- 1Hadoop 与 HBase 版本对应_hadoop3.3.0和hbase对应版本
- 2经验:调教200多个ChatGPT模型后的经验分享_经验chart gpt
- 3会议安排(贪心算法和动态规划)_会议安排 动态规划
- 4Android车载应用开发与分析 - Android Automotive概述与编译
- 5Java+SSM+JSP图书管理借阅系统源码+论文_毕业设计图书管理系统源代码
- 6AET生态新纪元:数字人AIGC平台发布会在香港成功举办
- 7联邦学习论文笔记——一种面向边缘计算的高效异步联邦学习机制
- 8IDEA中使用git拉取gitee上的代码并运行
- 9前端(五)——从 Vue.js 到 UniApp:开启一次全新的跨平台开发之旅_vue uniapp
- 10Java面试题:java服务端研发知识图谱pdf
NLP——Translation 机器翻译_机器翻译模型
赞
踩
为什么翻译任务困难


Statistical Machine Translation

基于统计的机器翻译任务通常通过翻译模型(Translation Model)和语言模型(Language Model)的结合来学习更强大的翻译模型。这种结合被称为统计机器翻译(SMT)。
-
翻译模型(Translation Model):翻译模型主要关注如何将源语言句子翻译成目标语言句子。它使用双语语料库进行训练,学习源语言和目标语言之间的翻译概率。基于短语的翻译模型是SMT中常用的模型之一,它将源语言和目标语言的句子划分为短语,并建立短语对之间的翻译概率。基于句法的翻译模型则利用语法结构信息来进行翻译。
-
语言模型(Language Model):语言模型主要关注目标语言句子的流畅性和合理性。它利用目标语言的单语语料库,学习目标语言中句子的概率分布。语言模型可以帮助翻译模型选择更合理的翻译候选,提高翻译的质量。
在SMT中,翻译模型和语言模型的结合通过联合概率来进行建模。给定一个源语言句子,翻译模型计算源语言句子到目标语言句子的翻译概率,语言模型计算目标语言句子的概率,然后将两者结合起来,得到最终的翻译结果。 通常使用最大似然估计或最大后验概率估计来训练这些模型参数。




- 那么如何从
corpora中学习 P ( f ∣ e ) P(f|e) P(f∣e) 呢?

- 这些给定的
sentence pair并没有进行对齐
- 这些给定的
Alignment 对齐

-
并行语料库(Parallel Corpora):并行语料库是指在源语言和目标语言之间具有对应关系的句子或短语集合。这种语料库通常是由人工翻译或对齐得到的,是进行机器翻译的理想数据。通过使用已有的并行语料库,可以直接将源语言和目标语言之间的句子或短语进行对齐。
-
基于词对齐(Word Alignment):基于词对齐的方法尝试将源语言和目标语言中的单词进行对应,以实现句子或短语的对齐。常见的词对齐算法包括IBM模型和统计短语对齐模型。这些模型使用统计方法来学习源语言和目标语言之间的单词对齐概率,从而实现对齐。
-
基于短语对齐(Phrase Alignment):基于短语对齐的方法将源语言和目标语言的短语进行对应,以实现句子或段落级别的对齐。常见的基于短语对齐的方法包括IBM模型和统计短语对齐模型。这些模型基于统计和概率模型,利用双语语料库来学习源语言和目标语言之间的短语对齐概率。
-
基于句法对齐(Syntax-based Alignment):基于句法对齐的方法尝试利用源语言和目标语言之间的句法结构进行对齐。这种方法通常使用句法分析工具来分析源语言和目标语言的句法结构,并基于句法结构之间的对应关系来进行对齐。
-
基于神经网络的对齐方法:近年来,随着神经网络的发展,基于神经网络的方法在对齐任务中取得了一些进展。这些方法使用神经网络模型来学习源语言和目标语言之间的对应关系,可以使用注意力机制或编码器-解码器模型来实现对齐。
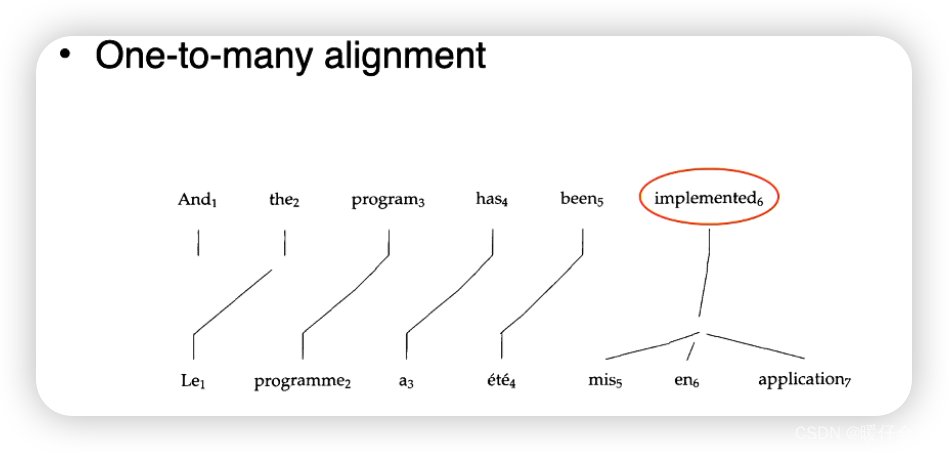
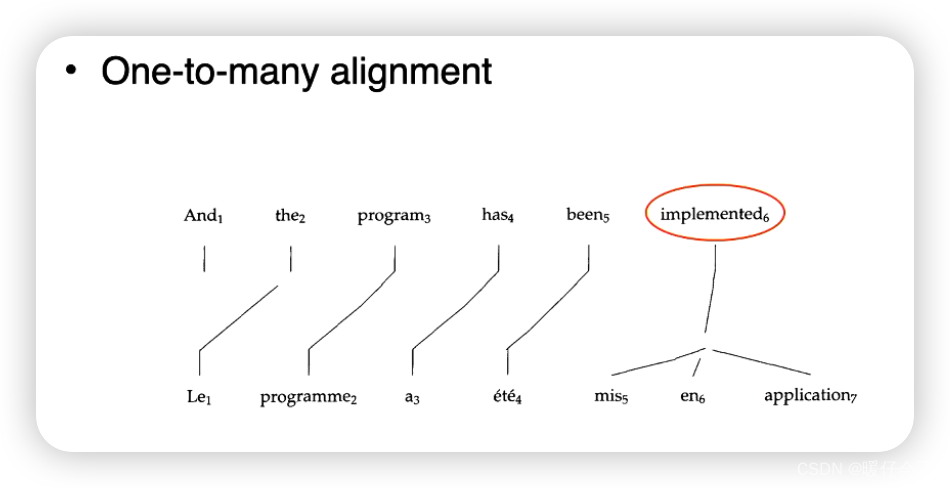
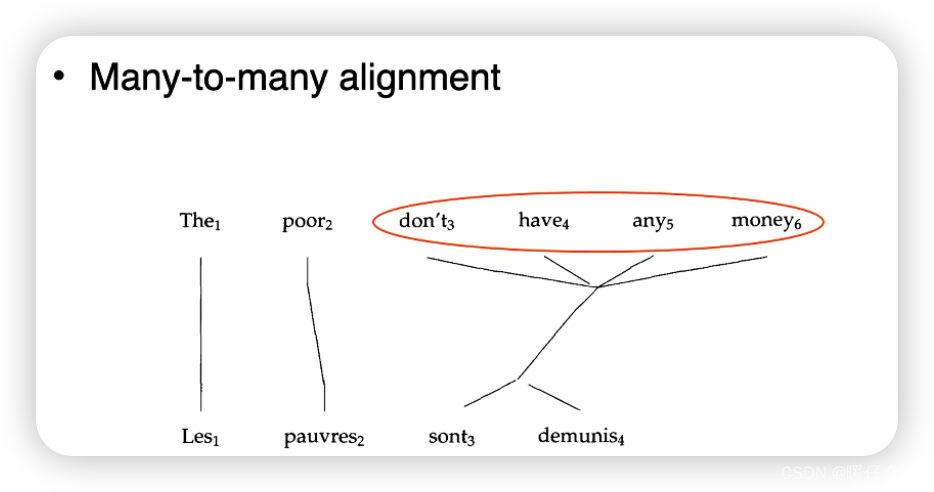
在对齐的时候可能出现下述情况:

summary

Neural Machine Translation

编码器-解码器结构: 基于神经网络的翻译模型通常采用编码器-解码器结构。编码器负责将源语言句子编码为一个固定长度的向量(语义表示),解码器则使用该向量生成目标语言的翻译结果。 编码器和解码器通常使用循环神经网络(RNN)或Transformer等模型来建模上下文和序列信息。
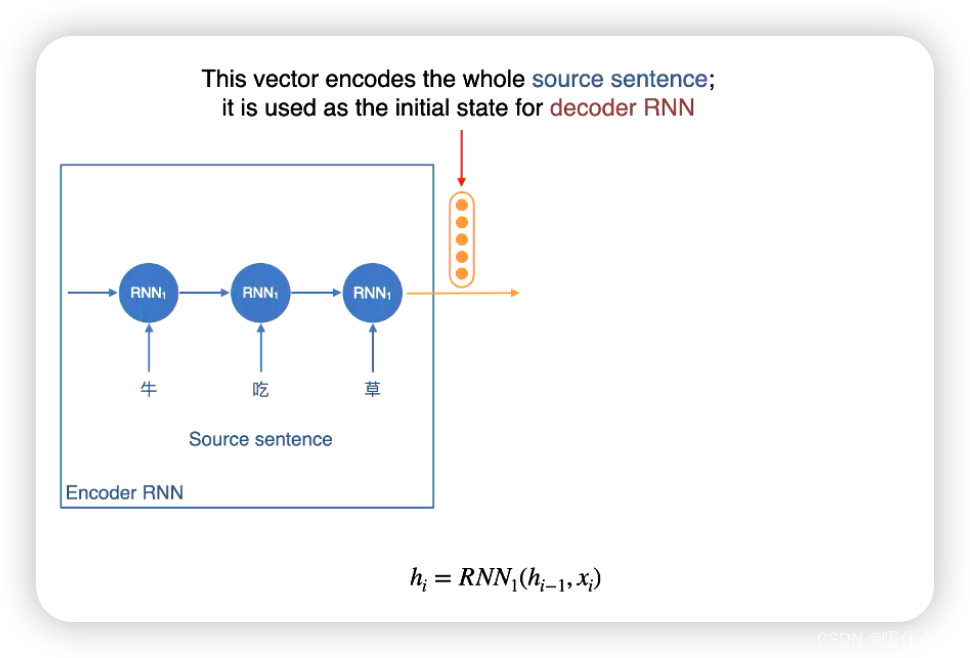
-
首先使用一个
encoder将信息编码成一个hidden vector你可以认为这个vector包含了原句子的所有语义信息 -
构建一个
decoder网络对这个hidden vector进行解码
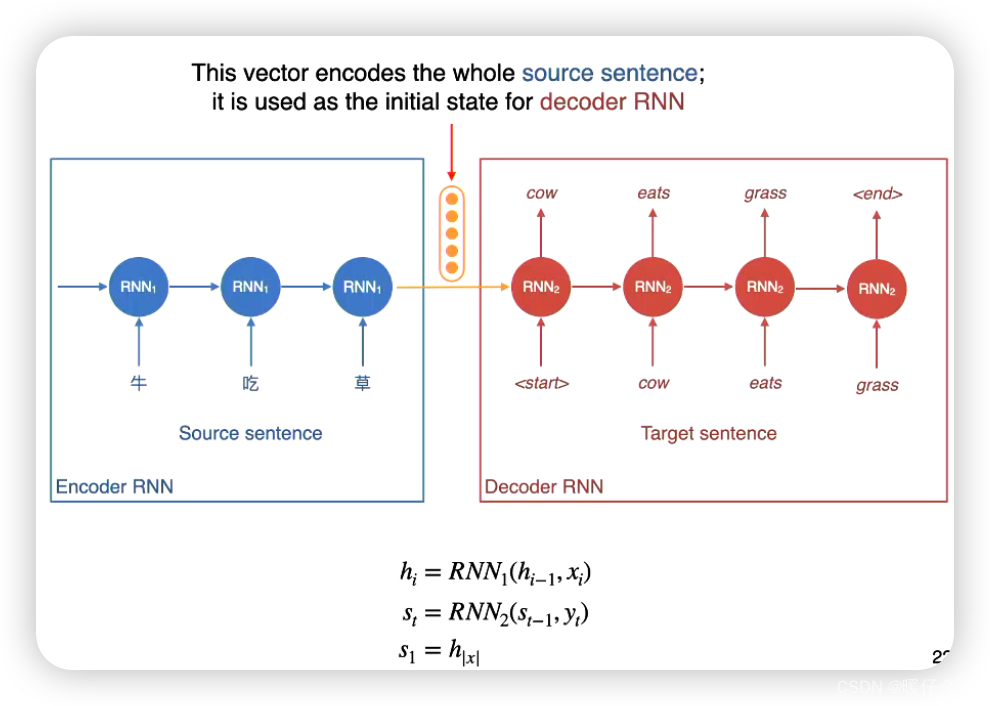
-
负责进行
decoder的模型可以被称为conditional language model -
条件语言模型(Conditional Language Model)是一种语言模型的变体,它在生成文本时不仅仅考虑上下文,还考虑一个给定的条件。
-
传统的语言模型(如n-gram模型)是基于给定前面的
n-1个词来预测下一个词的概率分布。而条件语言模型引入了额外的条件信息,使得生成的文本能够与条件相关。条件可以是多样的,例如上下文句子、特定的主题或指定的输入。
如何训练 Neural MT

