
- 1Hadoop集成GooseFS遇到的问题及解决方法_org.apache.hadoop.fs.unsupportedfilesystemexceptio
- 2Kafka核心技术与实战 15 消费者组
- 3【2024最新】jetbrains全家桶解锁(PyCharm,IntelliJ IDEA,PhpStorm,RubyMine,WebStorm)一键激活永久使用_jetbrains 2024 最新全家桶激活
- 4《自然语言处理实战:利用Python理解、分析和生成文本》读书笔记:第4章 词频背后的语义_python 自然语言语义距离
- 5C++ 容器的排序算法_c++容器排序
- 6Go操作Kafka_go kafka
- 7[玩转AIGC]LLaMA2之如何微调模型_llama2微调
- 8产品经理和项目经理区别与联系_项目经理与产品经理的区别
- 9Verilog实现二进制乘除法器_verilog二进制乘法器
- 10SpringBoot中实现发送邮件
一些可以参考的文档集合9_xuejianxinokok. 掘金
赞
踩
之前的文章集合:
一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客
一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合5_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合6_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合7_xuejianxinokok的博客-CSDN博客
一些可以参考的文档集合8_xuejianxinokok的博客-CSDN博客
20221116
打印类的布局信息 org.openjdk.jol.info.ClassLayout

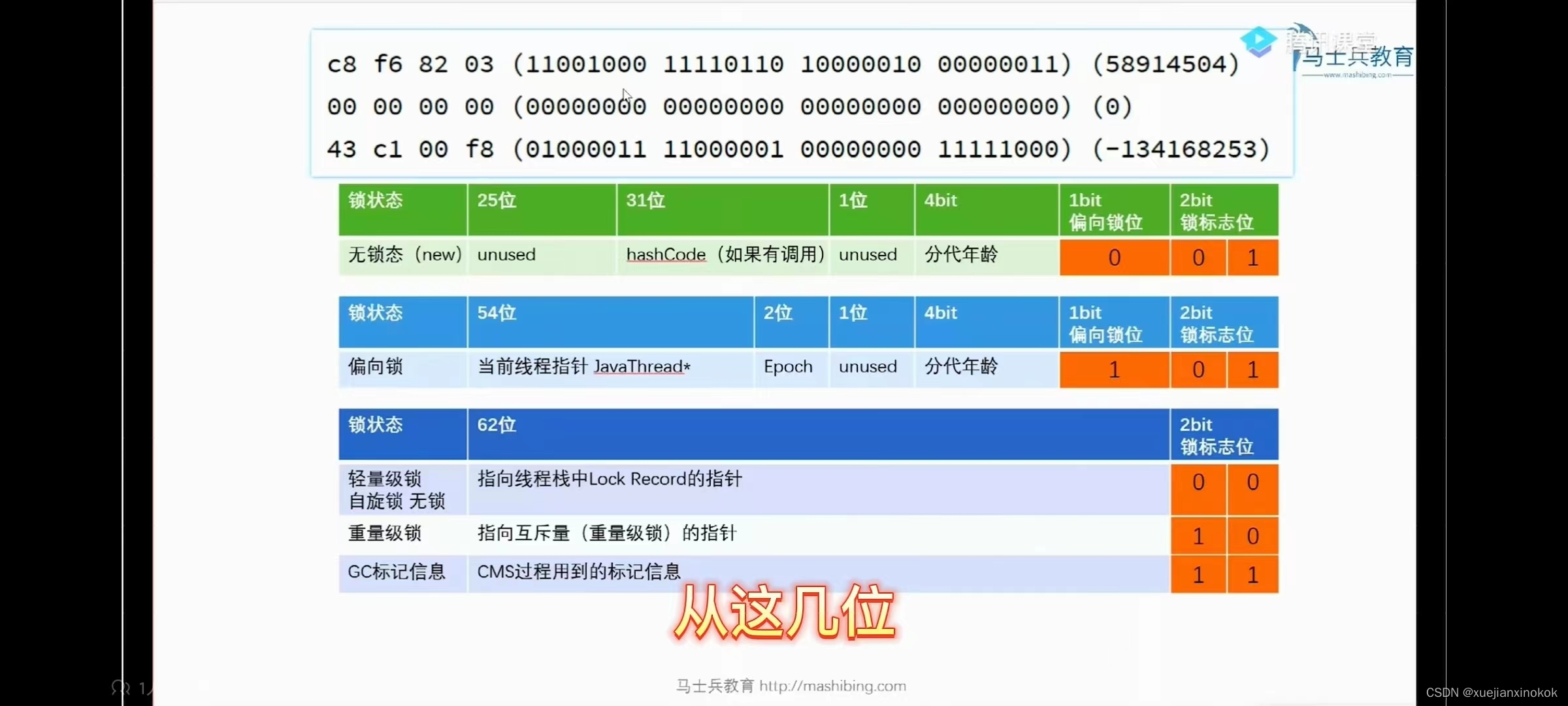
为什么要有双亲委派机制?
两个原因: 1. 沙箱安全机制, 自己写的java.lang.String.class类不会被加载, 这样便可以防止核心API库被随意修改 2. 避免类重复加载. 比如之前说的, 在AppClassLoader里面有java/jre/lib包下的类, 他会加载么? 不会, 他会让上面的类加载器加载, 当上面的类加载器加载以后, 就直接返回了, 避免了重复加载.
全盘委托机制。比如Math类,里面有定义了private User user;那么user也会由AppClassLoader来加载。除非手动指定使用其他类加载器加载。也就是说,类里面调用的其他的类都会委托当前的类加载器加载。
tomcat为何要打破双亲委派机制?
