
- 1基于FPGA的OFDM基带发射机的设计与实现_ofdm fpga
- 2数据库常见面试题目及答案,软件测试面试找工作必看_测试岗位数据库面试题
- 3Workbench的服务器公网白名单:_访问公网ip地址需要在实例安全组白名单中增加 workbench的服务器白名单: 47.96.60
- 4Golang实现一个批量自动化执行树莓派指令的软件(1)文本加密&配置&命令行交互实现
- 5selenium如何切换页面标签_selenium切换标签页
- 6教会舍友玩 Git (再也不用担心他的学习)_代码没入库能继续提交吗
- 7批量下载github上的多个仓库代码_怎么用github 如何下载多个仓库 和 repo一样
- 8卡尔.波普尔摘要: 科学的方法_卡尔波普尔科学方法论
- 9LeetCode 114. 二叉树展开为链表_public static void flatten(treenode root){
- 10Mongodb中group与索引使用记录_group 索引
深入浅出聊聊如何保证数据库与缓存的一致性_生产环境保证数据库和缓存的一致性
赞
踩
前言
我们平时的业务系统在需要保证性能的链路,大部分主要用缓存来隔离数据库的流量,所以缓存和数据库的数据一致性基本都是绕不开的问题。本文主要是基于通用方案对数据和缓存一致性的问题进行延展,讨论一下它是如何发生的以及我们该如何尽量避免这个问题的出现。
常见的场景
电商秒杀业务系统中,库存的扣减
业务系统,用户进入页面,数据的读取
等等......
怎么样才算数据一致性
一般满足两点,就可以保证我们通过缓存命中的数据与数据库是一致的
-
缓存里有数据,和数据库中的数据都是最新的
-
缓存里无数据,数据库中的数据是最新的
如果不满足以上两点,几乎都可以认为是数据不一致的场景,比如:
-
缓存里有数据(旧值),数据库的值是最新的(缓存更新失败或被覆盖)
-
缓存里有数据(新值),数据库的值不是最新的(数据库更新失败)
-
缓存里有数据(新值),数据库里面没有值(数据库插入失败)
数据不一致是如何发生的?
一句话概括
数据库和缓存在双写过程的原子性无法保证
缓存的两种模式的试用场景以及优缺点
