
- 1MySQL索引的分类及性能分析及问题排查_mysql 索引类型以及效率
- 2STM32CubeMX使用说明_stm32cubemx汉化
- 3Flask配置远程访问_flask 远程访问
- 4Flex debug : Flash player not found_fr_flash:not found
- 5前端与区块链的结合实践:构建去中心化应用_前段区块链
- 6门控循环单元(GRU)_gru门控循环单元
- 7解决elasticsearch报错:FORBIDDEN/12/index read-only / allow delete (api)_es index [ots] blocked by: [forbidden/12/index rea
- 8【转】大数据开发之Spark面试八股文_大数据开发八股文
- 9git强制覆盖本地代码(与git远程仓库保持一致:git reset --hard origin/master)_git用本地覆盖远程
- 10Mac电脑,python+appium+安卓模拟器使用步骤_appium mac
运维工程师岗位-面试问答_运维工程师面试官都问啥
赞
踩
一、前言
最近参加运维工程师岗位的面试,笔者把自己遇到的和网友分享的一些常见的面试问答收集整理出来了,希望能对自己和对正在准备面试的同学提供一些参考。
二、面试问答
1、介绍下自己?(几乎每家公司首先都会让你做个自我介绍,好像是必修课一样)
笔者回答:此处省略笔者的自我介绍,笔者建议介绍自己的时间不宜过长,3-4分钟为宜,说多了面试官会觉得你太啰嗦了。说太少了也不行,那样会让人感觉你的经历太简单了、太空了。正常情况下,一般你在做自我介绍的同时,面试官这个时候在看你的简历,他需要一边看简历、一边听你介绍自己,如果你说个几句话就把自己介绍完了,他肯定还没缓过神来,对你的映像会减分的。在介绍的同时思维要清晰,逻辑要清楚,最好是根据你简历上写的经历来介绍,这样可以把面试官的思路带到你这里来,让他思路跟着你走。不要东扯一句,西扯一句。竟量少介绍自己的性格、爱好(最好能不说就不说),你可以简单罗列干过几家公司(最多罗列3家公司/也包含目前所在的公司,注意顺序不要乱),都在那几家公司负责什么工作,都用过什么技术,在着重介绍一下你目前所在的公司是负责哪些工作的,可以稍微详细一点介绍,不要让面试官听着晕头转向的感觉。
2、灰度发布如何实现?
笔者回答:其实对这个问题笔者也答的不好,就不写出来误导大家了。大家有好的方法可以共享出来。不过笔事后在知呼上看到了一位网友的建议觉得不错,大家可以参考看一下 :https://www.zhihu.com/question/20584476
3、Mongodb熟悉吗,一般部署几台?
笔者回答:部署过,没有深入研究过,一般mongodb部署主从、或者mongodb分片集群;建议3台或5台服务器来部署。MongoDB分片的基本思想就是将集合切分成小块。这些块分散到若干片里面,每个片只负责总数据的一部分。 对于客户端来说,无需知道数据被拆分了,也无需知道服务端哪个分片对应哪些数据。数据在分片之前需要运行一个路由进程,进程名为mongos。这个路由器知道所有数据的存放位置,知道数据和片的对应关系。对客户端来说,它仅知道连接了一个普通的mongod,在请求数据的过程中,通过路由器上的数据和片的对应关系,路由到目标数据所在的片上,如果请求有了回应,路由器将其收集起来回送给客户端。
4、如何发布和回滚,用jenkins又是怎么实现?
笔者回答:发布:jenkins配置好代码路径(SVN或GIT),然后拉代码,打tag。需要编译就编译,编译之后推送到发布服务器(jenkins里面可以调脚本),然后从分发服务器往下分发到业务服务器上。
回滚:按照版本号到发布服务器找到对应的版本推送
5、Tomcat工作模式?
笔者回答:Tomcat是一个JSP/Servlet容器。其作为Servlet容器,有三种工作模式:独立的Servlet容器、进程内的Servlet容器和进程外的Servlet容器。
进入Tomcat的请求可以根据Tomcat的工作模式分为如下两类:
Tomcat作为应用程序服务器:请求来自于前端的web服务器,这可能是Apache, IIS, Nginx等;
Tomcat作为独立服务器:请求来自于web浏览器;
6、监控用什么实现的?
笔者回答:现在公司的业务都跑在阿里云上,我们首选的监控就是用阿里云监控,阿里云监控自带了ECS、RDS等服务的监控模板,可结合自定义报警规则来触发监控项。上家公司的业务是托管在IDC,用的是zabbix监控方案,zabbix图形界面丰富,也自带很多监控模板,特别是多个分区、多个网卡等自动发现并进行监控做得非常不错,不过需要在每台客户机(被监控端)安装zabbix agent。
7、你是怎么备份数据的,包括数据库备份?
笔者回答:在生产环境下,不管是应用数据、还是数据库数据首先在部署的时候就会有主从架构、或者集群,这本身就是属于数据的热备份;其实考虑冷备份,用专门一台服务器做为备份服务器,比如可以用rsync+inotify配合计划任务来实现数据的冷备份,如果是发版的包备份,正常情况下有台发布服务器,每次发版都会保存好发版的包。
8、redis集群的原理,redis分片是怎么实现的,你们公司redis用在了哪些环境?
笔者回答:reids集群原理:
其实它的原理不是三两句话能说明白的,redis 3.0版本之前是不支持集群的,官方推荐最大的节点数量为1000,至少需要3(Master)+3(Slave)才能建立集群,是无中心的分布式存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用、可扩展等问题。集群可以将数据自动切分(split)到多个节点,当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
redis分片:
分片(partitioning)就是将你的数据拆分到多个 Redis 实例的过程,这样每个实例将只包含所有键的子集。当数据量大的时候,把数据分散存入多个数据库中,减少单节点的连接压力,实现海量数据存储。分片部署方式一般分为以下三种:
(1)在客户端做分片;这种方式在客户端确定要连接的redis实例,然后直接访问相应的redis实例;
(2)在代理中做分片;这种方式中,客户端并不直接访问redis实例,它也不知道自己要访问的具体是哪个redis实例,而是由代理转发请求和结果;其工作过程为:客户端先将请求发送给代理,代理通过分片算法确定要访问的是哪个redis实例,然后将请求发送给相应的redis实例,redis实例将结果返回给代理,代理最后将结果返回给客户端。
(3)在redis服务器端做分片;这种方式被称为“查询路由”,在这种方式中客户端随机选择一个redis实例发送请求,如果所请求的内容不再当前redis实例中它会负责将请求转交给正确的redis实例,也有的实现中,redis实例不会转发请求,而是将正确redis的信息发给客户端,由客户端再去向正确的redis实例发送请求。
redis用在了哪些环境:
java、php环境用到了redis,主要缓存有登录用户信息数据、设备详情数据、会员签到数据等
9、你会怎么统计当前访问的IP,并排序?
笔者回答:统计用户的访问IP,用awk结合uniq、sort过滤access.log日志就能统计并排序好。一般这么回答就够了,当然你还可以说出其它方式来统计,这都是你的加分项。
10、你会使用哪些虚拟化技术?
笔者回答:vmware vsphere及kvm,我用得比较多的是vmware vsphere虚拟化,几本上生产环境都用的vmware vsphere,kvm我是用在测试环境中使用。vmware 是属于原生架构虚拟化技术,也就是可直接在硬件上运行。kvm属于寄居架构的虚拟化技术,它是依托在系统之上运行。vmware vcenter
管理上比较方便,图形管理界面功能很强大,稳定性强,一般比较适合企业使用。KVM管理界面稍差点,需要管理人员花费点时间学习它的维护管理技术。
11、假如有人反应,调取后端接口时特别慢,你会如何排查?