通常,我们在服务器安装的一个tomcat下会部署多个应用。而这多个应用可能使用的类库的版本是不同的。比如:项目A使用的是spring4,项目B使用的是Spring5。Spring4和Spring5多数类都是一样的,但是有个别类有所不同,这些不同是类的内容不同,而类名,包名都是一样的。假如,我们采用jdk向上委托的方式,项目A在部署的时候,应用类加载器加载了他的类。在部署项目B的时候,由于类名相同,这是应用服务器就不会再次加载同包同名的类。这样就会有问题。所以, tomcat需要打破双亲委派机制。不同的war包下的类自己加载,而不向上委托。基础类依然向上委托。
2.双亲委派机制详细解析及原理 - 山河永慕~ - 博客园写在前面的话:为什么要研究类加载的过程?为什么要研究双亲委派机制? 研究类加载的过程就是要知道类加载的时候使用了双亲委派机制。但仅仅知道双亲委派机制不是目的,目的是要了解为什么要使用双亲委派机制,他的 https://www.cnblogs.com/shanheyongmu/p/15932606.html3.代码实现自定义类加载器 - 山河永慕~ - 博客园手把手叫你写类加载器。 了解了类加载器的双亲委派机制, 也知道了双亲委派机制的原理,接下来就是检验我们学习是否扎实了,来自定义一个类加载器 一. 回顾类加载器的原理 还是这张图,类加载器的入口是c++https://www.cnblogs.com/shanheyongmu/p/15935320.html4.自定义类加载器实现及在tomcat中的应用 - 山河永慕~ - 博客园了解了类加载器的双亲委派机制, 也知道了双亲委派机制的原理,接下来就是检验我们学习是否扎实了,来自定义一个类加载器 一. 回顾类加载器的原理 还是这张图,类加载器的入口是c++调用java代码创建了Jhttps://www.cnblogs.com/shanheyongmu/p/15936397.html
https://www.cnblogs.com/shanheyongmu/p/15932606.html3.代码实现自定义类加载器 - 山河永慕~ - 博客园手把手叫你写类加载器。 了解了类加载器的双亲委派机制, 也知道了双亲委派机制的原理,接下来就是检验我们学习是否扎实了,来自定义一个类加载器 一. 回顾类加载器的原理 还是这张图,类加载器的入口是c++https://www.cnblogs.com/shanheyongmu/p/15935320.html4.自定义类加载器实现及在tomcat中的应用 - 山河永慕~ - 博客园了解了类加载器的双亲委派机制, 也知道了双亲委派机制的原理,接下来就是检验我们学习是否扎实了,来自定义一个类加载器 一. 回顾类加载器的原理 还是这张图,类加载器的入口是c++调用java代码创建了Jhttps://www.cnblogs.com/shanheyongmu/p/15936397.html
20221114
H5移动端调试攻略超实用~https://mp.weixin.qq.com/s/OMp-Hj9lLdP8JChI7GRxow

可以看到打包产物是一个立即执行函数,函数初始先定义了多个 module,每个 module 是实际代码中被 require 的文件内容,同时由于浏览器不支持 require 方法,webpack 内部自行实现了一个 __webpack__require__,并将代码中的 require 全部替换为该函数(从打包结果可看出)。
在 webpack__require 定义之后,便开始执行入口文件,同时可以看出,webpack 的打包过程便是通过入口文件,将直接依赖和间接依赖以 module 的形式组织到一起,并通过自行实现的 require 实现模块的同步加载。
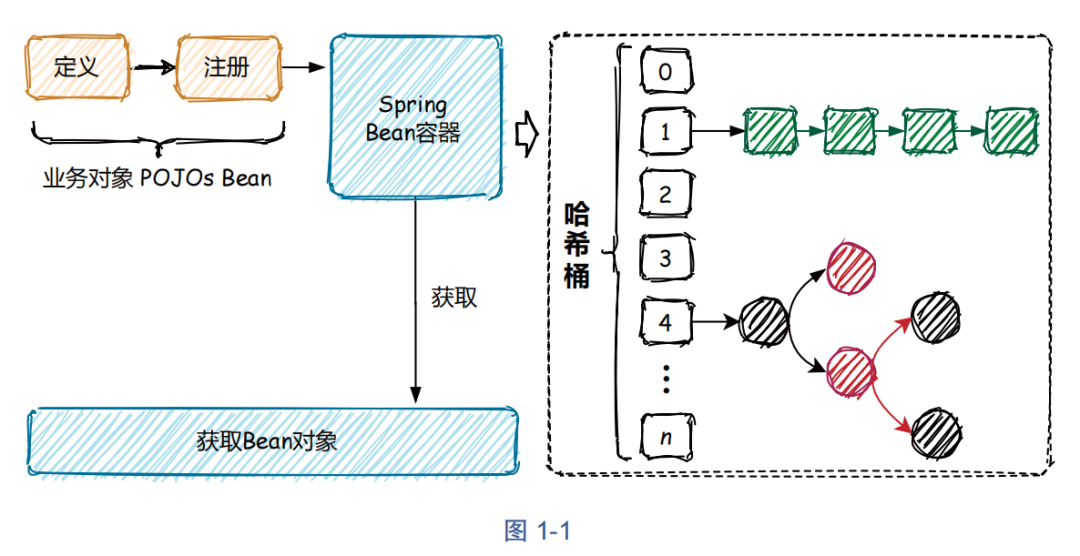
实现一个简单的 Spring Bean 容器https://mp.weixin.qq.com/s/5skPbAcx8tsWFVpUE-aerg
20221109
数据库与普通文件系统的一个重要的区别就是;数据库可以在多种故障下仍然可以正确运行,保证系统以及数据的正确性;这些故障包括但不限于数据库系统本身故障,操作系统故障,以及存储介质故障等。那么数据库是如何在这些故障下面还能保证系统和数据的正确性的呢?主要靠Redo Log和Undo Log日志与WAL(Write Ahead Log)机制的配合来支持,其理论支持在论文《ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging》中介绍的非常详细。
该论文主要介绍通过Logging的方式来记录数据库最新的修改,在故障恢复时通过Log的内容将数据库恢复到正确的状态。那么为了保证恢复中可以看到数据库最新的状态,就要求Log先于数据落盘,这就是WAL的概念;其中记录了数据库最新数据内容的Log称之为Redo Log;但是为了方便事务回滚,数据库在修改数据时也必须记录数据的旧值,这就是Undo Log。正因为有了Redo Log,对于已经提交的事务的数据一定存在于磁盘,所以保证了数据库系统的持久性;而有了Undo Log,数据库可以保证在故障恢复时对没有完成的事务进行回滚,也就保证的事务的原子性。
