
利用机器学习识别验证码(从0到1)_机器学习算术验证码识别
赞
踩
最近喜欢先把测试结果图放前面。大家可以先看下效果。
识别速度并不是很快,代码并没有进一步优化。
本篇主要讲的是 从制作验证码开始,到我们利用机器学习识别出来结果的过程。
利用机器学习识别验证码的思路是:让计算机经过大量数据和相应标签的训练,计算机习得了各种不同标签之间的差别与关系。形成一个庞大的分类器。此时再向这个分类器输入一张图片。分类器将输出这个图片的“标签”。图片识别过程就完毕了。
下面我们正式开始本篇内容。
一:生成验证码:
这里生成验证码的方式是使用了python的PIL库。 他已经是Python平台上的图像处理标准库了。PIL功能非常强大,API也非常简单易用。
这里就放代码吧。
import random,os from PIL import ImageFont,Image,ImageDraw,ImageFilter def auth_code(): size = (140,40) #图片大小 font_list = list("0123456789") #验证码范围 c_chars = " ".join(random.sample(font_list,4)) # 4个+中间加个俩空格 print(c_chars) img = Image.new("RGB",size,(33,33,34)) #RGB颜色 draw = ImageDraw.Draw(img) #draw一个 font = ImageFont.truetype("arial.ttf", 23) #字体 draw.text((5,4),c_chars,font=font,fill="white") #字颜色 params = [1 - float(random.randint(1, 2)) / 100, 0, 0, 0, 1 - float(random.randint(1, 10)) / 100, float(random.randint(1, 2)) / 500, 0.001, float(random.randint(1, 2)) / 500 ] img = img.transform(size, Image.PERSPECTIVE, params) img = img.filter(ImageFilter.EDGE_ENHANCE_MORE) img.save(f'./test_img/{c_chars}.png') if __name__ == '__main__': if not os.path.exists('./test_img'): os.mkdir('./test_img') while True: auth_code() if len(os.listdir('./test_img'))>=3000: # 你改成 10000就行了 #我这个电脑太老了。 break

