
- 1实时绘画迎来大更新,本地即可部署_krita-ai-diffusion
- 2GitHub上传代码显示LF will be replaced by CRLF the next time Git touches it_githublf will be replaced by crlf the next time gi
- 3RabbitMQ2/4---集群和高可用方案_4节点 rabbitmq
- 4论文查重相似度多高算是重复 神码ai_论文aigc总体疑似度多少正常
- 5java 初中级笔试题_Java面试宝典_中级软件工程师笔试题(一)
- 6物联网实战--入门篇之(九)安卓QT--开发框架
- 7行测题相关,在线测评(图形找规律。逻辑思维)_在线测评图像规律题
- 8flink on yarn集群部署模式_flink on yarn模式启动flink集群
- 9【大数据】Flink 详解(五):核心篇 Ⅳ(反压、序列化、内存模型)
- 10git回退版本_git超前,如何回到远程最新版本
AI项目十九:YOLOV8实现目标追踪_yolov8目标追踪
赞
踩
若该文为原创文章,转载请注明原文出处。
主要是学习一下实现目标追踪的原理,并测试一下效果。
目的是通过YOLOV8实现人员检测,并实现人员追踪,没个人员给分配一个ID,实现追踪的效果。
也可以统计人数。在小区办公楼的出入场所,这类很常见。
一、简介
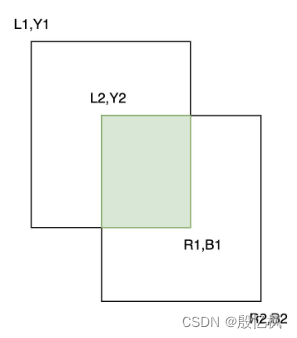
追踪任务是指识别和跟踪特定目标在视频序列中的运动和位置,一般用唯一ID或固定颜色检测框表示),如下图:

目标检测和目标跟踪的区别:
目标检测:目标检测任务要求同时完成对象的定位(即确定对象的边界框位置)和分类(即确定对象的类别)。这意味着目标检测算法必须不仅能够确定对象是否存在,还要知道它是什么。
目标检测通常用于识别和定位图像或视频帧中的对象,通常需要明确的目标类别信息。
目标跟踪:目标跟踪任务更关注对象在帧与帧之间的连续性,通常更注重对象的运动特征,而不要求进行目标的分类。
目标跟踪可以不涉及目标的类别,它的主要目标是维护对象的位置和轨迹,以实现在视频序列中的跟踪。
这里就有个问题,视频中不同时刻的同一个人,位置发生了变化,那么是如何关联上的呢?答案就是匈牙利算法和卡尔曼滤波。
- 匈牙利算法可以告诉我们当前帧的某个目标,是否与前一帧的某个目标相同。
- 卡尔曼滤波可以基于目标前一时刻的位置,来预测当前时刻的位置,并且可以比传感器(在目标跟踪中即目标检测器,比如Yolo等)更准确的估计目标的位置。
最经典的是DeepSORT,本篇记录的是如何使用IOU,所以了解下DeepSORT。
DeepSORT对每一帧的处理流程如下:
检测器得到bbox → 生成detections → 卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新
Frame 0:检测器检测到了3个detections,当前没有任何tracks,将这3个detections初始化为tracks
Frame 1:检测器又检测到了3个detections,对于Frame 0中的tracks,先进行预测得到新的tracks,然后使用匈牙利算法将新的tracks与detections进行匹配,得到(track, detection)匹配对,最后用每对中的detection更新对应的track
二、方法介绍
目前主流的目标跟踪算法都是基于Tracking-by-Detecton策略,即基于目标检测的结果来进行目标跟踪。
实现目标跟踪的方法:
1、IOU
比较前后两帧检测框IOU是否大于指定阈值,是则是同一个物体,不是则分配新ID,此方法对于运动慢的可以,效果差。
2、卡尔曼滤波
卡尔曼滤波是一种用于估计系统状态的优秀算法。它结合了传感器测量和系统模型,通过递归地计算加权平均值,实时更新状态估计。卡尔曼滤波在众多领域,如导航、机器人技术和信号处理中广泛应用,以提高系统的准确性和鲁棒性。
可以用的库:GitHub - adipandas/multi-object-tracker: Multi-object trackers in Python
3、botsort&bytetrack
BoT-SORT是今年非常游戏的跟踪器模型。就所有主要 MOT 指标MOTA、IDF1 和 HOTA而言,BoT-SORT 和 BoT-SORT-ReID 在 MOT17 和 MOT20 测试集的 MOTChallenge数据集中排名第一。对于 MOT17:实现了 80.5 MOTA、80.2 IDF1 和 65.0 HOTA,在跟踪器的排行榜上暂居第一。
论文翻译:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/126890651
论文链接:https://arxiv.org/pdf/2206.14651.pdf
代码:https://github.com/NirAharon/BOT-SORT