与此相对的,如果数据库系统只记录Undo Log不记录Redo Log,那么事务在commit之前必须保证数据已经落盘,这样才能完成数据持久化;如果只记录Redo Log不记录Undo Log,那么在事务提交之前数据不能落盘,这样在故障恢复时就不会出现还未提交的事务,保证了事务的原子性。显然,这两种方案在具体实现时都有较大的瓶颈。
Undo log 的两大作用
-
事务回滚:数据回滚操作(事务的原子性实现),在事务执行过程中,如果出现错误或需要回滚操作,Undo log 可以恢复事务执行之前的数据状态,实现事务的回滚操作。
-
并发控制:实现 MVCC 多版本并发控制,通过 Undo log 可以实现数据库并发事务的隔离性和一致性,避免数据读取和写入的冲突。

MySQL · UNDO LOG的演进与现状数据库内核月报, 来着阿里云 PolarDB 数据库内核团队。![]() http://mysql.taobao.org/monthly/2022/10/02/在MySQL 5.7,Online DDL在性能和稳定性上不断得到优化,比如通过bulk load方式来去除表重建时的redo日志等。到了MySQL 8.0,Online DDL已经支持秒级加列特性,该特性来源于国内的腾讯互娱DBA团队。
http://mysql.taobao.org/monthly/2022/10/02/在MySQL 5.7,Online DDL在性能和稳定性上不断得到优化,比如通过bulk load方式来去除表重建时的redo日志等。到了MySQL 8.0,Online DDL已经支持秒级加列特性,该特性来源于国内的腾讯互娱DBA团队。
20221108

org.springframework.context.ApplicationContextInitializer
这是整个spring容器在刷新之前初始化ConfigurableApplicationContext的回调接口,简单来说,就是在容器刷新之前调用此类的initialize方法。这个点允许被用户自己扩展。用户可以在整个spring容器还没被初始化之前做一些事情。
可以想到的场景可能为,在最开始激活一些配置,或者利用这时候class还没被类加载器加载的时机,进行动态字节码注入等操作。
- @SpringBootApplication
- public class SpringbootApplication {
-
- public static void main(String[] args) {
- // SpringApplication.run(SpringbootApplication.class, args);
- SpringApplication springApplication = new SpringApplication(SpringbootApplication.class);
- springApplication.addInitializers(new SecondInitializer());
- springApplication.run();
- }
-
- }
20221104
卡曼滤波器

网页爬虫
Crawlee · Build reliable crawlers. Fast. | Crawlee
20221113
文章在介绍Transformer的架构时,是自顶向下介绍的。但是,一开始我们并不了解Transformer的各个模块,理解整体框架时会有不少的阻碍。因此,我们可以自底向上地来学习Transformer架构。
首先,跳到3.2节,这一节介绍了Transformer里最核心的机制——注意力。在阅读这部分的文字之前,我们先抽象地理解一下注意力机制究竟是在做什么。
注意力计算的一个例子
其实,“注意力”这个名字取得非常不易于理解。这个机制应该叫做“全局信息查询”。做一次“注意力”计算,其实就跟去数据库了做了一次查询一样。假设,我们现在有这样一个以人名为key(键),以年龄为value(值)的数据库:
- {
- 张三: 18,
- 张三: 20,
- 李四: 22,
- 张伟: 19
- }
现在,我们有一个query(查询),问所有叫“张三”的人的年龄平均值是多少。让我们写程序的话,我们会把字符串“张三”和所有key做比较,找出所有“张三”的value,把这些年龄值相加,取一个平均数。这个平均数是(18+20)/2=19。
但是,很多时候,我们的查询并不是那么明确。比如,我们可能想查询一下所有姓张的人的年龄平均值。这次,我们不是去比较key == 张三,而是比较key[0] == 张。这个平均数应该是(18+20+19)/3=19。