- 依然需要平行的数据集
- 按照训练语言模型的方式来训练
loss 设定
- 在解码的时候,我们可以根据每个时间步的输出与
label之间的差距来计算每一步的损失,然后得到decoder端的总损失
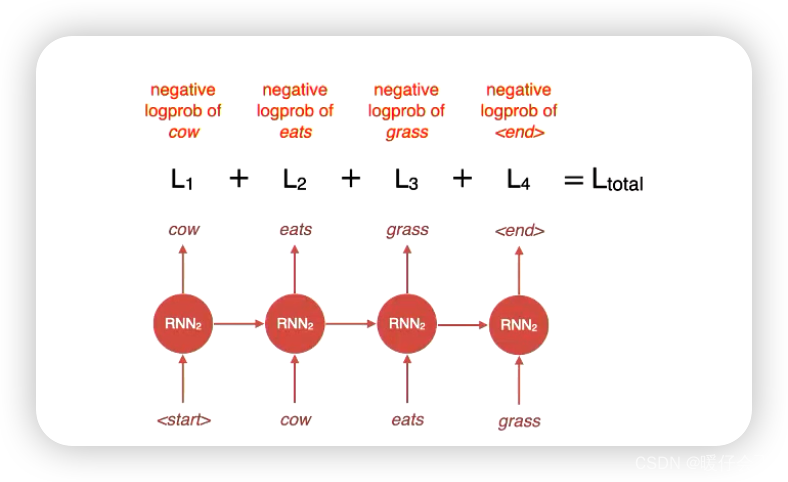
Training
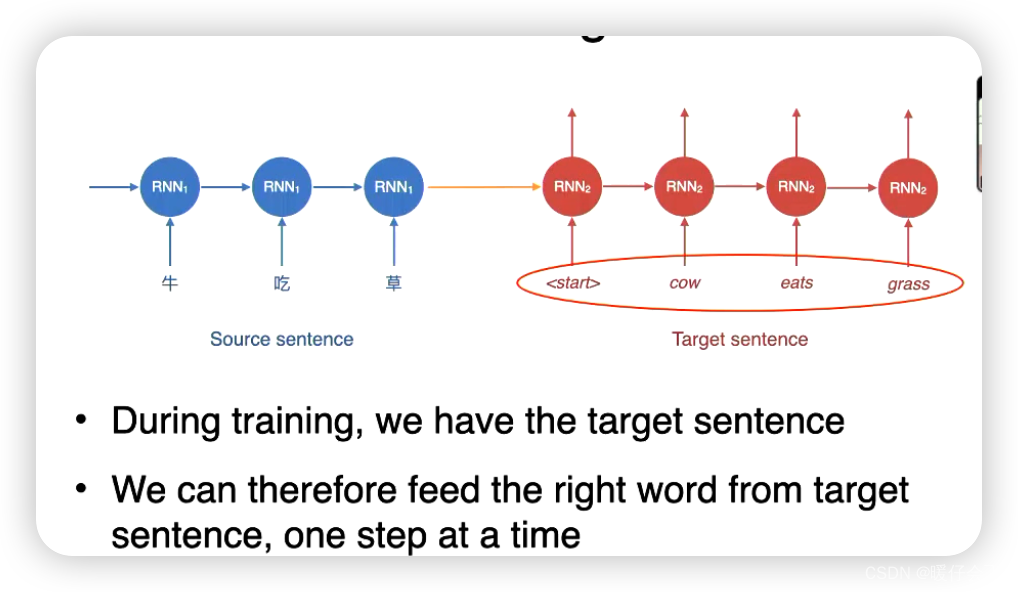
- 训练的过程非常简单,因为我们有
target sentence,按部就班执行即可
decoding at Test Time
- 但是在进行
evaluation的时候,由于没有target sentence,所以情况有些复杂
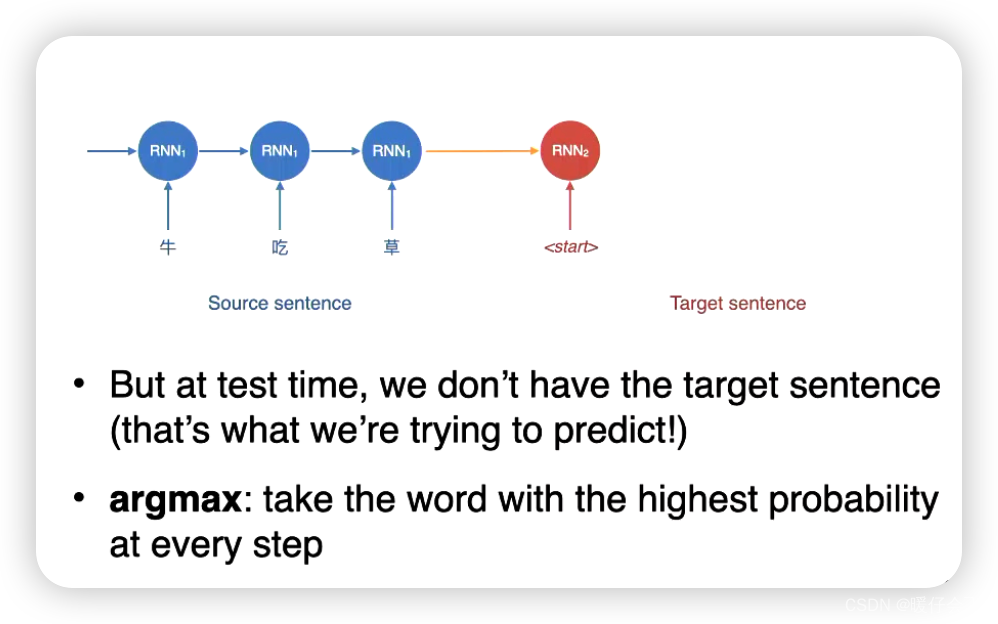
- 因此在预测的时候,我们只能按照更高的概率值来确定每一个时间步的输出
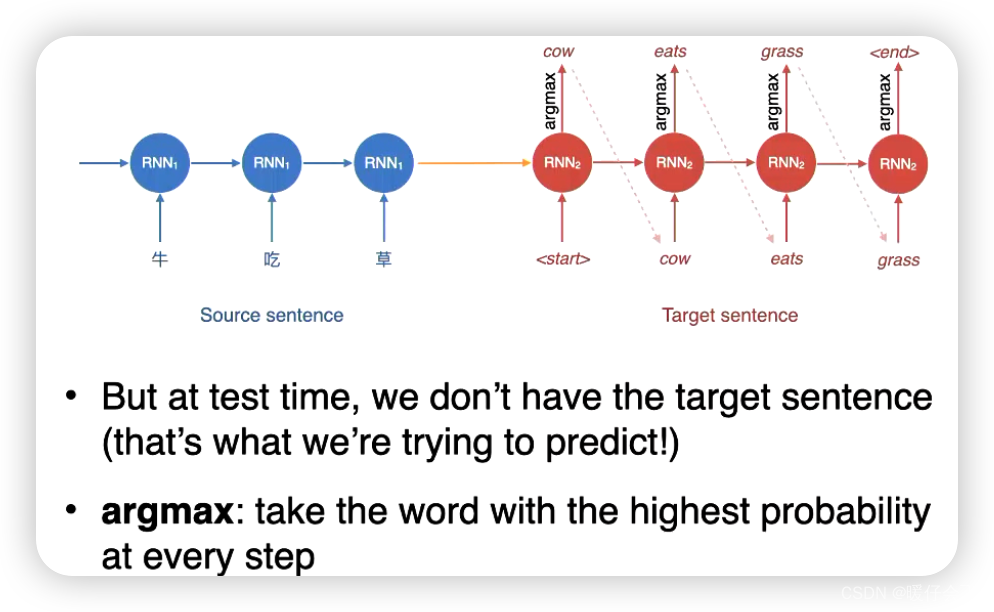
