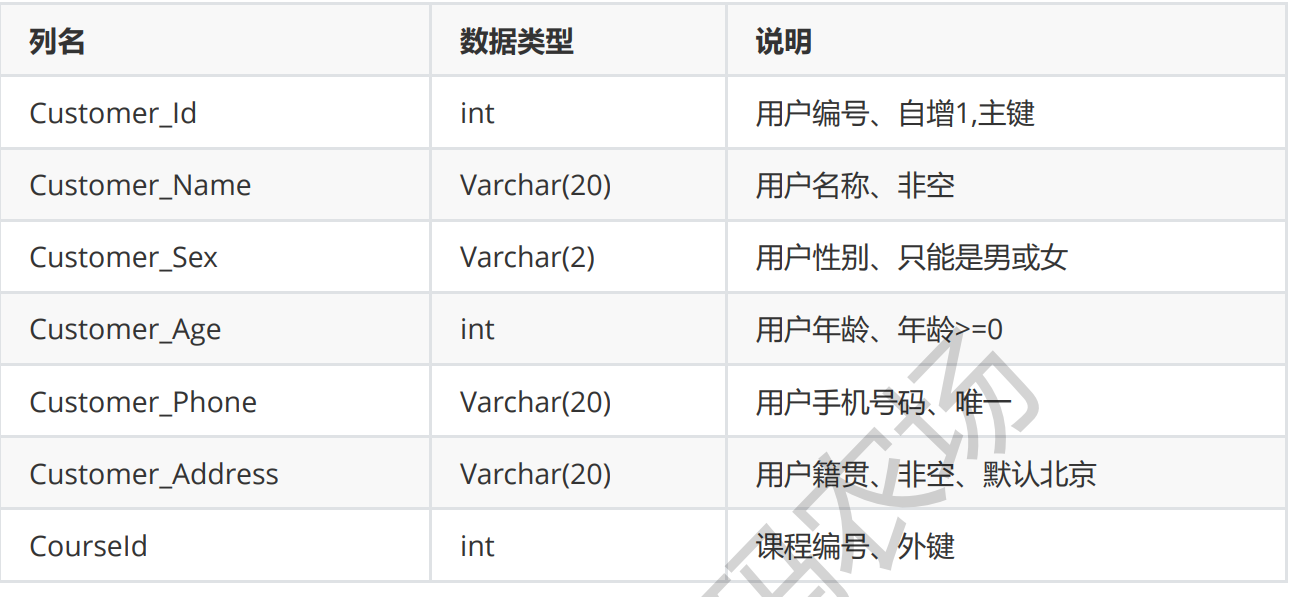
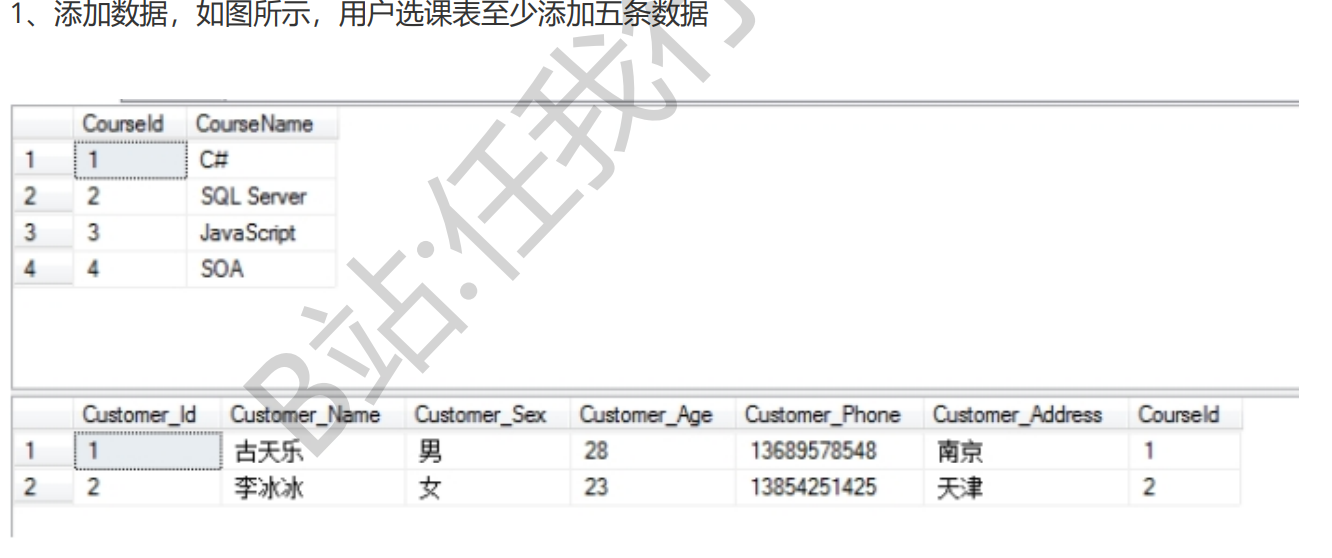
创建数据库Education_DB,创建表(根据说明创建符合规范的表),如图所示:
课程表:

用户选课表:
需求描述:
- 创建两张表并添加约束。
- 每张表添加5条数据。
- 查询用户选课信息表的前3条数据。
- 查询用户选课信息表中年龄大于20的用户信息。
- 查询用户选课信息表中性别为女的信息 。
- 查询用户选课信息表中用户名称、用户性别和用户年龄并为查询的字段起中文别名。
- 查询用户选课信息表的信息并按照年龄升序排列。
- 查询用户选课信息表中所有用户的年龄总和。
- 查询用户选课信息表中所有用户的最小年龄。
- 查询用户选课信息表中所有用户的最大年龄 。
- 查询用户选课信息表中所有用户的平均年龄。
- 查询用户选课信息表中一共有多少条数据 。
- 查询姓李的用户信息。
- 查询姓张的两个字的用户信息。
- 查询每个课程有多少人选择 。
- 查询大于平均年龄的用户信息 。
- 查询大于平均年龄的前2条信息。
- 查询学习C#课程的人数。
答案示例(不唯一):
--2.每张表添加5条数据 insert into Course(CourseName) values ('语文'); insert into Course(CourseName) values ('数学'); insert into Course(CourseName) values ('英语'); insert into Course(CourseName) values ('物理'); insert into Course(CourseName) values ('化学'); insert into Course(CourseName) values ('操作系统'); insert into Course(CourseName) values ('数据结构'); insert into Course(CourseName) values ('语文'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('钢铁侠','男','21','111111','NewYork','1'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('蜘蛛侠','男','18','222222','London','2'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('绿巨人','男','30','333333','NewYork','3'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('绯红女巫','女','24','444444','California','4'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('黑寡妇','女','23','555555','Los Angeles','5'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('张大中','女','24','444444','California','6'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('张三','女','23','555555','Los Angeles','7'); insert into Customer(Customer_Name,Customer_Sex,Customer_Age,Customer_Phone,Customer_Address,CourseId) values('王五','男','29','666666','Los Angeles','1'); --3.