笔者回答:其实这种问题都没有具体答案,只是看你回答的内容与面试官契合度有多高,能不能说到他想要的点上,主要是看你排查问题的思路。我是这么说的:问清楚反应的人哪个服务应用或者页面调取哪个接口慢,叫他把页面或相关的URL发给你,首先,最直观的分析就是用浏览器按F12,看下是哪一块的内容过慢(DNS解析、网络加载、大图片、还是某个文件内容等),如果有,就对症下药去解决(图片慢就优化图片、网络慢就查看内网情况等)。其次,看后端服务的日志,其实大多数的问题看相关日志是最有效分析,最好用tail -f 跟踪一下日志,当然你也要点击测试来访问接口日志才会打出来。最后,排除sql,,找到sql去mysql执行一下,看看时间是否很久,如果很久,就要优化SQL问题了,expain一下SQL看看索引情况啥的,针对性优化。数据量太大的能分表就分表,能分库就分库。如果SQL没啥问题,那可能就是写的逻辑代码的问题了,一行行审代码,找到耗时的地方改造,优化逻辑。
12、mysql数据库用的是主从读写分离,主库写,从库读,假如从库无法读取了、或者从库读取特别慢,你会如何解决?
笔者回答:这个问题笔者觉得回答的不太好,对mysql比较在行的朋友希望能给点建议。以解决问题为前提条件,先添加从库数量,临时把问题给解决,然后抓取slow log ,分析sql语句,该优化就优化处理。慢要不就是硬件跟不上,需要升级;要不就是软件需要调试优化,等问题解决在细化。
13、cpu单核和多核有啥区别?
笔者回答:很少有面试官会问这样的问题,即然问到了,也要老实回答。还好笔者之前了解过CPU,我是这么说的:双核CPU就是能处理多份任务,顺序排成队列来处理。单核CPU一次处理一份任务,轮流处理每个程序任务。双核的优势不是频率,而是对付同时处理多件事情。单核同时只能干一件事,比如你同时在后台BT下载,前台一边看电影一边拷贝文件一边QQ。
14、机械磁盘和固态硬盘有啥区别?
笔者回答:我擦,啥年代了,还问磁盘的问题,这面试官有点逗啊。那也要回答啊:
HDD代表机械硬盘,SSD代表固态硬盘。首先,从性能方面来说,固态硬盘几乎完胜机械硬盘,固态硬盘的读写速度肯定要快机械硬盘,因为固态硬盘和机械硬盘的构造是完全不同的(具体的构造就没必要解释了)。其次,固态盘几乎没有噪音、而机械盘噪音比较大。还有就是,以目前的市场情况来看,一般机械盘容量大,价格低;固态盘容量小,价格偏高。但是企业还是首选固态盘。
15、说一下用过哪些监控系统?
笔者回答:这个监控的问题又问到了,笔者在2018年1月4号也被问到类似这样的问题,笔者曾经用过zabbix、nagios、 cacit等。但是在这次面试中只说用过zabbix和nagios。说完了之后,面试官就让我说一下这两个监控有啥区别:
从web功能及画图来讲:
Nagios简单直观,报警与数据都在同一页面, 红色即为问题项。Nagios web端不要做任何配置。 Nagios需要额外安装插件,且插件画图不够美观。
Zabbix监控数据与报警是分开的,查看问题项需要看触发器,查看数据在最新数据查看。而且zabbix有很多其它配置项, zabbix携带画图功能,且能手动把多个监控项集在一个图中展示。
从监控服务来讲:
Nagios自带的监控项很少。对一些变动的如多个分区、多个网卡进行监控时需要手动配置。
Zabbix自带了很多监控内容,感觉zabbix一开始就为你做了很多事,特别是对多个分区、多个网卡等自动发现并进行监控时,那一瞬间很惊喜,很省心的感觉。
从批量配置和报警来讲:
Nagios对于批量监控主机,需要用脚本在server端新增host,并拷贝service文件。 Nagios用脚本来修改所有主机的services文件,加入新增服务。
Zabbix在server端配置自动注册规则,配置好规则后,后续新增client端不需要对server端进行操作。 Zabbix只需手动在模板中新增一监控项即可。
总体来讲:
Nagios要花很多时间写插件,Zabbix要花很多时间探索功能。
Nagios更易上手,Nagios两天弄会,Zabbix两周弄会。
Zabbix画图功能比Nagios更强大
Zabbix对于批量监控与服务更改,操作更简洁;Nagios如果写好自动化脚本后,也很简单,问题在于写自动化脚本很费神。
16、给你一套环境,你会如何设计高可用、高并发的架构?
笔者回答:如果这套环境是部署在云端(比如阿里云),你就不用去考虑硬件设计的问题。可直接上阿里云的SLB+ECS+RDS这套标准的高可用、高并发的架构。对外服务直接上SLB负载均衡技术,由阿里的SLB分发到后端的ECS主机;ECS主机部署多台,应用拆分在不同的ECS主机上,尽量细分服务。数据库用RDS高可用版本(一主一备的经典高可用架构)、或者用RDS金融版(一主两备的三节点架构)。在结合阿里其它的服务就完全OK,业务量上来了,主机不够用了,直横向扩容ECS主机搞定。
如果这套环境托管在IDC,那么你就要从硬件、软件(应用服务)双面去考虑了。硬件要达到高可用、高并发公司必须买多套网络硬件设备(比如负载设备F5、防火墙、核心层交换、接入层交换)都必须要冗余,由其是在网络设计上,设备之间都必须有双线连接。设备如果都是跑的单机,其中一个设备挂了,你整个网络都瘫痪了,就谈不上高可用、高并发了。其次在是考虑应用服务了,对外服务我会采用成熟的开源方案LVS+Keepalived或者Nginx+Keepalived,缓存层可以考虑redis集群及Mongodb集群,中间件等其它服务可以用kafka、zookeeper,图片存储可以用fastDFS或MFS,如果数据量大、又非常多,那么可采用hadoop这一套方案。后端数据库可采用 “主从+MHA”。这样一套环境下来是绝对满足高可用、高并发的架构。
17、nginx反向代理配置,此类url www.abc.com/refuse,禁止访问,返回403
笔者回答:首先呢,安装nginx,然后进入nginx的配置文件,加入upstream 自定义名字{ server:www.abc.com/refuse}这样得一个节点,然后在server{}节点上加上http://自定义的名字,最后呢配置nginx限制过滤特定的接口访问,像这个样location ~/solr/.*/update{return 403;} ,这样就能返回403了。
18、如何使用 ptables将本地 80端口的请求转发到8080端口,当前主机 IP为192.168.16.1,其中本地网卡 etho;
笔者回答:iptables允许192.168.16.1ip端口为80转发到ip为8080的端口,操作如下:
iptables -t nat -A PREROUTING -d 192.168.16.1 -p tcp --dport 80 -j DNAT --to 192.168.16.1:8080
19、如何查看 linux系统的当前状态,CPU 内存的使用情况和负载
笔者回答:使用top命令,查看linux的状态,top里边有一个cpu值,这个就是cpu的内存使用的情况 使用uptime中load average的查看平均负载
20、nginx如何重新定义或者添加发往后端服务器的请求头?