- 这种贪婪的算法会导致一个问题
exposure bias
Exposure Bias
自我评估偏差(Exposure Bias):训练过程中,神经网络模型是通过自回归方式生成目标语言句子的,即每个时间步都使用了前面生成的词作为输入。 然而,在评估阶段,模型必须依赖先前生成的词来生成后续的词,这导致了自我评估偏差。自我评估偏差会使得在训练过程中模型与评估过程中的生成结果之间存在差距,当解码器依赖于之前生成的词来生成下一个词时,模型的错误可能会逐渐累积并导致不准确的生成。 即使模型在训练阶段能够很好地利用真实目标词进行预测,但在推断阶段却不能保证同样的质量。
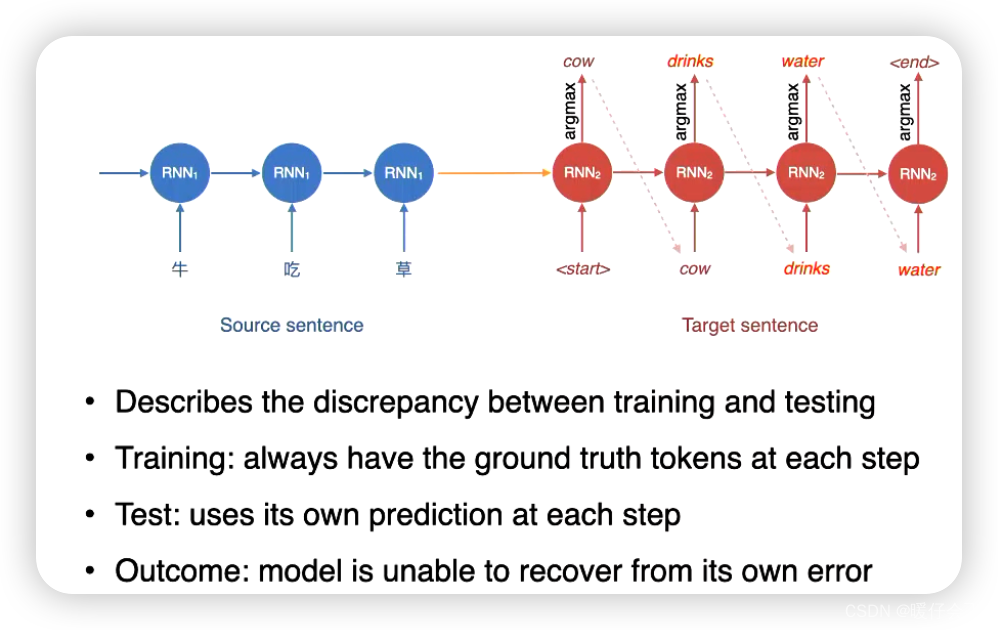
- 这个问题出现的一个重要原因在于:模型在解码的时候采用了
greedy的方式 - 要解决这个问题可以采用从全局角度更好的
decoding方法
Exhaustive Search Decoding