读写缓存
场景就是在请求链路里面,既有读取缓存,也有更新缓存的操作,这样在高并发同时进行读写的场景下,会有什么问题呢?
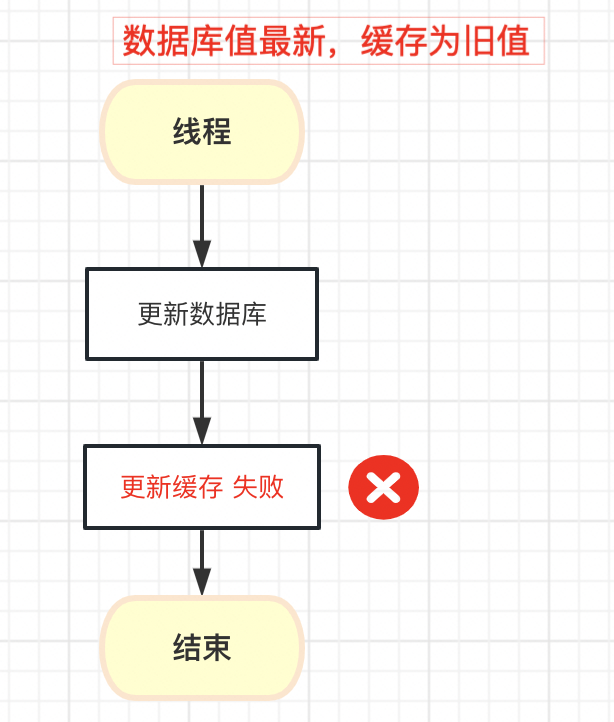
1. 更新数据库,再更新缓存
2. 先更新缓存,再更新数据库
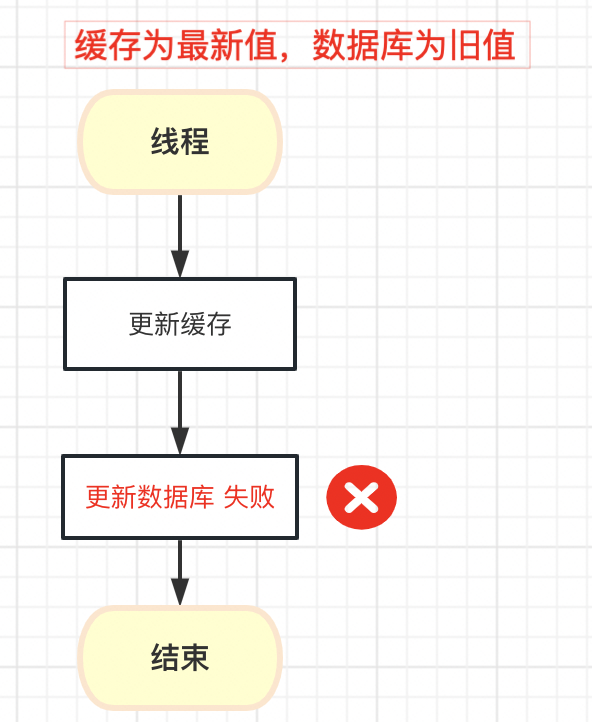
可以看到,只要更新数据库和缓存有一个失败,就必然会出现数据不一致的问题;以及更新缓存的时机也是无法保证的,所以仍然会出现数据不一致的场景。
只读缓存
场景是只会删除缓存,让其重新从数据库加载进去
1. 先更新数据库,再删除缓存

2. 先删除缓存,再删除数据库
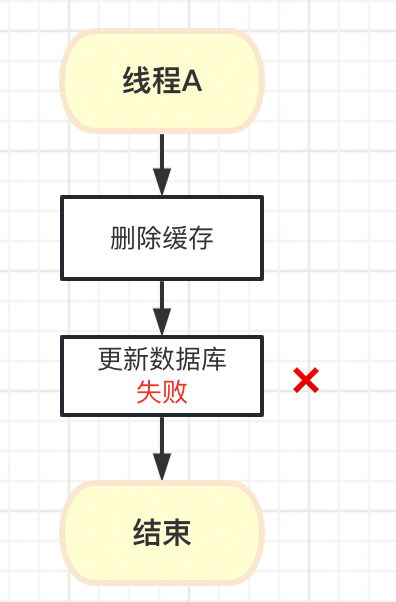
可以看出,只读缓存的问题主要在于读取的是旧值,而没有读写缓存的旧值覆盖问题
总结
| 场景 | 通用问题点 | 潜在问题 |
| 读写缓存 | 缓存和数据库,只要有一个更新失败,就会出现数据不一致。 | 无法保证顺序,容易出现旧值覆盖的问题(A请求的"旧"值把B请求的新值覆盖) |