笔者回答:默认情况下,有两个请求头会被重新定义:
proxy_set_header Host $proxy_host; //默认会将后端服务器的HOST填写进去
proxy_set_header Connection close;
然后将nginx map配置根据请求头不同分配流量到不同后端服务
21、编写个 shll脚本将当前目录下大于10K的文件转移到/tmp目录下
笔者回答:
#!/bin/bash
name = ls -l | awk ‘$5 > 10240 {print $9}’
mv $name > /tmp
ls -la /tmp
22、写出你所了解的门户网站的服务架构,可用什么方式实现的高可用、负载均衡?
笔者回答:我了解的大部分的大型网站是采用docker+redi集群来实现缓存,然后通过使用nginx反向代理来确保安全性,再采用lvs+MySQL主主+keepalived来实现单点高可用和负载均衡。
23、nginx 日志过滤10点到12点之间访问 IP排名和统计
笔者回答:
sed -n ‘/10:00/,/12:00/p’ /var/log/nginx/access.log | awk ‘{a[$1]++} END {for(b in a) print b"\t"a[b]}’ | sort -k 2 -r | head -n 10
24、在11月份内,每天的早上6点到12点,每隔2小时执行一次/usr/bin/httpd.sh怎么实现
笔者回答:
0 6-12/2 * 11 * /usr/bin/httpd.sh
25、分布式文件存储是否有过了解和使用,了解过的有什么特性
笔者回答:DFS
通过DFS,可以使分布在多个服务器上的文件在用户面前显示时,就如同位于网络上的一个位置。用户在访问文件时不再需要知道和指定它们的实际物理位置。
26、使用 netstat 和 awk 命令统计下网络连接数;
笔者回答:
netstat -n | awk ‘/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}’
LAST_ACK 1
SYN_RECV 14
ESTABLISHED 79
FIN_WAIT1 28
FIN_WAIT2 3
CLOSING 5
TIME_WAIT 1669
状态:描述
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
27、在linux下,假设 nginx 日志的路径为/opt/logs/access.logs,日志不能自动分割,请写出一个简单的脚本,让日志每天能够定时自动分割
笔者回答:
#! /bin/bash
base_path=’/usr/local/nginx/logs’
log_path=( d a t e − d y e s t e r d a y + " m i n u t e = (date -d yesterday +"%Y%m") minute=(date−dyesterday+"minute=(date -d “1 minute ago” +"%Y%m%d-%H:%M")
mkdir -p b a s e p a t h / base_path/base
p
ath/log_path
echo $base_path/access.log
mv $base_path/access.log b a s e p a t h / base_path/base
p
ath/log_path/access_$minute.log
echo b a s e p a t h / base_path/base
p
ath/log_path/access_$minite.log
kill -USR1 cat /usr/local/nginx/logs/nginx.pid
#crontab -l
1 * * eck_nginx_log.sh
28、 写出raid 的几种模式,以及他们的特点
笔者回答:
Raid 0: 读写传输数据的速度最快
Raid 1:所存储的数据安全性高,但硬盘容量损失大
Raid 3:安全性能好,但是写入慢
Raid 5:磁盘利用率高,数据安全性高,成本低
Raid 10 :拥有RAID 0的高速,又拥有RAID 1的安全。
29、写一个脚本,查找15天前以 png 结尾的文件并删除
笔者回答:
#!/bin/bash
find ./ -name “*.png” -mtime +15 -print -exec rm -fr {} ;
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为’command’ { } ;
30、对于服务器的监控使用过哪类工具及其特点
笔者回答:Zabbix:数据采集比较强,支持agent、teknet等多种采集方式;支持多种报警管理,报警的设置比较全面,图形化展示比较直观,历史数据查询可配置,具有安装的用户审计日志
普罗米修斯:具有多维数据模型,拥有一种灵活的查询语言,课完成复杂的查询,不依赖分布式存储,通过服务发现或静态配置发现目标。
Nagios:具备定义网络分层结构的能力,可以支持并实现对主机的冗余监控,自动的日志回滚,并行服务检查机制
31、作为运维工程师,你对该职位的认识和理解有哪些,日常工作中应该怎么做
笔者回答:
运维就是对网络软硬件的维护,是要保证业务的上线与运作的正常,在业务运转的过程中,对业务进行维护,运维集合了网络、系统、数据库、开发、安全、 监控于一身的技术。运维要做的一个事情除了协调工作以外,还需要与各平台沟通,做好开服的时间、开 服数、用户导量、活动等计划。
32、介绍一下:Linux标准输入、输出和错误和文件重定向
笔者回答:
当我们在shell中执行命令的时候,每个进程都和三个打开的文件相联系,并使用文件描述符来引用这些文件。由于文件描述符不容易记忆,shell同时也给出了相应的文件名。
下面就是这些文件描述符及它们通常所对应的文件名:
文件文件描述符
系统中实际上有12个文件描述符,但是正如我们在上表中所看到的, 0、1、2是标准输入、输出和错误。可以任意使用文件描述符3到9。标准输入是文件描述符0。它是命令的输入,缺省是键盘,也可以是文件或其他命令的输出。
标准输出是文件描述符1。它是命令的输出,缺省是屏幕,也可以是文件。
标准错误是文件描述符2。这是命令错误的输出,缺省是屏幕,同样也可以是文件。
你可能会问,为什么会有一个专门针对错误的特殊文件?这是由于很多人喜欢把错误单独保存到一个文件中,特别是在处理大的数据文件时,可能会产生很多错误。
如果没有特别指定文件说明符,命令将使用缺省的文件说明符(你的屏幕,更确切地说是你的终端)。文件重定向
在执行命令时,可以指定命令的标准输入、输出和错误,要实现这一点就需要使用文件重定向。下表列出了最常用的重定向组合,并给出了相应的文件描述符。
在对标准错误进行重定向时,必须要使用文件描述符,但是对于标准输入和输出来说,这不是必需的。其语法如下:
command < filename 把标准输入重定向到filename文件中
command 0< filename 同上
command > filename 把标准输出重定向到filename文件中(覆盖)
command 1> fielname 同上
command >> filename 把标准输出重定向到filename文件中(追加)
command 1>> filename 同上
command 2> filename 把标准错误重定向到filename文件中(覆盖)
command 2>> filename 同上
command > filename 2>&1 把标准输出和标准错误一起重定向到filename文件中(覆盖)
command >> filename 2>&1 把标准输出和标准错误一起重定向到filename文件中(追加)
command < filename >filename2 把文件filename中的内容作为command的输入,把标准输出重定向到filename2文件中command 0< filename 1> filename2 同上
重定向的使用有如下规律:
1)标准输入0、输出1、错误2需要分别重定向,一个重定向只能改变它们中的一个。
2)标准输入0和标准输出1可以省略。(当其出现重定向符号左侧时)
3)文件描述符在重定向符号左侧时直接写即可,在右侧时前面加& 【类似于指针前要加*号,来区分这、两种情况】。
4)文件描述符与重定向符号之间不能有空格!
33、Linux启动大致过程?
第一步:开机自检,加载BIOS
第二步:读取MBR
第三步:Boot Loader grub引导菜单
第四步:加载kernel内核
第五步:init进程依据inittab文件夹来设定运行级别
第六步:init进程执行rc.sysinit
第七步:启动内核模块
第八步:执行不同运行级别的脚本程序
第九步:执行/etc/rc.d/rc.local
第十步:执行/bin/login程序,启动mingetty,进入登录状态
34、Nginx和Apache的区别?