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
运行之后,就在 test_img 生成了如图所示的验证码图片。我这里是直接在生成时候以图片名 标注了 验证码对应的数字。 因为做案例嘛,不想再去爬验证码然后手动标注了。很累的!!
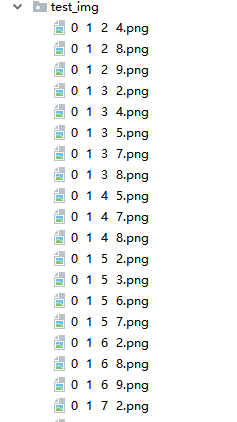
我这里生成的图片还是很干净的。如果你要搞比较复杂一点的图片,可以去看看下面贴的博客。

之前写过一篇利用opencv进行验证码处理,感兴趣可以看看,本篇的验证码并没有过多处理:https://blog.csdn.net/weixin_43582101/article/details/90609399
二:验证码分割
这里是要把我们生成的验证码,给切成4份,按照不同的标注,放到 train_data_img 不同的0—9的文件夹里面。
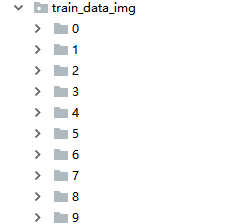
这个样子。做一个训练集。我这里分割也是处理的比较简单,按照宽度直接除以4 =。=
import os from PIL import Image from sklearn.externals import joblib import time def read_img(): img_array = [] img_lable = [] file_list = os.listdir('./test_img') for file in file_list: try: image = file img_array.append(image) except: print(f'{file}:图像已损坏') os.remove('./test_img/'+file) return img_array def sliceImg(img_path, count = 4): if not os.path.exists('train_data_img'): os.mkdir('train_data_img') for i in range(10): if not os.path.exists(f'train_data_img/{i}'): os.mkdir(f'train_data_img/{i}') img = Image.open('./test_img/'+img_path) w, h = img.size eachWidth = int((w - 17) / count) img_path = img_path.replace(' ', '').split('.')