ByteTrack是基于tracking-by-detection范式的跟踪方法。大多数多目标跟踪方法通过关联分数高于阈值的检测框来获取目标ID。对于检测分数较低的目标,例如遮挡目标,会被简单的丢弃,这带来了不可忽略的问题,包括大量的漏检和碎片化轨迹。为了解决该问题,作者提出了一种简单、高效且通用的数据关联方法BYTE,通过关联每个检测框而不仅仅是高分检测框来进行跟踪。对于低分检测框,利用它们与轨迹的相似性来恢复真实目标并过滤掉背景检测。
BoT-SORT:https://github.com/NirAharon/BoT-SORT
ByteTrack :https://github.com/ifzhang/ByteTrack
三、IOU实现目标追踪
1、环境安装
本人的电脑使用的是CPU(无GPU)版本,所以直接安装,GPU需要安装CUDA等,自行安装。
- # 使用Conda为本项目单独创建一个虚拟环境(python 3.8版本)
- conda create -n yolov8_env python=3.8
- # 激活进入环境
- conda activate yolov8_env
-
- # YOLOv8安装方式
- pip install ultralytics
2、验证
- # 图片cli验证
- yolo predict model=yolov8n.pt source=./bus.jpg
-
- # 视频cli验证
- yolo predict model=yolov8n.pt source=./test.mp4
3、使用python验证
使用python语言验证主要是熟悉YOLOV8的API,知道如何调用,并测试。
- from ultralytics import YOLO
- import cv2
- import numpy as np
- import time
-
- # 加载模型
- model = YOLO("./yolov8n.pt") # load a pretrained model (recommended for training)
- objs_labels = model.names # get class labels
- print(objs_labels)
-
-
- # 打开摄像头
- cap = cv2.VideoCapture(0)
-
- while True:
- # 读取一帧
- start_time = time.time()
- ret, frame = cap.read()
- if ret:
- # 检测
- result = list(model(frame, stream=True))[0] # inference,如果stream=False,返回的是一个列表,如果stream=True,返回的是一个生成器
-
- boxes = result.boxes # Boxes object for bbox outputs
- boxes = boxes.cpu().numpy() # convert to numpy array
-
- # 遍历每个框
- for box in boxes.data:
- l,t,r,b = box[:4].astype(np.int32) # left, top, right, bottom
- conf, id = box[4:] # confidence, class
- # 绘制框
- cv2.rectangle(frame, (l,t), (r,b), (0,0,255), 2)
- # 绘制类别+置信度(格式:98.1%)
- cv2.putText(frame, f"{objs_labels[id]} {conf*100:.1f}%", (l, t-10), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
-
- end_time = time.time()
- fps = 1 / (end_time - start_time)
- # 绘制FPS
- cv2.putText(frame, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
-
- # 显示
- cv2.imshow("frame", frame)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
- else:
- break

在终端里执行python demo.py

4、IOU实现追踪
- '''
- iou追踪示例
- '''
- from ultralytics import YOLO
- import cv2
- import numpy as np
- import time
- import random
- import os
- from shapely.geometry import Polygon, LineString
- import json
-
- class IouTracker:
- def __init__(self):
-
- # 加载检测模型
- self.detection_model = YOLO("./yolov8n.pt")
- # 获取类别
- self.objs_labels = self.detection_model.names