Apache和Nginx最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程;而 nginx 是异步的,多个连接(万级别)可以对应一个进程。
一般来说,需要性能的 web 服务,用 nginx 。如果不需要性能只求稳定,更考虑 apache 。更为通用的方案是,前端 nginx 抗并发,后端 apache 集群,配合起来会更好。
详细区别对比:
- Apache
-
- ● apache 的 rewrite 比 nginx 强大,在 rewrite 频繁的情况下,用 apache
- ● apache 发展到现在,模块超多,基本想到的都可以找到
- ● apache 更为成熟,少 bug ,nginx 的 bug 相对较多
- ● apache 超稳定
- ● apache 对 PHP 支持比较简单,nginx 需要配合其他后端用
- ● apache 在处理动态请求有优势,nginx 在这方面是鸡肋,一般动态请求要 apache 去做,nginx 适合静态和反向。
- ● apache 仍然是目前的主流,拥有丰富的特性,成熟的技术和开发社区
-
- Nginx
-
- ● 轻量级,采用 C 进行编写,同样的 web 服务,会占用更少的内存及资源
- ● 抗并发,nginx 以 epoll and kqueue 作为开发模型,处理请求是异步非阻塞的,负载能力比 apache 高很多,而 apache 则是阻塞型的。
- 在高并发下 nginx 能保持低资源低消耗高性能 .而 apache 在 PHP 处理慢或者前端压力很大的情况下,很容易出现进程数飙升,从而拒绝服务的现象。
- ● nginx 处理静态文件好,静态处理性能比 apache 高三倍以上
- ● nginx 的设计高度模块化,编写模块相对简单
- ● nginx 配置简洁,正则配置让很多事情变得简单,而且改完配置能使用 -t 测试配置有没有问题
- apache 配置复杂 ,重启的时候发现配置出错了,会很崩溃
- ● nginx 作为负载均衡服务器,支持 7 层负载均衡
- ● nginx 本身就是一个反向代理服务器,而且可以作为非常优秀的邮件代理服务器
- ● 启动特别容易, 并且几乎可以做到 7*24 不间断运行,即使运行数个月也不需要重新启动,还能够不间断服务的情况下进行软件版本的升级
- ● 社区活跃,各种高性能模块出品迅速

35、LVS三种模式的工作过程?
原文链接:
LVS工作模式分为NAT模式、TUN模式、以及DR模式
LVS(Linux Virtual Server)即Linux虚拟服务器,是由章文嵩博士主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中。该项目在Linux内核中实现了基于IP的数据请求负载均衡调度方案,其体系结构如图1所示,终端互联网用户从外部访问公司的外部负载均衡服务器,终端用户的Web请求会发送给LVS调度器,调度器根据自己预设的算法决定将该请求发送给后端的某台Web服务器,比如,轮询算法可以将外部的请求平均分发给后端的所有服务器,终端用户访问LVS调度器虽然会被转发到后端真实的服务器,但如果真实服务器连接的是相同的存储,提供的服务也是相同的服务,最终用户不管是访问哪台真实服务器,得到的服务内容都是一样的,整个集群对用户而言都是透明的。最后根据LVS工作模式的不同,真实服务器会选择不同的方式将用户需要的数据发送到终端用户,LVS工作模式分为NAT模式、TUN模式、以及DR模式。

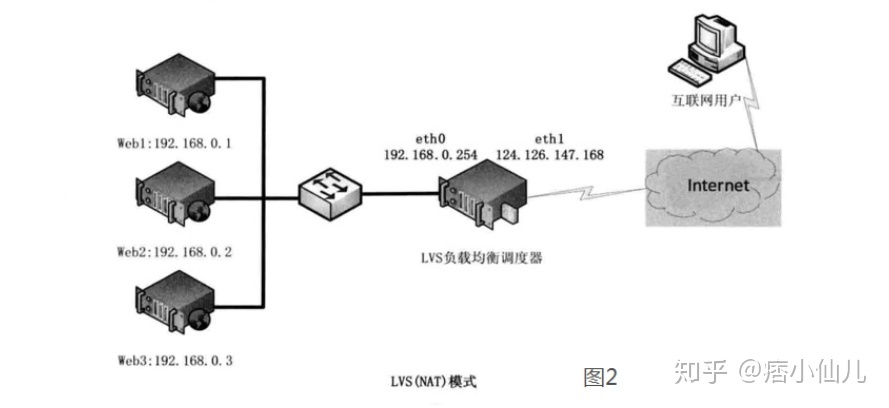
1、基于NAT的LVS模式负载均衡
第一步,用户通过互联网DNS服务器解析到公司负载均衡设备上面的外网地址,相对于真实服务器而言,LVS外网IP又称VIP(Virtual IP Address),用户通过访问VIP,即可连接后端的真实服务器(Real Server),而这一切对用户而言都是透明的,用户以为自己访问的就是真实服务器,但他并不知道自己访问的VIP仅仅是一个调度器,也不清楚后端的真实服务器到底在哪里、有多少真实服务器。
第二步,用户将请求发送至124.126.147.168,此时LVS将根据预设的算法选择后端的一台真实服务器(192.168.0.1~192.168.0.3),将数据请求包转发给真实服务器,并且在转发之前LVS会修改数据包中的目标地址以及目标端口,目标地址与目标端口将被修改为选出的真实服务器IP地址以及相应的端口。
第三步,真实的服务器将响应数据包返回给LVS调度器,调度器在得到响应的数据包后会将源地址和源端口修改为VIP及调度器相应的端口,修改完成后,由调度器将响应数据包发送回终端用户,另外,由于LVS调度器有一个连接Hash表,该表中会记录连接请求及转发信息,当同一个连接的下一个数据包发送给调度器时,从该Hash表中可以直接找到之前的连接记录,并根据记录信息选出相同的真实服务器及端口信息。
2、基于TUN的LVS负载均衡
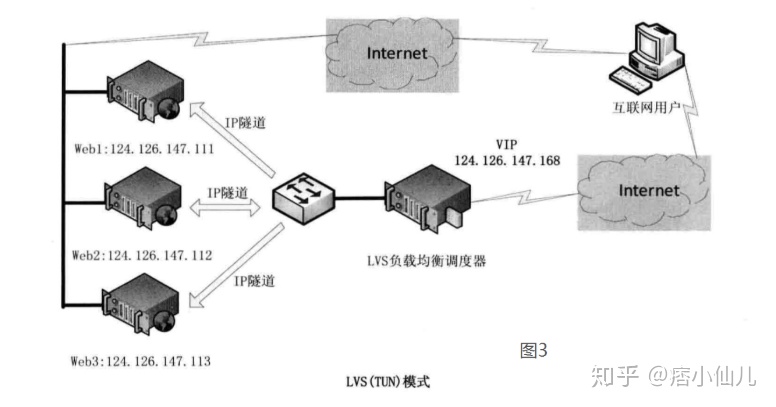
在LVS(NAT)模式的集群环境中,由于所有的数据请求及响应的数据包都需要经过LVS调度器转发,如果后端服务器的数量大于10台,则调度器就会成为整个集群环境的瓶颈。我们知道,数据请求包往往远小于响应数据包的大小。因为响应数据包中包含有客户需要的具体数据,所以LVS(TUN)的思路就是将请求与响应数据分离,让调度器仅处理数据请求,而让真实服务器响应数据包直接返回给客户端。VS/TUN工作模式拓扑结构如图3所示。其中,IP隧道(IP tunning)是一种数据包封装技术,它可以将原始数据包封装并添加新的包头(内容包括新的源地址及端口、目标地址及端口),从而实现将一个目标为调度器的VIP地址的数据包封装,通过隧道转发给后端的真实服务器(Real Server),通过将客户端发往调度器的原始数据包封装,并在其基础上添加新的数据包头(修改目标地址为调度器选择出来的真实服务器的IP地址及对应端口),LVS(TUN)模式要求真实服务器可以直接与外部网络连接,真实服务器在收到请求数据包后直接给客户端主机响应数据。