查询用户选课信息表的前3条数据 select top 3 * from Customer; --4.查询用户选课信息表中年龄大于20的用户信息 select * from Customer where Customer_Age>20; --5.查询用户选课信息表中性别为女的信息 select *from Customer where Customer_Sex='女'; --6.查询用户选课信息表中用户名称、用户性别和用户年龄并为查询的字段起中文别名 select Customer_Name as 名字,Customer_Sex as 性别,Customer_Age as 年龄 from Customer; --7.查询用户选课信息表的信息并按照年龄升序排列 select *from Customer order by Customer_Age; --8.查询用户选课信息表中所有用户的最小年龄 select min(Customer_Age) from Customer; --9.查询用户选课信息表中所有用户的最大年龄 select max(Customer_Age) from Customer; --10.查询用户选课信息表中所有用户的平均年龄 select avg(Customer_Age) from Customer; --11.查询用户选课信息表中一共有多少条数据 select count(Customer_Age) from Customer; --12.查询姓李的用户信息 select *from Customer where Customer_Sex like '李'; --13.查询姓张的两个字的用户信息 select *from Customer where Customer_Name like '张_'; --14.查询每个课程有多少人选择 select count(Customer_Name) from Customer group by CourseId; --15.查询大于平均年龄的前2条信息 select top 2 * from Customer where Customer_Age >(select avg(Customer_Age) from Customer); --16.查询学习语文课程的人数 select *from Customer where CourseId in ( select CourseId from Course where CourseName='语文' )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
8.嵌套查询
ClassInfo:
StudentInfo:

StudentScore:
--1.查询软件技术1班的所有学生信息 --思路:--分析可得:这需要综合查询2张表格,那么就要通过外键来连接2张表格进行综合查询 --1.找表:学生表,班级表,外键:ClassId --2.根据已经条件查询外键的值 --3.根据外键的值查询出题目的所有要求 select *from StudentInfo where ClassId= ( select Id from ClassInfo where Name='软件技术1班' ); --2.查询任我行同学的所有成绩 --思路: --1.找外键 stuId --2.根据已经条件查询外键的值 --3.根据外键的值查询出题目要求的成绩信息 select * from StudentScore where stuId= ( select stuId from StudentInfo where stuName='任我行' ); --3.查询'张三'同学所在班级信息 select *from ClassInfo where Id= ( select ClassId from StudentInfo where stuName='张三' ) --4.