- 但是穷举法在实现上显然不可接受
- 假设一个句子的长度是
n,那么解码过程中需要考虑的复杂度是 O ( V n ) O(V^n) O(Vn) 其中 V V V 是词表的规模
Beam Search Decoding

在序列生成任务中,神经网络模型生成一个输出序列,例如目标语言句子。Beam Search Decoding通过在每个时间步保留前k个最有可能的候选序列,逐步扩展和搜索最优序列
- 当
k=1的时候就是贪婪算法 - 当
k=V的时候就是穷举法
下面是一个实例展示:
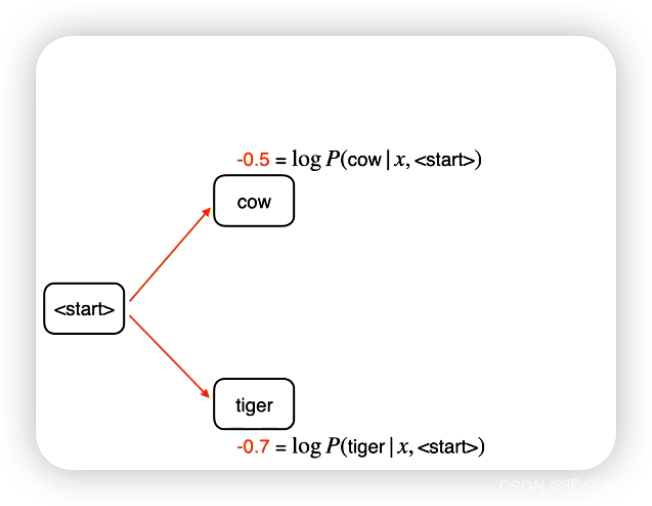
-
假设我们的模型已经完成了训练,现在是在 evaluation 的 decoding 阶段
-
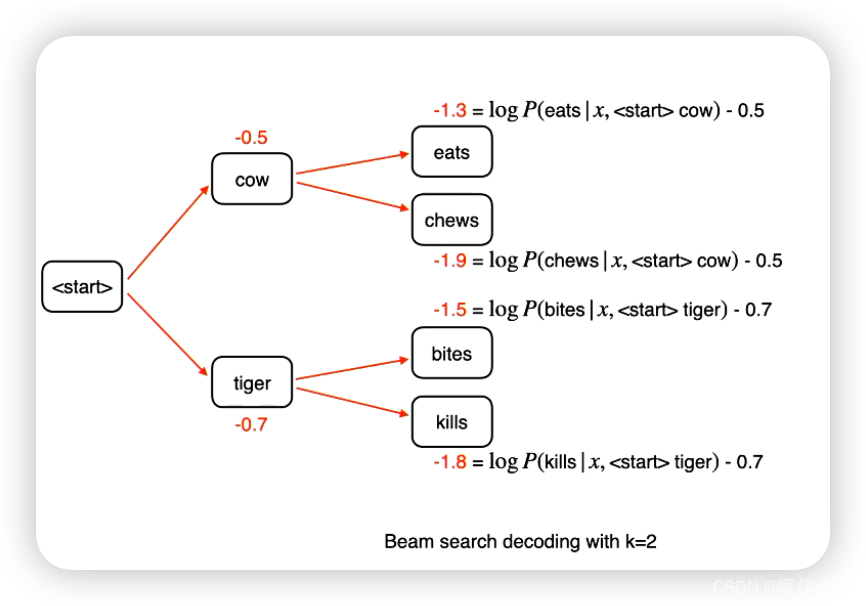
首先在第一个时间步,
cow和tiger的logits值分别如图所示 -
第二个时间步,我们会将
cow和tiger分别计算,当他们作为第一步解码结果的时候,后面的概率值
-
我们会在第二个时间步结束的时候来选择概率最高的
k条路径作为全局的最优解码结果,因为这里k=2因此我们只选择cow eats和tiger bites来进行后续的decoding任务 -
同样的过程重复:
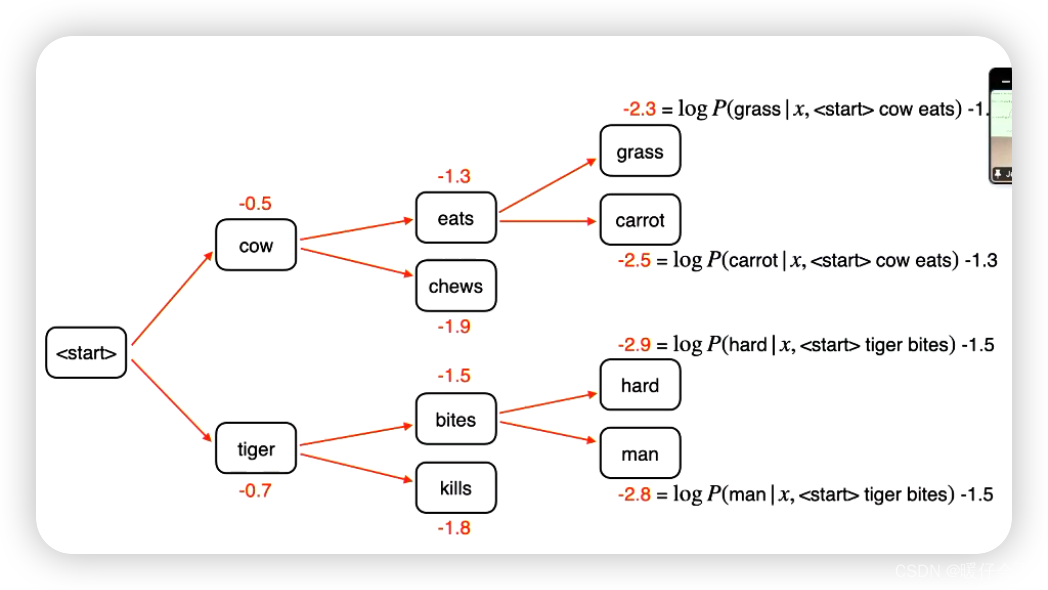
-
在第三步的时候,
cow eats grass和cow eats carrot成为两个最高的路径 -
接下来继续生成:
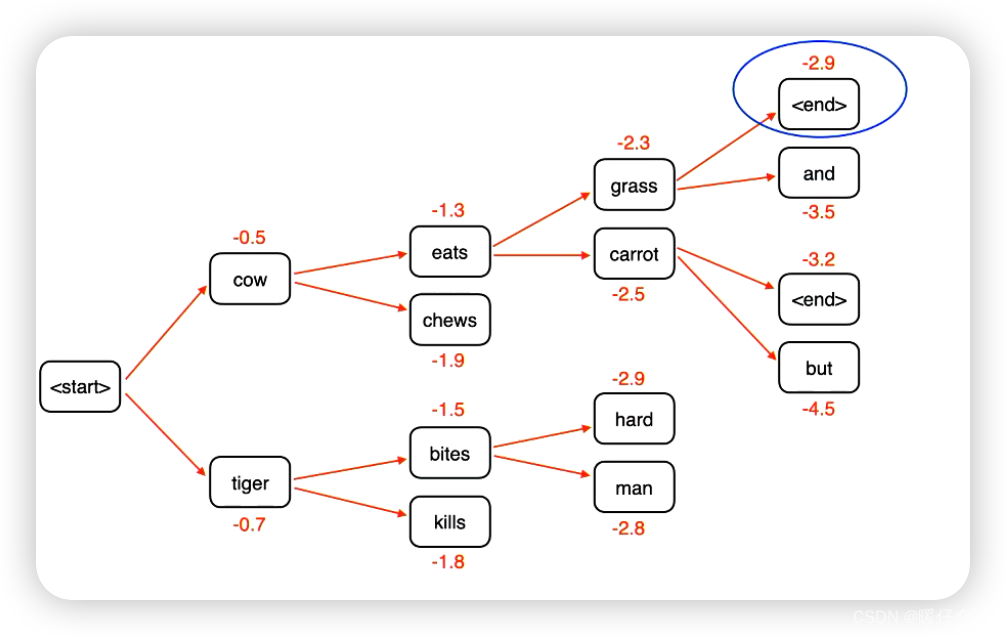
-
直到遇到了
<end>符号,生成过程结束,最终的decoding结果选最高的
什么时候解码停止
- 生成
end的时候 - 或者设置最大的生成数量