3、基于DR的LVS负载均衡
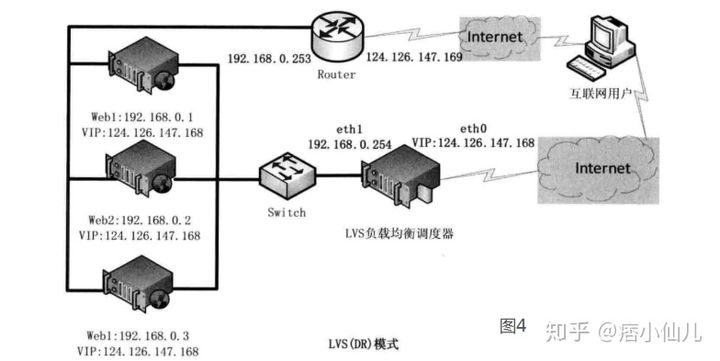
在LVS(TUN)模式下,由于需要在LVS调度器与真实服务器之间创建隧道连接,这同样会增加服务器的负担。与LVS(TUN)类似,DR模式也叫直接路由模式,其体系结构如图4所示,该模式中LVS依然仅承担数据的入站请求以及根据算法选出合理的真实服务器,最终由后端真实服务器负责将响应数据包发送返回给客户端。与隧道模式不同的是,直接路由模式(DR模式)要求调度器与后端服务器必须在同一个局域网内,VIP地址需要在调度器与后端所有的服务器间共享,因为最终的真实服务器给客户端回应数据包时需要设置源IP为VIP地址,目标IP为客户端IP,这样客户端访问的是调度器的VIP地址,回应的源地址也依然是该VIP地址(真实服务器上的VIP),客户端是感觉不到后端服务器存在的。由于多台计算机都设置了同样一个VIP地址,所以在直接路由模式中要求调度器的VIP地址是对外可见的,客户端需要将请求数据包发送到调度器主机,而所有的真实服务器的VIP地址必须配置在Non-ARP的网络设备上,也就是该网络设备并不会向外广播自己的MAC及对应的IP地址,真实服务器的VIP对外界是不可见的,但真实服务器却可以接受目标地址VIP的网络请求,并在回应数据包时将源地址设置为该VIP地址。调度器根据算法在选出真实服务器后,在不修改数据报文的情况下,将数据帧的MAC地址修改为选出的真实服务器的MAC地址,通过交换机将该数据帧发给真实服务器。整个过程中,真实服务器的VIP不需要对外界可见。
36、MySQL数据库备份的方法
在linux中简单选择两种备份方法
1.编写shell脚本
- dbName=你的数据库名称
- user=你的数据库账户
- password=你的数据库密码
- storePath=备份文件存储目录
- mysqldump -u$user -p$password $dbName > $storePath/${dbName}_$(date +%Y%m%d_%H%M).sql
-
- #添加可执行权限
- chmod u+x backup.sh
-
- #运行
- ./backup.sh
-
- #写进定时执行任务里 (四小时备份一次)
- crontab -e
- 30 */4 * * * /home/mysql/expertsystem/backup.sh
- #定时任务表达式
- 基本格式 : 分 时 日 月 周 命令
- 第1列表示分钟1~59 每分钟用 * 或者 /1表示
- 第2列表示小时1~23(0表示0点)
- 第3列表示日期1~31
- 第4列表示月份1~12
- 第5列标识号星期0~6(0表示星期天)
37、 简述/etc/fstab里面每个字段的含义
/etc/fstab内容主要包括六项:
例如:打印出中间的两行内容
LABEL=/ / ext3 defaults 1 1 /dev/sda2 /mnt/D/ vfat defaults 0 0
第一列:设备名或者设备卷标名,(/dev/sda10 或者 LABEL=/)
第二列:设备挂载目录 (例如上面的“/”或者“/mnt/D/”)
第三列:设备文件系统 (例如上面的“ext3”或者“vfat”)
第四列:挂载参数 (看帮助man mount)
- 对于已经挂载好的设备,例如上面的/dev/sda2,现在要改变挂载参数,这时可以不用卸载该设备,而可以使用下面的命令(没有挂载的设备,remount 这个参数无效)
- #mount /mnt/D/ -o remount,ro (改defaults为ro)
- 为了安全起见,可以指明其他挂载参数,例如:
- noexec(不允许可执行文件可执行,但千万不要把根分区挂为noexec,那就无法使用系统了,连mount 命令都无法使用了,这时只有重新做系统了!
- nodev(不允许挂载设备文件)nosuid,nosgid(不允许有suid和sgid属性)
- nouser(不允许普通用户挂载)
第五列:指明是否要备份,(0为不备份,1为要备份,一般根分区要备份)
第六列:指明自检顺序。 (0为不自检,1或者2为要自检,如果是根分区要设为1,其他分区只能是2)
38、列举你知道的负载均衡
1. 实现负载均衡有多种方式:
软件负载均衡:比如常见的Nginx、LVS。
硬件负载均衡;买相应硬件。
DNS负载均衡:通过DNS域名解析的方式,使多个服务器IP对应一个域名。
2. 除了硬件外,下面是几种常见的方式,除了DNS域名解析是DNS实现的,其他均是软件负载均衡:
HTTP重定向
DNS域名解析
反向代理(Nginx)
IP负载均衡
链路层的负载均衡(LVS)
原谅链接:负载均衡及其常见实现方式_weixin_43751710的博客-CSDN博客
39、列出Linux常见打包工具并写相应解压缩参数(至少三种)
常用的就是tar,gz,和zip
tar结尾的,tar -cvf 打包,tar -xvf 解包
gz结尾的,tar -zcvf打包,tar -zxvf解包
zip结尾的,zip打包,unzip解包
40、一个ext3的文件分区,当用touch新建文件时报错,错误信息是磁盘已满,但是使用 df -h 查看空间并没有占满,原因是什么?
两种情况,一种是磁盘配额问题,另外一种就是EXT3文件系统的设计不适合很多小文件跟大文件的一种文件格式,出现很多小文件时,容易导致inode耗尽了。
41、请使用Linux系统命令统计出establish状态的连接数有多少?
[root @痞小仙儿 ] netstat -an |grep 80 |grep ESTABLISHED |wc -l42、MySQL数据库的备份还原是怎么做的?
平时采用两种方法来做:
(1)利用mysql自带的使用工具mysqldump和mysql来备份还原数据库
(2)利用第三方的mysql管理工具比如:mysqladmin
(3)停止mysqld服务拷贝数据文件
43、简述运维工程师的职责?