| 只读缓存 | 先删除缓存,后更新数据库的间隙,可能会被其他请求读取到未更新的旧值 |
如何解决不一致的问题
保证原子性
核心理念:并行转串行
假设操作不存在失败,通过把多个操作包装为一个原子操作,这样就可以保证其执行会按照请求顺序依次执行,可以实现数据一致性。
使用原子命令
我们看一段扣减库存的代码,这是一个典型的库存超卖的例子,不是很清楚的同学具体可以线下再详细了解一下。
- // 获取物品库存数
- int num = redis.get(goods_id);
- // 扣减库存
- num = num - 1;
- // 设置回去
- redis.set(goods_id, num);
但其实,我们可以使用一个命令就解决这个问题,借用Redis的原子命令和单线程执行,保证了业务逻辑执行的原子性
- // 库存扣减
- redis.decr(goods_id);
使用lua脚本
道理同上,不做赘述
使用分布式锁
道理同上,不做赘述
优缺点对比
可以解决数据不一致的问题,并且保证数据强一致性,但是在高并发场景下,性能上有极大的问题,毕竟是并行改为串行。流量不大的系统,可以采用这个方案
| 方式 | 优点 | 缺点 |
| 原子命令 | 简单,单线程高性能的特性 | 只适用简单的业务场景 |
| lua脚本 | 无锁的方式来保证原子性,性能比加锁要好 |
|
| 分布式锁 | 使用灵活,适合复杂的业务场景 | 依赖分布式锁框架 |
消息队列
核心理念:重试,保证操作一定执行成功
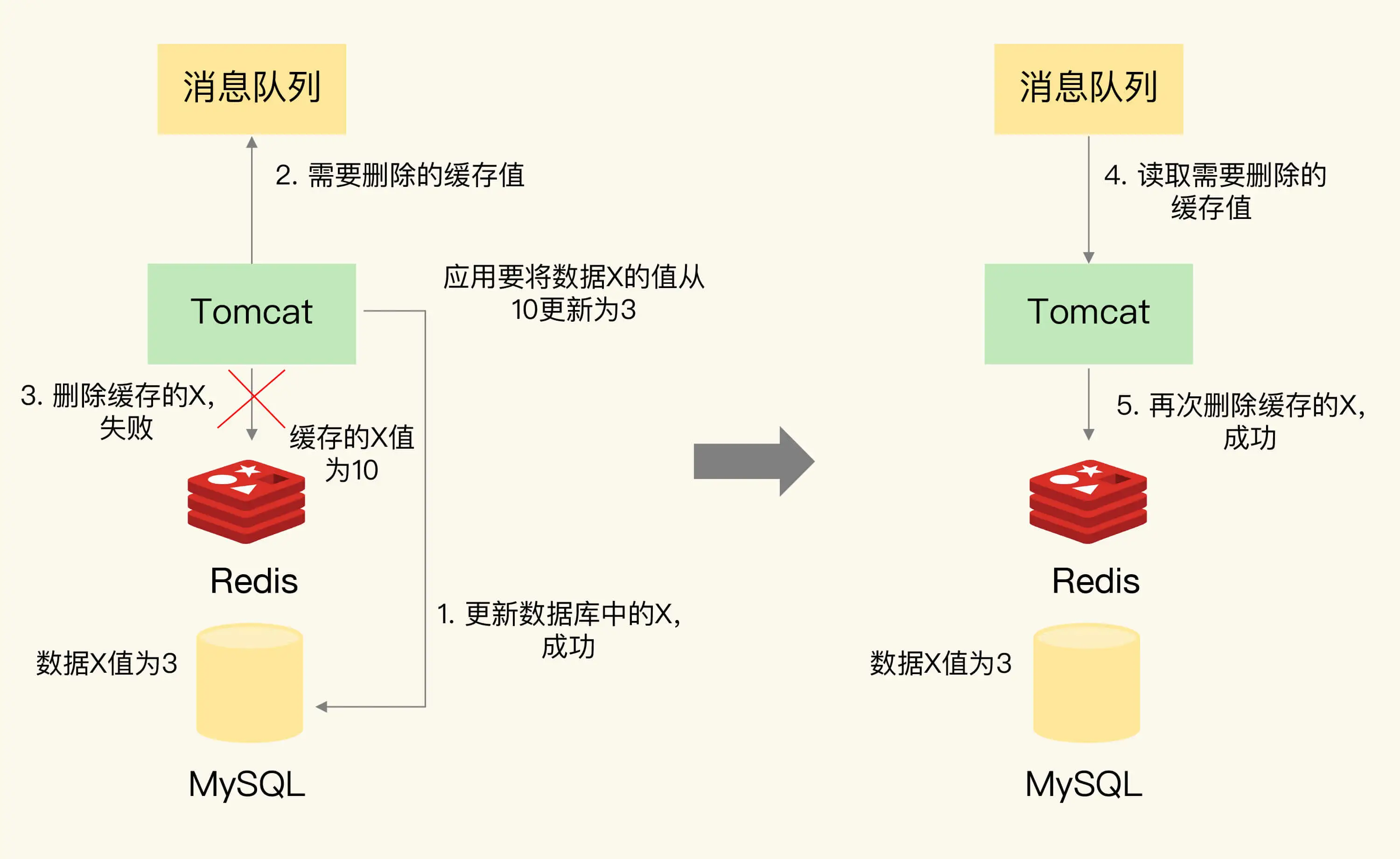
相信服务端的同学在系统里面都用过消息队列,主要是有三个特性:异步,削峰,重试。
这里我们主要采用的是重试,比如防止意外情况下 删除缓存失败导致的问题,直到重试成功,保证数据的最终一致性。
优缺点对比
可以保证缓存和数据库同时执行成功,但是使用队列,还是无法保证强一致性,只能实现最终一致性。
| 方式 | 优点 | 缺点 |
| 消息队列 | 保证业务操作失败后可以重试,直到成功。保证最终一致性 | 无法实现强一致性 |
延时双删