查询学号为'180325011'的同学所在班级所有男生的信息 select *from StudentInfo where ClassId= ( select ClassId from StudentInfo where stuId='180325011' ) and stuSex='男'; --5.查询班级名为“软件技术1班”一共有多少个女生信息 select * from StudentInfo where ClassId= ( select ClassId from ClassInfo where Name='软件技术1班' ) and stuSex='女'; --6.查询电话号为“18899251152”同学所在的班级信息 select * from ClassInfo where Id= ( select ClassId from StudentInfo where stuPhone='18899251152' ); --7.查询所有成绩高于平均分的学生信息 select * from StudentInfo where stuId in ( -- 查询出高于平均分的Stuid select stuId from StudentScore where skillScore>= ( select AVG(skillScore) from StudentScore ) ); --8.查询所有年龄小于平均年龄的学生信息 select * from StudentInfo where (year(getdate())-year(stuBirthday))< ( -- 计算平均年龄 select avg(year(getdate())-year(stuBirthday)) from StudentInfo ); --9.查询不是软件技术1班级的学生信息 --写法1: select * from StudentInfo where ClassId not in ( select Id from ClassInfo where Name='软件技术1班' ); --写法2: select * from StudentInfo where ClassId != ( select Id from ClassInfo where Name='软件技术1班' ); --10.查询所有班级人数高于平均人数的班级信息 -- 每个班有多少人 select * from ClassInfo where Id in ( select ClassId from StudentInfo group by ClassId having count(stuId)> ( -- 求平均人数 select avg(人数)from ( select count(stuId) as 人数 from StudentInfo group by ClassId ) aa ) ); --11.查询成绩最高的学生信息 select * from StudentInfo where stuId in ( select stuId from StudentScore where skillScore = ( select MAX(skillScore) from StudentScore ) ); --12.查询班级名是“会计1班”所有学生(使用in 关键字查询) select * from StudentInfo where ClassId in ( select Id from ClassInfo where Name='会计1班' ); --13.查询年龄是16、18、21岁的学生信息 select * from StudentInfo where (year(getdate())-year(stuBirthday)) in (16,18,21); --14.