(1)有产品时的职责:
产品发布前:负责参与并审核架构设计的合理性和可运维性,以确保在产品发布之后能高效稳定的运行。
产品发布阶段:负责用自动化的技术或者平台确保产品可以高效的发布上线,之后可以快速稳定迭代。
产品运行维护阶段:负责保障产品7*24H稳定运行,在此期间对出现的各种问题可以快速定位并解决;在日常工作中不断优化系统架构和部署的合理性,以提升系统服务的稳定性
(2)日常职责
1,每日定时对机房内的网络服务器、数据库服务器、Internet服务器进行日常巡视,检查是否正常工作,公司的网站是否能正常访问;
2,每日巡查计算机系统各个终端电脑、打印机、复印机等设备是否工作正常,是否有不正确的操作使用,是否有带故障工作的设备;
3,每天夜间在大家都下班之后对财务软件进行自动实时备份,每周做一次物理数据备份,并在备份服务器中进行逻辑备份的验证工作;
4,每周至少对文件服务器做一次物理数据备份;还有就是处理各种有关网络的突发问题
44、 Linux系统是由哪些部分组成的?
内核、shell、文件系统和应用程序。
详情链接: linux系统组成及结构_不忘初心-CSDN博客
45、用一条命令查看目前系统已启动服务所监听的端口
[root @痞小仙儿 ] netstat -antl | grep "LISTEN"46、统计出一台web server上的各个状态(ESTABLISHED/SYN_SENT/SYN_RECV等)的个数?
- [root @痞小仙儿 ] netstat -antl | grep 'ESTABLISHED' | wc -l
- [root @痞小仙儿 ] netstat -antl | grep "SYN_SENT" | wc -l
- [root @痞小仙儿 ] netstat -antl | grep "SYN_RECV" | wc -l
47、查找/usr/local/nginx/logs目录最后修改时间大于30天的文件,并删除
[root @痞小仙儿 ] find /usr/local/nginx/logs -type f -mtime +30 -exec rm -f{} \;48、添加一条到192.168.3.0/24的路由,网关为192.168.1.254;
[root@localhost wang]# route add -net 192.168.3.0 netmask 255.255.255.0 gw 192.168.1.254
49、利用sed命令将test.txt中所有的回车替换成空格;
[root @痞小仙儿 ] sed -i s/\r/ /g test.txt50、在每周6的凌晨3:15执行/home/shell/collect.pl,并将标准输出和标准错误输出到/dev/null设备,请写出crontab中的语句;
15 3 * * 6 /home/shell/collect.pl > /dev/null 2>&1
51、源码编译安装apache,要求为:安装目录为/usr/local/apache,需要压缩模块rewrite,worker模式;并说明在Apache的worker MPM中,为什么ServerLimit要放到配置段最前面?
不放在最前面的话,client会忽略掉的
./configure --prefix=/usr/local/apache --enable-so --with-rewrite --with-mpm-worker52、请写出精确匹配IPV4规范的正则表达式;
([0-1][0-9][0-9]|2[0-4][0-9]|25[0-5]|[0-9][0-9]|[1-9])
53、匹配文本中的key,并打印出该行级下面的5行
[root @痞小仙儿 ] grep -A5 key filename54、dmesg命令中看到ip_conntrack:table full,dropping packet,如何解决
解决方法:
55、查询fifile1里面空行的所有行号
[root @痞小仙儿 ] grep -n ^$ file|awk -F":" '{print $1}'56、查询fifile1中以abc结尾的行
[root @痞小仙儿 ] grep abc$ file157、如何将本地80端口的请求转发到8080端口,当前主机IP为192.168.2.1
[root @痞小仙儿 ] iptables -t nat -A PREROUTING -d 192.168.2.1 -p tcp --dport 80 -j DNAT --to-des 192.168.2.1:808058、crontab: 在11月份内,每天的早上6点到12点中,每隔2小时执行一次/usr/bin/httpd.sh,怎样实现?
00 6-12/2 * 11 * /bin/sh /usr/bin/httpd.sh &>/dev/null
59、编写一个shell脚本将/usr/local/test目录下大于100k的文件转移到/tmp目录
[root @痞小仙儿 ] find /usr/local/test -type f -size +100k -exec mv {} /tmp \;60、有三台Linux主机:A、B和C,A上有私钥,B和C上都有公钥,如何做到用私钥从A登陆到B后,可以直接不输密码即可再登录到C?并写出具体命令行。
大致思路在A上面ssh-keygen -t dsa 直接回车生成密钥,然后把公钥分别用ssh-copy-id拷贝到B和C上面。ssh-copy-id -i id_dsa.pub "-p端口号 root@B的ip地址",然后在A上面就可以用ssh -p端口号 root@IP不要密码直接登录服务器B和C
61、介绍一下grep显示匹配行的上下几行的用法
- grep -C 3 love filename #显示filename文件中,包含字符串love行上下3行内容(含love行)
-
- grep -A 3 love filename #显示filename文件中,包含字符串love行下3行内容(含love行)
-
- grep -B 3 love filename #显示filename文件中,包含字符串love行上3行内容(含love行)
62、介绍一下sed命令的常见用法
简介:
sed是一种流编辑器,它是文本处理中非常有用的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为『模式空间』(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。sed主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等。
命令语法:
sed [-hnV][-e<script>][-f<script文件>][文本文件] #sed命令语法选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。function:
a :新增行, a 的后面可以是字串,而这些字串会在新的一行出现(目前的下一行)
c :取代行, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
d :删除行,因为是删除,所以 d 后面通常不接任何参数,直接删除地址表示的行;
i :插入行, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :替换,可以直接进行替换的工作,通常这个 s 的动作可以搭配正规表示法,例如 1,20s/old/new/g 一般是替换符合条件的字符串而不是整行一般function的前面会有一个地址的限制,例如 [地址]function,表示我们的动作要操作的行。下面我们通过具体的例子直观的看看sed的使用方法。
(1)打印行
新建文件 test.txt 内容如下:
打印文件所有行:
打印文件第2行:
打印文件第2,3,5行:
打印文件中包含moon的行(其中//内支持正则表达式 过滤内容):
打印文件第1到3行:
打印文件中包含cat的行到包含moon的行:
打印文件的奇数行:
打印文件的偶数行:
(2)删除行
新建文件 test.txt 内容如下:
删除文件中所有空白行:
删除文件的第2行:
删除文件第2行到末行的所有行:
删除文件的最后一行:
删除文件所有以33开头的行:
删除文件包含moon的行:
删除文件从包含cat的行到包含moon的行:
(3)新增行
a 即append,意思为:追加,--下一行
i 即insert,意思为:插入,--上一行在文件第1行的下方新增一行(追加)):
在文件第1行的上方新增一行(插入)):
在文件包含moon的行的上方新增一行:
在文件包含moon的行的上方新增两行:
在文件 包含moon的行 到 包含bingo的行 的上方各新增两行(使用\n):
(4)取代行
取代文件的第1行:
取代文件的第2号到第6行:
(5)替换指定字符
不加g,将每行第一处被匹配到的字符串进行替换:
加g --global,每行所有被匹配到的字符串进行全部替换:
-n选项和p命令一起使用表示只打印那些发生替换的行:
当需要从第N处匹配开始替换时,可以使用/Ng:
正则表达式\w\+匹配每一个单词,使用[&]替换它,&对应之前所匹配到的单词:
变量替换,需要使用双引号识别,###之间定义变量:
(6)修改读取的文件内容
test.txt文件中的第2行被删除了
使用 -i 选项直接修改文件的内容,而不是将修改结果输出到终端上(需要谨慎使用)
(7)sed中的元字符
63、说明一下:如何用 grep + rm 删除当前目录下的名称带有test的文件和文件夹
- [root@localhost wang]# ls | grep "test"
- test001
- test002
- test003
- test004
- test005
- test006
- test007
- test008
- test.txt
- [root@localhost wang]# rm -rf `ls | grep "test"`
- [root@localhost wang]# ls | grep "test"
- [root@localhost wang]#
64、 简述一下:grep同时匹配多个关键字或任意关键字
(1)与操作
(2)或操作
(3)其他操作
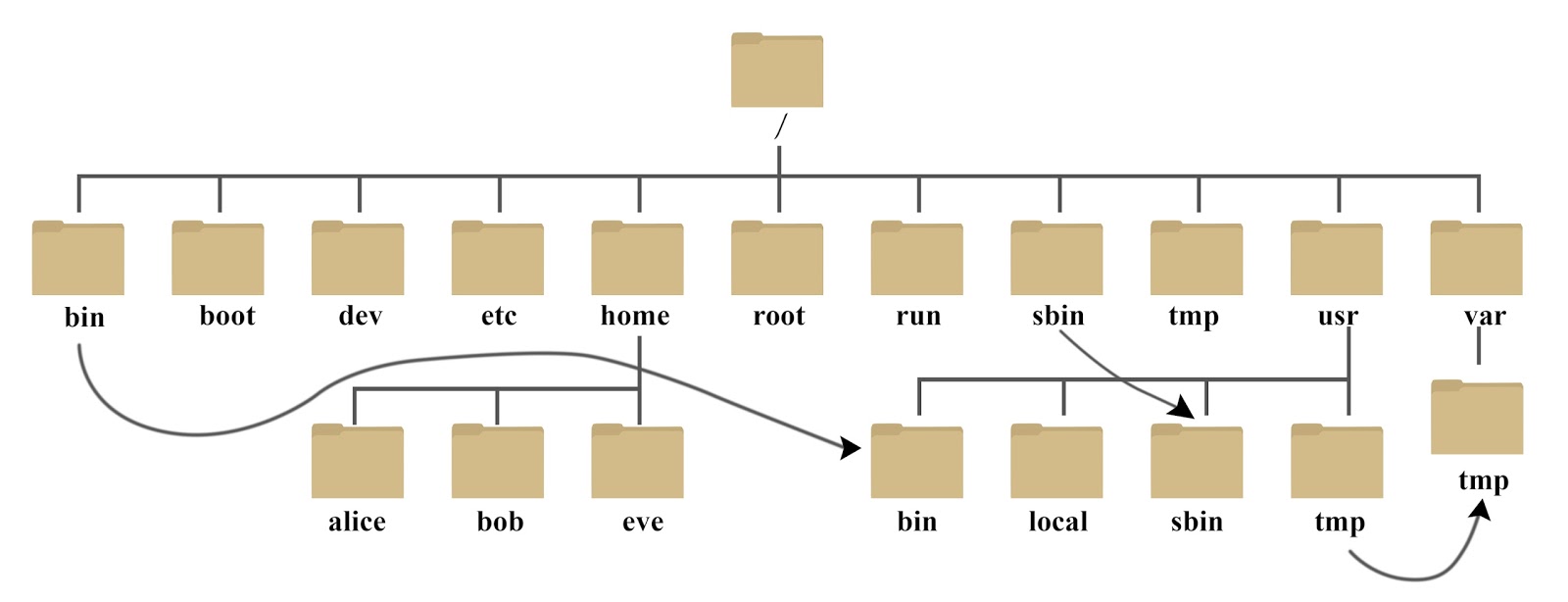
65、 介绍一下:linux软件默认安装目录
(1)linux软件默认安装目录
(2)拓展1:linux目录结构
树状目录结构:
以下是对这些目录的解释:
(3)拓展2:常用目录详解
/proc
/proc 正在运行的内核信息映射,主要输出的信息为:进程信息、内存资源信息、磁盘分区信息等。
/sys
/sys 硬件设备的驱动程序信息
/usr
/usr用于存放系统应用程序,比较重要的目录/usr/local 本地系统管理员软件安装目录(安装系统级的应用)。这是最庞大的目录,要用到的应用程序和文件几乎都在这个目录。
66、 CentOS7开机进入紧急模式EmergencyMode的解决办法
这个情况主要是 修改了 /etc/fstab 文件
vi /etc/fstab 文件
如果之前添加过一行 把添加的一行注释掉
如果之前没有添加过,把挂载到 /home 这一行取消注释
操作之后 记得 :wq 保存退出
然后 reboot 即可
67、Linux查看进程的4种方法
进程是在 CPU 及内存中运行的程序代码,而每个进程可以创建一个或多个进程(父子进程)。
第一种:
ps auxps命令用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
a:显示当前终端下的所有进程信息,包括其他用户的进程。
u:使用以用户为主的格式输出进程信息。
x:显示当前用户在所有终端下的进程。
示例:
**上图中各字段解释:**USER:启动该进程的用户账号名称
PID:该进程的ID号,在当前系统中是唯一的
%CPU:CPU占用的百分比
%MEM:内存占用的百分比VSZ:占用虚拟内存(swap空间)的大小
RSS:占用常驻内存(物理内存)的大小TTY:该进程在哪个终端上运行。“?”表未知或不需要终端
STAT:显示了进程当前的状态,如S(休眠)、R(运行)、Z(僵死)、<(高优先级)、N(低优先级)、s(父进程)、+(前台进程)。对处于僵死状态的进程应予以手动终止。START:启动该进程的时间
TIME:该进程占用CPU时间
COMMAND:启动该进程的命令的名称**总结:ps aux 是以简单列表的形式显示出进程信息。**
第二种:
ps -elf-e:显示系统内的所有进程信息。
-l:使用长(long)格式显示进程信息。
-f:使用完整的(full)格式显示进程信息。
上图字段解释:
大部分跟第一种一样,PPID为父进程的PID。第三种:
上图解释:
Tasks(系统任务)信息:total,总进程数;running,正在运行的进程数;sleeping,休眠的进程数;stopped,中止的进程数;zombie,僵死无响应的进程数。CPU信息:us,用户占用;sy,内核占用;ni,优先级调度占用;id,空闲CPU;wa,I/O等待占用;hi,硬件中断占用;si,软件中断占用;st,虚拟化占用。了解空闲的CPU百分比,主要看%id部分。
Mem(内存)信息:total,总内存空间;used,已用内存;free,空闲内存;buffers,缓存区域。
Swap(交换空间)信息:total,总交换空间;used,已用交换空间;free,空闲交换空间;cached,缓存空间。
第四种:
pstree -aup可以带上|grep 查询特定进程。例如 pstree -aup | grep gvfsd
以树状图的方式展现进程之间的派生关系,显示效果比较直观。
-a:显示每个程序的完整指令,包含路径,参数或是常驻服务的标示;
-c:不使用精简标示法;
-G:使用VT100终端机的列绘图字符;
-h:列出树状图时,特别标明现在执行的程序;
-H<程序识别码>:此参数的效果和指定"-h"参数类似,但特别标明指定的程序;
-l:采用长列格式显示树状图;
-n:用程序识别码排序。预设是以程序名称来排序;
-p:显示程序识别码;
-u:显示用户名称;
68、说明一下k8s中pod的几种状态及排障方法
pod的几种状态:
常用的排障命令:
k8s常见命令 :
命令 解释 示例 kubectl get 显示一个或更多 resources # 获取集群状态
kubectl get cs
# 获取集群服务器节点
kubectl get node
# 获取集群命名空间(ns=namespace)
kubectl get ns
# 获取prod命名空间(正式环境)下所有的pod
kubectl -n prod get pod
kubectl -n prod get pod -o wide 可以看到pod 的ip
# 获取持久化的配置字典
kubectl -n prod get configmaps
# 获取服务(svc=services)
kubectl -n prod get svc
# 获取部署
kubectl -n prod get deployment
# 获取定时任务
kubectl -n prod get cronjob
#获取任务
kubectl -n prod get job
kubectl delete 删除资源 #删除pod
kubectl -n prod delete pod eurban-mis-backend-xxx-xxx
#通过文件删除depolyment
kubectl delete -f /opt/kube/egova-web/prod/eurban-mis-backend/web-mis-deployment.yaml
kubectl edit 在服务器上编辑一个资源 #编辑gis的配置
kubectl -n prod edit configmaps eurban-gis-config
#编辑备份业务库的定时任务
kubectl -n prod edit cronjobs.batch job-backup-mysql-biz
kubectl describe 显示一个指定 resource 或者 group 的 resources 详情
一般用于看服务创建失败的原因(指调度失败,而非启动失败)
#查看mis后台的部署
kubectl -n prod describe deployment eurban-mis-backend
#查看mis后台pod的情况
kubectl -n prod describe pod eurban-mis-backend-xxxx
kubectl logs 输出容器在 pod 中的日志 #查看一个mis后台pod中tomcat容器的日志,追踪最后100行
kubectl -n prod logs -f eurban-mis-backend-5898f5496d-m9wl9 -c tomcat --tail 100
kubectl rollout/scale/autoscale/set 回滚/扩容/自动伸缩/更新服务镜像版本 这四个命令直接用更新工具箱即可,在熟悉的情况下可以直接使用kubectl kubectl top Display Resource (CPU/Memory/Storage) usage.