或许,我们的查询会更模糊一点,模糊到无法用简单的判断语句来完成。因此,最通用的方法是,把query和key各建模成一个向量。之后,对query和key之间算一个相似度(比如向量内积),以这个相似度为权重,算value的加权和。这样,不管多么抽象的查询,我们都可以把query, key建模成向量,用向量相似度代替查询的判断语句,用加权和代替直接取值再求平均值。“注意力”,其实指的就是这里的权重。
把这种新方法套入刚刚那个例子里。我们先把所有key建模成向量,可能可以得到这样的一个新数据库:
- {
- [1, 2, 0]: 18, # 张三
- [1, 2, 0]: 20, # 张三
- [0, 0, 2]: 22, # 李四
- [1, 4, 0]: 19 # 张伟
- }
假设key[0]==1表示姓张。我们的查询“所有姓张的人的年龄平均值”就可以表示成向量[1, 0, 0]。用这个query和所有key算出的权重是:
- dot([1, 0, 0], [1, 2, 0]) = 1
- dot([1, 0, 0], [1, 2, 0]) = 1
- dot([1, 0, 0], [0, 0, 2]) = 0
- dot([1, 0, 0], [1, 4, 0]) = 1
之后,我们该用这些权重算平均值了。注意,算平均值时,权重的和应该是1。因此,我们可以用softmax把这些权重归一化一下,再算value的加权和。
- softmax([1, 1, 0, 1]) = [1/3, 1/3, 0, 1/3]
- dot([1/3, 1/3, 0, 1/3], [18, 20, 22, 19]) = 19
这样,我们就用向量运算代替了判断语句,完成了数据库的全局信息查询。那三个1/3,就是query对每个key的注意力。
Attention Is All You Need (Transformer) 论文精读在这篇文章里,我将先补充背景知识,再清晰地解读一下Attention Is All You Need 这篇论文。https://mp.weixin.qq.com/s/sU2uK2kQVJxzXeVNTmvfYg【深度学习】各种各样神奇的自注意力机制(Self-attention)变形自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。
https://mp.weixin.qq.com/s/7xsvdrORq3y50Qgr1Dku5w
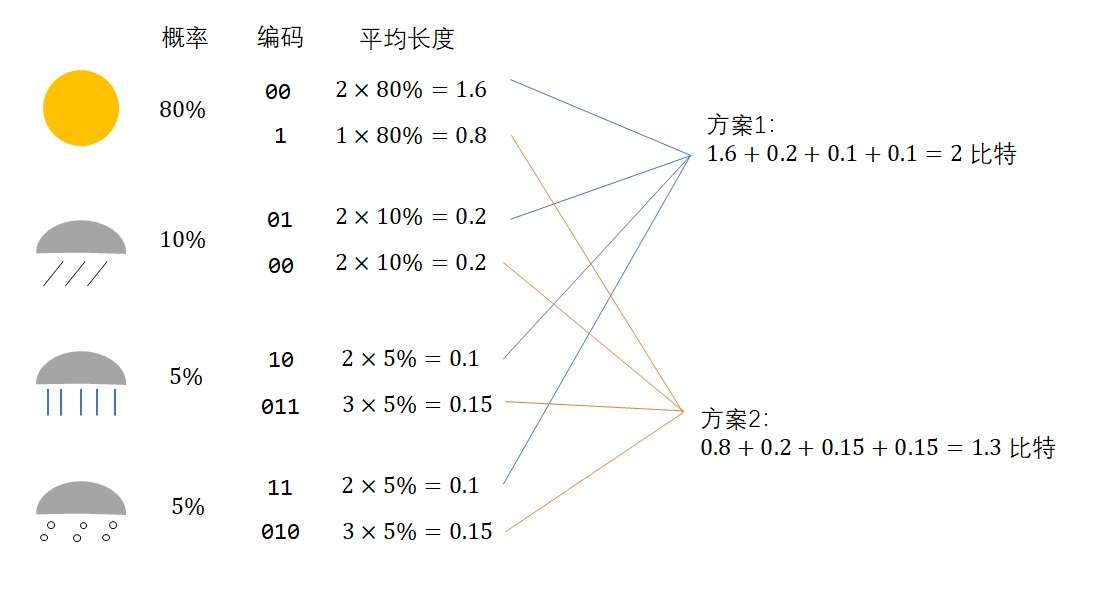
刚刚我们也看到了,1个二进制数表示2种情况,2个二进制数表示4种情况。现在有4种情况,只要两位编码就行了:

因此,这个问题的熵是2。
但有人可能对这种编码方式感到不满:“这种编码太乱了,每个二进制位都没有意义。我有一种更好的编码方式。”
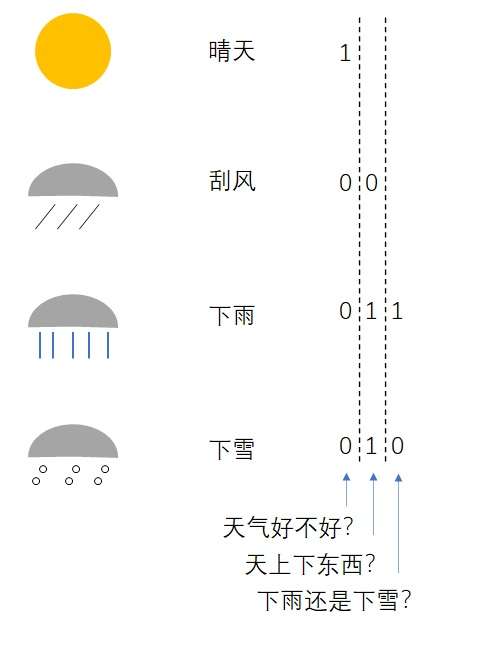
确实如此。要表示四种情况,不是非得用2位的编码,而可以用1-3位的编码分别表示不同的信息。可是,这两种方案哪个更节省一些呢?我们不能轻易做出判断。假如大部分时候都是晴天,那么用第二种方案的话很多时候只需要1位编码就行了;而假如大部分时候都是下雨或下雪,则用第一种方案会更好一些。为了判断哪种方案更好,我们还缺了一个重要的信息——每种天气的出现概率。
假如我们知道了每种天气的出现概率,就可以算出某种编码的平均编码长度,进而选择一种更优的编码。让我们看一个例子。假设四种天气的出现概率是80%/10%/5%/5%,则两种编码的平均长度为:
20221102
什么是timm库?
PyTorch Image Models (timm)是一个图像模型(models)、层(layers)、实用程序(utilities)、优化器(optimizers)、调度器(schedulers)、数据加载/增强(data-loaders / augmentations)和参考训练/验证脚本(reference training / validation scripts)的集合,目的是将各种SOTA模型组合在一起,从而能够重现ImageNet的训练结果。
这里列出一下他们目前提供的模型(截至到2021/03):
Big Transfer ResNetV2 (BiT)
Cross-Stage Partial Networks
DenseNet
DLA
Dual-Path Networks
GPU-Efficient Networks
HRNet
Inception-V3
Inception-V4
Inception-ResNet-V2
NASNet-A
PNasNet-5
EfficientNet
MobileNet-V3
RegNet
RepVGG
ResNet, ResNeXt
Res2Net
ResNeSt
ReXNet
Selective-Kernel Networks
SelecSLS
Squeeze-and-Excitation Networks
TResNet
VGG
Vision Transformer vit
VovNet V2 and V1
Xception
Xception (Modified Aligned, Gluon)