[0] for i in range(count): box = (i * eachWidth, 0, (i + 1) * eachWidth, h) img.crop(box).save(f'./train_data_img/{img_path[i]}/'+img_path[i]+ str(time.time()) + ".png") if __name__ == '__main__': img_array = read_img() for i in img_array: print(i) sliceImg(i)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
跑完之后,每个文件夹下面都有对应的验证码图片,并且他们的标注时图片名的首字母。
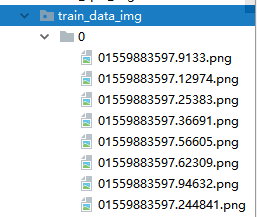
三:验证码特征提取
这里的思路是:利用 numpy 先把 train_data_img 图片转换成向量,我没有转01,嫌麻烦=。=
from PIL import Image
import numpy as np
import os
from sklearn.neighbors import KNeighborsClassifier as knn
def img2vec(fname):
'''将图片转为向量'''
im = Image.open(fname).convert('L')
im = im.resize((30,30))
tmp = np.array(im)
vec = tmp.ravel()
return vec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
然后利用我们标注好的标签,来做一个特征提取,
tarin_img_path = 'train_data_img'
def split_data(paths):
X = []
y = []
for i in os.listdir(tarin_img_path):
path = os.path.join(tarin_img_path, i)
fn_list = os.listdir(path)
for name in fn_list:
y.append(name[0])
X.append(img2vec(os.path.join(path,name)))
return X, y # x向量 y标签
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
然后构建一个分类器,
def knn_clf(X_train,label):
'''构建分类器'''
clf = knn()
clf.fit(X_train,label)
return clf
- 1
- 2