核心理念:更新数据库后,缓存失效,重新读取
主要体现在"先删除缓存,再更新数据库"的场景
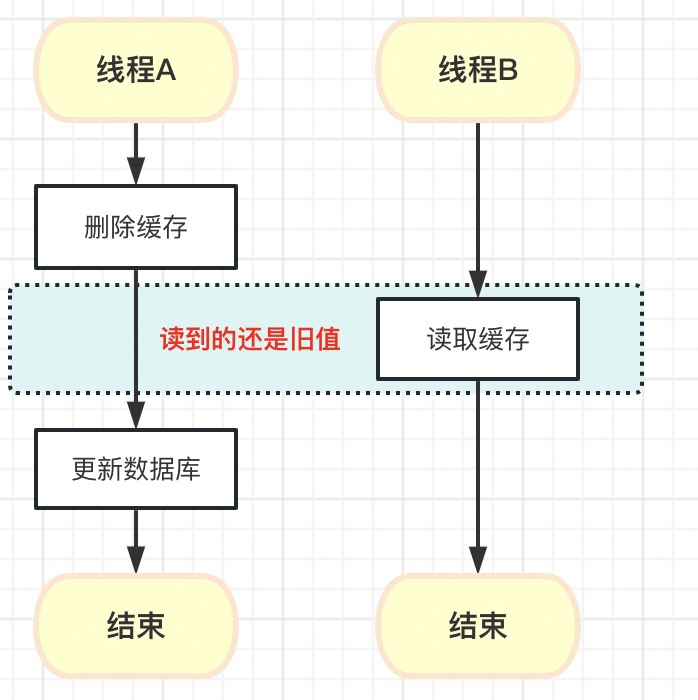
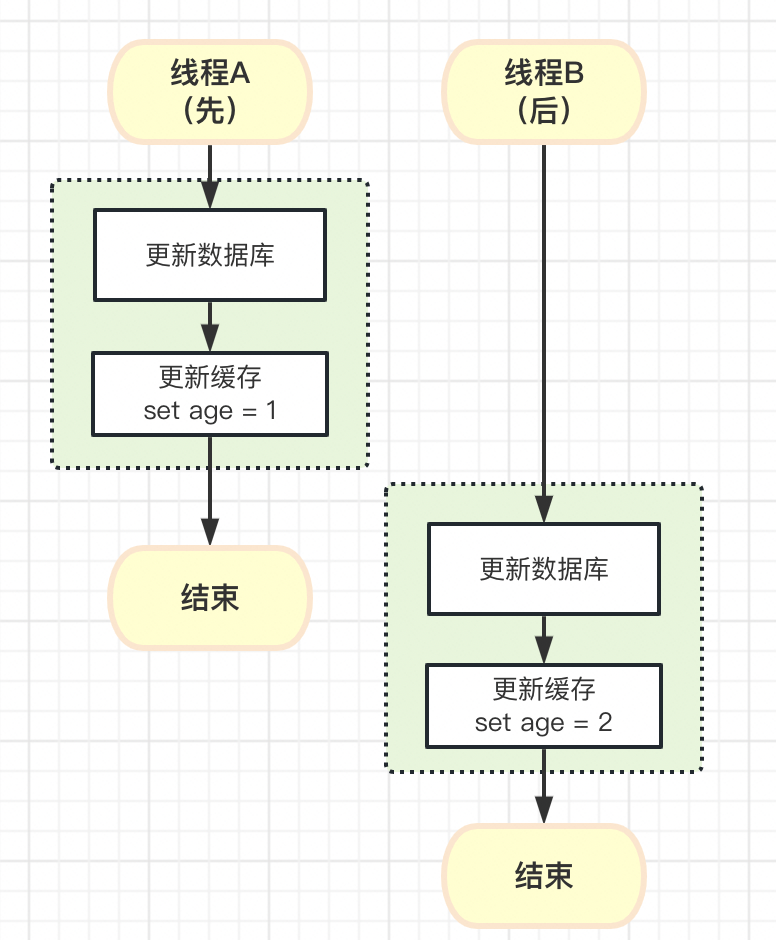
线程A删除完缓存后,线程B发现缓存没有命中,查询数据库并设置到缓存中,最后线程A才把数据库更新。导致了数据更新后缓存的还是旧值。
那么是不是更新数据库后再把缓存删掉就可以了呢?
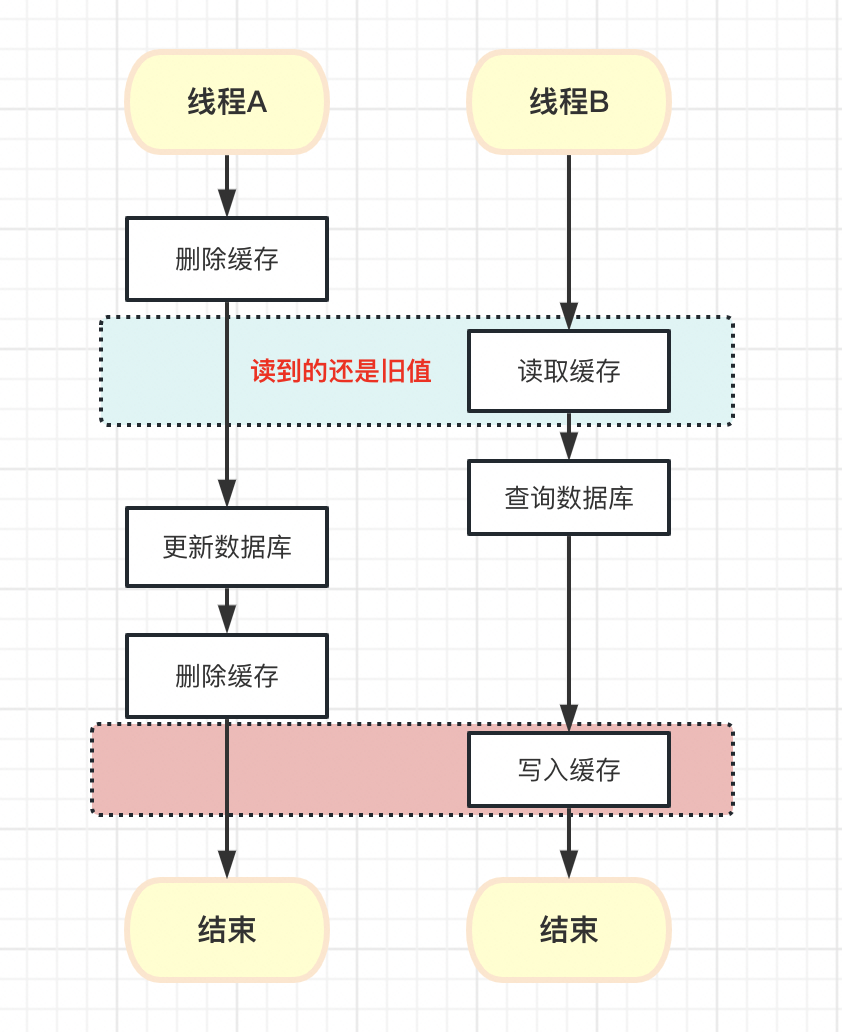
根据下图我们可以发现,我们仍然无法控制不同线程 删除缓存和写入缓存的执行顺序。
除非……我们在更新数据库后,等待一段时间,等线程B写入缓存操作执行后,再删除缓存
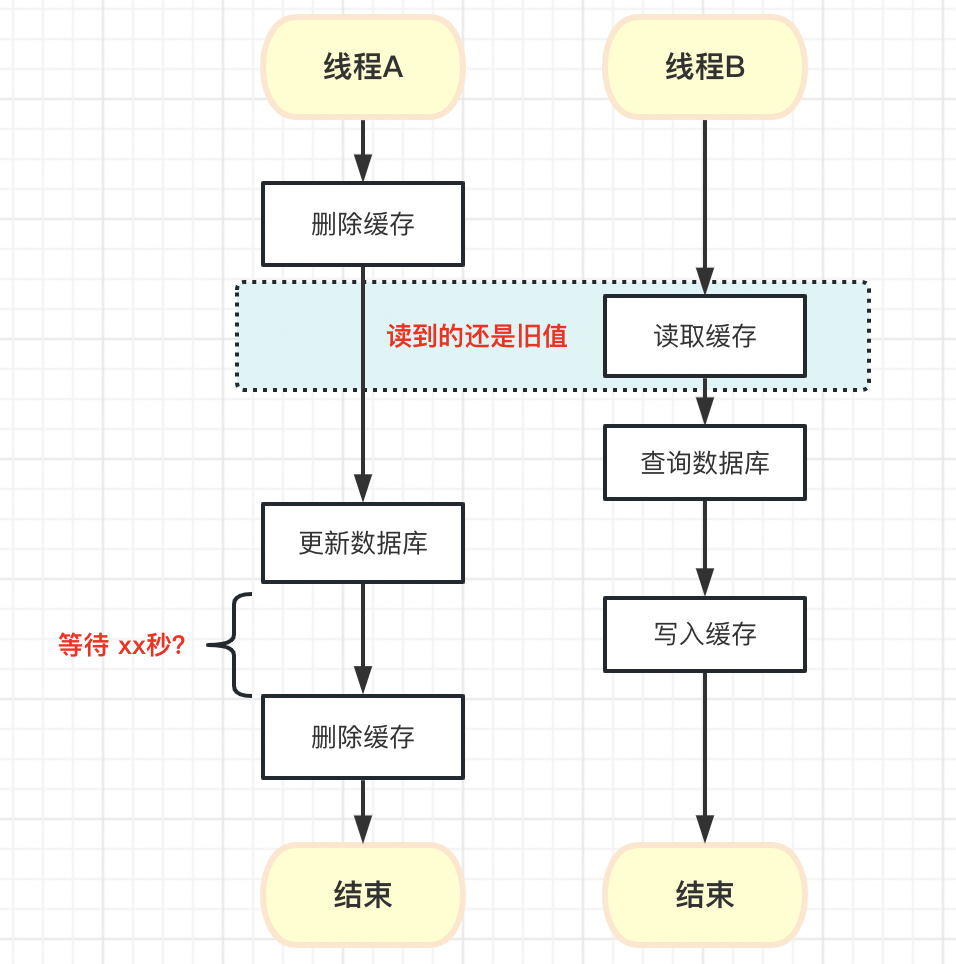
看似可以解决数据不一致的问题,但是还是有很多问题,比如延时时间如何精准判定?所以这个方法还是不推荐
优缺点对比
| 场景 | 优点 | 缺点 | 能否解决问题 |