Xception (Modified Aligned, TF)
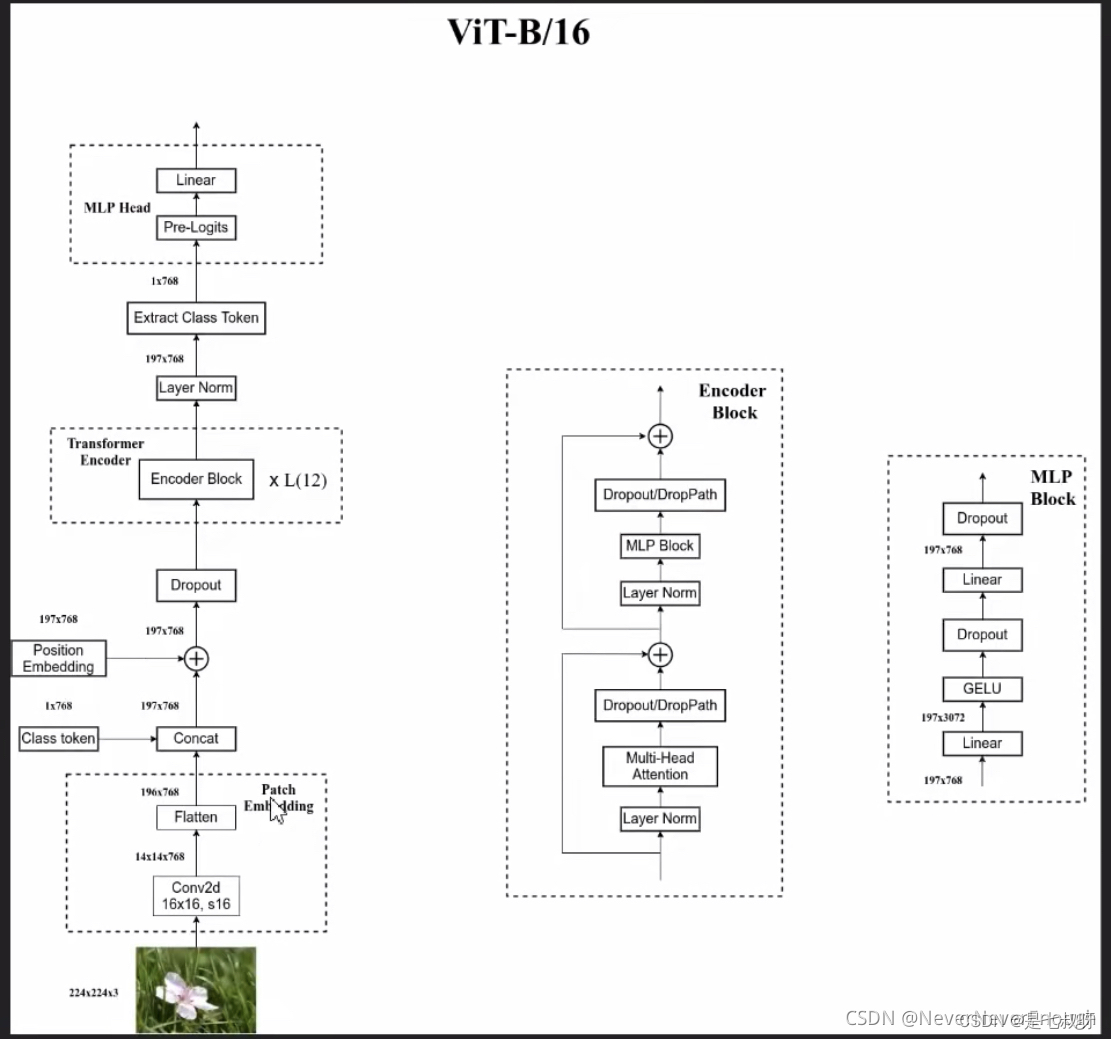
ViT的输入部分
3.1、图片切分为Token
输入x = [bs,3,224,224]
比如一张224x224x3的图片,切分为16x16个token,每个token是14x14大小,得到16x16x3=768个token。
3.2、Token转换为Token Embedding
将一个16x16x3=768个Token拉直,拉到一个1维,长度为768的向量 -> [bs,196,768];
196=14*14
接一个Linear层,把768映射到Transormer Encode规定的Embedding Size(1024)的长度 -> [bs,196,1024];
3.3、Token Embedding和Position Embedding对应位置相加
生成一个Cls对应的Token Embedding(对应图中的*部分) -> [bs,1,1024];
生成所有序列的位置编码(包括Cls符号和和所有Token Embeding的位置编码 对应图中的0-9) -> [bs,197,1024];
将Token Embedding和Position Embedding对应位置相加 -> [bs,197,1024];
问题1:为什么要加一个Cls的符号呢?
Cls是在Bert中的用到的一个符号,NLP任务中的Cls可以在一定程度上让bert的两个任务保持一定的独立性,而在ViT中只有一个多分类任务,所以Cls符号并不是必须的;
而论文作者也做了实验证明了这点,在ViT的任务中,加Cls和不加Cls训练效果是差不多的,所以我认为可以不用;
问题2:为什么需要位置编码?
RNN在计算的时候是一个个的运算,具有一种天然时序关系,可以告诉模型哪些单词在前面,哪些单词在后面;但是在Transformer中它的单词是一起输入进去的,然后经过Attention层,那么如果没用位置编码,模型并不知道哪些单词在前面哪些单词在后面。
所以,我们需要给模型一个位置信息,告诉模型,哪些词/哪个token在前面,哪些词/token在后面。
问题3:为什么Token Embedding和Position Embedding是相加的?可不可以Concat?
这个问题好像没用什么很好的答案,Concat会让计算量翻倍?
从论文的实验结果可以发现,加入位置编码可以加3个点左右。位置编码是有用的。
论文中要让Patching Embedding和位置编码pos相加的原因应该是强迫后面的线性层学到这个时序关系,而直接concat会削弱这种能力。假如输入的embedding是x,concat后送入linear层输出就是y=【W,Wp】^T【X,pos】=【W^T*X,Wp^T*pos】,因为位置编码pos是一个很强的周期信息,本身不随输入内容的变化而变化,所以网络会倾向于将Wp优化成0,也就是忽略这部分信息。而如果是相加的话,y=W(X+pos),会强迫网络学习到这个位置信息
四、Encoder部分
Encoder 输入:[bs,197,1024]
Transformer和ViT中的Encoder部分的区别:
把Norm层提前了;
没用Pad符号;
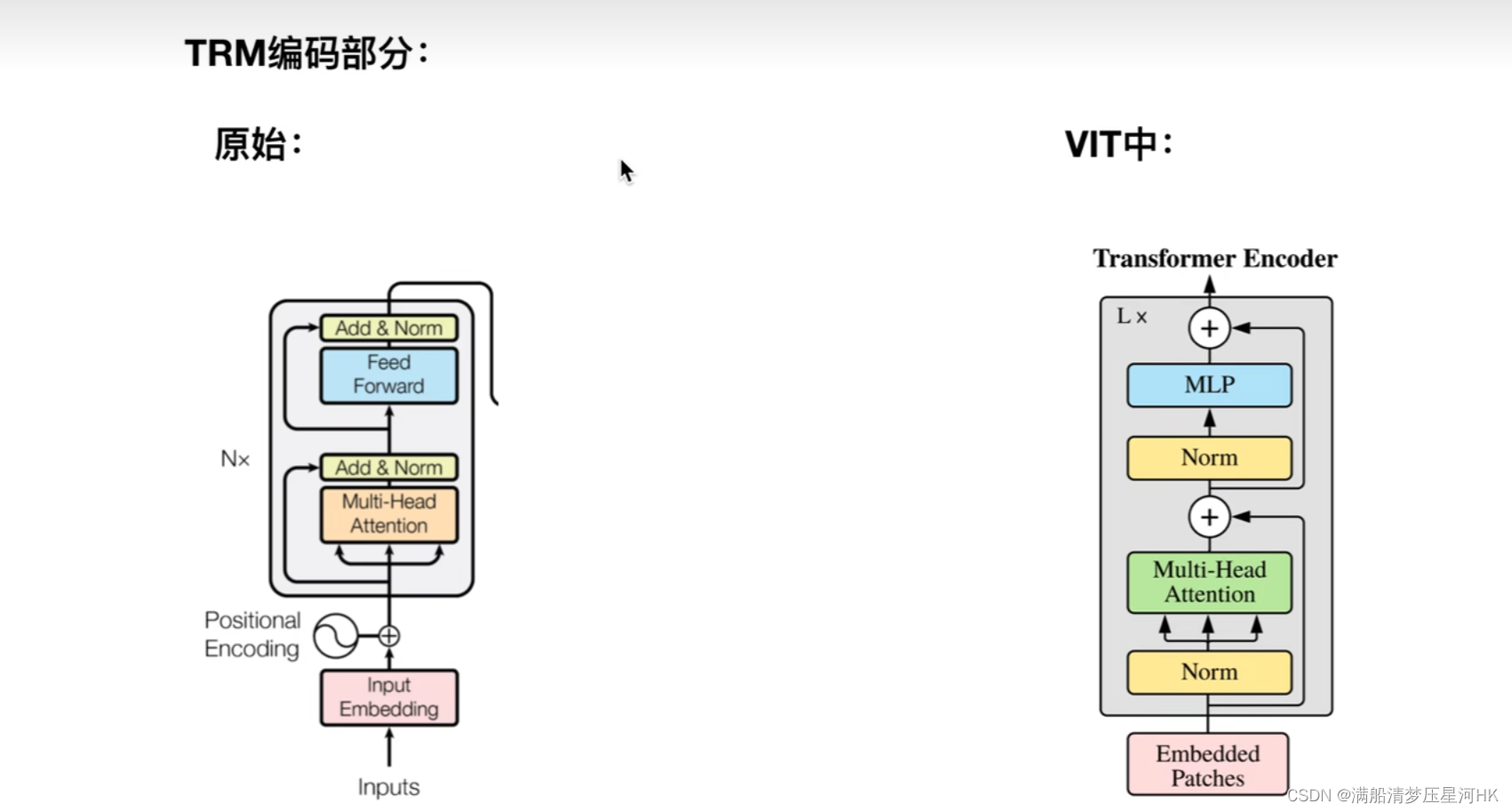
Encoder 输出:[bs,197,1024]
五、CLS多分类输出
最终得到每一个token都会得到一个1024的输出,再把第一个1024的向量拿出来,接一个全连接层进行多分类。
[bs,197,1024] -> 拿第一个[bs,1024] -> [bs,num_classes]
下表是论文用来对比ViT,Resnet(和刚刚讲的一样,使用的卷积层和Norm层都进行了修改)以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。
20221101
20221026
Node.js 中的关注点分离 项目最佳实践
 https://www.infoq.com/articles/separation-concerns-nodejs/
https://www.infoq.com/articles/separation-concerns-nodejs/20221025
矛盾的普遍性和特殊性
世界上大多数事物的发展规律是相似的,在最开始往往都会出现相对通用的方案解决绝大多数的问题,随后会出现为某一场景专门设计的解决方案,这些解决方案不能解决通用的问题,但是在某些具体的领域会有极其出色的表现。而在计算领域中,CPU(Central Processing Unit)和 GPU(Graphics Processing Unit)分别是通用的和特定的方案,前者可以提供最基本的计算能力解决几乎所有问题,而后者在图形计算和机器学习等领域内表现优异。