查询所有17-20岁且成绩高于平均分的女生信息 select * from StudentInfo where (year(getdate())-year(stuBirthday)) between 17 and 20 and stuSex='女' and stuId in ( select stuId from StudentScore where skillScore> ( select avg(skillScore) from StudentScore ) ); --15.查询不包括'张三'、'王明'、'肖义'的所有学生信息(not in 关键字查询) select * from StudentInfo where stuName not in('张三','王明','肖义') --16.查询不是“计算机系”学院的所有学生(not in 关键字查询) select * from StudentInfo where ClassId not in ( select Id from ClassInfo where College='计算机系' ); --17.-查询成绩比学生编号为'180325011','180325012'其中一位高的同学 -- any,some:某一个,其中一个 select * from StudentInfo where stuId in ( select stuId from StudentScore where skillScore> some ( select skillScore from StudentScore where stuId in('180325011','180325012') ) ); --18.查询成绩比学生编号为'180325011','180325012'都高的同学(all) -- all:所有 select * from StudentInfo where stuId in ( select stuId from StudentScore where skillScore> all ( select skillScore from StudentScore where stuId in('180325011','180325012') ) ); --19.-Row_Number() Over(Order by 字段):按某个字段进行编号排名 -- 以stuId进行升序排名 select Row_Number() Over(Order by stuId) ,* from StudentInfo --20.按总成绩降序排序并给每一位同学进行编号 select Row_Number() Over(Order by skillScore desc) as 排名, * from StudentScore --21.按总成绩降序排序后查询4-8名的学生信息 select * from ( select Row_Number() Over(Order by (skillScore+theoryScore) desc) as 排名, * from StudentScore ) aa where aa.排名 between 4 and 8; --22.sqlserver 2012以后,offset rows fetch next rows only用于从有序的结果集中,跳过一定数量的数据行,获取指定数量的数据行,从而达到数据行分页的目的 -- offset:在。。。位置 select * from StudentScore order by (skillScore+theoryScore) desc offset 3 rows fetch next 5 rows only; --23.获取按Id排序后的第3-5位同学信息 select * from ( select Row_Number() Over(Order by StuId) as 排名, * from StudentScore ) aa where aa.排名 between 3 and 5; --24. select * from StudentScore order by Id offset 2 rows fetch next 3 rows only;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