| 先更新数据库,再删除缓存 | 逻辑简单,适合业务流量不大的场景 | 会出现短暂的数据不一致 | 可以解决 |
| 延时双删(先删缓存,再数据库,再删缓存) | - |
| 无法解决 |
监听binlog,异步更新
核心理念:更新数据库后,重新设置缓存,防止大流量下的缓存击穿
这是基于"延时双删",延展出来的方案,以"更新数据库"动作为信号,来通知缓存服务进行更新
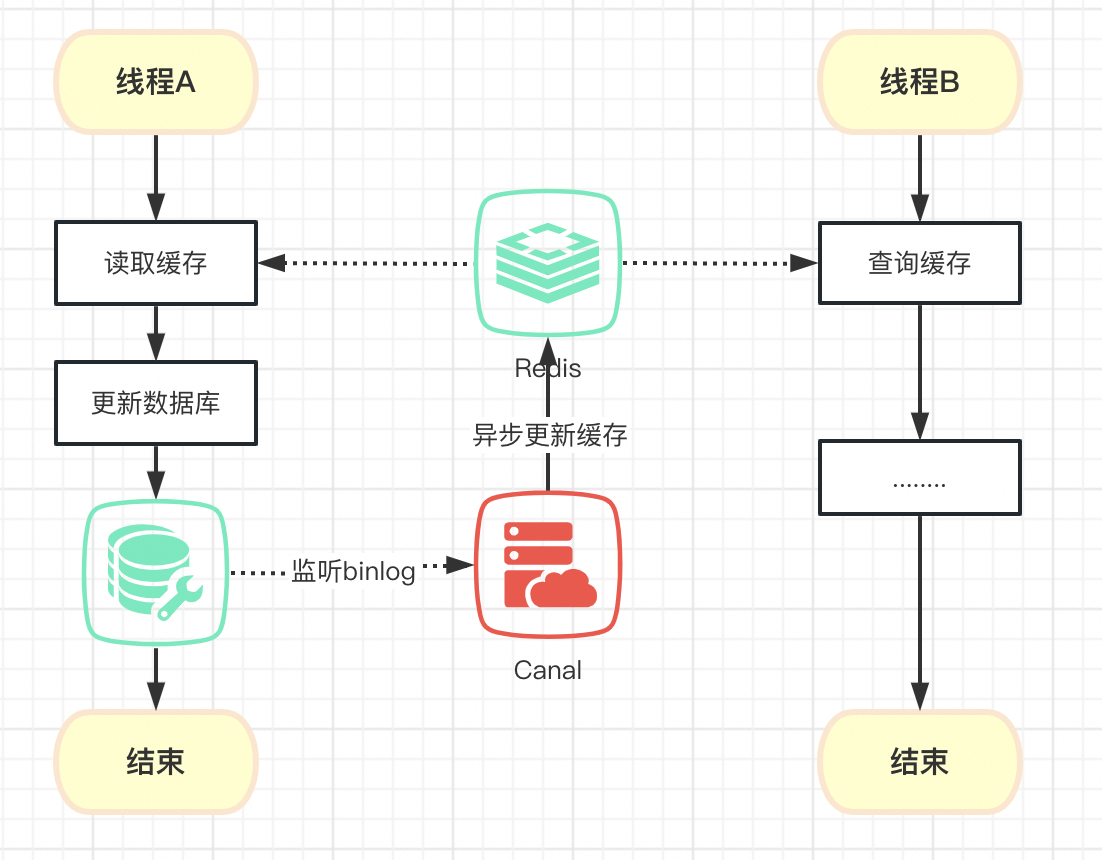
优缺点对比
| 场景 | 优点 | 缺点 |
| 监听binlog |
|
|
总结
经过了这么多方案的讲解,我针对数据一致性这个问题,大概总结几个要点:
-
设计上要会"取舍"。保证强一致性,要牺牲 性能;保证性能,只能保证最终一致性
-
"延时双删"不能从根本上解决数据一致性的问题,使用要慎重
-
要考虑缓存穿透、缓存击穿、缓存雪崩这些常见的业务场景,尤其是删除!
笔者根据目前的经验总结出的解决数据一致性的一些常用方案,如果你发现文中有BUG的地方或者更好的建议,欢迎留言或私聊一起讨论~