大多数的 CPU 不仅期望在尽可能短的时间内更快地完成任务以降低系统的延迟,还需要在不同任务之间快速切换保证实时性,正是因为这样的需求,CPU 往往都会串行地执行任务。GPU 的设计与 CPU 完全不同,它期望提高系统的吞吐量,在同一时间竭尽全力处理更多的任务,而设计理念上的差异最终反映到了 CPU 和 GPU 的核心数量上

在测量 GPU 性能之前,我需要线测试 CPU 的基准性能。
为了给让芯片满载和延长运行时间,我增加了in_row、in_f、out_f个数,也设置了循环操作10000次。
复制
- import torch
- import torch.nn
- import timein_row, in_f, out_f = 256, 1024, 2048
- loop_times = 10000
现在,让我们看看CPU完成10000个转换需要多少秒:
复制
- s = time.time()
- tensor = torch.randn(in_row, in_f).to('cpu')
- l_trans = torch.nn.Linear(in_f, out_f).to('cpu')
- for _ in range(loop_times):
-
- print('cpu take time:',time.time()-s)
-
- #cpu take time: 55.70971965789795
可以看到cpu花费55秒。
GPU计算
为了让GPU的CUDA执行相同的计算,我只需将. To (' cpu ')替换为. cuda()。另外,考虑到CUDA中的操作是异步的,我们还需要添加一个同步语句,以确保在所有CUDA任务完成后打印使用的时间。
复制
- s = time.time()
- tensor = torch.randn(in_row, in_f).cuda()
- l_trans = torch.nn.Linear(in_f, out_f).cuda()
- for _ in range(loop_times):
-
-
- torch.cuda.synchronize()
- print('CUDA take time:',time.time()-s)
-
- #CUDA take time: 1.327127456665039
并行运算只用了1.3秒,几乎是CPU运行速度的42倍。这就是为什么一个在CPU上需要几天训练的模型现在在GPU上只需要几个小时。因为并行的简单计算式GPU的强项
如何使用Tensor Cores
CUDA已经很快了,那么如何启用RTX 3070Ti的197Tensor Cores?,启用后是否会更快呢?在PyTorch中我们需要做的是减少浮点精度从FP32到FP16。,也就是我们说的半精度或者叫混合精度
复制
- s = time.time()
- tensor = torch.randn(in_row, in_f).cuda().half()
- layer = torch.nn.Linear(in_f, out_f).cuda().half()
- for _ in range(loop_times):
-
- torch.cuda.synchronize()
- print('CUDA with tensor cores take time:',time.time()-s)
-
- #CUDA with tensor cores take time:0.5381264686584473
又是2.6倍的提升。
总结
在本文中,通过在CPU、GPU CUDA和GPU CUDA +Tensor Cores中调用PyTorch线性转换函数来比较线性转换操作。下面是一个总结的结果:

NVIDIA的CUDA和Tensor Cores确实大大提高了矩阵乘法的性能。
20221024
我们要使用OpenCV那么可以先从OpenCV提供的编译后的SDK入手。(等什么时候水平提高了,可以自己编译改源码)
先从OpenCV下载最新releases版本:https://github.com/opencv/opencv/releases
-
opencv-4.6.0-android-sdk.zip
225 MB07 Jun 2022
将下载包的压缩包解压,将会得到两个文件夹 samples 和 sdk。
-
samples:主要就是官方提供的一些Demo,让我们了解相关API的用法。
-
sdk:openCV的一些API接口和文档等库。
我们将sdk 整体导入到项目中来,作为一个library进行依赖就可以了。导入就可以使用了
关于SDK里面的目录和结构,可以通过这篇文章了解:https://zinyan.com/?p=344
在需要依赖的模块的build.gradle文件中添加 implementation project(':opencv') 就可以了。
3. Android 使用OpenCV
当我们依赖完毕后,就可以开始使用了。
第一步:都是调用System.loadLibrary("opencv_java4");方法进行动态库初始化。
OpenCV提供了两种方法进行初始化。我们可以根据需求进行处理.