- # 打印类别
- print(self.objs_labels)
- # 只处理person
- self.track_classes = {0: 'person'}
-
- # 追踪的IOU阈值
- self.sigma_iou = 0.5
- # detection threshold
- self.conf_thresh = 0.3
-
- def iou(sel,bbox1, bbox2):
- """
- 计算两个bounding box的IOU
- """
-
- (x0_1, y0_1, x1_1, y1_1) = bbox1
- (x0_2, y0_2, x1_2, y1_2) = bbox2
-
- # 计算重叠的矩形的坐标
- overlap_x0 = max(x0_1, x0_2)
- overlap_y0 = max(y0_1, y0_2)
- overlap_x1 = min(x1_1, x1_2)
- overlap_y1 = min(y1_1, y1_2)
-
- # 检查是否有重叠
- if overlap_x1 - overlap_x0 <= 0 or overlap_y1 - overlap_y0 <= 0:
- return 0
-
- # 计算重叠矩形的面积以及两个矩形的面积
- size_1 = (x1_1 - x0_1) * (y1_1 - y0_1)
- size_2 = (x1_2 - x0_2) * (y1_2 - y0_2)
- size_intersection = (overlap_x1 - overlap_x0) * (overlap_y1 - overlap_y0)
- size_union = size_1 + size_2 - size_intersection
- # 计算IOU
- return size_intersection / size_union
-
-
- def predict(self, frame):
- '''
- 检测
- '''
- result = list(self.detection_model(frame, stream=True, conf=self.conf_thresh))[0] # inference,如果stream=False,返回的是一个列表,如果stream=True,返回的是一个生成器
- boxes = result.boxes # Boxes object for bbox outputs
- boxes = boxes.cpu().numpy() # convert to numpy array
-
- dets = [] # 检测结果
- # 遍历每个框
- for box in boxes.data:
- l,t,r,b = box[:4] # left, top, right, bottom
- conf, class_id = box[4:] # confidence, class
- # 排除不需要追踪的类别
- if class_id not in self.track_classes:
- continue
- dets.append({'bbox': [l,t,r,b], 'score': conf, 'class_id': class_id })
- return dets
-
-
- def main(self):
- '''
- 主函数
- '''
- # 读取视频
- cap = cv2.VideoCapture("./media/video.mp4")
-
- # 获取视频帧率、宽、高
- fps = cap.get(cv2.CAP_PROP_FPS)
- width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- print(f"fps: {fps}, width: {width}, height: {height}")
-
-
- tracks_active = [] # 活跃的跟踪器
- frame_id = 1 # 帧ID
- track_idx = 1 # 跟踪器ID
-
- # writer
- out = cv2.VideoWriter("./test_out.mp4", cv2.VideoWriter_fourcc(*'mp4v'), fps, (1280, 720))
-
- while True:
- # 读取一帧
- start_time = time.time()
- ret, raw_frame = cap.read()
- if ret:
- # 检测
- frame = cv2.resize(raw_frame, (1280, 720))
- raw_frame = frame
- dets = self.predict(raw_frame)
- # 更新后的跟踪器
- updated_tracks = []
- # 遍历活跃的跟踪器
- for track in tracks_active:
- if len(dets) > 0:
- # 根据最大IOU更新跟踪器,先去explain.ipynb中看一下MAX用法