summary

Attention Mechanism
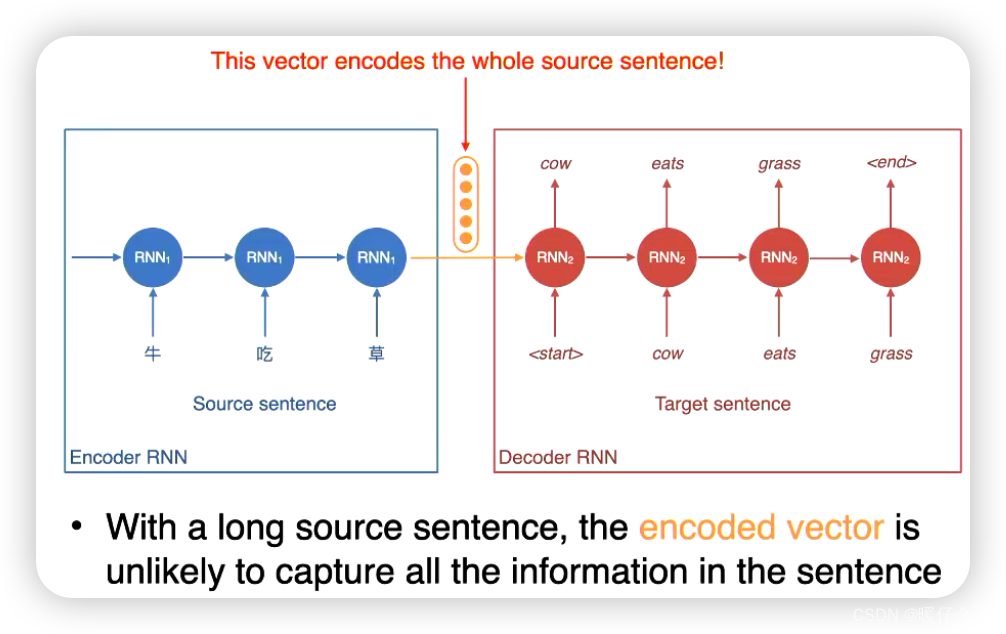
- 由于
rnn这里模型构成的encoder最终编码的这个vector的质量并不特别好(比较长距离的关系捕捉不太好) - 而编码段的质量直接影响了解码端的结果,因此我们讲这种现象称为
information bottleneck信息瓶颈 - 因此通过
attention mechanism来解决这个问题
attention