9.连接查询
连接查询就是把多张表连接成一张表。
其实连接查询和上面学习过的嵌套查询,都属于共同查询多个表。但是,嵌套查询用的并不是很多,而且也不简单(但是嵌套查询也要会。)。连接查询也是很重要的一个知识点。
内连接会把两表中匹配上的数据进行连接显示,注意是匹配上的数据,如果匹配不上就不会显示。
1.连接查询的分类
- 内连接。
- 外连接(左外连接,右外连接,全连接)。
- 自连接。
- 交差连接(用处不大,暂时不学)。
2.内连接
1.简介
以下为2张表的结构:
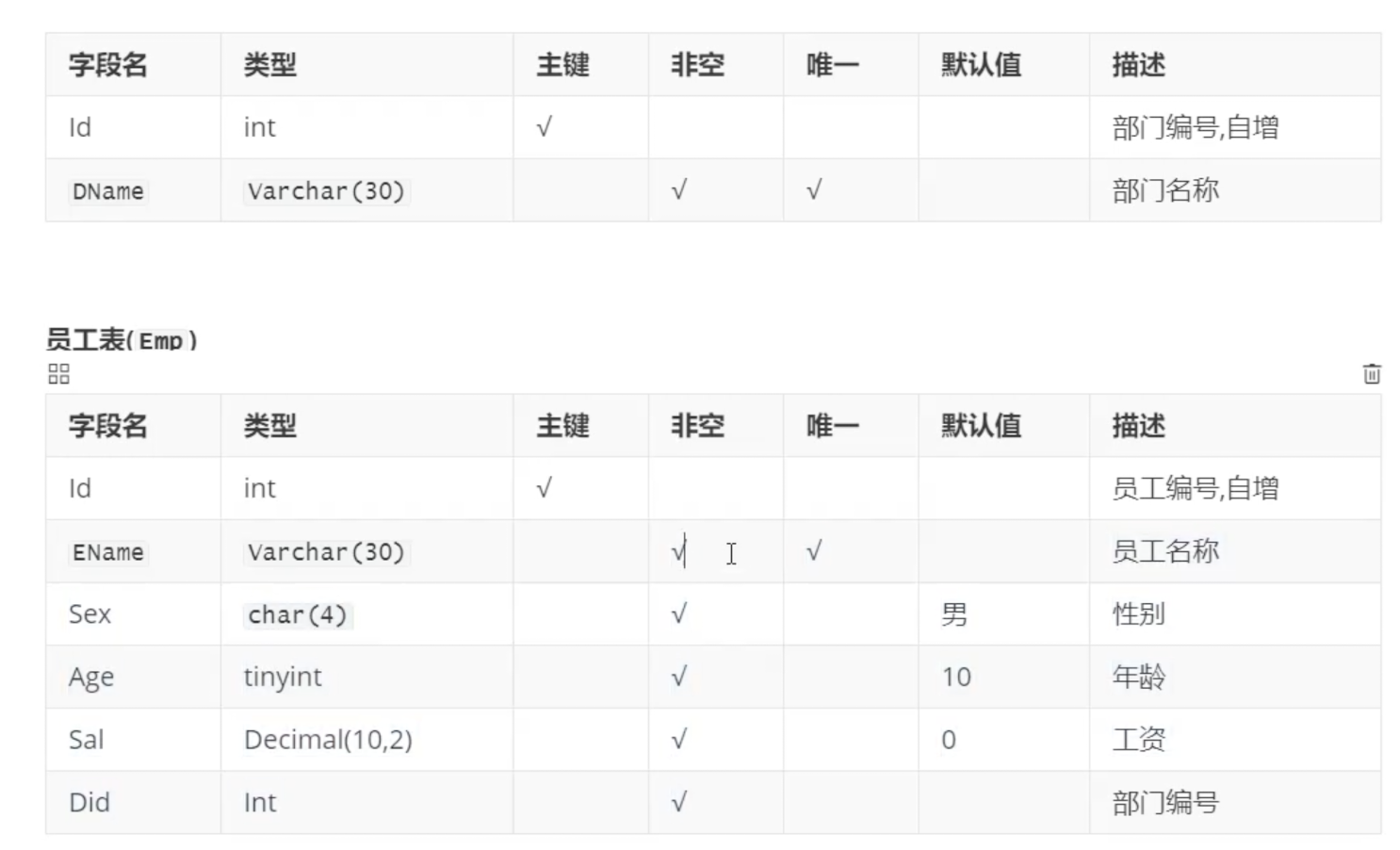
语法格式:select 字段列表 from 表1 inner join 表2 on 表1.外键=表2.外键。
注意:
- Join 与 inner join等效(默认为内连接)。
- inner join:内连接。
- on:当…时。
- 在使用连接时,尽量避免使用 * 获取字段。
代码示例:
--2.查询部门编号、部门名
select Id,DName from Dept;
--3.查询员工姓名,薪资
select * from Emp;
--4.查询员工姓名,薪资,所在部门
select *from Emp inner join Dept on Emp.Did=Dept.Id;
--5.查询分配了部门的员工信息和相应的部门信息(内连接)
select a.*,b.DName from Emp a join Dept b on a.Did=b.Id; --这里分别对2张表格取了别名
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.等值内连接
条件是等量关系。
select * from 表1 (inner) join 表2 on 表1的主键列 = 表2的外键列
注:表1是主键表,表2是外键表
- 1
- 2
仍然以上文中嵌套查询中的3张表为例:
use step2; -- 1.查询出分配了班级的学生和班级信息 select a.*,b.Name,b.College from StudentInfo a inner join ClassInfo b on a.ClassId=b.Id; -- 2.查询出软件技术1班的学生和班级信息 select a.*,b.Name,b.College from StudentInfo a inner join ClassInfo b on a.ClassId=b.Id where b.Name='软件技术1班' -- 3.查询分配了班级,年龄又在20岁以上的学生和班级信息 select a.*,b.Name,b.College from StudentInfo a inner join ClassInfo b on a.ClassId=b.Id where (year(getdate())-year(stuBirthday))>20; -- 4.查询分配了班级,年龄又在20-24之间的学生和班级信息 select a.*,b.Name,b.College from StudentInfo a inner join ClassInfo b on a.ClassId=b.Id where (year(getdate())-year(stuBirthday)) between 20 and 24; -- 5.