
- 1自动驾驶哪国强?各国和地区自动驾驶成熟度指数 | 自动驾驶系列
- 2Git仓库完整迁移全过程_gitee 将a仓库的克隆到b仓库
- 3微信小程序(十二)在线图标与字体的获取与引入_小程序 引入在线字体
- 4美团Java面试,狂问八股,感觉被榨干了_美团面试java
- 5Anaconda 无法启动的解决方案_annaconda无法启动
- 6远程桌面登录,锁定与解锁_远程桌面怎么解锁
- 7AI 实战篇 |基于 AI开放平台实现 人脸识别对比 功能,超详细教程【附带源码】_ai功能比较实践
- 8windows下安装chromedriver驱动
- 9网络安全SQL注入
- 10Ubuntu 24.04 LTS (Noble Numbat) 下载
MF(推荐系统的矩阵分解技术)论文笔记
赞
踩
论文概述
推荐系统的矩阵分解技术可以为用户提供更为准确的个性化推荐,对比传统的近邻技术,矩阵分解技术可以纳入更多信息,如隐式反馈、时间效应和置信度
近邻技术:基于用户或物品之间的相似性进行推荐,当用户之间已有评价计算出两个用户爱好类似,就将a用户的其他物品推荐给b
矩阵分解技术:把原来的大矩阵,近似分解成两个小矩阵的乘积,在实际推荐计算时不再使用大矩阵,而是使用分解得到的两个小矩阵。
论文内容
推荐系统策略
1. 为每一个用户或者项目创建一个档案记录特征,通过这些资料,系统可以将用户和匹配的产品联系起来
2. 协同过滤:依赖于用户过去的行为,分析用户之间的关系和产品之间的关系,按照群体行为去推荐,寻找和a相似的用户群体,将这些群体的爱好推荐给a
邻域方法:一个用户评价了产品A是好,那么他很有可能给A的相似产品B也评价好;当两个用户有很相似的爱好,那么他们之间的评分也可以互相补充
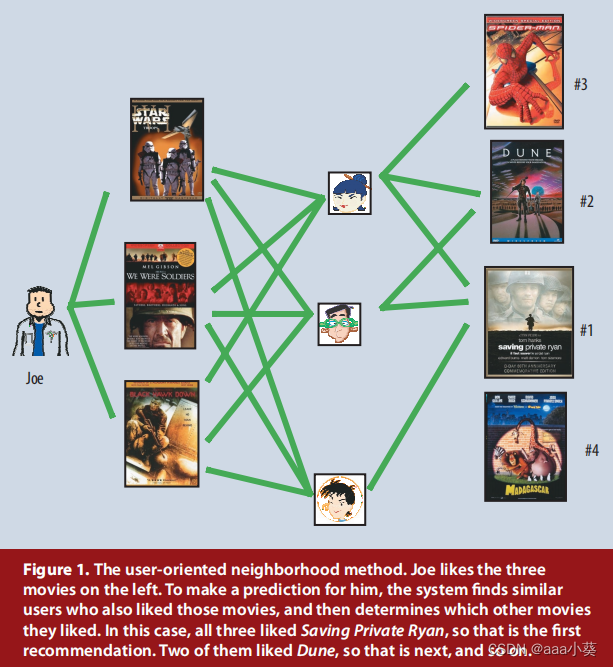
潜在因素模型:通过分析大量的用户评分,可以大概知道影响评分的一些潜在因素,比如你给戏剧电影很高评价,那么系统会认为戏剧这个特征就是一个潜在因素,当有新的戏剧出现就会给你推荐,利用一个二维模型简化说明,我们可以预测Gus可能对Dumb and Dumber的评分较高,而对Braveheart评分一般,不喜欢The Color Purple

横坐标表示用户的性别导向,纵坐标表示电影积极或消极,将用户和项目(电影)按照已有评价分析后放入图中,每个项目i对应一个向量qi,每个用户u对应一个pu,两者的点积越大,说明该用户对此项目偏爱程度更高
当一些用户可能并没有对某些电影做出评价,我们也可以通过该方法估算用户u对项目i的评分r
基本矩阵因式分解模型
将上述二维坐标扩展,将用户和项目映射到维数f的联合潜在因子空间,用户和项目的交互可以建模为空间的内积,捕获了用户和项目之间的交互,公式1表示预测的用户和项目之间的交互
该模型的主要挑战就是系统需要找到每个项目和用户映射的向量qi和pu,这个模型和SVD技术密切相关
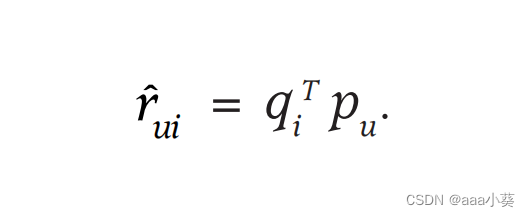
奇异值分解SVD技术:
将一个大矩阵分解为三个部分,第一个部分告诉我们数据的主要方向,第二个部分告诉我们每个方向的重要性有多大,第三个部分则是另一个角度的数据主要方向。,但是当数据稀疏性很高,会导致过拟合状态
损失函数
早期为了解决稀疏性问题采用填补空缺值,但是往往不准确的估计值会扭曲数据,我们只对已有的评分建模,该系统通过拟合先前观察到的评级来学习模型。

公式2为SVD的损失函数,系统会最小化已知评分集合上的正则化平方误差,在加号左边是最小化预测评分与实际评分之间的差异,加号右侧是正则化项(也叫惩罚项)用于控制模型的复杂度;可以防止出现过拟合状态
优化算法
最小化该上述方程有两个方法:随机梯度下降法和交替最小二乘法
随机梯度下降法
随机梯度下降(SGD)就像是在一座大山的地图上寻找最低点,但你不能看到整个地形,只能通过不断随机挑选一些地方来感受坡度,然后沿着坡度最大的方向小步向下走,希望最终能找到那个最低点。
随机梯度下降是一种迭代的优化算法,它在每次迭代中只使用一个或一小批训练样本来更新模型参数。这种方法的优点是在大规模数据集上效率较高,因为不需要在每次迭代时处理整个训练集。
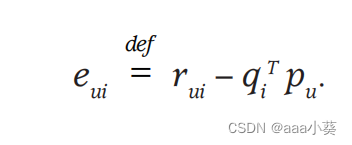
公式3表示给出训练集(u,i),系统会给出预测值qiTpu,然后用真是的计算值r减去预测值,得到误差预测值
接着我们要优化更新参数q和p,见公式4

首先,我们有一个误差项 e,它表示模型对第
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