注意力机制通过动态地对编码器的隐藏状态进行加权汇总,为解码器提供更全面的上下文信息, 从而解决了这个问题。它允许解码器在生成每个目标语言词时,根据输入序列的不同部分进行自适应地关注。
以下是使用注意力机制的编码器-解码器结构的基本步骤:
-
编码器:将输入序列(源语言句子)通过编码器的循环神经网络(RNN)或Transformer 等模型进行编码,得到一系列的隐藏状态。
-
注意力计算:在解码器的每个时间步,根据解码器当前的隐藏状态和编码器的隐藏状态,计算注意力权重。这个注意力权重表示解码器对于编码器各个隐藏状态的关注程度。
-
上下文向量:使用注意力权重对编码器的隐藏状态进行加权汇总,得到一个上下文向量。该上下文向量包含了根据注意力权重对编码器隐藏状态进行加权后的综合信息。
-
解码器生成:将上下文向量与解码器当前的输入(通常是之前生成的目标语言词)一起输入解码器,生成下一个目标语言词的概率分布。
重复步骤2到步骤4,直到生成完整的目标语言序列。
通过注意力机制,解码器可以根据输入序列的不同部分进行自适应地关注,从而更好地捕捉输入序列的相关信息。注意力机制在翻译任务中的应用可以改善翻译的质量和处理长距离依赖关系的能力。
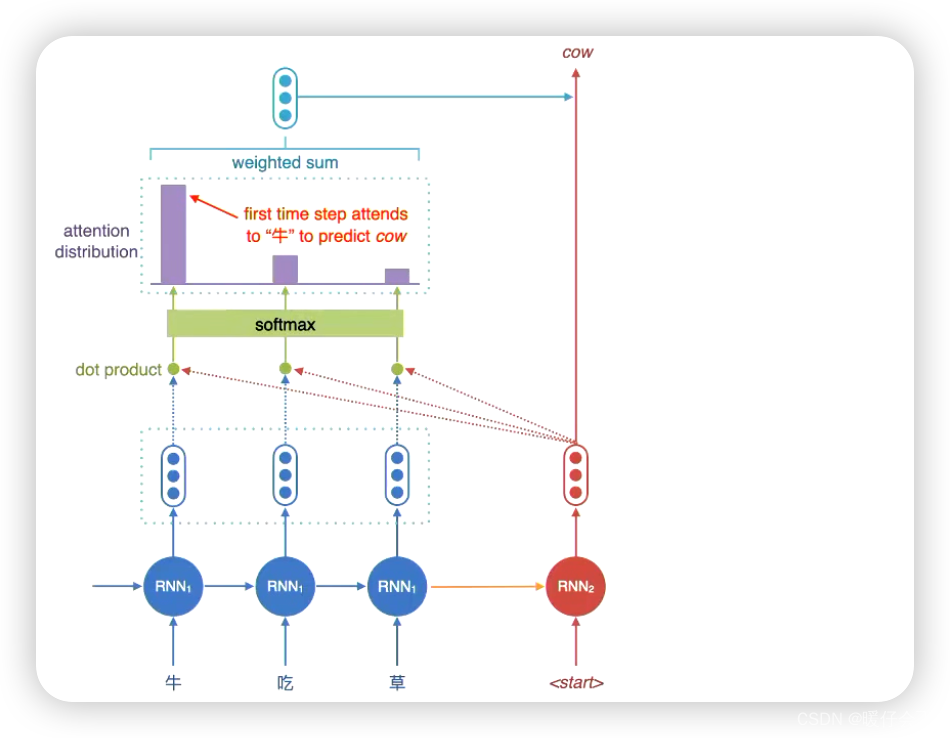
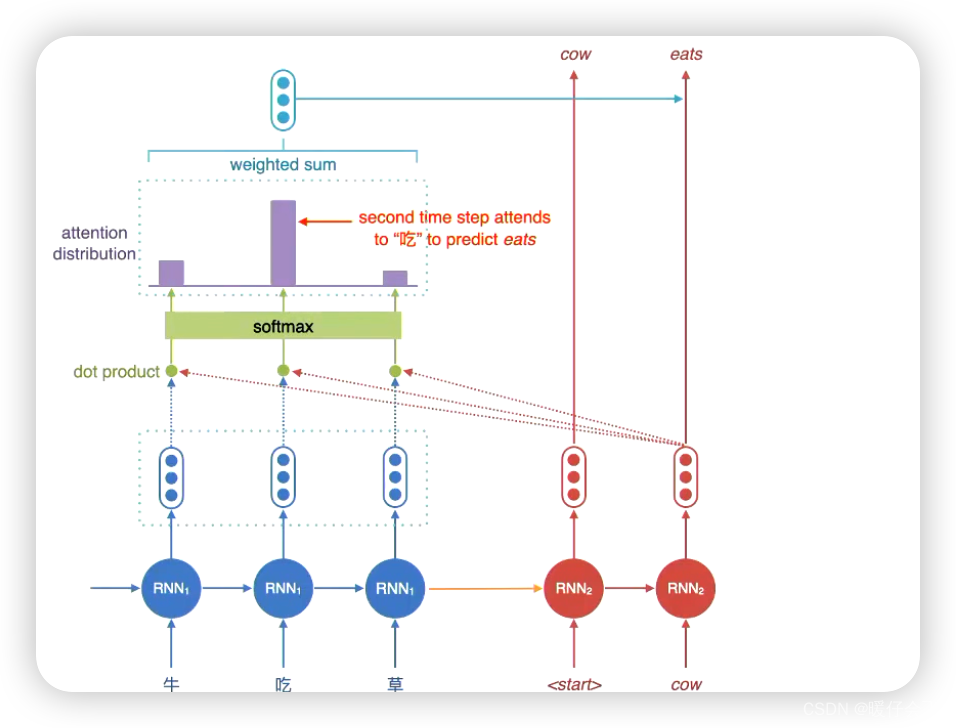
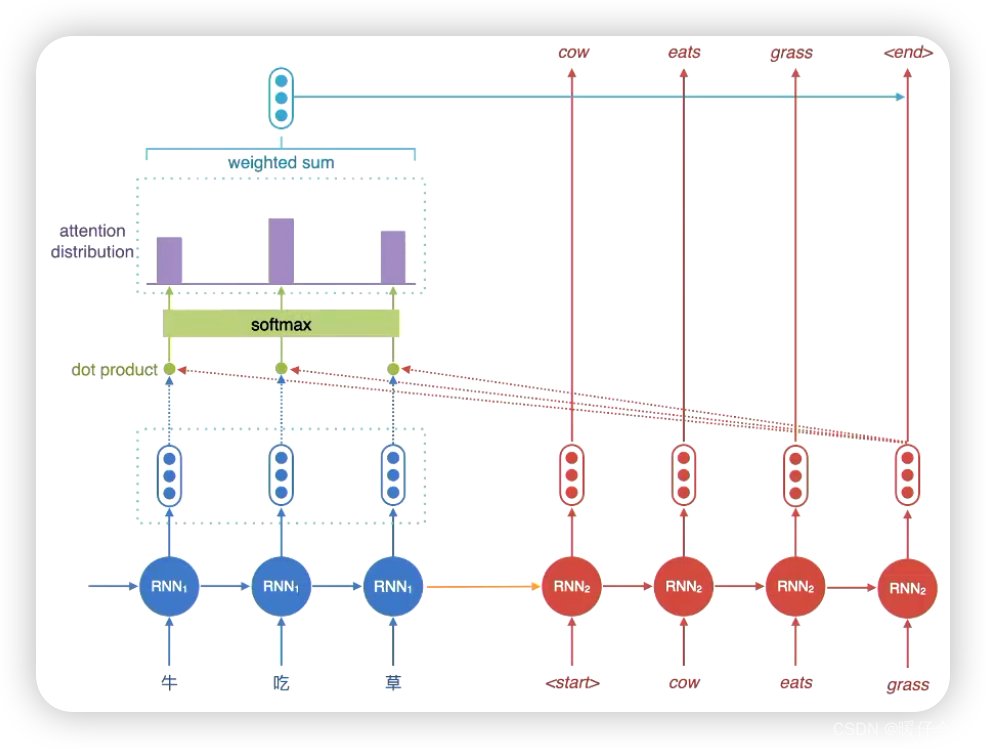
- 通过
attention进行解码的核心步骤就是,将decoding中每个时间步的hidden state和encoding端的每一个时间步的hidden state进行相似度计算并加权得到一个动态的向量用于解码(代替了最初版本的只在最后一个时间步生成一个 vector 的方式)
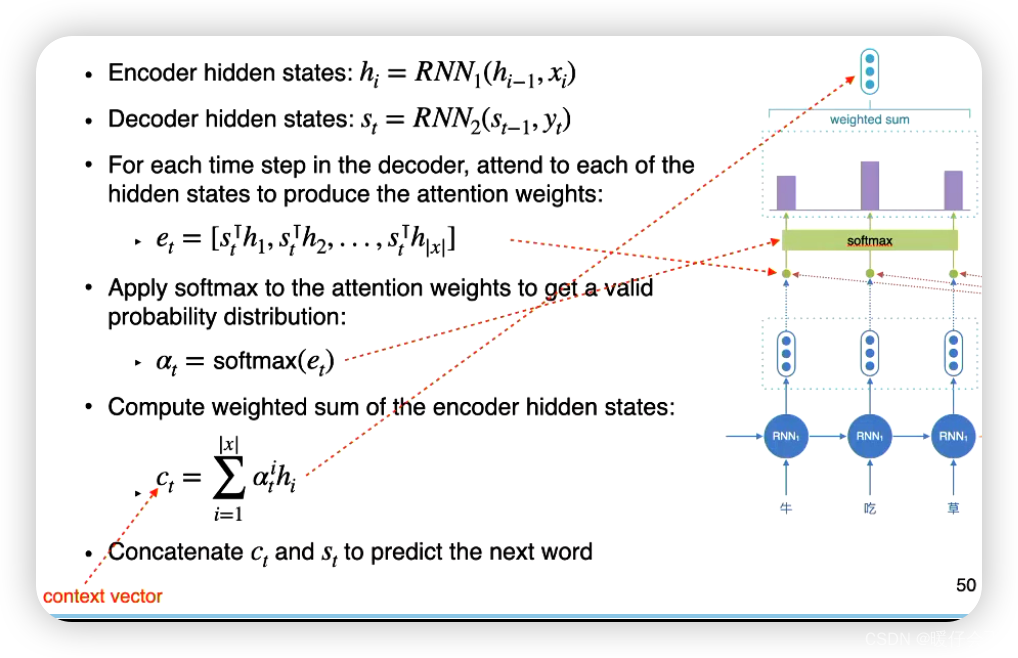
attention summary