将下面的代码,放在Activity中进行执行:
private BaseLoaderCallback mLoaderCallback = new BaseLoaderCallback(this) {
@Override
public void onManagerConnected(int status) {
switch (status) {
case LoaderCallbackInterface.SUCCESS: {
// Log.i(TAG, "OpenCV loaded successfully");
// mOpenCvCameraView.enableView();
}
break;
default: {
super.onManagerConnected(status);
}
break;
}
}
};
@Override
public void onResume() {
super.onResume();
if (!OpenCVLoader.initDebug()) {
// Log.d(TAG, "Internal OpenCV library not found. Using OpenCV Manager for initialization");
OpenCVLoader.initAsync(OpenCVLoader.OPENCV_VERSION_3_0_0, this, mLoaderCallback);
} else {
// Log.d(TAG, "OpenCV library found inside package. Using it!");
mLoaderCallback.onManagerConnected(LoaderCallbackInterface.SUCCESS);
}
}
但是有一个问题,就是如果我们在onCreate方法中调用了OpenCV的API就会出现崩溃,因为上面的实例是在onResume方法后才会初始化加载OpenCV动态库。
可以采用第二种初始化方法:在Appcation或者Activity的onCreate()方法中初始化即可。
new OpenCVNativeLoader().init();
第二步:OpenCV初始化后,我们通过CameraX获取的数据交给OpenCV进行处理即可。
给CameraProvider添加一个AnalysisUseCase处理,分析得到的ImageProxy对象。实例:(在这里省略了CameraX的初始化和权限,大家结合自己的代码进行配置哦)
ImageAnalysis.Builder builder = new ImageAnalysis.Builder();
analysisUseCase = builder.build();
analysisUseCase.setAnalyzer(
// 图像处理器。processImageProxy将使用另一个线程来运行下面的检测,
//因此,我们可以在主线程上运行分析器本身。
ContextCompat.getMainExecutor(this),
imageProxy -> {
//1. 将imageProxy转为 Mat
//2. openCV 处理Mat
//3. 将Mat 转为Bitmap ,输出到ImageView进行显示该Bitmap
//4. 关闭imageProxy对象
});
cameraProvider.bindToLifecycle(/* lifecycleOwner= */ this, cameraSelector, analysisUseCase);
按照上面注释的四个步骤,进行处理就能得到处理后的效果并显示了。下面分步骤介绍。
20221019
datasource-proxy-spring-boot-starter 为我们提供了一个DataSourceProxyProperties 来配置DataSourceProxy ,我们可以通过application.yaml 来配置。如:
复制
- # 设置日志库,默认为slf4j(slf4j, jul, common, sysout)
- decorator.datasource.datasource-proxy.logging: slf4j
-
- # 开启所有的查询到日志,默认为true
- decorator.datasource.datasource-proxy.query.enable-logging: true
- decorator.datasource.datasource-proxy.query.log-level: debug
- # 日志名称设置
- decorator.datasource.datasource-proxy.query.logger-name:
-
- # 设置慢SQL的情况,慢SQL的日志级别是WARN
- decorator.datasource.datasource-proxy.slow-query.enable-logging: true
- decorator.datasource.datasource-proxy.slow-query.log-level: warn
- decorator.datasource.datasource-proxy.slow-query.logger-name:
- # 设置被认为是慢sql的时间并用日志记录下来
- decorator.datasource.datasource-proxy.slow-query.threshold: 300
-
- decorator.datasource.datasource-proxy.multiline: true
- decorator.datasource.datasource-proxy.json-format: false
- # 开启查询指标
- decorator.datasource.datasource-proxy.count-query: false

20221018
HTTP 的 Keep-Alive,是由应用层(用户态) 实现的,称为 HTTP 长连接;
TCP 的 Keepalive,是由 TCP 层(内核态) 实现的,称为 TCP 保活机制;
开启Keep-Alive的优缺点:
优点:Keep-Alive模式更加高效,因为避免了连接建立和释放的开销。
缺点:长时间的Tcp连接容易导致系统资源无效占用,浪费系统资源。
当保持长连接时,如何判断一次请求已经完成?
Content-Length
Content-Length表示实体内容的长度。浏览器通过这个字段来判断当前请求的数据是否已经全部接收。
所以,当浏览器请求的是一个静态资源时,即服务器能明确知道返回内容的长度时,可以设置Content-Length来控制请求的结束。但当服务器并不知道请求结果的长度时,如一个动态的页面或者数据,Content-Length就无法解决上面的问题,这个时候就需要用到Transfer-Encoding字段。
Transfer-Encoding
Transfer-Encoding是指传输编码,在上面的问题中,当服务端无法知道实体内容的长度时,就可以通过指定Transfer-Encoding: chunked来告知浏览器当前的编码是将数据分成一块一块传递的。当然, 还可以指定Transfer-Encoding: gzip, chunked表明实体内容不仅是gzip压缩的,还是分块传递的。最后,当浏览器接收到一个长度为0的chunked时, 知道当前请求内容已全部接收。
Keep-Alive_timeout
Httpd守护进程,一般都提供了keep-alive timeout时间设置参数。比如nginx的keepalive_timeout,和Apache的KeepAliveTimeout。这个keepalive_timout时间值意味着:一个http产生的tcp连接在传送完最后一个响应后,还需要hold住keepalive_timeout秒后,才开始关闭这个连接。
当httpd守护进程发送完一个响应后,理应马上主动关闭相应的tcp连接,设置 keepalive_timeout后,httpd守护进程会想说:”再等等吧,看看浏览器还有没有请求过来”,这一等,便是keepalive_timeout时间。如果守护进程在这个等待的时间里,一直没有收到浏览器发过来http请求,则关闭这个http连接。
20221013
Redo Log 是 MySQL InnoDB 引擎中的 WAL,所有的数据修改都需要通过 Redo Log 进行保护,当 MySQL 发生异常重启时,需要通过 Redo Log 来恢复数据,这也是 MySQL 数据库实现 ACID 中 D(durability) 的基本保障。长期以来,MySQL InnoDB 中的 Redo Log 采用了循环覆盖写的结构,以社区默认配置为例,MySQL 在启动时会默认创建两个日志文件:ib_logfile0 和 ib_logfile1,两个日志文件会进行交替的写入,通过 checkpoint 机制来保证写入的安全性。
MySQL 提供了两个参数 innodb_log_files_in_group 和 innodb_log_file_size 分别控制日志文件的个数和单个日志文件的大小,但是不支持动态的进行修改,这也是 MySQL 一直比较欠缺的能力。一个线上的典型场景是:大量的写入操作造成系统 IO 压力很大,Redo Log 写满触发同步刷脏,导致数据库写入跌 0。
MySQL 在最新的 8.0.30 小版本中对 Redo Log 进行了重构,引入了一个新的参数 innodb_redo_log_capacity ,这个参数定义了 Redo Log 的总量,支持动态调整。当设置了 innodb_redo_log_capacity 时,innodb_log_files_in_group 和 innodb_log_file_size 会被自动忽略。本文主要从使用和源码两个角度对这一特性进行介绍。
1. 在新引入的 #innodb_redo 的目录下,为什么会有多个文件,并且命名还不一样?