- 3
- 4
- 5
这里使用的是sklearn中的knn,我直接调包了。如果想看手写版本的,可以看之前写的KNN手写数字识别。https://blog.csdn.net/weixin_43582101/article/details/88772273
构建完分类器后,就可以把上面的结合起来,做一个识别模型了。
def knn_shib(test_img):
X_train,y_label = split_data(tarin_img_path)
clf = knn_clf(X_train,y_label)
result = clf.predict([img2vec(test_img)])
return result
- 1
- 2
- 3
- 4
- 5
四:验证码识别
我前面忘记搞测试集了,这次还是使用上面生成验证码的方法来生成一点测试集。
import random,time import os from PIL import ImageFont,Image,ImageDraw,ImageFilter def auth_code(): size = (140,40) #图片大小 font_list = list("0123456789") #验证码范围 c_chars = " ".join(random.sample(font_list,4)) # 4个+中间加个俩空格 print(c_chars) img = Image.new("RGB",size,(33,33,34)) #RGB颜色 draw = ImageDraw.Draw(img) #draw一个 font = ImageFont.truetype("arial.ttf", 23) #字体 draw.text((5,4),c_chars,font=font,fill="white") #字颜色 params = [1 - float(random.randint(1, 2)) / 100, 0, 0, 0, 1 - float(random.randint(1, 10)) / 100, float(random.randint(1, 2)) / 500, 0.001, float(random.randint(1, 2)) / 500 ] img = img.transform(size, Image.PERSPECTIVE, params) img = img.filter(ImageFilter.EDGE_ENHANCE_MORE) random_name = str(time.time())[-7:] img.save(f'./test_data_img/{random_name}.png') if __name__ == '__main__': if not