查询没有学生的班级名称 -- 如果这个班有学生,是不是一定会在学生中有classId -- 如果说在学生表中没有出现的classId,是不是就表示 那个班没有学生呢? select Name from ClassInfo where id not in ( select classId from StudentInfo ); -- 6.查询分配了班级,性别又为女的学生和班级信息 select stuName,stuBirthday,Name,College from StudentInfo a inner join ClassInfo b on a.ClassId=b.Id where stuSex='女';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3.不等连接
连接条件中的关系是非等量关系,就是使用除(=)以外的比较运算符查询的内连接, 如:>,>=,<=,<,!>,!<,<> ,!=。
-- 1.每位同学除了自己所属的班级外查询出其余可选择的班级
select * from StudentInfo a join ClassInfo b on a.ClassId!=b.Id;
-- 2.查询其他同学的成绩
select * from StudentInfo a join StudentScore b on a.stuId!=b.stuId;
- 1
- 2
- 3
- 4
- 5
3.自连接
一张表看做两张表,自己连自己。
create table menu
(
Id int primary key identity,
Name varchar(30), -- 菜单名称
ParentId int -- 上级菜单
) ;
insert into menu values('商品管理',0),('系统管理',0),('订单管理',0) ;
insert into menu values('商品列表',1),('商品分类',1),('发布商品',1) ;
insert into menu values('权限管理',2),('用户管理',2),('角色管理',2) ;
insert into menu values('订单列表',3),('运费模板',3),('物流跟踪',3) ;
-- 查询所有菜单信息以及它的上级菜单名称
-- 自连接一定要取别名
select a.*,b.Name from menu a inner join menu b on a.ParentId=b.Id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.外连接
外连接是以一张表为基表,返回基表中所有记录及连接表中 符合条件的记录的连接查询。外连接分为以下3种:
- 左外连接 。
- 右外连接 。
- 全外连接。
1.左外连接
是以左表为基表,返回左表中所有记录及连接表中符合条件的记录的外连接:
- 以左表为基表 。
- 返回左表中所有数据。
- 连接表不符合条件以NULL填充。
数据库表仍以上文中嵌套查询表为例:
use step2;
-- 1.查询所有学生信息以及对应的班级信息(要求显示学生编号,学生姓名,班级编号,班级名称)
-- 左外连接:left outer join
select * from StudentInfo a left outer join ClassInfo b on a.ClassId =b.Id;
-- 左连接:以左表主表,不管是否匹配上,都会把左表中的数据都显示出来,未匹配的数据会以NULL进行填充
- 1
- 2
- 3
- 4
- 5
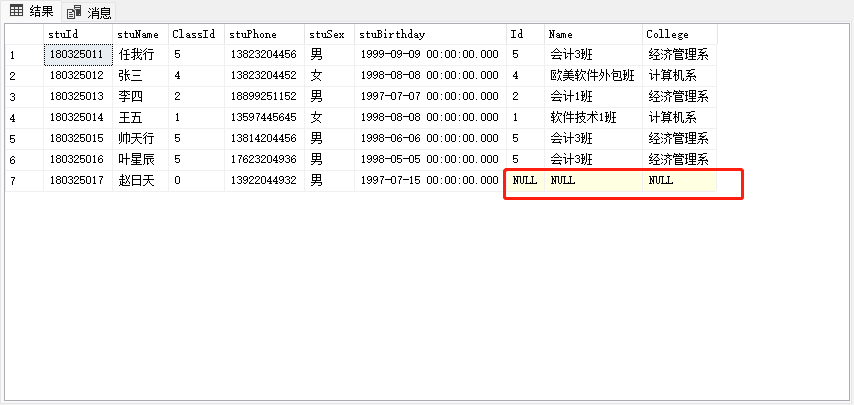
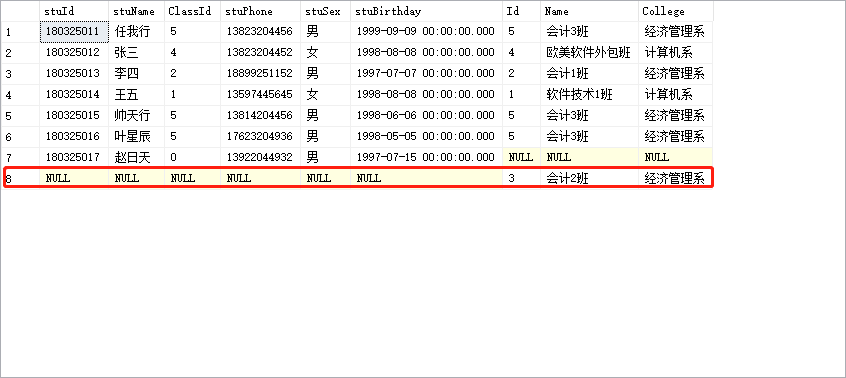
2.右外连接
是以右表为基表,返回右表中所有记录及连接表中符合条件的记录的外连接:
- 以右表为基表 。
- 返回右表中所有数据 。
- 连接表不符合条件以NULL填充。
-- 1.查询所有班级信息以及对应的学生信息(要求显示学生编号,学生姓名,班级编号,班级名称)