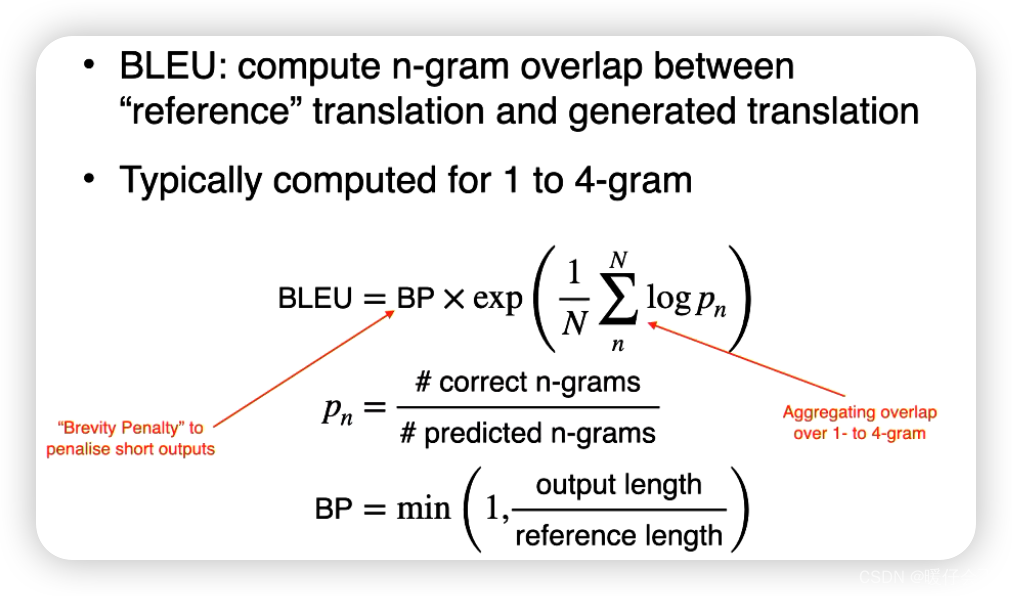
Evaluation
BLEU(Bilingual Evaluation Understudy):BLEU是一种常用的自动评估指标,用于衡量机器翻译结果与参考翻译之间的相似程度。它通过比较候选翻译与多个参考翻译之间的n-gram重叠来计算得分。