- best_match = max(dets, key=lambda x: self.iou(track['bboxes'][-1], x['bbox'])) # 找出dets中与当前跟踪器(track['bboxes'][-1])最匹配的检测框(IOU最大)
- # 如果最大IOU大于阈值,则将本次检测结果加入跟踪器
- if self.iou(track['bboxes'][-1], best_match['bbox']) > self.sigma_iou:
- # 将本次检测结果加入跟踪器
- track['bboxes'].append(best_match['bbox'])
- track['max_score'] = max(track['max_score'], best_match['score'])
- track['frame_ids'].append(frame_id)
- # 更新跟踪器
- updated_tracks.append(track)
- # 删除已经匹配的检测框,避免后续重复匹配以及新建跟踪器
- del dets[dets.index(best_match)]
-
-
- # 如有未分配的目标,创建新的跟踪器
- new_tracks = []
- for det in dets: # 未分配的目标,已经分配的目标已经从dets中删除
- new_track = {
- 'bboxes': [det['bbox']], # 跟踪目标的矩形框
- 'max_score': det['score'], # 跟踪目标的最大score
- 'start_frame': frame_id, # 目标出现的 帧id
- 'frame_ids': [frame_id], # 目标出现的所有帧id
- 'track_id': track_idx, # 跟踪标号
- 'class_id': det['class_id'], # 类别
- 'is_counted': False # 是否已经计数
- }
- track_idx += 1
- new_tracks.append(new_track)
- # 最终的跟踪器
- tracks_active = updated_tracks + new_tracks
-
- cross_line_color = (0,255,0) # 越界线的颜色
-
- # 绘制跟踪器
- for tracker in tracks_active:
- # 绘制跟踪器的矩形框
- l,t,r,b = tracker['bboxes'][-1]
- # 取整
- l,t,r,b = int(l), int(t), int(r), int(b)
- class_id = tracker['class_id']
- cv2.rectangle(raw_frame, (l,t), (r,b), cross_line_color, 2)
- # 绘制跟踪器的track_id + class_name + score(99.2%格式)
- cv2.putText(raw_frame, f"{tracker['track_id']}", (l, t-10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0,255,0), 2)
-
- # 设置半透明
- color = (0,0,0)
- alpha = 0.2
- l,t = 0,0
- r,b = l+240,t+40
- raw_frame[t:b,l:r,0] = raw_frame[t:b,l:r,0] * alpha + color[0] * (1-alpha)
- raw_frame[t:b,l:r,1] = raw_frame[t:b,l:r,1] * alpha + color[1] * (1-alpha)
- raw_frame[t:b,l:r,2] = raw_frame[t:b,l:r,2] * alpha + color[2] * (1-alpha)
-
- # end time
- end_time = time.time()
- # FPS
- fps = 1 / (end_time - start_time)
- # 绘制FPS
- cv2.putText(raw_frame, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
-
-
-
- # 显示
- cv2.imshow("frame", raw_frame)
- if cv2.waitKey(1) & 0xFF == ord('q'):
- break
-
- out.write(raw_frame)
- else:
- break
-
- out.release()
-
- # 实例化
- iou_tracker = IouTracker()
- # 运行
- iou_tracker.main()
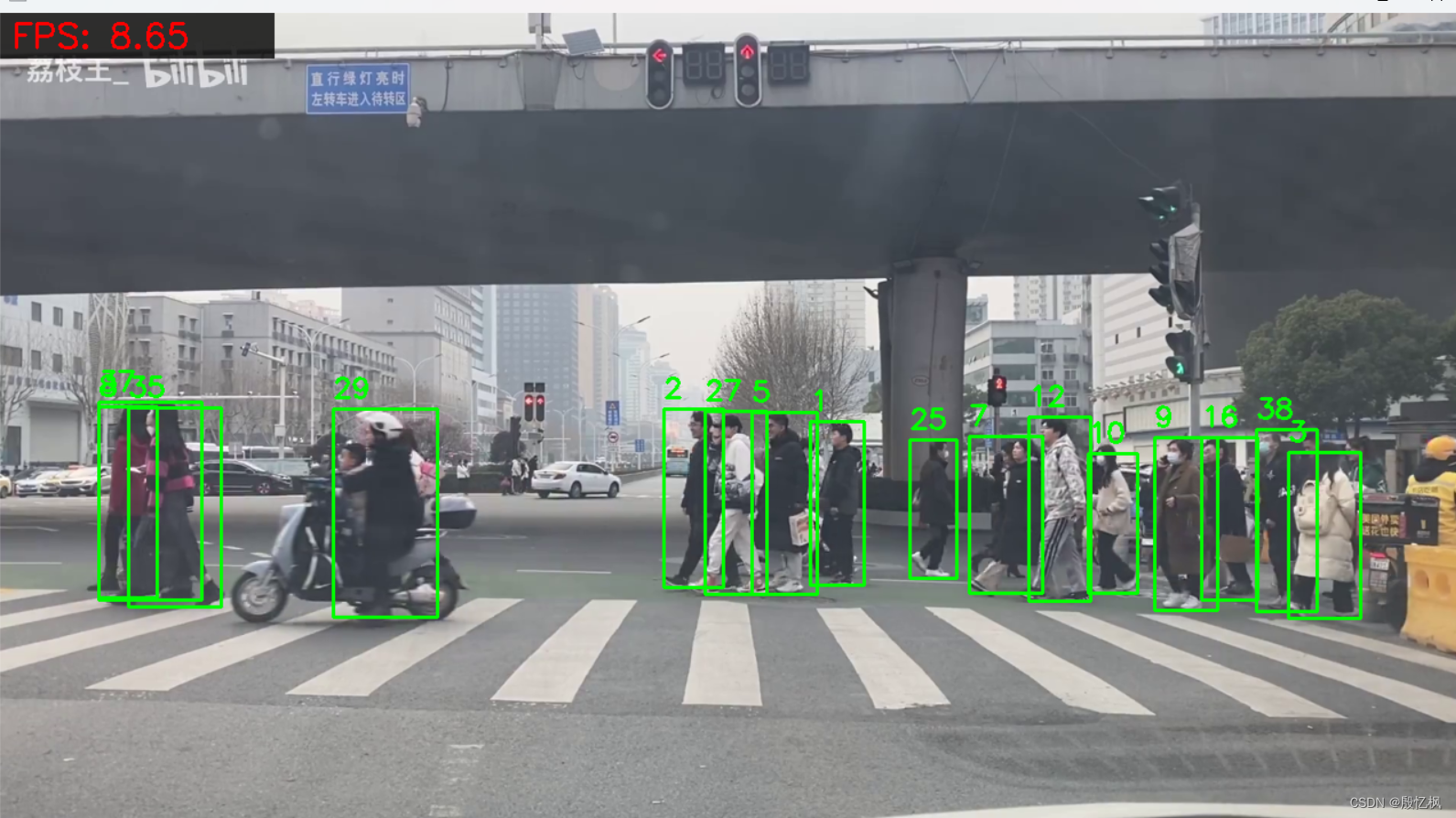
测试效果,视频是马路上的,如果想要效果好,建议自己训练模型,使用的是yolov8n.pt模型
如有侵权,或需要完整代码,请及时联系博主。