select * from StudentInfo a right outer join ClassInfo b on a.ClassId=b.Id;
-- 右连接:以右表为主表,不管是否匹配上,都会把右表中的数据都显示出来,未匹配上的数据会以NULL进行填充
- 1
- 2
- 3
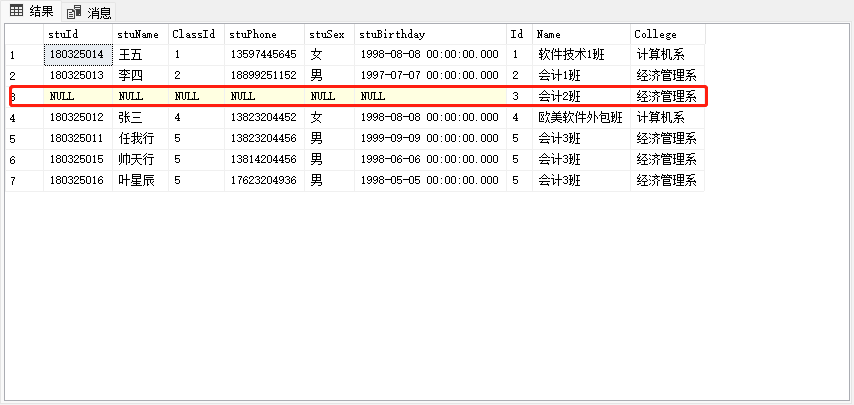
3.全外连接
是分别以左右表为基表的外连接:
- 将左表和右表所有的记录都显示。
- 连接表不符合条件以NULL填。
-- 1.查询所有学生信息以及所有班级信息(要求显示学生编号,学生姓名,班级编号,班级名称)
-- 全连接:full join,不管是否有没有匹配上,都会显示
select * from StudentInfo a full outer join ClassInfo b on a.ClassId=b.Id
- 1
- 2
- 3
5.联合查询
连接查询可以理解为把多张表的数据综合横着显示。
而联合查询可以理解为把多张表的数据竖着综合显示。
create table course1 ( Id int primary key, Name varchar(30) ); create table course2 ( Id int primary key, Name varchar(30) ); insert into course1 values(1,'c#'),(2,'sql'),(3,'.net core'),(4,'mysql'); insert into course2 values(1,'c#'),(2,'sql'),(3,'asp.net core'), (4,'docker'); select *from course1; select *from course2;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
如图,2张表数据分别为:
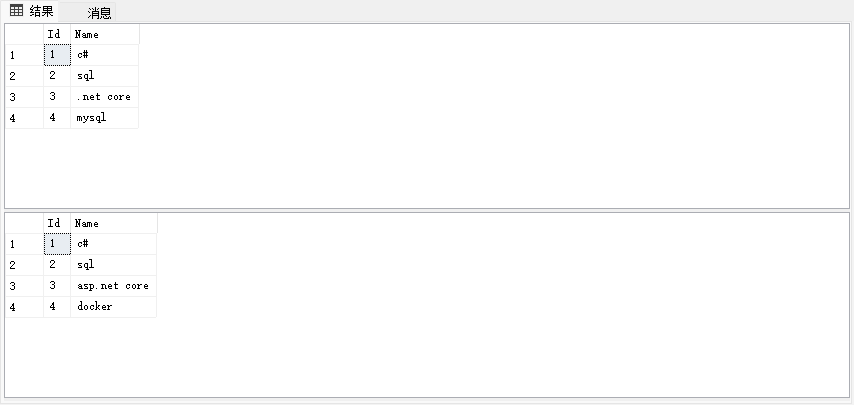
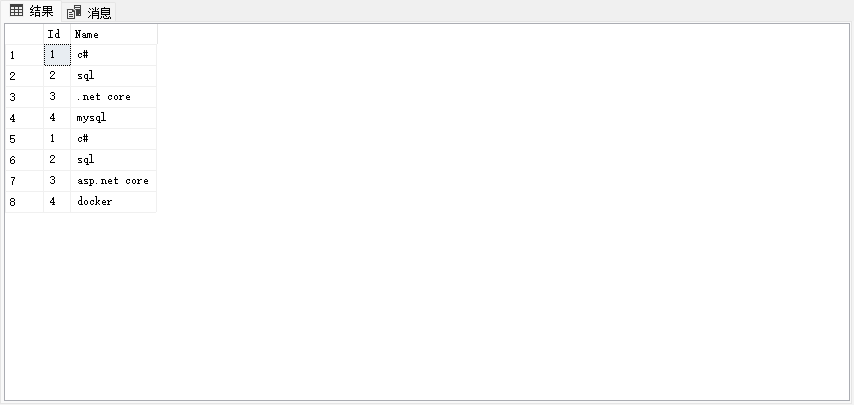
现在通过联合查询将2个表的数据合并在一起(相当于竖着堆叠在一起):
以下为操作语句:
select *from course1
union all
select *from course2
- 1
- 2
- 3
执行结果:
6.作业
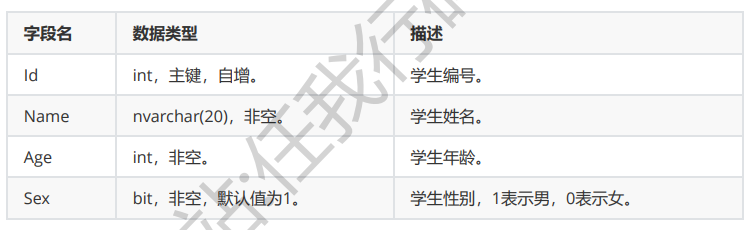
Students(学生表):
Teachers(老师表):

Courses(课程表):

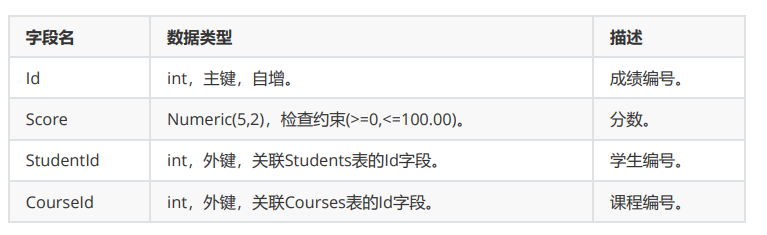
Scores(成绩表):
开发要求:
- 使用SSMS或SQL语句创建数据库。
- 按数据字典要求创建表结构。
- 分别给各表按照下列语句添加数据:
--1.向表Students中添加数据 insert into Students values('冯程',20,0) insert into Students values('许文强',18,1) insert into Students values('凌凌七',19,0) insert into Students values('莫向南',22,1) insert into Students values('路宝妮',25,0) insert into Students values('凤凰',16,1) --2.