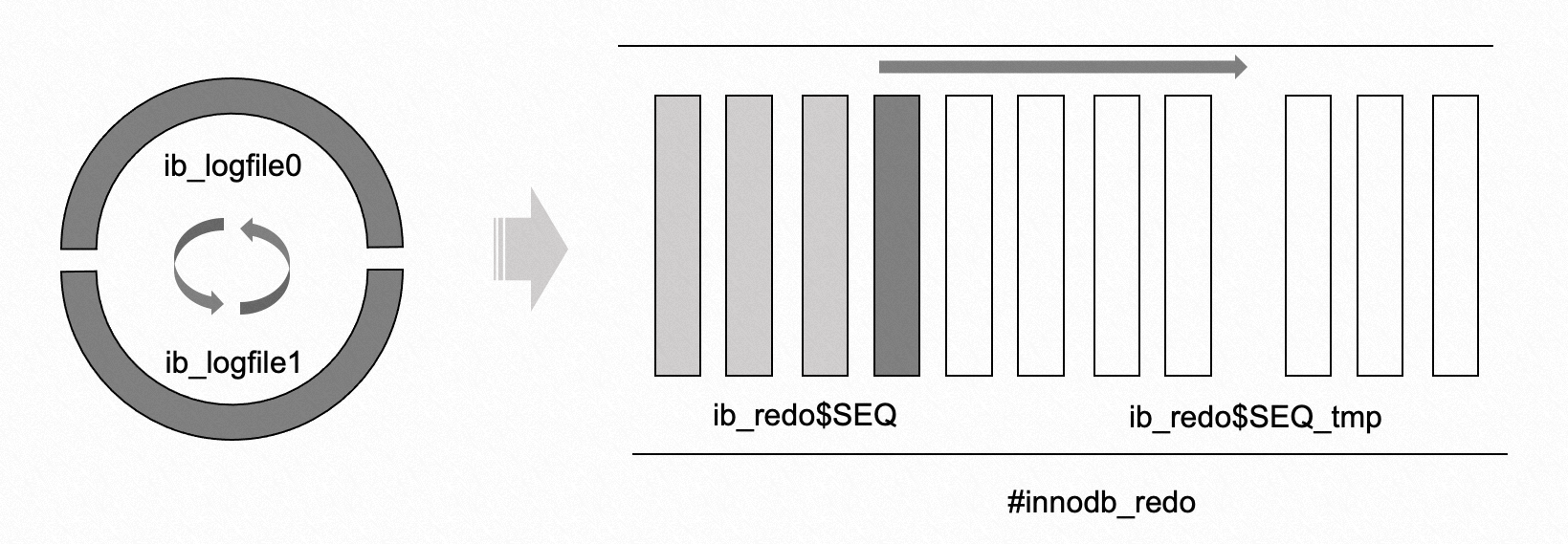
如图所示,8.0.30 版本对原来的循环覆盖写的结构进行了改造,不再以 redo 文件个数和单个 redo 文件的大小来进行限制,而是通过 innodb_redo_log_capacity 来指定整个 redo 空间的大小。整个 redo 空间会被切成 32 个文件(固定个数),文件按照 ib_redo$SEQ 的方式进行编号,$SEQ 是一个递增的序列号。在文件管理上,所有的文件会被分成两类:
- normal redo 文件,命名为 ib_redo$SEQ,正常的 redo 文件,和以前一样,任意时刻只会有一个 redo 文件进行写入;
- unused redo 文件,命名为 ib_redo$SEQ_tmp,未被使用的 redo 文件在被使用时,会被重命名为正常文件;
后台的 log_files_governor 线程会负责处理已经写完成的文件,在满足回收条件时,会重新变成 unused redo 文件。
2. InnoDB 是如何实现 innodb_redo_log_capacity 的动态修改的?
当 innodb_redo_log_capacity 发生变化时,已经使用过的和正在使用过的 redo 文件并不会发生改变,仅需要调整 unused redo 文件。结合前面的代码,当用户修改 innodb_redo_log_capacity 时,会唤醒后台的 log_files_governor 线程,后台线程首先会重新计算当前的 redo_log_capacity,然后根据变化的类型:
- 如果是空间放大,直接根据放大后的大小,重新生成新的 unused redo 文件;
- 如果是空间缩小,需要计算当前已使用的空间数能否满足目标值,如果满足,那么缩小过程和放大过程一样,直接重新生成新的 ununsed redo 文件即可;如果不能,还需要在更新 redo_log_capacity 之后,通过调整暴露给 log_writer 和 page_cleaner 线程的 lsn 信息,来加速空间回收;
unused redo 文件的引入,类似于引入了缓存区的机制,因为 unused redo 文件不是正在使用的 redo 文件,所以可以直接进行重建,从而满足 innodb_redo_log_capacity 的设置。
3. 修改 innodb_redo_log_capacity 之后是不是立即生效?
对于这个问题,社区文档上的说法是:
When set at runtime, the configuration change occurs immediately but it may take some time for the new limit to be fully implemented. If the redo log files occupy less space than the specified value, dirty pages are flushed from the buffer pool to tablespace data files less aggressively, eventually increasing the disk space occupied by the redo log files. If the redo log files occupy more space than the specified value, dirty pages pages are flushed more aggressively, eventually decreasing the disk space occupied by redo log files.
简单点说就是:参数的修改是立即生效的,但是整个 redo 文件的变更过程需要花费一点时间。结合问题 1 和问题 2 比较容易理解,如果是空间放大,基本上是立即生效的;如果是空间缩小,可能需要依赖于后台刷脏线程的推进,来异步回收已经使用的空间。