os.path.exists('./test_data_img'): os.mkdir('./test_data_img') while True: auth_code() if len(os.listdir('./test_data_img'))>=30: break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
测试集图片保存在 test_data_img 中,但是现在的图片是完整的,我们想要识别,就要按照之前的方法先进行图片切割,分成4份,然后拿我们的模型来识别。
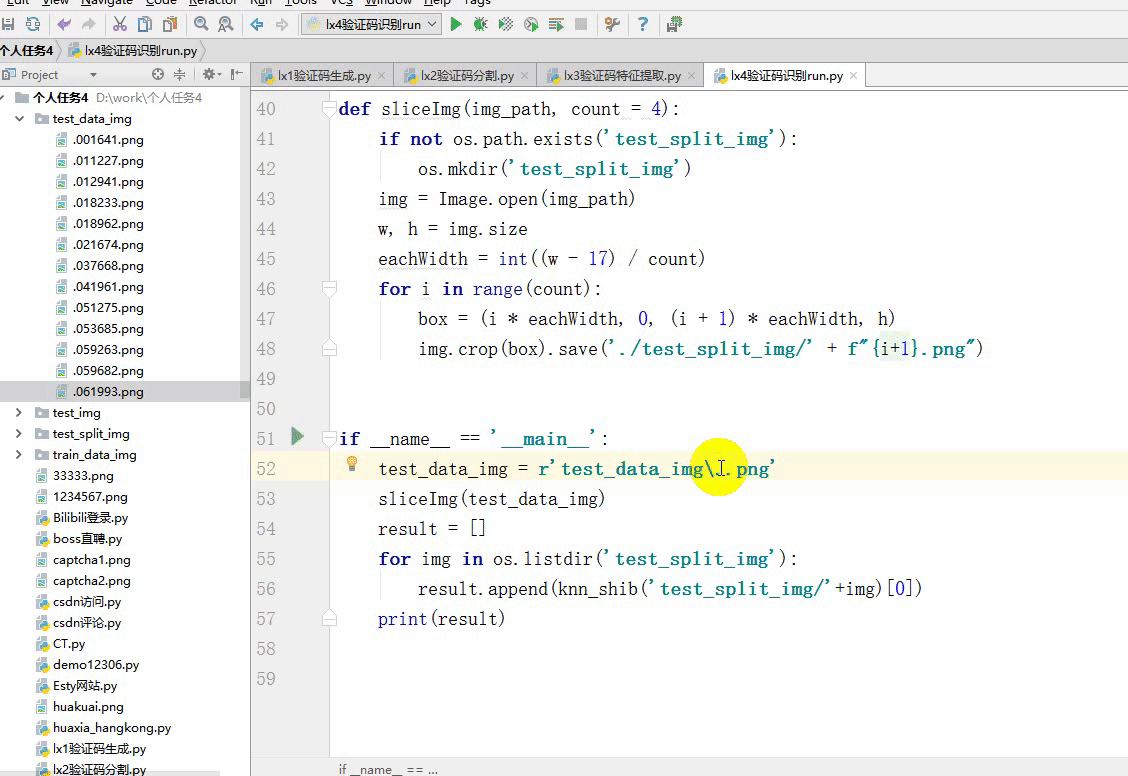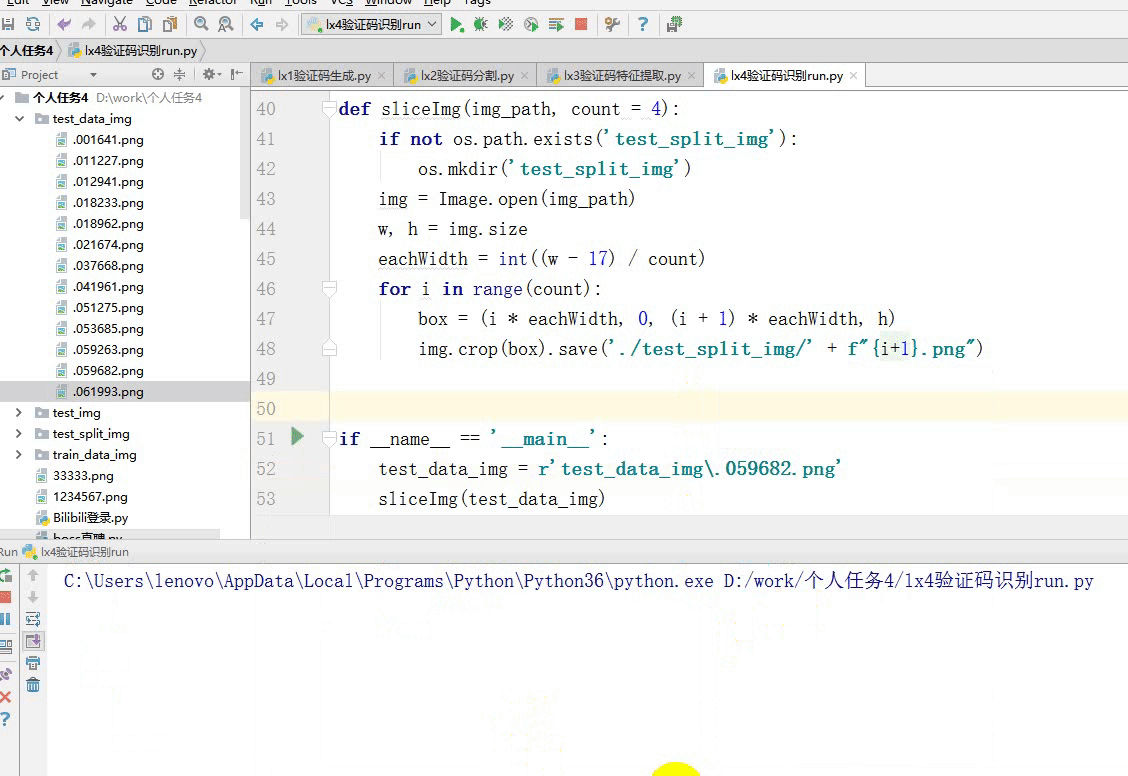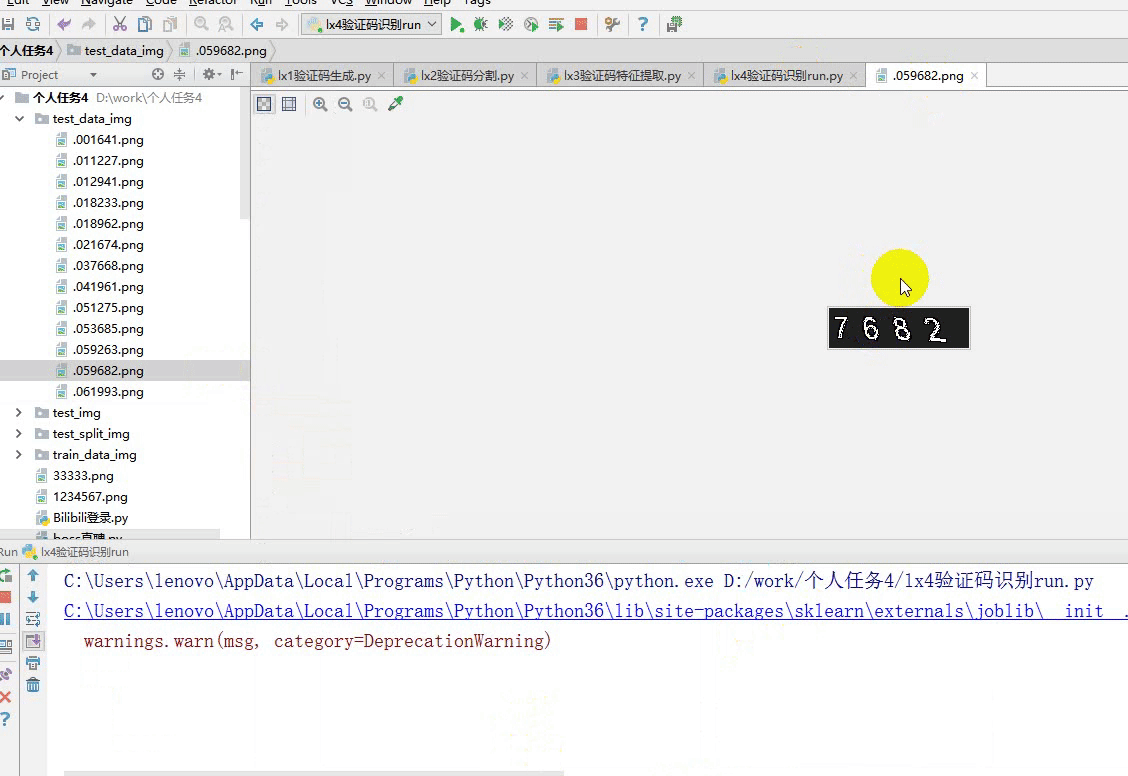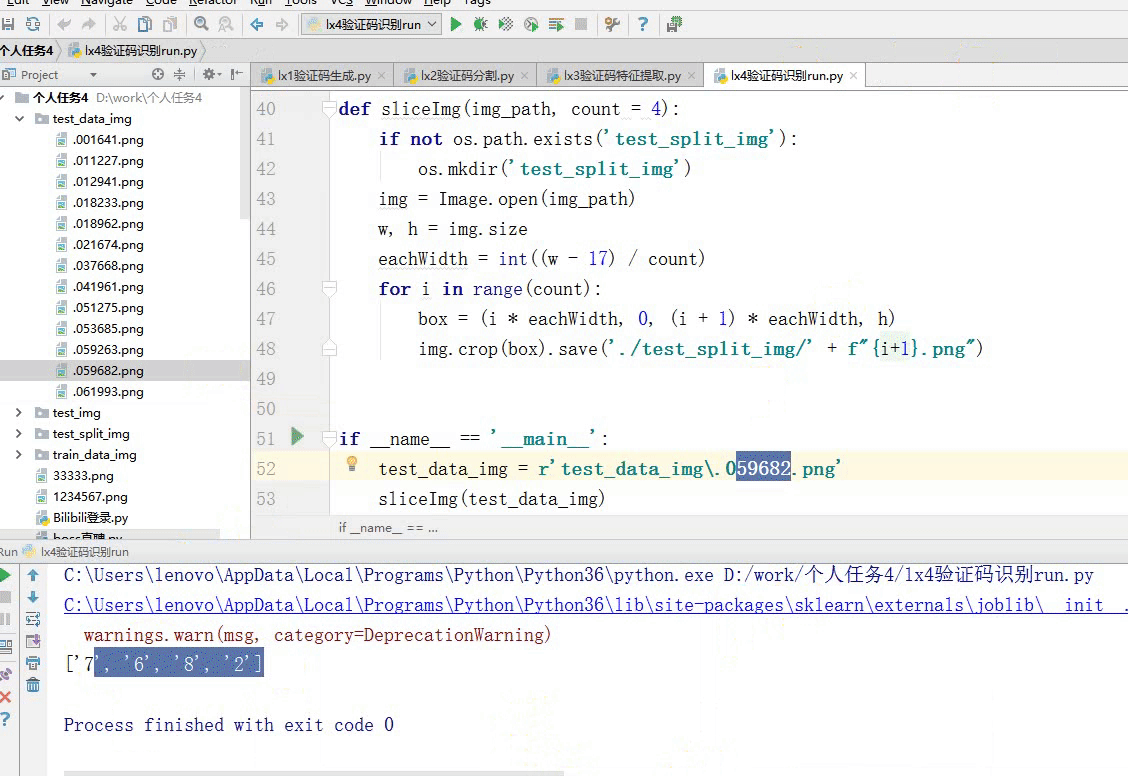
from lx3验证码特征提取 import * from lx2验证码分割 import * def sliceImg(img_path, count = 4): if not os.path.exists('test_split_img'): os.mkdir('test_split_img') img = Image.open(img_path) w, h = img.size eachWidth = int((w - 17) / count) for i in range(count): box = (i * eachWidth, 0, (i + 1) * eachWidth, h) img.crop(box).save('./test_split_img/' + f"{i+1}.png") if __name__ == '__main__': test_data_img = r'test_data_img\.059682.png' sliceImg(test_data_img) result = [] for img in os.listdir('test_split_img'): result.append(knn_shib('test_split_img/'+img)[0]) print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
到这里其实就结束了,这里的代码主要还是以案例为主,并没有进行优化,很多地方都需要改进,一些细节也没有处理,感兴趣的同学大家可以自己再进行改进。
祝大家端午节快乐啊。
数据和代码都放在github。可直接下载,https://github.com/lixi5338619/OCR_Yanzhengma/tree/master