向表Teachers中添加数据 insert into Teachers values('梁冰','112') insert into Teachers values('李剑','113') insert into Teachers values('耿彬彬','001') insert into Teachers values('刘龙飞','002') insert into Teachers values('吴慧敏','116') insert into Teachers values('张静敏','068') insert into Teachers values('刘泽飞','167') insert into Teachers values('项天佑','153') --3.向表Courses中添加数据 insert into Courses values('C#入站编程',3) insert into Courses values('SQL Server',3) insert into Courses values('ASP.NET Core',5) insert into Courses values('前端入门',6) insert into Courses values('ASP.NET WebApi',8) insert into Courses values('Linux虚拟化技术',1) insert into Courses values('MySQL',1) --4.向表Scores中添加数据 insert into Scores values(100,6,1) insert into Scores values(90,3,1) insert into Scores values(100,3,2) insert into Scores values(99,3,3) insert into Scores values(95,3,4) insert into Scores values(90,3,5) insert into Scores values(91,3,6) insert into Scores values(89,3,7) insert into Scores values(100,1,3) insert into Scores values(70,1,4) insert into Scores values(100,2,3) insert into Scores values(80,2,1) insert into Scores values(90,2,2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4. 使用SQL语句查询如下:
- 查询学生表中的前5条记录并按照年龄进行降序排序,显示字段为中文:学号,姓名,年龄,性别。
- 查询姓“李”的老师的个数。
- 查询学生表中年龄大于16岁的男生信息。
- 统计每个教师所教的课程数量,显示字段包括老师编号,课程数量。
- 查询“梁冰”老师所教课程的信息。
- 查询成绩最高的学生编号及学生姓名。
- 按成绩进行降序排序,查询第6名到第10名的成绩信息。
- 按学生编号分组,查询平均成绩大于90分的同学的学生编号和平均成绩。
- 查询所有的课程信息及对应的老师信息,显示字段包含课程编号、课程名称、老师编号、老师姓 名。
- 查询学过“耿彬彬”老师所教课程的同学的学号、姓名。
- 每行SQL语句添加注释。
代码:
--1.查询学生表中的前5条记录并按照年龄进行降序排序,显示字段为中文:学号,姓名,年龄
select Id 学号,Name 姓名,Age 年龄,Sex 性别 from Students order by Age desc;
--2.查询姓“李”的老师的个数
select * from Teachers where Name like '李%';
--3.查询学生表中年龄大于16岁的男生信息
select *from Students where Age>=16 and Sex=1;
--4.统计每个教师所教的课程数量,显示字段包括老师编号,课程数量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