显示资源占用
# 查看物理机资源占用
kubectl top node
#查看prod正式环境的pod资源占用
kubectl -n prod top pod
kubectl exec 在一个 container 中执行一个命令 # 进入到一个mis后台的pod中
kubectl -n prod exec -it eurban-mis-backend-5898f5496d-m9wl9 bash
kubectl cp 复制 files 和 directories 到 containers 和从容器中复制 files 和 directories. #复制一个mis后台pod的jdbc到物理机
kubectl -n prod cp eurban-mis-backend-5898f5496d-m9wl9:/usr/local/tomcat/webapps/eUrbanMIS/WEB-INF/classes/jdbc.properties ./jdbc.properties
#复制物理机中的文件到pod
kubectl -n prod cp ./test.txt eurban-mis-backend-5898f5496d-m9wl9:/usr/local/tomcat/webapps/eUrbanMIS/WEB-INF/classes/test.txt
kubectl port-forward 临时转发某个pod的端口到物理机.
常用于单节点测试
#转发一个mis容器中的8080端口,到当前物理机的8099上
kubectl -n prod port-forward --address 0.0.0.0 eurban-mis-backend-5898f5496d-m9wl9 8099:8080
69、新增一块硬盘,在系统不重启的情况下,对这块硬盘进行分区、格式化和挂载
(1)linux硬盘分区、linux目录挂载的原理介绍:
https://blog.csdn.net/weixin_39620984/article/details/116676898
(2)linux新增硬盘,系统不重启识别新增硬盘的方法:
(3)linux硬盘分区(5GB的硬盘sdb要求分为:1个主分区2GB,1个扩展分区3GB,扩展分区再被细分为3个1GB的逻辑分区。)
(4)硬盘划分成功后,就要对分区进行格式化了
(5)硬盘完成分区和格式化后,需要进行挂载操作
70、介绍一下nginx反向代理
https://www.cnblogs.com/ysocean/p/9392908.html
98、介绍一下linux中awk命令的常见用法
awk 过滤命令
find 查找命令
xargs与-exec 常用的组合命令
corn linux系统的任务计划
rsync 远程同步、备份命令
99、linux系统的日常管理
【监控系统的状态】
1. w 查看当前系统的负载
2. vmstat 监控系统的状态
3. top 显示进程所占系统资源
4. sar 监控系统状态
5. free查看内存使用状况
6. ps 查看系统进程
7. netstat 查看网络状况
8. 抓包工具tcpdump
【linux网络相关】
1. ifconfig 查看网卡IP
2. 给一个网卡设定多个IP
3. 查看网卡连接状态mii-tool
4. 更改主机名,使用hostname
5. 设置DNS,配置文件就是/etc/resolv.conf
【linux的防火墙】
1. selinux是Redhat/CentOS系统特有的安全机制
2. iptables是linux上特有的防火墙机制,其功能非常强大
【linux系统的任务计划】
大部分系统管理工作都是通过定期自动执行某一个脚本来完成的,linux的cron功能了。
关于cron任务计划功能的操作都是通过crontab这个命令来完成的。
【linux的系统服务管理】
1. ntsysv
用来配置哪些服务开启或者关闭,有点想图形界面,不过是使用键盘来控制的
2. chkconfig
Linux系统所有的预设服务可以查看/etc/init.d/目录得到
【linux中的数据备份】
在linux上作为数据备份的工具很多,但笔者就只用一种那就是rsync 从字面上的意思你可以理解为remote sync
【linux系统日志】
笔者常查看的日志文件为/var/log/message. 它是核心系统日志文件
【xargs与-exec】
好用的组合命令,实现复杂需求。
【screen工具介绍】
当退出该终端时,不挂断地运行命令。
1.使用nohup
2.screen工具的使用
【linux下同步时间服务器】
ntpdate每隔6小时同步一次那么请指定一个计划任务。
00 */6 * * * /usr/sbin/ntpdate 210.72.145.44 >/dev/null
参考文档:
https://www.cnblogs.com/zhang-jun-jie/p/9266871.html
三、注意事项
总结面试注意几点事项,可能笔者也说得不太对,为了我们运维工作的兄弟们都能拿到高薪,大家一定要指证出来一起进步、一起探讨:
第一,你要对自己的简历很熟悉,简历上的写的技能自己一定要能说出个一二,因为面试官的很多问题都会挑你简历上写的问。比如你简历上写了这么一条技能“熟悉mysql数据库的部署安装及原理”。你即然写了这么一条技能,你在怎么不熟悉你也要了解mysql的原理,能说出个大概意思。万一面试官问到了你写的这一条,你都答不上来,那在他心里你又减分了,基本上这次面试希望不大。
第二,如果面试官问到你不会的问题,你就说这个不太熟悉,没有具体研究过,千万别不懂装懂,还扯一堆没用的话题来掩饰,这样只会让面试官反感你。
第三,准备充分,竟可能多的记住原理性的知识,一般面试问的多的就是原理。很少问具体的配置文件是怎么配置的。面试前也要了解清楚“职位描述”和“岗位要求”,虽然有时候大多数不会问到岗位要求的问题,但也要了解和熟悉。
第四,面试完后一定要总结,尽量记住面试官问的每一个问题,回去记录下来,如果问到不会的问题,事后要立马查百度或者找朋友搞清楚、弄明白,这样你才能记劳,下次面试说不定又问到同样的问题。
四、参考文档
https://www.jianshu.com/p/5e853a8936fb
https://www.jianshu.com/p/b1b7eaa0e160
https://blog.csdn.net/qq_44947614/article/details/106842668
https://zhuanlan.zhihu.com/p/148615267
(文章转自网络,如有侵权,请联系删除)

